2022-CVPR-Transformador giratorio de vídeo
Transformador giratorio de vídeo
Resumen
El campo de visión está siendo testigo de un cambio de modelado de CNN a Transformers, con arquitecturas Transformer puras que logran la mayor precisión en los principales puntos de referencia de reconocimiento de video. Estos modelos de vídeo se basan en capas Transformer, que conectan globalmente bloques tanto en dimensiones espaciales como temporales. En este artículo, defendemos el sesgo inductivo local en los transformadores de video, que permite que la autoatención se calcule globalmente, lo que resulta en mejores compensaciones entre velocidad y precisión en comparación con los métodos anteriores, incluso utilizando la descomposición espaciotemporal. La localidad de la arquitectura de video propuesta se Swin Transformerlogra adaptándola al diseño del dominio de la imagen, mientras se continúa explotando el poder de los modelos de imagen previamente entrenados. Nuestro enfoque logra una precisión de vanguardia en una amplia gama de puntos de referencia de reconocimiento de video, incluido el reconocimiento de acciones (84,9 precisión superior en Kinetics-400 y 85,9 precisión superior en Kinetics-600, lo que reduce aproximadamente 20 veces la precisión previa). -datos de entrenamiento y tamaño de modelo 3 veces más pequeño) y modelado temporal (69,6 precisión superior en SomethingSomething v2).
1. Introducción
Las arquitecturas troncales basadas en convolución han dominado durante mucho tiempo el modelado visual en visión por computadora [14, 18, 22, 24, 32, 33]. Sin embargo, la arquitectura principal actual de clasificación de imágenes está experimentando un cambio de modelado, de redes neuronales convolucionales (CNN) a Transformer [8, 28, 34]. Esta tendencia comenzó con la introducción de Vision Transformer (ViT) [8, 34], que utiliza un codificador Transformer estándar [38] para modelar globalmente relaciones espaciales en parches de imágenes que no se superponen. El gran éxito de ViT en imágenes ha llevado a investigar arquitecturas basadas en Transformer para tareas de reconocimiento de vídeo [1, 3].
Anteriormente, para los modelos convolucionales, la arquitectura troncal del vídeo simplemente se adaptaba a partir de la arquitectura troncal de la imagen ampliando el modelado en la línea de tiempo . Por ejemplo, la convolución 3D [35] es una extensión directa de la convolución 2D para el modelado espacial y temporal conjunto a nivel de operador. Dado que el modelado espaciotemporal conjunto no es económico ni fácil de optimizar, se ha propuesto la descomposición de los dominios espaciales y temporales para lograr una mejor relación velocidad-precisión [30, 41]. En los intentos iniciales de reconocimiento de video basado en Transformer, también se adoptaron métodos de descomposición , ya sea descomponiendo el codificador [1] o descomponiendo la autoatención [1, 3]. Se ha demostrado que esto reduce significativamente el tamaño del modelo sin reducir significativamente el rendimiento.
En este artículo, proponemos una arquitectura troncal Transformer pura para el reconocimiento de video y descubrimos que su eficiencia excede la de los modelos factorizados. Para ello, explota la localidad espaciotemporal inherente del vídeo, donde los píxeles que están más cerca entre sí en la distancia espaciotemporal tienen más probabilidades de estar correlacionados entre sí . Debido a esta propiedad, la autoatención espaciotemporal completa se puede aproximar bien mediante la autoatención calculada localmente, lo que resulta en ahorros significativos en el cálculo y el tamaño del modelo.
Implementamos este enfoque a través de la adaptación espaciotemporal de Swin Transformer [28], que se introdujo recientemente como una columna vertebral visual de propósito general para la comprensión de imágenes. Swin Transformer combina localidad espacial con polarización inductiva para invariancia de nivel y traducción . Nuestro modelo, llamado Video Swin Transformer, sigue estrictamente la estructura jerárquica del Swin Transformer original, pero extiende el alcance del cálculo de la atención local desde solo el dominio espacial al dominio espaciotemporal . Dado que la atención local se calcula sobre ventanas que no se superponen, el mecanismo de ventana cambiante del Swin Transformer original también se reformula para manejar la entrada espaciotemporal.
Dado que nuestra arquitectura está adaptada de Swin Transformer, se puede inicializar fácilmente utilizando modelos potentes previamente entrenados en conjuntos de datos de imágenes a gran escala. Utilizando un modelo previamente entrenado en ImageNet-21K, encontramos curiosamente que la tasa de aprendizaje de la arquitectura troncal debe ser menor que la del cabezal inicializado aleatoriamente (por ejemplo, 0,1 ×). Como resultado, la red troncal olvida lentamente los parámetros y datos previamente entrenados a medida que se adapta a nuevas entradas de video, lo que lleva a una mejor generalización. Esta observación señala el camino para futuras investigaciones sobre cómo utilizar mejor las pesas previamente entrenadas.
El método propuesto muestra un sólido rendimiento en tareas de reconocimiento de video de reconocimiento de acciones en Kinetics400/Kinetics-600 y modelado temporal en SomethingSomething v2 (abreviado como SSv2). Para el reconocimiento de acciones de video, su precisión superior del 84,9 % en Kinetics-400 y su precisión superior del 85,9 % en Kinetics-600 son ligeramente superiores al mejor resultado anterior (ViViT [1]) en +0,1 puntos, tamaño de modelo más pequeño ( 200,0 millones de parámetros de Swin-L frente a 647,5 millones de parámetros de ViViT-H) y un conjunto de datos previo al entrenamiento más pequeño (ImageNet-21K frente a JFT-300M). Para el modelado temporal en SSv2, logra una precisión superior del 69,6%, una mejora de +0,9 puntos con respecto al estado del arte anterior (MViT [9]).
2. Trabajo relacionado
En visión por computadora, las redes convolucionales han sido durante mucho tiempo la arquitectura principal estándar. Para el modelado 3D, C3D [35] es un trabajo pionero que diseña una red profunda de 11 capas con convoluciones 3D. El trabajo de I3D [5] muestra que inflar convoluciones 2D en Inception V1 a convoluciones 3D e inicializarlas con pesos preentrenados de ImageNet logra buenos resultados en conjuntos de datos de Kinetics a gran escala. En P3D [30], S3D [41] y R(2+1)D [37], se encontró que las convoluciones espaciales y temporales desenredadas logran mejores compensaciones entre velocidad y precisión que las convoluciones 3D originales. El potencial de los métodos basados en convolución está limitado por el pequeño campo receptivo del operador de convolución. Con el mecanismo de autoatención, el campo receptivo se puede ampliar con menos parámetros y menores costos computacionales, lo que permite a Vision Transformers funcionar mejor en el reconocimiento de video .
Autoatención/Transformers complementan CNN . NLNet [40] es el primer trabajo que adopta la autoatención para modelar la dependencia de largo alcance a nivel de píxeles de las tareas de reconocimiento visual. GCNet [4] observó que la mejora en la precisión de NLNet se atribuye principalmente a su modelado de contexto global, por lo que simplifica el bloque NL en un bloque de contexto global liviano con un rendimiento comparable al de NLNet pero con menos parámetros y menos cálculo. Por el contrario, DNL [43] intenta aliviar este problema de degradación a través de un diseño de entrelazamiento descompuesto que permite aprender diferentes contextos para diferentes píxeles preservando al mismo tiempo el contexto global compartido. Todos estos métodos proporcionan un componente complementario a CNN para modelar dependencias de largo alcance. En nuestro trabajo, demostramos que los métodos basados puramente en Transformer capturan de manera más completa el poder de la autoatención, lo que conduce a un rendimiento superior.
Transformadores de visión . La transformación de la arquitectura troncal de visión por computadora de CNN a Transformers ha comenzado recientemente con Vision Transformer (ViT) [8, 34]. Este trabajo pionero dio lugar a investigaciones posteriores encaminadas a mejorar su utilidad. DeiT [34] integra varias estrategias de entrenamiento, lo que permite a ViT utilizar también de manera eficiente el conjunto de datos más pequeño ImageNet1K. Swin Transformer [28] introduce además sesgos inductivos para la localidad, la jerarquía y la invariancia de traducción, lo que le permite servir como columna vertebral general para diversas tareas de reconocimiento de imágenes.
El gran éxito de los Transformers de imágenes ha llevado a la investigación de arquitecturas basadas en Transformers para tareas de reconocimiento basadas en vídeo [1, 3, 9, 25, 29]. VTN [29] propone agregar un codificador de atención temporal además de ViT previamente entrenado, lo que produce un buen rendimiento en el reconocimiento de acciones de video. TimeSformer [3] estudia cinco variantes diferentes de atención espaciotemporal y propone una atención espaciotemporal factorizada para lograr su poderosa compensación entre velocidad y precisión. ViViT [1] examina cuatro diseños de descomposición de atención espacial y temporal para modelos ViT previamente entrenados y propone una arquitectura similar a VTN que logra un rendimiento de vanguardia en el conjunto de datos de Kinetics. MViT [9] es un transformador visual multiescala para reconocimiento de video entrenado desde cero, que logra resultados de última generación en SSv2 al centrar la atención en el modelado espaciotemporal para reducir el esfuerzo computacional. Todos estos estudios se basan en el módulo de autoatención global. En este artículo, primero estudiamos la localidad espaciotemporal y luego demostramos experimentalmente que Video Swin Transformer con sesgo de localidad espaciotemporal supera a todos los demás Transformers visuales en diversas tareas de reconocimiento de video .
