1. Introduction
I have never been exposed to the multi-modal direction before. This time I participated in a VQA-related competition with my senior colleagues at Byte and found that image-text based pre-training is a very hot field, such as BLIP, LAVT, etc. On this basis, a dual-stream visual-language interaction method was designed for the VQA Grounding task that not only requires answering questions but also visual segmentation, and finally achieved first place in the VizWiz VQA Grounding track of CVPR2022. Detailed introduction links are as follows:
Video:ByteDance&Tianjin University --- Aurora
论文链接: Tell Me the Evidence? Dual Visual-Linguistic Interaction for Answer Grounding
2. Introduction to the competition
"Visual question answering" is a fundamental challenge towards multi-modal artificial intelligence.
A natural application is to help the visually impaired people overcome the visual challenges in their daily lives. For example, the visually impaired people capture visual content through the lens of their mobile phone and then ask questions about the content in the lens through language. AI algorithms need to identify and describe objects or scenes and answer them in natural language.
At CVPR 2022, the authoritative visual question and answer competition VizWiz raised a new challenge: when AI answers (Talk) related visual questions, it must accurately highlight (Show) the corresponding visual evidence.

With the end-to-end DaVI (Dual Visual-Linguistic Interaction) new paradigm of visual language interaction, the Aurora team successfully won first place in the VizWiz 2022 Answer Grounding competition.
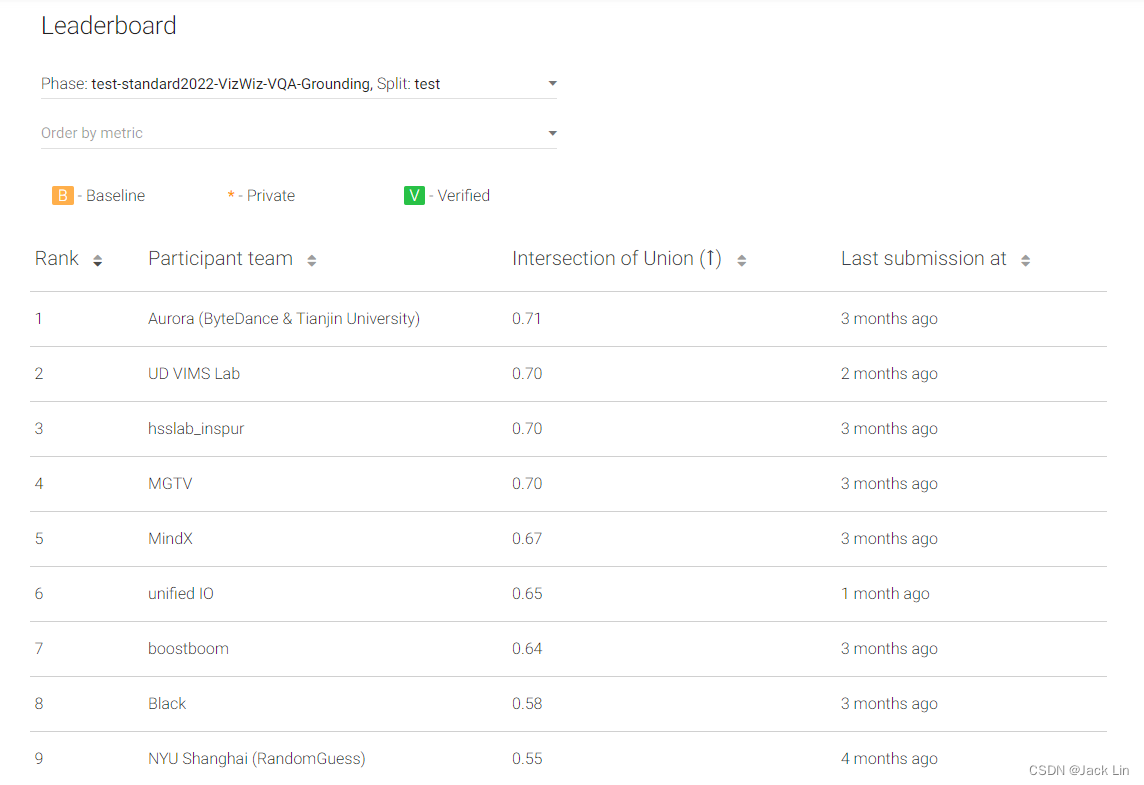
In this competition, Aurora competed with 60+ teams from well-known domestic and foreign research institutions and universities, including Google DeepMind, New York University, Inspur State Key Laboratory, Xi'an University of Electronic Science and Technology, and the University of Delaware.
The accuracy of the winning solution is 43.14% higher than the baseline algorithm, 3.65% ahead of the DeepMind team, which has been deeply involved in the multi-mode field for a long time.
