Nivel 1: descripción general del algoritmo knn
detalles de la misión
La tarea de este nivel: usar pythonel método de implementación para encontrar las kmuestras más cercanas a la muestra objetivo.
información relacionada
Para completar la tarea de este nivel, debe dominar: 1. knnPensamiento algorítmico, 2. Medición de distancia.
idea del algoritmo knn
k-El vecino más cercano (k-nearest neighbor ,knn)es un método de clasificación y regresión. Solo discutimos aquí para la clasificación knn. El llamado kvecino más cercano ksignifica el vecino más cercano, lo que significa que cada muestra puede ser krepresentada por sus vecinos más cercanos.
knnkLa idea central del algoritmo es que si la mayoría de las muestras adyacentes más cercanas de una muestra en el espacio de características pertenecen a una determinada categoría, entonces la muestra también pertenece a esta categoría y tiene las características de las muestras de esta categoría. Al determinar la decisión de clasificación, este método solo determina la categoría de la muestra que se dividirá de acuerdo con la categoría de una o varias muestras más cercanas. knnEl método solo está relacionado con un número muy pequeño de muestras adyacentes al tomar decisiones de clase.
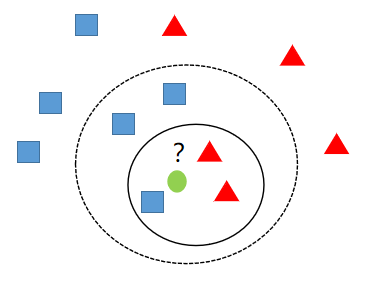
Como se muestra en la figura anterior, entre las tres muestras más cercanas al círculo verde k=3en ese momento , había dos triángulos rojos y un cuadrado azul, entonces el círculo verde debe clasificarse como un triángulo rojo en este momento. En k=5ese momento , entre las cinco muestras más cercanas al círculo verde, había dos triángulos rojos y tres cuadrados azules, por lo que el círculo verde debe clasificarse en la categoría de cuadrados azules.
medida de distancia
Ya sabemos que cómo juzgar a qué tipo pertenece una muestra es principalmente ver qué tipo tiene el número más grande entre las muestras más cercanas, luego la muestra pertenece al tipo con el número más grande. Aquí surge una pregunta: ¿qué es reciente?
Con respecto a lo que es más cercano, todos deberían pensar naturalmente que se puede medir por la distancia entre dos muestras.Hay dos distancias comúnmente utilizadas:
- Distancia euclidiana: La distancia euclidiana es el método de medición de distancia más fácil de entender intuitivamente. La distancia entre dos puntos en el espacio con los que entramos en contacto en la escuela primaria, secundaria y preparatoria generalmente se refiere a la distancia euclidiana.
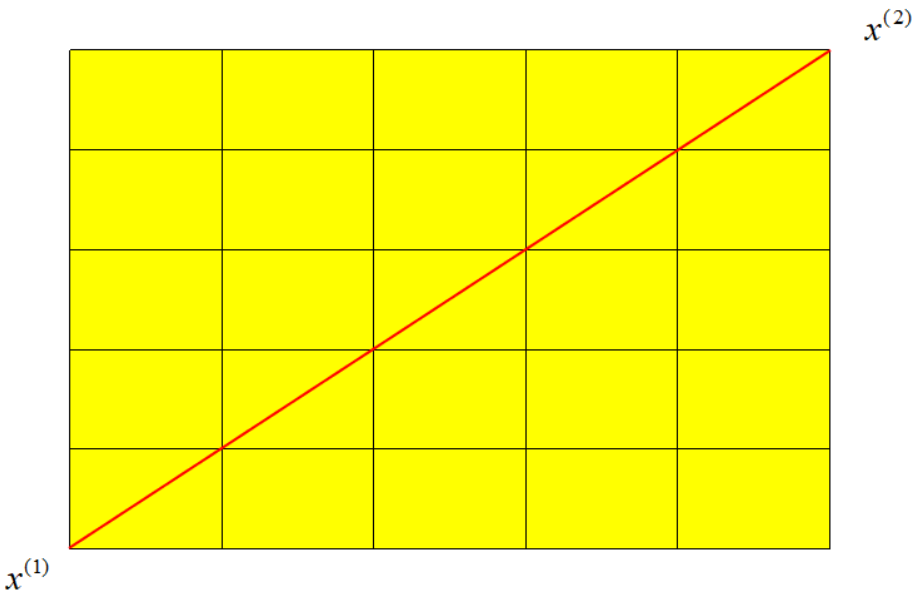
Fórmula de cálculo de la distancia euclidiana en un plano bidimensional:
d12=(x1(1)−x1(2))2+(x2(1)−x2(2))2
nFórmula de cálculo de la distancia euclidiana en el plano dimensional:
d12=i=1∑n(xi(1)−xi(2))2
- Distancia de Manhattan: Como sugiere el nombre, conduciendo de una intersección a otra en el vecindario de Manhattan, la distancia de conducción obviamente no es la distancia en línea recta entre dos puntos. Esta distancia de conducción real es la "distancia de Manhattan". La distancia de Manhattan también se conoce como "distancia de bloque de ciudad".