3. Transformador giratorio de vídeo
3.1 Arquitectura general
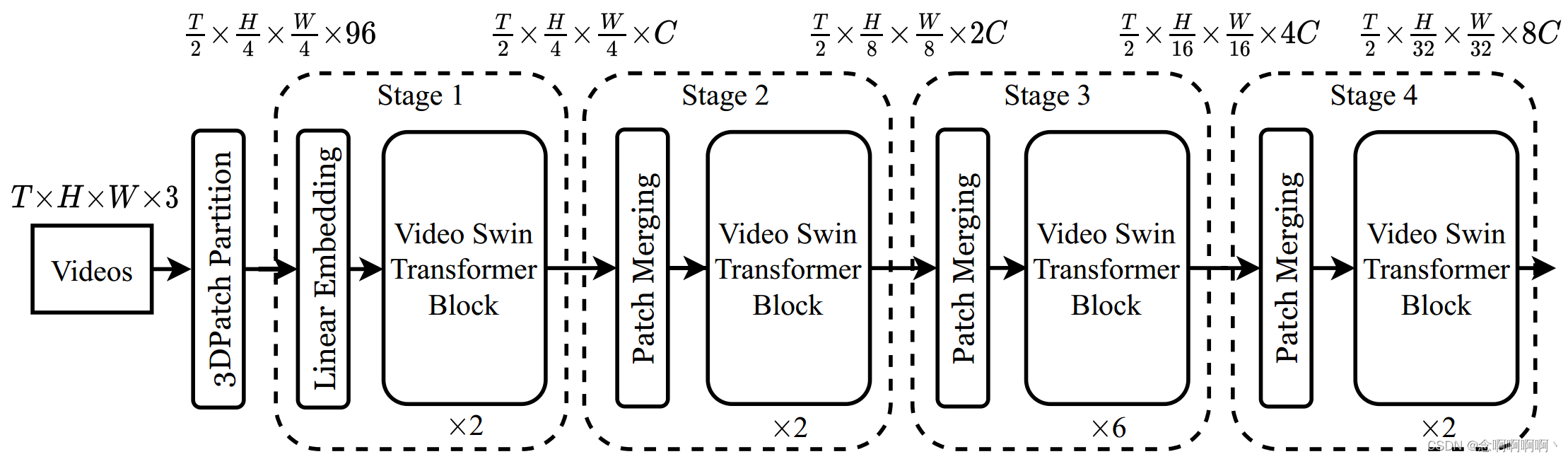
La arquitectura general del Video Swin Transformer propuesto se muestra en la Figura 2, donde se muestra su versión en miniatura (Swin-T). El tamaño del vídeo de entrada se define como T × H × W × 3 T\times H\times W\times3t×h×W.×3 , porTTCompuesto por T cuadros, cada cuadro contieneH × W × 3 H\times W\times3h×W.×3 píxeles. En Video Swin Transformer, tratamos cada bloque 3D de tamaño 2×4×4×3 como un token. Por lo tanto, la capa de partición del parche 3D obtieneT 2 × H 4 × W 4 \frac{T}{2}\times\frac{H}{4}\times\frac{W}{4}2t×4h×4WFichas 3D, cada parche/ficha consta de una característica de 96 dimensiones. Luego aplique una capa de incrustación lineal para proyectar las características de cada token al CCC representa cualquier dimensión.
Siguiendo las técnicas existentes [11, 12, 30, 41], no reducimos la resolución a lo largo de la dimensión temporal . Esto nos permite seguir estrictamente la estructura jerárquica del Swin Transformer original [28], que consta de cuatro etapas y realiza una reducción de resolución espacial 2× en la capa de fusión de parches de cada etapa. Una capa de fusión de parches concatena las características de cada conjunto de parches espacialmente adyacentes de 2×2, y se aplica una capa lineal para proyectar las características concatenadas a la mitad de sus dimensiones. Por ejemplo, la capa lineal en la segunda etapa proyecta las características de 4C dimensiones de cada token a 2C dimensiones.
El componente principal de la arquitectura es el bloque Video Swin Transformer, que se construye reemplazando el módulo de autoatención de múltiples cabezales (MSA) en la capa Transformer estándar con un módulo de autoatención de múltiples cabezales basado en ventana de desplazamiento 3D (introducido en la Sección 3.2) y mantenga los demás componentes sin cambios . Específicamente, el bloque Video Transformer consta de un módulo MSA basado en ventana de desplazamiento 3D y una red de alimentación directa, es decir, un MLP de 2 capas con no linealidad GELU en el medio. La normalización de capa (LN) se aplica antes de cada módulo MSA y FFN, y las conexiones residuales se aplican después de cada módulo. La fórmula de cálculo del bloque Video Swin Transformer se proporciona en la ecuación (1).
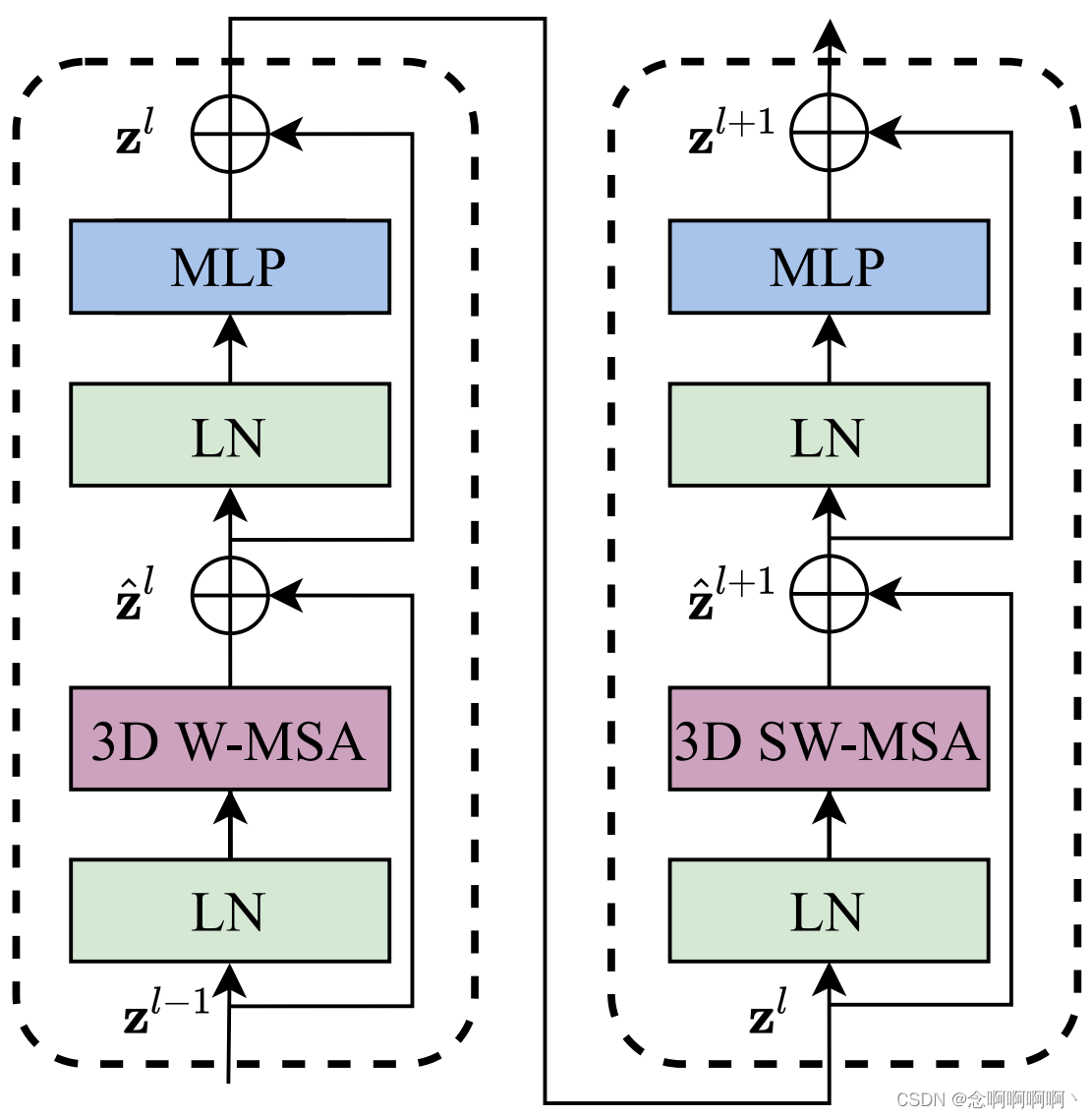
3.2 Módulo MSA basado en ventana de traducción 3D
En comparación con las imágenes, los vídeos requieren más tokens de entrada para representarlos porque los vídeos también tienen una dimensión temporal . Por lo tanto, los módulos de autoatención global no son adecuados para tareas de vídeo, ya que esto generaría enormes costos computacionales y de memoria. Aquí, seguimos el Swin Transformer para introducir un sesgo inductivo local en el módulo de autoatención, que luego demostró ser efectivo para el reconocimiento de video.
