Estimación de la pose humana en 3D con análisis de papel de transformadores espaciales y temporales
Enlace del artículo: Estimación de la pose humana en 3D con transformadores espaciales y temporales
Código del artículo: https://github.com/zczcwh/PoseFormer
Fuente del artículo: ICCV 2021
Unidad del artículo: Universidad de Florida Central, EE. UU.
Resumen
- La arquitectura Transformer se ha convertido en el modelo elegido en el procesamiento del lenguaje natural y ahora se está introduciendo en tareas de visión por computadora como la clasificación de imágenes, la detección de objetos y la segmentación semántica.
- Sin embargo, en el campo de la estimación de la pose humana, las arquitecturas convolucionales todavía dominan.
- En este trabajo, presentamos PoseFormer , un método puramente basado en Transformer para la estimación de pose humana 3D en videos que no involucra arquitecturas convolucionales .
- Inspirándonos en el último desarrollo de Transformers visuales, diseñamos una estructura Transformer espacio-temporal para modelar de manera integral las relaciones de las articulaciones humanas dentro de cada cuadro y la correlación temporal entre cuadros, y luego generamos la pose humana 3D precisa del cuadro central.
- Evaluamos nuestro método cuantitativa y cualitativamente en dos conjuntos de datos de referencia estándar y populares: Human3.6M y MPI-INF-3DHP . Amplios experimentos muestran que PoseFormer logra un rendimiento de vanguardia en ambos conjuntos de datos.
1. Introducción
- La estimación de la postura humana (HPE) tiene como objetivo localizar articulaciones y construir representaciones corporales (por ejemplo, posiciones de los huesos) a partir de datos de entrada, como imágenes y vídeos.
- HPE proporciona información geométrica y de movimiento del cuerpo humano, que se puede utilizar en una amplia gama de aplicaciones (como interacción persona-computadora, análisis de movimiento, atención médica).
- El trabajo actual se puede dividir aproximadamente en dos categorías: (1) métodos de estimación directa, (2) métodos de elevación de 2D a 3D .
- Los métodos de estimación directa infieren poses humanas en 3D a partir de imágenes o fotogramas de vídeo en 2D sin la necesidad de una estimación intermedia de representaciones de poses en 2D.
- Los métodos de elevación de 2D a 3D infieren posturas humanas en 3D a partir de posturas 2D estimadas intermedias.
- Gracias al excelente rendimiento de los detectores de postura 2D de última generación, los métodos de elevación de 2D a 3D a menudo superan a los métodos de estimación directa.
- Sin embargo, estas asignaciones de pose 2D a 3D no son triviales; debido al desenfoque de profundidad y la oclusión, la misma pose 2D puede generar una variedad de poses 3D potenciales.
- Para aliviar estos problemas y mantener la coherencia natural, muchos trabajos recientes integran información temporal de videos en sus métodos. Sin embargo, los métodos basados en CNN a menudo se basan en técnicas de dilatación con una conectividad temporal inherentemente limitada, mientras que las redes recurrentes están limitadas principalmente por correlaciones secuenciales simples.
- Recientemente, Transformer se ha convertido en el modelo de facto para el procesamiento del lenguaje natural (NLP) debido a su eficiencia, escalabilidad y potentes capacidades de modelado. Gracias al mecanismo de autoatención de Transformer, se pueden capturar claramente las correlaciones globales entre largas secuencias de entrada. Esto lo hace particularmente adecuado para la arquitectura de problemas de datos de secuencia y, por lo tanto, se extiende naturalmente a 3D HPE.
- Con su conectividad y expresión integrales, Transformer brinda la oportunidad de aprender representaciones temporales más sólidas en todos los fotogramas.
- Sin embargo, investigaciones recientes muestran que los Transformers requieren un diseño específico para lograr un rendimiento comparable al de sus homólogos de CNN en tareas de visión. Específicamente, a menudo requieren conjuntos de datos de entrenamiento muy grandes o, si se aplican a conjuntos de datos más pequeños, un aumento y una regularización de datos mejorados.
- Además, los transformadores de visión existentes se limitan principalmente a la clasificación de imágenes, la detección de objetos y la segmentación, pero aún no está claro cómo aprovechar la potencia de los transformadores para HPE 3D.
- Para responder a esta pregunta, primero aplicamos el transformador directamente al HPE de elevación 2D a 3D. En este caso, tratamos toda la pose 2D de cada cuadro en una secuencia determinada como una ficha (Figura 1 (a)). Si bien este enfoque básico es efectivo hasta cierto punto, ignora la distinción natural de las relaciones espaciales (junta a articulación).
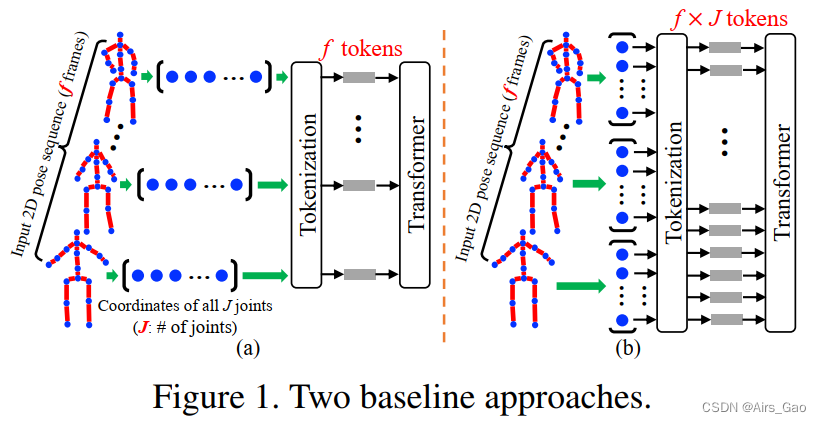
- Una extensión natural de esta línea de base es tratar cada coordenada conjunta 2D como un token, proporcionando una entrada que consiste en estas uniones en todos los fotogramas de la secuencia (Figura 1(b)). Sin embargo, en este caso, la cantidad de tokens aumenta cada vez más cuando se utilizan secuencias de fotogramas largas (en 3D HPE, con un máximo de 243 fotogramas por fotograma y 17 uniones como común, el número de tokens será 243× 17=4131) . Dado que Transformer calcula la atención directa de cada token a otro token, los requisitos de memoria del modelo se acercan a niveles irrazonables.
- Por lo tanto, como una solución efectiva a estos desafíos, proponemos PoseFormer, la primera red Transformer pura para levantamiento de HPE de 2D a 3D en videos .
- PoseFormer modela directamente los aspectos espaciales y temporales utilizando diferentes módulos Transformer en dos dimensiones .
- PoseFormer no solo produce representaciones sólidas entre elementos espaciales y temporales, sino que tampoco produce grandes recuentos de tokens para secuencias de entrada largas.
- En un nivel alto, PoseFormer simplemente extrae una secuencia de poses 2D detectadas de un estimador de poses 2D disponible en el mercado y genera la pose 3D del cuadro central .
- Más específicamente, construimos un módulo Transformer espacial para codificar las relaciones locales entre uniones 2D en cada cuadro. La capa de autoatención espacial considera la información de posición de las uniones bidimensionales y devuelve la representación de características latentes del marco. A continuación, nuestro módulo Transformador temporal analiza las dependencias globales entre cada representación de características espaciales y genera estimaciones de pose 3D precisas.
- Las evaluaciones experimentales en dos puntos de referencia 3D HPE populares (Human3.6M y MPI-INF-3DHP) muestran que PoseFormer logra un rendimiento de vanguardia en ambos conjuntos de datos. Comparamos nuestras poses 3D estimadas con el método SOAT y descubrimos que
PoseFormer produce resultados más fluidos y confiables. Además, en el estudio de ablación se proporcionan visualización y análisis de los mapas de atención de PoseFormer para comprender el funcionamiento interno del modelo y demostrar su eficacia. - Nuestras contribuciones son triples:
(1) Proponemos el primer modelo PoseFormer puramente basado en Transformer para el levantamiento de 2D a 3D de HPE 3D.
(2) Diseñamos un modelo Transformer espacio-temporal eficaz, donde el módulo Transformer espacial codifica las relaciones locales entre las articulaciones del cuerpo humano, mientras que el módulo Transformer temporal captura las dependencias globales entre fotogramas en toda la secuencia.
(3) Nuestro modelo PoseFormer logra efectos SOAT en los conjuntos de datos Human3.6M y MPI-INF-3DHP.
2. Trabajos relacionados
- Aquí, resumimos específicamente el método HPE de vista única de una sola persona en 3D .
- Método de estimación directa : infiere la pose humana en 3D a partir de imágenes en 2D sin la necesidad de una estimación intermedia de la representación de la pose en 2D.
- Método de elevación de 2D a 3D : utilizar la pose 2D como entrada para generar la pose 3D correspondiente, este es el más popular entre los métodos más recientes en este campo. Cualquier estimador de pose 2D disponible en el mercado es efectivamente compatible con estos métodos.
2.1 Elevación HPE de 2D a 3D
- Los métodos de elevación de 2D a 3D utilizan poses 2D estimadas a partir de imágenes de entrada o fotogramas de vídeo.
- OpenPose, CPN, AlphaPose y HRNet se utilizan ampliamente como detectores de pose 2D.
- A partir de esta representación intermedia, se pueden utilizar diversos métodos para generar poses 3D.
- Sin embargo, los métodos de última generación anteriores se basan en convoluciones temporales dilatadas para capturar dependencias globales, que están limitadas en conexiones temporales.
- Además, la mayoría de estos trabajos utilizan operaciones simples para proyectar coordenadas de articulaciones en un espacio latente sin considerar la correlación cinemática de las articulaciones humanas.
2.2 GNN en 3D HPE
- Naturalmente, la postura humana se puede representar como un gráfico, donde las articulaciones son nodos y los huesos son bordes.
- Las redes neuronales gráficas (GNN) también se han aplicado al problema de elevación de poses de 2D a 3D y han proporcionado un buen rendimiento.
- Para nuestro PoseFormer, el transformador puede verse como un tipo de GNN con operaciones gráficas únicas y, a menudo, ventajosas.
- Específicamente, un módulo codificador de transformador forma esencialmente un gráfico completamente conectado donde los pesos de los bordes se calculan utilizando la autoatención de múltiples cabezales condicional de entrada.
- La operación también incluye la normalización de las características de los nodos, agregadores de retroalimentación a través de las salidas del cabezal de atención y conexiones residuales que permiten un escalado eficiente de capas apiladas.
- Estas operaciones son ventajosas en comparación con otras operaciones de gráficos. Por ejemplo, la fuerza de las conexiones entre nodos está determinada por el mecanismo de autoatención del transformador, en lugar de estar predefinida como es típico a través de la matriz de adyacencia.
- La receta basada en gcn utilizada en esta tarea. Esto le da al modelo la flexibilidad de ajustar la importancia relativa de las articulaciones en función de cada postura de entrada.
- Además, los componentes integrados de escalado y normalización del transformador pueden ser beneficiosos para mitigar los efectos de suavizado excesivo que afectan a muchas variantes operativas de GNN cuando se apilan varias capas juntas.
2.3 Transformadores de visión
- Recientemente, ha surgido un interés en aplicar Transformers a tareas de visión.
- DEtection TRansformer (DETR) se utiliza para la detección de objetivos y la segmentación panorámica.
- Vision Transformer (ViT) , una arquitectura Transformer pura, logra el rendimiento de SOAT en la clasificación de imágenes.
- Transpose , basado en la arquitectura Transformer, estima poses 3D a partir de imágenes.
- MEsh TRansfOrmer combina CNN con la red Transformer para reconstruir poses 3D y vértices de malla a partir de una sola imagen.
- La arquitectura Transformer espaciotemporal de nuestro método explota la correlación de puntos clave en cada cuadro y preserva la consistencia temporal natural en el video.
3. Método
- Canalización : obtenga la pose 2D de cada cuadro a través de un detector de pose 2D disponible en el mercado, use la secuencia de pose 2D de cuadros consecutivos como entrada y estime la pose 3D del cuadro central.
3.1 Línea Base del Transformador Temporal
- Como aplicación básica del levantamiento de 2D a 3D, tratamos cada pose 2D como un token de entrada y utilizamos un transformador para capturar las dependencias globales entre las entradas, como se muestra en la Figura 2(a).
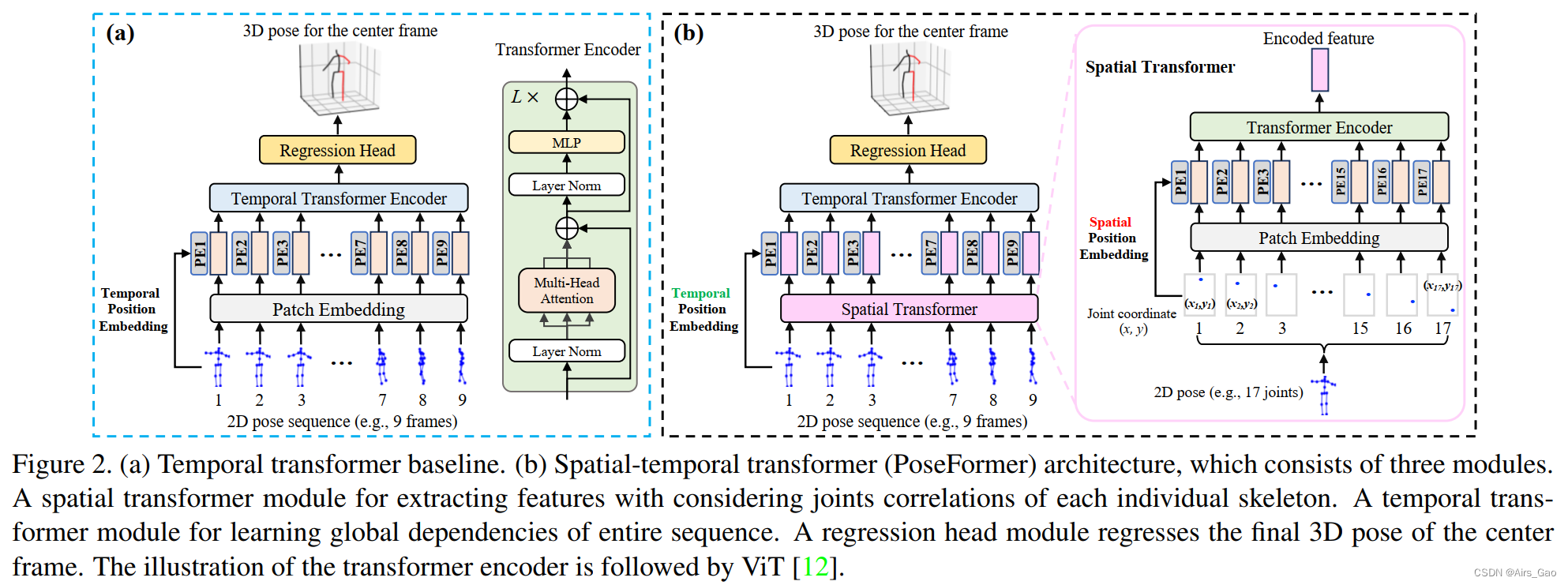
- Llamaremos parche a cada token de entrada, similar en terminología a ViT.
- Para la secuencia de entrada X∈R^(f×(J·2)), f es el número de fotogramas de la secuencia de entrada, J es la pose 2D del número de uniones en cada fotograma y 2 representa las coordenadas de la articulaciones en el espacio 2D.
- La incrustación de parches es una capa de proyección lineal entrenable que incrusta cada parche en características de alta dimensión.
- Las redes de transformadores utilizan incrustaciones posicionales para preservar la información posicional de las secuencias.
- La autoatención es la función principal de Transformer, que asocia diferentes posiciones de la secuencia de entrada con funciones integradas.
- Nuestro codificador Transformer consta de bloques de autoatención de múltiples cabezales y bloques de perceptrón multicapa (MLP). LayerNorm se aplica antes de cada bloque y las conexiones restantes se aplican después de cada bloque.
- Para predecir la pose tridimensional del cuadro central, la salida del codificador Y∈R f×C se reduce a un vector y∈R 1×C promediando las dimensiones del cuadro . Finalmente, un bloque MLP hace una regresión de la salida a y∈R 1×(J*3) , la pose 3D del marco central.
3.2 PoseFormer: Transformador espacio-temporal
- Observamos que la línea base del Temporal Transformer se centra principalmente en las dependencias globales entre fotogramas en la secuencia de entrada. Utilice la incrustación de parches de transformación lineal para proyectar coordenadas conjuntas en la dimensión oculta.
- Sin embargo, dado que una capa de proyección lineal simple no puede aprender información de atención, la información de movimiento entre las coordenadas de las articulaciones locales no está fuertemente representada en la línea base temporal del Transformador.
- Una posible solución es tratar cada coordenada conjunta como un parche separado y alimentar todas las uniones de los marcos como entrada al Transformador (consulte la Figura 1(b)).
- Sin embargo, el número de parches aumentará rápidamente (el número de fotogramas f multiplicado por el número de uniones J), lo que dará como resultado una complejidad computacional del modelo de O((f·J)2).
- Para aprender eficazmente las correlaciones conjuntas locales, utilizamos dos transformadores separados para información espacial y temporal respectivamente .
- Como se muestra en la Figura 2 (b), PoseFormer consta de tres módulos: módulo de transformador espacial, módulo de transformador temporal y módulo de cabezal de regresión .
Módulo transformador espacial
- El módulo de transformador espacial extrae incorporaciones de características de alta dimensión de un solo marco. Dada una pose 2D con juntas J, tratamos cada junta (es decir, dos coordenadas) como un parche y realizamos la extracción de características entre todos los parches de acuerdo con un proceso de transformación visual común.
- Primero, asignamos las coordenadas de cada articulación en un espacio de alta dimensión utilizando una proyección lineal entrenable, lo que se denomina incrustación de parches espaciales.
Módulo transformador temporal
- Dado que el módulo transformador espacial codifica características de alta dimensión para cada cuadro individual, el módulo transformador temporal tiene como objetivo modelar dependencias en una secuencia de cuadros.
- Antes del módulo transformador temporal, agregamos una incrustación de posición temporal que se puede aprender para preservar la información de posición del marco.
- Para el codificador del Módulo transformador temporal, adoptamos la misma arquitectura que el codificador del Módulo transformador espacial, que consta de bloques de autoatención de múltiples cabezales y bloques MLP.
- La salida del módulo transformador secuencial es Y∈R f*(J*c) .
Cabeza de regresión
- Dado que utilizamos un conjunto de secuencias de fotogramas para predecir la pose 3D del fotograma central, la salida del módulo transformador temporal Y∈R f*(J·c) debe simplificarse a y∈R 1*(J·c) .
- Logramos esto aplicando una operación de promedio ponderado (usando pesos aprendidos) sobre la dimensión del marco.
- Finalmente, un bloque MLP simple con norma de capa y una capa lineal devuelve la salida y∈R 1*(J·3) , que es la pose 3D prevista del cuadro central.
Función de pérdida
- Para entrenar nuestro modelo de transformación espaciotemporal, utilizamos la pérdida estándar MPJPE (error medio por posición conjunta) para minimizar el error entre el valor predicho y la verdad fundamental planteada como
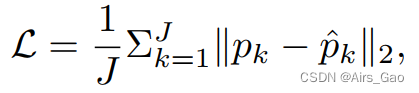
4. Conjunto de datos
4.1 Humano3.6M
- Human3.6M es el conjunto de datos de interiores más utilizado para HPE 3D unipersonal .
- 11 actores profesionales realizan 17 acciones como sentarse, caminar y hablar por teléfono.
- Cada sujeto fue grabado en video desde 4 ángulos diferentes en un ambiente interior.
- Este conjunto de datos contiene 3,6 millones de fotogramas de vídeo con anotaciones reales en 3D capturadas mediante un sistema preciso de captura de movimiento basado en marcadores.
- Según el trabajo anterior, adoptamos la misma configuración experimental: las 15 acciones se utilizan para entrenamiento y prueba, el modelo se entrena en 5 secciones (S1, S5, S6, S7, S8) y se prueba en 2 secciones (S9 y S11). .
4.2 MPI-INF-3DHP
- MPI-INF-3DHP es un conjunto de datos de pose 3D más desafiante.
- Contiene escenas interiores restringidas y escenas exteriores complejas.
- Son 8 actores que realizan 8 acciones, desde 14 vistas de cámara, abarcando una mayor diversidad de poses.
- MPI-INF-3DHP proporciona conjuntos de prueba para 6 escenarios diferentes.
5. Indicadores de evaluación
- MPJPE : Error medio de posición por articulación, error de posición promedio de cada articulación, distancia euclidiana promedio estimada entre la articulación y la verdad del terreno, en milímetros.
- P-MPJPE : P-MPJPE es un MPJPE en el que la pose tridimensional estimada y la verdad fundamental están rígidamente alineadas después del posprocesamiento y es más robusto ante fallas de predicción de una sola articulación.
- PCK : Porcentaje de puntos clave correctos, el porcentaje de puntos de unión correctos dentro del rango de 150 mm.
- AUC : Área bajo la curva, área bajo la curva.