Aún no he terminado de escribir, así que no me regañes... Agregaré cualquier material nuevo que encuentre.
1. Función de pérdida/medida de distancia
1.1 divergencia KL
Se utiliza para medir la distancia entre distribuciones.
1.1.1 Proceso de derivación
Si desea comprender mejor la divergencia de KL, le recomiendo que eche un vistazo. Creo que es un mejor punto de partida comenzar desde la perspectiva de la entropía de la información: entropía relativa (divergencia de KL), divergencia de JS y distancia de Wasserstein.
y
ambas son distribuciones de probabilidad,
generalmente representan la distribución verdadera y
generalmente representan la
distribución aproximada ajustada.

Utilizando la fórmula de cálculo de expectativas, puede obtener la divergencia de KL expresada en términos de expectativa.
1.1.2 Propiedades
- No negatividad: la divergencia de KL siempre es no negativa, es decir, KL (P || Q) ≥ 0.
- Valor cero: si y solo si P y Q son iguales, la divergencia KL es 0, lo que indica que las dos distribuciones son exactamente iguales.
- Asimetría : La divergencia de KL es asimétrica, es decir, KL (P || Q) ≠ KL (Q || P), lo que significa que la ganancia de información de P con respecto a Q y la pérdida de información de P con respecto a Q son diferentes.
1.1.3 Divergencia KL hacia adelante y hacia atrás
Llamado divergencia delantera KL (divergencia delantera Kullback-Leibler)
Llamada divergencia KL inversa (divergencia inversa de Kullback-Leibler)
[Análisis detallado] Explicación detallada avanzada de la divergencia KL - Zhihu (zhihu.com)
1.2 Divergencia JS (divergencia Jensen-Shannon)
Para resolver el problema de la divergencia KL asimétrica, se introduce la divergencia JS.
1.2.1 Oficial
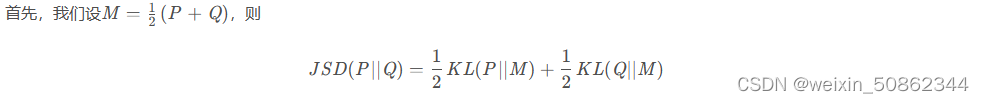
1.2.2 Prueba de simetría
1.2.3 Defectos
Cuando dos distribuciones no se superponen en absoluto, no importa qué tan cerca estén los centros de las dos distribuciones, su divergencia JS es constante, por lo que el gradiente es 0 y no se puede actualizar.
[Referencia] GAN: Prueba matemática de que las dos distribuciones no se superponen y la divergencia JS es log2
1.3 Pérdida de Wasserstein
2. Tres cuestiones principales en la formación de GAN
- No convergencia : los parámetros del modelo oscilan y la función de pérdida no puede converger al valor teórico;
- Colapso de modo : todas las muestras sintetizadas convergen;
- Gradiente desaparecido : El discriminador es demasiado fuerte, el gradiente del generador desaparece y el entrenamiento no puede continuar.
El problema del colapso modal de las redes generativas adversarias (GAN)
3.1 Colapso del patrón
GAN esencialmente compara la distribución real con la distribución generada por el generador.
Primero: el generador genera muestras poco realistas. Correspondiente a esas muestras irreales, Pg(X)>0 pero Pr(X)≈0, en este momento el integrando en el medio de la divergencia KL tenderá a ∞;
Segundo: el generador no pudo generar muestras reales. En correspondencia con aquellas muestras reales que no se pudieron generar, pr (x)>0 pero pg (x) ≈0, en este momento el integrando en el medio de la divergencia KL tenderá a 0.
La función de pérdida del generador optimizado en GAN requiere que la divergencia KL sea lo más pequeña posible. En el primer caso, la pérdida es casi infinita y la penalización es enorme, por lo que el generador evitará generar muestras irreales; en el segundo caso, la pérdida es cercana a cero y la penalización es muy pequeña, por lo que es completamente posible que el generador genere solo una única muestra real sin generar muestras reales más diversas. Generar una única muestra real es suficiente para engañar al discriminador, no es necesario que el generador genere diversas muestras con riesgo de distorsión, y surge el problema del colapso modal.
3. Marco de código modelo
[Implementación de referencia] facebookresearch/pytorch_GAN_zoo: una combinación de implementaciones de GAN que incluyen un crecimiento progresivo
3.1 Parte de pérdida
3.1.1 Pérdida del discriminador

3.1.2 Pérdida del generador

3.1.2 Estrategia de formación progresiva
Después del lanzamiento de ProGAN, muchos modelos también optaron por utilizar estrategias de entrenamiento progresivo. La estrategia de entrenamiento progresivo reduce el tiempo de manera conveniente y también evita hasta cierto punto la falla del modelo.
4. Indicadores de evaluación
4.1 FID (puntuación de distancia de inicio de Frechet)
La distancia de inicio de Frechet (FID) es una métrica para evaluar la calidad de las imágenes generadas, que se utiliza específicamente para evaluar el rendimiento de las redes generativas adversarias.
Fundamental:
- Elimine la capa de salida original del modelo y reemplace la capa de salida con el valor de salida de la función de activación de la última capa de agrupación (es decir, la capa de agrupación espacial global). Esta capa de salida tiene un vector de activación de 2048 dimensiones, por lo que se predice que cada imagen tendrá 2048 características activadas. Este vector se denomina vector de codificación o vector de características de la imagen.
- Luego, la puntuación FID se calcula utilizando la siguiente fórmula:

- Esta fracción se denota como d^2, lo que significa que es una distancia con un término al cuadrado.
- "mu_1" y "mu_2" se refieren a la característica media de la imagen real y la imagen generada (por ejemplo, un vector de elementos de 2048 dimensiones donde cada elemento es la característica media observada en la imagen).
- C_1 y C_2 son las matrices de covarianza de los vectores propios de la imagen real y la imagen generada, a menudo llamadas sigma.
- || mu_1-mu_2 ||^2 representa la suma de los cuadrados de las diferencias entre los dos vectores promedio. Tr se refiere a una operación de álgebra lineal llamada "traza" (es decir, la suma de los elementos en la diagonal principal de una matriz cuadrada).
- sqrt es la raíz cuadrada de la matriz cuadrada, dada por el producto entre las dos matrices de covarianza
[Referencia] Para aprender la evaluación cuantitativa de los modelos GAN, comencemos por dominar FID.