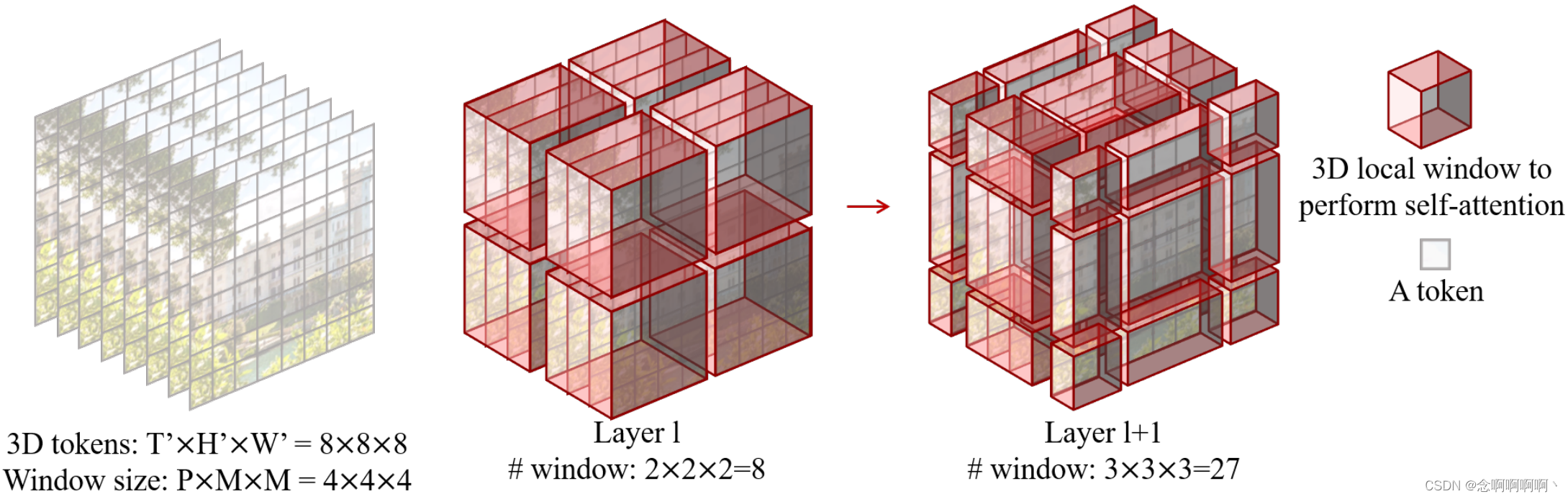
Autoatención de múltiples cabezales en ventanas 3D que no se superponen . Se ha demostrado que el mecanismo de autoatención de múltiples cabezales (MSA) en cada ventana 2D no superpuesta es efectivo y eficiente para el reconocimiento de imágenes. Aquí ampliamos directamente este diseño para manejar la entrada de video. Dado por T ′ × H ′ × W ′ T^\prime\times H^\prime\times W^\primet′×h′×W.′ Marcadores 3D yP × M × MP\times M\times MPAG×METRO×Un vídeo que consta de ventanas 3D de tamaño M dispuestas para dividir uniformemente la entrada de vídeo sin superponerse. Es decir, los tokens de entrada se dividen en⌈ T ′ P ⌉ × ⌈ H ′ M ⌉ × ⌈ W ′ M ⌉ \left\lceil\frac{T^\prime}{P}\right\rceil\times\left\ lceil\frac{H^\prime}{M}\right\rceil\times\left\lceil\frac{W^\prime}{M}\right\rceil⌈PAGt′⌉×⌈METROh′⌉×⌈METROW.′⌉Ventanas 3D que no se superponen. Por ejemplo, como se muestra en la Figura 3, para8 × 8 × 8 8 × 8 × 88×8×Tamaño de 8 fichas y4×4×4 4×4×44×4×Tamaño de ventana de 4 , llEl número de ventanas en la capa l será 2 × 2 × 2 = 8 2×2×2=82×2×2=8 . Y la autoatención de múltiples cabezales se realiza en cada ventana 3D.
Ventana de cambio 3D . Dado que el mecanismo de autoatención de múltiples cabezales se aplica en cada ventana 3D que no se superpone, existe una falta de conexiones entre diferentes ventanas, lo que puede limitar la capacidad de representación de la arquitectura. Por lo tanto, ampliamos el mecanismo de ventana 2D móvil de Swin Transformer a ventanas 3D con el objetivo de introducir conexiones entre ventanas mientras se mantiene un cálculo eficiente de la autoatención basado en ventanas que no se superponen .
Supongamos que el número de tokens 3D de entrada es T ′ × H ′ × W ′ T^\prime\times H^\prime\times W^\primet′×h′×W.′ , el tamaño de cada ventana 3D esP × M × MP\times M\times MPAG×METRO×M , para dos capas consecutivas, el módulo de autoatención de la primera capa utiliza una estrategia de partición de ventana convencional para que obtengamos⌈ T ′ P ⌉ × ⌈ H ′ M ⌉ × ⌈ W ′ M ⌉ \left\lceil\frac{ T ^\prime}{P}\right\rceil\times\left\lceil\frac{H^\prime}{M}\right\rceil\times\left\lceil\frac{W^\prime}{M} \ derecha\rceil⌈PAGt′⌉×⌈METROh′⌉×⌈METROW.′⌉Ventanas 3D que no se superponen. Para el módulo de autoatención en la segunda capa, la configuración de la partición de la ventana se mueve a lo largo del eje de tiempo, los ejes de altura y ancho por ( P 2 , M 2 , M 2 ) \ left(\frac{P}{2},\ \frac{M}{2},\ \frac{M}{2}\derecha)(2P, 2m, 2m) ficha.
Ilustramos esto usando el ejemplo de la Figura 3. El tamaño de entrada es 8 × 8 × 8 8 × 8 × 88×8×8 , el tamaño de la ventana es4 × 4 × 4 4 × 4 × 44×4×4 . debidopeajeLa capa l adopta una división de ventana regular,llEl número de ventanas en la capa l es 2 × 2 × 2 = 8 2×2×2=82×2×2=8 . Para ell+1 l+1yo+Nivel 1 , a medida que la ventana se mueve( P 2 , M 2 , M 2 ) = ( 2 , 2 , 2 ) \left(\frac{P}{2},\ \frac{M}{2},\ \frac {M}{2}\derecha)=\izquierda(2,\ 2,\ 2\derecha)(2P, 2m, 2m)=( 2 , 2 , 2 ) marcadores, el número de ventanas se convierte en3 × 3 × 3 = 27 3×3×3=273×3×3=27 . Aunque el número de ventanas ha aumentado, se puede seguir el cálculo por lotes eficiente para la configuración de turnos en [28], de modo que el número final calculado de ventanas sigue siendo8 88 .
Utilizando 移位窗口分区el método, se calculan dos bloques consecutivos de Video Swin Transformer como
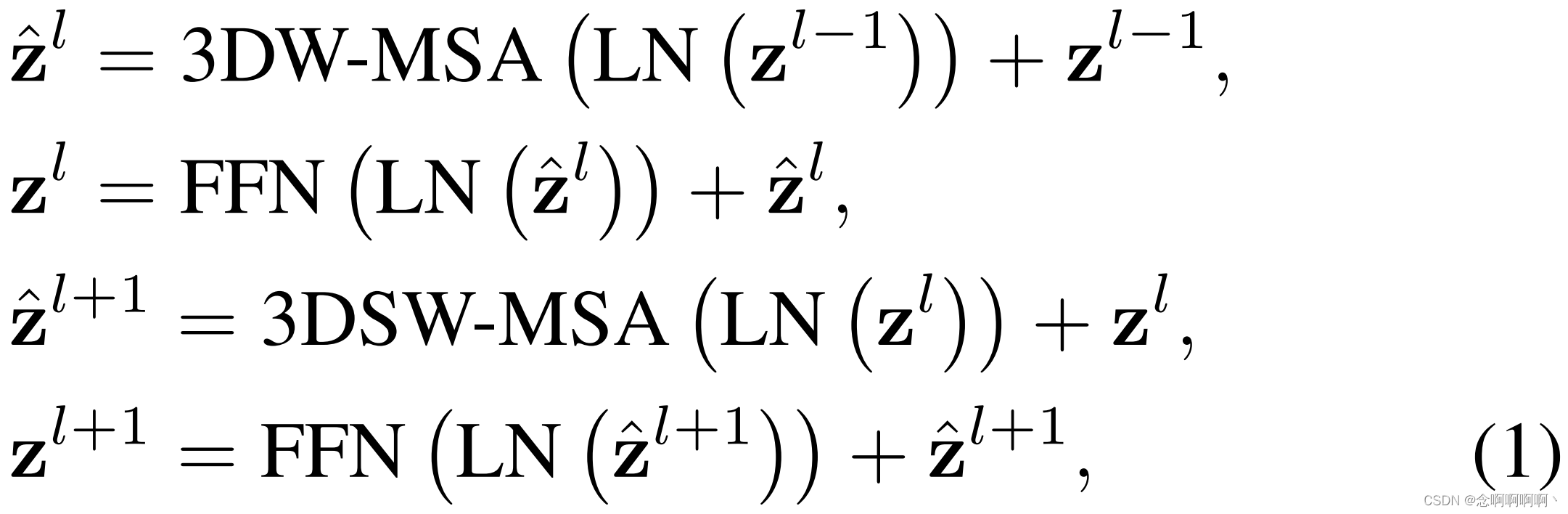
其中z ^ l {\hat{\mathbf{z}}}^lz^l和zl \mathbf{z}^lzl representa respectivamente el bloquellLas características de salida del módulo 3D(S)WMSA y el módulo FFN de l ; 3DW-MSA y 3DSW-MSA respectivamente representan la autoatención de múltiples cabezales basada en ventanas 3D que utilizan configuraciones de tabla de división de ventanas convencionales y desplazadas.
Similar al reconocimiento de imágenes [28], esta ventana 3D desplazada introduce conexiones entre ventanas 3D adyacentes que no se superponen en la capa anterior . Más adelante se demostrará que esto es eficaz para varias tareas de reconocimiento de vídeo, como el reconocimiento de acciones en Kinetics 400/600 y el modelado temporal en SSv2.
