0X0-1 encuentra la longitud de la lista vinculada
Esta pregunta requiere la implementación de una función para encontrar la longitud de una lista vinculada.
Definición de interfaz de función:
int Length( List L );
La estructura de la Lista se define de la siguiente manera:
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode List;
L es una lista enlazada individualmente, y la función Longitud debe devolver la longitud de la lista enlazada.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <stdlib.h>
typedef int ElementType;
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode List;
List Read(); /* 细节在此不表 */
int Length( List L );
int main()
{
List L = Read();
printf("%d\n", Length(L));
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
1 3 4 5 2 -1
Muestra de salida:
5
Código:
int Length( List L )
{
int n = 0;
if (L==NULL) return 0;
while (L!=NULL)
{
L = L->Next;
n++;
}
return n;
}
0X0-2 Crear lista de enlaces de información del estudiante
Esta pregunta requiere la implementación de una función simple que organice las puntuaciones de entrada de los estudiantes en una lista vinculada unidireccional.
Definición de interfaz de función:
void input();
Esta función utiliza scanf para obtener información del estudiante a partir de la entrada y la organiza en una lista vinculada unidireccional. La estructura de nodos de la lista vinculada se define de la siguiente manera:
struct stud_node {
int num; /*学号*/
char name[20]; /*姓名*/
int score; /*成绩*/
struct stud_node *next; /*指向下个结点的指针*/
};
Los punteros de cabeza y cola de la lista enlazada unidireccional se almacenan en las variables globales cabeza y cola.
La entrada es información de varios estudiantes (ID del estudiante, nombre, calificaciones) y finaliza cuando el ID del estudiante es 0.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct stud_node {
int num;
char name[20];
int score;
struct stud_node *next;
};
struct stud_node *head, *tail;
void input();
int main()
{
struct stud_node *p;
head = tail = NULL;
input();
for ( p = head; p != NULL; p = p->next )
printf("%d %s %d\n", p->num, p->name, p->score);
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
1 zhang 78
2 wang 80
3 li 75
4 zhao 85
0
Muestra de salida:
1 zhang 78
2 wang 80
3 li 75
4 zhao 85
Código:
void input()
{
struct stud_node *q;
q = (struct stud_node *)malloc(sizeof(struct stud_node));
scanf("%d",&q->num);
while (q->num != 0)
{
scanf("%s %d",q->name,&q->score);
if (head == NULL)
{
head = q;
head->next = NULL;
}
if (tail != NULL)
{
tail->next = q;
}
tail = q;
tail->next = NULL;
q = (struct stud_node *)malloc(sizeof(struct stud_node));
scanf("%d",&q->num);
}
}
0X0-3 cuenta el número de profesionales
Esta pregunta requiere la implementación de una función para contar el número de estudiantes con especialización en informática en la lista de números de estudiantes. Los nodos de la lista enlazada se definen de la siguiente manera:
struct ListNode {
char code[8];
struct ListNode *next;
};
El número de identificación del estudiante aquí tiene un total de 7 dígitos, de los cuales el segundo y tercer dígito son el número principal. El número de especialización en informática es 02.
Definición de interfaz de función:
int countcs( struct ListNode *head );
Donde head es el puntero principal de la lista enlazada de números de estudiantes pasada por el usuario; la función countcs cuenta y devuelve el número de estudiantes con especialización en informática en la lista enlazada principal.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct ListNode {
char code[8];
struct ListNode *next; };
struct ListNode *createlist(); /*裁判实现,细节不表*/ int countcs( struct ListNode *head );
int main() {
struct ListNode *head;
head = createlist();
printf("%d\n", countcs(head));
return 0; }
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
1021202
2022310
8102134
1030912
3110203
4021205
#
Muestra de salida:
3
Código:
int countcs( struct ListNode *head )
{
int num = 0;
while (head)
{
if(head->code[1]=='0'&&head->code[2]=='2')
num++;
head = head->next;
}
return num;
}
Empalme de lista enlazada 0X0-4
Esta pregunta requiere la implementación de una función simple que combine dos listas vinculadas ordenadas. Los nodos de la lista enlazada se definen de la siguiente manera:
struct ListNode {
int data;
struct ListNode *next;
};
Definición de interfaz de función:
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2);
Entre ellos, lista1 y lista2 son los punteros principales de dos listas vinculadas pasadas por el usuario en orden ascendente de datos; la función mergelists fusiona las dos listas vinculadas en una lista vinculada en orden ascendente de datos y devuelve el puntero principal de la lista vinculada resultante. lista.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <stdlib.h>
struct ListNode {
int data;
struct ListNode *next;
};
struct ListNode *createlist(); /*裁判实现,细节不表*/
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2);
void printlist( struct ListNode *head )
{
struct ListNode *p = head;
while (p) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
int main()
{
struct ListNode *list1, *list2;
list1 = createlist();
list2 = createlist();
list1 = mergelists(list1, list2);
printlist(list1);
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
1 3 5 7 -1
2 4 6 -1
Muestra de salida:
1 2 3 4 5 6 7
Código:
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2)
{
int num = 0; //把两个链表连接成一个数组再排序
int temp[100];
struct ListNode *p = list1;
while(p != NULL)
{
temp[num] = p->data;
num++;
p = p->next;
}
p = list2;
while(p != NULL)
{
temp[num] = p->data;
num++;
p = p->next;
}
int i,j;
for(i = 0; i < num; i++)
for(j = i + 1; j < num; j++)
{
if(temp[i] > temp[j])
{
int t;
t = temp[i];
temp[i] = temp[j];
temp[j] = t;
}
}
struct ListNode *newlist = NULL;
struct ListNode *endlist = NULL;
struct ListNode *q;
for(i = 0; i < num; i++)
{
q = (struct ListNode *)malloc(sizeof(struct ListNode));
q->data = temp[i];
if(newlist == NULL)
{
newlist = q;
newlist->next = NULL;
}
if(endlist != NULL)
{
endlist->next = q;
}
endlist = q;
endlist->next = NULL;
}
return newlist;
}
0X0-5 Operaciones básicas de la tabla de secuencia.
Esta pregunta requiere la implementación de cuatro funciones operativas básicas: agregar, eliminar, buscar y generar elementos de la tabla de secuencia. L es una tabla de secuencia. La función Status ListInsert_Sq(SqList &L, int pos, ElemType e) inserta un elemento e en la posición pos de la tabla de secuencia (pos debe comenzar desde 1). La función Status ListDelete_Sq(SqList &L, int pos , ElemType &e ) es eliminar el elemento en la posición pos en la tabla de secuencia y traerlo de vuelta con el parámetro de referencia e (pos debe comenzar desde 1). La función int ListLocate_Sq(SqList L, ElemType e) es consultar la posición del elemento e en la tabla de secuencia y devuélvalo (si lo hay, tome la primera posición de varios elementos y devuelva la posición, comenzando desde 1, si no existe, devuelva 0). La función void ListPrint_Sq (SqList L) es la lista de secuencia de salida elemento. La cuestión de la ampliación de la capacidad total de la mesa debe considerarse durante la implementación.
Definición de interfaz de función:
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
donde L es la lista de secuencias. pos es la posición; e representa el elemento. Cuando el parámetro pos en las operaciones de inserción y eliminación es ilegal, la función devuelve ERROR; de lo contrario, devuelve OK.
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
//结构初始化与销毁操作
Status InitList_Sq(SqList &L){
//初始化L为一个空的有序顺序表
L.elem=(ElemType *)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem)exit(OVERFLOW);
L.listsize=LIST_INIT_SIZE;
L.length=0;
return OK;
}
int main() {
SqList L;
if(InitList_Sq(L)!= OK) {
printf("InitList_Sq: 初始化失败!!!\n");
return -1;
}
for(int i = 1; i <= 10; ++ i)
ListInsert_Sq(L, i, i);
int operationNumber; //操作次数
scanf("%d", &operationNumber);
while(operationNumber != 0) {
int operationType; //操作种类
scanf("%d", & operationType);
if(operationType == 1) { //增加操作
int pos, elem;
scanf("%d%d", &pos, &elem);
ListInsert_Sq(L, pos, elem);
} else if(operationType == 2) { //删除操作
int pos; ElemType elem;
scanf("%d", &pos);
ListDelete_Sq(L, pos, elem);
printf("%d\n", elem);
} else if(operationType == 3) { //查找定位操作
ElemType elem;
scanf("%d", &elem);
int pos = ListLocate_Sq(L, elem);
if(pos >= 1 && pos <= L.length)
printf("%d\n", pos);
else
printf("NOT FIND!\n");
} else if(operationType == 4) { //输出操作
ListPrint_Sq(L);
}
operationNumber--;
}
return 0;
}
/* 请在这里填写答案 */
Formato de entrada: ingrese un número de operación entero en la primera línea, que indica el operando, seguido de la línea del número de operación, cada línea indica una información de operación (incluido el "contenido de la operación del número de tipo de operación"). El número 1 representa la operación de inserción. Los siguientes dos parámetros representan la posición insertada y el valor del elemento insertado. El número 2 representa la operación de eliminación. El último parámetro representa la posición eliminada. El número 3 representa la operación de búsqueda. El último parámetro representa el número del valor de búsqueda. 4 representa la operación de salida de la tabla de secuencia formato de salida: Para la operación 2, genera el valor del elemento eliminado. Para la operación 3, genera la posición del elemento. Si el elemento no existe, genera "NO ENCONTRADO" ; Para la operación 4, genere toda la tabla de secuencia en secuencia. elementos, dos elementos están separados por un espacio y no hay espacio después del último elemento.
Ejemplo de entrada:
4
1 1 11
2 2
3 3
4
Muestra de salida:
1
3
11 2 3 4 5 6 7 8 9 10
Código:
//pos位置之后的元素都往后挪一位,给pos让位
//注意:存储可能不够
Status ListInsert_Sq(SqList &L, int pos, ElemType e)
{
if(L.length + 1 < pos || pos<1)
return OVERFLOW;
else
{
if(L.length >= L.listsize)
{
ElemType* newelem;
newelem = (ElemType *)realloc(L.elem,(L.listsize+LISTINCREMENT) * sizeof(ElemType));
if(!newelem)
return ERROR;
L.elem = newelem;
L.listsize += LISTINCREMENT;
}
ElemType *temp, *p;
temp = &(L.elem[pos-1]);
for(p = &(L.elem[L.length-1]); p >= temp; p--)
*(p+1) = *p;
*temp = e;
L.length = L.length + 1;
return OK;
}
}
//将pos位置的元素赋值给e,然后后边的一次覆盖前边的元素
//注意:pos可能不合法
Status ListDelete_Sq(SqList &L, int pos, ElemType &e)
{
if(L.length < pos || pos<1)
return OVERFLOW;
else
{
e = L.elem[pos-1];
ElemType* temp;
for(temp = &(L.elem[pos-1]); temp <= &(L.elem[L.length-1]); temp++)
*temp = *(temp+1);
L.length = L.length - 1;
//return OK;
}
}
//遍历,只要有相同的就标记并结束
int ListLocate_Sq(SqList L, ElemType e)
{
int i;
for(i = 0; i < L.length; i++)
{
if(L.elem[i] == e)
{
//break;
return i+1;
}
}
return ERROR;
}
void ListPrint_Sq(SqList L)
{
int i;
for (i=0;i<L.length;i++)
{
if (i==0) printf("%d",L.elem[i]);
else printf(" %d",L.elem[i]);
}
}
Operaciones básicas de la tabla de secuencia 1X1-1.
Esta pregunta requiere la implementación de cuatro funciones operativas básicas: agregar, eliminar, buscar y generar elementos de la tabla de secuencia. L es una tabla de secuencia. La función Status ListInsert_Sq(SqList &L, int pos, ElemType e) inserta un elemento e en la posición pos de la tabla de secuencia (pos debe comenzar desde 1). La función Status ListDelete_Sq(SqList &L, int pos , ElemType &e ) es eliminar el elemento en la posición pos en la tabla de secuencia y traerlo de vuelta con el parámetro de referencia e (pos debe comenzar desde 1). La función int ListLocate_Sq(SqList L, ElemType e) es consultar la posición del elemento e en la tabla de secuencia y devuélvalo (si lo hay, tome la primera posición de varios elementos y devuelva la posición, comenzando desde 1, si no existe, devuelva 0). La función void ListPrint_Sq (SqList L) es la lista de secuencia de salida elemento. La cuestión de la ampliación de la capacidad total de la mesa debe considerarse durante la implementación.
Definición de interfaz de función:
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
donde L es la lista de secuencias. pos es la posición; e representa el elemento. Cuando el parámetro pos en las operaciones de inserción y eliminación es ilegal, la función devuelve ERROR; de lo contrario, devuelve OK.
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
//结构初始化与销毁操作
Status InitList_Sq(SqList &L){
//初始化L为一个空的有序顺序表
L.elem=(ElemType *)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem)exit(OVERFLOW);
L.listsize=LIST_INIT_SIZE;
L.length=0;
return OK;
}
int main() {
SqList L;
if(InitList_Sq(L)!= OK) {
printf("InitList_Sq: 初始化失败!!!\n");
return -1;
}
for(int i = 1; i <= 10; ++ i)
ListInsert_Sq(L, i, i);
int operationNumber; //操作次数
scanf("%d", &operationNumber);
while(operationNumber != 0) {
int operationType; //操作种类
scanf("%d", & operationType);
if(operationType == 1) { //增加操作
int pos, elem;
scanf("%d%d", &pos, &elem);
ListInsert_Sq(L, pos, elem);
} else if(operationType == 2) { //删除操作
int pos; ElemType elem;
scanf("%d", &pos);
ListDelete_Sq(L, pos, elem);
printf("%d\n", elem);
} else if(operationType == 3) { //查找定位操作
ElemType elem;
scanf("%d", &elem);
int pos = ListLocate_Sq(L, elem);
if(pos >= 1 && pos <= L.length)
printf("%d\n", pos);
else
printf("NOT FIND!\n");
} else if(operationType == 4) { //输出操作
ListPrint_Sq(L);
}
operationNumber--;
}
return 0;
}
/* 请在这里填写答案 */
Formato de entrada: ingrese un número de operación entero en la primera línea, que indica el operando, seguido de la línea del número de operación, cada línea indica una información de operación (incluido el "contenido de la operación del número de tipo de operación"). El número 1 representa la operación de inserción. Los siguientes dos parámetros representan la posición insertada y el valor del elemento insertado. El número 2 representa la operación de eliminación. El último parámetro representa la posición eliminada. El número 3 representa la operación de búsqueda. El último parámetro representa el número del valor de búsqueda. 4 representa la operación de salida de la tabla de secuencia formato de salida: Para la operación 2, genera el valor del elemento eliminado. Para la operación 3, genera la posición del elemento. Si el elemento no existe, genera "NO ENCONTRADO" ; Para la operación 4, genere toda la tabla de secuencia en secuencia. elementos, dos elementos están separados por un espacio y no hay espacio después del último elemento.
