Sobre el fregadero
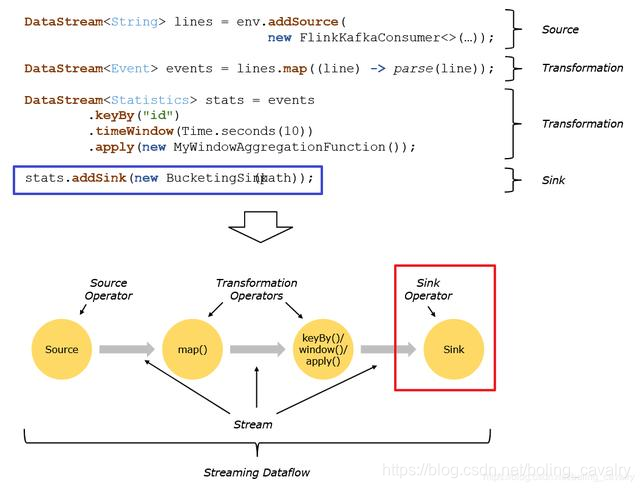
La siguiente imagen es del funcionario de Flink. El cuadro rojo es el sumidero. Se puede ver que los datos en tiempo real comienzan en la Fuente y terminan en el sumidero después de completar la lógica de negocios en la etapa de Transformación. Por lo tanto, el sumidero se puede usar para procesar los resultados del cálculo, como la salida de la consola o guardar la base de datos:
Una serie de artículos sobre "Combate de hundimiento de Flink"
Este artículo es la primera parte del "Combate del sumidero de Flink", cuyo objetivo es obtener una comprensión preliminar del sumidero. Mediante el análisis e investigación sobre la API básica y el método addSink, se sentará una base sólida para el posterior combate de codificación
Comience con un código de muestra
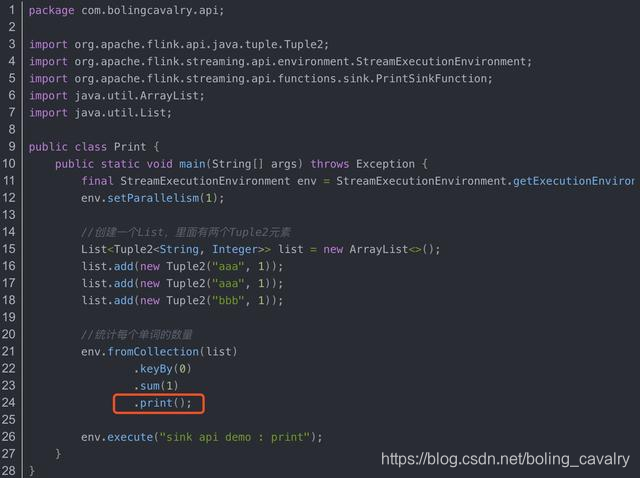
- El siguiente es un código simple de aplicación de parpadeo, el método de impresión en el cuadro rojo es la operación de sumidero:
- La siguiente figura es el método oficial de sumidero, que es la API de la clase DataStream. La llamada directa se puede utilizar para realizar el sumidero. La impresión en el código ahora es una de ellas:

- Luego, mire el código fuente de la API en la figura anterior. Primero mire el método de impresión. En DataStream.java, de la siguiente manera, se llama realmente al método addSink, y el parámetro de entrada es PrintSinkFunction:

- Otra API de uso común es writeAsText, el código fuente es el siguiente, el método writeUsingOutputFormat se llama:

- El seguimiento de writeUsingOutputFormat descubrió que addSink también se llamaba y que el parámetro de entrada era OutputFormatSinkFunction :