Desviación de posición relativa 3D . Muchos trabajos anteriores [2, 16, 17, 31] han demostrado que es ventajoso incluir el sesgo de posición relativa de cada cabeza en el cálculo de la autoatención . Por lo tanto, introducimos la desviación de posición relativa 3D B ∈ RP 2 × M 2 × M 2 B\in\mathbb{R}^{P^2\times M^2\times M^2} para cada cabeza siguiente [28 ]B∈RPAG2 ×M2 ×M2 para
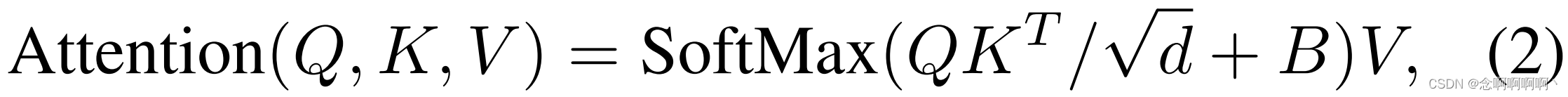
Donde Q , K , V ∈ RPM 2 × d Q,\ K,\ V\in\mathbb{R}^{PM^2\times d}P , k , V∈RPM _2 ×des la matriz de consulta, clave y valor; d es la dimensión de la consulta y las características clave, PM2 es el número de marcadores en la ventana 3D. Dado que la posición relativa a lo largo de cada eje está en[ − P + 1 , P − 1 ] \left[-P+1,\ P-1\right][ -P _+1 , PAG−1 ] (tiempo) o[ − M + 1 , M − 1 ] \left[-M+1,\ M-1\right][ − METRO+1 , METRO−1 ] (alto o ancho), parametrizamos una matriz de sesgo de tamaño más pequeñoB ^ ∈ R ( 2 P − 1 ) × ( 2 M − 1 ) × ( 2 M − 1 ) \hat{ B}\in\mathbb{R }^{\left(2P-1\right)\times\left(2M-1\right)\times\left(2M-1\right)}B^∈R( 2 P - 1 ) × ( 2 M - 1 ) × ( 2 M - 1 ),BBLos valores en B están tomados de B ^ \hat{B}B^。
3.3 Variables estructurales
A continuación de [28], presentamos cuatro versiones diferentes de Video Swin Transformer. Los hiperparámetros arquitectónicos para estas variantes de modelo son :
- Swin-T: C = 96 C = 96C=96 , número de capas= { 2 , 2 , 6 , 2 } =\left\{2,\ 2,\ 6,\ 2\right\}={ 2 , 2 , 6 , 2 }
- Swin-S: C = 96 C = 96C=96 , número de capas= { 2 , 2 , 18 , 2 } =\left\{2,\ 2,\ 18,\ 2\right\}={ 2 , 2 , 18 , 2 }
- Swin-B: C = 128 C = 128C=128 , número de capas= { 2 , 2 , 18 , 2 } =\left\{2,\ 2,\ 18,\ 2\right\}={ 2 , 2 , 18 , 2 }
- Swin-L: C = 192 C = 192C=192 , número de capas= { 2 , 2 , 18 , 2 } =\left\{2,\ 2,\ 18,\ 2\right\}={ 2 , 2 , 18 , 2 }
donde CCC representa el número de canales de la capa oculta en la primera etapa. Estas cuatro versiones son aproximadamente 0,25 veces, 0,5 veces, 1 vez y 2 veces el tamaño y la complejidad computacional del modelo base, respectivamente. De forma predeterminada, el tamaño de la ventana está establecido enP=8 P=8PAG=8 yM = 7 M = 7METRO=7 . La dimensión de consulta de cada encabezado esd = 32 d = 32d=32 , la capa de expansión de cada MLP se establece enα = 4 \alpha=4a=4 .
3.4 Inicialización desde un modelo previamente entrenado
Dado que nuestra arquitectura está adaptada de Swin Transformer [28], nuestro modelo puede inicializarse mediante su potente modelo previamente entrenado en conjuntos de datos a gran escala. En comparación con el Swin Transformer original, solo dos bloques de construcción en Video Swin Transformers tienen formas diferentes: la capa de incrustación lineal en la primera etapa y el sesgo de posición relativa en el bloque Video Swin Transformer.
Para nuestro modelo, los tokens de entrada se dilatan a una dimensión temporal de 2, por lo que la forma de la capa de incrustación lineal cambia de 48 × C en el Swin original.48×C se convierte en96 × C 96 × C96×C._ _ Aquí, copiamos directamente los pesos del modelo previamente entrenado dos veces y luego multiplicamos toda la matriz por 0,5 para mantener la media y la varianza de la salida sin cambios. La forma de la matriz de desplazamiento de posición relativa es( 2 P − 1 , 2 M − 1 , 2 M − 1 ) (2P−1, 2M−1, 2M−1)( 2P _−1 ,2M_ _−1 ,2M_ _−1 ) , mientras que en el Swin original es( 2 M − 1 , 2 M − 1 ) (2M−1, 2M−1)( 2 millones _−1 ,2M_ _−1 ) . Para que la desviación de la posición relativa sea la misma dentro de cada cuadro, copiamos la matriz en el modelo previamente entrenado2 P − 1 2P−12p _−1 vez para obtener( 2 P − 1 , 2 M − 1 , 2 M − 1 ) (2P−1, 2M−1, 2M−1)( 2P _−1 ,2M_ _−1 ,2M_ _−1 ) para inicializar la forma.
4. Experimentar
4.1 Configuración
conjunto de datos . Para el reconocimiento de la acción humana, empleamos dos versiones del conjunto de datos Kinetics [20] ampliamente utilizado, Kinetics400 y Kinetics-600. Kinetics-400 (K400) consta de aproximadamente 240.000 vídeos de formación y 20.000 vídeos de validación en 400 categorías de comportamiento humano. Kinetics-600 (K600) es una extensión de K400 y contiene aproximadamente 370.000 vídeos de formación y 28,3.000 vídeos de validación de 600 categorías de acciones humanas. Para el modelado temporal, utilizamos el popular conjunto de datos SomethingSomething V2 (SSv2) [13], que contiene 168,9 000 vídeos de formación y 24,7 000 vídeos de validación en 174 categorías. Para todos los métodos, seguimos los últimos avances al informar la precisión de reconocimiento de los primeros 1 y 5 primeros.
Detalles de implementación . Para K400 y K600, adoptamos el optimizador AdamW [21] durante 30 épocas, utilizando un programador de tasa de aprendizaje de caída del coseno y un calentamiento lineal de 2,5 épocas. Utilice un tamaño de lote de 64. Dado que la columna vertebral se inicializa a partir de un modelo previamente entrenado, mientras que la cabeza se inicializa aleatoriamente, encontramos que multiplicar la tasa de aprendizaje de la columna vertebral por 0,1 mejora el rendimiento (como se muestra en la Tabla 7). Específicamente, las tasas de aprendizaje inicial de la columna vertebral previamente entrenada de ImageNet y los cabezales inicializados aleatoriamente se establecen en 3e-5 y 3e-4 respectivamente. A menos que se indique lo contrario, para todas las variantes del modelo, tomamos muestras de un clip de 32 cuadros de cada video completo usando un paso de tiempo de 2 y un tamaño espacial de 224 × 224, lo que da como resultado 16 × 56 × 56 tokens 3D de entrada. Después de [28], se utiliza un mayor grado de profundidad estocástica [19] y caída de peso para modelos más grandes, concretamente 0,1, 0,1, 0,3 de profundidad estocástica para Swin-T, Swin-S y Swin-B respectivamente. 0,02, 0,02, 0,05. Para razonar, seguimos [1] usando una vista de 4 × 3, donde un video se muestrea uniformemente en 4 clips en la dimensión temporal, y para cada clip, el borde espacial más corto se escala a 224 píxeles. Usamos 3 tamaños de 224 × 224 cultivos para cubrir el eje espacial más largo. La puntuación final se calcula como la puntuación media de todas las vistas. Para los experimentos de entrenamiento desde cero, adoptamos el código base de [9] y seguimos sus configuraciones e hiperparámetros, y entrenamos nuestro Swin tiny con una dimensión temporal de 8. También informamos la precisión en la vista de prueba 5×1.
Para SSv2, utilizamos el optimizador AdamW [21] para un entrenamiento más prolongado de 60 épocas y un calentamiento lineal de 2,5 épocas. El tamaño del lote, la tasa de aprendizaje y la disminución del peso son los mismos que los de Kinetics. Seguimos [9] con mejoras más potentes que incluyen suavizado de etiquetas, RandAugment [7] y borrado aleatorio [44]. También adoptamos una profundidad aleatoria con una proporción de 0,4 [19]. Como se hizo en [9], utilizamos el modelo previamente entrenado en Kinetics-400 como inicialización y utilizamos un tamaño de ventana de dimensión temporal de 16. A modo de inferencia, la puntuación final se calcula como la puntuación media de 1 × 3 vistas.