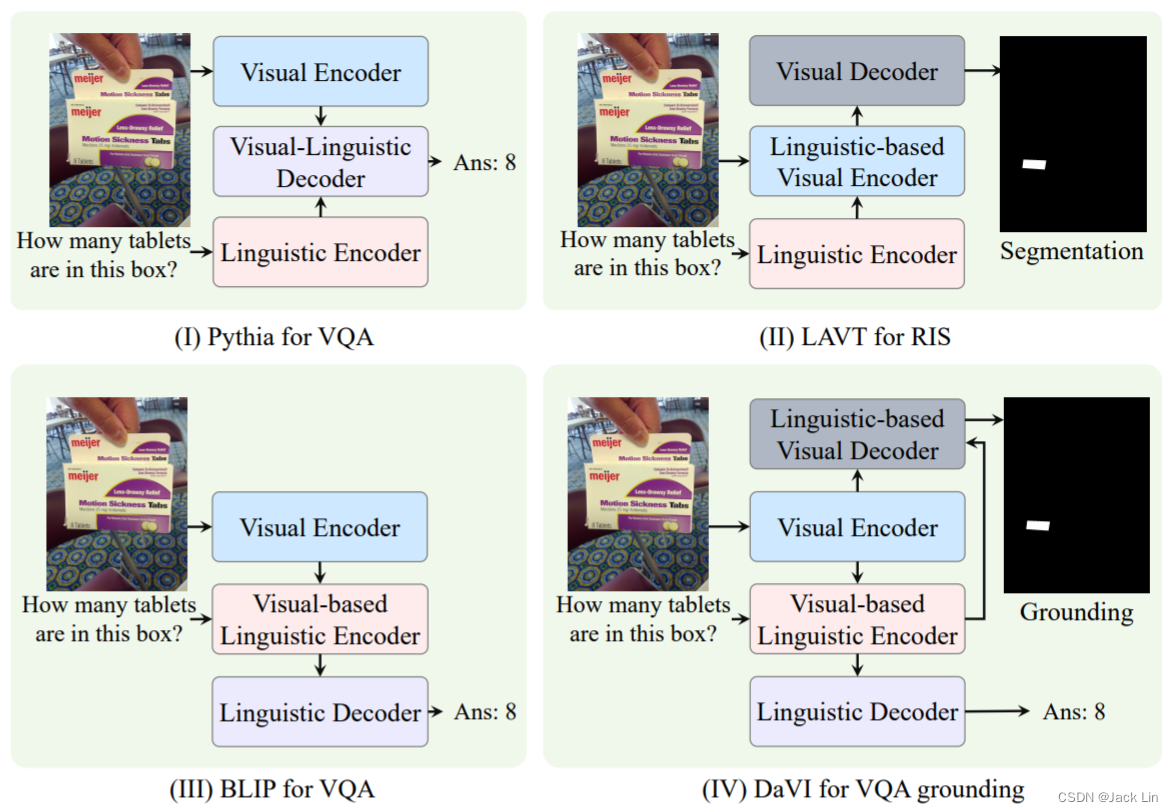
3. DaVI Framework
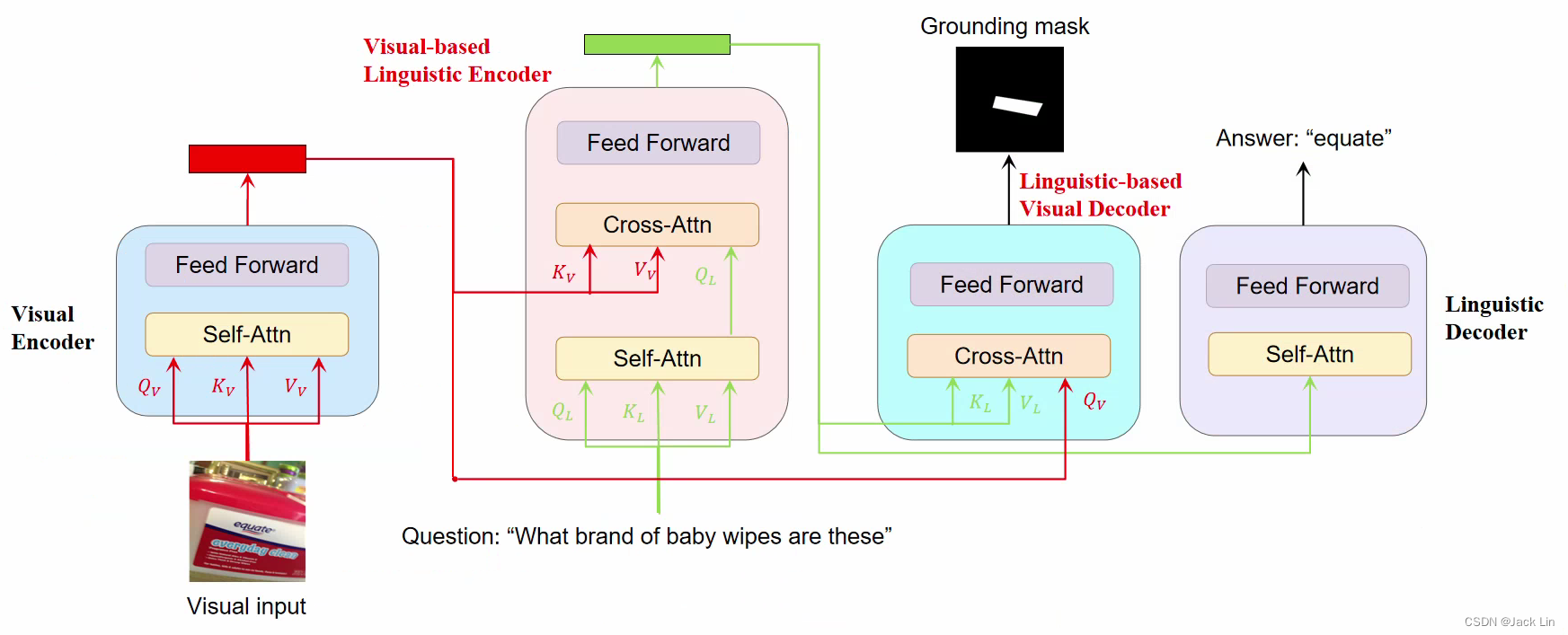
VLE: (Visual-based Linguistic Encoder) understands questions incorporated with visual features and produces linguistic-oriented evidence for answer decoding.