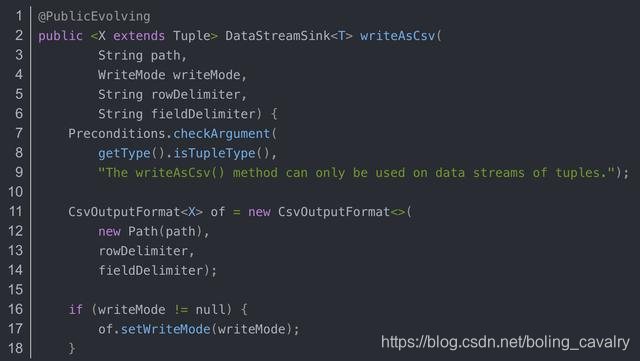
- AddSink se llama detrás de print y writeAsText, entonces, ¿qué pasa con otro método writeAsCsv comúnmente utilizado ? ¿Es posible llamar a addSink? Lo abrió y lo suficientemente seguro, y writeAsText como se pide writeUsingOutputFormat , y el método que está llamando addSink:
- En resumen, la clave del sumidero de datos es el parámetro de entrada de addSink , es decir , la implementación de la interfaz SinkFunction . A través del diagrama de clases, puede ver intuitivamente cómo se implementan las capacidades de sumidero comunes:
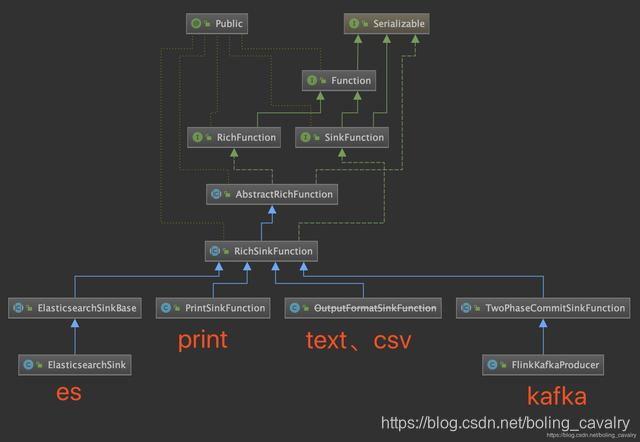
- De la figura anterior, podemos ver que la clase abstracta RichSinkFunction está estrechamente relacionada con varias capacidades de sumidero. Debemos centrarnos en ella y mostrar la firma del método en el diagrama de clases, como se muestra a continuación:
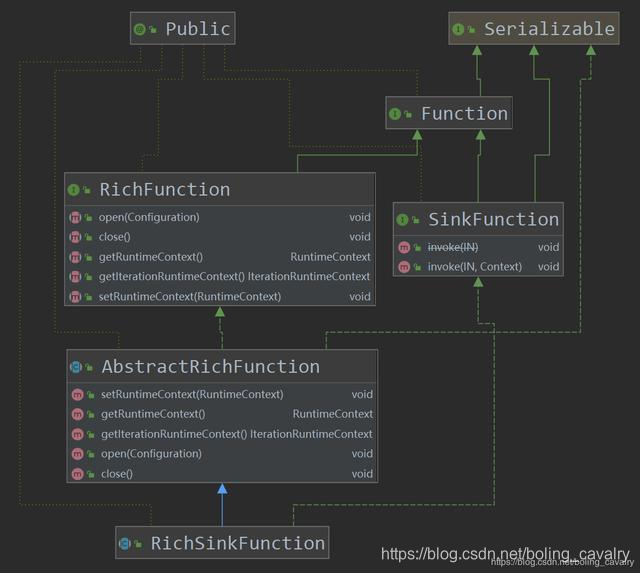
- Como se muestra en la figura anterior, RichSinkFunction en sí no tiene contenido, pero implementa SinkFunction y hereda AbstractRichFunction , que es una combinación de RichFunction y SinkFunction .
- Las características de RichFunction se han entendido en la "Trilogía de Flink DataSource" anterior , que es la apertura y cierre de recursos;
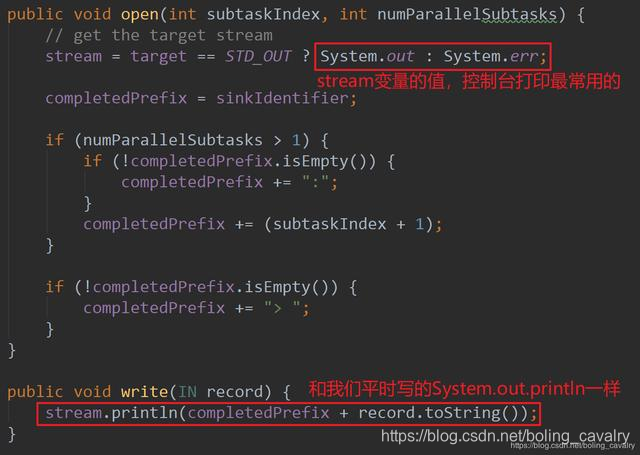
- ¿Cuáles son las características de SinkFunction ? Obviamente, se utiliza para procesar los resultados del cálculo. El diagrama de clase muestra dos métodos de invocación. Eche un vistazo al PrintSinkFunction.java oficial :

- El código fuente de writer.write (record) está en PrintSinkOutputWriter.java, como se muestra a continuación:
Resumen
Hasta ahora, tenemos una comprensión básica del fregadero de Flink:
- Responsable del procesamiento de resultados de cálculo en tiempo real (como salida o persistencia);
- El método de implementación principal es llamar al método DataStream.addSink;
- La forma principal de realizar varias capacidades de sumidero es implementar la interfaz definida por los parámetros de entrada del método addSink;
En los siguientes capítulos, realicemos juntos la codificación real del sumidero: la dirección del combate real: experimente las capacidades de sumidero provistas oficialmente e implemente capacidades de sumidero personalizadas;