4.2 Comparación con tecnología de punta
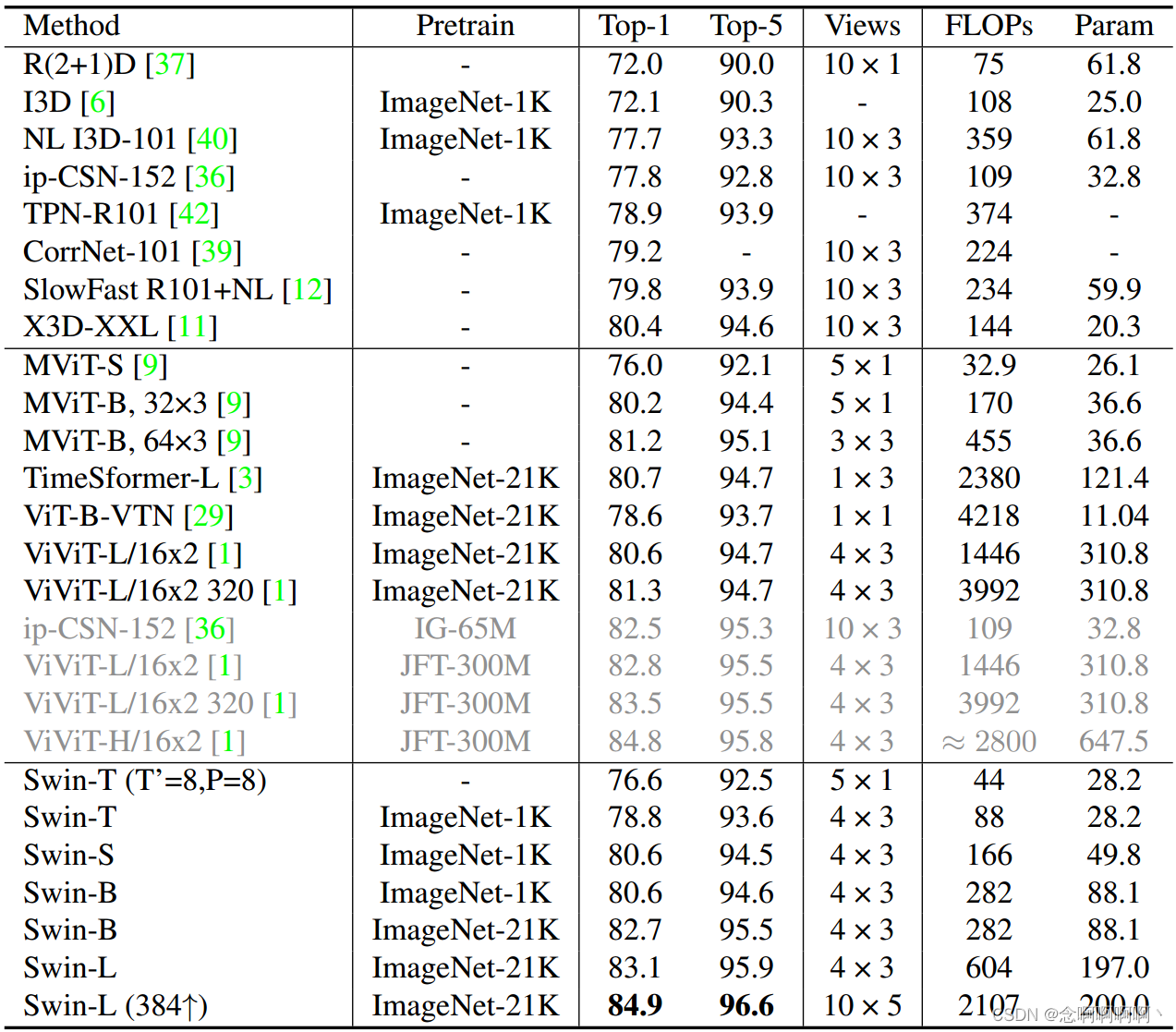
Cinética-400 . La Tabla 1 muestra la comparación con backbones de última generación, incluidos backbones convolucionales y basados en transformadores basados en Kinetics-400. En comparación con el Vision Transformer de última generación sin preentrenamiento a gran escala, Swin-S con preentrenamiento ImageNet-1K funciona ligeramente mejor que MViT-B (32×3) [9] entrenado desde cero con métodos similares. costo computacional . En comparación con el ConvNet X3DXXL [11] de última generación, Swin-S también lo supera en términos de costo computacional similar y menos vistas de inferencia. Para SwinB, el entrenamiento previo de ImageNet-21K genera una ganancia del 2,1 % con respecto al entrenamiento en ImageNet-1K desde cero. Con el entrenamiento previo de ImageNet21K, nuestro Swin-L (384 ↑) supera a ViViTL (320) en un 3,6 % en precisión de primer nivel con un costo computacional similar. Preentrenado en un conjunto de datos mucho más pequeño (ImageNet-21K) que ViViT-H (JFT-300M), nuestro Swin-L (384 ↑) logra un rendimiento de última generación del 84,9 % en K400.
Para una comparación justa con MViT [9], entrenamos nuestro SwinT desde cero sin cambiar los hiperparámetros. Nuestro método logra resultados competitivos en comparación con MViT [9], pero observamos que el entrenamiento desde cero requiere 200 épocas y se repite dos veces con refuerzos repetidos [15], lo cual es más costoso que nuestra configuración de ajuste fino: aproximadamente 13,3 veces el tiempo de entrenamiento.
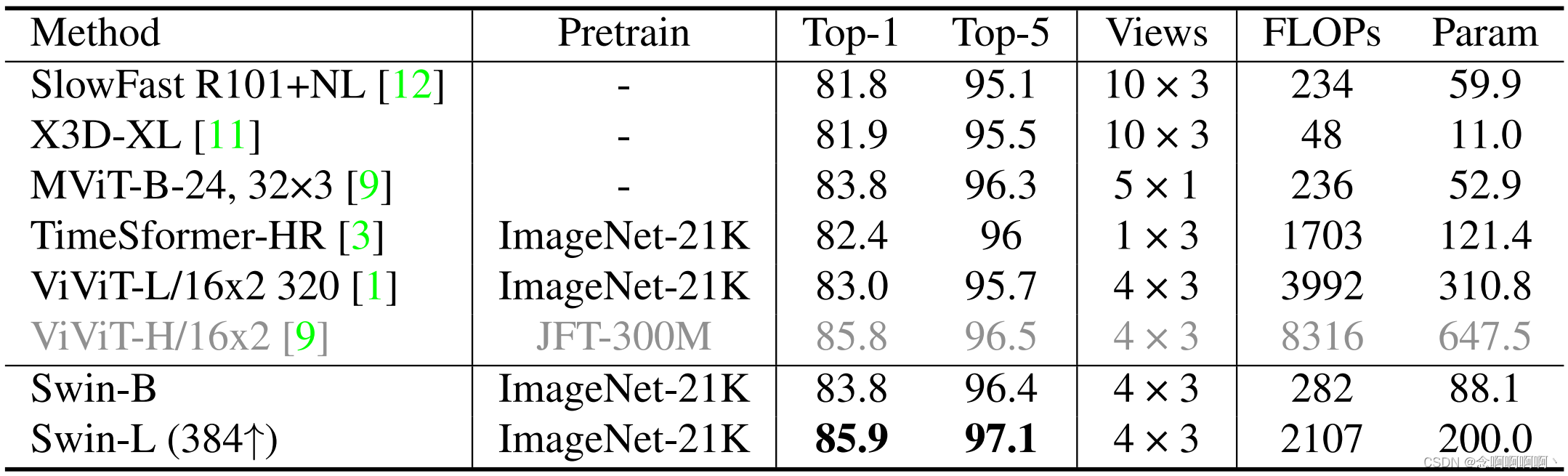
Cinética-600 . Los resultados para K600 se muestran en la Tabla 2. Las observaciones para K600 son similares a las de K400. En comparación con el preentrenamiento ImageNet-21K de última generación, nuestro Swin-L (384 ↑) supera a ViViT-L (320) en un 2,9 % en precisión de primer nivel con un costo computacional similar. Al realizar un entrenamiento previo en un conjunto de datos mucho más pequeño (ImageNet-21K) que ViViT-H (JFT-300M), nuestro Swin-L (384 ↑) logra una precisión de última generación del 85,9 % en K600 .
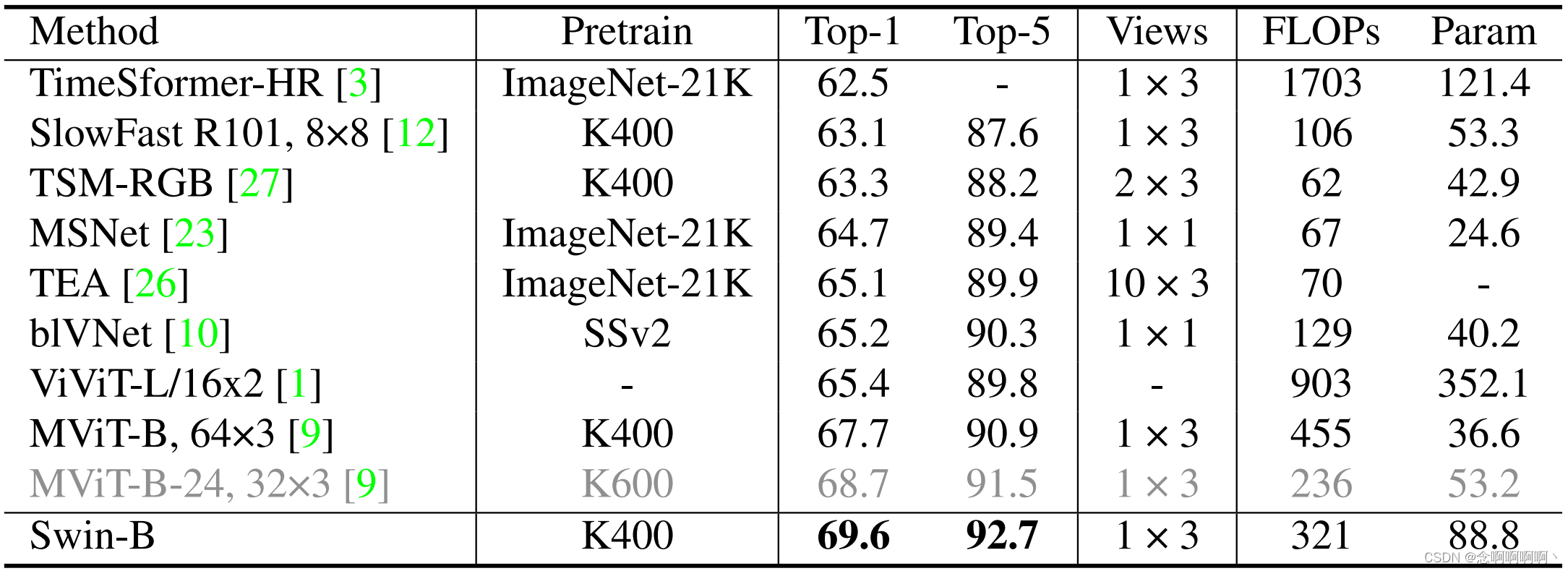
Algo-Algo v2 . La Tabla 3 compara nuestro método con métodos de última generación en SSv2. Seguimos MViT [9] y utilizamos el modelo previamente entrenado K400 como inicialización. Con un modelo previamente entrenado en K400, Swin-B logró una precisión superior del 69,6% , superando el mejor método anterior MViT-B-24 previamente entrenado en K600 en un 0,9%. Nuestro método se puede mejorar aún más mediante el uso de modelos más grandes (por ejemplo, Swin-L), mayor resolución de entrada (por ejemplo, 3842) y mejores modelos previamente entrenados (por ejemplo, K600) . Dejamos estos intentos como trabajo futuro.
4.3 Experimento de ablación
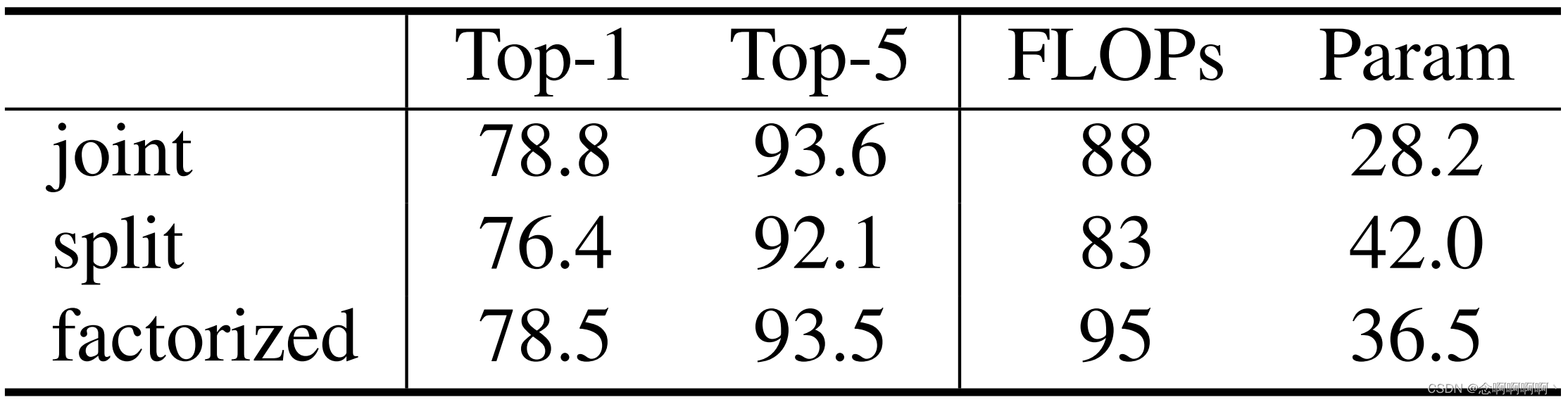
Diferentes diseños de atención espacial y temporal . Eliminamos los tres diseños principales de atención espaciotemporal: variantes conjuntas, divididas y factorizadas. La versión conjunta calcula conjuntamente la atención espaciotemporal en cada capa MSA basada en ventana 3D, que es nuestra configuración predeterminada. La versión dividida agrega dos capas de transformador temporal encima del Swin Transformer de solo espacio, que ha demostrado ser efectivo en ViViT [1] y VTN [29]. La versión descompuesta agrega una capa MSA de solo tiempo después de cada capa MSA de solo espacio en Swin Transformer, lo cual resultó ser eficiente en TimeSformer [3]. Para la versión descompuesta, para reducir los efectos nocivos de agregar capas inicializadas aleatoriamente a la red troncal con pesos previamente entrenados, agregamos un parámetro de ponderación inicializado a cero al final de cada capa MSA de solo tiempo.
Los resultados se muestran en la Tabla 4. Podemos observar que la versión conjunta logra el mejor equilibrio entre velocidad y precisión . Esto se debe principalmente a que la localidad en el dominio espacial reduce el cálculo de la versión conjunta manteniendo la efectividad. En comparación, la versión conjunta basada en ViT/DeiT es demasiado costosa desde el punto de vista computacional . La versión dividida no funciona bien en nuestro escenario . Aunque esta versión puede beneficiarse naturalmente de los modelos previamente entrenados, no es muy eficiente en términos de modelado temporal. La versión descompuesta produce una precisión superior relativamente alta, pero requiere más parámetros que la versión conjunta. Esto se debe a que la versión descompuesta tiene una capa de atención solo temporal después de cada capa de atención solo espacial, mientras que la versión conjunta realiza atención espacial y temporal en la misma capa de atención.
La dimensión temporal de los tokens 3D . Realizamos estudios de ablación sobre la dimensión temporal de los tokens 3D de manera global temporal, donde la dimensión temporal de los tokens 3D es igual al tamaño de la ventana de tiempo. Los resultados de Swin-T en K400 y SSv2 se muestran en la Tabla 5. En términos generales, cuanto mayor es la dimensión del tiempo, mayor es la precisión top1, pero el costo computacional es mayor y la velocidad de inferencia es más lenta. SSv2 se beneficia más del aumento de la dimensión temporal, que atribuimos a la mayor dependencia temporal en SSv2 .

Tamaño de la ventana de tiempo . Fijando la dimensión temporal de los marcadores 3D en 16, realizamos estudios de ablación en tamaños de ventana temporal de 8/4/16. Los resultados del uso de Swin-T en K400 se muestran en la Tabla 5. Observamos que Swin-T con un tamaño de ventana de tiempo de 8 da como resultado sólo una pequeña caída de rendimiento de 0,3 en comparación con un tamaño de ventana de tiempo de 16 (temporal global), pero una reducción relativa del 17% en el esfuerzo computacional (88 vs. 106). ). Entonces adoptamos esto como la configuración predeterminada del K400. Sin embargo, SSv2 a menudo requiere más tokens de tiempo y ventanas de tiempo (globales) más grandes , por lo que adoptamos 16 tokens de tiempo y una ventana global como configuración predeterminada para el conjunto de datos SSv2.
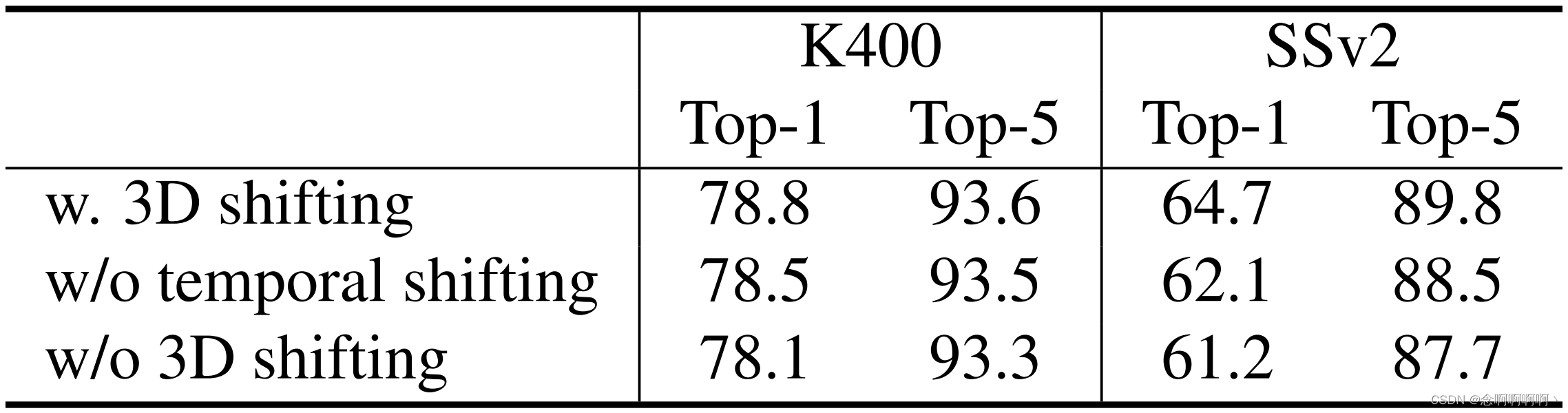
Ventanas móviles 3D . En la Tabla 6 se informa la ablación del método de ventana desplazada 3D en Swin-T para K400 y SSv2. La ventana de cambio 3D produce una precisión superior de +0,7%/+3,5%, y la ventana de cambio de tiempo produce +0,3%/+2,6% respectivamente en K400/SSv2. Los resultados demuestran la efectividad del esquema de ventana desplazada 3D para establecer conexiones entre ventanas que no se superponen .
Relación de tasa de aprendizaje de columna vertebral/cabeza . La Tabla 7 muestra un hallazgo interesante con respecto a la relación entre las tasas de aprendizaje de la columna vertebral y la cabeza. Al utilizar modelos previamente entrenados en ImageNet1K/ImageNet-21K, observamos que la arquitectura troncal tiene una tasa de aprendizaje más baja (por ejemplo, 0,1 ×) en relación con un cabezal inicializado aleatoriamente , lo que resulta en ganancias de precisión de primer nivel para el K400. Además, dado que los modelos previamente entrenados en ImageNet-21K son más potentes, puede beneficiarse más de esta técnica utilizando modelos previamente entrenados en ImageNet-21K . Por lo tanto, la red troncal olvida lentamente los parámetros y datos previamente entrenados cuando ajusta nuevas entradas de video, logrando así una mejor generalización . Esta observación señala el camino para futuras investigaciones sobre cómo utilizar mejor las pesas previamente entrenadas.

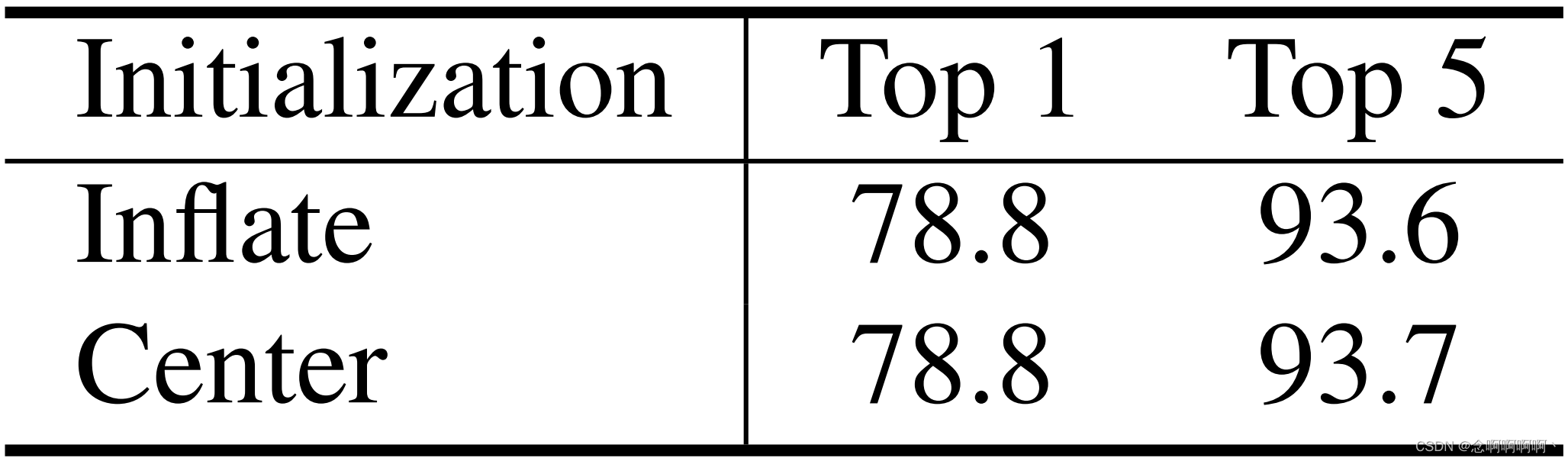
Inicialización de la capa de incrustación lineal y la matriz de desviación de posición relativa 3D . En ViViT [1], la inicialización central de las capas de incrustación lineal supera significativamente la inicialización de la dilatación. Esto nos impulsó a realizar estudios de ablación sobre estos dos métodos de inicialización de Video Swin Transformer. Como se muestra en la Tabla 8, descubrimos sorprendentemente que al utilizar el modelo 1 previamente entrenado de ImageNet-1K en K400, Swin-T con inicialización central logró el mismo rendimiento que Swin-T con inicialización de dilatación, logrando una precisión superior al 78,8%. En este artículo, utilizamos de forma predeterminada la inicialización de dilatación regular en capas de incrustación lineal .
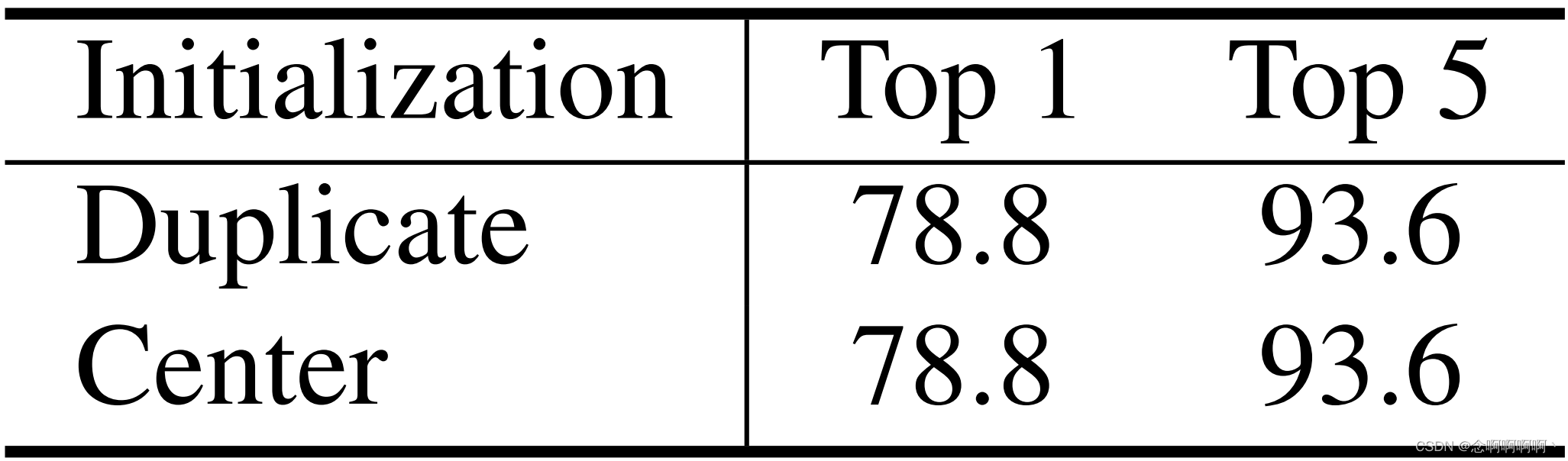
Para la matriz de desviación de posición relativa 3D, también tenemos dos opciones de inicialización diferentes, inicialización repetida o inicialización central. A diferencia del método de inicialización central de la capa de incrustación lineal, inicializamos la matriz de desviación de posición relativa 3D enmascarando la desviación de posición relativa entre diferentes fotogramas con un pequeño valor negativo (por ejemplo, -4,6), de modo que cada marcador solo se enfoque desde el principio. dentro del mismo marco. Como se muestra en la Tabla 9, encontramos que ambos métodos de inicialización lograron la misma precisión superior del 78,8% usando Swin-T en K400. De forma predeterminada, utilizamos la inicialización repetida de la matriz de desviación de posición relativa 3D .
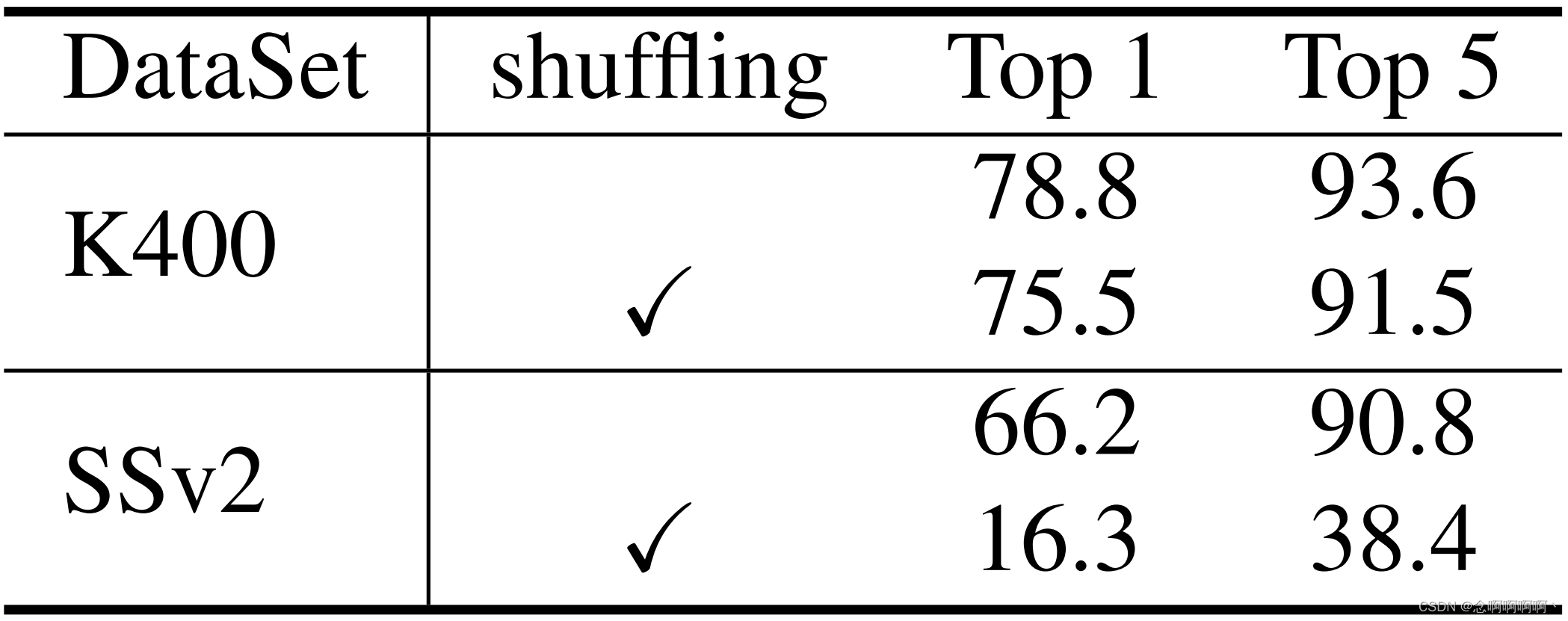
Inferencia de cuadros aleatorios . También evaluamos nuestro modelo de video transformando fotogramas aleatoriamente durante las pruebas [9] y descubrimos que el impacto en K400 y SSv2 fue significativamente diferente. Como se muestra en la Tabla 10, la transformación de fotogramas hace que la precisión del primer nivel disminuya en un 3,3 % en K400 y un 49,9 % en SSv2. La disminución significativa en SSv2 indica que el conjunto de datos SSv2 requiere más esfuerzo en el modelado temporal, y nuestro video Swin Transformer puede lograr una mejor compensación en el modelado de información espacial y temporal en diferentes conjuntos de datos .
5. Conclusión
Proponemos una arquitectura Transformer pura para el reconocimiento de video basada en un sesgo inductivo local espaciotemporal. Este modelo está adaptado de Swin Transformer para el reconocimiento de imágenes, por lo que puede aprovechar el poder de potentes modelos de imágenes previamente entrenados. El método propuesto logra un rendimiento de última generación en tres puntos de referencia ampliamente utilizados: Kinetics-400, Kinetics-600 y Something-Something v2. Esperamos que Video Swin Transformer sirva como base simple y confiable para futuras investigaciones.。
referencias
[1] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Luciˇc y Cordelia Schmid. Vivit: A video vi-sion transformador. arXiv preprint arXiv:2103.15691, 2021. 1, 2, 5, 6, 7, 8
[2] Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, Yu Wang, Jianfeng Gao, Songhao Piao, Ming Zhou y otros Unilmv2: Modelos de lenguaje pseudoenmascarados para el entrenamiento previo del modelo de lenguaje unificado. En Conferencia Internacional sobre Aprendizaje Automático, páginas 642 a 652. PMLR, 2020. 4
[3] Gedas Bertasius, Heng Wang y Lorenzo Torresani.¿Es la atención espacio-temporal todo lo que necesita para comprender el vídeo? arXiv preprint arXiv:2102.05095, 2021. 1, 2, 6, 7
[4] Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei y Han Hu. Gcnet: las redes no locales se encuentran con las redes de excitación y compresión y más allá. En Actas de los talleres de la Conferencia Internacional sobre Visión por Computador (ICCV) de IEEE/CVF, octubre de 2019. 2
[5] Joao Carreira y Andrew Zisserman. Quo vadis, ¿reconocimiento de la acción? un nuevo modelo y el conjunto de datos cinéticos. En actas de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 6299–6308, 2017. 2
[6] Joao Carreira y Andrew Zisserman. Quo vadis, ¿reconocimiento de la acción? un nuevo modelo y el conjunto de datos cinéticos. En actas de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 6299–6308, 2017. 6
[7] Ekin D Cubuk, Barret Zoph, Jonathon Shlens y Quoc V Le. Randaugment: Práctico aumento de datos automatizado con un espacio de búsqueda reducido. En Actas de la Conferencia IEEE/CVF sobre talleres de visión por computadora y reconocimiento de patrones, páginas 702–703, 2020. 5
[8] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer , Georg Heigold, Sylvain Gelly, Jakob Uszkoreit y Neil Houlsby. Una imagen vale 16x16 palabras: Transformadores para el reconocimiento de imágenes a escala. En Conferencia internacional sobre representaciones del aprendizaje, 2021. 1, 2
[9] Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik y Christoph Feichtenhofer. Transformadores de visión multiescala. arXiv:2104.11227, 2021. 2, 5, 6, 7, 8
[10] Quanfu Fan, Chun-Fu Chen, Hilde Kuehne, Marco Pistoia y David Cox. Más es menos: aprender representaciones de video eficientes mediante redes grandes y pequeñas y agregación temporal en profundidad. Preimpresión de arXiv arXiv:1912.00869, 2019. 7
[11] Christoph Feichtenhofer. X3d: Arquitecturas en expansión para un reconocimiento de video eficiente. En Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones, páginas 203–213, 2020. 2, 5, 6
[12] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik y Kaiming He. Redes lentas y rápidas para reconocimiento de vídeo. En Actas de la Conferencia Internacional IEEE/CVF sobre Visión por Computadora, páginas 6202–6211, 2019. 2, 6, 7
[13] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. La base de datos de vídeos “algo, algo” para el aprendizaje y la evaluación visual. sentido común. En Actas de la Conferencia Internacional IEEE sobre Visión por Computadora, páginas 5842–5850, 2017. 5
[14] Kaiming He, Xiangyu Zhang, Shaoqing Ren y Jian Sun. Aprendizaje residual profundo para el reconocimiento de imágenes. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 770–778, 2016. 1
[15] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler y Daniel Soudry. Aumente su lote: mejorando la generalización mediante la repetición de instancias. En Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones (CVPR), junio de 2020. 5
[16] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai y Yichen Wei. Redes de relación para la detección de objetos. En Actas de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 3588–3597, 2018. 4
[17] Han Hu, Zheng Zhang, Zhenda Xie y Stephen Lin. Redes de relaciones locales para el reconocimiento de imágenes. En Actas de la Conferencia Internacional IEEE/CVF sobre Visión por Computador (ICCV), páginas 3464–3473, octubre de 2019. 4
[18] Gao Huang, Zhuang Liu, Laurens Van Der Maaten y Kilian Q Weinberger. Redes convolucionales densamente conectadas. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 4700–4708, 2017. 1
[19] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra y Kilian Q Weinberger. Redes profundas con profundidad estocástica. En conferencia europea sobre visión por computadora, páginas 646–661. Springer, 2016. 5
[20] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev y otros El conjunto de datos de videos de acción humana cinética. Preimpresión de arXiv arXiv:1705.06950, 2017. 5
[21] Diederik P Kingma y Jimmy Ba. Adam: un método para la optimización estocástica. preimpresión de arXiv arXiv:1412.6980, 2014. 5
[22] Alex Krizhevsky, Ilya Sutskever y Geoffrey E Hinton. Clasificación de Imagenet con redes neuronales convolucionales profundas. En Avances en sistemas de procesamiento de información neuronal, páginas 1097–1105, 2012. 1
[23] Heeseung Kwon, Manjin Kim, Suha Kwak y Minsu Cho. Motionsqueeze: aprendizaje de funciones de movimiento neuronal para la comprensión de vídeos. En Conferencia europea sobre visión por computadora, páginas 345–362. Springer, 2020. 7
[24] Yann LeCun, Leon Bottou, Yoshua Bengio, Patrick Haffner, ´ et al Aprendizaje basado en gradientes aplicado al reconocimiento de documentos. Actas del IEEE, 86(11):2278–2324, 1998. 1
[25] Xinyu Li, Yanyi Zhang, Chunhui Liu, Bing Shuai, Yi Zhu, Biagio Brattoli, Hao Chen, Ivan Marsic y Joseph Tighe. Vidtr: Transformador de vídeo sin convoluciones. Preimpresión de arXiv arXiv:2104.11746, 2021. 2
[26] Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang y Limin Wang. Té: Excitación temporal y agregación para el reconocimiento de acciones. En Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones, páginas 909–918, 2020. 7
[27] Ji Lin, Chuang Gan y Song Han. Tsm: módulo de cambio temporal para una comprensión eficiente del video. En Actas de la Conferencia Internacional IEEE/CVF sobre Visión por Computadora, páginas 7083–7093, 2019. 7
[28] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin y Baining Guo. Transformador Swin: Transformador de visión jerárquica mediante ventanas desplazadas. Preimpresión de arXiv arXiv:2103.14030, 2021. 1, 2, 3, 4, 5
[29] Daniel Neimark, Omri Bar, Maya Zohar y Dotan Asselmann. Red de transformadores de vídeo. Preimpresión de arXiv arXiv:2102.00719, 2021. 2, 6, 7
[30] Zhaofan Qiu, Ting Yao y Tao Mei. Aprendizaje de la representación espaciotemporal con redes residuales pseudo-3D. En actas de la Conferencia Internacional IEEE sobre Visión por Computadora, páginas 5533–5541, 2017. 1, 2
[31] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li y Peter J. Liu. Explorando los límites del aprendizaje por transferencia con un transformador unificado de texto a texto. Journal of Machine Learning Research, 21(140):1–67, 2020. 4
[32] K. Simonyan y A. Zisserman. Redes convolucionales muy profundas para reconocimiento de imágenes a gran escala. En Conferencia Internacional sobre Representaciones del Aprendizaje, mayo de 2015. 1
[33] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke y Andrew Rabinovich. Profundizando con las convoluciones. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 1 a 9, 2015. 1
[34] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles y Herve J ´ egou. Capacitación en transformadores de imágenes eficientes en datos y destilación a través de la atención. Preimpresión de arXiv arXiv:2012.12877, 2020. 1, 2
[35] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani y Manohar Paluri. Aprendizaje de características espaciotemporales con redes convolucionales 3D. En Actas de la conferencia internacional IEEE sobre visión por computadora, páginas 4489–4497, 2015. 1, 2
[36] Du Tran, Heng Wang, Lorenzo Torresani y Matt Feiszli. Clasificación de vídeos con redes convolucionales separadas por canales. En Actas de la Conferencia Internacional IEEE/CVF sobre Visión por Computadora, páginas 5552–5561, 2019. 6
[37] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun y Manohar Paluri. Una mirada más cercana a las convoluciones espaciotemporales para el reconocimiento de acciones. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 6450–6459, 2018. 2, 6
[38] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser e Illia Polosukhin. Atención es todo lo que necesitas. En Avances en sistemas de procesamiento de información neuronal, páginas 5998–6008, 2017.1
[39] Heng Wang, Du Tran, Lorenzo Torresani y Matt Feiszli. Modelado de vídeo con redes de correlación. En Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones, páginas 352–361, 2020. 6
[40] Xiaolong Wang, Ross Girshick, Abhinav Gupta y Kaiming He. Redes neuronales no locales. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 7794–7803, 2018. 2, 6
[41] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu y Kevin Murphy. Repensar el aprendizaje de características espaciotemporales: compensaciones entre velocidad y precisión en la clasificación de videos. En Actas de la Conferencia Europea sobre Visión por Computador (ECCV), páginas 305–321, 2018. 1, 2
[42] Ceyuan Yang, Yinghao Xu, Jianping Shi, Bo Dai y Bolei Zhou. Red piramidal temporal para el reconocimiento de acciones. En Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones, páginas 591–600, 2020. 6
[ 43] Minghao Yin, Zhuliang Yao, Yue Cao, Xiu Li, Zheng Zhang, Stephen Lin y Han Hu. Redes neuronales no locales desenredadas. En Actas de la conferencia europea sobre visión por computadora (ECCV), 2020. 2 [44
] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li y Yi Yang, aumento de datos por borrado aleatorio, en Actas de la Conferencia AAAI sobre Inteligencia Artificial, volumen 34, páginas 13001–13008, 2020. 5