LVD: (Linguistic-based Visual Decoder) focuses visual features on the evidence-related regions for answer grounding.
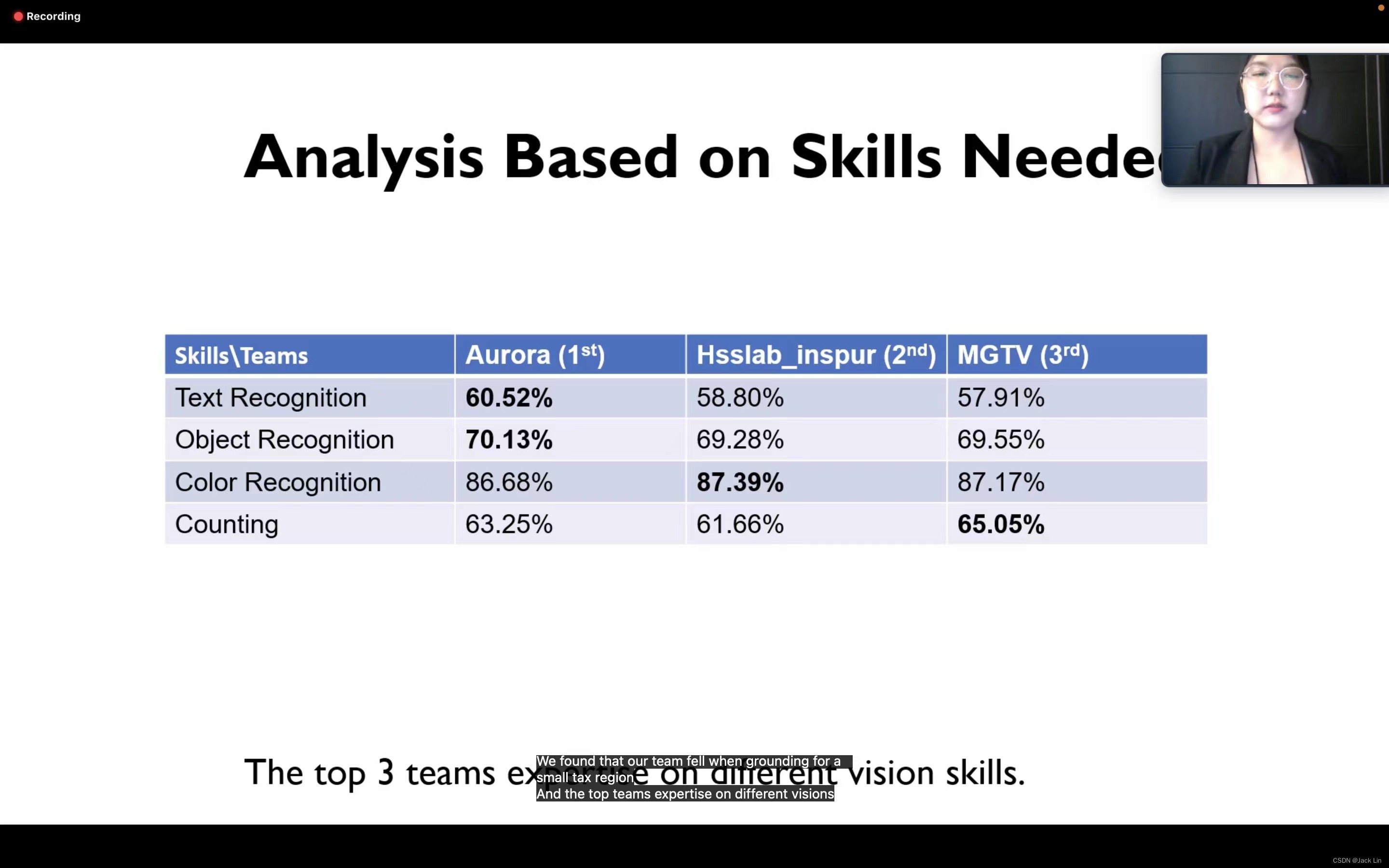
4. Results