Índice de contenidos de los artículos de la serie.
Capítulo 2: K Vecinos más cercanos (Clasificación)
Dirección del código relacionado: https://github.com/wzybmw888/MachineLearning.git
Directorio de artículos
- Índice de contenidos de los artículos de la serie.
- 1. Algoritmo del vecino más cercano
- 2. Defectos del algoritmo del vecino más cercano (1)
- Desventajas del algoritmo del vecino más cercano (2)
- Nueva pregunta: Cálculo de la cantidad de fuerza bruta
- Resumir
- Introducción a los datos de Iris
- Referencias
1. Algoritmo del vecino más cercano
Para determinar la categoría de la muestra desconocida, todas las muestras de entrenamiento se utilizan como puntos representativos, se calcula la distancia entre la muestra desconocida y todas las muestras de entrenamiento y la categoría del vecino más cercano se utiliza como única base para determinar la categoría. de la muestra desconocida.
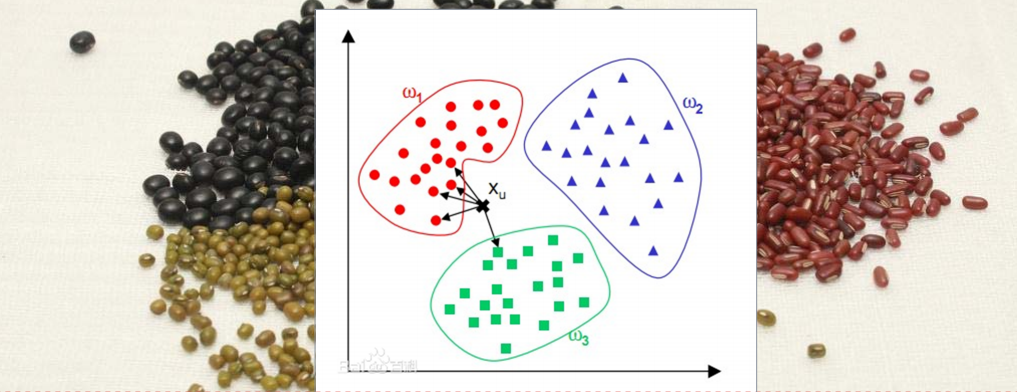
Entonces, ¿cómo calcular la distancia entre una muestra de ubicación y todas las muestras de entrenamiento? Sklearn proporciona el siguiente método de clase para calcular la distancia:
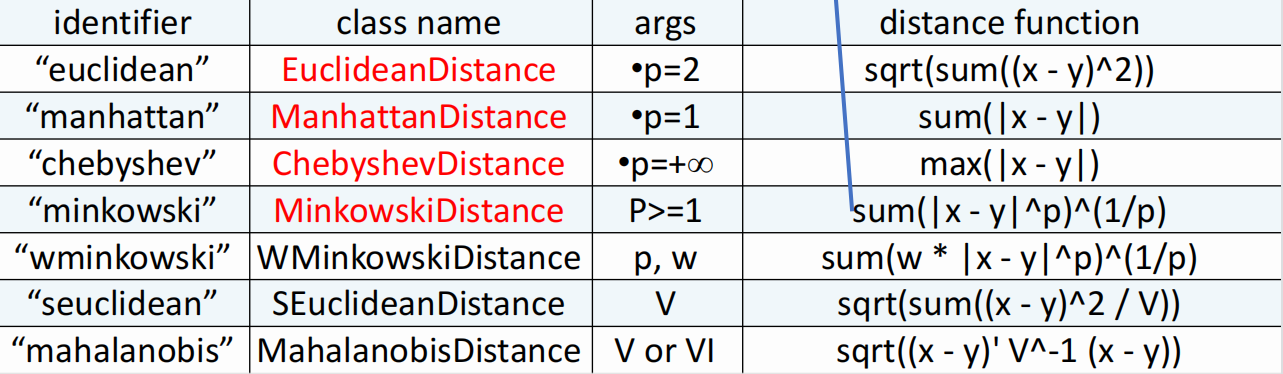
donde la fórmula "minkowski" es la siguiente:
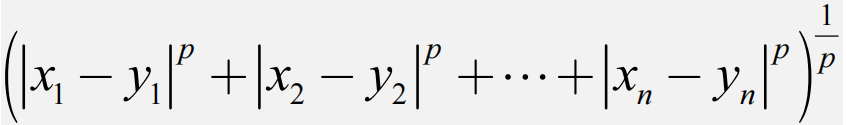
# 欧几里得距离(Euclidean Distance):
from sklearn.metrics import pairwise_distances
X = [[0, 1], [1, 1]]
Y = [[1, 2], [2, 2]]
distances = pairwise_distances(X, Y, metric='euclidean')
print(distances)
# 曼哈顿距离(Manhattan Distance):
distances = pairwise_distances(X, Y, metric='manhattan')
print(distances)
# 切比雪夫距离(Chebyshev Distance):
distances = pairwise_distances(X, Y, metric='chebyshev')
print(distances)
# 余弦相似度(Cosine Similarity):
distances = pairwise_distances(X, Y, metric='cosine')
print(distances)
2. Defectos del algoritmo del vecino más cercano (1)
