Notas de estudio de Swin-Transformer (adecuadas para Xiaobai)
Recientemente, estoy aprendiendo conocimientos relevantes sobre el aprendizaje profundo y el aprendizaje automático. Aquí registraré el modelo aprendido y algunas ideas personales. El artículo incluye la explicación del modelo y el código fuente del proyecto. Debido a mi propio dominio, generalmente tiendo a hablar en lengua vernácula, lo cual es adecuado para principiantes. Por favor corríjanme si cometo algún error.

1. Código fuente del proyecto y referencias principales.
Explicación del blog: https://blog.csdn.net/qq_37541097/article/details/121119988
Explicación de la estación B: dirección del enlace
Dirección del código fuente: dirección del enlace
Versiones relevantes de los archivos de la biblioteca principal:
torch 1.10.1+cu102
torchaudio 0.10.1+cu102
torchvision 0.11.2
tensorflow 2.4.1
numpy 1.23.4
(Baidu puede resolver directamente las advertencias o errores específicos causados por problemas con la versión de la biblioteca)
Descarga de datos: https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz (puede copiar directamente el enlace para descargar Thunder)
2. Introducción a Swin-Transformer
Swin Transformer es un artículo publicado por Microsoft Research sobre ICCV en 2021 y ganó el título honorífico de mejor artículo de ICCV 2021. Se puede utilizar como columna vertebral de uso general para la visión por computadora y ha alcanzado el nivel de Sota en muchas tareas visuales de bajo nivel.

La imagen de arriba es una mejora realizada por Swin Transformer basada en el papel Vit. Al igual que yo, muchas personas pueden sentirse confundidas al ver esta imagen después de leer Vit. Antes de leer el artículo, permítanme presentarles brevemente algunas "unidades" del modelo.
Píxel: la unidad más pequeña de una imagen
Parche: un área cuadrada compuesta por varios píxeles adyacentes
Ventana: un área cuadrada compuesta por varios parches adyacentes
Ejemplo: En la versión ligera del Swin Transformer Tiny hay:
1 Parche = 4x4 Píxeles
1 Ventana = 7x7 Pacto
Por lo tanto, 4x en la figura anterior (a) puede entenderse simplemente como tomar 4 ventanas en total para operar; de manera similar, 8x puede entenderse como tomar 8 ventanas en total para operar (autoatención de cabezales múltiples W-MSA) etc······
Por lo tanto, en comparación con el modelo Vit anterior, nuestro modelo Swin Transformer toma menos ventanas a la vez, reduce la dimensión de las operaciones matriciales y, por lo tanto, reduce la cantidad de cálculo. Sin embargo, también tiene algunas deficiencias, que explicaremos a continuación. mencionado.
3. La composición del modelo.
El modelo Swin Transformer se muestra en la siguiente figura. En circunstancias normales, la siguiente estructura se usa como red backbones (red troncal). En pocas palabras, estas estructuras se pueden usar para extraer características y luego agregar una capa completamente conectada a completarlo según nuestras necesidades tareas de regresión o clasificación.

3.1 Partición de parches
Primero, la imagen se ingresa en el módulo de partición de parches para el bloque, es decir, cada 4x4 píxeles adyacentes son un parche, y luego se aplana en la dirección del canal. Suponiendo que la entrada es una imagen RGB de tres canales, entonces cada parche tiene 4x4 = 16 píxeles, y cada píxel tiene tres valores de R, G y B, por lo que es 16x3 = 48 después del aplanamiento, por lo que la forma de la imagen después de pasar la partición de parche de [H, W, 3] a [H/4, W/4, 48]. (Del blogger: Frijol mungo de girasol )
Esta parte puede entenderse simplemente como dividir y aplanar , dividir 4 * 4 píxeles en un parche y los píxeles de cada parche no se repiten, por lo que el número de parches en la dirección horizontal de la imagen es W/4 , y el número de parches en la dirección vertical es H/ 4 ( operaremos en unidades de parche más adelante).
Cada parche tiene 4x4=16 píxeles y hay 3 canales para imágenes RGB, por lo que el número de funciones de cada parche es 4x4x3=48.
3.2 Incrustación lineal
Esta parte consiste en pasar directamente a través de una capa de convolución para cambiar la imagen (H/4)x(W/4)x48 a (H/4)x(W/4)xC, que es una operación de "mapeo " . Las dimensiones de se asignan a la dimensión C que queremos, y la C en el medio del código es 96.
3.3 Bloque transformador giratorio
De hecho, esta parte son las dos operaciones en la figura siguiente, por lo que podemos encontrar que el bloque transformador Swin es siempre un múltiplo entero de 2, porque cada bloque tiene dos partes. El módulo Swin Transformer Block no cambia el tamaño relativo de la imagen.

Capa normal (LN)
LayerNorm es un método de normalización . La siguiente es la descripción oficial en el documento de Pytorch. Si está interesado, puede consultar este blog https://blog.csdn.net/weixin_41978699/article/details/122778085

Autoataque de cabezales múltiples de Windows (W-MSA)
La función del módulo de autoatención de múltiples cabezales de ventana, según mi entendimiento personal, es extraer la conexión entre ventanas . Por ejemplo, para la cabeza de un gato, los ojos deben estar por encima de la nariz y la boca debe estar por debajo de la nariz. Es una especie de característica del espacio, y la operación de autoatención es extraer esta característica.