Ejemplo de entrada:
4
1 1 11
2 2
3 3
4
Muestra de salida:
1
3
11 2 3 4 5 6 7 8 9 10
Código:
//添加元素
//pos位置之后的元素都往后挪一位,给pos让位
//注意:存储可能不够
Status ListInsert_Sq(SqList &L, int pos, ElemType e)
{
if (pos<1 || pos>L.length+1) return OVERFLOW; //注意判断条件限制的临界值
if (L.length >= L.listsize)
{
L.elem = (ElemType *)realloc(L.elem,(L.listsize + LISTINCREMENT)*sizeof(ElemType));
if (!L.elem) exit(OVERFLOW);
L.listsize += LISTINCREMENT;
}
ElemType*p;
for(p = L.elem+L.length-1; p >= L.elem+pos-1; p--)
*(p+1) = *p;
*(L.elem+pos-1) = e;
L.length++;
return OK;
}
//删除元素
//将pos位置的元素赋值给e,然后后边的一次覆盖前边的元素
//注意:pos可能不合法
Status ListDelete_Sq(SqList &L, int pos, ElemType &e)
{
if (pos<1 || pos>L.length)
return OVERFLOW;
e = L.elem[pos-1];
ElemType *p;
for (p = L.elem+pos-1;p<=L.elem+L.length-1;p++)
*p = *(p+1);
L.length--;
return OK;
}
//查询元素
//遍历,只要有相同的就标记并结束
int ListLocate_Sq(SqList L, ElemType e)
{
for (int i=0;i<L.length;i++)
if (e==L.elem[i]) return i+1;
return ERROR;
}
//输出元素
void ListPrint_Sq(SqList L)
{
ElemType *p;
for (p = L.elem;p<L.elem+L.length;p++)
{
if (p==L.elem) printf("%d",*p);
else printf(" %d",*p);
}
}
Ejemplo de función de explosión de memoria 2X2-1
Esta pregunta requiere la implementación de una función recursiva: el usuario pasa un parámetro entero no negativo n y genera secuencialmente un número entero entre 1 y n. La llamada función recursiva se refiere a una función que se llama a sí misma.
ilustrar:
- La idea básica de la resolución de funciones recursivas es reducir la solución de un problema a gran escala a la solución de un problema de escala relativamente pequeña, y el
problema de pequeña escala se reduce a la solución de un problema de pequeña escala, y así sucesivamente, hasta que la escala del problema sea lo suficientemente pequeña como para alcanzar el límite (los problemas de límites se pueden resolver directamente). La función recursiva consta de dos
partes, una es el límite recursivo y la otra es la relación recursiva. Tomando la función factorial como ejemplo, laFactorial(1)=1;fórmula recursiva de límite recursivo:Factorial(n)=n*Factorial(n-1),su función recursiva correspondiente es la siguiente:
int GetFactorial(int n)
{
int result;
if(n==1) result = 1; //递归边界,此时问题答案易知,可直接求解
else result =n* GetFactorial(n-1); //递归关系,大问题求解归结为小问题求解
return result;
}
- Cuando ocurre una llamada a una función recursiva (llamándose a sí misma) o una llamada a una función normal, el sistema necesita guardar la
información (incluida la información del valor de cada variable antes de que ocurra la llamada y la ubicación de ejecución de la función, etc.) para que la función llamada se pueda ejecutar y luego pueda regresar sin problemas
y continuar con las operaciones posteriores. Cada llamada necesita guardar información de una escena. El tamaño del espacio auxiliar requerido para guardar esta información de escena
es proporcional al número de llamadas a funciones, o su complejidad espacial es O (n), donde n es el número de llamadas. - El propósito de este ejemplo es permitir a los estudiantes escribir una función recursiva y probar en sus propias máquinas cuántas veces se producirán las llamadas recursivas antes de que la memoria explote
y se produzca un error de desbordamiento de la memoria (se desbordará cuando el parámetro se establezca en 66000 en la máquina de mi oficina). Para el mismo problema, si no
usa una función recursiva pero usa una declaración de bucle ordinaria para resolver el problema, ¡no habrá desbordamiento de memoria!
Definición de interfaz de función:
void PrintN (long n);
Donde n es el parámetro pasado por el usuario.
Ejemplo de procedimiento de prueba de árbitro:
Aquí se proporciona un ejemplo de una función que se llama para realizar pruebas. Por ejemplo:
#include <stdio.h>
void PrintN(long n);
int main()
{
PrintN(66000L);
return 0;
}
/* 请在这里填写答案 */
Ejemplo de entrada:
5
Muestra de salida:
12345
Código:
//找递归的结束条件:到1时结束就好
void PrintN(long n)
{
if(n==1)
printf("%d",n);
else
{
PrintN(n-1);
printf("%d",n);
}
}
Creación de tabla de secuencia 3X3-1 e inversión in situ
Esta pregunta requiere la creación de una tabla de secuencia y la función de operación de inversión in situ. L es una tabla de secuencia. La función ListCreate_Sq(SqList &L) se utiliza para crear una tabla de secuencia. La función ListReverse_Sq(SqList &L) es para invertir los elementos de la tabla de secuencia sin introducir una matriz auxiliar. Por ejemplo, los elementos de la La tabla de secuencia original está en secuencia. es 1,2,3,4, luego es 4,3,2,1 después de la inversión.
Definición de interfaz de función:
Status ListCreate_Sq(SqList &L);
void ListReverse_Sq(SqList &L);
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
Status ListCreate_Sq(SqList &L);
void ListReverse_Sq(SqList &L);
int main() {
SqList L;
ElemType *p;
if(ListCreate_Sq(L)!= OK) {
printf("ListCreate_Sq: 创建失败!!!\n");
return -1;
}
ListReverse_Sq(L);
if(L.length){
for(p=L.elem;p<L.elem+L.length-1;++p){
printf("%d ",*p);
}
printf("%d",*p);
}
return 0;
}
/* 请在这里填写答案 */
Formato de entrada: ingrese un número entero n en la primera línea, que representa el número de elementos en la tabla de secuencia. Los siguientes n enteros son elementos de la tabla, separados por espacios. Formato de salida: genera cada elemento de la tabla de secuencia invertida. Los dos elementos están separados por un espacio y no hay espacio después del último elemento.
Ejemplo de entrada:
4
1 2 3 4
Muestra de salida:
4 3 2 1
Código:
//思路:动态分配空间,设置表长,设置指针p,通过p++来输入元素,表容量为100
//注意:有可能分配空间会失败
Status ListCreate_Sq(SqList &L)
{
int n;
ElemType *p;
L.elem = (ElemType *)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if (!L.elem) exit(OVERFLOW);
L.listsize = LIST_INIT_SIZE;
scanf("%d",&n);
L.length = n;
for (p = L.elem;p<L.elem + L.length; p++)
scanf("%d",p);
return OK;
}
//思路:定义两个指针First和last分别指向顺序表的首地址和最后元素的地址,First和Last的元素交换,Frist和Last自增,一直到中间元素结束
//注意:
void ListReverse_Sq(SqList &L)
{
ElemType* First;
ElemType* Last;
ElemType temp;
for (First = L.elem,Last = L.elem + L.length - 1 ;First<=(L.elem + L.length/2),Last>=(L.elem + L.length/2);First++,Last--)
{
temp = *First;
*First = *Last;
*Last = temp;
}
}
Inserción en una tabla de secuencia ordenada 3X3-2
Esta pregunta requiere la implementación de una función de inserción ordenada para una tabla de secuencia ascendente. L es una lista de secuencia ordenada creciente y la función Status ListInsert_SortedSq(SqList &L, ElemType e) se utiliza para insertar datos en la tabla de secuencia en orden creciente. Por ejemplo: los datos originales son: 2 5, y se va a insertar un elemento 3, luego la tabla de secuencia después de la inserción es 2 3 5. Considere los problemas de expansión.
Definición de interfaz de función:
Status ListInsert_SortedSq(SqList &L, ElemType e);
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
//函数声明
Status ListInsert_SortedSq(SqList &L, ElemType e);
//顺序表初始化函数
Status InitList_Sq(SqList &L)
{
//开辟一段空间
L.elem = (ElemType*)malloc(LIST_INIT_SIZE * sizeof(ElemType));
//检测开辟是否成功
if(!L.elem){
exit(OVERFLOW);
}
//赋值
L.length = 0;
L.listsize = LIST_INIT_SIZE;
return OK;
}
//顺序表输出函数
void ListPrint_Sq(SqList L)
{
ElemType *p = L.elem;//遍历元素用的指针
for(int i = 0; i < L.length; ++i){
if(i == L.length - 1){
printf("%d", *(p+i));
}
else{
printf("%d ", *(p+i));
}
}
}
int main()
{
//声明一个顺序表
SqList L;
//初始化顺序表
InitList_Sq(L);
int number = 0;
ElemType e;
scanf("%d", &number);//插入数据的个数
for(int i = 0; i < number; ++i)
{
scanf("%d", &e);//输入数据
ListInsert_SortedSq(L, e);
}
ListPrint_Sq(L);
return 0;
}
/* 请在这里填写答案 */
Formato de entrada: Ingrese el número de números que se insertarán en la primera línea. Ingrese el número en la segunda línea. Formato de salida: Imprima el número después de la inserción.
Ejemplo de entrada:
5
2 3 9 8 4
Muestra de salida:
2 3 4 8 9
Código:
//设置指针p,从最后一位开始如果待插入的元素比当前元素小,就把当前元素后移一位,一直到当前元素比待插入元素小
//注意:有可能表满,需要扩容
Status ListInsert_SortedSq(SqList &L, ElemType e)
{
//对表满情况的处理
if (L.length>=L.listsize)
{
L.elem = (ElemType *)realloc(L.elem,(L.listsize + LISTINCREMENT)*sizeof(ElemType));//注意每次扩容的基础
if (!L.elem) exit(OVERFLOW);
L.listsize += LISTINCREMENT;
}
ElemType *p = L.elem + L.length -1;
while (p>=L.elem && *p>e) //定位以及移动
{
*(p+1) = *p;
p--;
}
*(p+1) = e; //插入
L.length++;
return OK;
}
Desplazamiento circular a la izquierda de matriz 3X3-3
Esta pregunta requiere la implementación de una función simple que desplaza circularmente una matriz hacia la izquierda: hay n (>0) números enteros en una matriz a, y bajo la premisa de que no se permite el uso de otras matrices, cada número entero se desplaza circularmente a la izquierda por m (≥0 ) posiciones, es decir, los datos en a se transforman de (a0a1⋯an−1) a (amm⋯a n−1a0 a1⋯amm−1) (los primeros m números se mueven circularmente a las últimas m posiciones). Si también debemos considerar que el programa mueve datos la menor cantidad de veces posible, ¿cómo deberíamos diseñar un método de movimiento?
Formato de entrada:
La primera línea de entrada da un número entero positivo n (≤100) y un número entero m (≥0); la segunda línea da n números enteros separados por espacios.
Formato de salida:
Genere la secuencia de enteros girada hacia la izquierda m bits en una línea, separada por espacios, y no debe haber espacios adicionales al final de la secuencia.
Ejemplo de entrada:
8 3
1 2 3 4 5 6 7 8
Muestra de salida:
4 5 6 7 8 1 2 3
Código:
//思路:需要左移的串逆转,需要右移的串逆转,将两个串拼接起来,再逆转就会得到结果
#include <stdio.h>
//实现字符串的逆转
void Reverse(int *s,int left,int right)
{
int temp;
while (left<right)
{
temp = s[left];
s[left] = s[right];
s[right] = temp;
left++;
right--;
}
}
//输出数组
void Print(int *s,int len)
{
int i;
for (i=0;i<len;i++)
{
if (i==0) printf("%d",s[i]);
else printf(" %d",s[i]);
}
}
int main()
{
int s[110];
int n,m;
int i;
scanf("%d %d",&n,&m);
m = m%n;
for (i=0;i<n;i++)
scanf("%d",&s[i]);
Reverse(s,0,m-1); //逆转前半部分需要左移的
Reverse(s,m,n-1); //逆转后半部分需要右移的
Reverse(s,0,n-1); //逆转整个字符串
Print(s,n);
}
Eliminación de intervalos de elementos de tabla lineal 4X4-1
Dada una lista lineal almacenada secuencialmente, diseñe una función para eliminar todos los elementos con valores mayores que el mínimo y menores que el máximo. Después de la eliminación, los elementos restantes de la tabla permanecen almacenados en orden y sus posiciones relativas no se pueden cambiar.
Definición de interfaz de función:
List Delete( List L, ElementType minD, ElementType maxD );
La estructura de la Lista se define de la siguiente manera:
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
L es una tabla lineal pasada por el usuario, en la que los elementos ElementType se pueden comparar mediante >, == y <; minD y maxD son los límites inferior y superior del rango de valores del elemento que se va a eliminar, respectivamente. La función Eliminar debe eliminar todos los elementos en Datos [] con valores mayores que minD y menores que maxD, al tiempo que garantiza que los elementos restantes en la tabla se almacenen en orden y sus posiciones relativas permanezcan sin cambios, y finalmente devolver la tabla eliminada.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#define MAXSIZE 20
typedef int ElementType;
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
List ReadInput(); /* 裁判实现,细节不表。元素从下标0开始存储 */
void PrintList( List L ); /* 裁判实现,细节不表 */
List Delete( List L, ElementType minD, ElementType maxD );
int main()
{
List L;
ElementType minD, maxD;
int i;
L = ReadInput();
scanf("%d %d", &minD, &maxD);
L = Delete( L, minD, maxD );
PrintList( L );
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
10
4 -8 2 12 1 5 9 3 3 10
0 4
Muestra de salida:
4 -8 12 5 9 10
Código:
//思路:遍历数组元素,将每一个元素需要前移的位数找出来,再分别将元素前移多少位数即可
//注意:L.length需要变化;有可能会有minD和maxD不合理的请求
List Delete( List L, ElementType minD, ElementType maxD )
{
if(minD >= maxD) return L;
int i;
int num = 0;
for (i = 0;i<=L->Last;i++) //注意L->Last是最后一个元素
{
if (L->Data[i]>minD && L->Data[i]<maxD) num++;
else L->Data[i-num] = L->Data[i];
}
L->Last -= num;
return L;
}
//补充:在移动元素的时候,不是使用覆盖的方法,只需要把当前元素直接向前移动num就行,不用使用while
4X4-2 subsecuencia creciente continua más larga
Dada una lista lineal almacenada secuencialmente, diseñe un algoritmo para encontrar la subsecuencia creciente consecutiva más larga en la lista lineal. Por ejemplo, la subsecuencia creciente más larga en (1,9,2,5,7,3,4,6,8,0) es (3,4,6,8).
Formato de entrada:
La línea de entrada 1 da un número entero positivo n (≤105); la línea 2 da n números enteros separados por espacios.
Formato de salida:
Genera la subsecuencia creciente consecutiva más larga que aparece por primera vez en una línea. Los números están separados por espacios. No debe haber espacios adicionales al final de la secuencia.
