Índice de contenidos de los artículos de la serie.
Habilidades profesionales de diseño de arquitectura de sistemas · Ingeniería de software (1) [Arquitecto de sistemas]
Habilidades avanzadas de diseño de arquitectura de sistemas · Conceptos de arquitectura de software, estilos arquitectónicos, ABSD, reutilización de arquitectura, DSSA (1) [Arquitecto de sistemas]
Habilidades avanzadas de diseño de arquitectura de sistemas · Atributos de calidad del sistema y evaluación de arquitectura (2) [Arquitecto de sistemas]
Habilidades avanzadas en diseño de arquitectura de sistemas · Análisis y diseño de confiabilidad del software (3) [Arquitecto de sistemas]
Habilidades profesionales en diseño de arquitectura de sistemas · Diseño de bases de datos (2)
- Índice de contenidos de los artículos de la serie.
- 1. Concepto de base de datos
- 2. modelo de base de datos
- 3. Base de datos relacional
- 4. Diseño de base de datos
- 1. Interacción entre aplicación y base de datos.
- 1. Base de datos NoSQL
- 1. Base de datos distribuida
- 1. Tecnología de optimización de bases de datos
- 1. Tecnología de almacenamiento en caché distribuido Redis
1. Concepto de base de datos
1.1 modelo de datos
Los modelos de datos se dividen en: modelo jerárquico, modelo de red, modelo orientado a objetos y modelo relacional.
Los tres elementos de un modelo de datos son: estructura de datos, operaciones de datos y restricciones de datos.
Las restricciones de datos incluyen:
(1) Integridad de la entidad:
(2) Integridad referencial:
(3) Integridad definida por el usuario:
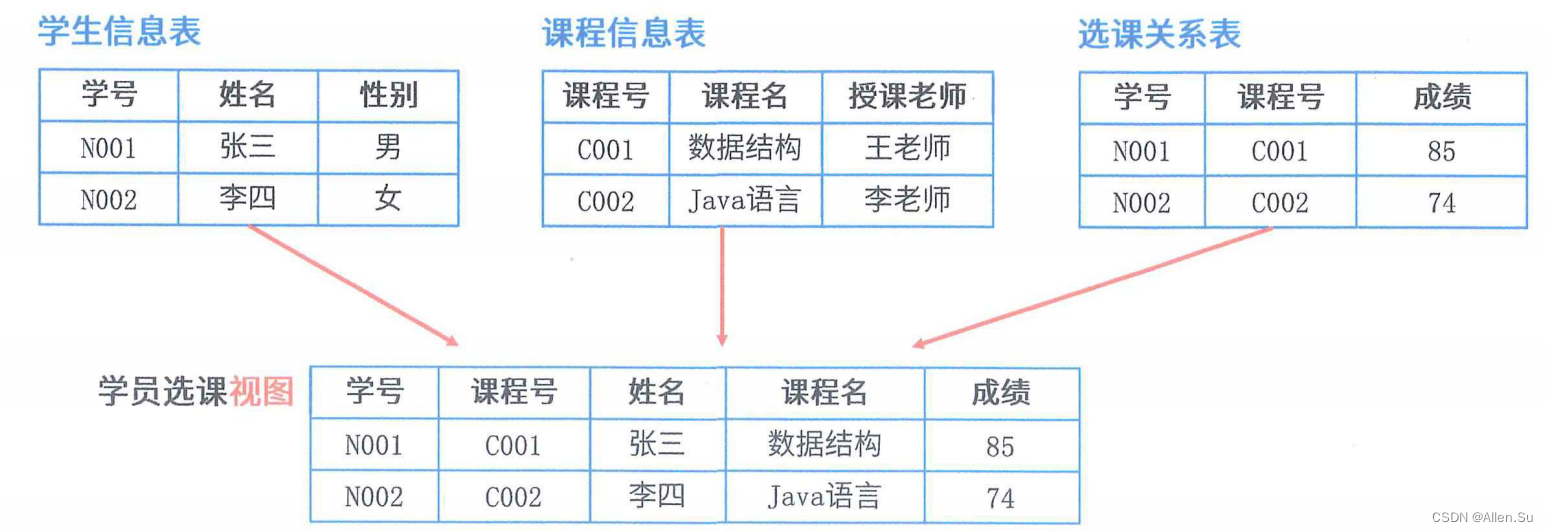
1.2 Vista de base de datos
En realidad, una vista no existe en la base de datos, sino que es una tabla virtual.
2. modelo de base de datos
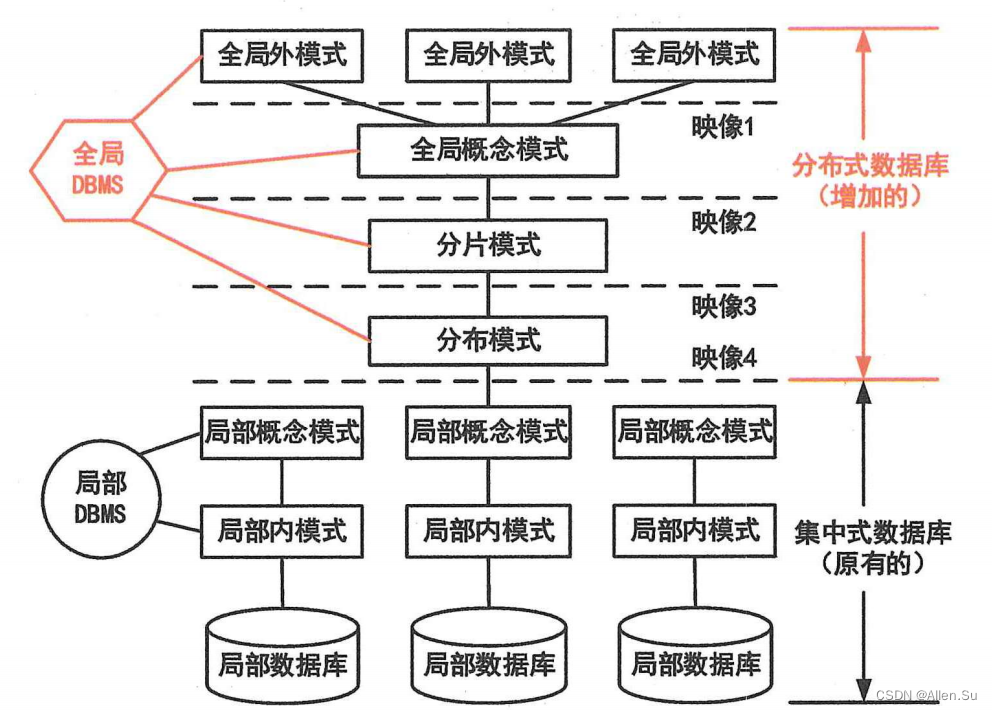
Las bases de datos generalmente adoptan un modelo de tres niveles: los desarrolladores de sistemas necesitan reducir la complejidad del sistema de protección del usuario y simplificar la interacción entre los usuarios y el sistema mediante la abstracción en tres niveles: capa de vista, capa lógica y capa física.
Desde la perspectiva de los sistemas de gestión de bases de datos, las bases de datos también se dividen en esquemas externos, esquemas conceptuales y esquemas internos.
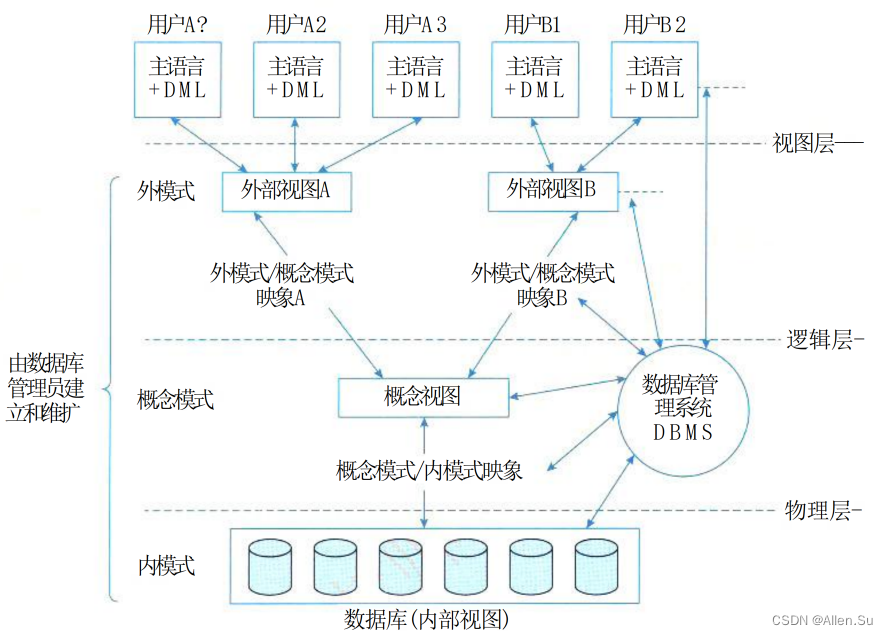
El sistema de base de datos proporciona imágenes de dos niveles entre esquemas de tres niveles: esquema conceptual/imagen de esquema interno y esquema externo/imagen de esquema conceptual. Estos dos niveles de imágenes garantizan que los datos de la base de datos tengan una alta independencia lógica y física.
Esquema de tres niveles de base de datos
| modo externo | modelo conceptual | modo interno |
|---|---|---|
| También llamado submodo o modo de usuario, se utiliza para describir la estructura lógica de la parte de los datos que los usuarios ven o usan. Los usuarios utilizan declaraciones o aplicaciones de manipulación de datos para operar datos en la base de datos de acuerdo con el modo externo. | Es una descripción de la estructura lógica y las características de todos los datos de la base de datos y es una vista de datos común para todos los usuarios. | Es una descripción de la estructura física y el método de almacenamiento de los datos, cómo se representan los datos dentro de la base de datos y define todos los tipos de registros internos, índices y métodos de organización de archivos. |
Imágenes de dos niveles de base de datos
| independencia lógica | independencia fisica |
|---|---|
| Corresponde al mapeo entre esquema externo y esquema conceptual. Significa que el programa de aplicación es independiente de la estructura lógica de la base de datos. Cuando la estructura lógica de los datos cambia, el programa de aplicación permanece sin cambios. | Corresponde al mapeo entre esquemas conceptuales y esquemas internos. Significa que la aplicación y los datos del disco son independientes entre sí. Cuando el almacenamiento físico de datos cambia, la aplicación no cambia |
3. Base de datos relacional
3.1 Modelo relacional
Los tres elementos de un modelo de datos son: estructura de datos, operaciones de datos y restricciones de datos.
Forma de expresión del modelo relacional
1:
estudiante (número de estudiante, nombre, edad, número de clase)
Formulario 2:
Estudiante (U, F)
U = {número de estudiante, nombre, edad, número de clase}
F = {número de estudiante → nombre, número de estudiante → edad, número de estudiante → número de clase}
Concepto básico:
orden o grado: el número de atributos en el patrón de relación.
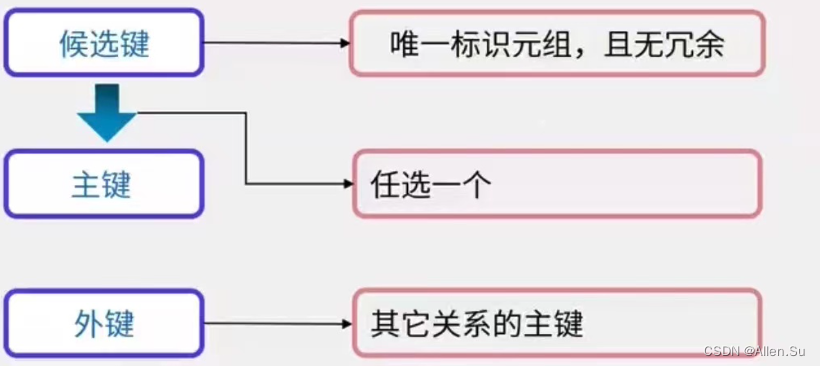
Clave candidata (clave candidata): el valor de un atributo o grupo de atributos en una relación e identifica de forma única una tupla.
Clave principal (clave principal): si hay varias claves candidatas en una relación, seleccione una de ellas como clave principal.
Atributos primarios y atributos no primarios: los atributos que componen el código candidato son los atributos primarios y los demás son atributos no primarios.
Clave externa (clave externa): El código de otras relaciones es la clave externa.
Código completo: todos los grupos de atributos del patrón de relación son códigos candidatos para esta relación.
Restricciones de integridad:
- Restricción de integridad de la entidad: estipula que los atributos principales de la relación básica no pueden tomar valores nulos.
- Restricciones de integridad referencial: referencias entre relaciones, claves primarias o valores nulos de otras relaciones.
- Restricciones de integridad definidas por el usuario: determinadas por el entorno de la aplicación.
- desencadenar:
3.1 Operaciones relacionales
Unión (∪) : La unión de las relaciones R y S es el conjunto formado por tuplas pertenecientes o pertenecientes a S.
Intersección (∩) : La intersección de las relaciones R y S es el conjunto de tuplas que pertenecen a R y pertenecen a S al mismo tiempo .
Diferencia (—) : La diferencia entre las relaciones R y S es el conjunto de tuplas que pertenecen a R pero no a S.
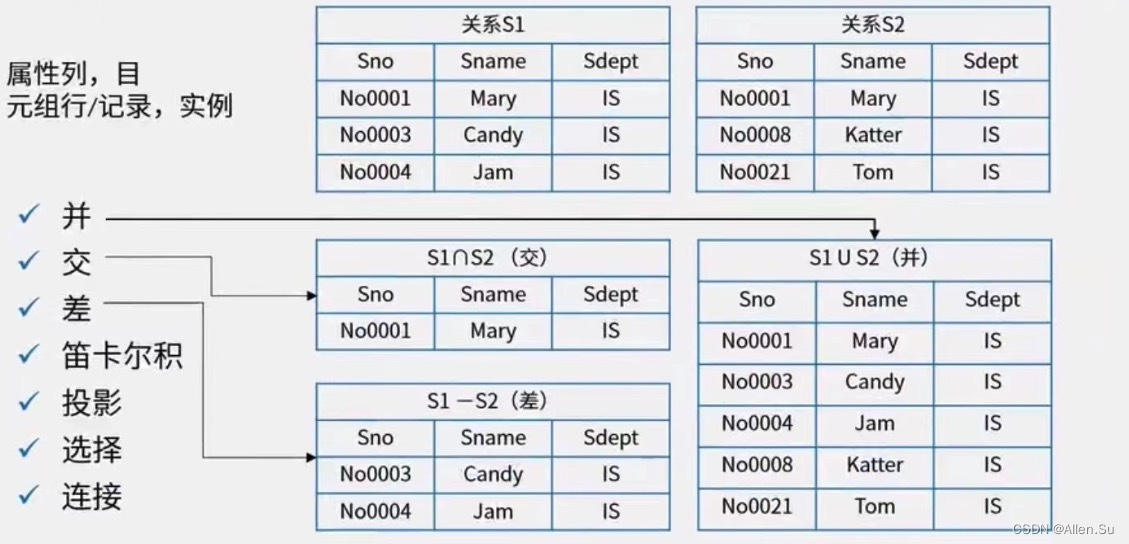
Producto cartesiano (X) : El producto cartesiano de dos relaciones R y S con n y m columnas respectivamente es un conjunto de tuplas con (n + m) columnas. Las primeras n columnas son una tupla de la relación R, y las últimas m columnas son una tupla de la relación S, denotada como RXS. Si R y S tienen el mismo nombre de atributo, el nombre de la relación se puede agregar como una calificación antes de la nombre del atributo para indicar la diferencia. Si R tiene K1 tuplas y S tiene K2 tuplas, entonces el producto cartesiano de R y S tiene K1 X K2 tuplas.
Seleccionar (σ) : obtiene las filas de la relación R que cumplen las condiciones.
Proyección (π) : Obtenga las columnas calificadas en la relación R.
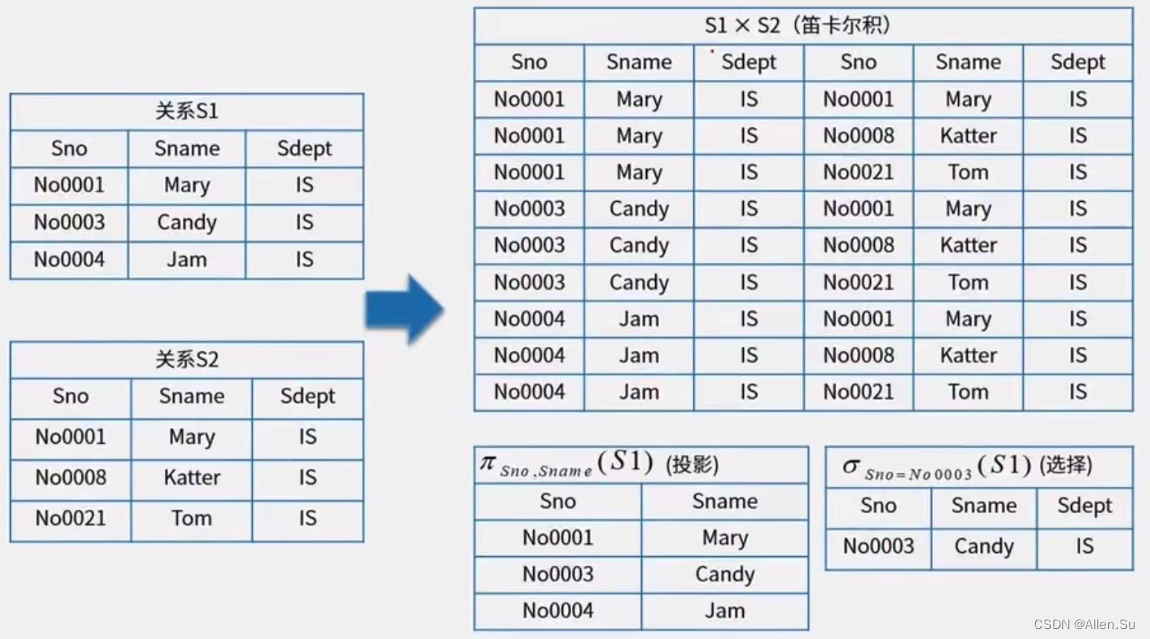
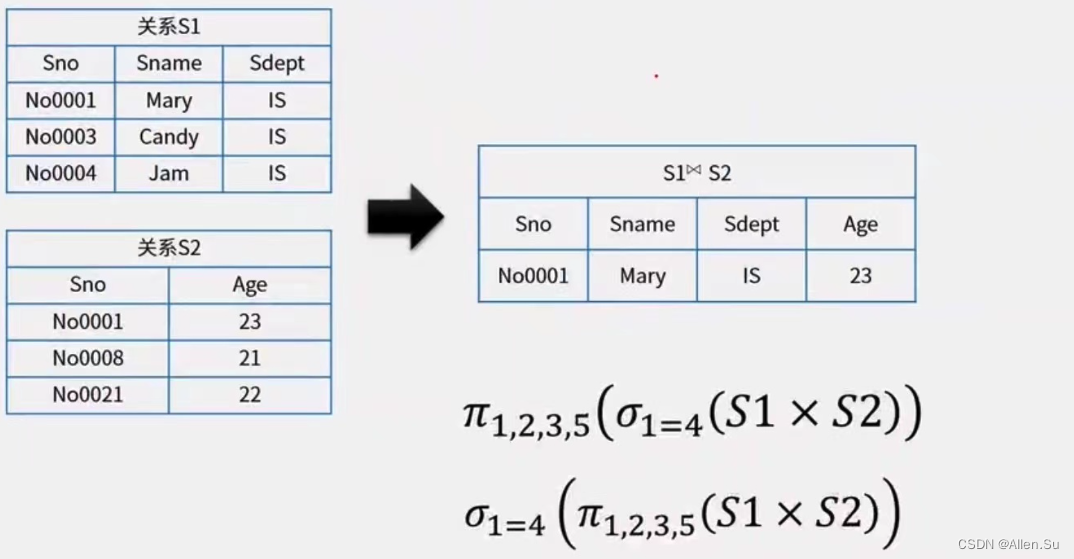
Conexión (Φ) :
Conexión equivalente: seleccione las relaciones R y S, y seleccione tuplas con valores de atributos iguales en el producto cartesiano de las dos.
Unión natural: una unión equivalente especial que requiere que la comparación de columnas de atributos sean del mismo grupo de atributos y elimina atributos duplicados de los resultados.
3.1 Teoría básica del diseño de datos relacionales
El objetivo del diseño de bases de datos relacionales es generar un conjunto de esquemas relacionales apropiados y de buen rendimiento que reduzcan la redundancia del almacenamiento de información en el sistema pero permitan un fácil acceso a la información.
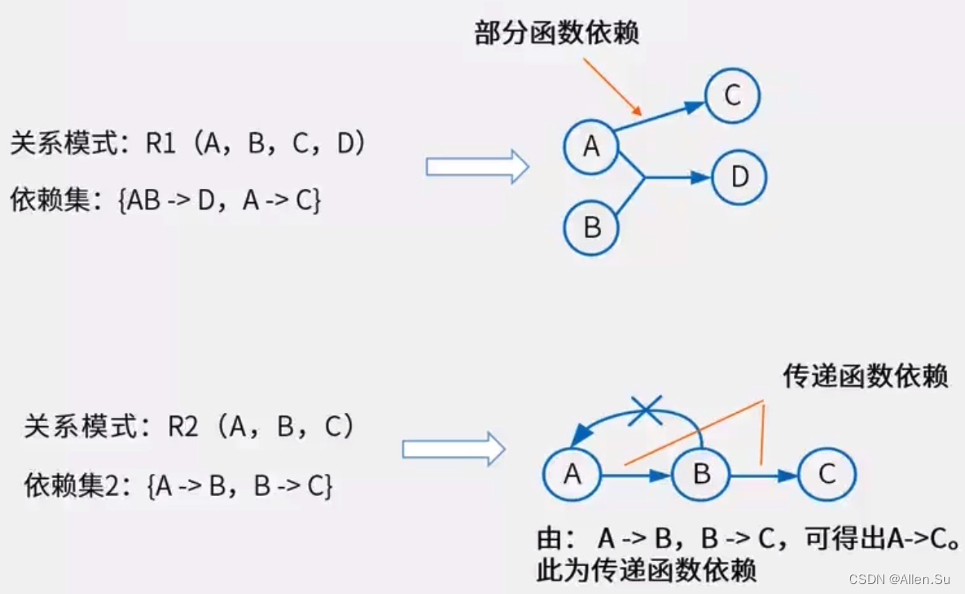
3.1.1 Dependencias funcionales
Sea R (U, F) un patrón relacional en el atributo U, X e Y son subconjuntos de U, y r es cualquier relación de R. Si para dos tuplas cualesquiera u, v en r, siempre que haya u[ Y ] = v[Y], entonces se dice que la función X depende de Y, o que la función Y depende de X, denotada como X → Y, lo que se llama dependencia funcional.
Por ejemplo: número de estudiante → número de departamento, número de departamento → nombre del departamento
3.1.2 Clave/Clave candidata
- Atributos primarios y atributos no primarios: los atributos que componen el código candidato son los atributos primarios y los demás son atributos no primarios.
Encuentre instancias clave candidatas
- Representar las dependencias funcionales del patrón relacional en forma de "gráfico dirigido".
- Encuentre el atributo con grado 0 y utilice este conjunto de atributos como punto de partida para intentar atravesar el gráfico dirigido. Si todos los nodos del gráfico se pueden atravesar normalmente, entonces este conjunto de atributos es una clave candidata para el patrón relacional.
- Si el atributo establecido con un grado de entrada de 0 no puede atravesar todos los nodos en el gráfico, debe intentar incorporar algunos nodos intermedios (nodos con grado de entrada y de salida) en el atributo establecido con un grado de entrada. de 0 hasta que los conjuntos puedan atravesar todos los nodos y los conjuntos sean claves candidatas.
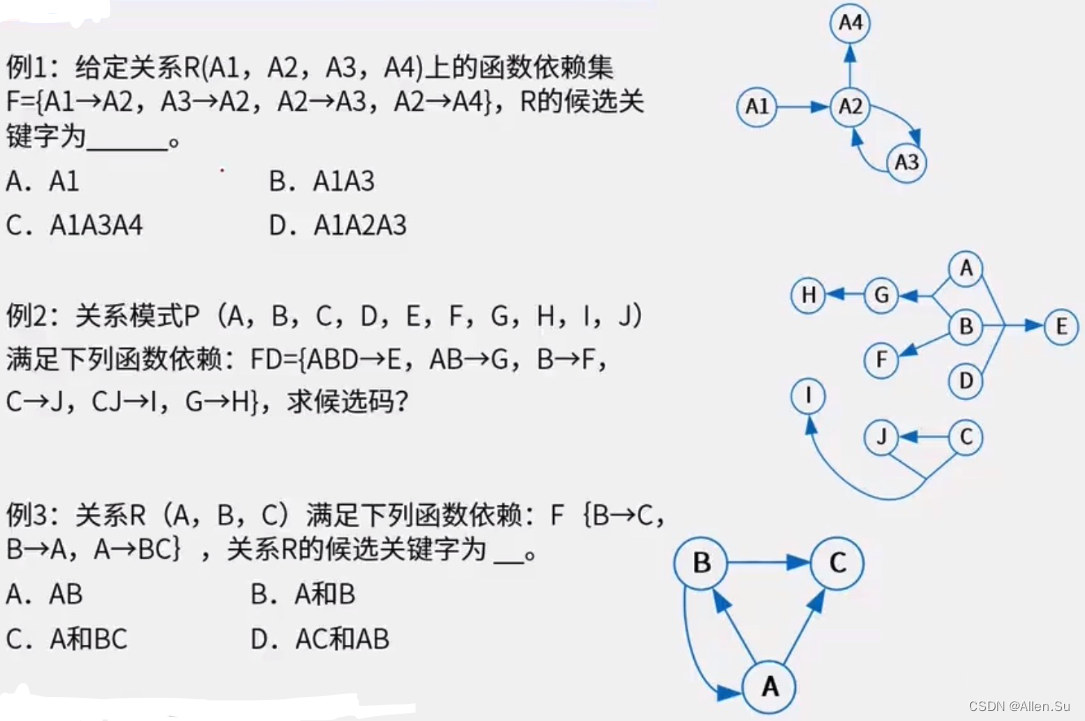
3.1.3 Axioma de dependencia funcional (axioma de Armstrong)
A partir de dependencias funcionales conocidas se pueden deducir otras dependencias funcionales, lo que requiere una serie de reglas de inferencia, que a menudo se denominan " axiomas de Armstrong ".
Suponiendo la relación R (U, F), U es el conjunto de atributos del patrón relacional R, y F es un conjunto de dependencias funcionales de U, entonces existen las siguientes tres reglas de inferencia: (1) Ley reflexiva: si Y ⊆
X ⊆ U , Entonces X → Y está implicado por F.
(2) Ley de aumento : si Z ⊆ U y X → Y está implicado por F, entonces XZ → YZ está implicado por F.
(3) Ley transitiva : X → Y, Y → Z están implicados por F, luego X → Z está implicado por F.
De acuerdo con las reglas de razonamiento anteriores, se pueden deducir las siguientes tres reglas :
(1) Regla de fusión: si X → Y, X → Z, entonces X → YZ está implícito en F.
(2) Regla pseudotransitiva : si X → Y, WY → Z, entonces XW → Z está implicado por F.
(3) Regla de descomposición :Y , Z ⊆ Y, entonces X → Z está implícito en F.
La prueba es como sigue:

3.1.4 Teoría de la normalización
Uno de los métodos del diseño de bases de datos relacionales es encontrar el modelo paradigmático apropiado. Por lo general, el grado de estandarización del modelo se puede evaluar juzgando cuántos paradigmas alcanza el modelo descompuesto. Las formas normales incluyen: 1NF, 2NF, 3NF, BCNF, 4NF, 5NF.
¿Qué impacto trae el aumento en el nivel de especificación?
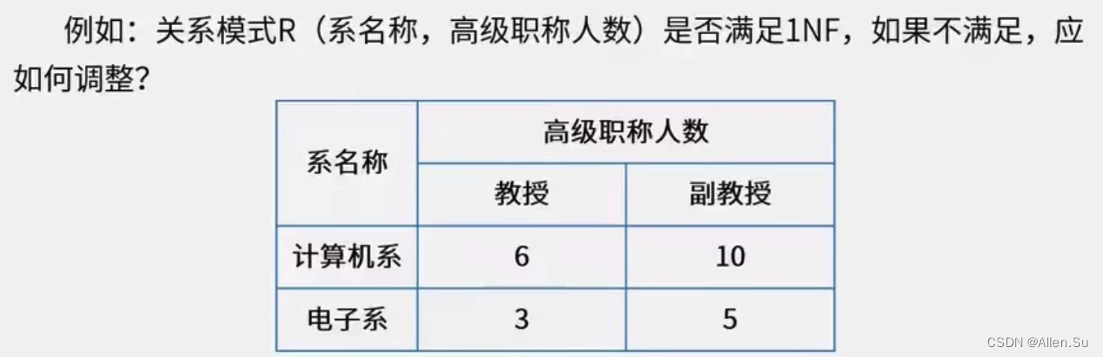
(1) Primera forma normal (1NF) : en el esquema relacional R, si y solo si todos los campos contienen solo valores atómicos, es decir, cada atributo es un elemento de datos indivisible, entonces el esquema relacional R pertenece a la primera forma normal .
Por ejemplo: lo siguiente no cumple con 1NF y el número de títulos profesionales senior se puede dividir en profesores y profesores asociados .
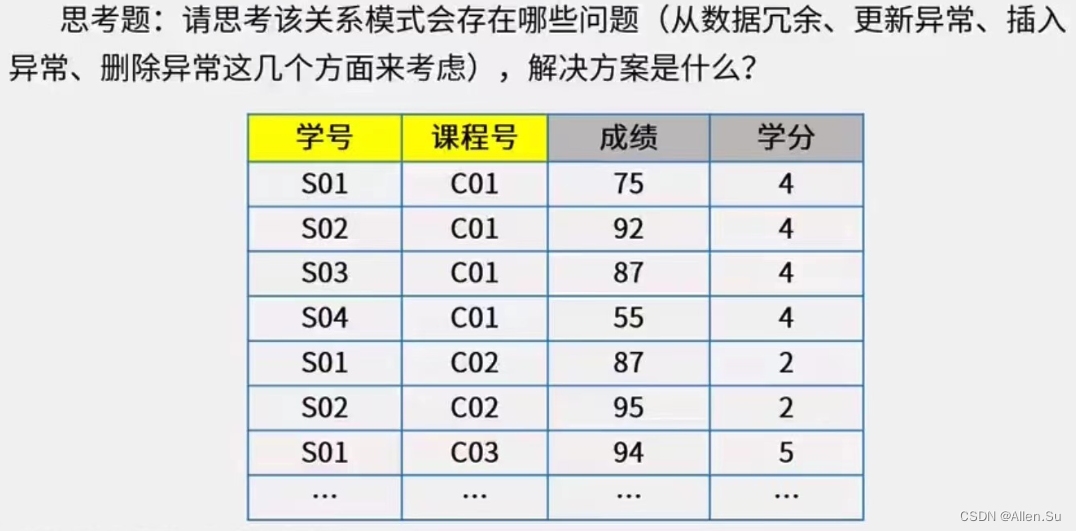
(2) Segunda forma normal (2NF) : si el esquema relacional R ∈ 1NF, y cada atributo no primario depende completamente de la clave primaria (no hay dependencia parcial), entonces el esquema relacional R pertenece a la segunda forma normal .
Por ejemplo: lo siguiente no satisface 2NF y el número de curso puede contener créditos .
(3) Tercera forma normal (3NF) : si el patrón relacional R ∈ 2NF y no existe una dependencia funcional transitiva de los atributos no primarios de la clave primaria. Entonces el patrón relacional R pertenece a la tercera forma normal .
Por ejemplo: lo siguiente no cumple con 3NF, el nombre del departamento y la posición del departamento dependen del número de departamento .
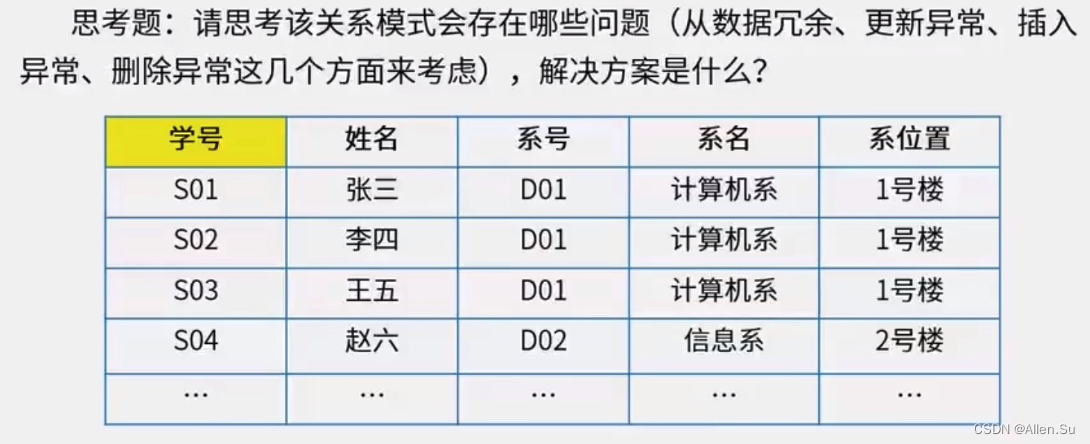
(4) Forma normal de BC (BCNF) : supongamos que R es un patrón relacional, F es su conjunto de dependencias, R pertenece a BCNF si y solo si el determinante de cada dependencia en F debe contener un determinado código candidato de R.
Por ejemplo:
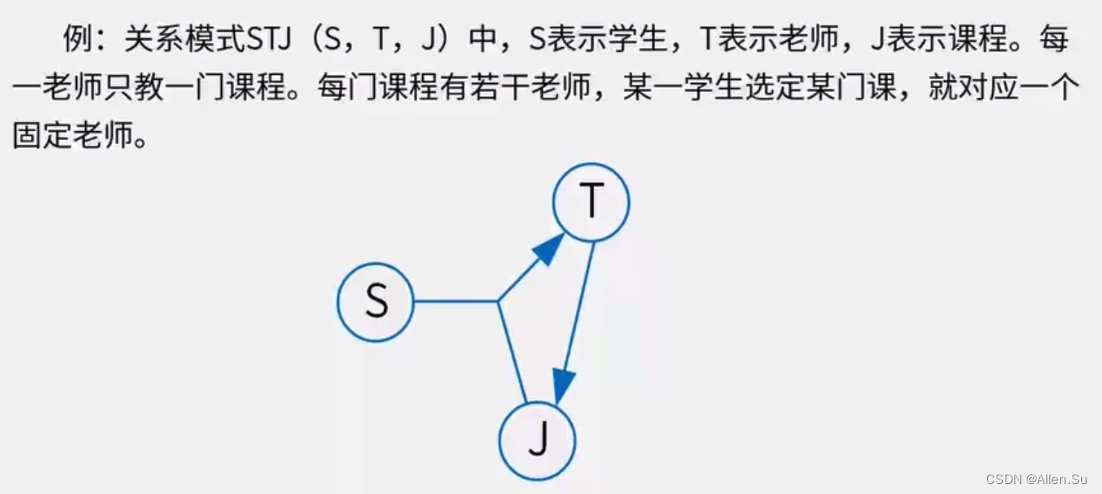
3.1.5 Descomposición de patrones (si se mantienen las dependencias funcionales y si no se producen pérdidas)
4. Diseño de base de datos
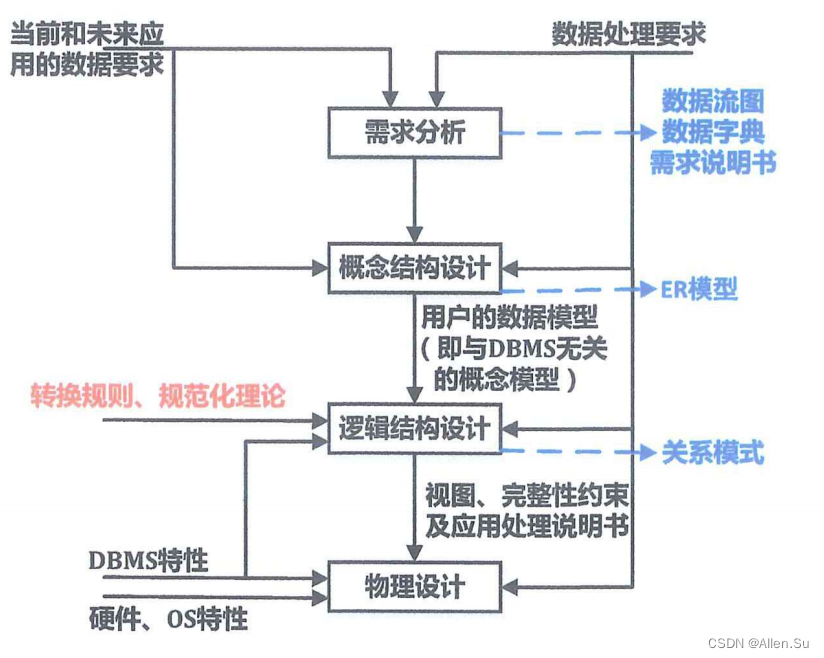
Los pasos básicos del diseño de una base de datos se pueden dividir en análisis de las necesidades del usuario, diseño de la estructura conceptual, diseño de la estructura lógica, diseño de la estructura física, etapa de implementación de la base de datos (diseño de la aplicación), operación y mantenimiento.Proceso de diseño de la base de datos
:
4.1 Diseño estructural conceptual
4.2.1 modelo ER
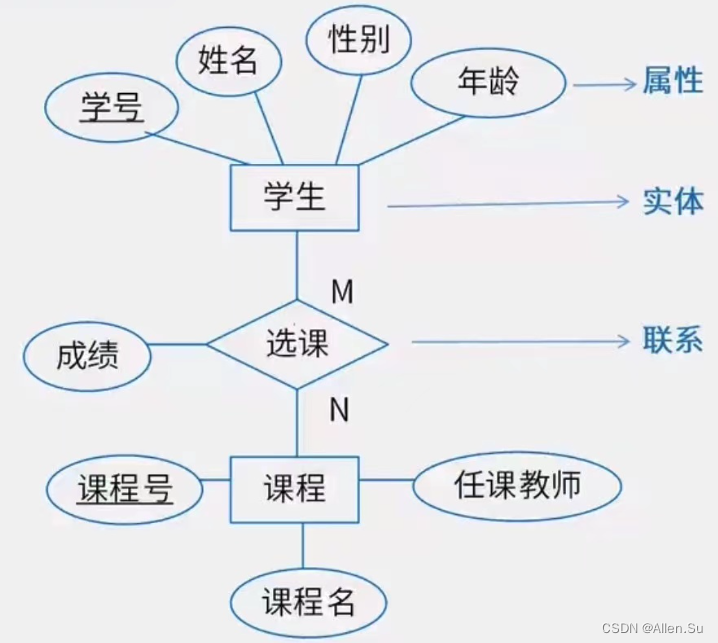
El modelo ER, denominado diagrama ER , es una herramienta práctica para describir el mundo conceptual y establecer modelos conceptuales. Los tres elementos del diagrama ER:
(1) Entidad: representada por un rectángulo, con el nombre de la entidad marcado en el cuadro.
(2) Atributos: representados por gráficos elípticos y conectados con entidades mediante líneas.
(3) La relación entre entidades: representada por un cuadro de diamantes, con el nombre del contacto marcado en el cuadro, conectando los cuadros de diamantes con las entidades relevantes con líneas e indicando el tipo de contacto en las líneas.
4.2.2 La relación entre dos entidades diferentes en el diagrama ER:
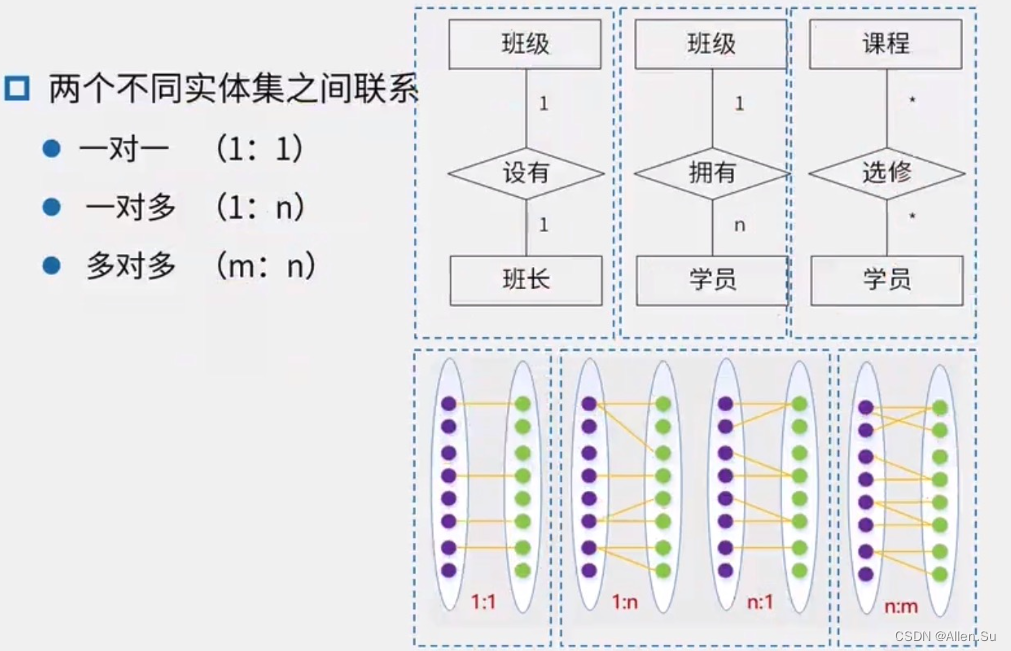
4.2.3 Proceso de diseño de estructura conceptual:
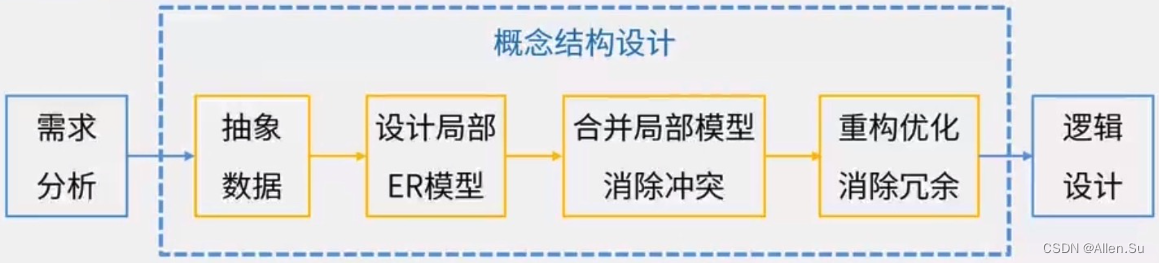
-
Método de integración :
se integran varios diagramas ER locales
a la vez y se integran paso a paso, y se integran dos diagramas ER locales a la vez de forma acumulativa. -
Conflictos causados por la integración y sus soluciones :
Conflictos de atributos: incluidos conflictos de dominio de atributos y conflictos de valores de atributos
Conflictos de nombres: incluidas objeciones del mismo nombre y
conflictos de estructuras sinónimas: incluidos objetos unificados que tienen diferentes abstracciones en diferentes aplicaciones y la misma entidad en diferentes aplicaciones. El número de atributos y el orden de los atributos incluidos en diferentes diagramas ER parciales no son exactamente los mismos.
4.2 Diseño de estructura lógica
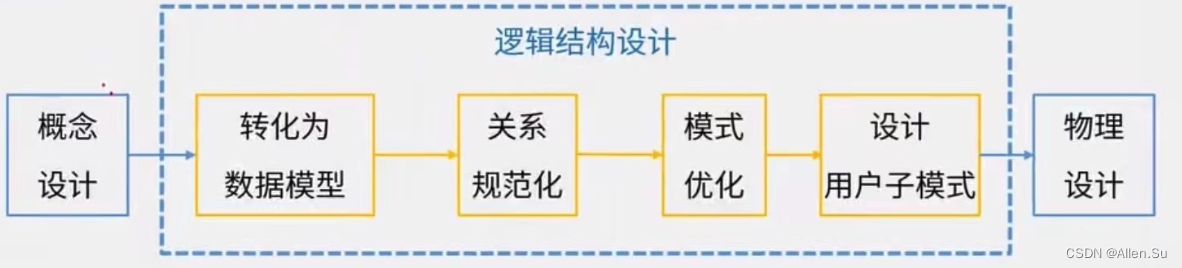
- Conversión de diagrama ER a modelo relacional Conversión
de entidad a modelo relacional Conversión
de contacto a modelo relacional - Normalización del esquema relacional.
- Determinar restricciones de integridad (garantizar la exactitud de los datos)
- Determinación de la vista del usuario (para mejorar la seguridad e independencia de los datos)
Determinar la vista del proceso de procesamiento en función del diagrama de flujo de datos
Determinar las vistas utilizadas por diferentes usuarios en función de la vista del usuario - Diseño de aplicaciones
☆ Un tipo de entidad debe convertirse en un modelo de relación
☆ Contacto al modelo de relación :
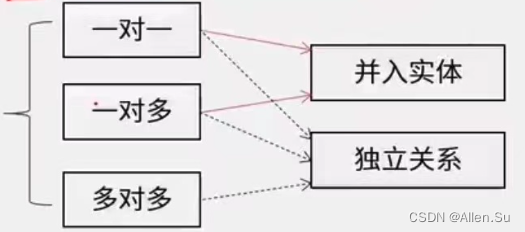
-
(1) Hay dos formas de convertir una relación uno a uno en
un modelo de relación independiente : fusionar las claves primarias en ambos extremos y las propiedades de la relación misma. ( Clave primaria : clave primaria en cualquier extremo)
Fusionar (en cualquier extremo ): fusionar con la clave primaria en el otro extremo y asociar sus propios atributos. ( Clave principal : permanece sin cambios) -
(2) Hay dos modos de relación independientes para convertir relaciones de uno a muchos : fusionar las claves primarias en ambos extremos y las propiedades de la relación misma. ( Clave primaria : clave primaria multiterminal) Fusionar (multiterminal) : fusionar con la clave primaria del otro extremo y los atributos relacionados. ( Clave principal : permanece sin cambios)
-
(3) Sólo hay una forma de convertir una relación de muchos a muchos
en un modelo de relación independiente : fusionar las claves primarias en ambos extremos y las propiedades de la relación misma. ( Clave principal : la clave combinada de las claves principales en ambos extremos)
4.3 Control de concurrencia
4.3.1 Características ACID de las transacciones
4.4 Seguridad de la base de datos
4.5 Copia de seguridad y recuperación de bases de datos
4.6 Optimización del rendimiento de la base de datos
1. Interacción entre aplicación y base de datos.
1. Base de datos NoSQL
Sin SQL (no solo SQL): con el auge de los sitios web web 2.0 de Internet, las bases de datos relacionales tradicionales se han vuelto incapaces de hacer frente a los sitios web web 2.0, especialmente los sitios web web 2.0 puramente dinámicos de tipo SNS ultragrandes y altamente concurrentes, y han quedado expuestos. Hay muchos problemas difíciles de superar, pero las bases de datos no relacionales se han desarrollado muy rápidamente debido a sus propias características.
| esquema de base de datos relacional | Modo NoSQL | |
|---|---|---|
| Soporte de concurrencia | Soporte de concurrencia, baja eficiencia. | Alto rendimiento de concurrencia |
| Almacenamiento y consulta | Almacenamiento de tablas relacionales, consulta SQL. | Almacenamiento masivo de datos y alta eficiencia de consultas |
| Modo de extensión | Expandir hacia arriba | poner a escala |
| Modo de índice | Árbol B, hash, etc. | índice de valor clave |
| Áreas de aplicación | Orientado a campos generales. | áreas de aplicación específicas |
| Clasificación | Escenarios de aplicación típicos | modelo de datos | ventaja | defecto | EjemplosEjemplos |
|---|---|---|---|---|---|
| valor clave | El almacenamiento en caché de contenido se utiliza principalmente para manejar cargas de acceso elevadas de grandes cantidades de datos y también se utiliza en algunos sistemas de registro, etc. | Puntos clave para el par clave-valor de Valor, generalmente implementado mediante una tabla hash | Velocidad de búsqueda rápida | Los datos no están estructurados y generalmente solo se tratan como cadenas o datos binarios. | Redis, Gabinete de Tokio/Tirano, Voldemort, Oracle BDB |
| Base de datos del almacén de columnas | sistema de archivos distribuido | Almacene datos en grupos de columnas para almacenar datos juntos en la misma columna | Velocidad de búsqueda rápida, gran escalabilidad y expansión distribuida más sencilla | Las funciones son relativamente limitadas. | HBase, Cassandra, Riak |
| base de datos de documentos | Aplicación web (similar a Key-Value, Value está estructurado, pero la diferencia es que la base de datos puede comprender el contenido de Value) | El par clave-valor correspondiente a clave-valor, el valor son datos estructurados | Los requisitos de la estructura de datos no son estrictos y la estructura de la tabla es variable. No es necesario predefinir la estructura de la tabla como una base de datos relacional. | El rendimiento de las consultas no es alto y falta una sintaxis de consulta unificada. | Sofá DB, Mongo Db |
| Base de datos de gráficos (gráfico) | Redes sociales, sistemas de recomendación, etc. Centrarse en la construcción de gráficos de relaciones. | estructura grafica | Utilice algoritmos relacionados con la estructura del gráfico. Por ejemplo, direccionamiento por ruta más corta, búsqueda de relaciones de N grados, etc. | Muchas veces es necesario calcular el gráfico completo para obtener la información requerida y esta estructura no es adecuada para soluciones de clúster distribuido. | Neo4J, cuadrícula de información, gráfico infinito |
1. Base de datos distribuida