La fórmula para calcular la distancia de Manhattan en un plano bidimensional:
d12=∣x1(1)−x1(2)∣+∣x2(1)−x2(2)∣
nFórmula de cálculo de Manhattan en el plano dimensional:
d12=i=1∑n∣xi(1)−xi(2)∣
Entre ellos, el número entre paréntesis en superíndice representa el número de muestras y el número en subíndice representa las características de las muestras.
requisitos de programación
Begin-EndDe acuerdo con el aviso, complemente el código en el editor de la derecha para realizar topKel método.
instrucción de prueba
El programa llamará al método que implementó para encontrar klas etiquetas de las muestras más cercanas a la muestra de destino. Devuelve una lista si las 5muestras más cercanas a la muestra de destino son . Si el resultado devuelto es consistente con el resultado real, se considerará un despacho de aduana.0,0,1,1,1[0,0,1,1,1]
¡Comencemos tu misión, te deseo éxito!
Código de implementación:
#codificación=utf8
importar numpy como np
def topK(i,k,x,y):
'''
aporte:
i(int): i-ésima muestra
k(int): el número de muestras vecinas más cercanas
x(ndarray): características de los datos
y(ndarray): etiqueta de datos
producción:
topK(lista): las últimas k etiquetas de muestra de la muestra i
'''
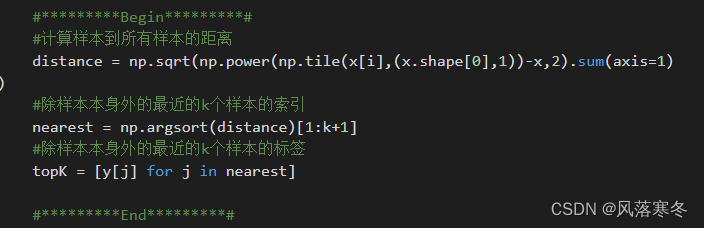
#*********Comenzar*********#
# Calcular la distancia de la muestra a todas las muestras
distancia = np.sqrt(np.power(np.tile(x[i],(x.shape[0],1))-x,2).sum(axis=1))
#Índices de las k muestras más cercanas que no sean la propia muestra
más cercano = np.argsort(distancia)[1:k+1]
#La etiqueta de las k muestras más cercanas excepto la muestra misma
topK = [y[j] para j en el más cercano]
#*********Fin*********#
volver arribaK
Captura de pantalla del código:
Nivel 2: Implementación práctica del algoritmo knn
detalles de la misión
La tarea de este nivel: usar el algoritmo pythonde implementación knny reconocer números escritos a mano.
información relacionada
Para completar la tarea de este nivel, debe dominar: 1. Votación ponderada, 2. knnProceso algorítmico.
Introducción al conjunto de datos
El conjunto de datos de dígitos escritos a mano tiene un total 1797de muestras, y cada muestra tiene 64una característica. El valor de cada característica 0-255es el píxel intermedio, y nuestra tarea 64es identificar 0-9a cuál de las diez categorías pertenece el número en función de este valor de característica.
Podemos usar sklearnpara cargar los datos directamente, el código es el siguiente:
from sklearn.datasets import load_digits#加载手写数字数据集digits = load_digits()#获取数据特征与标签x,y = digits .data,digits .target
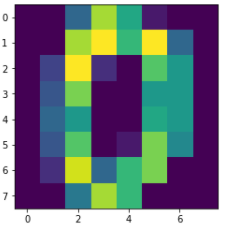
Por supuesto, cada muestra es un número, podemos restaurarlo al 8x8tamaño de la vista:
import matplotlib.pyplot as pltimg = x[0].reshape(8,8)plt.imshow(img)
Luego dividimos el conjunto de entrenamiento y el conjunto de prueba, el conjunto de entrenamiento se usa para entrenar el modelo y el conjunto de prueba se usa para probar el rendimiento del modelo. el código se muestra a continuación:
from sklearn.model_selection import train_test_split#划分训练集测试集,其中测试集样本数为整个数据集的20%train_feature,test_feature,train_label,test_label = train_test_split(x,y,test_size=0.2,random_state=666)
voto ponderado
Por el nivel anterior, ya sabemos cómo encontrar kla muestra más cercana, sin embargo, todavía nos queda un problema por resolver: si hay dos tipos de muestras con el mismo número y el número mayor, ¿a qué tipo debe pertenecer la muestra? ?
De hecho, knnel algoritmo finalmente determina a qué categoría pertenece la muestra, de hecho, es como votar, qué categoría tiene más votos, a qué categoría pertenece la muestra. Y si el número de votos es el mismo, podemos agregar un peso a cada voto para indicar la importancia de cada voto, de modo que se pueda resolver el problema del mismo número de votos. Obviamente, un voto emitido por una muestra con una distancia más cercana debería ser más importante, en este momento, podemos asignar el recíproco de la distancia como peso a cada voto.
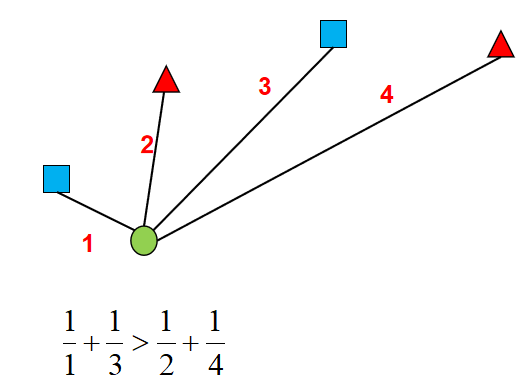
Como se muestra en la figura anterior, aunque el número de cuadrados azules es el mismo que el de los triángulos rojos, de acuerdo con las reglas de votación ponderada, el círculo verde debería pertenecer a la categoría de los cuadrados azules.
proceso de algoritmo knn
knnEl algoritmo no necesita entrenar el modelo, sino que solo juzga el tipo de muestra en función de los tipos de muestra más cercanos a la muestra, por lo que el proceso es muy simple:
计算出新样本与每一个样本的距离找出距离最近的k个样本根据加权投票规则得到新样本的类别
requisitos de programación
Begin-EndDe acuerdo con el aviso, complemente el código en el editor de la derecha para realizar knnel algoritmo.
instrucción de prueba
El programa llamará a su método implementado para reconocer dígitos escritos a mano, y 0.95si la tasa correcta es mayor que eso, se considerará una autorización.
¡Comencemos tu misión, te deseo éxito!
Código de implementación:
#codificación=utf8
importar numpy como np
def knn_clf(k,train_feature,train_label,test_feature):
'''
aporte:
k(int): el número de muestras vecinas más cercanas
train_feature(ndarray): funciones de ejemplo de entrenamiento
train_label(ndarray): etiqueta de muestra de entrenamiento
test_feature(ndarray): funciones de muestra de prueba
producción:
predecir (ndarray): etiqueta de predicción de muestra de prueba
'''
#*********Comenzar*********#
#Inicializar resultados de predicción
predecir = np.zeros(test_feature.shape[0],).astype('int')
# Recorrer cada muestra en el conjunto de prueba
para i en el rango (test_feature.shape[0]):
#La distancia desde la i-ésima muestra en el conjunto de prueba hasta cada muestra en el conjunto de entrenamiento
distancia = np.sqrt(np.power(np.tile(test_feature[i],(train_feature.shape[0],1))-train_feature,2).sum(axis=1))
#La distancia de las k muestras más cercanas
distancia_k = np.sort(distancia)[:k]
#El índice de las k muestras más recientes
más cercano = np.argsort(distancia)[:k]
#Las etiquetas de las k muestras más recientes
topK = [train_label[i] para i en el más cercano]
#Inicialice el diccionario para votar, la clave del diccionario es la etiqueta y el valor es el puntaje de votación
votos = {}
#Inicializar el número máximo de votos
max_count = 0
# votar
para j, etiqueta en enumerar (topK):
# Los votos se puntúan si la etiqueta está en la clave del diccionario
si etiqueta en votos.keys():
votos[etiqueta] += 1/(distancia_k[j]+1e-10)#Evitar que el denominador sea 0
#Si la puntuación es la más alta, actualice el valor predicho en la etiqueta correspondiente
si votos[etiqueta] > max_count:
max_count = votos[etiqueta]
predecir[i] = etiqueta
#Si la etiqueta no está en el diccionario, agregue la etiqueta a la clave del diccionario y cuéntela en la puntuación correspondiente
demás:
votos[etiqueta] = 1/(distancia_k[j]+1e-10)
si votos[etiqueta] > max_count:
max_count = votos[etiqueta]
predecir[i] = etiqueta
#*********Fin*********#
volver predecir
Captura de pantalla del código: