Tabla de contenido
1. Comprensión sencilla de modelos grandes.
(2) Centrarse en modelos de lenguaje grandes
(3) Ejemplos de aplicación de modelos grandes.
2. Cómo conseguir un modelo grande
Utilice modelos previamente entrenados
Utilice la plataforma de computación en la nube
Comprender las restricciones de uso y licencias de modelos
(2) Análisis previo al entrenamiento
Suplemento: ¿Qué se puede hacer con el modelo de pedestal?
(3) Análisis del concepto de alineación
1.Definiciones y explicaciones básicas
2. Ajuste fino de comandos (SFT Supervised FineTune)
3. ¿Cómo completar múltiples rondas de tareas de diálogo?
Múltiples rondas de diálogo convertidas en tareas de continuación.
Formato de convención del historial de conversaciones
Diálogo de continuación del modelo.
El usuario interactúa con el modelo.
Extensión: descripción de caso de uso de ejemplo
4. Ejemplos de métodos de alineación comunes
3. Cómo controlar modelos grandes
(2) Entrenamiento secundario del modelo.
2. Dé un ejemplo de una tarea: Análisis de sentimiento
3. Ampliación: Alinear el modelo con nuestras expectativas de uso.
(3) Preprocesamiento y posprocesamiento basado en reglas
Preprocesamiento basado en reglas
Postprocesamiento basado en reglas
(4) Límites y limitaciones de los modelos grandes.
Descripción general de sitios de aprendizaje y tutoriales
1. Comprensión sencilla de modelos grandes.
(1) Definición oficial
Los Modelos Grandes no tienen una definición oficial unificada porque suele ser un concepto relativo y su tamaño cambiará según el tiempo, la tecnología y el desarrollo del campo. Los modelos grandes generalmente se refieren a modelos de redes neuronales en aprendizaje profundo que tienen una gran cantidad de parámetros y requisitos de recursos computacionales. Estos modelos pueden tener diferentes umbrales de tamaño en diferentes contextos.
Por ejemplo, en el campo del procesamiento del lenguaje natural (NLP), los modelos grandes pueden referirse a modelos que contienen miles de millones a cientos de miles de millones de parámetros, como GPT-3, GPT-4, etc. Para el campo de la visión por computadora, los modelos grandes pueden ser redes neuronales convolucionales profundas con cientos de millones de parámetros, como ResNet-152.
En el campo del aprendizaje profundo, con el avance de la tecnología, la escala de modelos grandes continúa expandiéndose para mejorar el rendimiento del modelo. Por lo tanto, la definición oficial puede ser difícil de precisar, pero normalmente se puede juzgar si un modelo se denomina "modelo grande" en función del número de parámetros del modelo, los requisitos de recursos computacionales y el desempeño de la tarea.
Es importante destacar que los modelos grandes a menudo requieren amplios recursos informáticos y datos a gran escala para entrenarse, por lo que se debe considerar cuidadosamente el equilibrio entre recursos y rendimiento al usarlos.
(2) Centrarse en modelos de lenguaje grandes
Large Language Model ( LLM ) es un modelo de red neuronal con una gran cantidad de parámetros, utilizado principalmente para tareas de procesamiento de lenguaje natural . Su tarea principal es continuar escribiendo texto, es decir, después de un período determinado de entrada de texto, generar un A continuo. secuencia de texto, haciéndolo parecer una continuación del lenguaje natural. La salida de este modelo se genera palabra por palabra y puede continuar hasta que se encuentre un símbolo de terminación específico. La presencia de este símbolo de terminación permite al modelo elegir el final apropiado la salida en lugar de generar el texto completo de una vez.
- Grande en "modelo de lenguaje grande" se refiere a la gran escala del modelo, que generalmente necesita contener miles de millones o incluso cientos de miles de millones o billones de parámetros . Un modelo de este tamaño requiere una gran cantidad de espacio en el disco duro para almacenamiento . Por ejemplo, un modelo que contiene 7 mil millones de parámetros puede requerir más de 13 GB de espacio en el disco duro.
- El modelo de lenguaje grande de diálogo de múltiples turnos no solo se puede usar para una tarea de continuación de texto único, sino también para el diálogo de múltiples turnos, es decir, para generar texto de respuesta continuo en la conversación, haciendo que parezca un flujo de conversación natural. Estos modelos se pueden utilizar para crear aplicaciones como asistentes de inteligencia artificial y chatbots.
En conjunto, el modelo de lenguaje grande es una poderosa herramienta de procesamiento de lenguaje natural con una gran cantidad de parámetros y capacidades. Puede usarse para generar texto en lenguaje natural, una sola tarea de continuación y múltiples rondas de diálogo, generando lenguaje natural para varios textos. Se apoyan las tareas de comprensión del lenguaje.
(3) Ejemplos de aplicación de modelos grandes.
Los "modelos grandes" generalmente se refieren a grandes modelos de redes neuronales en el campo del aprendizaje profundo, que tienen una gran cantidad de parámetros y arquitecturas complejas y se utilizan para resolver diversas tareas de inteligencia artificial. Estos modelos a gran escala han logrado resultados notables en campos como el procesamiento del lenguaje natural, la visión por computadora y el reconocimiento de voz. A continuación se muestran algunos ejemplos comunes de modelos grandes:
-
GPT-3 (Generative Pretrained Transformer 3): un modelo de procesamiento de lenguaje natural desarrollado por OpenAI con 175 mil millones de parámetros. Puede generar texto de alta calidad y realizar una variedad de tareas relacionadas con el texto.
-
BERT (Transformador de representación de codificador bidireccional): un modelo de procesamiento de lenguaje natural desarrollado por Google con entre 110 y 340 millones de parámetros para comprender el contexto y procesar texto en lenguaje natural.
-
ResNet (Red Residual): una red neuronal convolucional profunda ampliamente utilizada en el campo de la visión por computadora, que contiene millones de parámetros y se utiliza para la clasificación y el reconocimiento de imágenes.
-
VGGNet (Visual Geometric Group Network): otra gran red neuronal convolucional para clasificación de imágenes con numerosos parámetros.
-
BERT (Transformador de representación de codificador bidireccional): un modelo de procesamiento de lenguaje natural desarrollado por Google con entre 110 y 340 millones de parámetros para comprender el contexto y procesar texto en lenguaje natural.
-
Inception (GoogLeNet): otra gran red neuronal convolucional para clasificación de imágenes y reconocimiento de objetos con una gran cantidad de parámetros.
Los modelos grandes se utilizan ampliamente porque funcionan bien en tareas complejas , pero también requieren importantes recursos informáticos para entrenarlos y ejecutarlos . Por lo general , estos modelos se entrenan previamente en conjuntos de datos a gran escala y luego se ajustan para adaptarse a tareas específicas . Los modelos a gran escala han logrado un rendimiento impresionante en campos como la comprensión del lenguaje natural, la visión por computadora y el procesamiento del habla, y tienen un amplio potencial para una variedad de aplicaciones.
2. Cómo conseguir un modelo grande
(1) Pasos generales generales
La obtención de grandes modelos de redes neuronales (como modelos de lenguaje grandes, modelos de aprendizaje profundo de gran tamaño, etc.) generalmente implica los siguientes pasos:
Entrena tu propio modelo
- Si tiene suficientes datos y recursos informáticos, puede intentar entrenar un modelo grande usted mismo. Normalmente requiere recursos informáticos masivos (como GPU o TPU) y conjuntos de datos a gran escala. Debe elegir un marco de aprendizaje profundo apropiado (como TensorFlow, PyTorch) y escribir código de entrenamiento modelo.
- Si desea entrenar un modelo de lenguaje grande, también debe considerar aspectos como el preprocesamiento de datos de texto, la tokenización y el ajuste del proceso de capacitación.
Utilice modelos previamente entrenados
- Un enfoque más común es utilizar modelos grandes que hayan sido entrenados previamente por grandes organizaciones (como OpenAI, Google, Facebook). Estos modelos están previamente entrenados en conjuntos de datos a gran escala y pueden usarse para una variedad de tareas de procesamiento de lenguaje natural y visión por computadora.
- Estos modelos previamente entrenados suelen estar disponibles a través de canales comerciales o de código abierto. Estos modelos se pueden descargar o acceder a ellos y ajustarlos para adaptarlos a tareas específicas en sus propios proyectos.
Elige el modelo apropiado
- Al seleccionar un modelo grande, considere la complejidad de la tarea, los recursos informáticos disponibles y la cantidad de datos disponibles. Los modelos más pequeños pueden requerir menos recursos, pero su rendimiento puede ser limitado.
- Si solo necesita realizar una tarea específica, puede elegir un modelo que haya sido ajustado para esa tarea.
Utilice la plataforma de computación en la nube
- Los grandes modelos de redes neuronales requieren grandes cantidades de recursos informáticos, incluidas GPU o TPU de alto rendimiento. Si estos recursos no están disponibles, puede considerar el uso de plataformas de computación en la nube como AWS, Google Cloud, Azure, etc. Estas plataformas proporcionan potentes recursos informáticos de aprendizaje profundo para alquilar.
Comprender las restricciones de uso y licencias de modelos
- Antes de utilizar un modelo grande, asegúrese de comprender su licencia y restricciones de uso. Algunos modelos grandes pueden estar sujetos a condiciones de uso específicas, como tarifas de uso comercial, etc.
Dominar el uso y ajuste de modelos.
- Una vez que tenga un modelo grande, necesitará aprender cómo usarlo y cómo ajustarlo para tareas específicas. La mayoría de los modelos previamente entrenados tienen documentación y código de muestra para ayudar a comenzar.
En resumen, obtener grandes modelos de redes neuronales requiere una cuidadosa consideración de los recursos informáticos, los datos y los requisitos de las tareas. Si no tiene suficientes recursos o experiencia, considere usar un modelo ya entrenado previamente y ajustarlo según sea necesario para cumplir con los requisitos de su tarea específica.
(2) Análisis previo al entrenamiento
El "preentrenamiento" es un concepto importante en los campos del aprendizaje profundo y el procesamiento del lenguaje natural. Se refiere al proceso de entrenamiento inicial de un modelo con datos a gran escala antes de que el modelo se aplique formalmente a una tarea específica. Este proceso suele dividirse en los siguientes pasos:
-
Recopilación de datos : se recopila una gran cantidad de datos de texto, que a menudo contienen texto de Internet, incluidos artículos, noticias, publicaciones en redes sociales, etc.
-
Preprocesamiento : los datos se someten a pasos de preprocesamiento, como limpieza, segmentación de palabras y tokenización, para facilitar el entrenamiento del modelo.
-
Entrenamiento previo del modelo : utilizando estos datos, el modelo se preentrenó inicialmente. En esta etapa, el modelo aprende la estructura, gramática, semántica y otros conocimientos del idioma, así como las características estadísticas de los datos del texto. Este modelo previamente entrenado a menudo se denomina "modelo base" o "modelo previamente entrenado". Por ejemplo, LLaMa, GPT-3, GLM130B, estos modelos son todos modelos básicos.
-
Ajuste fino : una vez que el modelo base está previamente entrenado, se puede ajustar en una tarea específica . A menudo, esto implica el uso de conjuntos de datos de tareas específicas, como análisis de sentimientos, generación de texto, etc., para ajustar aún más los parámetros del modelo y adaptarlo a la tarea específica.
Después de completar la capacitación previa, el modelo base tiene amplias capacidades de generación y comprensión del lenguaje. Puede realizar una variedad de tareas relacionadas con el texto, incluida la continuación, traducción, respuesta a preguntas, clasificación de texto, etc. La razón por la que los modelos previamente entrenados son poderosos es que han aprendido el conocimiento general y las reglas del lenguaje a través de datos a gran escala y pueden usarse para la inicialización de diversas tareas de procesamiento del lenguaje natural.

Los modelos previamente entrenados han logrado resultados notables en el campo del procesamiento del lenguaje natural y se utilizan ampliamente en diversas aplicaciones, incluidos asistentes inteligentes, traducción automática, búsqueda inteligente, etc. Estos modelos funcionan bien en muchas tareas porque poseen amplias capacidades de generación y comprensión de texto y pueden manejar datos complejos en lenguaje natural.
Suplemento: ¿Qué se puede hacer con el modelo de pedestal?
Los modelos básicos, como la serie GPT (como GPT-3, GPT-4) y otros modelos de lenguaje a gran escala , tienen una amplia gama de capacidades de generación y comprensión del lenguaje y no se limitan a tareas de continuación. Esto es lo que puede hacer el modelo base:
-
Generación y continuación de texto : el modelo base puede aceptar fragmentos de texto y generar texto coherente y sensato. Esto es útil en tareas como generación automática de texto, resumen automático, creación de artículos, etc. (El modelo debe tener conocimiento: La capital de China es Beijing . El modelo debe poder calcular: 111+222= 333 ; etc.)
-
Comprensión del lenguaje natural : puede comprender e interpretar el contenido del texto, incluidas respuestas a preguntas, clasificación de texto, análisis de sentimientos, etc. Esto es muy útil para tareas como sistemas de respuesta a preguntas, análisis de sentimientos, clasificación de textos, etc.
-
Traducción : el modelo base puede traducir texto de un idioma a otro y, por lo tanto, puede usarse para traducción automática.
-
Generación de conversaciones : Puede usarse para generar conversaciones, por lo que puede usarse en chatbots, asistentes virtuales, sistemas inteligentes de atención al cliente, etc.
-
Recuperación de información y respuesta a preguntas : los modelos de pedestal se pueden utilizar para recuperar información con motores de búsqueda y también para responder preguntas específicas.
-
Población de la base de conocimientos : los modelos base pueden extraer conocimientos de textos de gran escala, que pueden utilizarse para crear una base de conocimientos o ayudar a responder preguntas específicas.
-
Recomendación inteligente : Puede generar recomendaciones personalizadas basadas en el comportamiento histórico y las preferencias del usuario, como películas, música, noticias, etc.
-
Resumen automático : puede generar automáticamente un resumen del texto para ayudar a los usuarios a comprender rápidamente el contenido principal de textos largos.
-
Edición y reparación de texto : se puede utilizar para editar texto, ayudar a corregir errores gramaticales, proporcionar sugerencias y más.
La razón por la que los modelos base son tan útiles es que han aprendido el conocimiento general y las reglas del lenguaje a través de datos de texto a gran escala y, por lo tanto, pueden usarse para la inicialización de diversas tareas relacionadas con el texto. Además, al ajustar el modelo base, puede adaptarlo a un dominio o tarea específica, mejorando aún más el rendimiento. Por lo tanto, el modelo base tiene amplias perspectivas de aplicación en los campos del procesamiento del lenguaje natural y la inteligencia artificial, y puede usarse para resolver diversos problemas complejos relacionados con el texto.
(3) Análisis del concepto de alineación
1.Definiciones y explicaciones básicas
"Alineación" en este contexto se refiere a ajustar la salida de un modelo de lenguaje grande para que coincida con las expectativas humanas y las necesidades específicas. La alineación se realiza para que los modelos grandes sean más prácticos y seguros.
A continuación se explica detalladamente ambos aspectos:
mejor usar
-
Coincidir con las expectativas del usuario : cuando los usuarios plantean una pregunta o tarea a un modelo de lenguaje grande, a menudo esperan que las respuestas del modelo o el texto generado sean relevantes para el contexto de la pregunta o tarea. El objetivo de la alineación es garantizar que el resultado del modelo sea coherente con las expectativas del usuario. Por ejemplo, cuando un usuario pregunta sobre la capital de China, la respuesta esperada es "Pekín" en lugar de otra información irrelevante (el modelo puede generar "¿Cuál es la capital de los Estados Unidos? ¿Cuál es la capital de Alemania?... ", o puede dar como resultado "Esta es una pregunta que todos conocen". Desde la perspectiva de la continuación, las respuestas del modelo pueden ser correctas, pero no están en línea con nuestras expectativas).
-
Sensible al contexto : para algunas tareas, como consultas en motores de búsqueda o recuperación de información de un dominio específico, los usuarios esperan que el modelo genere resultados que sean contextualmente relevantes para la entrada. La alineación garantiza que el modelo comprenda el contexto y genere una respuesta adecuada, en lugar de simplemente realizar una tarea de continuación. (Por ejemplo, cuando el modelo asistente pregunta "Platos especiales de la ciudad natal de Baotou, Mongolia Interior", se espera que el modelo pueda generar una llamada al motor de búsqueda, en lugar de que el modelo realice directamente la tarea de continuación).
más seguro
-
Evite contenido dañino : la alineación también se puede utilizar para limitar que el modelo genere contenido que pueda ser dañino o inapropiado. Por ejemplo, el modelo debe diseñarse para no generar contenido ilegal o inmoral que incluya pornografía, juegos de azar, drogas, violencia, terrorismo, etc. Una de las tareas del alineamiento es asegurar que los modelos no generen este tipo de contenidos, mejorando así la seguridad de la plataforma.
-
Cumplimiento y ética : la alineación también es importante cuando se trata de cumplimiento y ética. El resultado del modelo debe cumplir con las leyes y normas éticas aplicables, seguir la política de privacidad y no causar daño a los usuarios ni a la sociedad.
En resumen, la alineación es una tarea crítica que tiene como objetivo garantizar que la salida de grandes modelos de lenguaje satisfaga las necesidades, expectativas y regulaciones del usuario al tiempo que mejora la utilidad y seguridad del modelo. A través de métodos de alineación efectivos, el comportamiento de generación del modelo se puede controlar y guiar mejor, haciéndolo más adecuado para diversos escenarios de aplicación.
2. Ajuste fino de comandos (SFT Supervised FineTune)
"Supervised Fine-Tune, SFT" (Supervised Fine-Tune, SFT) es un método para ajustar modelos de aprendizaje profundo, que a menudo se utiliza para ajustar modelos de lenguaje grandes para que puedan comprender y seguir instrucciones específicas.
-
Construcción de datos especiales : durante la fase de ajuste fino de la instrucción, es necesario preparar algunas muestras de datos especiales, que contienen instrucciones y respuestas estándar construidas artificialmente o resultados esperados. Estas instrucciones pueden ser diversas formas de tareas o requisitos, como repetir lecturas, responder preguntas, generar texto, etc.
-
Utilice modelos previamente entrenados : durante el proceso de ajuste fino, los modelos base a gran escala que han sido previamente entrenados, como los modelos de la serie GPT, generalmente se utilizan como modelo inicial.
-
Instrucciones de entrada : Utilice las instrucciones ("¿Dónde está la capital de China?" "¿Cuál es la dirección del blog CSDN de Zhang Yanfeng?") Como entrada del modelo y luego observe la salida del modelo. A menudo, el resultado de un modelo puede no ser el esperado inicialmente porque solo se genera en base a conocimientos previamente entrenados. Las instrucciones de entrada son el contexto anterior y la salida del modelo es el contexto posterior.
-
Comparación y mejora : compare el resultado del modelo con la respuesta estándar esperada y calcule la diferencia entre ellos, generalmente medida mediante una función de pérdida. Luego, mediante el algoritmo de retropropagación, los parámetros del modelo se ajustan para reducir la función de pérdida, de modo que la salida del modelo se acerque gradualmente a la respuesta estándar.
-
Ajuste iterativo : este proceso se repite varias veces, cada vez utilizando diferentes instrucciones y muestras de respuestas estándar, para ajustar los parámetros del modelo para que pueda seguir mejor las instrucciones y generar el resultado esperado.
Mediante el ajuste de las instrucciones, el modelo aprende gradualmente a comprender varias instrucciones y realizar las tareas correspondientes. Este enfoque ayuda a alinear mejor el modelo con las expectativas y necesidades de los usuarios, aumentando así la utilidad del modelo para una tarea específica. El ajuste de las instrucciones también ayuda a que el modelo siga reglas y restricciones específicas, mejorando así la seguridad y la controlabilidad del modelo. En última instancia, este proceso da como resultado un modelo que puede seguir instrucciones y realizar el trabajo, lo que a menudo se utiliza en aplicaciones como conversaciones de un solo turno.
3. ¿Cómo completar múltiples rondas de tareas de diálogo?
El modelo solo puede continuar escribiendo, pero ¿cómo puede completar múltiples rondas de tareas de diálogo? Esto se logra convirtiendo múltiples rondas de diálogo en una tarea de continuación, a través de la cual el modelo genera la ilusión de diálogo.
Múltiples rondas de diálogo convertidas en tareas de continuación.
La idea central de convertir múltiples rondas de diálogo en una tarea de continuación es presentar todo el historial de la conversación al modelo de manera formateada, permitiendo que el modelo lo trate como un único fragmento de texto para la continuación. Este formato normalmente incluye la pregunta del usuario, la respuesta del modelo y posiblemente marcadores de diálogo para distinguir qué texto es entrada del usuario y qué texto es la respuesta del modelo.
Formato de convención del historial de conversaciones
En la etapa SFT (Supervised Fine-Tune), el modelo recibe una capacitación específica y aprende el formato organizativo y las etiquetas de múltiples rondas de diálogo. Puede comprender el papel y la relación de cada oración en este formato, incluidas cuáles son entradas del usuario y cuáles son respuestas modelo. Esta formación permite al modelo comprender correctamente el contexto y el contexto de la conversación.
Entrada de diálogo histórico
En aplicaciones prácticas, las conversaciones históricas se ingresan al modelo en un formato acordado. Esta conversación histórica incluye las preguntas del usuario y las respuestas del modelo, así como posibles marcadores de conversación. Una vez que el modelo recibe esta entrada formateada, la trata como un único fragmento de texto.
Diálogo de continuación del modelo.
Una vez que el modelo reciba el diálogo histórico formateado, generará el resultado de continuación correspondiente, es decir, la respuesta o respuesta a la siguiente oración. Este resultado se agregará al diálogo histórico para formar un nuevo diálogo histórico y luego se ingresará nuevamente al modelo, quien continuará escribiendo y completando el proceso de múltiples rondas de diálogo.
El usuario interactúa con el modelo.
De esta forma, el usuario y el modelo pueden tener múltiples rondas de diálogo, aunque el modelo en sí no recuerda el historial de diálogo. El modelo simplemente genera respuestas coherentes basadas en el formato y el contexto de conversaciones históricas, haciendo que el usuario sienta como si se estuviera comunicando con una entidad inteligente que puede comprender y responder a múltiples rondas de conversaciones.
En resumen, al formatear conversaciones de varios turnos como tareas de continuación, el modelo puede comprender y responder al contexto de las conversaciones de varios turnos, completando así la tarea de conversación de varios turnos. Este enfoque aprovecha al máximo las capacidades de generación de modelos de lenguaje grandes y proporciona a los usuarios una experiencia de interacción con el modelo. El modelo no tiene capacidades reales de memoria, pero hace que el proceso de diálogo sea coherente y natural al comprender y continuar el diálogo histórico formateado.
Extensión: descripción de caso de uso de ejemplo
Al convertir múltiples rondas de diálogo en una tarea de continuación, el modelo puede comprender y generar texto de diálogo continuo. Aquí hay un ejemplo:
Supongamos que hay las siguientes múltiples rondas de diálogo:
Usuario: Hola, Zhang Yanfeng escribió un blog llamado "Comprensión preliminar de los modelos grandes de la ciencia popular", ¿puede darme la dirección?
Modelo: Hola, según sus requisitos, la dirección del blog correspondiente es: https://blog.csdn.net/xiaofeng10330111/article/details/132718410.
Usuario: ¡Vale, gracias!
Ahora, para convertir esta conversación de varios turnos en una tarea de continuación, primero debe formatear la conversación en un fragmento de texto, generalmente usando marcadores o delimitadores especiales para representar cada turno de conversación. El texto de conversación formateado podría verse así:
"[U1: Hola, Zhang Yanfeng escribió un blog llamado "Comprensión científica popular preliminar de modelos grandes". ¿Puede proporcionarme la dirección? M1: Hola, según su solicitud, la dirección del blog correspondiente es: https://blog .csdn.net/xiaofeng10330111/article/details/132718410. U2: ¡Está bien, gracias!]"
En este texto de conversación formateado, U1 representa la primera ronda de entrada del usuario, M1 representa la primera ronda de respuestas del modelo y U2 representa la segunda ronda de entrada del usuario. Ahora, el modelo puede tratar todo el historial de conversaciones como un fragmento de texto y utilizar la tarea de continuación para generar la siguiente ronda de respuestas.
Por ejemplo, si quieres continuar la conversación:
Usuario: Ayúdame a ordenar el resumen de ideas correspondiente.
Luego, agregue esta entrada del usuario al texto de conversación formateado y el modelo continuará generando la siguiente respuesta:
"[U1: Hola, Zhang Yanfeng escribió un blog llamado "Comprensión científica popular preliminar de modelos grandes". ¿Puede proporcionarme la dirección? M1: Hola, según su solicitud, la dirección del blog correspondiente es: https://blog "
Al iterar continuamente este proceso, el modelo puede completar múltiples rondas de diálogo y generar respuestas coherentes, haciendo que el usuario sienta que se está comunicando con una entidad inteligente que puede comprender y responder a múltiples rondas de diálogo. Aunque el modelo en sí no tiene memoria real, logra el efecto de múltiples rondas de diálogo al comprender y continuar la historia del diálogo. Este método se puede aplicar a tareas de conversación de varios turnos, como chatbots, asistentes virtuales y servicio de atención al cliente inteligente.
4. Ejemplos de métodos de alineación comunes
Existen muchos métodos para alinear modelos de lenguaje grandes que tienen como objetivo garantizar que el comportamiento generado por el modelo se ajuste a expectativas, requisitos y reglas específicas. A continuación se muestran algunos métodos de alineación comunes:
-
Ajuste fino supervisado (SFT) : como se mencionó anteriormente, este método permite que el modelo realice tareas específicas u obedezca reglas específicas entrenando al modelo para que comprenda y siga instrucciones específicas.
-
Red de políticas : este enfoque implica el uso de una red neuronal adicional para generar una política que determina el comportamiento que debe adoptar el modelo al generar texto. Este método se puede utilizar para guiar el modelo para generar tipos específicos de texto, como texto de cumplimiento, texto emocional, etc.
-
Coincidencia de plantillas : la coincidencia de plantillas es un método para hacer coincidir el texto generado de un modelo con una plantilla de texto predefinida. Estas plantillas pueden contener una estructura y una sintaxis específicas para garantizar que el texto generado cumpla con los requisitos.
-
Aprendizaje por refuerzo : en los métodos de aprendizaje por refuerzo, el modelo aprende a generar texto interactuando con el entorno. A través de señales de recompensa y castigo, el modelo puede ajustar gradualmente el comportamiento generado para hacerlo más consistente con las expectativas.
-
Motor de reglas : el motor de reglas es un enfoque basado en reglas y lógica para controlar el comportamiento de generación de un modelo. Al definir un conjunto de reglas, se puede dirigir el modelo para que genere tipos específicos de texto.
-
Detección y filtrado : este enfoque implica el uso de técnicas de procesamiento de lenguaje natural y modelos de aprendizaje automático para detectar y filtrar texto dañino o no conforme. Una vez que se detecta texto que no cumple, se pueden tomar las medidas adecuadas, como eliminarlo, modificarlo o marcarlo.
-
Revisión y edición humana : en algunos casos, la alineación se puede lograr mediante revisión y edición humana. Los revisores humanos pueden revisar el texto generado por el modelo y realizar las ediciones y correcciones necesarias para garantizar que el texto cumpla con los requisitos.
Estos métodos de alineación se pueden utilizar individualmente o en combinación, según el escenario y los requisitos de la aplicación. La alineación es un paso fundamental para garantizar que los modelos de lenguaje grandes se comporten de manera adecuada, sean prácticos y seguros en una variedad de aplicaciones. Se pueden utilizar diferentes métodos para diferentes tareas y dominios para satisfacer las necesidades y expectativas del usuario.
3. Cómo controlar modelos grandes
En el pasado, definimos interfaces para el sistema y diseñamos las capacidades que el sistema puede proporcionar, pero en el futuro, el sistema central tendrá solo una interfaz, que es el lenguaje natural, y nosotros mismos aprendemos sus capacidades. Nuestro sistema de ingeniería debe construirse en torno a este núcleo de IA, y los ingenieros deben saber cómo comunicarse con la IA mejor que otros (con la ayuda de una ingeniería rápida).
(1) proyecto rápido
introducir:
-
El objetivo principal del proyecto Prompt es garantizar que los modelos de lenguaje a gran escala generen texto como los usuarios esperan y sigan reglas y convenciones específicas para cumplir con los requisitos de la tarea.
-
El mensaje es una entrada de texto proporcionada por el usuario al modelo, que generalmente incluye preguntas, instrucciones o contexto, que se utiliza para guiar al modelo a generar las respuestas de texto correspondientes.
-
Los proyectos rápidos tienen una amplia gama de aplicaciones, que incluyen generar artículos, responder preguntas, traducir texto, crear historias, escribir código y más.
Instrucciones de uso:
Pasos generales para utilizar proyectos rápidos:
-
Identifique la tarea u objetivo : primero, identifique la tarea o el tipo de texto que desea que el modelo realice o genere. Puede ser una pregunta, una descripción de la tarea u otro requisito.
-
Diseñe un mensaje claro : cree un mensaje claro e inequívoco para guiar al modelo a través de la tarea. Las indicaciones deben incluir suficiente información para que el modelo comprenda los requisitos de la tarea. Evite indicaciones ambiguas o vagas.
-
Considere las tendencias del modelo : teniendo en cuenta las posibles tendencias y preferencias del modelo, el diseño sugiere de una manera que sea fácil de entender y seguir para el modelo. Si el modelo tiende a generar texto largo, puede solicitar explícitamente generar respuestas breves.
-
Indicaciones de prueba y ajuste : utilice indicaciones diseñadas para realizar solicitudes al modelo y observar el texto resultante. Si los resultados no son los esperados, pruebe con un mensaje diferente o ajústelo para mejorar los resultados. Esto puede requerir varios intentos y experimentos.
-
Cumplimiento y seguimiento de las instrucciones : asegúrese de que el modelo siga las instrucciones y produzca el texto como se esperaba. Supervise el texto generado y, si nota un comportamiento que no cumple con sus expectativas, puede intentar ajustar las sugerencias para tener un mejor control sobre su modelo.
-
Manejar casos extremos : considere los casos extremos que puedan surgir, como lidiar con instrucciones negativas, manejar tareas complejas o imponer límites de longitud al texto.
-
Bucle de retroalimentación : recopile continuamente los comentarios generados por el modelo, ajuste y mejore los consejos en función de los comentarios, para que el modelo genere mejores resultados.
-
Pruebas y Validación : Los textos generados se prueban y validan para garantizar que cumplen con los requisitos y estándares de calidad de la tarea.
-
Automatización e integración : integre la ingeniería rápida en procesos automatizados según sea necesario para generar texto a escala o manejar una gran cantidad de solicitudes.
Tenga en cuenta que cada tarea y aplicación puede requerir un enfoque diferente para impulsar la ingeniería. Estos pasos se pueden personalizar y adaptar a la situación específica. Cuando se utilizan métodos rápidos de ingeniería, la práctica y la experiencia suelen ser factores clave para mejorar la calidad de los resultados. Sigue probando y mejorando las indicaciones para que el modelo genere el texto deseado o realice la tarea.
(2) Entrenamiento secundario del modelo.
1.Descripción general
El entrenamiento secundario del modelo se refiere al entrenamiento adicional del modelo después de haber sido entrenado previamente para hacerlo más adecuado a las necesidades de una tarea o dominio específico. Este enfoque puede ayudarnos a ganar más libertad y flexibilidad en el control del modelo.
- Personalización de tareas: el entrenamiento secundario del modelo permite personalizarlo para una tarea o dominio específico . Esto significa que puede aplicar sus modelos a una amplia gama de escenarios de aplicación, incluido el procesamiento del lenguaje natural, la visión por computadora, el procesamiento de audio y más.
- Anotación de datos: antes de la capacitación secundaria, generalmente es necesario preparar datos de anotación relacionados con la tarea de destino. El modelo utiliza estos datos para realizar un aprendizaje supervisado en una tarea específica. Por ejemplo, en una tarea de clasificación de texto, es necesario preparar datos de texto con etiquetas.
- Ajuste fino: la formación secundaria suele utilizar un método llamado Ajuste fino . En Fine-Tuning, el modelo utiliza parámetros previamente entrenados como pesos iniciales y luego realiza un entrenamiento adicional sobre datos específicos de la tarea. Esto permite que el modelo conserve el conocimiento general del modelo previamente entrenado y se adapte a los requisitos de una tarea específica.
- Controlar el comportamiento del modelo: al diseñar datos de entrenamiento y funciones de pérdida adecuados durante el proceso de ajuste fino, se puede controlar el comportamiento del modelo para adaptarlo a las necesidades específicas de la tarea. Por ejemplo, en la tarea de generar texto, se pueden utilizar diferentes funciones de pérdida para controlar la calidad y el estilo del texto generado.
- Aprendizaje multitarea: la formación secundaria también apoya el aprendizaje multitarea . Esto significa que puede realizar ajustes finos en múltiples tareas al mismo tiempo en un modelo, lo que permite que el modelo realice múltiples tareas relacionadas al mismo tiempo, aumentando así la versatilidad del modelo.
- Adaptación de dominio: el entrenamiento secundario del modelo también es muy útil para tareas que deben adaptarse a diferentes dominios o dominios específicos . Un modelo se puede ajustar utilizando datos de un dominio específico para que funcione mejor en las tareas de ese dominio.
- Controlar la salida: al ajustar los datos de entrenamiento y la función de pérdida, puede controlar el texto o la forma de salida generada por el modelo para garantizar que cumpla con los requisitos de la tarea o aplicación. Este enfoque ayuda a evitar contenido inapropiado u ofensivo .
En resumen, el entrenamiento secundario de modelos es una técnica poderosa que permite personalizar modelos de lenguaje grandes para una variedad de tareas y aplicaciones. A través de datos cuidadosamente diseñados y estrategias de capacitación, se puede lograr el objetivo de controlar el comportamiento del modelo de manera más libre y flexible. Este enfoque se utiliza ampliamente en muchas aplicaciones en los campos del procesamiento del lenguaje natural y la inteligencia artificial.
2. Dé un ejemplo de una tarea: Análisis de sentimiento
Suponga que desea crear un modelo de análisis de sentimientos que pueda analizar el sentimiento de una revisión de texto, como positivo, negativo o neutral. Ya tiene un gran conjunto de datos de reseñas de texto, que incluye texto de reseñas y etiquetas de opiniones (por ejemplo, "positivo", "negativo", "neutral"). Ejemplo de pasos:
-
Preparación de datos: primero, debe preparar el conjunto de datos requerido para la tarea de análisis de sentimiento . Esto incluye texto de reseña y etiquetas de opinión. Es posible que también necesite preprocesar el texto, como tokenización, eliminación de palabras vacías, etc.
-
Selección de modelo: puede elegir un modelo de lenguaje grande previamente entrenado, como GPT-3 o BERT, como modelo base para la capacitación secundaria . Este modelo básico ya tiene capacidades ricas de comprensión del lenguaje, pero necesita adaptarse aún más a las tareas de análisis de sentimientos.
-
Ajuste fino: en la etapa de ajuste fino, el modelo se entrenará utilizando el conjunto de datos de análisis de sentimiento preparado . El objetivo es que el modelo aprenda a comprender el texto de la reseña y prediga las etiquetas de opinión correspondientes. Se puede diseñar una función de pérdida para que las predicciones del modelo sean lo más consistentes posible con las etiquetas.
-
Control del modelo: durante el proceso de ajuste fino, se puede introducir un mecanismo de control para garantizar que los resultados del análisis de sentimiento generados por el modelo cumplan con sus expectativas. Por ejemplo, puede agregar una etiqueta de control o directiva que le indique al modelo que genere texto relevante para el análisis de opiniones. Esto ayuda a garantizar que el modelo produzca los resultados esperados.
-
Evaluación y ajuste: después de completar el ajuste, debe evaluar el rendimiento del modelo en las tareas de análisis de sentimiento. El conjunto de validación se puede utilizar para la evaluación y el modelo se puede ajustar en función de métricas de rendimiento como la precisión, la puntuación F1, etc. Si el modelo funciona mal, puede continuar con el ajuste fino o probar diferentes arquitecturas y parámetros.
-
Implementación y aplicación: una vez que un modelo funciona bien en una tarea de análisis de sentimientos, se puede implementar en un entorno de producción para analizar comentarios o texto proporcionados por los usuarios. El modelo genera resultados de análisis de opiniones basados en el texto de entrada para satisfacer las necesidades de su aplicación.
Con este ejemplo, puede ver cómo el entrenamiento secundario de un modelo le permite adaptarlo a las necesidades de una tarea específica, con mecanismos de control para garantizar que el texto generado por el modelo coincida con el uso previsto. Este método se puede aplicar a diversas tareas de procesamiento del lenguaje natural y escenarios de aplicación.
3. Ampliación: Alinear el modelo con nuestras expectativas de uso.
El entrenamiento secundario del modelo puede ayudar a garantizar que el modelo esté alineado con nuestras expectativas de uso, es decir, que el texto generado por el modelo o las tareas realizadas por el modelo cumplan con nuestras intenciones y expectativas.
Ajuste fino de instrucciones (SFT, ajuste fino supervisado): en la capacitación secundaria, el método de ajuste fino de instrucciones se puede utilizar para guiar el comportamiento del modelo proporcionando instrucciones claras. Estas instrucciones le dicen al modelo cómo manejar tipos específicos de solicitudes, asegurando que el resultado del modelo sea consistente con nuestras expectativas de uso.
Ejemplo: si desea que el modelo responda correctamente a las preguntas de geografía, puede ajustar las instrucciones proporcionando instrucciones como "Responda la siguiente pregunta de geografía:" o "Proporcione respuestas a las siguientes preguntas:" y luego proporcione una serie de preguntas de geografía. Esto hará que el modelo comprenda que necesita responder estas preguntas en lugar de generar otro tipo de texto.
2. Controlar el estilo y la calidad de la generación: al diseñar una función de pérdida adecuada en la capacitación secundaria, se puede controlar el estilo, la calidad y la coherencia del texto generado para garantizar que el texto cumpla con nuestras expectativas de uso.
Ejemplo: si desea que su modelo genere informes formales de noticias tecnológicas, puede usar una función de pérdida en el entrenamiento secundario que requiere que el texto generado tenga un estilo de lenguaje formal y garantice que el texto no contenga contenido ofensivo.
3. Adaptación del dominio: en la capacitación secundaria, puede utilizar datos de un dominio específico para adaptar el modelo a las tareas y necesidades del dominio específico para garantizar que se cumpla el uso esperado del modelo en ese dominio.
Ejemplo: si desea que el modelo brinde asesoramiento médico profesional en el campo médico, puede utilizar literatura médica y datos médicos para el ajuste fino para que el modelo comprenda la terminología médica y los conocimientos relacionados para satisfacer mejor las expectativas de uso en el campo médico.
4. Monitorear y ajustar: mientras usa el modelo, monitoree continuamente el texto generado o las tareas realizadas e intervenga o ajuste según sea necesario. Esto ayuda a garantizar que el modelo se comporte como se espera para nuestro uso.
Ejemplo: si el modelo genera texto inapropiado en determinadas situaciones, puede desarrollar mecanismos de seguimiento para detectar y filtrar este texto para garantizar que el resultado del modelo se alinee con nuestras expectativas.
A través del método anterior, el comportamiento del modelo se puede guiar en el entrenamiento secundario del modelo para satisfacer mejor nuestras expectativas de uso y garantizar que el texto generado o las tareas realizadas sean consistentes con nuestras intenciones. Esta alineación se logra mediante un diseño y control cuidadosos en diferentes etapas del entrenamiento y uso del modelo.
(3) Preprocesamiento y posprocesamiento basado en reglas
El preprocesamiento y posprocesamiento basado en reglas son componentes clave en el entrenamiento secundario del modelo, que se pueden utilizar para controlar el comportamiento del modelo y garantizar que el texto generado o las tareas realizadas cumplan con nuestras expectativas.
Preprocesamiento basado en reglas
El preprocesamiento es el proceso de procesar o transformar datos de entrada antes de pasarlos al modelo. Se puede utilizar para preparar datos de entrada, guiar el comportamiento del modelo o garantizar que los datos de entrada se ajusten a un formato o requisitos específicos.
Ejemplo 1: tareas generativas
Suponiendo que está creando un modelo de generación automática de resumen de texto, puede realizar las siguientes tareas en la etapa de preprocesamiento:
- Elimine texto o marcas irrelevantes, como anuncios, texto ruidoso, etc.
- Extraiga oraciones o párrafos clave para utilizarlos en la generación de resúmenes.
- Tokenice y segmente el texto de entrada para que el modelo pueda comprenderlo y procesarlo mejor.
Ejemplo 2: sistema de diálogo
Si está desarrollando un sistema de diálogo, puede hacer lo siguiente en el preprocesamiento:
- Detectar y corregir errores ortográficos en las entradas del usuario.
- Identificar y extraer información clave de las preguntas de los usuarios.
- Convierta la entrada del usuario a un formato específico para guiar al modelo a generar respuestas relevantes.
Postprocesamiento basado en reglas
El posprocesamiento es el proceso de procesar o modificar los resultados generados después de que el modelo genera texto. Se utiliza para garantizar que el texto generado por el modelo cumpla con estándares o requisitos específicos.
Ejemplo 1: tarea de generación de texto
Suponiendo que está realizando una tarea de generación de texto, puede realizar las siguientes tareas en la etapa de posprocesamiento:
- Elimine contenido inapropiado o información confidencial del texto generado para garantizar la seguridad del texto.
- Ajuste la longitud del texto generado para cumplir con las restricciones o requisitos de longitud.
- Se verifica la sintaxis y la semántica del texto generado para garantizar su calidad y precisión.
Ejemplo 2: sistema de diálogo
Si su sistema de diálogo genera una serie de respuestas de diálogo, puede hacer lo siguiente en el posprocesamiento:
- Ordena las respuestas generadas y selecciona las más adecuadas.
- Ajuste las respuestas generadas según los comentarios de los usuarios o la información contextual.
- Detecta y filtra información redundante o contenido duplicado en las respuestas generadas.
A través del preprocesamiento y posprocesamiento basado en reglas, puede guiar el comportamiento del modelo, garantizar que el texto generado o las tareas realizadas sean los esperados y mejorar la controlabilidad y confiabilidad del modelo. Estas reglas se pueden diseñar y optimizar en función de los requisitos de la tarea y las características de comportamiento del modelo.
(4) Límites y limitaciones de los modelos grandes.
-
Alucinaciones: los modelos grandes pueden presentar alucinaciones al generar texto, inventarlo o no proporcionar información precisa y confiable. Esto se debe a que el modelo puede aprender información inexacta o falsa durante la etapa previa al entrenamiento, lo que resulta en una disminución en la calidad del contenido generado. Por ejemplo, un modelo puede fabricar hechos o acontecimientos históricos falsos.
-
Inestabilidad: la salida del modelo puede mostrar inestabilidad de una ejecución a otra. La misma entrada puede generar resultados diferentes, lo que dificulta la reproducibilidad del modelo. Esta inestabilidad puede generar resultados inconsistentes, especialmente en aplicaciones que requieren coherencia, como la toma de decisiones automatizada o las tareas de generación automatizadas.
-
No tiene conocimiento en tiempo real: los datos con los que los modelos grandes entran en contacto durante la etapa de preentrenamiento suelen ser estáticos y no pueden reflejar eventos o información actuales de manera oportuna. Por lo tanto, el modelo no puede proporcionar conocimiento o actualizaciones de información en tiempo real. Para aplicaciones que requieren información oportuna, los modelos grandes pueden no ser adecuados.
-
Longitudes de entrada y salida restringidas: los modelos grandes suelen tener limitaciones en la longitud del texto de entrada y del texto generado. Si la longitud de la entrada o del texto generado excede los límites del modelo, el modelo puede truncar o descartar partes del contenido, lo que resulta en información incompleta o poco clara. Esto puede ser un desafío para las aplicaciones que necesitan procesar textos largos o conversaciones largas.
-
Capacidad de respuesta limitada: la inferencia en modelos grandes puede ser lenta, especialmente sin recursos informáticos masivamente paralelos. Esto afecta al rendimiento de las aplicaciones en tiempo real, como los sistemas de conversación en tiempo real o el análisis de datos en tiempo real.
-
Capacidad limitada para seguir instrucciones: los modelos grandes pueden tener ciertas limitaciones para seguir instrucciones. Aunque el modelo puede comprender las instrucciones y realizar la tarea, en algunas situaciones complejas o poco claras, es posible que el modelo no comprenda o no siga las instrucciones correctamente. Esto puede hacer que el modelo produzca resultados inesperados.
En conjunto, los modelos grandes tienen limitaciones y deficiencias en ciertos aspectos, incluida la calidad, la estabilidad, la naturaleza en tiempo real del contenido generado, las limitaciones de entrada y salida, la velocidad de respuesta y la capacidad de seguir instrucciones. Al aplicar modelos grandes, se deben considerar estas limitaciones y, si es necesario, tomar medidas para abordar o mitigar estos problemas para garantizar que el modelo pueda ejecutarse de manera efectiva en tareas y escenarios específicos. Al mismo tiempo, los modelos de diferentes tamaños pueden funcionar de manera diferente en diferentes aplicaciones, y el tamaño del modelo y los requisitos de la tarea deben considerarse de manera integral.
4. Entrando al gran modelo
Para experimentarlo a través de un modelo existente, descargue directamente PharMolix/OpenBioMed en github . Este es el primer modelo de biomedicina multimodal disponible comercialmente en el mundo con decenas de miles de millones de parámetros a gran escala, BioMedGPT-10B de código abierto del equipo de Zhang Tielei . tiene características biológicas únicas: las capacidades de generación de texto en el campo profesional médico son comparables a las de los expertos humanos y ha alcanzado SOTA en tareas intermodales de preguntas y respuestas en lenguaje natural, moléculas y proteínas. Al mismo tiempo, este repositorio también abrió el primer modelo de lenguaje comercial gratuito Llama 2 para biomedicina del mundo, BioMedGPT-LM-7B (el siguiente tutorial introductorio se basa en este modelo 7B como ejemplo).
Configuración del entorno Mac
entorno de conda
Anaconda es una poderosa herramienta para administrar entornos Python. Puede crear y administrar múltiples entornos Python independientes y aislados, e instalar y administrar dependencias de Python en los entornos. Puedes utilizar MiniConda, su versión gratuita y de mínima disponibilidad. Puede encontrar el enlace de descarga correspondiente y el método de instalación en Miniconda - documentación de conda .
mkdir -p ~/miniconda3
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh -o ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
//After installing, initialize your newly-installed Miniconda. The following commands initialize for bash and zsh shells:
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zshentorno Python
Después de instalar miniconda, puede crear un entorno Python, donde se crea y activa un entorno Python llamado biomedgpt conda activate.
cd /Users/zyf/miniconda3/bin
./conda create -n biomedgpt python=3.10
./conda activate biomedgptPara ejecutar BioMedGPT-LM-7B, necesitamos instalar pytorch y transformadores.
./conda install pytorch torchvision torchaudio -c pytorch -c conda-forge
pip install transformersDescarga del modelo
Dado que el archivo del modelo es grande, también es necesario instalar Git Large File Storage.
brew install git-lfsLuego puedes descargarlo a través de git clone.
cd /Users/zyf/zyfcodes/jpt
git clone https://huggingface.co/PharMolix/BioMedGPT-LM-7BCarga de modelo
BioMedGPT-LM-7B se basa en meta-llama/Llama-2-7b y se entrena incrementalmente en corpus biomédicos. El método de carga del modelo es consistente con el método de carga del modelo llama2-7B. Podemos cargar el modelo directamente a través de transformadores. También puede imprimir directamente (modelo) para imprimir la estructura del modelo. Para obtener detalles específicos del modelo, puede consultar el sitio web oficial y el informe técnico de llama2.
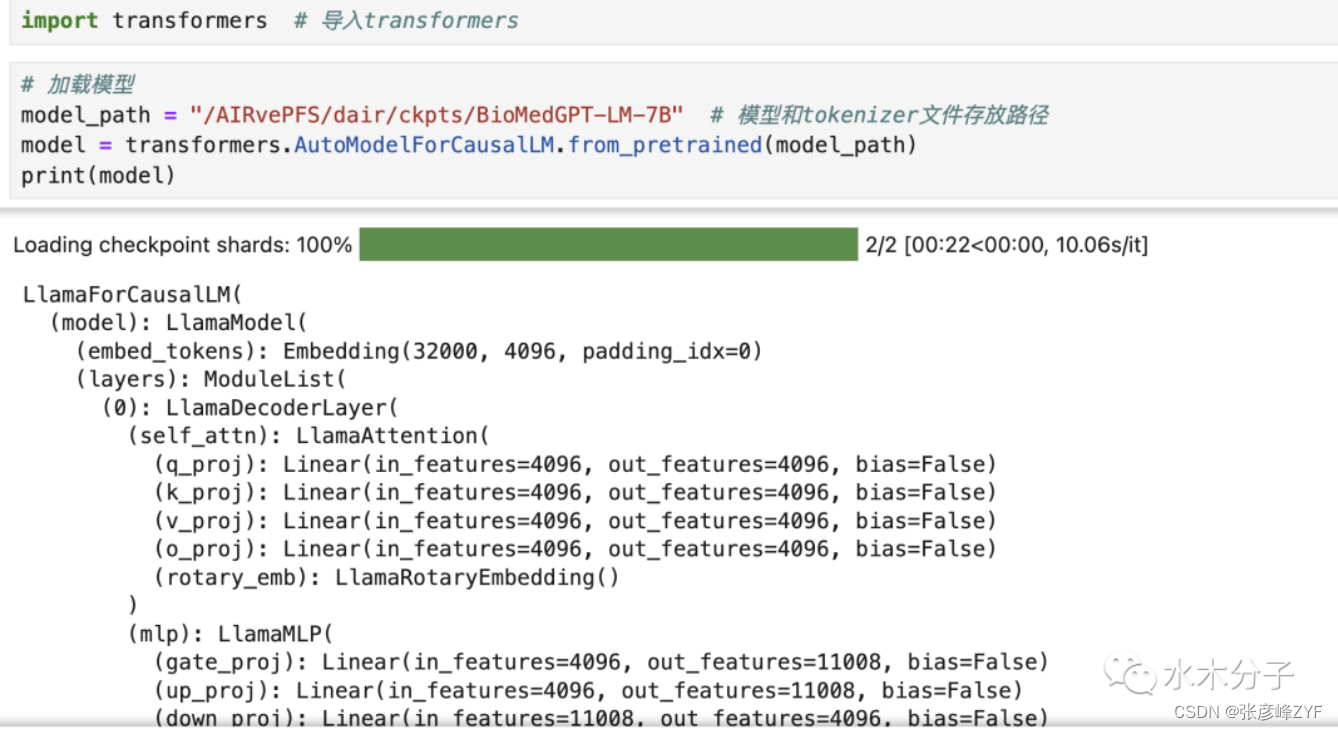
La función from_pretrained de transformadores.AutoModelForCausalLM puede descargar directamente el modelo desde el almacén de huggingface o cargar el modelo descargado localmente. model_path es la ruta donde almacena los archivos del modelo y del tokenizador. Al ejecutar el código anterior, cargamos con éxito el modelo BioMedGPT-LM-7B en la computadora portátil Mac. Podemos imprimir el modelo directamente y ver la información detallada del modelo. Si indica que no hay memoria suficiente, se recomienda cerrar primero otros procesos innecesarios.
Carga del tokenizador
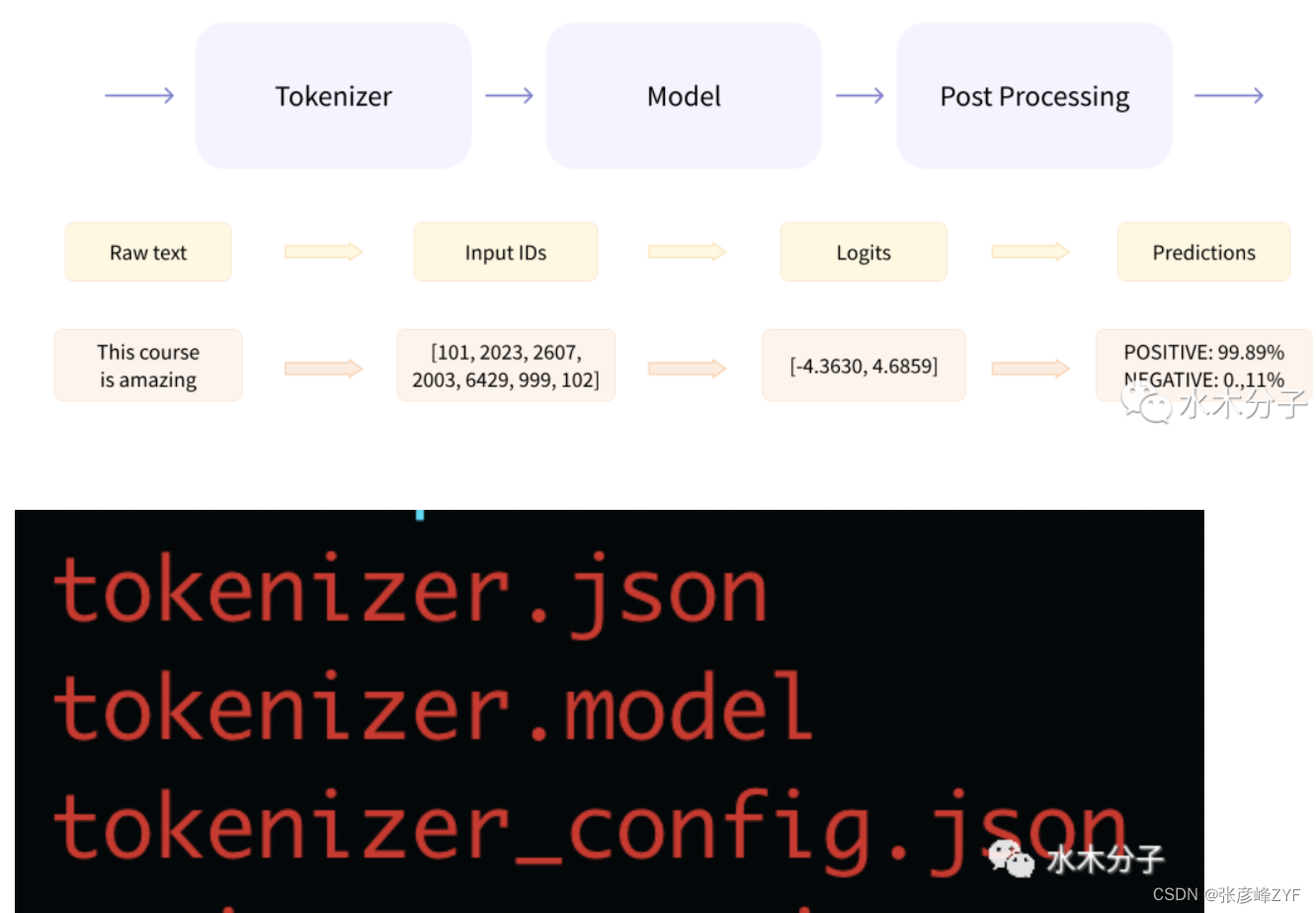
Como se muestra en la figura siguiente (de la documentación oficial de huggingface), el texto debe pasar por tres pasos desde que se pasa al modelo hasta que se genera el resultado. Tokenizer divide el texto de entrada en tokens uno por uno y luego convierte los tokens en vectores. El modelo es responsable de extraer información semántica basada en las variables de entrada y generar logits. Finalmente, el posprocesamiento realiza tareas específicas de PNL, como emociones, basadas en sobre la información semántica generada por el modelo, análisis, clasificación de textos, etc. A continuación, debemos cargar el tokenizador correspondiente al modelo. Los archivos relacionados con el tokenizador y los archivos del modelo se encuentran en la carpeta BioMedGPT-LM-7B/. Entre ellos, tokenizer.json almacena el vocabulario del tokenizer, tokenizer_config.json contiene parámetros relacionados con el tokenizer y tokenizer.model almacena los parámetros del modelo.
Utilice tokenizer para procesar el texto de entrada y obtener la representación vectorial requerida por el modelo.

input_ids es la identificación del vocabulario correspondiente a cada token. Úselo como entrada del modelo para obtener la identificación del token de salida y luego decodifique la salida en texto a través del método decodificador del tokenizador.
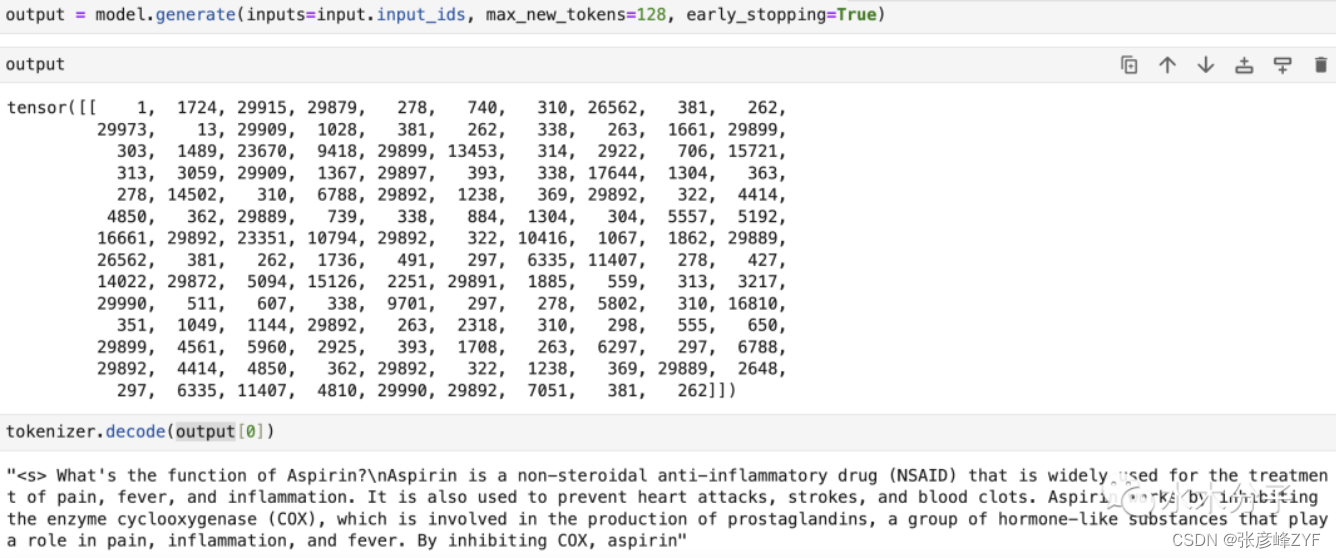
En este punto, cargamos con éxito el modelo grande 7B en el cuaderno y lo usamos para generar un fragmento de texto. Tenga en cuenta que dado que este tutorial se ejecuta en una computadora portátil usando la CPU y el modelo 7B tiene hasta 7 mil millones de parámetros, el proceso de inferencia del modelo de model.generate lleva mucho tiempo y debe esperar pacientemente hasta que se obtenga el resultado. (La ejecución puede tardar 2 horas).
Esta parte no se está ejecutando y se realizará una nueva prueba más adelante.
Lectura recomendada: interpretación del código fuente de Spring Boot y análisis de principios
El predecesor de este libro es el folleto más vendido en la comunidad de Nuggets: "Análisis de principios e interpretación del código fuente de Spring Boot". Más de 3600 desarrolladores de toda la comunidad han elegido este folleto, lo que lo convierte en el folleto líder en la comunidad de Nuggets. ¡El tutorial de primavera de la carta de triunfo es muy bueno!
Este folleto ha colocado al autor en el Top 40 de la Lista de popularidad de 2020 y ha recibido 8 medallas de honor. El volumen de ventas en el sitio está muy por delante. Los lectores lo consideran un trabajo concienzudo, les gusta y lo llaman .
Sin embargo, debido al volumen y extensión limitados del folleto, los lectores han expresado que aún no están terminados y les gustaría obtener más información útil y esperan que el autor pueda explicarlo con más detalle y profundidad.
Si desea tener una experiencia de aprendizaje relativamente razonable, fluida y sistemática, este libro es perfecto.
Dado que este libro es una actualización basada en el folleto, el contenido del libro es más sistemático, está optimizado en función de los comentarios de los lectores del folleto y la explicación es más profunda y detallada. ¡No es sólo una actualización, es una actualización!
A diferencia de la explicación del conocimiento centralizado en el folleto, Linked-Bear ha reorganizado el contenido en las siguientes cuatro partes para explicar el conocimiento de lo más superficial a lo más profundo.
Parte 1: El contenedor central en el que se basa Spring Boot en la parte inferior
presenta principalmente el conocimiento básico subyacente, con el objetivo de ayudar al autor a sentar una base sólida. Primero, revisamos el conocimiento de Spring Boot desde un nivel general, lo que permite a los lectores revisar rápidamente la lógica subyacente y el conocimiento central de Spring Boot. Este conocimiento es la base para la posterior programación y aplicación.
Parte 2: Análisis de los principios del ciclo de vida de Spring Boot. Tomando
los eventos emitidos en cada período del ciclo de vida como línea principal, combinados con los principales eventos completados en cada ciclo de vida, puede tener una descripción general de Spring Boot y obtener una visión más profunda. comprensión de Spring Boot.
Parte 3: Spring Boot integra escenarios de desarrollo comunes.
En correspondencia con los contenedores principales de las dos primeras partes, se explica la configuración del módulo y se demuestra la aplicación del módulo en diferentes escenarios. Esta parte del contenido está muy cerca del combate real y estas tecnologías se pueden utilizar en comercio electrónico, servicios de puerta de enlace, bases de datos y otros escenarios.
Parte 4: Ejecución de aplicaciones Spring Boot
Spring Boot tiene múltiples métodos de empaquetado. El autor eligió dos métodos para explicar el proceso de inicio de la aplicación respectivamente e introdujo la función de apagado elegante introducida en la nueva versión. ¡Después de estudiar este capítulo, podrás dominar Spring Boot por completo! Se centra en la investigación de sistemas distribuidos y algoritmos de aprendizaje automático, y ha publicado artículos en importantes conferencias académicas en múltiples campos, como teoría, aprendizaje automático, aplicaciones y sistemas operativos.
Descripción general de sitios de aprendizaje y tutoriales
Sitio web y tutoriales
-
Sitio web oficial de OpenAI : el sitio web oficial de OpenAI generalmente proporciona información sobre sus últimas investigaciones y desarrollo, así como tutoriales y documentación relacionados. Allí podrás encontrar los últimos avances y tecnologías en cuanto a modelos de gran tamaño.
-
Especialización en aprendizaje profundo : el curso de especialización en aprendizaje profundo en Coursera organizado por el profesor Andrew Ng incluye contenido relacionado con grandes redes neuronales. Este curso proporciona los conceptos básicos del aprendizaje profundo, incluido el procesamiento del lenguaje natural y los modelos generativos.
-
Cursos en la Universidad de Stanford : La Universidad de Stanford ofrece algunos cursos relacionados con el aprendizaje profundo y el procesamiento del lenguaje natural. Los materiales de sus cursos generalmente están disponibles de forma gratuita en línea, incluidos apuntes de conferencias, videos y tareas.
-
GitHub : Hay muchos proyectos de código abierto y repositorios de código en GitHub que pueden brindarle información sobre la implementación y aplicación de modelos grandes. Por ejemplo, puede encontrar varios modelos y herramientas previamente entrenados para tareas de procesamiento del lenguaje natural.
Libros :
-
"Aprendizaje profundo" de Ian Goodfellow, Yoshua Bengio y Aaron Courville: un clásico en el campo del aprendizaje profundo, que cubre los conceptos y técnicas básicos del aprendizaje profundo y es muy útil para comprender grandes redes neuronales y modelos de lenguaje.
-
"Procesamiento del lenguaje natural en acción" de Lane, Howard y Hapke: presenta los conceptos y técnicas centrales del procesamiento del lenguaje natural, incluida la aplicación de modelos de lenguaje grandes. Proporciona ejemplos prácticos y código.
-
"BERT (representaciones de codificador bidireccional de transformadores) explicadas" por Ben Trevett: un tutorial en línea que explica en detalle el principio de funcionamiento y la aplicación del modelo BERT. Es un excelente punto de partida para comprender los modelos previamente entrenados.
-
"GPT-3 y más allá: modelos generativos" de Benjamin Obi Tayo Ph.D.: este libro presenta modelos generativos (incluido GPT-3, etc.), que es muy útil para una comprensión profunda de los principios de funcionamiento y aplicaciones de Modelos lingüísticos a gran escala.
otro: