现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。
Now everything is for the future of dream weaving wings, let the dream fly in reality.
Haga clic para ingresar al directorio de series de artículos.
Habilidades avanzadas en diseño de arquitectura de sistemas·Composición y estructura de ordenadores
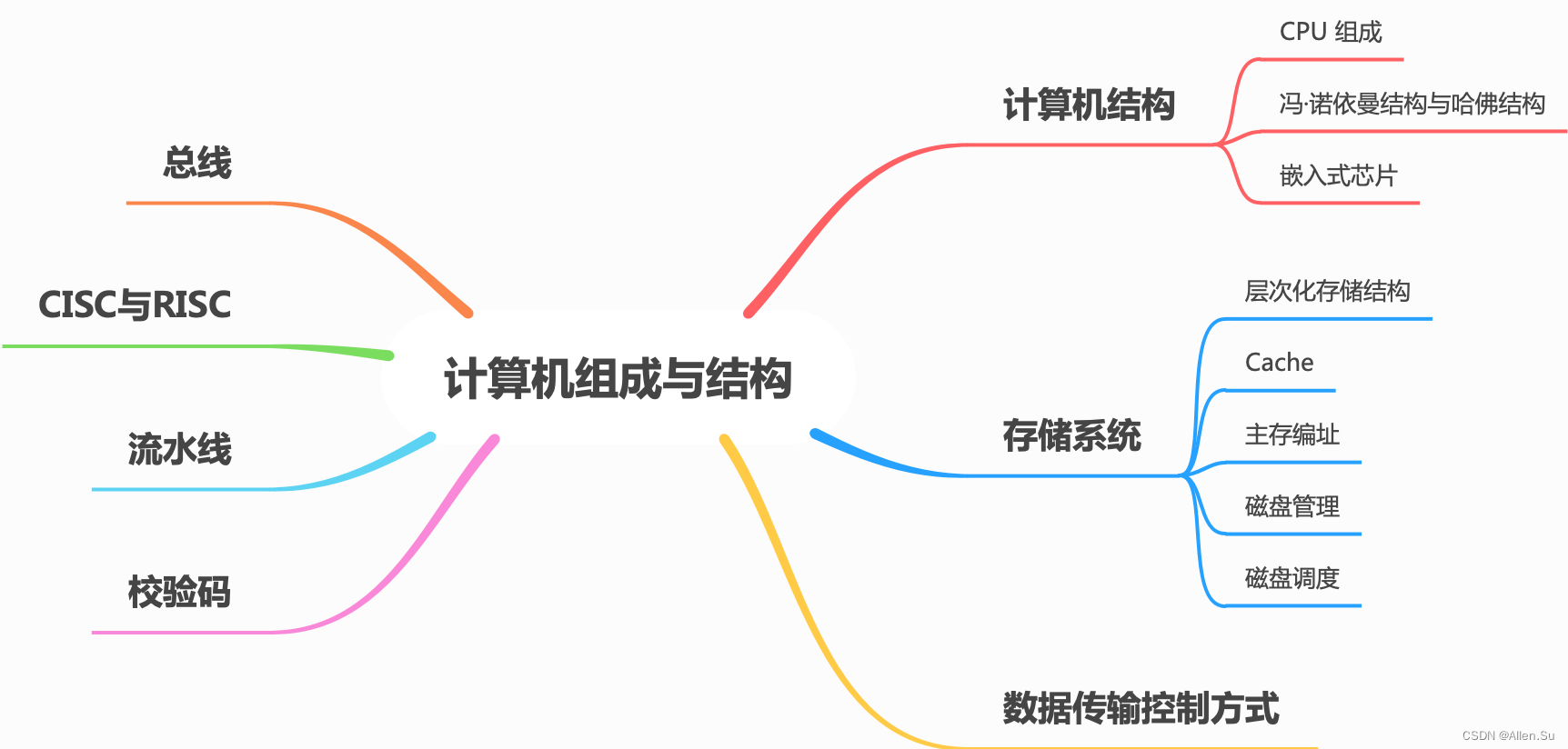
1. Estructura informática
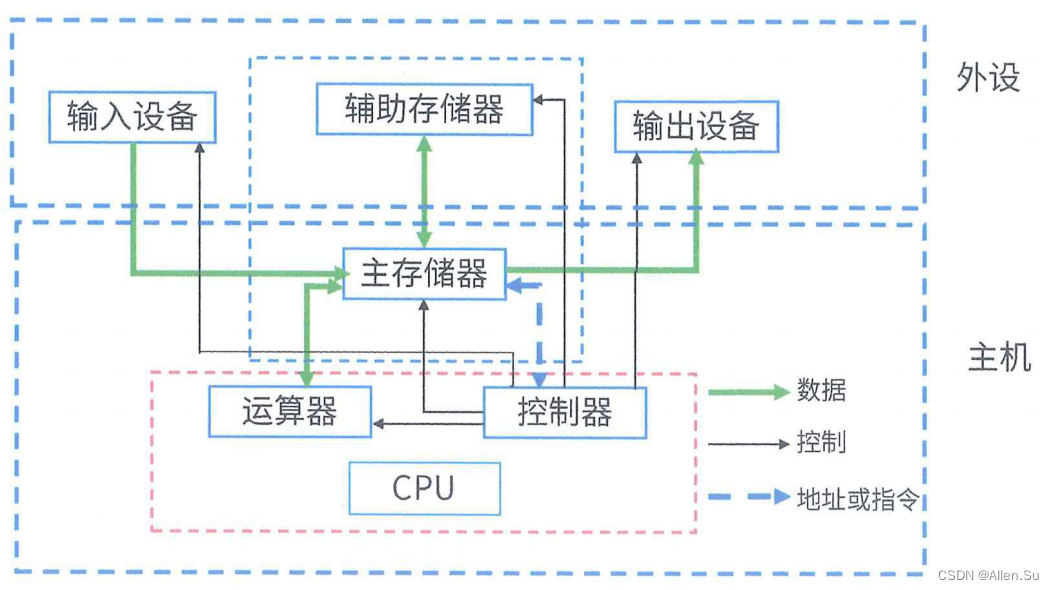
1.1 composición de la CPU
-
Operador
① Unidad lógica aritmética ALU: operaciones aritméticas y operaciones lógicas con datos
② Registro de acumulación AC: registro de propósito general, que proporciona un área de trabajo para ALU para el almacenamiento temporal de datos
③ Registro de búfer de datos DR: almacenamiento temporal de instrucciones o datos al escribir en la memoria
④Registro de condición de estado PSW: almacena indicadores de estado y indicadores de control (controversia: algunos también lo clasifican como controlador) -
Controlador
① Contador de programa PC: almacena la dirección de la siguiente instrucción a ejecutar
② Registro de instrucciones IR: almacena la instrucción a ejecutar
③ ID del decodificador de instrucciones: analiza e interpreta el campo de código de operación en la instrucción
④ Componente de temporización: proporciona señales de control de temporización
1.2 Estructura de Von Neumann y estructura de Harvard
-
Estructura de von Neumann
La estructura de von Neumann, también conocida como estructura de Princeton, es una estructura de memoria que combina memoria de instrucciones de programa y memoria de datos
.
Características:
(1) Generalmente utilizado en procesadores de PC, como los procesadores I3, I5 e I7
(2) Las instrucciones y la memoria de datos se fusionan
(3) Las instrucciones y los datos se transmiten a través del mismo bus de datos -
Arquitectura de Harvard
La arquitectura de Harvard es una estructura de memoria que separa el almacenamiento de instrucciones del programa y el almacenamiento de datos. La arquitectura Harvard es una
arquitectura paralela, su característica principal es almacenar programas y datos en diferentes espacios de almacenamiento, es decir, la
memoria de programa y
Características:
(1) Generalmente utilizado en procesadores de sistemas integrados (DSP) procesamiento de señales digitales (DSP, procesamiento de señales digitales) (2) Las
instrucciones y los datos se almacenan por separado y se pueden leer en paralelo, con una alta tasa de rendimiento de datos
(3) Allí Hay 4 buses: bus de datos y bus de direcciones para instrucciones y datos.
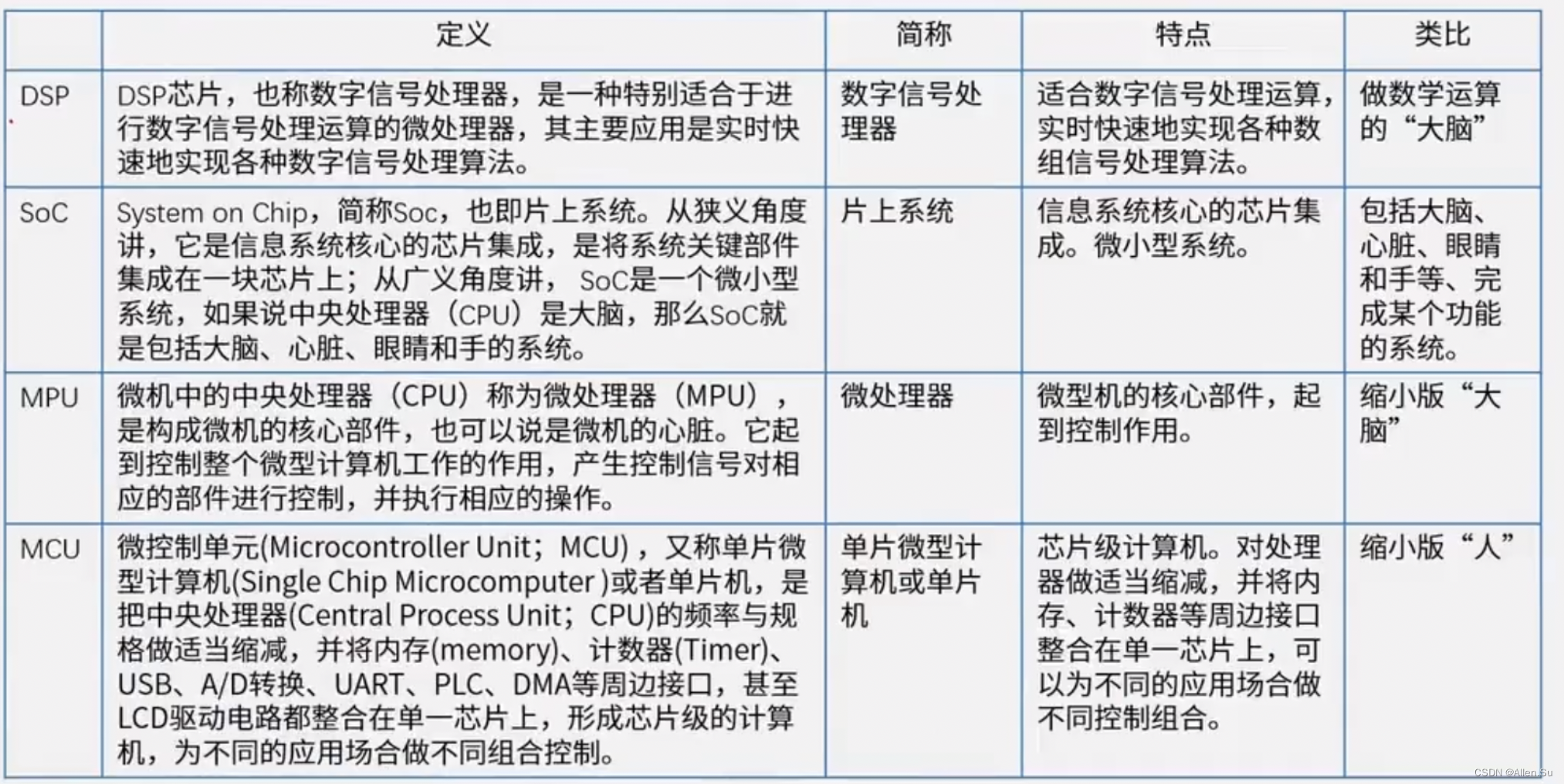
1.3 chip integrado
2. Sistema de almacenamiento
2.1 Estructura de almacenamiento jerárquica
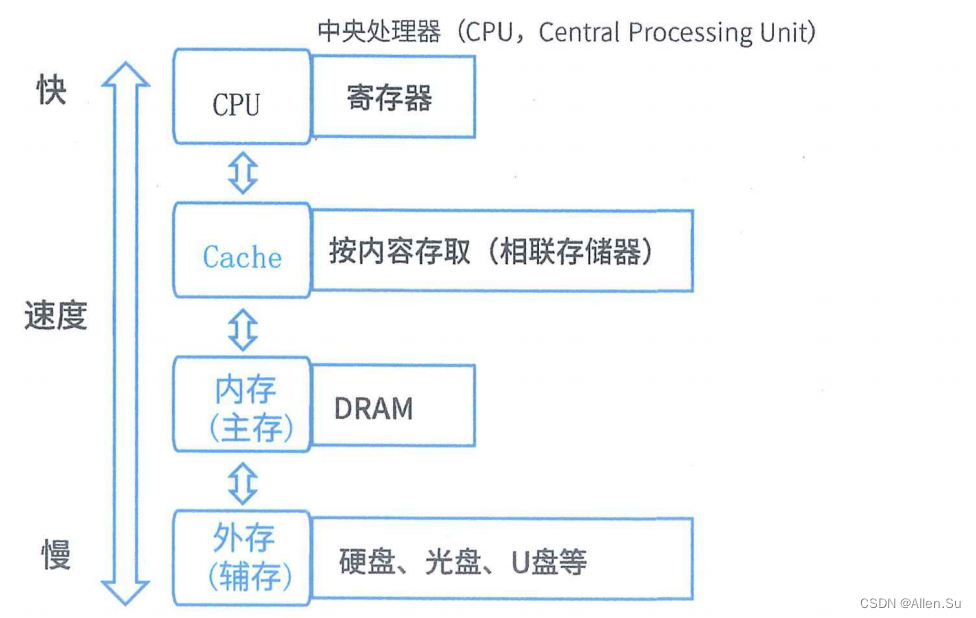
2.2 Caché
-
La función de caché: mejora la velocidad de entrada y salida de datos de la CPU y rompe el cuello de botella de von Neumann, es decir, el límite de ancho de banda de transmisión de datos entre la CPU y el sistema de almacenamiento.
-
En el sistema del sistema de almacenamiento informático, la caché es la capa con la velocidad de acceso más rápida.
-
El caché es transparente para los programadores.
-
La base para utilizar Cache para mejorar el rendimiento del sistema es el principio de localidad del programa.
localidad temporal
localidad espacial -
Localidad temporal : una vez que se ejecuta una instrucción en el programa, la instrucción puede volver a ejecutarse pronto. La razón típica es que hay una gran cantidad de operaciones de bucle en el programa.
-
Localidad espacial : Una vez que un programa accede a una determinada unidad de almacenamiento, pronto también se accederá a sus unidades de almacenamiento cercanas, es decir, las direcciones visitadas por el programa dentro de un período de tiempo pueden concentrarse en un cierto rango. Una situación típica es que la programa Ejecutado secuencialmente.
-
Teoría de conjuntos de trabajo : el conjunto de trabajo es una colección de páginas a las que se accede con frecuencia cuando se ejecuta un proceso.
ejemplo:
inti, j, s=0, n=10000;
for(i=1; i<=n; i++)
for(j=1; j<=n; j++)
s+=j;
printf("结果为:%d", s) ;
Si h representa la tasa de aciertos de acceso al caché, t1 representa el tiempo del ciclo del caché y t2 representa el tiempo del ciclo de la memoria principal. Tomando la operación de lectura como ejemplo, el ciclo promedio del sistema que usa "Caché + memoria principal" es t3 , entonces: t3
= hx t1+(1 - h) × t2
donde (1 - h) también se llama tasa de fallas (tasa de fallas)
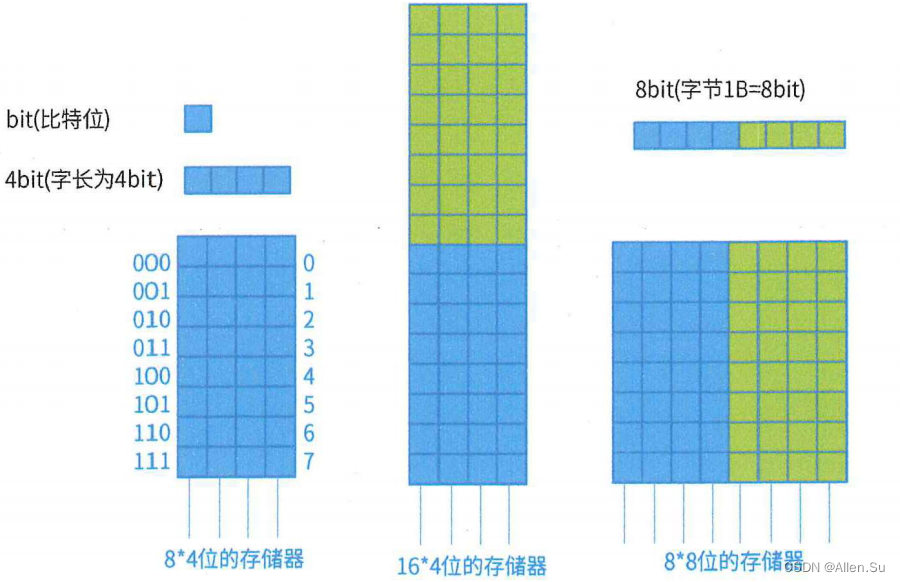
2.3 Direccionamiento de la memoria principal
-
Unidad de almacenamiento
número de unidades de almacenamiento = dirección máxima - dirección mínima + 1 -
El contenido direccionado
se direcciona por palabra: la unidad de almacenamiento del banco de memoria es una unidad de almacenamiento de palabras, es decir, la unidad mínima de direccionamiento es una palabra. Direccionado por byte:
la unidad de almacenamiento del banco de memoria es una unidad de almacenamiento de bytes, es decir , la unidad mínima de direccionamiento es un byte. -
Capacidad total = número de unidades de almacenamiento * contenido de direcciones
-
Según la capacidad requerida de la memoria y la capacidad del chip de memoria seleccionado, se puede calcular el número total de chips necesarios, es decir:
número total de chips = capacidad total / capacidad de cada chip
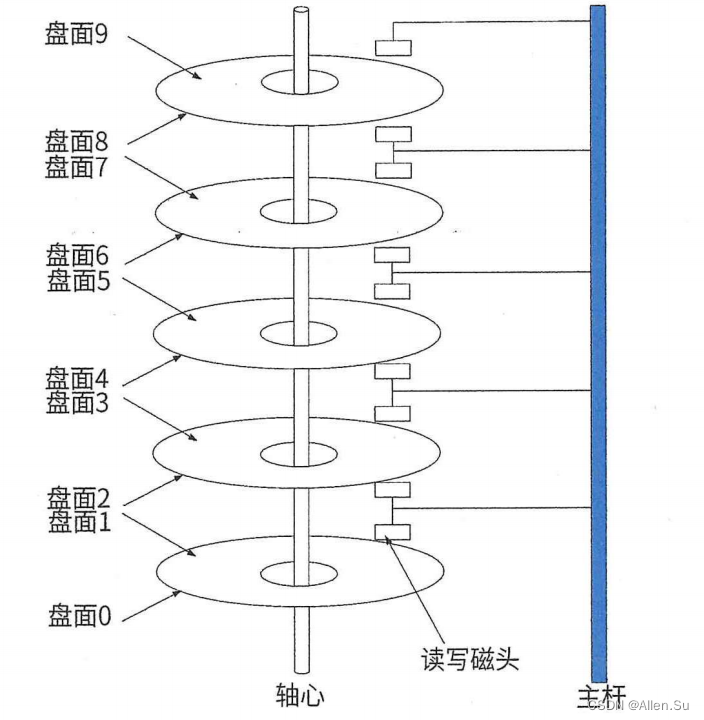
2.4 Gestión de discos

Tiempo de acceso = tiempo de búsqueda + tiempo de espera
El tiempo de búsqueda se refiere al tiempo que tarda el cabezal magnético en moverse a la pista, el
tiempo de espera es el tiempo que tardan los sectores que esperan ser leídos y escritos en moverse debajo del cabezal magnético.
El tiempo para leer los datos del disco debe incluir las siguientes tres partes:
(1) El tiempo para encontrar la pista.
(2) El tiempo para encontrar un bloque (sector, es decir, el tiempo de retardo de rotación.
(3) Tiempo de transmisión.
-
¿duda? ? :
Tiempo de acceso = tiempo de búsqueda + tiempo de espera (tiempo promedio de posicionamiento + retraso de rotación) Creo que hay un problema con esta fórmula.
Creo que debería ser: tiempo de acceso = tiempo de búsqueda + retardo de rotación + tiempo para almacenar (o recuperar) el contenido del sector del disco,
si lo dicho arriba es correcto, ¿cómo debemos entenderlo?, si es incorrecto, ¿dónde está el error? -
El tiempo de acceso promedio se refiere al tiempo promedio que le toma al cabezal magnético encontrar los datos especificados.
El tiempo de acceso promedio se refiere al tiempo promedio que le toma al cabezal del disco encontrar los datos especificados. Generalmente es la suma del tiempo de búsqueda promedio del disco duro y la latencia promedio (tiempo de espera). El tiempo de acceso promedio representa mejor el tiempo que le toma al disco duro encontrar ciertos datos. Cuanto menor sea el valor, mejor. -
Tiempo promedio de acceso = tiempo promedio de búsqueda + tiempo promedio de espera
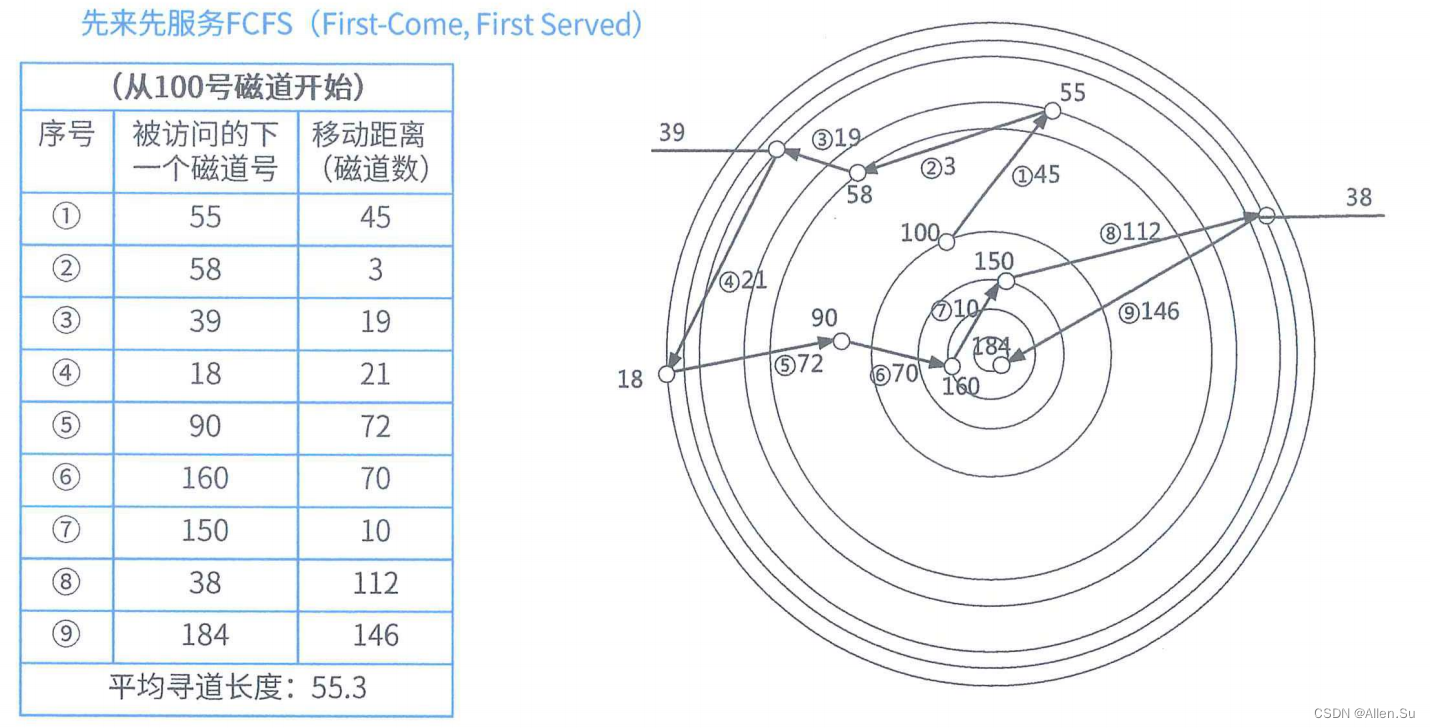
2.5 Programación de disco
- Por orden de llegada (FCFS)
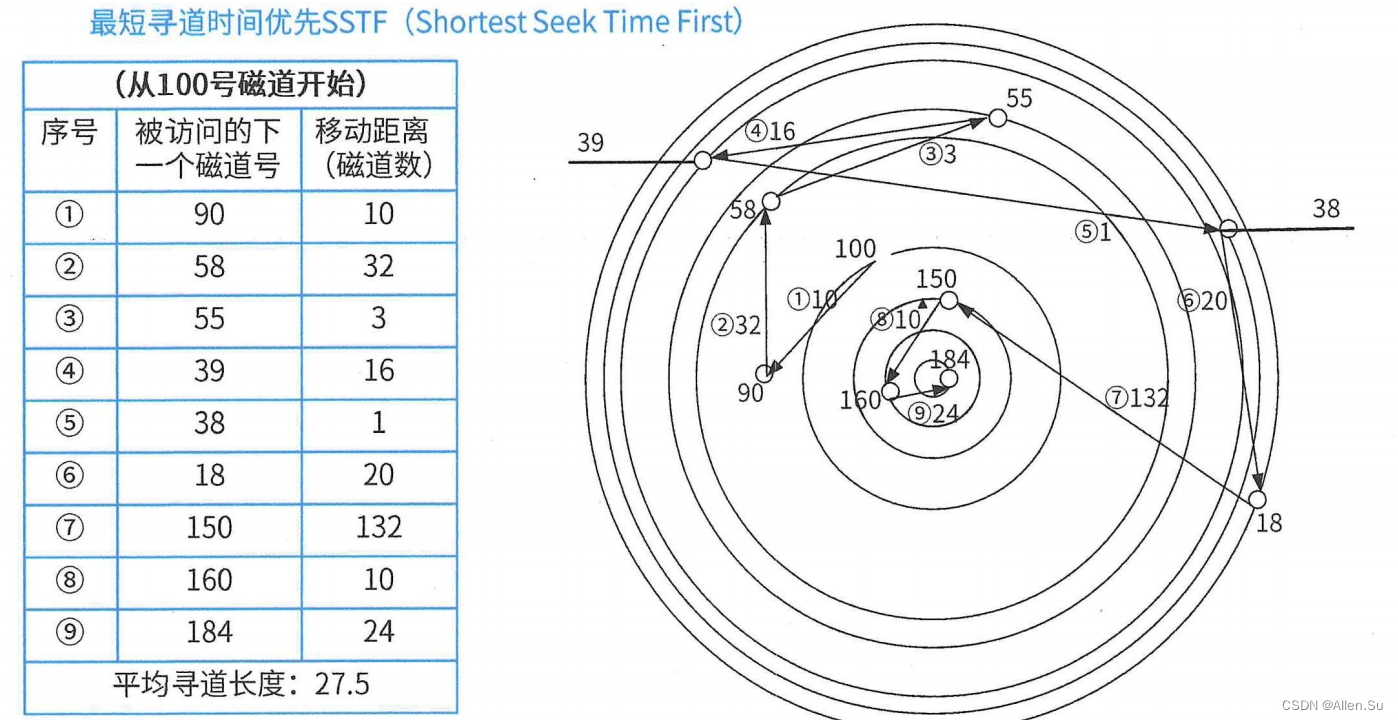
- Tiempo de búsqueda más corto primero (SSTF)
- Algoritmo de escaneo (SCAN)
- Algoritmo de escaneo circular (CSCAN)
3. Método de control de la transmisión de datos

4. autobús
- Un bus permite que solo un dispositivo envíe al mismo tiempo, pero permite que varios dispositivos reciban. Entonces el bus está en modo semidúplex.
- Medio dúplex y dúplex completo
- Bus serie y bus paralelo
Clasificación de autobuses:
- Bus de datos (DataBus, DB): transfiere datos que deben procesarse o almacenarse entre la CPU y la RAM.
- Bus de direcciones (AB): se utiliza para especificar la dirección de los datos almacenados en la RAM (memoria de acceso aleatorio).
- Bus de Control (CB): transmite señales desde la unidad de control por microprocesador (Control Unit) a dispositivos periféricos. excelente
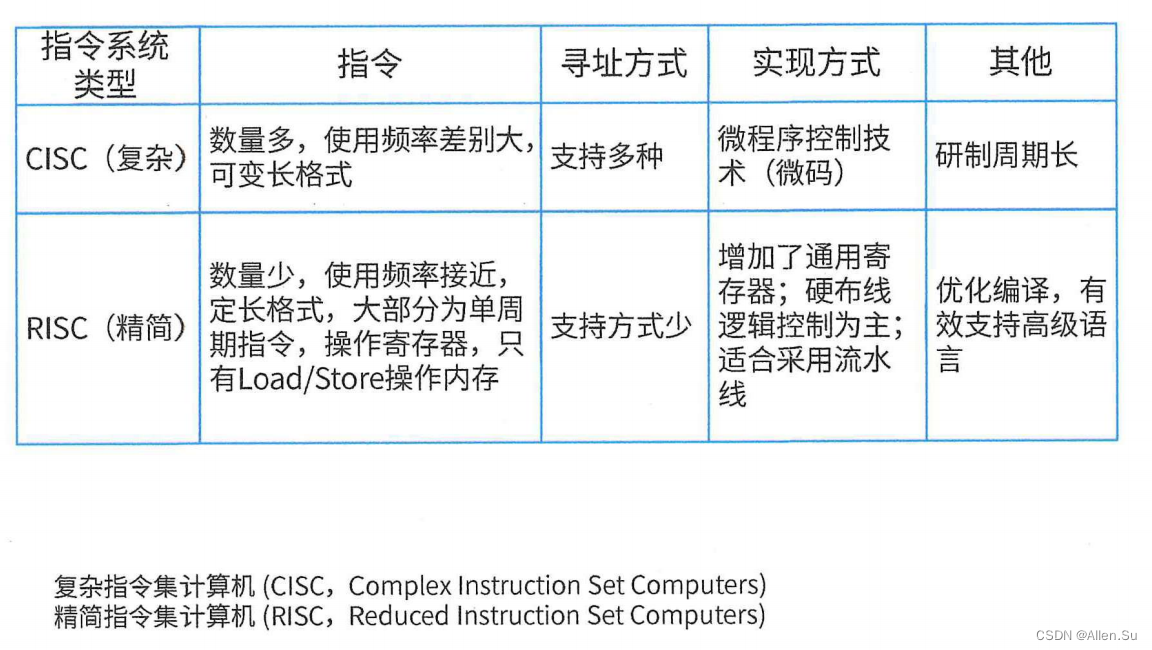
5. CISC y RISC
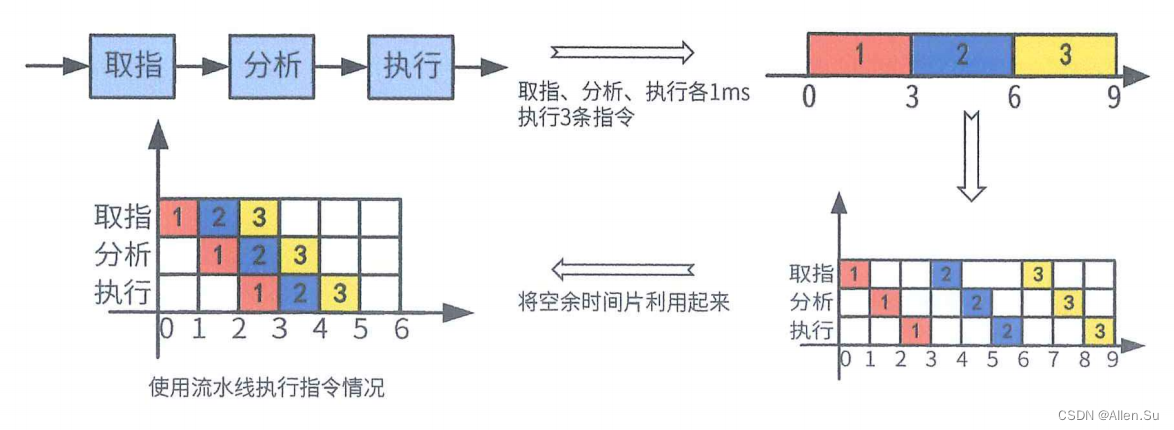
6. Línea de montaje
- Cálculo de parámetros relevantes: cálculo del tiempo de ejecución de la tubería, tasa de rendimiento de la tubería, índice de aceleración de la tubería, etc.
- Pipelining se refiere a una tecnología de implementación de procesamiento casi paralelo en la que múltiples instrucciones se superponen durante la ejecución del programa.
El procesamiento simultáneo de varios componentes es para diferentes instrucciones. Pueden trabajar en diferentes partes de múltiples instrucciones al mismo tiempo para mejorar la utilización de cada componente y la velocidad promedio de ejecución de las instrucciones.
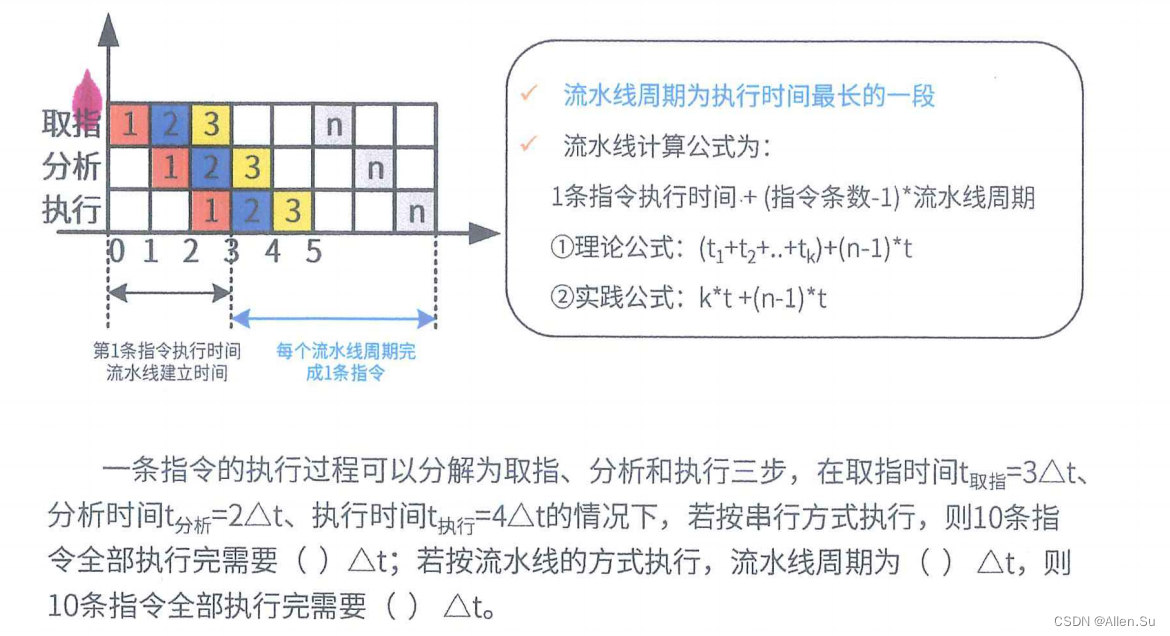
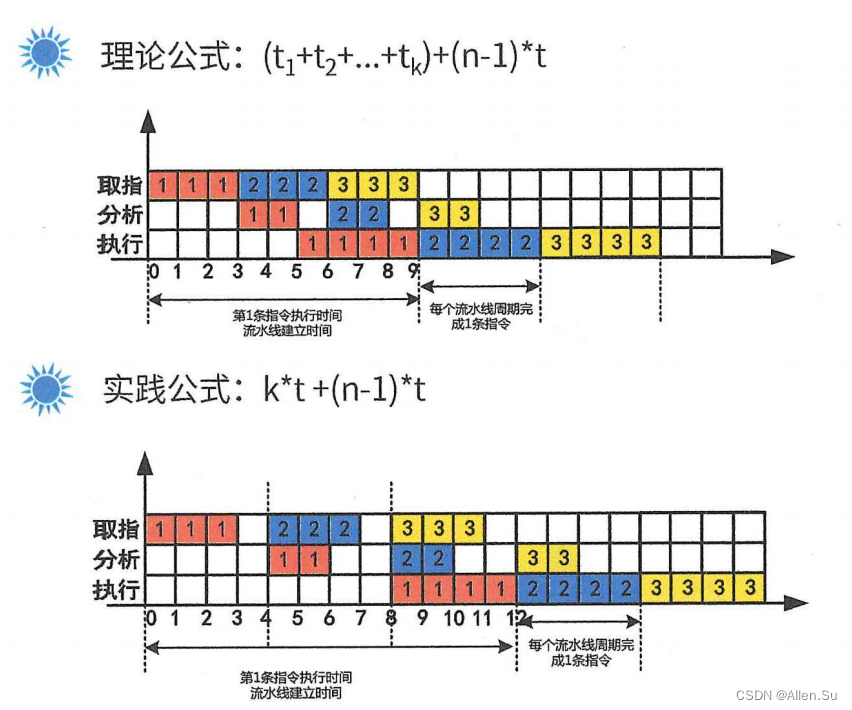

Cálculo de aceleración de la tubería:

7. Verificar código
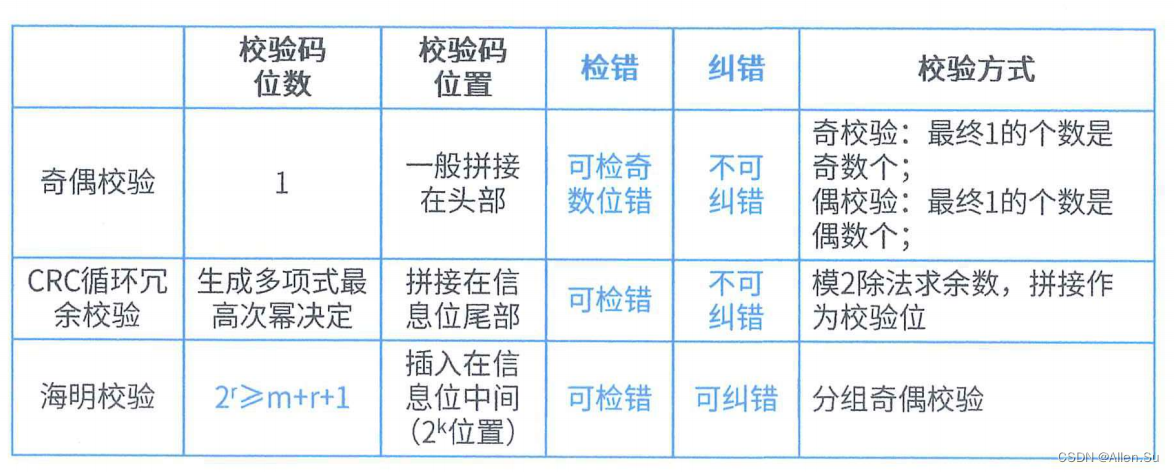
7.1 Verificación de paridad
-
El método de codificación del código de verificación de paridad es: un código de verificación se compone de varios bits de información válida (como un byte) más un bit binario (bit de verificación).
-
Paridad impar: el número de "1" en todo el código de verificación (bits de información válida y bits de verificación) es un número impar.
Paridad par: el número de "1" en todo el código de verificación (bits de información válida y bits de verificación) es un número par. -
La verificación de paridad puede detectar errores de 1 bit y no se puede corregir.
7.2 Código de verificación cíclica CRC
Comprobación CRC, error detectable pero no corregible.
Verificación de redundancia cíclica (CRC, verificación de redundancia cíclica)
-
El método de codificación de CRC es: empalmar un código de verificación de r bits después de un código de información de k bits. La clave para aplicar el código CRC es cómo obtener fácilmente el bit de verificación (codificación) de r bits a partir de los bits de información de k bits y cómo determinar si hay un error a partir del código de información de k + r bits.
-
Las reglas de codificación del código de verificación de redundancia cíclica son las siguientes:
① Expresar la información efectiva de N bits a codificar como polinomio M(X);
② Desplazar M(X) a la izquierda en K bits para obtener M(X)×XK, que son K bits libres para ensamblar el resto de K bits (es decir, dígito de control);
③Seleccione un bit K+1 que genere el polinomio G(X) y divida M(X)×XK módulo 2;
④Desplace hacia la izquierda K bits La información válida y el resto R (X) se suman y restan en módulo 2 y se concatenan en un código CRC. En este momento, el código CRC tiene un total de N + K bits. -
Utilice el polinomio generador acordado G(X) para dividir el código CRC recibido. Si es correcto, el resto será 0; si un determinado bit es incorrecto, el resto no será 0
. Diferentes errores de bits dan como resultado restos diferentes y existe una correspondencia única entre el resto y el número de secuencia de bits de error.
¿Qué es la división de módulo 2 y en qué se diferencia de la división ordinaria?
La división de módulo 2 se refiere a la división en la que el acarreo no se considera durante la operación de división.
Por ejemplo, la división módulo 2 de 10111 por 110 es:

