
Enlace del artículo: https://arxiv.org/pdf/2111.09833.pdf
Enlace del código: https://github.com/Beckschen/TransMix
1. motivo
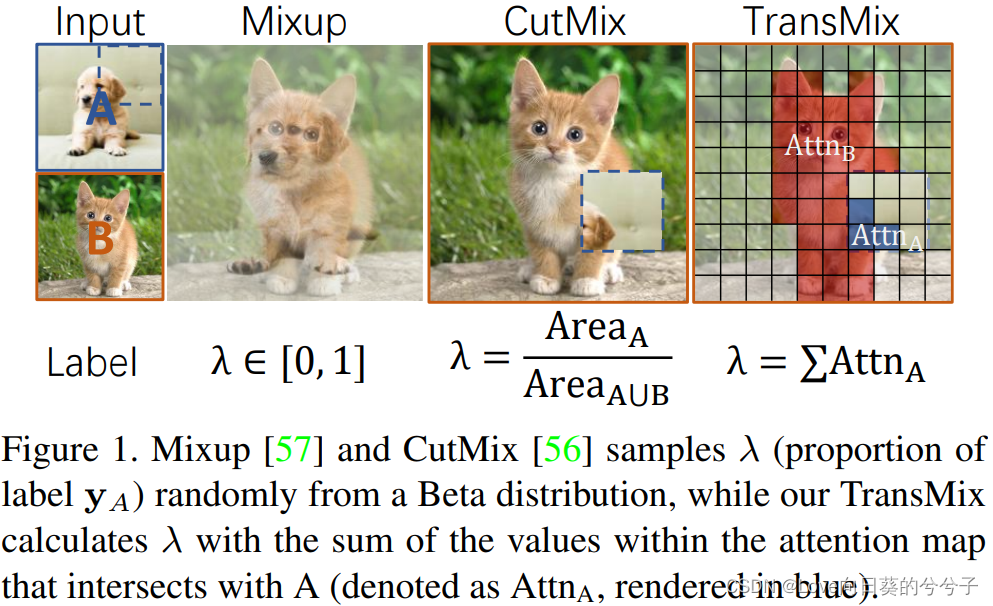
Muchos estudios recientes han descubierto que las redes basadas en ViT son difíciles de optimizar y pueden sobreajustarse fácilmente si no hay suficientes datos de entrenamiento . Una solución rápida a este problema es aplicar técnicas de regularización y aumento de datos durante el proceso de formación . Entre ellos, los métodos basados en Mix, como Mixup y CutMix, han demostrado ser particularmente útiles para la generalización de redes basadas en ViT. Sin embargo, los métodos anteriores basados en mezclas tienen un conocimiento previo subyacente, que supone que la relación de interpolación lineal del objetivo debe ser consistente con la relación propuesta en la interpolación de entrada . Esto puede provocar un fenómeno extraño en el que a veces no hay objetos válidos en la imagen Mixup debido al proceso estocástico aumentado, pero todavía hay respuestas en el espacio de etiquetas . El autor cree que la suposición anterior no es del todo correcta porque no todos los píxeles son iguales. Como se muestra en la Figura 1 anterior, los píxeles del fondo no contribuyen tanto al espacio de la etiqueta como los píxeles del área saliente . Aunque también hay trabajos que han descubierto este problema, esos métodos solo mezclan las partes más descriptivas en el nivel de entrada para resolverlo. Esta operación en la entrada puede reducir el espacio para mejorar (porque tienden a considerar menos imágenes de fondo en Mezclar imagen ), al tiempo que requiere más parámetros o rendimiento de entrenamiento para extraer regiones destacadas de entrada .
2. Contribución
Este artículo no estudia cómo mezclar mejor las imágenes en el nivel de entrada, sino que se centra más en cómo aliviar la brecha entre el espacio de entrada y el de etiquetas mediante el aprendizaje de las asignaciones de etiquetas. Las contribuciones específicas son las siguientes:
- Para cerrar la brecha entre el espacio de entrada y el espacio de etiquetas, este artículo propone TransMix , que mezcla etiquetas según el mapa de atención de Vision Transformer. Cuanto mayor sea el peso del mapa de atención en la imagen de entrada correspondiente, mayor será la confianza de la etiqueta. TransMix es muy simple y se puede implementar con solo unas pocas líneas de código sin introducir parámetros adicionales ni fracasos en el modelo basado en ViT.
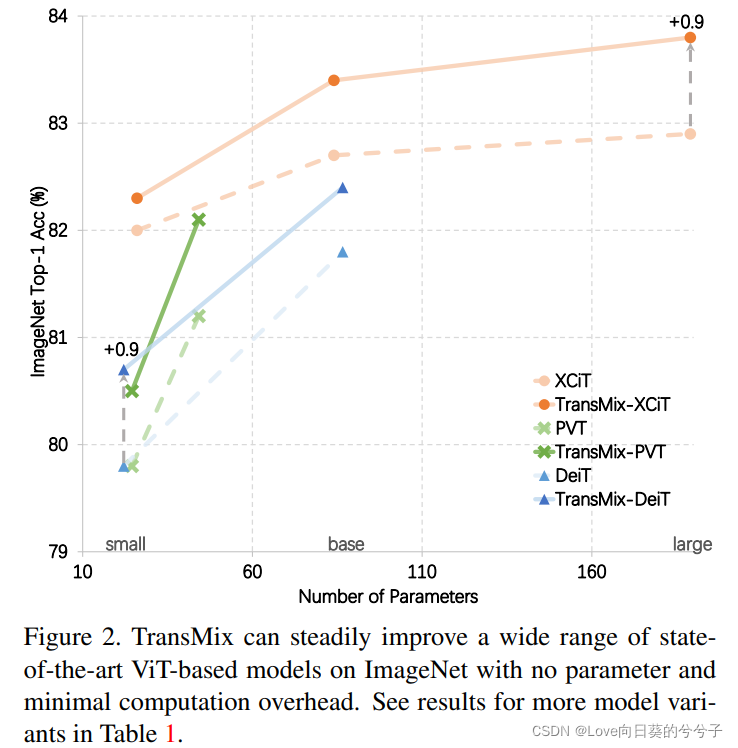
- Los resultados experimentales muestran que este método puede mejorar continuamente varios modelos basados en ViT en diferentes escalas en la clasificación ImageNet. Después de usar TransMix para el preprocesamiento en ImageNet, el modelo basado en ViT-C también mostró una buena portabilidad en segmentación semántica, detección de objetivos y segmentación de instancias. TransMix también tuvo un desempeño más sólido cuando se evaluó en 4 puntos de referencia diferentes.
3. Método
3.1 Revisión: Mejora de datos de CutMix
CutMix es una técnica simple de aumento de datos que combina 2 pares de etiquetas de entrada ( x A , y A ) (x_A, y_A)( xun,yun) suma( x B , y B ) (x_B, y_B)( xB,yB) para mejorar una nueva muestra de entrenamiento( x ~ , y ~ ) (\tilde{x}, \tilde{y})(X~ ,y~) . La fórmula es la siguiente:

dondeM ∈ { 0 , 1 } HWM \in \{0, 1\}^{HW}METRO∈{
0 ,1 }H W es una máscara binaria, que indica las posiciones a eliminar y llenar de las dos imágenes,1es una máscara binaria,⊙ \odot⊙ es una multiplicación de elementos,λ \lambdaλ是 y A y_A yunProporción en etiquetas mixtas.
Durante el proceso de mejora, en x B x_BXBEliminar una región muestreada aleatoriamente de x A x_AXunObjetivo AARelleno de parche recortado en A , donde las coordenadas de límite del parche se muestrean uniformemente como (rx, ry, rw, rh) (r_x, r_y, r_w, r_h)( rx,ry,rw,rh) , factor de asignación de objetivos mixtoλ \lambdaλ es igual a la relación del área de cultivorwrh WH \frac{r_wr_h}{WH}WH _rwrh。
3.2 Revisión: mecanismo de autoatención
La autoatención opera en una matriz de entrada x ∈ RN × dx \in \mathbb{R}^{N \times d}X∈Rnorte × d , dondenorte norteN es el número de tokens,ddd es la dimensión de cada token. Introduzcaxxx se asigna linealmente a consulta, clave y valor utilizando la matriz de pesowq ∈ R d × dq w_q \in \mathbb{R}^{d \times d_q}wq∈Rd × dq, semana ∈ R d × dk w_k \in \mathbb{R}^{d \times d_k}wk∈Rd × dk和wv ∈ R d × dv w_v \in \mathbb{R}^{d \times d_v}wv∈Rd × dv,即q = xwqq=x_wqq=Xwq ,k = xwkk=x_wkk=Xwk sumav = xwvv=x_wvv=Xwv , en el quedq = dk d_q = d_kdq=dk. Calcule el mapa de atención A ( q , k ) = S oftmax ( qk > k ) ∈ RN × N \mathcal{A}(q, k) = Softmax(q_k>\sqrt{k}) \in R mediante consulta y clave ^{N×N}A ( q ,k )=S o f t m a x ( qk>k)∈RN × N , la salida de la operación de autoatención se define comovvv enNNLa suma ponderada de N características del token, cuyo peso corresponde al mapa de atención:
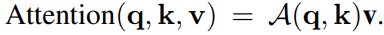
mediante el uso de diferentes proyecciones lineales aprendidasggg veces proyectadas adk d_kdk、dk d_kdky dv d_vdvDimensionalmente, la autoatención de una sola cabeza se puede extender a la autoatención de múltiples cabezas.
3.3 TransMix
El autor propuso que TransMix asigne etiquetas de confusión bajo la guía del mapa de atención, que se define específicamente como atención de clase A de múltiples cabezas, que se calcula como parte de la autoatención. En la tarea de clasificación, el token de clase es una consulta qqq , su clave correspondientekkk son todos los tokens de entrada, la atención de clase A es el mapeo de atención de los tokens de clase a los tokens de entrada, resume qué tokens de entrada son más útiles para el clasificador final y luego propone usar la atención de clase A para mezclar etiquetas.
-
Transformador de visión de atención de clases de cabezales múltiples
(ViTs)将图像x ∈ R 3 × H × W x \in \mathbb{R}^{3 \times H \times W}X∈R3 × H × W se divide e incrusta en $p $ tokens de parchexpatches ∈ R p × d x_{patches} \in \mathbb{R}^{p \times d}Xparches _ _ _ _ _ _∈REn p × d , a través del token de clasexcls ∈ R 1 × d x_{cls} \in \mathbb{R}^{1 \times d}Xc l s∈R1 × d agrega información global, dondeddd es la dimensión de incrustación. ViT actúa sobre la incrustación de parchesz = [ xcls , xpatches ] ∈ R ( 1 + p ) × dz = [x_{cls}, x_{patches}] \in \mathbb{R}^{(1+p) \times d }z=[ xc l s,Xparches _ _ _ _ _ _]∈R( 1 + pag ) × re .
Dada una función conggg cabezas de atención y parche de entrada incrustandozzTransformador de z , usando la matriz de mapeowq w_qwq, wk ∈ R d × d w_k \in \mathbb{R}^{d \times d}wk∈Rd × d parametriza el cabezal de atención múltiple, y la atención de clase de cada cabezal se puede expresar como:
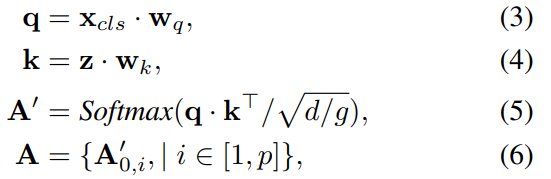
dondeq ⋅ k T ∈ R 1 × ( 1 + p ) q \cdot k^T \in \mathbb{R}^ {1 \veces (1+p)}q⋅kt∈R1 × ( 1 + p ) significa que el token de clase es una consulta y su valor clave correspondiente son todos los tokens de entrada,A ∈ [0, 1] p A \in [0, 1]^pA∈[ 0 ,1 ]p es el mapeo de atención de los tokens de clase a los tokens de parches de imágenes, que resume qué parches son más útiles para el clasificador final. Cuando hay varias cabezas en la atención, solo necesitamos promediar todas las cabezas de atención para obtenerA ∈ [0, 1] p A \in [0,1]^pA∈[ 0 ,1 ]pág . En la implementación, A en la ecuación (6) se puede utilizar como salida intermedia del último bloque transformador sin requerir modificaciones arquitectónicas. -
Mezclando etiquetas con el mapa de atención A
Los autores siguen el proceso de mezcla de entradas propuesto en CutMix, que se define en la Ecn (1). Entonces preste atención a la Figura AA.Vuelva a calcularλ \lambda bajo la guía de Aλ ( y A y_A yunProporción en la ecuación (2)):

donde ↓ ( ⋅ ) \downarrow(\cdot)↓( ⋅ ) indica que el MMoriginalM deHW HWConvertir HW appInterpolación del vecino más cercano y reducción de resolución de p píxeles. Tenga en cuenta que la descompresión dimensional en la ecuación (7) se ignora por simplicidad. De esta manera, la red puede aprender a reasignar dinámicamente el peso de las etiquetas en función de la respuesta de cada punto de datos en el mapa de atención. A los insumos que estén mejor enfocados por el mapa de atención se les asignará un valor más alto en la etiqueta híbrida.
3.4 Implementación de pseudocódigo

4. Algunos resultados experimentales
4.1 Comparación de resultados de tres tareas.
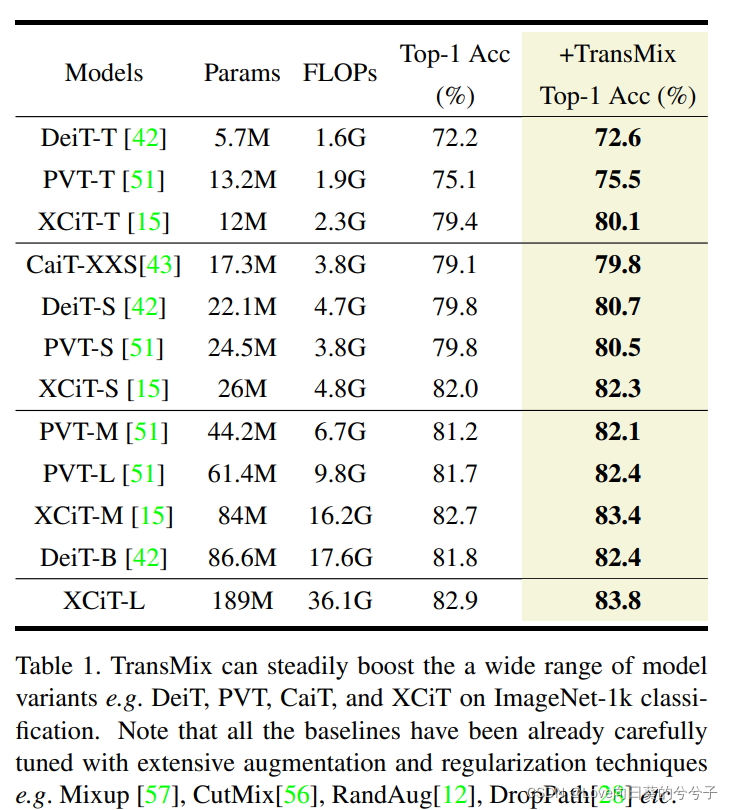
- Clasificación de ImageNet
- Migrar a tareas de segmentación semántica

- Migrar a tareas de detección de objetos y segmentación de instancias

4.2 Análisis sólido
-
oclusión
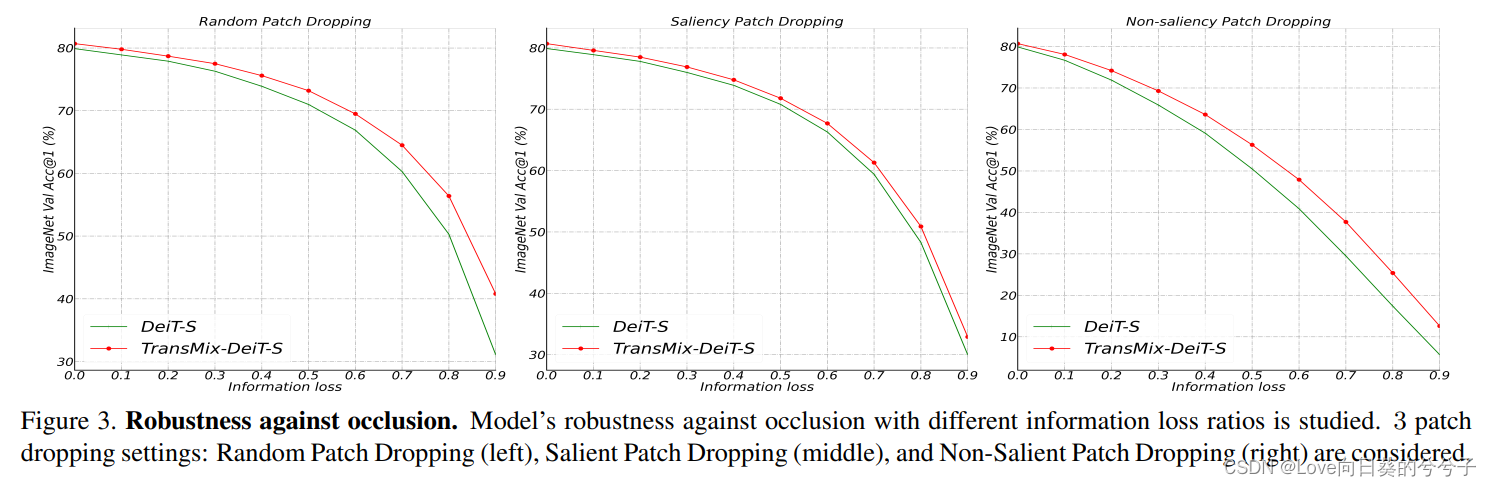
-
Sensibilidad a las transformaciones en la estructura espacial.
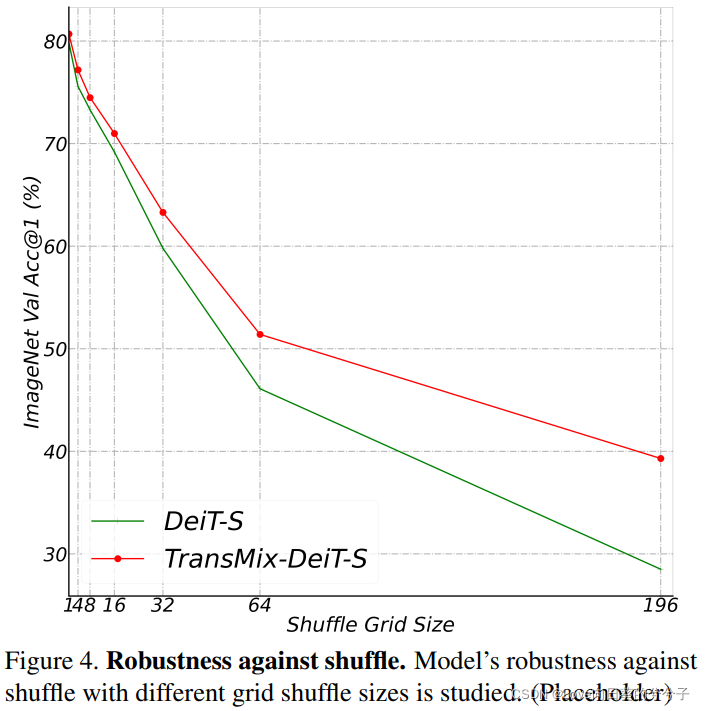
-
Confrontación natural y detección fuera de distribución.
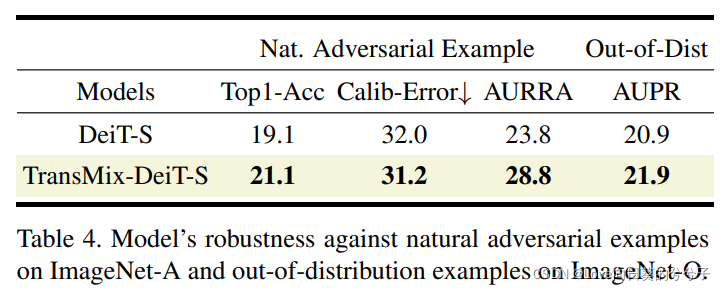
4.3 Investigación de generalización
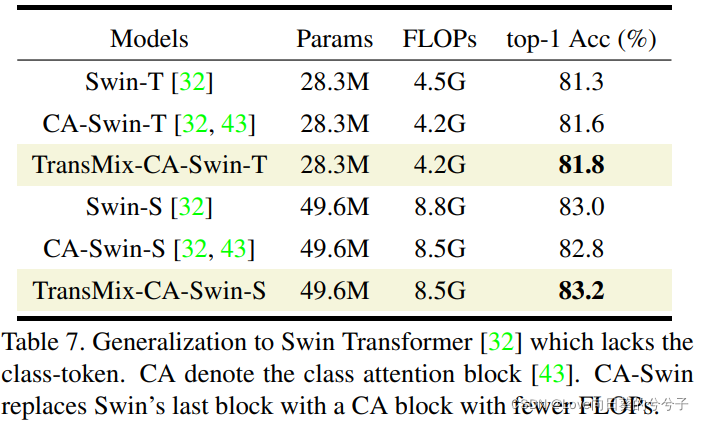
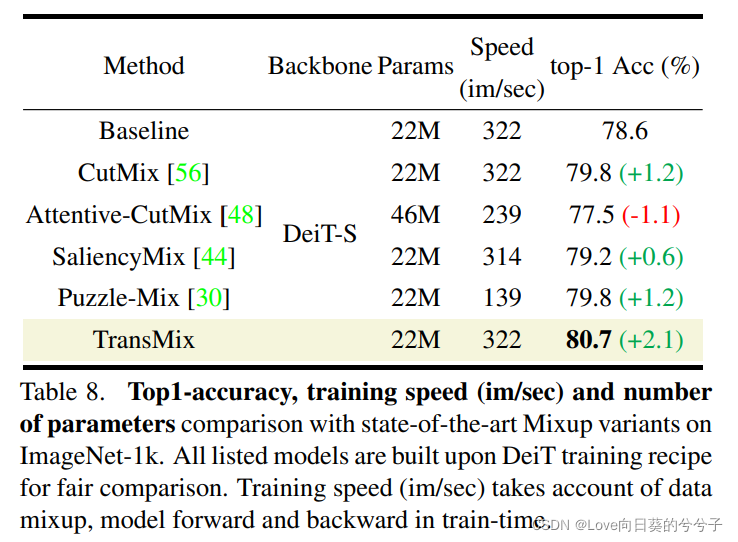
4.4 Comparación con las variantes Mixup más modernas
TransMix es significativamente mejor que todas las demás variantes de Mixup. En comparación con CutMix tradicional, los métodos basados en prominencia como SaliencyMix y Puzzle-Mix no muestran las ventajas de Visual Transformer. Analizamos que estos métodos son engorrosos de ajustar y difíciles de aplicar en nuevas arquitecturas. Por ejemplo, Attentive-CutMix no solo genera tiempo adicional sino también una sobrecarga de parámetros porque introduce un modelo externo para extraer mapas de prominencia. Puzzle-Mix funciona más lento porque avanza y retrocede dos veces en una iteración de entrenamiento. En comparación, TransMix logra una mejora significativa del rendimiento del 2,1 %, tiene el mayor rendimiento de entrenamiento y no tiene sobrecarga de parámetros.
4.5 Visualización TransMix
La primera línea ilustra que la antigua asignación de etiquetas basada en regiones es contraintuitiva porque el primer plano de la imagen A está ocluido por el parche de la imagen B. TransMix corrige la asignación de etiquetas a través de la atención del Transformer. TransMix puede aumentar el peso de las etiquetas si aparecen atributos discriminativos de grano fino (por ejemplo, las mejillas y los ojos de Pomerania aparecen en la segunda fila).

4.6 Experimento de ablación

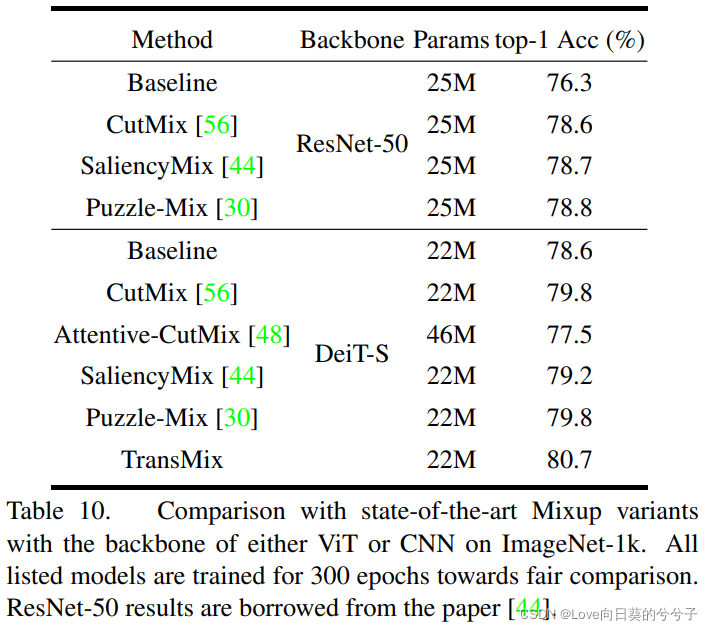
5. Conclusión
En este artículo, los autores proponen TransMix, una técnica de aumento de datos simple pero efectiva que asigna etiquetas Mixup con guía de atención a los transformadores Vision. TransMix naturalmente aprovecha el mapa de atención del Transformer para asignar credibilidad a objetos mixtos y mejora la precisión de DeiT-S y la variante grande XCiT-L en un 0,9 % en ImageNet. Se llevan a cabo extensos experimentos en un total de 10 puntos de referencia para verificar la efectividad, portabilidad, robustez y versatilidad de TransMix.
Dado que este es el primer trabajo que avanza en métodos basados en mezclas hacia transformadores visuales mejorados, existen las siguientes limitaciones:
- TransMix no maneja bien esas redes troncales sin tokens de clase porque depende en gran medida de la atención de la clase. Esta limitación puede mitigarse a costa de modificaciones arquitectónicas.
- TransMix requiere que el mapa de atención esté alineado espacialmente con la entrada, lo que sugiere que puede no ser compatible con Transformers basados en deformaciones (como PSViT, DeformDETR). En el futuro, este problema se puede resolver utilizando una cuadrícula desplazada deformada para posicionar el mapa de atención en el espacio de entrada.
- Dado que la diferencia entre el parche recortado con límites rectangulares definidos y el fondo es muy obvia, el Transformer naturalmente puede sentir curiosidad por el parche recortado y luego prestarle atención, por lo que, ya sea que el parche contenga información útil o no, obtendrá una Peso de atención básica. Este fenómeno también aparecerá en métodos anteriores basados en prominencia, porque los bordes del parche recortados mejorarán las estadísticas de características de primer y segundo orden.