Ejemplo de entrada:
15
1 9 2 5 7 3 4 6 8 0 11 15 17 17 10
Muestra de salida:
3 4 6 8
Código:
/*思路:首先,创建一个结构体,定义一个maxIncSeq,用来记录最长连续递增子序列,再定义一个curIncSeq,用来记录当前连续递增子序列的信息
只要后一位的数比前一位要大,就更新curIncSeq的信息。
如果,当前长度大于最长的,就把maxIncSeq的信息更新。
注意:最后一个连续递增子序列需要单独处理*/
#include <stdio.h>
typedef struct IncSeq
{
int *p; //记录序列的开始位置
int length; //记录序列的长度
} IncSeq;
int main()
{
IncSeq maxIncSeq;
IncSeq curIncSeq;
int n;
int num = 0;
int a[100001];
int *q = a;
scanf("%d",&n);
for (int i=0;i<n;i++)
a[i] = 0;
maxIncSeq.p = a; //初始化连续递增子序列的信息
maxIncSeq.length = 0;
curIncSeq.p = a;
curIncSeq.length = 0;
scanf("%d",&a[0]);
for (q = a+1;q<a+n;q++)
{
scanf("%d",q);
num++;
if (*(q-1) >= *q)
{
curIncSeq.p = q-num; //更新curIncSeq的信息
curIncSeq.length = num;
if ( maxIncSeq.length < curIncSeq.length) //更新maxIncSeq的信息
{
maxIncSeq.p = curIncSeq.p;
maxIncSeq.length = curIncSeq.length;
}
num = 0;
}
}
//对最后一个递增子序列的单独处理
int lastLen = (a+n)-(curIncSeq.p + curIncSeq.length);
if (lastLen > maxIncSeq.length)
{
maxIncSeq.p = curIncSeq.p + curIncSeq.length;
maxIncSeq.length = lastLen;
}
for (q = maxIncSeq.p;q<maxIncSeq.p + maxIncSeq.length;q++) //输出最长连续递增子序列
{
if (q == maxIncSeq.p) printf("%d",*q);
else printf(" %d",*q);
}
}
/*补充:(1)比较连续递增子序列是否结束时,必须使用前一位和当前位的比较
(2)最后一位的单独处理注意开始位置和长度
(3)使用num计数,更新最大序列的信息时,不要忘记把num清0,而且注意num=0放的位置
*/
Posicionamiento de elementos de lista enlazada individualmente 5X5-1
Esta pregunta requiere encontrar el nodo cuyo primer valor de campo de datos es x en la lista vinculada y devolver el orden del nodo. L es una lista enlazada individualmente con el nodo principal. La función ListLocate_L (LinkList L, ElemType x) requiere encontrar el nodo cuyo primer valor de campo de datos es x en la lista enlazada y devolver su orden (comenzando desde 1). Si no se puede encontrado, Devuelve 0. Por ejemplo, si los elementos de cada nodo de elemento de la lista enlazada individualmente original son 1, 2, 3 y 4, entonces ListLocate_L(L, 1) devuelve 1, ListLocate_L(L, 3) devuelve 3 y ListLocate_L(L, 100) devuelve 0.
Definición de interfaz de función:
int ListLocate_L(LinkList L, ElemType x);
donde L es una lista enlazada individualmente de nodos principales. x es un valor dado. La función debe encontrar el nodo con el primer valor de campo de datos x en la lista vinculada. Si se encuentra, se devuelve su orden de bits (a partir de 1); si no se encuentra, se devuelve 0.
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
Status ListCreate_L(LinkList &L,int n)
{
LNode *rearPtr,*curPtr; //一个尾指针,一个指向新节点的指针
L=(LNode*)malloc(sizeof (LNode));
if(!L)exit(OVERFLOW);
L->next=NULL; //先建立一个带头结点的单链表
rearPtr=L; //初始时头结点为尾节点,rearPtr指向尾巴节点
for (int i=1;i<=n;i++){ //每次循环都开辟一个新节点,并把新节点拼到尾节点后
curPtr=(LNode*)malloc(sizeof(LNode));//生成新结点
if(!curPtr)exit(OVERFLOW);
scanf("%d",&curPtr->data);//输入元素值
curPtr->next=NULL; //最后一个节点的next赋空
rearPtr->next=curPtr;
rearPtr=curPtr;
}
return OK;
}
//下面是需要实现的函数的声明
int ListLocate_L(LinkList L, ElemType x);
int main()
{
LinkList L;
int n;
int x,k;
scanf("%d",&n); //输入链表中元素个数
if(ListCreate_L(L,n)!= OK) {
printf("表创建失败!!!\n");
return -1;
}
scanf("%d",&x); //输入待查找元素
k=ListLocate_L(L,x);
printf("%d\n",k);
return 0;
}
/* 请在这里填写答案 */
Ejemplo de entrada:
4
1 2 3 4
1
Muestra de salida:
1
Código:
/*
思路:遍历链表,使用count计数的同时比较L->data和x,只要相等就返回count,否则返回0
注意:如果x不存在于链表中,那么最后指针p为NULL
*/
int ListLocate_L(LinkList L, ElemType x)
{
LNode *p=L;
int count=1;
while(p->next != NULL)
{
p = p->next;
if(p->data == x) return count;
count++;
}
return 0;
}
5X5-2 Eliminar el último nodo de la lista enlazada individualmente que sea igual al valor dado
Esta pregunta requiere eliminar el nodo con el último valor del campo de datos x en la lista vinculada. L es una lista enlazada individualmente con el nodo principal. La función ListLocateAndDel_L (LinkList L, ElemType x) requiere encontrar el nodo con el último valor del campo de datos x en la lista enlazada y eliminarlo. Por ejemplo, los campos de datos de cada nodo en la lista enlazada individualmente original son 1 3 1 4 3 5. Después de ejecutar ListLocateAndDel_L(L,3), los campos de datos de los nodos restantes en la lista enlazada son 1 3 1 4 5 .
Definición de interfaz de función:
void ListLocateAndDel_L(LinkList L, ElemType x);
donde L es una lista enlazada individualmente de nodos principales. x es un valor dado. La función debe ubicar el nodo con el último valor del campo de datos x en la lista vinculada y eliminarlo.
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define NULL 0
typedef int Status;
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
//链表创建函数
Status ListCreate_L(LinkList &L,int n)
{
LNode *rearPtr,*curPtr;
L=(LNode*)malloc(sizeof (LNode));
if(!L)exit(OVERFLOW);
L->next=NULL;
rearPtr=L;
for (int i=1;i<=n;i++){
curPtr=(LNode*)malloc(sizeof(LNode));
if(!curPtr)exit(OVERFLOW);
scanf("%d",&curPtr->data);
curPtr->next=NULL;
rearPtr->next=curPtr;
rearPtr=curPtr;
}
return OK;
}
//链表输出函数
void ListPrint_L(LinkList L)
{
LNode *p=L->next;
if(!p){
printf("空表");
return;
}
while(p!=NULL)
{
if(p->next!=NULL)
printf("%d ",p->data);
else
printf("%d",p->data);
p=p->next;
}
}
//下面是需要实现的函数的声明
void ListLocateAndDel_L(LinkList L, ElemType x);
int main()
{
LinkList L;
int n;
int x;
scanf("%d",&n); //输入链表中元素个数
if(ListCreate_L(L,n)!= OK) {
printf("表创建失败!!!\n");
return -1;
}
scanf("%d",&x); //输入待查找元素
ListLocateAndDel_L(L,x);
ListPrint_L(L);
return 0;
}
/* 请在这里填写答案 */
Ejemplo de entrada:
6
1 3 1 4 3 5
3
Muestra de salida:
1 3 1 4 5
Código:
/*
思路:先遍历一遍链表,把与x相等的值的个数num找出来,然后再遍历一遍链表,使用count计数器,只要遇到x,count就自增。
当count与num相等时,就把对应的x值删除
注意:x有可能不存在于链表中,那么此时的num==0;当x位于最后一位时需要特殊处理
*/
void ListLocateAndDel_L(LinkList L, ElemType x)
{
//遍历链表找出与x相等的个数
LNode *p = L;
int num = 0;
while (p->next != NULL)
{
if (p->data == x) num++;
p = p->next;
}
if (p->data == x) num++;
//删除最后一个与x相等的值
LNode *q = L;
int count = 0;
while (q->next != NULL)
{
if (q->next->data == x) count++;
if (count == num && num != 0) //注意元素不存在的判断
{
q->next = q->next->next;
break;
}
q = q->next;
}
}
5X5-3 Fusión de dos secuencias de listas enlazadas ordenadas
Dadas dos secuencias de listas enlazadas no descendentes S1 y S2, la función de diseño construye una nueva lista enlazada no descendente S3 después de la fusión de S1 y S2.
Formato de entrada:
La entrada se divide en dos líneas, y en cada línea se proporciona una secuencia no descendente compuesta de varios números enteros positivos. −1 se utiliza para representar el final de la secuencia (−1 no pertenece a esta secuencia). Los números están separados por espacios.
Formato de salida:
Genere la nueva lista vinculada no descendente fusionada en una línea, con espacios separando los números y sin espacios adicionales al final; si la nueva lista vinculada está vacía, se genera NULL.
Ejemplo de entrada:
1 3 5 -1
2 4 6 8 10 -1
Muestra de salida:
1 2 3 4 5 6 8 10
Código:
/*
思路:定义两个指针p、q分别指向s1和s2,从第一个元素开始比较,如果p->data大于q->data的话,就把q->next放入新的链表中。
然后,q = q->next,p不动,继续和下一个比较,以此类推
注意:总有一个链表要先遍历完,直接把剩余链表的元素接上就行
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define NULL 0
typedef int Status;
typedef struct LNode
{
int data;
struct LNode *next;
}LNode,*LinkList;
//函数实现
Status CreatList(LinkList &L); //创建一个链表
LinkList InsertList(); //往链表里插入元素
LinkList Merge(LinkList s1,LinkList s2); //合并两个链表
void Print(LinkList L); //输出链表的元素
int main()
{
LinkList s1,s2,L;
CreatList(s1);
CreatList(s2);
CreatList(L);
s1 = InsertList();
s2 = InsertList();
L = Merge(s1,s2);
Print(L);
}
//创建链表
Status CreatList(LinkList &L)
{
L = (LNode*)malloc(sizeof(LNode));
if (!L) exit(OVERFLOW);
L->next = NULL;
return OK;
}
//向链表中插入元素
LinkList InsertList()
{
int n;
LinkList L;
CreatList(L);
LNode *p = L;
scanf("%d",&n);
while (n != -1)
{
LNode *temp;
temp = (LNode*)malloc(sizeof(LNode));
temp->data = n;
p->next = temp;
p = temp;
scanf("%d",&n);
p->next = NULL;
}
return L;
}
//合并链表
LinkList Merge(LinkList s1,LinkList s2)
{
LNode *p = s1->next; //用来遍历s1
LNode *q = s2->next; //用来遍历s2
LinkList L; //不要忘记初始化
L = (LNode *)malloc(sizeof(LNode));
LNode *temp = L;
while (p && q)
{
if (p->data < q->data)
{
temp->next = p; //连接元素
temp = p; //新表移动
p = p->next; //原来的表移动
}
else
{
temp->next = q;
temp = q;
q = q->next;
}
}
//将剩余元素接上
temp->next = p?p:q;
s1->next = NULL;
s2->next = NULL;
return L;
}
//输出元素
//注意与顺序表不同的是要在循环里边加上L = L->next
void Print(LinkList L)
{
L = L->next;
int num = 0;
if (L==NULL) printf("NULL");
else
{
while (L)
{
if (!num) printf("%d",L->data);
else printf(" %d",L->data);
num++;
L = L->next;
}
printf("\n");
}
}
6X6-1 La lista enlazada individualmente del nodo principal se invierte en su lugar
Esta pregunta requiere escribir una función para implementar la función de operación de inversión in situ de una lista lineal de enlace único con el nodo principal. L es una lista enlazada individualmente con el nodo principal. La función ListReverse_L (LinkList &L) requiere que los elementos de la lista enlazada individualmente se inviertan sin abrir nuevos nodos. Por ejemplo, los elementos de la lista enlazada individualmente original son 1, 2, 3 y 4 en orden, luego, después de la inversión, es 4,3,2,1.
Definición de interfaz de función:
void ListReverse_L(LinkList &L);
Donde L es una lista enlazada individualmente con el nodo principal.
Ejemplo de procedimiento de prueba de árbitro:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
Status ListCreate_L(LinkList &L,int n)
{
LNode *rearPtr,*curPtr; //一个尾指针,一个指向新节点的指针
L=(LNode*)malloc(sizeof (LNode));
if(!L)exit(OVERFLOW);
L->next=NULL; //先建立一个带头结点的单链表
rearPtr=L; //初始时头结点为尾节点,rearPtr指向尾巴节点
for (int i=1;i<=n;i++){ //每次循环都开辟一个新节点,并把新节点拼到尾节点后
curPtr=(LNode*)malloc(sizeof(LNode));//生成新结点
if(!curPtr)exit(OVERFLOW);
scanf("%d",&curPtr->data);//输入元素值
curPtr->next=NULL; //最后一个节点的next赋空
rearPtr->next=curPtr;
rearPtr=curPtr;
}
return OK;
}
void ListReverse_L(LinkList &L);
void ListPrint_L(LinkList &L){
//输出单链表
LNode *p=L->next; //p指向第一个元素结点
while(p!=NULL)
{
if(p->next!=NULL)
printf("%d ",p->data);
else
printf("%d",p->data);
p=p->next;
}
}
int main()
{
LinkList L;
int n;
scanf("%d",&n);
if(ListCreate_L(L,n)!= OK) {
printf("表创建失败!!!\n");
return -1;
}
ListReverse_L(L);
ListPrint_L(L);
return 0;
}
/* 请在这里填写答案 */
Formato de entrada:
Ingrese un número entero n en la primera línea, que representa el número de elementos en la lista enlazada individualmente. La siguiente línea contiene un total de n números enteros, separados por espacios.
Formato de salida:
Genere cada elemento de la lista de secuencia invertida. Dos elementos están separados por un espacio y no hay espacio después del último elemento.
Ejemplo de entrada:
4
1 2 3 4
Muestra de salida:
4 3 2 1
Código:
/*思路:使用指针p来指向当前元素,另一个指针q赋值为当前元素的next成员,p的next成员赋值为q的next成员,这就实现把链表中的元素取出来。
取出来的元素用q来表示,把q添加到头结点的后边,q的next成员赋值为第一个元素即可。以此类推,直至链表为NULL。
注意:有可能链表为空或者链表只有一个元素
*/
void ListReverse_L(LinkList &L)
{
LNode *p; //用于指向当前元素
LNode *q; //用于取出元素
p = L->next;
while (p->next != NULL)
{
//取出当前元素
q = p->next;
p->next = q->next;
//添加到头结点后边
q->next = L->next;
L->next = q;
}
}
Derivación de polinomio de una variable 6X6-2
Diseñar una función para encontrar la derivada de un polinomio de una variable.
Formato de entrada:
Ingrese los coeficientes y exponentes distintos de cero del polinomio en orden exponencial descendente (los valores absolutos son todos números enteros que no exceden 1000). Separe los números con espacios.
Formato de salida:
Genera los coeficientes y exponentes de los términos distintos de cero del polinomio derivado en el mismo formato que la entrada. Los números deben estar separados por espacios, pero no deben haber espacios adicionales al final.
Ejemplo de entrada:
3 4 -5 2 6 1 -2 0
Muestra de salida:
12 3 -10 1 6 0
Código:
/*思路:多项式的求导就是系数变成指数和原来系数相同,指数减一。由于该多项式是一元多项式而且指数按照递降顺序排列,所以不需要求导以后的合并。
求导过程:指数乘以系数,然后指数减一
注意:创造结构体时data的类型是Elemtype,而此时的data包括两个内容,系数和指数,又是结构体类型
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct Elemtype
{
int coef; //系数
int index; //指数
}Elemtype;
typedef struct LNode
{
Elemtype data;
struct LNode *next;
}LNode,*LinkList;
//函数实现
Status CreatList(LinkList &L); //创建链表
LinkList InputList(); //输入多项式
void Deri_List(LinkList &L); //求导
void Print_L(LinkList L); //输出多项式
int Flag1 = 0;
int Flag2 = 0;
int Flag3 = 0;
int main()
{
LinkList L;
CreatList(L);
L = InputList();
Deri_List(L);
Print_L(L);
}
Status CreatList(LinkList &L)
{
L = (LNode*)malloc(sizeof(LNode));
if (!L) exit(OVERFLOW);
L->next = NULL;
return OK;
}
LinkList InputList()
{
int m,n = 1;
LinkList L;
CreatList(L);
LNode *p = L;
int flag = 0;
while (scanf("%d",&m)!=EOF)
{
Flag1 = 1;
if (m==0 && flag == 0) Flag2 = 2;
LNode *temp = (LNode*)malloc(sizeof(LNode));
temp->data.coef = m; //系数
if (scanf("%d",&n)!=EOF)
{
temp->data.index = n; //指数
if (n == 0 && flag == 0) Flag2 = 2;
else if (n==0) Flag3 = 3;
}
else break;
flag++;
p->next = temp;
p = temp;
p->next = NULL;
}
return L;
}
void Deri_List(LinkList &L)
{
LNode *p = L->next;
while (p != NULL)
{
p->data.coef *= p->data.index;
p->data.index--;
p = p->next;
}
}
void Print_L(LinkList L)
{
if (!Flag1||Flag2 == 2) printf("0 0");
else
{
LNode *p = L->next;
int flag = 0;
while (p != NULL)
{
if (p->data.index != -1)
{
if (flag != 0) printf(" %d %d",p->data.coef,p->data.index);
else printf("%d %d",p->data.coef,p->data.index);
flag++;
}
p = p->next;
}
printf("\n");
}
}
/*补充:(1)输入函数的结束标记:由于while循环体里面要求输入m,所以要在输入m之前break;
(2)如果只输入一个系数的情况
(3)如果输入的第一个数是0的情况
*/
6X6-3 Encuentre el término K-ésimo del recíproco de la tabla lineal vinculada
Dada una serie de números enteros positivos, diseñe un algoritmo lo más eficiente posible para encontrar el número en la posición K-ésima desde abajo.
Formato de entrada:
La entrada primero da un número entero positivo K, seguido de varios números enteros positivos y finalmente termina con un número entero negativo (el número negativo no está incluido en la secuencia y no debe procesarse).
Formato de salida:
Genere los datos en la posición K-ésima desde la última. Si la ubicación no existe, se genera un mensaje de error NULL.
Ejemplo de entrada:
4 1 2 3 4 5 6 7 8 9 0 -1
Muestra de salida:
7
Código:
//求链式线性表的倒数第K项
/*
思路:设置两个指针p和q,两个指针之间的距离始终保持K个单位,当q指针指向末尾时,p指针就指向了倒数第K项
注意:链表长度可能小于K,此时要输出错误信息NULL
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct LNode
{
int data;
struct LNode *next;
}LNode,*LinkList;
//函数实现
Status CreatList(LinkList &L); //创建链表
LinkList InputList(); //输入数据
void Print_K(LinkList L,int k); //按要求输出数据
int main()
{
LinkList L;
CreatList(L);
int k;
scanf("%d",&k);
L = InputList();
Print_K(L,k);
}
//创建链表
Status CreatList(LinkList &L)
{
L = (LNode *)malloc(sizeof(LNode));
if (!L) exit(OVERFLOW);
L->next = NULL;
return OK;
}
//输入元素
LinkList InputList()
{
int n;
LinkList L;
CreatList(L);
LNode *p = L;
scanf("%d",&n);
while (n >= 0)
{
LNode *temp = (LNode*)malloc(sizeof(LNode));
temp->data = n;
p->next = temp;
p = temp;
scanf("%d",&n);
p->next = NULL;
}
return L;
}
void Print_K(LinkList L,int k)
{
LNode *p = L->next;
LNode *q = L->next;
int flag = 1;
while (p->next != NULL && flag < k)
{
p = p->next;
flag++;
}
while (p->next != NULL)
{
p = p->next;
q = q->next;
}
if (flag<k) printf("NULL");
else printf("%d",q->data);
}
Legalidad de la operación de pila 7X7-1
Supongamos que S y X representan operaciones push y pop respectivamente. Si se opera una pila vacía basándose en una secuencia que consta sólo de S y Escriba un programa para ingresar las secuencias S y X para determinar si la secuencia es legal.
Formato de entrada:
La primera línea de entrada proporciona dos números enteros positivos N y M, donde N es el número de secuencias que se van a probar y M (≤50) es la capacidad máxima de la pila. Luego hay N líneas, cada una de las cuales da una secuencia que consta únicamente de S y X. Se garantiza que la secuencia no estará vacía y que la longitud no excederá 100.
Formato de salida:
Para cada secuencia, imprima SÍ en una línea si la secuencia es una secuencia legal de operaciones de pila, o NO si no lo es.
Ejemplo de entrada:
4 10
SSSXXSXXSX
SSSXXSXXS
SSSSSSSSSSXSSXXXXXXXXXXX
SSSXXSXXX
Muestra de salida:
YES
NO
NO
NO
Código:
/*
思路:定义一个栈,栈的容量就是待输入的m,如果输入s,那么栈顶指针后移,如果输入x,那么栈顶指针前移
如果栈顶指针超过栈底指针+栈容量,返回ERROR;
如果栈顶指针小于栈底指针,返回ERROR;
如果输入结束时,栈顶指针不等于栈底指针,返回ERROR;
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct Stack
{
int *base;
int *top;
int Stacksize;
}Stack;
Status InitStack(Stack &S,int len)
{
S.base = (int *)malloc(len * sizeof(int));
if (!S.base) exit(OVERFLOW);
S.top = S.base;
S.Stacksize = len;
return OK;
}
Status ClearStack(Stack &S)
{
S.top = S.base;
return OK;
}
int main()
{
Stack S;
string s;
int n,m;
scanf("%d %d",&n,&m);
InitStack(S,m);
int flag = 0;
while (n--)
{
cin>>s;
int len = s.length();
for (int i=0; i<len; i++)
{
if (s[i] == 'S') S.top++;
else if (s[i] == 'X') S.top--;
if (S.top > S.base + S.Stacksize || S.top < S.base) flag++;
if (i == len - 1 && S.top != S.base) flag++;
}
if (!flag) printf("YES\n");
else
{
printf("NO\n");
flag = 0;
}
ClearStack(S);
}
}
Emparejamiento de símbolos 7X7-2
Escriba un programa para comprobar si los siguientes símbolos en el programa fuente en lenguaje C coinciden: / y /, (y), [y], {y}.
Formato de entrada:
La entrada es un programa fuente en lenguaje C. Cuando solo hay un punto y un retorno de carro en una determinada línea, marca el final de la entrada. No es necesario comprobar que coincidan más de 100 símbolos en el programa.
Formato de salida:
Primero, si todos los símbolos están emparejados correctamente, imprima SÍ en la primera línea; de lo contrario, imprima NO. El primer símbolo no emparejado se indica entonces en la segunda línea: si falta el símbolo de la izquierda, se emite el símbolo ? - derecho; si falta el símbolo de la derecha, se emite el símbolo de la izquierda - ?.
Ejemplo de entrada 1:
void test()
{
int i, A[10];
for (i=0; i<10; i++) /*/
A[i] = i;
}
.
Muestra de salida 1:
NO
/*-?
Ejemplo de entrada 2:
void test()
{
int i, A[10];
for (i=0; i<10; i++) /**/
A[i] = i;
}]
.
Muestra de salida 2:
NO
?-]
Ejemplo de entrada 3:
void test()
{
int i
double A[10];
for (i=0; i<10; i++) /**/
A[i] = 0.1*i;
}
.
Muestra de salida 3:
YES
Código:
/*
思路:定义一个栈,然后读入字符,只要没有同时遇到.和回车就判断是不是给定的符号,要是左半部分就存入栈,要是右半部分就出栈,如果二者对应即匹配
否则,即为不匹配。如果不匹配的话,输出对应缺少部分
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define STACK_INIT_SIZE 100
#define STACK_ADDSIZE 10
typedef int Status;
typedef struct Stack
{
char *top;
char *base;
int StackSize;
}Stack;
Status InitStack(Stack &S); //初始化栈
Status push(Stack &S,char ch); //往栈中压入元素
Status Pop(Stack &S); //弹出元素
Status GetTop(Stack &S,char &temp); //获取栈顶元素
void Right(char ch); //检查是否配对
int main()
{
Stack S;
InitStack(S);
char a[110];
int flag = 1;
while (cin>>a)
{
if (a[0] == '.') break;
int len = strlen(a);
for (int i=0;i<len;i++)
{
if (a[i] == '(' || a[i] == '[' || a[i] == '{')
push(S,a[i]);
else if (a[i] == '/' && a[i+1] == '*' && i+1<len) //特殊处理有两个字符出现的/**/,使用@代替
{
i++;
push(S,'@');
}
else if (a[i] == ')')
{
if(S.top!=S.base) //栈不为空
{
char temp;
GetTop(S,temp);
if(temp == '(') Pop(S); //符号匹配,出栈
else if(flag) //符号不匹配
{
cout<<"NO"<<endl;
flag = 0;
Right(temp);
}
}
else if(flag) //栈空并且从未输出的情况,缺少左符号
{
cout<<"NO"<<endl;
flag = 0;
cout<<"?-)"<<endl;
}
}
else if (a[i] == ']')
{
if(S.top != S.base)//如果栈不空
{
char temp;
GetTop(S,temp);
if(temp == '[') Pop(S);
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
Right(temp);
}
}
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
cout<<"?-]"<<endl;
}
}
else if (a[i] == '}')
{
if(S.top!=S.base)//如果栈不空
{
char temp;
GetTop(S,temp);
if(temp == '{') Pop(S);
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
Right(temp);
}
}
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
cout<<"?-}"<<endl;
}
}
else if(a[i]=='*' && a[i+1]=='/' && i+1<len)
{
i++;
if(S.top!=S.base)
{
char temp;
GetTop(S,temp);
if(temp == '@')
Pop(S);
else if(flag)
{
cout<<"NO"<<endl;
flag=0;
Right(temp);
}
}
else if(flag)
{
cout<<"NO"<<endl;
flag=0;
cout<<"?-*/"<<endl;
}
}
}
}
if(flag) //从未有过输出符号的情况
{
if(S.base == S.top) //没出现过符号或者符号都出栈,匹配成功
cout<<"YES"<<endl;
else //有剩余符号
{
char temp;
GetTop(S,temp);
cout<<"NO"<<endl;
Right(temp);
}
}
}
Status InitStack(Stack &S)
{
S.base = (char *)malloc(STACK_INIT_SIZE * sizeof(char));
if (!S.base) exit(OVERFLOW);
S.top = S.base;
S.StackSize = STACK_INIT_SIZE;
return OK;
}
Status push(Stack &S,char ch)
{
if (S.top == S.base + STACK_INIT_SIZE)
{
S.base = (char*)realloc(S.base,(STACK_INIT_SIZE + STACK_ADDSIZE) * sizeof(char));
if (!S.base) exit(OVERFLOW);
S.top = S.base + S.StackSize;
S.StackSize += STACK_ADDSIZE;
return OK;
}
*S.top = ch;
S.top++;
return OK;
}
Status Pop(Stack &S)
{
if (S.base == S.top) return ERROR;
S.top--;
return OK;
}
Status GetTop(Stack &S,char &temp)
{
if (S.top == S.base)
return ERROR;
temp = *(S.top - 1);
return OK;
}
void Right(char ch)
{
if(ch == '(')
cout<<"(-?"<<endl;
else if(ch == '[')
cout<<"[-?"<<endl;
else if(ch == '{')
cout<<"{-?"<<endl;
else if(ch == '@')//用@代替/*
cout<<"/*-?"<<endl;
}
/*
补充:(1)注意GetTop()函数中temp用于带回值,必须加上引用
(2)比较特殊的是注释符号,这也决定了字符的输入先用数组存起来才能判断下一位是否为*,然后用@代替整体的注释符
(3)缺少左右符号时第一位还得输出?-或者-?,所以需要用到标记变量判断是否是第一次或者最后一次输出
(4)缺少右符号的情况就是栈中有元素但是与当前元素不匹配,缺少左符号是栈为空,但此时还有符号等待匹配
*/
8X8-1 implementa recursivamente una función exponencial
Esta pregunta requiere la implementación de una función que calcule xn (n≥1).
Definición de interfaz de función:
double calc_pow( double x, int n );
La función calc_pow debería devolver el valor de x elevado a la enésima potencia. Se recomienda utilizar recursividad. La pregunta garantiza que el resultado está dentro del rango de doble precisión.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
double calc_pow( double x, int n );
int main()
{
double x;
int n;
scanf("%lf %d", &x, &n);
printf("%.0f\n", calc_pow(x, n));
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
2 3
Muestra de salida:
8
Código:
double calc_pow( double x, int n )
{
if (n == 1) return x;
else return x * calc_pow(x,n-1);
}
8X8-2 calcula recursivamente la función de Ackermenn
Esta pregunta requiere el cálculo de la función de Ackermenn, cuya función se define de la siguiente manera:
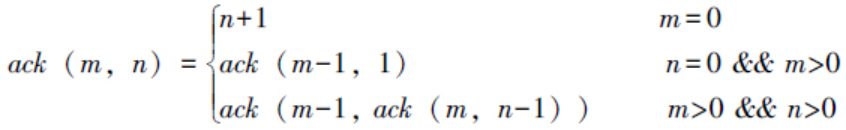
Definición de interfaz de función:
int Ack( int m, int n );
Donde myn son números enteros no negativos pasados por el usuario. La función Ack devuelve el valor correspondiente de la función Ackermenn. La pregunta garantiza que tanto la entrada como la salida estén en tipo entero largo.
dentro del rango.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
int Ack( int m, int n );
int main()
{
int m, n;
scanf("%d %d", &m, &n);
printf("%d\n", Ack(m, n));
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
2 3
Muestra de salida:
9
Código:
int Ack( int m, int n )
{
if (m == 0) return n+1;
else if(n == 0 && m>0) return Ack(m-1,1);
else if (m>0 && n>0) return Ack(m-1,Ack(m,n-1));
}
8X8-3 encuentra recursivamente la secuencia de Fabonacci
Esta pregunta requiere la implementación de una función que encuentre los términos de la secuencia de Fabonacci. La definición de la secuencia de Fabonacci es la siguiente:
f(n)=f(n−2)+f(n−1) (n≥2),其中f(0)=0,f(1)=1。
Definición de interfaz de función:
int f( int n );
La función f debería devolver el enésimo número de Fabonacci. La pregunta asegura que la entrada y la salida estén dentro del rango de enteros largos. Se recomienda utilizar recursividad.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
int f( int n );
int main()
{
int n;
scanf("%d", &n);
printf("%d\n", f(n));
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
6
Muestra de salida:
8
Código:
int f( int n )
{
if (n == 0) return 0;
else if (n == 1) return 1;
else return f(n-1) + f(n-2);
}
Conversión de decimal a binario 8X8-4
Esta pregunta requiere la implementación de una función para convertir un número entero positivo n en binario y luego generarlo.
Definición de interfaz de función:
void dectobin( int n );
La función dectobin debería imprimir el binario n en una línea. Se recomienda utilizar recursividad.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
void dectobin( int n );
int main()
{
int n;
scanf("%d", &n);
dectobin(n);
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
10
Muestra de salida:
1010
Código:
void dectobin( int n )
{
if (n == 0 || n == 1) printf("%d",n);
else
{
dectobin(n/2);
printf("%d",n%2);
}
}
8X8-5 calcula recursivamente la función P
Esta pregunta requiere el cálculo de la siguiente función P(n,x), cuya definición de función es la siguiente:
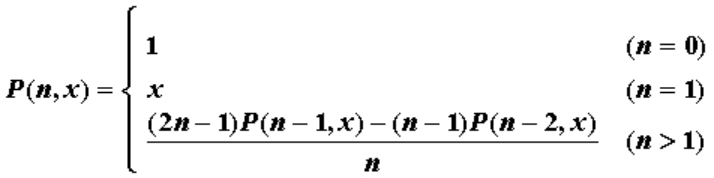
Definición de interfaz de función:
double P( int n, double x );
Donde n es un número entero no negativo pasado por el usuario y x es un número de punto flotante de doble precisión. La función P devuelve el valor correspondiente de la función P(n,x). La pregunta asegura que la entrada y la salida estén dentro del rango de doble precisión.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
double P( int n, double x );
int main()
{
int n;
double x;
scanf("%d %lf", &n, &x);
printf("%.2f\n", P(n,x));
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada:
10 1.7
Muestra de salida:
3.05
Código:
double P( int n, double x )
{
if (n == 0) return 1;
else if (n == 1) return x;
else return ((2*n-1)*P(n-1,x) - (n-1)*P(n-2,x))/n;
}
El entero 8X8-6 se descompone en la suma de varios términos
Para descomponer un número entero positivo N en varios números enteros positivos y sumarlos, existen muchos métodos de descomposición, como 7=6+1, 7=5+2, 7=5+1+1,…. Programa para encontrar todas las fórmulas de descomposición de números enteros positivos N.
Formato de entrada:
Cada entrada contiene un caso de prueba, que es un número entero positivo N (0<N≤30).
Formato de salida:
Genere todas las descomposiciones de números enteros de N en orden creciente. El orden creciente significa: para las dos secuencias de descomposición N1={n1,n2,⋯} y N2={m1,m2 ,⋯}, si existe i tal que n1=m1,⋯,nii=mii, pero nii+1<mii+1 , entonces la secuencia N1debe generarse antes que la secuencia N2. Cada fórmula se agrega de menor a mayor, las fórmulas se separan por punto y coma y se genera una nueva línea después de cada 4 fórmulas.
Ejemplo de entrada:
7
Muestra de salida:
7=1+1+1+1+1+1+1;7=1+1+1+1+1+2;7=1+1+1+1+3;7=1+1+1+2+2
7=1+1+1+4;7=1+1+2+3;7=1+1+5;7=1+2+2+2
7=1+2+4;7=1+3+3;7=1+6;7=2+2+3
7=2+5;7=3+4;7=7
Código:
/*
思路:如果n等于0,直接输出等号以及前边部分
如果n不等于0,依次递增分解输出,并且输出长度未分解的时候最小,越分解长度越大
*/
#include <bits/stdc++.h>
using namespace std;
int Num[35]; //存储分解的值
int N; //将最初输入的值保存下来以便等号前边的输出
int flag = 0; //控制换行符的输出
int k = 1; //用于控制初始不变的输出分解值
void Print(int len)
{
for (int i=0;i<len;i++)
{
if (i==0) printf("%d",Num[i]);
else printf("+%d",Num[i]);
}
}
int Decompose(int n,int len)
{
//递归边界
if (n<=0)
{
if (flag == 4) //每四个式子输出一个换行符
{
printf("\n");
flag = 0;
}
flag++;
if (flag == 1) //控制分号的输出
{
printf("%d=",N);
Print(len);
}
else
{
printf(";%d=",N);
Print(len);
}
return 0;
}
//递归条件
for (int i=1;i<=n;i++)
{
if (i>=k)
{
Num[len] = i;
k = i;
Decompose(n-i,len+1);
k = i; //回归到前边应该输出的数字
}
}
}
int main()
{
int n;
scanf("%d",&n);
N = n; //用于记录初始值
Decompose(n,0);
return 0;
}
Disposición completa de salida 8X8-7
Escriba un programa para generar la disposición completa de los primeros n enteros positivos (n <10) y observe el tiempo de ejecución del programa cuando n aumenta gradualmente a través de 9 casos de prueba (es decir, n de 1 a 9).
Formato de entrada:
La entrada se proporciona como un número entero positivo n (<10).
Formato de salida:
Genera todas las permutaciones de 1 a n. Cada permutación ocupa una línea, sin espacios entre números. El orden de salida de la disposición es el orden del diccionario, es decir, la secuencia a1,a2,⋯,ann se clasifica en la secuencia b1,b2 ,⋯,bn Previamente, si existe k tal que a1=b1,⋯,ak=bk y ak+1< bk+1.
Ejemplo de entrada:
3
Muestra de salida:
123
132
213
231
312
321
Código:
/*
思路:(1)把n之前的所有数字存入一个数组。
(2)从第一个数字开始,以第一个数字为首元素一共排列n个数字
(3)以第一个数字为首排列完成后,将第一个数字和第二个数字交换,重复(2)的操作
(4)以此类推,直到为首的数字是最后一个数字
注意:排列的输出顺序为字典顺序
*/
#include <bits/stdc++.h>
using namespace std;
int a[15];
void Swap(int &m,int &n)
{
int temp;
temp = m;
m = n;
n = temp;
}
//用于排列数组顺序使其按照字典序输出
void Sort(int a[],int start,int end)
{
for (int i=start;i<=end;i++)
{
for (int j = i;j<=end;j++)
{
if (a[i]>a[j])
{
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
}
void Array(int a[],int start,int n)
{
if (start == n)
{
for (int i=1;i<=n;i++)
printf("%d",a[i]);
printf("\n");
}
else
{
for (int i=start;i<=n;i++)
{
Sort(a,start,n);
Swap(a[start],a[i]); //为首的数字进行交换
Array(a,start+1,n);
Swap(a[start],a[i]); //进行下一个全排列的时候将上一次交换的数字归位
}
}
}
int main()
{
int n;
cin>>n;
for (int i = 1;i<=n;i++)
a[i] = i;
Array(a,1,n);
}
8X8-8 Encuentra el valor de la expresión del prefijo.
Las expresiones aritméticas vienen en forma de notación de prefijo, notación de infijo y notación de posfijo. Una expresión de prefijo significa que el operador binario se coloca antes de los dos operandos. Por ejemplo, la expresión de prefijo de 2+3*(7-4)+8/4 es: + + 2 * 3 - 7 4 / 8 4. Diseñe un programa para calcular el valor resultante de la expresión del prefijo.
Formato de entrada:
Ingrese una expresión de prefijo de no más de 30 caracteres en una línea, incluidos solo +, -, *, / y operandos. Los diferentes objetos (operandos, símbolos de operación) están separados por espacios.
Formato de salida:
Genere el resultado de la operación de la expresión de prefijo, conservando 1 dígito después del punto decimal, o el mensaje de error ERROR.
Ejemplo de entrada:
+ + 2 * 3 - 7 4 / 8 4
Muestra de salida:
13.0
Código:
/*
思路:只要字符串中是数字字符,就把字符转化成数字;
只要遇见运算符就按照运算规则进行运算;
只要有两个及以上的运算符,先把第一个数字运算上后边整个剩下字符串,直至只有一个数字
注意:(1)运算出来的结构是保留一位小数的double型;
(2)分母为零的情况返回ERROR,并且直接退出程序
(3)判断数字前边是否带有正负号
*/
#include <bits/stdc++.h>
using namespace std;
double Prefix()
{
char str[30];
scanf("%s",str);
if (!str[1]) //判断数字前边是否有符号
{
if (str[0] == '+')
return Prefix() + Prefix();
else if (str[0] == '-')
return Prefix() - Prefix();
else if (str[0] == '*')
return Prefix() * Prefix();
else if (str[0] == '/')
{
double mol = Prefix();
double den = Prefix();
if (den != 0) return mol / den;
else
{
printf("ERROR");
exit(0); //不能用return 0代替,exit(0)强制退出程序
}
}
else return atof(str); //应当将数字字符直接转化成浮点数,不能用str[0]-'0'
}
else //数字前边有符号的情况
{
if (str[0] == '-' || str[0] == '+')
{
char flag = str[0]; //先把数字符号记录下来,然后依次用后边的覆盖前边字符
int i = 0;
while (str[i])
{
str[i] = str[i+1];
i++;
}
if (flag == '-') return 0 - atof(str);
else return atof(str);
}
else return atof(str);
}
}
int main()
{
printf("%.1f",Prefix());
return 0;
}
Simulación simple de la cola de negocios bancarios 9X9-1
Supongamos que un banco tiene dos ventanas comerciales, A y B, y las velocidades de procesamiento son diferentes. La velocidad de procesamiento de la ventana A es el doble que la de la ventana B, es decir, cuando la ventana A termina de procesar 2 clientes, la ventana B termina de procesar 1 cliente. cliente. Dada una secuencia de clientes que llegan al banco, genere la secuencia de clientes en el orden en que se completa el negocio. Se supone que no se considera el intervalo de tiempo entre los clientes que llegan uno tras otro, y cuando dos clientes se procesan en diferentes ventanas al mismo tiempo, los clientes de la ventana A salen primero.
Formato de entrada:
La entrada es una fila de números enteros positivos, donde el primer número N (≤1000) es el número total de clientes, seguido del número de N clientes. Los clientes con números impares deben ir a la ventana A para gestionar el negocio, y los clientes con números pares deben ir a la ventana B. Separe los números con espacios.
Formato de salida:
Genere el número de cliente en el orden en que se completa el procesamiento comercial. Los números deben estar separados por espacios, pero no deben haber espacios adicionales después del último número.
Ejemplo de entrada:
8 2 1 3 9 4 11 13 15
Muestra de salida:
1 3 2 9 11 4 13 15
Código:
/*
思路:先把所有输入的数据按照奇偶数分别插入到两个队列里,并分别计数。然后循环删除队列元素,A队列每删除一个,B队列删除两个,并且计数器对应相减,直到一方为0
注意:两边窗口有特殊人数需要特殊处理
(1)A有两人以上 :一般处理
(2)A只有一人 :A出一个,B出一个
(3)有一边窗口没有人 :直接让一边的队列元素出队即可
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
typedef int Status;
typedef int Elemtype;
typedef struct QNode
{
Elemtype data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct
{
QueuePtr front;
QueuePtr rear;
} LinkQueue;
Status InitLinkQueue(LinkQueue &Q); //初始化队列
Status InsetLinkQueue(LinkQueue &Q,Elemtype n); //向队列中插入元素
Status DeleteLinkQueue(LinkQueue &Q,Elemtype &e);//删除队列元素,同时带回(注意引用)
int main()
{
LinkQueue A;
LinkQueue B;
InitLinkQueue(A);
InitLinkQueue(B);
int n,number;
int flag = 0; //控制输出格式
int countA = 0,countB = 0;
cin>>n;
for (int i = 0;i<n;i++) //将所有编号存起来
{
cin>>number;
if (number % 2 == 0) //奇数在A,偶数在B
{ InsetLinkQueue(B,number); countB++;}
else { InsetLinkQueue(A,number); countA++;}
}
while (countA && countB) //当两边窗口都有人的时候
{
int a,b,c;
if (countA >= 2 && countB >= 1)
{
DeleteLinkQueue(A,a); //根据题目窗口处理效率出队
DeleteLinkQueue(A,b);
DeleteLinkQueue(B,c);
countA -= 2;
countB--;
if (!flag) {cout<<a<<" "<<b<<" "<<c;flag = 1;}
else {cout<<" "<<a<<" "<<b<<" "<<c;}
}
else if (countA == 1 && countB >= 1) //特殊:A窗口不足两个人,所以只能A出一个,B出一个
{
DeleteLinkQueue(A,a);
DeleteLinkQueue(B,b);
countA--;
countB--;
if (!flag) {cout<<a<<" "<<b;flag = 1;}
else {cout<<" "<<a<<" "<<b;}
}
}
while (countA) //只有A窗口有人
{
int a;
DeleteLinkQueue(A,a);
countA--;
if (!flag) {cout<<a;flag = 1;}
else {cout<<" "<<a;}
}
while (countB) //只有B窗口有人
{
int a;
DeleteLinkQueue(B,a);
countB--;
if (!flag) {cout<<a;flag = 1;}
else {cout<<" "<<a;}
}
}
Status InitLinkQueue(LinkQueue &Q)
{
Q.front = Q.rear = (QueuePtr)malloc(sizeof(QNode));
if (!Q.front) exit(OVERFLOW);
Q.front->next = NULL; //注意!!!
return OK;
}
Status InsetLinkQueue(LinkQueue &Q,Elemtype n)
{
QueuePtr p;
p = (QNode *)malloc(sizeof(QNode));
if (!p) exit(OVERFLOW);
p->data = n;
p->next = NULL;
Q.rear->next = p;
Q.rear = p;
return OK;
}
Status DeleteLinkQueue(LinkQueue &Q,Elemtype &e)
{
if (Q.front == Q.rear) return ERROR;
QueuePtr p = Q.front->next; //队列是先进先出,所以要指向队头
e = p->data;
Q.front->next = p->next;
if (Q.rear == p) Q.rear = Q.front;
free(p);
return OK;
}
Encuentre la profundidad y el número de hojas de un árbol binario 11X11-1
Escriba una función para calcular la profundidad de un árbol binario y el número de nodos de hoja. El árbol binario utiliza una estructura de almacenamiento de lista vinculada binaria.Definición
de interfaz de función:
int GetDepthOfBiTree ( BiTree T);
int LeafCount(BiTree T);
Donde T es el parámetro pasado por el usuario, que indica la dirección del nodo raíz del árbol binario. La función devolverá la profundidad (también llamada altura) del árbol binario.
Ejemplo de procedimiento de prueba de árbitro:
//头文件包含
#include<stdlib.h>
#include<stdio.h>
#include<malloc.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define INFEASIBLE -2
#define NULL 0
typedef int Status;
//二叉链表存储结构定义
typedef int TElemType;
typedef struct BiTNode{
TElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
//创建二叉树各结点,输入零代表创建空树
//采用递归的思想创建
//递归边界:空树如何创建呢:直接输入0;
//递归关系:非空树的创建问题,可以归结为先创建根节点,输入其数据域值;再创建左子树;最后创建右子树。左右子树递归即可完成创建!
Status CreateBiTree(BiTree &T){
TElemType e;
scanf("%d",&e);
if(e==0)T=NULL;
else{
T=(BiTree)malloc(sizeof(BiTNode));
if(!T)exit(OVERFLOW);
T->data=e;
CreateBiTree(T->lchild);
CreateBiTree(T->rchild);
}
return OK;
}
//下面是需要实现的函数的声明
int GetDepthOfBiTree ( BiTree T);
int LeafCount(BiTree T);
//下面是主函数
int main()
{
BiTree T;
int depth, numberOfLeaves;
CreateBiTree(T);
depth= GetDepthOfBiTree(T);
numberOfLeaves=LeafCount(T);
printf("%d %d\n",depth,numberOfLeaves);
}
/* 请在这里填写答案 */
Ejemplo de entrada:
1 3 0 0 5 7 0 0 0
Muestra de salida:
3 2
Código:
//求树的深度
int GetDepthOfBiTree ( BiTree T)
{
if (T == NULL) return 0;
int depth1 = GetDepthOfBiTree(T->lchild);
int depth2 = GetDepthOfBiTree(T->rchild);
if (depth1>depth2) return depth1 + 1;
else return depth2 + 1;
}
//求叶子节点数
int LeafCount(BiTree T)
{
if (T == NULL) return 0;
if (T->lchild == NULL && T->rchild == NULL)
return 1;
else return LeafCount(T->lchild) + LeafCount(T->rchild);
}
Encuentre el número de nodos en el árbol binario 11X11-2
Escriba una función para contar el número de nodos en un árbol binario. Los árboles binarios utilizan estructuras de almacenamiento de listas enlazadas binarias.
Definición de interfaz de función:
int NodeCountOfBiTree ( BiTree T);
donde T es la dirección del nodo raíz del árbol binario.
Ejemplo de procedimiento de prueba de árbitro:
//头文件包含
#include<stdlib.h>
#include<stdio.h>
#include<malloc.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define INFEASIBLE -2
typedef int Status;
//二叉链表存储结构定义
typedef int TElemType;
typedef struct BiTNode{
TElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
//创建二叉树各结点,输入0代表创建空树。
//采用递归的思想创建
//递归边界:空树如何创建呢:直接输入0;
//递归关系:非空树的创建问题,可以归结为先创建根节点,输入其数据域值;再创建左子树;最后创建右子树。左右子树递归即可完成创建!
Status CreateBiTree(BiTree &T){
TElemType e;
scanf("%d",&e);
if(e==0)T=NULL;
else{
T=(BiTree)malloc(sizeof(BiTNode));
if(!T)exit(OVERFLOW);
T->data=e;
CreateBiTree(T->lchild);
CreateBiTree(T->rchild);
}
return OK;
}
//下面是需要实现的函数的声明
int NodeCountOfBiTree ( BiTree T);
//下面是主函数
int main()
{
BiTree T;
int n;
CreateBiTree(T); //先序递归创建二叉树
n= NodeCountOfBiTree(T);
printf("%d",n);
return 0;
}
/* 请在这里填写答案 */
Ejemplo de entrada (tenga en cuenta que ingresar 0 representa un subárbol vacío):
1 3 0 0 5 3 0 0 0
Muestra de salida:
4
Código:
int NodeCountOfBiTree ( BiTree T)
{
if (T == NULL) return 0;
else return NodeCountOfBiTree(T->lchild) + NodeCountOfBiTree(T->rchild) + 1;
}
12X12-1 genera un recorrido de pedido anticipado basado en un recorrido de pedido posterior y en orden
Esta pregunta requiere generar los resultados del recorrido de preorden de un árbol binario determinado en función de los resultados del recorrido de postorden y del recorrido en orden del árbol.
Formato de entrada:
La primera línea da un número entero positivo N (≤30), que es el número de nodos en el árbol. Cada una de las dos líneas siguientes proporciona N números enteros, correspondientes a los resultados del recorrido posterior al orden y del recorrido en orden, respectivamente. Los números están separados por espacios. La pregunta asegura que la entrada corresponde correctamente a un árbol binario.
Formato de salida:
Preorden de salida: y los resultados del recorrido del árbol en preorden en una línea. Debe haber 1 espacio entre los números y ningún espacio adicional al final de la línea.
Ejemplo de entrada:
7
2 3 1 5 7 6 4
1 2 3 4 5 6 7
Muestra de salida:
Preorder: 4 1 3 2 6 5 7
Código:
/*
思路:使用递归方法,只要得出根节点、左子树和右子树即可
递归边界:输入的个数N<=0的时候返回
递归关系:先找到后序遍历数组中的最后一位在中序遍历中的位置,这就是根节点,根节点的左侧是左子树,右侧是右子树
然后按照递归的思想,继续分别构造左子树和右子树的根节点、左子树和右子树
*/
//头文件包含
#include<stdlib.h>
#include<stdio.h>
#include<malloc.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define INFEASIBLE -2
typedef int Status;
typedef int TElemType;
typedef struct BiNode
{
TElemType data;
struct BiNode *lchild, *rchild;
}BiNode, *BiTree;
BiTree Create(int *Post,int *In,int N)
{
//递归边界
if (N <= 0) return NULL;
//递归关系
int *p = In; //定义一个指针用来遍历中序序列
while (*p != *(Post + N -1))
p++; //找到后序序列的最后一位,即根节点
BiTree T;
T = (BiTree)malloc(sizeof(BiNode));
T->data = *p;
int len = p - In; //找到根节点位置左边有几位数字,即左子树
T->lchild = Create(Post,In,len);
T->rchild = Create(Post + len,p + 1,N - len -1);
return T;
}
void Print(BiTree T)
{
if (T)
{
printf(" %d",T->data);
Print(T->lchild);
Print(T->rchild);
}
return ;
}
int main()
{
int N;
int *Post, *In;
scanf("%d",&N);
Post = (int*)malloc(N * sizeof(int));
In = (int*)malloc(N * sizeof(int));
for (int i=0; i<N; i++)
scanf("%d",&Post[i]);
for (int i=0; i<N; i++)
scanf("%d",&In[i]);
BiTree T = Create(Post,In,N);
printf("Preorder:");
Print(T);
free(Post);
free(In);
return 0;
}
Procesamiento de árbol genealógico 13X13-1
La investigación antropológica está muy interesada en las familias, por lo que los investigadores recopilaron genealogías de algunas familias para estudiarlas. En el experimento se utilizaron ordenadores para procesar árboles genealógicos. Para lograrlo, los investigadores convirtieron árboles genealógicos en archivos de texto. El siguiente es un ejemplo de un archivo de texto de árbol genealógico:
John
Robert
Frank
Andrew
Nancy
David
En un archivo de texto de árbol genealógico, cada línea contiene el nombre de una persona. El nombre en la primera línea es el antepasado más antiguo de la familia. Un árbol genealógico contiene sólo los descendientes de los primeros antepasados, y sus maridos o esposas no aparecen en el árbol genealógico. Los hijos de cada persona tienen una sangría de 2 espacios más que sus padres. Tomando como ejemplo el archivo de texto de genealogía anterior, John, el antepasado más antiguo de la familia, tiene dos hijos, Robert y Nancy, Robert tiene dos hijos, Frank y Andrew, y Nancy tiene un solo hijo, David.
En el experimento, los investigadores también recopilaron documentos familiares y extrajeron declaraciones sobre la relación entre dos personas del árbol genealógico. Los siguientes son ejemplos de declaraciones declarativas sobre relaciones en un árbol genealógico:
John is the parent of Robert
Robert is a sibling of Nancy
David is a descendant of Robert
El investigador necesita juzgar si cada afirmación es verdadera o falsa. Escriba un programa para ayudar al investigador a juzgar.
Formato de entrada:
La entrada primero proporciona dos números enteros positivos N (2≤N≤100) y M (≤100), donde N es el número de nombres en el árbol genealógico y M es el número de declaraciones en el árbol genealógico. Cada línea de entrada debe no exceder los 70 caracteres.
La cadena de nombre consta de no más de 10 letras en inglés. No hay espacios sangrados antes del nombre dado en la primera línea del árbol genealógico. Otros nombres en el árbol genealógico tienen una sangría de al menos 2 espacios, es decir, son descendientes del antepasado más antiguo del árbol genealógico (el nombre dado en la primera línea), y si un nombre en el árbol genealógico tiene una sangría de k espacios antes, el nombre en la siguiente línea debe tener como máximo sangría k+2 espacios.
El mismo nombre no aparecerá dos veces en un árbol genealógico y los nombres que no aparecen en el árbol genealógico no aparecerán en las declaraciones. El formato de cada declaración es el siguiente, donde X e Y son nombres diferentes en el árbol genealógico:
X is a child of Y
X is the parent of Y
X is a sibling of Y
X is a descendant of Y
X is an ancestor of Y
Formato de salida:
Para cada declaración en el caso de prueba, genere Verdadero, si la declaración es verdadera, o Falso, si la declaración es falsa, en una línea.
Ejemplo de entrada:
6 5
John
Robert
Frank
Andrew
Nancy
David
Robert is a child of John
Robert is an ancestor of Andrew
Robert is a sibling of Nancy
Nancy is the parent of Frank
John is a descendant of Andrew
Muestra de salida:
True
True
True
False
False
Código:
#include <bits/stdc++.h>
using namespace std;
struct people
{
char name[15]; //结点名字
char father[15]; //双亲名字
int num; //空格数
}People[101];
void Gets(char temp[])
{
int i = 0;
scanf("%c",&temp[0]);
while (temp[i] != '\n')
{i++;scanf("%c",&temp[i]);}
temp[i] = '\0';
}
int main()
{
int N; //家谱中名字的数量
int M; //判断家谱关系的语句
char temp[75]; //用来临时存储输入的名字和空格,注意名字不超过10个字符,但是还有空格,要把数组开大一点
scanf("%d %d",&N,&M);
getchar(); //注意接下来输入的是字符串,要用getchar把回车吃掉
for (int i = 0; i < N; i++)
{
memset(temp,'0',sizeof(temp));
People[i].num = 0; //先把家谱数组中所有的名字初始化
Gets(temp);
int L = strlen(temp);
for (int j = 0; j < L; j++)
{
if (temp[j] == ' ')
People[i].num++; //记录空格的个数,以便于判断家族关系
else
{
strcpy(People[i].name, temp + j); //把空格之后的名字复制下来
break;
}
}
if (!People[i].num)
strcpy(People[i].father, "root"); //空格数为0则表示根
else
{
for (int k = i-1; k >= 0; k--) //从后往前寻找父节点
{
if (People[i].num > People[k].num)
{
strcpy(People[i].father,People[k].name);
break;
}
}
}
}
char a[15], b[15], c[15], d[15]; //用来存储输入判断语句,a和c分别对应前后两个人名,b表示等待判断的关系
char temp1[15], temp2[15];
for (int i = 0; i < M; i++)
{
scanf("%s %s %s %s %s %s",a,d,d,b,d,c);
if (b[0] == 'c')
{
//X是Y的孩子
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,a)) //首先在数组中找到a,然后判断c是否与a的father一致
{
if (!strcmp(People[k].father,c))
printf("True\n");
else printf("False\n");
break;
}
}
}
else if (b[0] == 'p')
{
//X是Y的双亲
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,c))
{
if (!strcmp(People[k].father,a))
printf("True\n");
else printf("False\n");
break;
}
}
}
else if (b[0] == 's')
{
//X是Y的兄弟
for (int k = 0; k < N; k++)
{
//寻找两个结点的父节点
if (!strcmp(People[k].name,a))
strcpy(temp1,People[k].father);
if (!strcmp(People[k].name,c))
strcpy(temp2,People[k].father);
}
if (!strcmp(temp1,temp2)) printf("True\n");
else printf("False\n");
}
else if (b[0] == 'd')
{
//X是Y的子孙
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,a))
strcpy(temp1,People[k].father);
}
while (strcmp(temp1,c) && strcmp(temp1,"root"))
{
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,temp1))
strcpy(temp1,People[k].father);
}
}
if (!strcmp(temp1,"root"))
printf("False\n");
else printf("True\n");
}
else if (b[0] == 'a')
{
//X是Y的祖先
for (int k = 0; k < N; k++ )
{
if (!strcmp(People[k].name,c))
strcpy(temp1,People[k].father);
}
while (strcmp(temp1,a) && strcmp(temp1,"root"))
{
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,temp1))
strcpy(temp1,People[k].father);
}
}
if (!strcmp(temp1,"root"))
printf("False\n");
else printf("True\n");
}
}
getchar();
return 0;
}
Codificación Huffman 14X14-1
Dado un fragmento de texto, si contamos la frecuencia de aparición de letras, podemos dar un conjunto de códigos basados en el algoritmo de Huffman, de modo que al usar este código para comprimir el texto original se pueda obtener la longitud total de código más corta. Sin embargo, la codificación de Huffman no es única. Por ejemplo, para la cadena "aaaxuaxz", es fácil obtener las frecuencias de aparición de las letras 'a', 'x', 'u' y 'z' correspondientes a 4, 2, 1 y 1. Podemos diseñar la codificación {'a'=0, 'x'=10, 'u'=110, 'z'=111}, o usar otro conjunto de {'a'=1, 'x'=01, ' u'=001, 'z'=000}, también puedes usar {'a'=0, 'x'=11, 'u'=100, 'z'=101}. Los tres conjuntos de codificación pueden comprimir el texto original a 14 bytes. Pero {'a'=0, 'x'=01, 'u'=011, 'z'=001} no es la codificación de Huffman, porque después de usar esta codificación para comprimir 00001011001001, el resultado de la decodificación no es único. Ambos " aaaxuaxz" y "aazuaxax" pueden corresponder a los resultados de la decodificación. Esta pregunta le pide que juzgue si algún conjunto de códigos es código Huffman.
Formato de entrada:
Primero, la primera línea proporciona un número entero positivo N (2≤N≤63), y luego la segunda línea proporciona N caracteres no repetidos y su frecuencia de aparición. El formato es el siguiente:
c[1] f[1] c[2] f[2] ... c[N] f[N]
donde c[i] es un carácter del conjunto {'0' - '9', 'a' - 'z', 'A' - 'Z', '_'}; f[i] es el carácter de c [i] La frecuencia de aparición es un número entero que no excede 1000. La siguiente línea proporciona un número entero positivo M (≤1000), seguido de M conjuntos de códigos a verificar. Cada conjunto de códigos ocupa N líneas y el formato es:
c[i] código[i]
Donde c[i] es el carácter i-ésimo; código[i] es una cadena no vacía de no más de 63 '0 y '1'.
Formato de salida:
Para cada conjunto de códigos a verificar, si es un código Huffman correcto, escriba "Sí" en una línea; de lo contrario, escriba "No".
Nota: La codificación óptima no se obtiene necesariamente mediante el algoritmo de Huffman. Cualquier codificación de prefijo que se comprima a la longitud óptima se considerará correcta.
Ejemplo de entrada:
7
A 1 B 1 C 1 D 3 E 3 F 6 G 6
4
A 00000
B 00001
C 0001
D 001
E 01
F 10
G 11
A 01010
B 01011
C 0100
D 011
E 10
F 11
G 00
A 000
B 001
C 010
D 011
E 100
F 101
G 110
A 00000
B 00001
C 0001
D 001
E 00
F 10
G 11
Muestra de salida:
Yes
Yes
No
No
Código:
/*
思路:对于给定的字符及其出现的频率,先构建对应霍夫曼树,然后求出对应霍夫曼编码的最大路径长度。
判断是否是正确的霍夫曼编码只要满足前缀规则,并且每一个字符的最大路径长度与最先构建的霍夫曼编码所求出来的长度相等即可。
*/
#include <bits/stdc++.h>
using namespace std;
typedef int Status;
typedef struct HTNode
{
unsigned int weight;
unsigned int parent, lchild, rchild;
} HTNode, *HuffmanTree;
typedef char* *HuffmanCode;
void Select(HuffmanTree &HT, int index, int &s1, int &s2) //在HT数组前index个中选择parent为0,并且权值最小的两个节点,其序号用s1,s2带回
{
int minvalue1, minvalue2;
s1 = s2 = index;
minvalue1 = minvalue2 = 100000; //将最小值设置成无穷大,方便以后比较替换
for(int i = 1; i < index; ++i)
{
if(HT[i].parent == 0)
{
if(HT[i].weight <= minvalue1)
{
minvalue2 = minvalue1;
minvalue1 = HT[i].weight;
s2 = s1;
s1 = i;
}
else if(HT[i].weight <= minvalue2)
{
s2 = i;
minvalue2 = HT[i].weight;
}
}
}
}
int HuffmanCoding(int *w, int n) //已知权值和总数量,构造霍夫曼树,求出编码,并且返回最短路径长度
{
int m = 2 * n - 1;
HuffmanTree HT = (HTNode *)malloc(sizeof(HTNode) * (m + 1));
HuffmanTree p = HT + 1;
w++;
//初始化霍夫曼树
for(int i = 1; i <= n; ++i, ++w, ++p)
{
p->weight = *w;
p->parent = p->lchild = p->rchild = 0;
}
for(int i = n + 1; i <= m; ++i, ++p)
p->weight = p->parent = p->lchild = p->rchild = 0;
p = HT + n + 1;
for(int i = n + 1; i <= m; ++i, ++p)
{
int s1, s2;
Select(HT, i, s1, s2);
p->weight = HT[s1].weight + HT[s2].weight;
p->lchild = s1, p->rchild = s2;
HT[s1].parent = HT[s2].parent = i;
}
int pathnum[n + 1]; //求出每个字符的最大路径长度
for(int i = 1; i <= n; ++i)
{
int length = 0;
for(int cpos = i, ppos = HT[i].parent; ppos != 0; cpos = ppos, ppos = HT[ppos].parent)
length++;
pathnum[i] = length;
}
int min_length = 0;
for(int i = 1; i <= n; i++)
min_length += (pathnum[i] * HT[i].weight);
return min_length;
}
int isUncertain(char Codes[][65], int n) //判断是否符合前缀规则
{
for(int i = 0; i < n; ++i)
for(int j = i + 1; j < n; ++j)
{
int length = strlen(Codes[i]) > strlen(Codes[j]) ? strlen(Codes[j]):strlen(Codes[i]);
int k;
for(k = 0; k < length; ++k)
if(Codes[i][k] != Codes[j][k])
break;
if(k == length)
return 1;
}
return 0;
}
int GetLen(char Codes[][65], int *w, int n)
{
int len = 0;
for(int i = 0; i < n; ++i)
{
int length = strlen(Codes[i]);
len += (length * w[i + 1]);
}
return len;
}
int main()
{
int N, M, W[70];
char ch;
scanf("%d", &N);
getchar();
for(int i =1; i <= N; ++i) //输入字符以及出现的频率,注意空格也是一个字符,在末尾特殊处理
{
if(i <= N - 1)
scanf("%c %d ", &ch, &W[i]);
else
scanf("%c %d", &ch, &W[i]);
}
int min_length = HuffmanCoding(W, N);
scanf("%d", &M);
for(int i = 0; i < M; ++i)
{
char Codes[65][65]; //用来存放等待判断的编码
for(int i = 0; i < N; ++i)
{
getchar(); //吃掉每一行的回车
scanf("%c %s", &ch, Codes[i]);
}
if(isUncertain(Codes, N)) //
printf("No\n");
else
{
if(min_length == GetLen(Codes, W, N))
printf("Yes\n");
else
printf("No\n");
}
}
}
La lista de adyacencia 15X15-1 crea un gráfico no dirigido
Utilice la lista de adyacencia para crear un gráfico no dirigido G y genere los grados de cada vértice por turno.
Formato de entrada:
La primera línea de entrada proporciona dos números enteros i (0<i≤10) y j (j≥0), que son el número de vértices y aristas del gráfico G respectivamente. Ingrese la información del vértice en la segunda línea. Cada vértice solo puede representarse con un carácter. Ingrese j líneas en secuencia e ingrese un vértice adjunto a un borde en cada línea.
Formato de salida:
Genere los grados de cada vértice en secuencia, sin espacios finales al final de la línea.
Ejemplo de entrada:
5 7
ABCDE
AB
AD
BC
BE
CD
CE
DE
Muestra de salida:
2 3 3 3 3
Código:
/*
思路:使用一个结构体类型的数组,一个存放顶点字符,一个边的信息。
顶点按照输入顺序直接存放起来即可。
边要读取两个字符,第一个字符是起点,用来定位到对应顶点;另一个用来存终点下标
*/
#include <bits/stdc++.h>
using namespace std;
#define OK 1;
#define ERROR 0;
typedef int Status;
typedef struct VerNode
{
char ch;
struct VerNode *next;
}VerNode;
typedef struct
{
char V; //顶点
VerNode *start; //存放边的链表
int degree; //顶点的度数
}UDirGraph;
Status Create(UDirGraph graph[],int i,int j)
{
if (i < 0 || j < 0) return ERROR;
for (int k=0;k<i;k++)
{
graph[k].V = '0';
graph[k].start = NULL;
graph[k].degree = 0;
}
return OK;
}
int main()
{
int i, j;
char ch1, ch2;
scanf("%d %d",&i,&j);
getchar();
UDirGraph graph[i+1];
Create(graph,i,j);
for (int k=0; k<i; k++)
scanf("%c",&graph[k].V); //注意不要忘记&
graph[i].V = '\0';
getchar();
for (int k=0; k<j; k++)
{
scanf("%c%c",&ch1,&ch2);
getchar();
int n = 0;
int m = 0;
for (m=0; m<i; m++)
{
if (ch1 == graph[m].V)
{
graph[m].degree++;
for (n=0; n<i; n++)
if (ch2 == graph[n].V)
graph[n].degree++;
}
// printf("==%d==\n",graph[m].degree);
}
}
for (int k=0;k<i;k++)
{
if (k==0) printf("%d",graph[k].degree);
else printf(" %d",graph[k].degree);
}
}
Recorrido en profundidad del gráfico de almacenamiento de matriz de adyacencia 16X16-1
Intente implementar un recorrido en profundidad del gráfico de almacenamiento de la matriz de adyacencia.
Definición de interfaz de función:
void DFS( MGraph Graph, Vertex V, void (*Visit)(Vertex) );
Donde MGraph es el gráfico almacenado por la matriz de adyacencia, definido de la siguiente manera:
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
WeightType G[MaxVertexNum][MaxVertexNum]; /* 邻接矩阵 */
};
typedef PtrToGNode MGraph; /* 以邻接矩阵存储的图类型 */
La función DFS debe atravesar recursivamente el gráfico Graficar en profundidad primero comenzando desde el vértice V y usar la función Visita definida por el árbitro para visitar cada vértice durante el recorrido. Al acceder a puntos adyacentes, se requiere el orden de números de secuencia crecientes. La pregunta asegura que V es un vértice legal en el gráfico.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
typedef enum {false, true} bool;
#define MaxVertexNum 10 /* 最大顶点数设为10 */
#define INFINITY 65535 /* ∞设为双字节无符号整数的最大值65535*/
typedef int Vertex; /* 用顶点下标表示顶点,为整型 */
typedef int WeightType; /* 边的权值设为整型 */
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
WeightType G[MaxVertexNum][MaxVertexNum]; /* 邻接矩阵 */
};
typedef PtrToGNode MGraph; /* 以邻接矩阵存储的图类型 */
bool Visited[MaxVertexNum]; /* 顶点的访问标记 */
MGraph CreateGraph(); /* 创建图并且将Visited初始化为false;裁判实现,细节不表 */
void Visit( Vertex V )
{
printf(" %d", V);
}
void DFS( MGraph Graph, Vertex V, void (*Visit)(Vertex) );
int main()
{
MGraph G;
Vertex V;
G = CreateGraph();
scanf("%d", &V);
printf("DFS from %d:", V);
DFS(G, V, Visit);
return 0;
}
/* 你的代码将被嵌在这里 */
Muestra de entrada: la imagen dada es la siguiente
5
Muestra de salida:
DFS from 5: 5 1 3 0 2 4 6
Código:
void DFS( MGraph Graph, Vertex V, void (*Visit)(Vertex) )
{
int w;
Visited[V] = true; //标记为true,说明已经访问过该点
Visit(V);
for (w = 0; w < Graph->Nv; w++)
{
if (Graph->G[V][w] == 1 && !Visited[w]) //有节点而且没有被访问过的情况
{
DFS(Graph,w,Visit);
}
}
return ;
}
Recorrido en amplitud del gráfico de almacenamiento de lista de adyacencia 16X16-2
Intente implementar un recorrido en amplitud del gráfico de almacenamiento de la lista de adyacencia.
Definición de interfaz de función:
void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) );
Donde LGraph es el gráfico almacenado en la lista de adyacencia, definido de la siguiente manera:
/* 邻接点的定义 */
typedef struct AdjVNode *PtrToAdjVNode;
struct AdjVNode{
Vertex AdjV; /* 邻接点下标 */
PtrToAdjVNode Next; /* 指向下一个邻接点的指针 */
};
/* 顶点表头结点的定义 */
typedef struct Vnode{
PtrToAdjVNode FirstEdge; /* 边表头指针 */
} AdjList[MaxVertexNum]; /* AdjList是邻接表类型 */
/* 图结点的定义 */
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
AdjList G; /* 邻接表 */
};
typedef PtrToGNode LGraph; /* 以邻接表方式存储的图类型 */
La función BFS debe realizar una búsqueda en amplitud en el gráfico almacenado en la lista de adyacencia comenzando desde el vértice S-ésimo, y usar la función Visita definida por el árbitro para acceder a cada vértice durante el recorrido. Al acceder a puntos adyacentes, se requiere el acceso en el orden de la lista de adyacencia. La pregunta asegura que S es un vértice legal en el gráfico.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
typedef enum {false, true} bool;
#define MaxVertexNum 10 /* 最大顶点数设为10 */
typedef int Vertex; /* 用顶点下标表示顶点,为整型 */
/* 邻接点的定义 */
typedef struct AdjVNode *PtrToAdjVNode;
struct AdjVNode{
Vertex AdjV; /* 邻接点下标 */
PtrToAdjVNode Next; /* 指向下一个邻接点的指针 */
};
/* 顶点表头结点的定义 */
typedef struct Vnode{
PtrToAdjVNode FirstEdge; /* 边表头指针 */
} AdjList[MaxVertexNum]; /* AdjList是邻接表类型 */
/* 图结点的定义 */
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
AdjList G; /* 邻接表 */
};
typedef PtrToGNode LGraph; /* 以邻接表方式存储的图类型 */
bool Visited[MaxVertexNum]; /* 顶点的访问标记 */
LGraph CreateGraph(); /* 创建图并且将Visited初始化为false;裁判实现,细节不表 */
void Visit( Vertex V )
{
printf(" %d", V);
}
void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) );
int main()
{
LGraph G;
Vertex S;
G = CreateGraph();
scanf("%d", &S);
printf("BFS from %d:", S);
BFS(G, S, Visit);
return 0;
}
/* 你的代码将被嵌在这里 */
Muestra de entrada: la imagen dada es la siguiente
2
Muestra de salida:
BFS from 2: 2 0 3 5 4 1 6
Código:
/*
思路:设置一个数组队列,先把这一行读取到的结点存放到队列中一直到NULL,只要队列中有元素就往后取出一个结点访问。
同时更新标记数组Visited的值来避免结点的重复访问。
*/
void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) )
{
int len = Graph->Nv;
int Queue[len + 1];
int v;
PtrToAdjVNode p = NULL;
int i = 0;
int j = 0;
Queue[i++] = S;
Visited[S] = true;
while (j != i)
{
v = Queue[j++];
Visit(v);
p = Graph->G[v].FirstEdge;
while (p)
{
if (!Visited[p->AdjV])
{
Queue[i++] = p->AdjV;
Visited[p->AdjV] = true;
}
p = p->Next;
}
}
}
16X16-3 Problema de construcción de costo mínimo del proyecto de tráfico fluido
Después de un estudio de las condiciones del tráfico urbano en una determinada región, se obtuvieron datos estadísticos sobre las vías rápidas existentes entre las ciudades y se propuso el objetivo del "proyecto suave": permitir el transporte rápido entre dos ciudades cualesquiera en toda la región (pero (pueden no ser necesariamente conexiones directas). Las autopistas están conectadas siempre que se pueda acceder a ellas indirectamente a través de la autopista). Ahora tenemos una tabla estadística de caminos urbanos. La tabla enumera los costos de varios caminos que pueden construirse en autopistas. Encuentre el costo mínimo requerido para proyectos de tránsito fluido.
Formato de entrada:
La primera línea de entrada proporciona el número de ciudades N (1<N≤1000) y el número de carreteras candidatas M≤3N; las líneas M posteriores, cada línea proporciona 3 enteros positivos, que son las dos ciudades directamente conectadas por la carretera. .número (numerado del 1 al N) y el costo estimado de la reconstrucción de la carretera.
Formato de salida:
Genere el costo mínimo requerido para proyectos desbloqueados. Si los datos de entrada son insuficientes para garantizar un flujo fluido, se genera "Imposible".
Ejemplo de entrada 1:
6 15
1 2 5
1 3 3
1 4 7
1 5 4
1 6 2
2 3 4
2 4 6
2 5 2
2 6 6
3 4 6
3 5 1
3 6 1
4 5 10
4 6 8
5 6 3
Muestra de salida 1:
12
Ejemplo de entrada 2:
5 4
1 2 1
2 3 2
3 1 3
4 5 4
Muestra de salida 2:
Impossible
Código:
/*
思路:定义一个结构体,里面的变量包括起点,终点,权值
定义一个标记数组
输入完成信息后根据权值把所有的元素排序,从最小的开始挑选能够建设的路
需要满足的条件:起点和终点不能同时在已经挑选的结点里面。用标记变量来确定是否已经被挑选
判断连通分量的时候看标记变量的大小,若只有一个连通分量,标记变量只有两个为1,其余都大于1
*/
#include <bits/stdc++.h>
using namespace std;
typedef struct Info
{
int start;
int last;
int value;
}Info;
void Swap(Info &i,Info &j);
int main()
{
int N,M; //结点个数以及候选道路数目
scanf("%d %d",&N,&M);
Info info[M*2];
int flag[N*2];
for (int i=1;i<=N;i++)
flag[i] = 0; //初始化标记数组
//输入并存储信息
for (int i=0;i<M;i++)
{
scanf("%d %d %d",&info[i].start,&info[i].last,&info[i].value);
flag[info[i].start] = 0;
flag[info[i].last] = 0;
}
//将所有信息进行排序
for (int i=0;i<M;i++)
{
for (int j=i+1;j<M;j++)
{
if (info[i].value > info[j].value)
{
Swap(info[i],info[j]);
}
}
}
//挑选成本小的路
int sum = 0;
int num = 0;
for (int i=0; i<M; i++)
{
//if (num == N-1) break;
if(flag[info[i].start] && flag[info[i].last]) //两个同时都已经在的情况
{
continue;
}
else
{
sum += info[i].value;
num++;
flag[info[i].start]++;
flag[info[i].last]++;
}
}
int con = 0;
for (int i=1; i<=N; i++)
{
if (flag[i] == 0)
{
con++;
break;
}
}
if (num != N-1 ||con) printf("Impossible\n");
else printf("%d\n",sum);
}
void Swap(Info &i,Info &j)
{
int temp;
temp = i.start;
i.start = j.start;
j.start = temp;
temp = i.last;
i.last = j.last;
j.last = temp;
temp = i.value;
i.value = j.value;
j.value = temp;
}
Rescate de emergencia interurbano 18X18-1
Como líder del equipo de rescate de emergencia de una ciudad, tienes un mapa especial del país. El mapa muestra varias ciudades dispersas y algunas vías rápidas que conectan las ciudades. El número de equipos de rescate en cada ciudad y la longitud de cada autopista que conecta dos ciudades están marcados en el mapa. Cuando otras ciudades te llamen para pedir ayuda de emergencia, tu tarea será llevar a tu equipo de rescate al lugar del incidente lo más rápido posible y, al mismo tiempo, convocar tantos equipos de rescate como sea posible a lo largo del camino.
Formato de entrada:
La primera línea de entrada da cuatro enteros positivos N, M, S y D, donde N (2≤N≤500) es el número de ciudades. Por cierto, supongamos que el número de ciudades es 0 ~ (N− 1); M es rápido El número de carreteras; S es el número de ciudad del lugar de salida; D es el número de ciudad de destino.
La segunda línea proporciona N enteros positivos, donde el i-ésimo número es el número de equipos de rescate en la i-ésima ciudad y los números están separados por espacios. En las líneas M siguientes, cada línea proporciona información sobre una autopista, a saber: Ciudad 1, Ciudad 2 y la longitud de la autopista, separadas por espacios. Los números son todos números enteros y no superan 500. Los aportes garantizan que el rescate sea factible y que la solución óptima sea única.
Formato de salida:
La primera línea muestra el número de caminos más cortos y el número máximo de equipos de rescate que se pueden convocar. La segunda línea genera los números de las ciudades pasadas en el camino de S a D. Los números están separados por espacios y no debe haber espacios adicionales al final del resultado.
Ejemplo de entrada:
4 5 0 3
20 30 40 10
0 1 1
1 3 2
0 3 3
0 2 2
2 3 2
Muestra de salida:
2 60
0 1 3
Código:
#include<bits/stdc++.h>
using namespace std;
#define INF 1000000
int a[1001][1001];
int cnt[1001],exs[1001]={0},cf[1001],ccf[1001],pre[1001];
//最短路径条数,各城市是否经过,各城市的救援队数量,到达该城市时所召集的所有救援队数量,到达该城市前经过的城市编号
int n,m,s,d;
int Dijkstra()
{
cnt[s] = 1;//开始时路径条数为1
exs[s] = 1;//当前在出发城市
for(int i = 0; i<n; i++)
{
int mm = INF,f = -1;
for(int j = 0; j<n; j++)
{
if(exs[j] == 0 && a[s][j] < mm) //寻找下一个距离最短的城市
{
mm = a[s][j];
f = j;//做好下一城市编号的标记
}
}
if(f == -1)break;//与其他未经过的城市不连通,退出循环
else exs[f] = 1;//到达下一城市
for(int j = 0; j<n; j++)
{
if(exs[j] == 0 && a[s][j] > a[s][f] + a[f][j]) //到达某一城市的最短路径
{
a[s][j] = a[s][f] + a[f][j];//最短路径更新
pre[j] = f;//记录上一个城市编号
cnt[j] = cnt[f];//拷贝到达上一个城市时的最短路径条数
ccf[j] = ccf[f] + cf[j];//到达某城市召集的全部救援队数量
}
else if(exs[j] == 0&&a[s][j] == a[s][f] + a[f][j]) //发现其他的最短路径
{
cnt[j] = cnt[j] + cnt[f];//更新到达当前城市时的最短路径条数
if(ccf[j] < ccf[f] + cf[j]) //最多救援队数量更新
{
pre[j] = f;//记录所经过的上一个城市编号
ccf[j] = ccf[f] + cf[j];//更新救援队总数
}
}
}
}
}
int main()
{
cin>>n>>m>>s>>d;
for(int i = 0;i<n;i++){
cin>>cf[i];
ccf[i] = cf[i];
cnt[i] = 1;
}
for(int i = 0;i<n;i++){
for(int j = 0;j<n;j++){
if(i != j) a[i][j] = a[j][i] = INF;//初始化(双向图)
}
}
for(int i = 0;i<m;i++){
int q,w,e;
cin>>q>>w>>e;
a[q][w] = a[w][q] = e;
}
Dijkstra();
cout<<cnt[d]<<" "<<ccf[d]+cf[s]<<endl;
int road[1001];
int x = 0,t = d;
while(pre[t] != 0)
{//所经历的城市的从后往前的顺序
road[x++]=pre[t];
t=pre[t];
}
cout<<s;//出发地
for(int i = x-1;i >= 0;i--)
cout<<" "<<road[i];
cout<<" "<<d;//目的地
}
Búsqueda binaria 19X19-1
Esta pregunta requiere la implementación de un algoritmo de búsqueda binaria.
Definición de interfaz de función:
Position BinarySearch( List L, ElementType X );
La estructura de la Lista se define de la siguiente manera:
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
L es una lista lineal pasada por el usuario, en la que los elementos ElementType se pueden comparar mediante >, == y <, y la pregunta garantiza que los datos entrantes estén en orden creciente. La función BinarySearch quiere encontrar la posición de X en Datos, que es el subíndice de la matriz (nota: los elementos se almacenan a partir del subíndice 1). Si se encuentra, se devuelve el subíndice; de lo contrario, se devuelve una marca de error especial No encontrado.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 10
#define NotFound 0
typedef int ElementType;
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
List ReadInput(); /* 裁判实现,细节不表。元素从下标1开始存储 */
Position BinarySearch( List L, ElementType X );
int main()
{
List L;
ElementType X;
Position P;
L = ReadInput();
scanf("%d", &X);
P = BinarySearch( L, X );
printf("%d\n", P);
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada 1:
5
12 31 55 89 101
31
Muestra de salida 1:
2
Ejemplo de entrada 2:
3
26 78 233
31
Muestra de salida 2:
0
Código:
Position BinarySearch( List L, ElementType X )
{
if (L == NULL) return NotFound;
int left = 1; //最左边位置
int right = L->Last; //最右边位置
int flag = 0;
int mid;
while (left <= right)
{
mid = (left + right)/2; //中间位置
if (L->Data[mid] == X) {flag = 1;return mid;}
else if (L->Data[mid] < X) left = mid + 1;
else right = mid - 1;
}
if (!flag) return NotFound;
}
19X19-2 Mediana de dos secuencias ordenadas
Se sabe que existen dos secuencias no descendentes de igual longitud S1 y S2. Diseñe una función para encontrar la mediana de la unión de S1 y S2. La mediana de la secuencia ordenada A0,A1,⋯,ANN−1 se refiere al valor de A(N−1)/2, es decir, el ⌊( N+1) )/2⌋número (A0 es el primer número).
Formato de entrada:
La entrada se divide en tres líneas. La primera línea proporciona la longitud común N de la secuencia (0<N≤100000), y cada línea posterior ingresa la información de una secuencia, es decir, N números enteros dispuestos en orden no descendente. Los números están separados por espacios.
Formato de salida:
Genera la mediana de la secuencia de unión de dos secuencias de entrada en una línea.
Ejemplo de entrada 1:
5
1 3 5 7 9
2 3 4 5 6
Muestra de salida 1:
4
Ejemplo de entrada 2:
6
-100 -10 1 1 1 1
-50 0 2 3 4 5
Muestra de salida 2:
1
Código:
#include <bits/stdc++.h>
using namespace std;
int main(){
int str[100001],arr[100001];
int n;scanf("%d",&n);
for(int i=0;i<n;i++) scanf("%d",&str[i]);
for(int i=0;i<n;i++) scanf("%d",&arr[i]);
//中位数在大的左边 小的右边
int start1=0,end1=n-1,mid1=(n-1)/2;
int start2=0,end2=n-1,mid2=(n-1)/2;
int mid;int flag=0;
while(start1!=end1&&start2!=end2){
if(str[mid1]==arr[mid2]) {
mid=str[mid1];
flag=1;
break;
}
else if(str[mid1]>arr[mid2]){
if((end1-start1)%2==0&&(end2-start2)%2==0){
end1=mid1;
start2=mid2;
}
else{
end1=mid1;
start2=mid2+1;
}
mid1=(start1+end1)/2;
mid2=(start2+end2)/2;
}
else{
if((end1-start1)%2==0&&(end2-start2)%2==0){
start1=mid1;
end2=mid2;
}
else {
start1=mid1+1;
end2=mid2;
}
mid1=(start1+end1)/2;
mid2=(start2+end2)/2;
}
}
if(!flag) {
if(start1==end1) {
int a=str[start1],b=arr[end2];
if(a>b) mid=b;
else mid=a;
}
else {
int a=arr[start2],b=str[end1];
if(a>b) mid=b;
else mid=a;
}
}
printf("%d\n",mid);
}
¿Es 20X20-1 un árbol de búsqueda binario?
La pregunta requiere la implementación de una función para determinar si un árbol binario determinado es un árbol de búsqueda binario.
Definición de interfaz de función:
bool IsBST ( BinTree T );
La estructura BinTree se define de la siguiente manera:
typedef struct TNode *Position;
typedef Position BinTree;
struct TNode{
ElementType Data;
BinTree Left;
BinTree Right;
};
La función IsBST debe determinar si el T dado es un árbol de búsqueda binario, es decir, un árbol binario que cumple con la siguiente definición:
Definición: Un árbol de búsqueda binario es un árbol binario que puede estar vacío. Si no está vacío, satisface las siguientes propiedades:
非空左子树的所有键值小于其根结点的键值。
非空右子树的所有键值大于其根结点的键值。
左、右子树都是二叉搜索树。
Si T es un árbol de búsqueda binario, la función devuelve verdadero; de lo contrario, devuelve falso.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <stdlib.h>
typedef enum { false, true } bool;
typedef int ElementType;
typedef struct TNode *Position;
typedef Position BinTree;
struct TNode{
ElementType Data;
BinTree Left;
BinTree Right;
};
BinTree BuildTree(); /* 由裁判实现,细节不表 */
bool IsBST ( BinTree T );
int main()
{
BinTree T;
T = BuildTree();
if ( IsBST(T) ) printf("Yes\n");
else printf("No\n");
return 0;
}
/* 你的代码将被嵌在这里 */
Muestra de entrada 1: como se muestra a continuación

Muestra de salida 1:
Yes
Ejemplo de entrada 2: como se muestra a continuación
Muestra de salida 2:
No
Código:
int a[101];
int i = 0;
bool IsBST ( BinTree T )
{//中序遍历,得到的结果是从小到大排列,只要满足左边小于右边即可
if (T != NULL)
{
IsBST(T->Left);
a[i++] = T->Data;
IsBST(T->Right);
}
for (int j=0;j<i;j++)
{
if (a[j-1] >= a[j])
return false;
}
return true;
}
Función de operación de eliminación 21X21-1 del método de enlace de separación
Intente implementar la función de operación de eliminación del método de enlace separado.
Definición de interfaz de función:
bool Delete( HashTable H, ElementType Key );
Donde HashTable es una tabla hash vinculada separada, definida de la siguiente manera:
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
typedef struct TblNode *HashTable; /* 散列表类型 */
struct TblNode { /* 散列表结点定义 */
int TableSize; /* 表的最大长度 */
List Heads; /* 指向链表头结点的数组 */
};
La función Eliminar debe encontrar la ubicación de la clave en la tabla hash H y eliminarla según la función hash Hash(Key, H->TableSize) definida por el árbitro, y luego generar una línea de texto: La clave se elimina de la lista Heads [i], donde Clave es la palabra clave eliminada pasada, i es el número de la lista vinculada donde se encuentra la Clave y finalmente devuelve verdadero. Si la clave no existe, devuelve falso.
Ejemplo de procedimiento de prueba de árbitro:
#include <stdio.h>
#include <string.h>
#define KEYLENGTH 15 /* 关键词字符串的最大长度 */
typedef char ElementType[KEYLENGTH+1]; /* 关键词类型用字符串 */
typedef int Index; /* 散列地址类型 */
typedef enum {false, true} bool;
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
typedef struct TblNode *HashTable; /* 散列表类型 */
struct TblNode { /* 散列表结点定义 */
int TableSize; /* 表的最大长度 */
List Heads; /* 指向链表头结点的数组 */
};
Index Hash( ElementType Key, int TableSize )
{
return (Key[0]-'a')%TableSize;
}
HashTable BuildTable(); /* 裁判实现,细节不表 */
bool Delete( HashTable H, ElementType Key );
int main()
{
HashTable H;
ElementType Key;
H = BuildTable();
scanf("%s", Key);
if (Delete(H, Key) == false)
printf("ERROR: %s is not found\n", Key);
if (Delete(H, Key) == true)
printf("Are you kidding me?\n");
return 0;
}
/* 你的代码将被嵌在这里 */
Ejemplo de entrada 1: la tabla hash se muestra a continuación

able
Muestra de salida 1:
able is deleted from list Heads[0]
Muestra de entrada 2: tabla hash como se muestra en la muestra 1
date
Muestra de salida 2:
ERROR: date is not found
Código:
bool Delete( HashTable H, ElementType Key )
{
int w = Hash(Key,H->TableSize); //题目已知的函数,返回Key对表长的求余,即Key在数组中的下标
if (H->Heads[w].Next == NULL) return false; //Key应该在的下标处没有元素,直接返回没找到
PtrToLNode p = H->Heads[w].Next;
PtrToLNode q = p;
while (strcmp(Key,p->Data) && p->Next != NULL)
{
q = p; //记录要删除的结点的上一位
p = p->Next;
}
if (!strcmp(Key,p->Data))
{
printf("%s is deleted from list Heads[%d]",Key,w);
q = p->Next; //删除后的连接结点
free(p); //释放已经删除结点的空间
return true;
}
return false;
}
Clasificación por inserción directa 21X21-2
Esta pregunta requiere la implementación de una función de clasificación por inserción directa, y la longitud de la columna a ordenar es 1 <= n <= 1000.
Definición de interfaz de función:
void InsertSort(SqList L);
Donde L es la tabla que se va a ordenar, de modo que los datos ordenados se ordenen de pequeño a grande.
Definición de tipo:
typedef int KeyType;
typedef struct {
KeyType *elem; /*elem[0]一般作哨兵或缓冲区*/
int Length;
}SqList;
Ejemplo de procedimiento de prueba de árbitro:
#include<stdio.h>
#include<stdlib.h>
typedef int KeyType;
typedef struct {
KeyType *elem; /*elem[0]一般作哨兵或缓冲区*/
int Length;
}SqList;
void CreatSqList(SqList *L);/*待排序列建立,由裁判实现,细节不表*/
void InsertSort(SqList L);
int main()
{
SqList L;
int i;
CreatSqList(&L);
InsertSort(L);
for(i=1;i<=L.Length;i++)
{
printf("%d ",L.elem[i]);
}
return 0;
}
/*你的代码将被嵌在这里 */
Ejemplo de entrada:
El número entero en la primera línea representa la cantidad de palabras clave que participan en la clasificación. La segunda línea es el valor de la palabra clave. Por ejemplo:
10
5 2 4 1 8 9 10 12 3 6
Muestra de salida:
Genere una secuencia ordenada de pequeña a grande, cada palabra clave está separada por un espacio y hay un espacio después de la última palabra clave.
1 2 3 4 5 6 8 9 10 12
Código:
void InsertSort(SqList L)
{//先排第一个,然后第二个插入到前边的序列,第三个插入,以此类推。
int i,j;
for (i = 1; i <= L.Length; i++)
{
L.elem[0] = L.elem[i];
for (j = i; L.elem[j-1]>L.elem[0] && j > 0; j--)
{
L.elem[j] = L.elem[j-1];
L.elem[j-1] = L.elem[0];
}
}
}