El algoritmo del vecino más cercano es muy sensible a datos ruidosos y valores atípicos. Dado que el algoritmo del vecino más cercano se basa en la medición de distancias, si hay datos ruidosos o valores atípicos en los datos de la muestra, el algoritmo del vecino más cercano puede confundirlos con datos válidos, afectando así la precisión de los resultados de la predicción.
Estrategia 1: K-vecinos más cercanos (KNN)
1) Calcular la distancia entre los datos de prueba y cada dato de entrenamiento;
2) Ordenar según la relación creciente de distancia;
3) Seleccionar los k puntos con la distancia más pequeña;
4) Determinar la frecuencia de aparición de la categoría de los primeros k puntos;
5) Retorno La categoría con la frecuencia más alta entre los primeros k puntos se utiliza como clasificación prevista de los datos de prueba.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 定义K近邻算法模型
knn = KNeighborsClassifier(n_neighbors=3,metric='minkowski',p=2)
# 训练模型
knn.fit(X_train, y_train)
# 进行预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
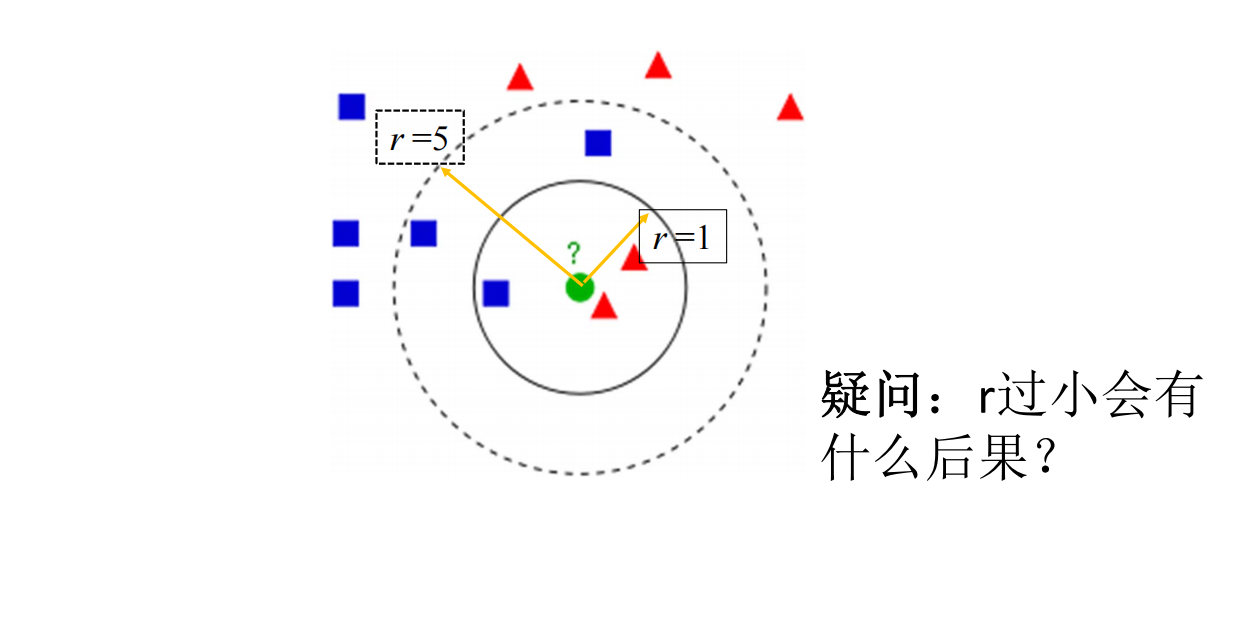
Estrategia 2: limitar el radio del vecino más cercano
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import RadiusNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 定义限定半径最近邻算法模型
rnn = RadiusNeighborsClassifier(radius=1,metric='minkowski',p=2)
# 训练模型
rnn.fit(X_train, y_train)
# 进行预测
y_pred = rnn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
El valor del radio se establece demasiado pequeño: si el valor del radio es demasiado pequeño, es posible que no se encuentre una cantidad suficiente de muestras vecinas. Puede intentar aumentar el valor del radio para ampliar el rango de muestras vecinas. El compilador informa un error. Puede intentar utilizar un radio mayor, asignar una etiqueta a los valores atípicos o considerar eliminarlos de su conjunto de datos.
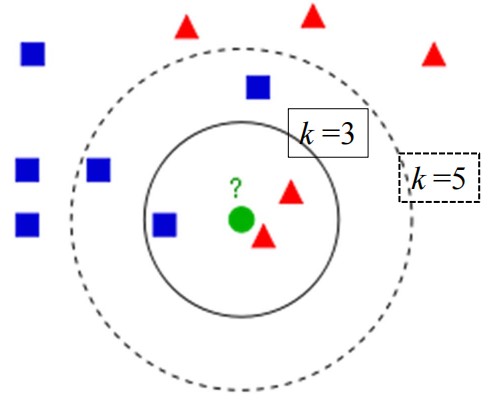