Una cosa a tener en cuenta aquí es que la operación de autoatención entre ventanas es para varias ventanas adyacentes. Por ejemplo, la autoatención se puede realizar entre las ventanas numeradas 1, 2, 3 y 4 en la figura anterior, pero 1, 2 no realizar operaciones de autoatención con 9, 10.
En la segunda parte, se presenta Swin-Transformer . Hemos explicado que, en comparación con Vit, el número de ventanas de autoatención que toma Swin Transformer se reduce, por lo que la cantidad de cálculo se reduce considerablemente. Pero al mismo tiempo, también perdemos las características espaciales de algunas áreas, como la parte compuesta por las ventanas 4, 5, 6 y 7, por lo que el artículo propone un método llamado ventana deslizante .
Autoatacante de cabezales múltiples de Windows (SW-MSA)
El principio de la ventana deslizante es similar a cortar una imagen con un molde: movemos el molde dos centímetros hacia la derecha y dos centímetros hacia abajo, y luego cortamos la imagen, de modo que se puedan obtener las características de diferentes regiones espaciales de la imagen. , pero esto lleva a una pregunta, es mejor para nosotros prestar atención propia en cuadrados generales, por lo que el autor del artículo realizó una codificación de A, B y C, y luego reorganizó el cuadrado (la parte de desplazamiento cíclico a continuación ).
Además, considerando que los "cuadrados" codificados pueden no ser ventanas conectadas entre sí y no pueden usarse para la autoatención, para el trabajo de tesis se realizó una operación enmascarada, que puede entenderse como cubrir con un trozo de tela que No debe usarse para la autoatención , esa parte de los resultados . De esta manera, podemos extraer características de múltiples escalas en el espacio y al mismo tiempo garantizar que se reduzca la cantidad de cálculo.
Si quieres saber más sobre input, puedes consultar este vídeo explicativo en la estación B: Lectura intensiva de artículos de Swin Transformer

MLP
Esta parte es una capa completamente conectada que utiliza la función de activación GELU + Abandono.
3.4 Fusión de parches
Esta parte del jefe ya la ha explicado muy bien, así que la pegaré directamente.
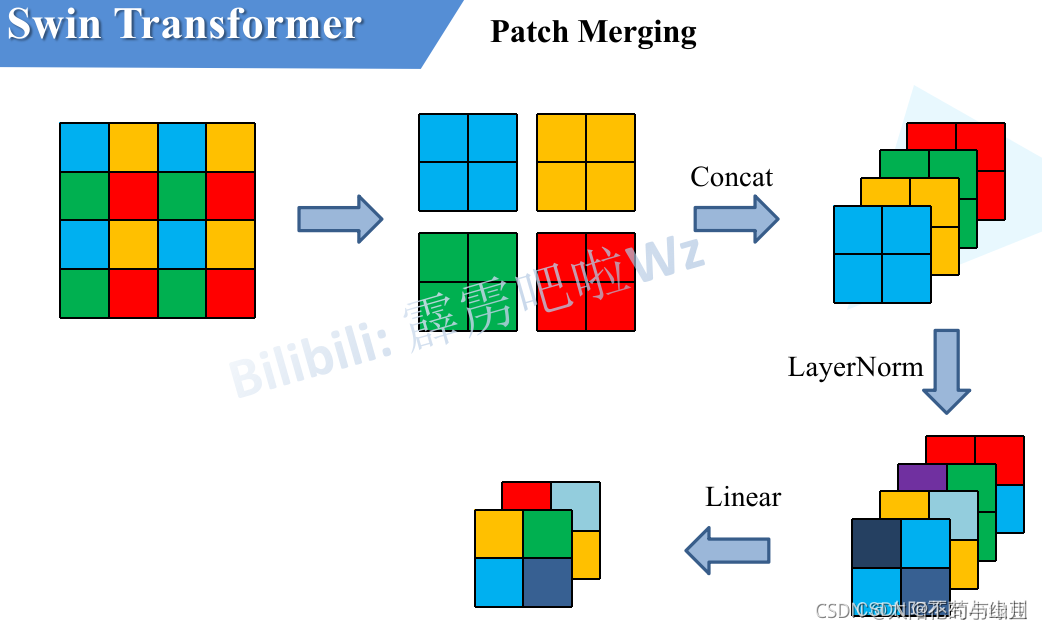
Como se mencionó anteriormente, en cada etapa, la reducción de resolución debe realizarse primero a través de una capa de fusión de parches (excepto la etapa 1). Como se muestra en la figura siguiente, suponiendo que la entrada a Patch Merging es un mapa de características de un solo canal de 4x4 (mapa de características), Patch Merging dividirá cada 2x2 píxeles adyacentes en un parche y luego dividirá la misma posición en cada parche (el mismo color) los píxeles se juntan para obtener 4 mapas de características. Luego concatene los cuatro mapas de características en la dirección de profundidad y luego pase una capa LayerNorm. Finalmente, se utiliza una capa completamente conectada para realizar un cambio lineal en la dirección de profundidad del mapa de características, y la profundidad del mapa de características se cambia de C a C/2. Se puede ver en este ejemplo simple que después de pasar la capa Patch Merging, la altura y el ancho del mapa de características se reducirán a la mitad y la profundidad se duplicará.
4. Uso del código fuente
Dirección del código: dirección del conjunto de datos de github
: https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz

En pocas palabras, después de descargar el código fuente del conjunto de datos, ingrese el archivo train.py, establezca la ruta del conjunto de datos y el número de clases de clasificación de imágenes, y luego ejecute el programa directamente. propio conjunto de datos, puede utilizar el conjunto de datos de la siguiente manera La ubicación del modelo del diagrama.

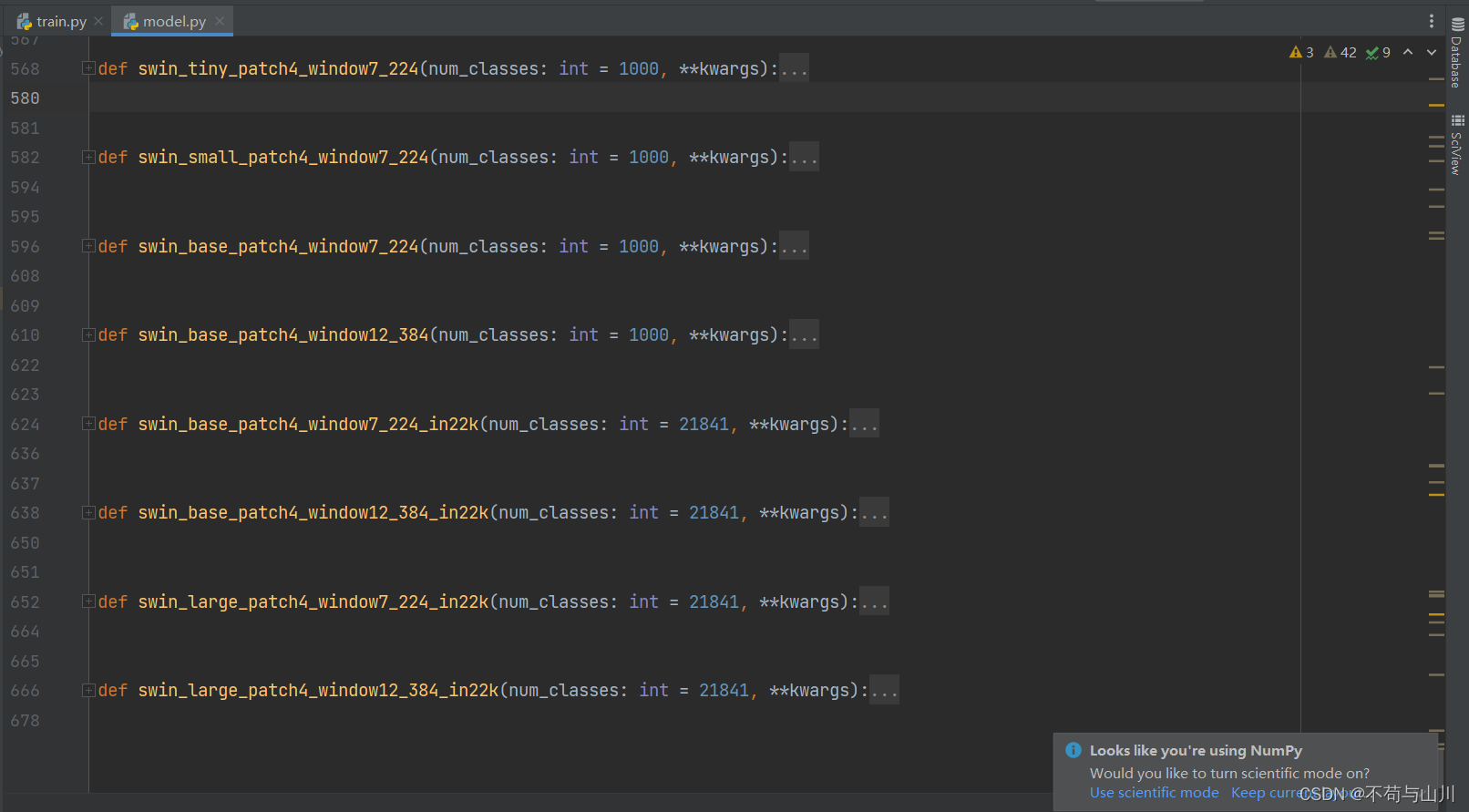
Si cree que el rendimiento de Swin Transformer Tiny no es suficiente, también puede elegir otras versiones como se muestra a continuación, simplemente modifique esta cadena de códigos delante de train.py.
from model import swin_tiny_patch4_window7_224 as create_model
Esta es la primera vez que escribo un artículo tan largo. Mi nivel es limitado y algunos lugares no son lo suficientemente rigurosos. ¡Espero que todos puedan elogiarme un poco!