La influencia de K (o r)
Elegir un valor k más pequeño equivale a usar instancias de entrenamiento en un campo más pequeño para hacer predicciones. El error de entrenamiento se reducirá. Solo las instancias de entrenamiento que sean cercanas o similares a la instancia de entrada tendrán un efecto en el resultado de la predicción. Al mismo tiempo Con el tiempo, el problema es que el error de generalización aumentará.En otras palabras, la reducción del valor k significa que el modelo general se vuelve complejo y es probable que se produzca un sobreajuste;
Elegir un valor k mayor equivale a utilizar ejemplos de entrenamiento en un campo más grande para la predicción. La ventaja es que puede reducir el error de generalización, pero la desventaja es que el error de entrenamiento aumentará. En este momento, las instancias de entrenamiento que están lejos de la instancia de entrada (no similares) también afectarán la predicción, provocando errores de predicción, y el aumento en el valor k significa que el modelo general se vuelve más simple. Un extremo es que k es igual al número de muestras m, y no hay ninguna clasificación. En este momento, no importa cuál sea la instancia de entrada, simplemente se predice que pertenece a la clase con más instancias de entrenamiento. y el modelo es demasiado simple.
Desventajas del algoritmo del vecino más cercano (2)
Cuando las muestras están desequilibradas, es decir, cuando la capacidad de muestra de una clase es grande y el número de muestras de otras clases es pequeño, es muy probable que cuando se ingresa una muestra desconocida, las muestras de la gran cantidad de clases entre los k vecinos de la muestra representarán la mayoría. Sin embargo, este tipo de muestra no está cerca de la muestra objetivo, mientras que un pequeño número de dichas muestras está muy cerca de la muestra objetivo.
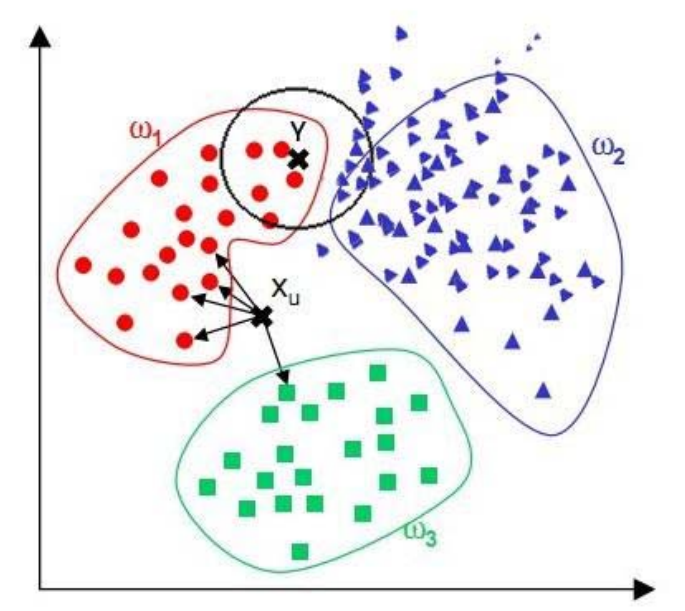
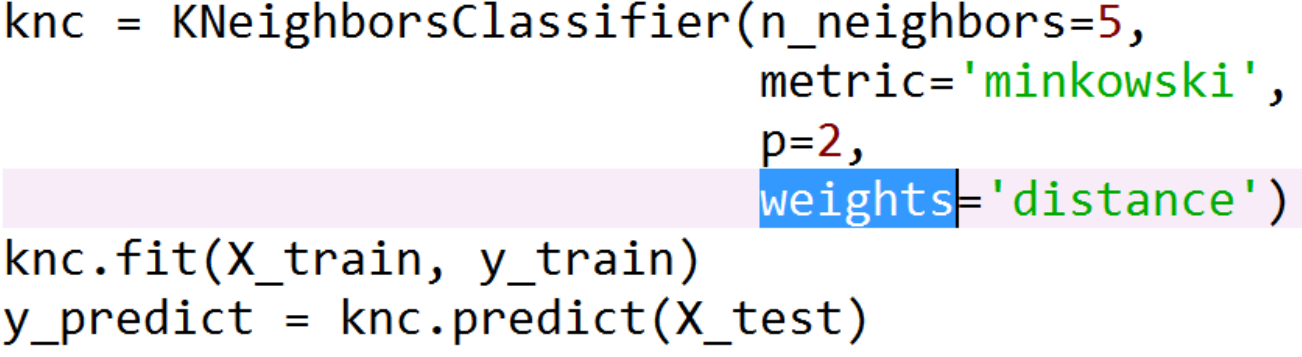
Solución: ponderación
Ideas de mejora: los vecinos con una distancia pequeña de la muestra tienen un peso grande y los vecinos con una distancia grande de la muestra tienen un peso relativamente pequeño.
Nueva pregunta: Cálculo de la cantidad de fuerza bruta
Brute Force KNN se refiere a un algoritmo de búsqueda de vecino más cercano basado en recorrido. En este algoritmo, para cada muestra de prueba, es necesario recorrer todo el conjunto de datos de entrenamiento, calcular la distancia entre este y cada muestra de entrenamiento y seleccionar las k muestras de entrenamiento más cercanas como muestras vecinas. La complejidad temporal de este algoritmo es O (nd), donde n es el número de muestras de entrenamiento y d es la dimensión de la característica.
La implementación más simple del método del vecino k-más cercano es el escaneo lineal (búsqueda exhaustiva), que calcula la distancia entre la instancia de entrada y cada instancia de entrenamiento. Después del cálculo y el almacenamiento, busque k vecinos más cercanos. Cuando el conjunto de entrenamiento
es grande, el cálculo lleva mucho tiempo.

Solución: estructura de datos árbol kd y árbol bola
El árbol KD (árbol K-dimensional) y el árbol Ball (árbol de bolas) son estructuras de datos que se utilizan para la búsqueda del vecino más cercano y se pueden utilizar para optimizar la eficiencia del algoritmo del vecino más cercano K.
El árbol KD es una estructura de árbol binario que divide recursivamente el conjunto de datos en múltiples subespacios según la distribución de las características del conjunto de datos para construir una estructura de árbol. Durante la búsqueda del vecino más cercano, podemos recorrer recursivamente la estructura del árbol hacia abajo de acuerdo con la posición del punto de consulta, encontrar el nodo hoja más cercano al punto de consulta y luego retroceder hasta el nodo principal para verificar si otros nodos secundarios tienen vecinos más cercanos. Dado que la estructura de árbol KD puede excluir rápidamente áreas de búsqueda innecesarias, la eficiencia de la búsqueda del vecino más cercano se puede mejorar significativamente.
knn = KNeighborsClassifier(n_neighbors=5, algorithm='kd_tree')
El árbol de bolas es una estructura de árbol que divide el espacio de datos en áreas esféricas con el punto del conjunto de datos como centro. La estructura de árbol de Ball divide recursivamente el conjunto de datos para construir una estructura de árbol. Durante la búsqueda del vecino más cercano, podemos comenzar desde el nodo raíz, recorrer recursivamente hacia abajo la estructura del árbol, encontrar el área esférica más pequeña que contiene el punto de consulta y luego verificar si hay un área esférica más pequeña que contiene el punto vecino. La estructura de árbol Ball puede eliminar rápidamente áreas de búsqueda innecesarias, mejorando así la eficiencia de la búsqueda del vecino más cercano.
knn = KNeighborsClassifier(n_neighbors=5, algorithm='ball_tree')
árbol de bolas vs árbol kd vs fuerza bruta
•Número de muestra N y dimensión K.
•El tiempo de consulta por fuerza bruta crece en O[KN];
•El tiempo de consulta del árbol de bolas crece aproximadamente en O[Klog(N)];
•La relación entre el tiempo de consulta del árbol KD y K es difícil de determinar. descripción precisa. Para K pequeña (menos de 20),
la complejidad de la consulta es aproximadamente O [log (N)]. Para K mayor, la complejidad se aproxima a O[KN]
Autor: Kobe está vagando
Enlace: https://www.zhihu.com/question/30957691/answer/338362344
Fuente: Zhihu
Los derechos de autor pertenecen al autor. Para reimpresiones comerciales, comuníquese con el autor para obtener autorización. Para reimpresiones no comerciales, indique la fuente.
Desde la perspectiva de la escala del volumen de datos, cuando el volumen de datos es inferior a 5000, aunque el tiempo de búsqueda del árbol kd y del árbol de bolas es menos complejo que el tiempo de búsqueda por fuerza bruta, la computadora dedica más tiempo a construir estructuras de datos relacionadas. es pequeño, el uso de la búsqueda de fuerza bruta ahorrará tiempo, pero cuando la cantidad de datos es muy grande, el uso del árbol kd y el árbol de bolas ahorrará más tiempo.
Desde la perspectiva de la dimensión de datos, cuando la dimensión de datos es baja, la complejidad temporal de kdtree y balltree no es muy diferente, y cuando la dimensión de datos es alta, la complejidad temporal de balltree es menor.
第一章:K近邻(分类)/练习/KNN速度比较.py
Resumir

ventaja
• La teoría es madura, la idea es simple y puede usarse tanto para clasificación como para regresión;
• Puede usarse para clasificación no lineal;
• En comparación con algoritmos como Naive Bayes, no tiene suposiciones sobre los datos y tiene alta precisión. y puede manejar anomalías Insensibilidad al punto;
• Dado que el método KNN se basa principalmente en las muestras circundantes limitadas, en lugar del método de discriminar el dominio de clase, para determinar la categoría a la que pertenece, para que el conjunto de muestras se divida con un gran número de intersecciones o superposiciones en el dominio de clase, el método KNN Más adecuado que otros métodos;
• Este algoritmo es más adecuado para la clasificación automática de categorías con tamaños de muestra relativamente grandes, mientras que es más probable que se produzca una clasificación errónea con este algoritmo para categorías con muestras más pequeñas tamaños.
defecto
• La cantidad de cálculo es grande, especialmente cuando el número de características es muy grande;
• Cuando la muestra está desequilibrada, la precisión de la predicción para categorías raras es baja; (ponderado + radio limitado)
• El establecimiento de modelos como árboles kd y Los árboles de bolas requieren una gran cantidad de tiempo Memoria
• Utilizando un método de aprendizaje diferido, básicamente no hay aprendizaje, lo que resulta en una predicción más lenta que algoritmos como la regresión logística.
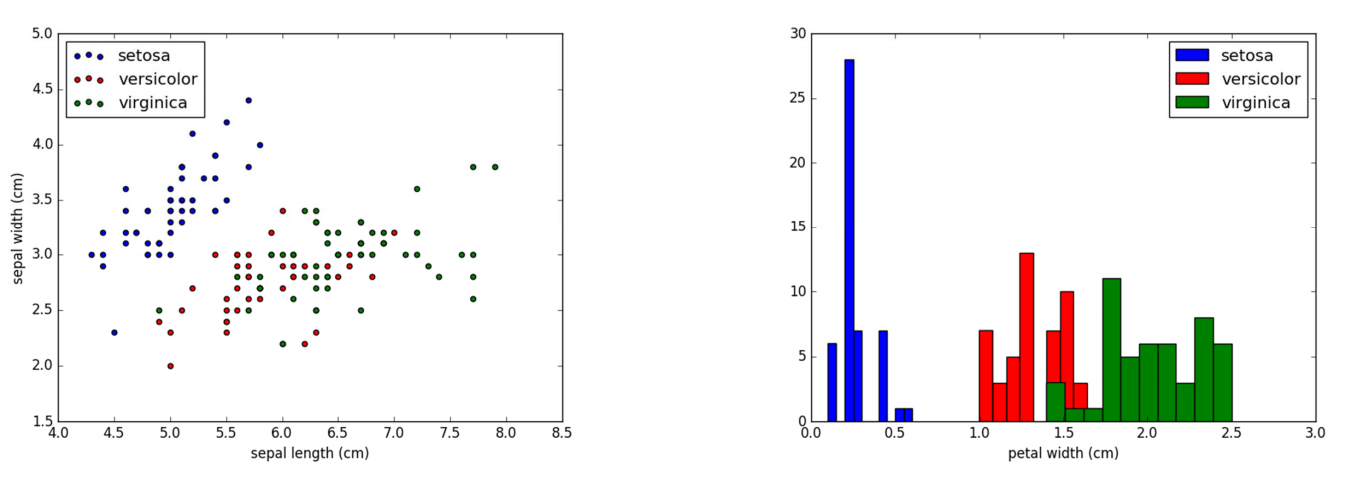
Introducción a los datos de Iris
Este conjunto de datos contiene 4 atributos:
Sepal.Length (largo del sépalo), Sepal.Width (ancho del sépalo)
Petal.Length (largo del pétalo), Petal.Width (ancho del pétalo), la unidad es cm;

Una de las categorías es linealmente separable de las otras dos categorías, y las dos últimas categorías son no linealmente separables.
Referencias
https://blog.csdn.net/pipisorry/article/details/53156836
https://www.cnblogs.com/21207‐iHome/p/6084670.html
tps://zhuanlan.zhihu.com/p/23083686
http ://blog.sina.com.cn/s/blog_6f611c300101c5u2.html
http://scikit‐learn.org/stable/modules/generated/sklearn.neighbors.DistanceMetric.html
https://www.cnblogs.com/pinard /p/6065607.html