Directorio de artículos
Prefacio
¡Repasemos los puntos de conocimiento del nivel anterior como de costumbre! En el nivel anterior, aprendimos cómo enviar los resultados del rastreador a correos electrónicos y ejecutar rastreadores con regularidad.
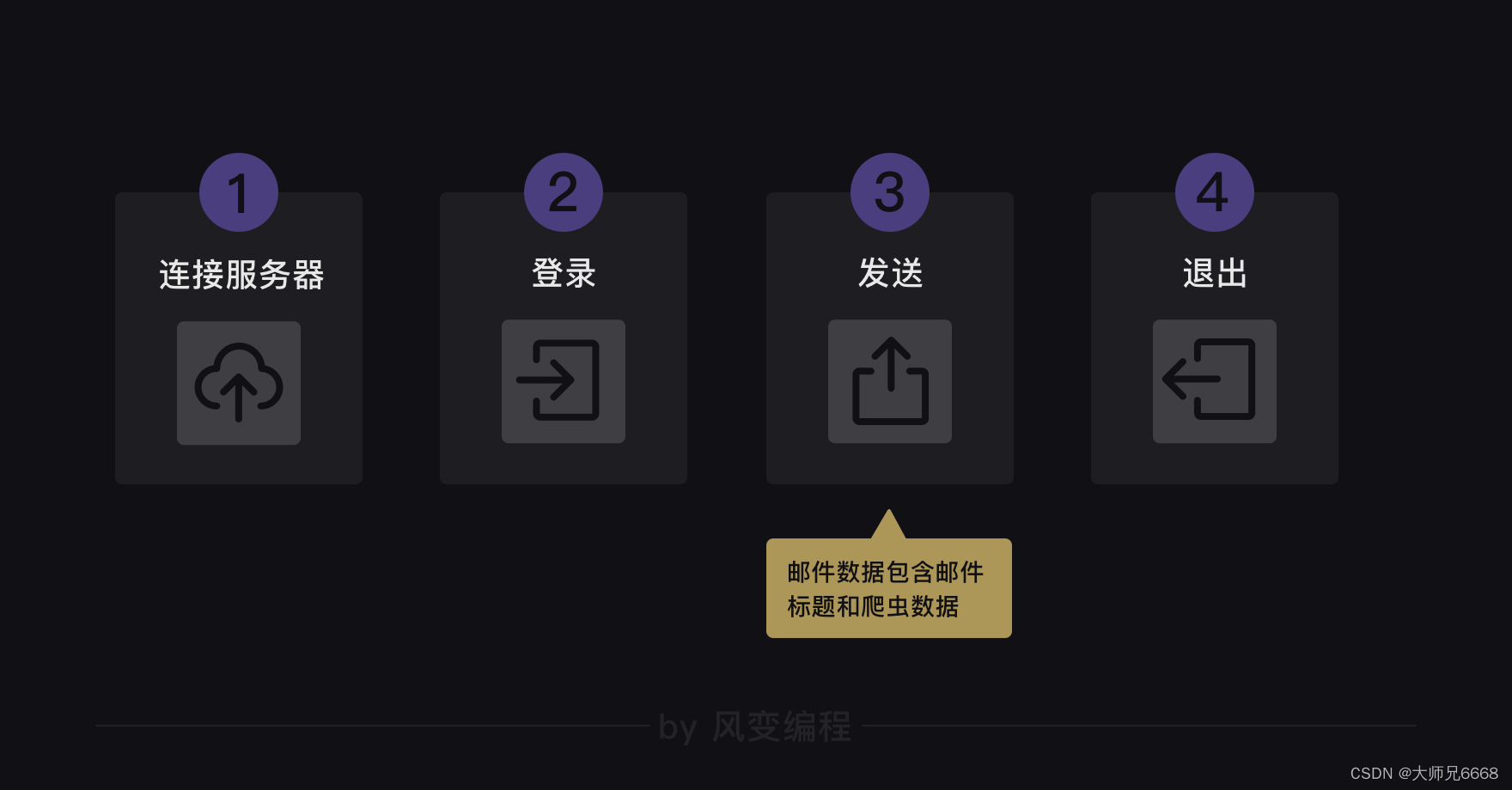
Respecto al correo electrónico, es un proceso como este:

Los módulos que queremos utilizar son smtplib y email, el primero se encarga del proceso de conexión al servidor, inicio de sesión, envío y salida. Este último se encarga de rellenar el título y el cuerpo del correo electrónico.
El último código de muestra se ve así:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#引入smtplib、MIMEText和Header
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址应为字符串格式
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以调用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器。
account = input('请输入你的邮箱:')
#获取邮箱账号,为字符串格式
password = input('请输入你的密码:')
#获取邮箱密码,为字符串格式
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
#以上,皆为登录邮箱。
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱。
content=input('请输入邮件正文:')
#输入你的邮件正文,为字符串格式
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码
subject = input('请输入你的邮件主题:')
#输入你的邮件主题,为字符串格式
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
#以上,为填写主题和正文。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
#以上为发送邮件和退出邮箱。
Para el tiempo, elegimos el módulo de programación, su uso es muy simple, como se describe en la documentación oficial:
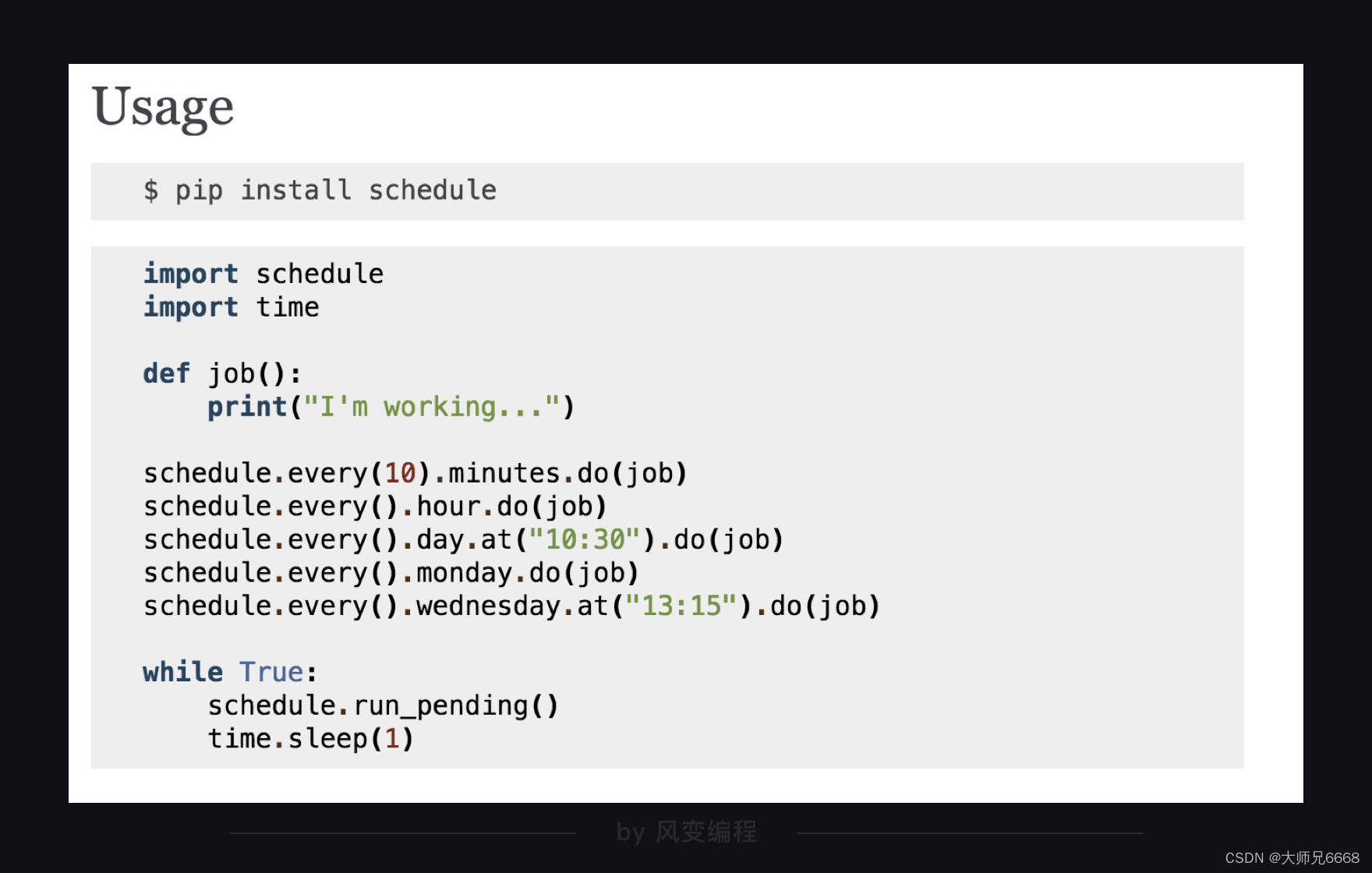
El siguiente código es un ejemplo:
import schedule
import time
#引入schedule和time
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(10).minutes.do(job) #部署每10分钟执行一次job()函数的任务
schedule.every().hour.do(job) #部署每×小时执行一次job()函数的任务
schedule.every().day.at("10:30").do(job) #部署在每天的10:30执行job()函数的任务
schedule.every().monday.do(job) #部署每个星期一执行job()函数的任务
schedule.every().wednesday.at("13:15").do(job)#部署每周三的13:15执行函数的任务
while True:
schedule.run_pending()
time.sleep(1)
#15-17都是检查部署的情况,如果任务准备就绪,就开始执行任务。
¿Qué es la corrutina?
Hemos realizado muchos proyectos de rastreo, pero los datos que rastreamos no son demasiado grandes. Si queremos rastrear miles de datos, entonces encontraremos un problema: porque el programa es línea por línea. Debido a la ejecución secuencial, Tenemos que esperar mucho tiempo antes de poder obtener los datos que queremos.
Dado que a un rastreador le lleva mucho tiempo rastrear una gran cantidad de datos, ¿podemos permitir que varios rastreadores rastreen juntos?
Sin duda, esto mejorará la eficiencia del rastreo. Al igual que un trabajo que una sola persona no puede completar, forme un equipo para hacerlo juntos y el trabajo se completará de una vez.
Es una buena idea: dejar que varios rastreadores hagan el trabajo por nosotros. ¿Pero cómo implementar esto específicamente en Python?
Podemos dejar de pensar en cómo implementar esto ahora, os lo contaré más adelante.
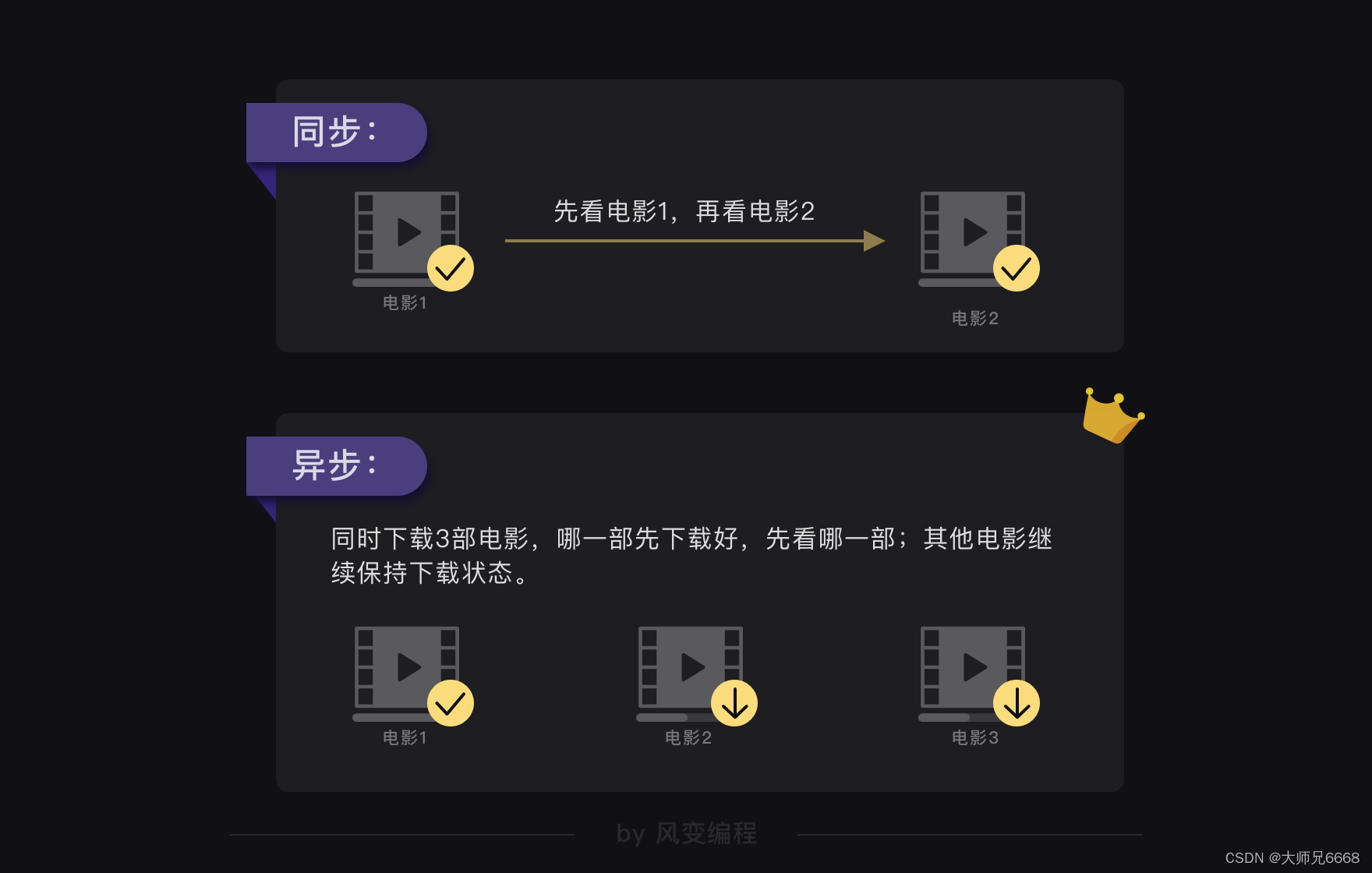
Ahora, imagina un escenario conmigo:

Creo que definitivamente harás esto: haz clic para descargar las tres películas. Cualquiera que se descargue primero, mírela primero y mantenga el estado de descarga de las películas que aún no se han descargado.
Si usa conceptos informáticos para explicar esto: cuando una tarea no se completa, puede realizar varias otras tareas sin afectarse entre sí (cuando mira la primera película descargada, otras películas continúan descargándose, no se ven afectadas entre sí), se llama asíncrono.
Existe el concepto de asíncrono, entonces también debería existir el concepto de sincronización, ¿verdad? Sí, la sincronización significa que se debe completar una tarea antes de poder iniciar la siguiente (similar a cómo puedes ver la siguiente película después de ver una).
Obviamente, ejecutar tareas de forma asincrónica ahorrará más tiempo que de forma sincrónica porque puede reducir esperas innecesarias. Si necesita optimizar el tiempo, la asincrónica es una solución que vale la pena considerar.

Si transferimos los conceptos de sincronización y asincronía al escenario del rastreador web, entonces los métodos del rastreador que aprendimos antes son todos sincrónicos.
Cada vez que el rastreador inicia una solicitud, espera a que el servidor devuelva una respuesta antes de ejecutar el siguiente paso. En muchos casos, debido a la inestabilidad de la red y al propio tiempo de respuesta del servidor, los rastreadores pierden mucho tiempo esperando. Esta es también la razón por la cual la velocidad del rastreador será más lenta cuando rastrea una gran cantidad de datos.

Entonces, ¿podemos adoptar un método de rastreo asincrónico para que varios rastreadores puedan permanecer relativamente independientes al ejecutar tareas sin interferir entre sí, de modo que podamos evitar el tiempo de espera? Obviamente, se mejorará la eficiencia y velocidad del rastreador.
¿Cómo podemos implementar un método de rastreo asincrónico y mejorar la eficiencia de los rastreadores? Para responder a esta pregunta, es necesario conocer un poco sobre la historia de las computadoras.
Sabemos que cada computadora depende de una CPU (Unidad Central de Procesamiento) para funcionar. En el pasado, cuando una computadora con CPU de un solo núcleo procesaba múltiples tareas, ocurría un problema: cada tarea tenía que apoderarse de la CPU y la siguiente tarea no se iniciaba hasta que se completaba una. Después de todo, solo hay una CPU, lo que hace que el procesamiento de la computadora sea muy ineficiente.
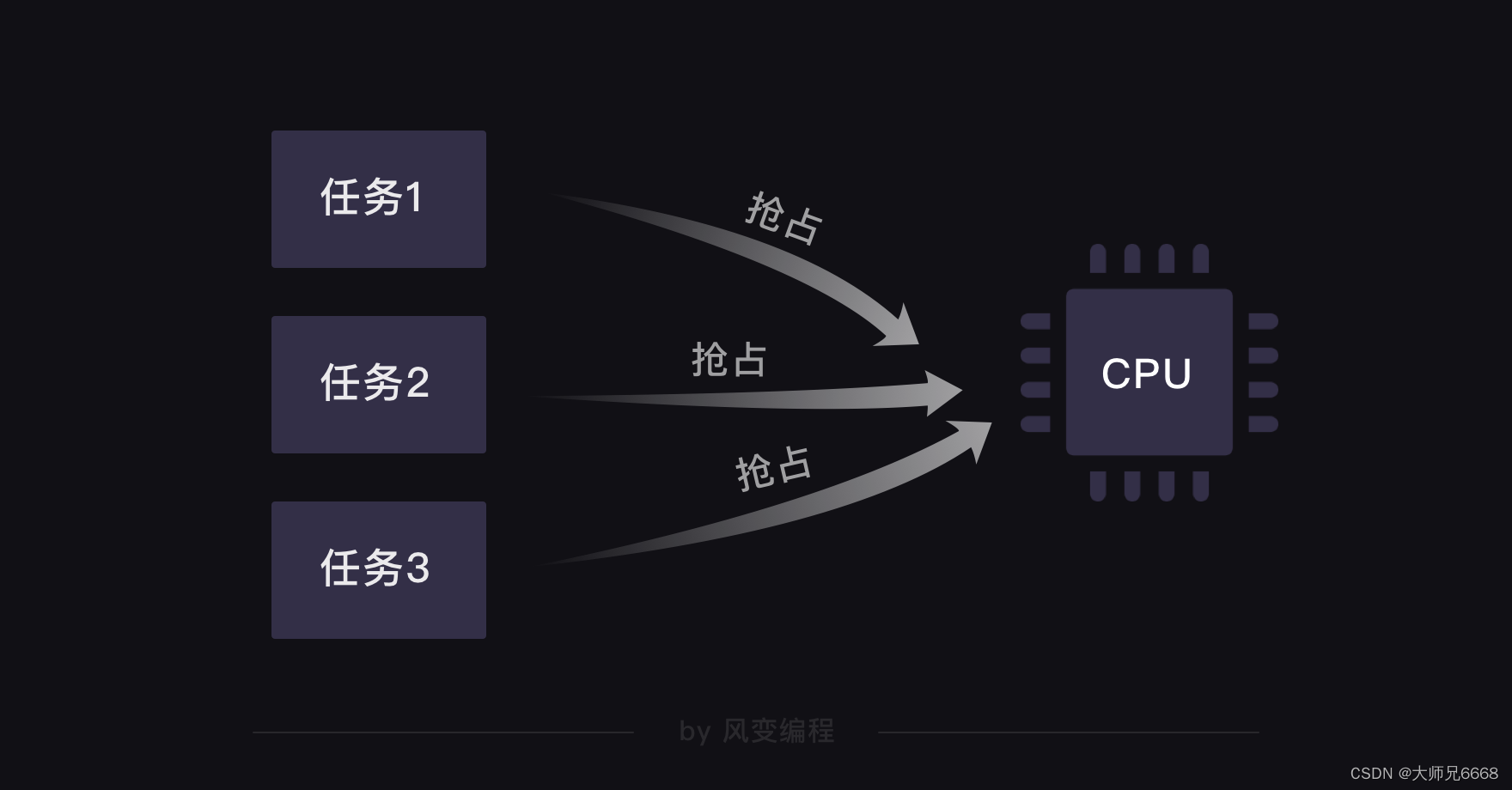
Para resolver este problema, se creó una tecnología asincrónica no preventiva, que se llama multi-corrutina (aquí, multi significa múltiple).
Su principio es: durante la ejecución de una tarea, si encuentra una espera, primero ejecutará otras tareas y, cuando termine la espera, volverá para continuar con la tarea anterior. En el mundo de la informática, este tipo de cambio de tareas de un lado a otro es muy rápido y parece que se están ejecutando varias tareas al mismo tiempo.
Esto es como cuando quieres preparar una mesa de comidas, puedes sofreír mientras esperas que la arrocera cocine el arroz al vapor. En lugar de esperar a que el arroz esté listo, sofríelo. Sigues siendo la misma persona, pero tu jornada laboral se ha reducido. Lo mismo ocurre con el principio de que las múltiples rutinas pueden acortar el tiempo de trabajo.
Por lo tanto, para implementar un método de rastreo asincrónico, es necesario utilizar varias rutinas. Con su ayuda, podemos lograr lo mencionado anteriormente "dejar que varios rastreadores hagan el trabajo por nosotros".
Entonces, aquí surge una nueva pregunta: ¿cómo usar múltiples rutinas?
Uso de multi-corrutina
biblioteca de eventos

Por lo tanto, a continuación lo llevaré a comprender el uso de gevent e implementar un caso de múltiples corrutinas: rastrear 8 sitios web (incluidos Baidu, Sina, Sohu, Tencent, NetEase, iQiyi, Tmall y Phoenix).
Primero rastreemos estos 8 sitios web utilizando el método de rastreo sincrónico anterior y luego compárelos con el rastreo asincrónico de gevent más adelante.
Lea atentamente el código de la izquierda antes de ejecutarlo.
import requests,time
#导入requests和time
start = time.time()
#记录程序开始时间
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
#把8个网站封装成列表
for url in url_list:
#遍历url_list
r = requests.get(url)
#用requests.get()函数爬取网站
print(url,r.status_code)
#打印网址和抓取请求的状态码
end = time.time()
#记录程序结束时间
print(end-start)
#end-start是结束时间减去开始时间,就是最终所花时间。
#最后,把时间打印出来。
resultado de la operación:
https://www.baidu.com/ 200
https://www.sina.com.cn/ 200
http://www.sohu.com/ 200
https://www.qq.com/ 200
https://www.163.com/ 200
http://www.iqiyi.com/ 200
https://www.tmall.com/ 200
http://www.ifeng.com/ 200
1.7253923416137695
Después de ejecutar el programa, verá el método de rastreo sincrónico, que rastrea sitios web en secuencia y espera a que el servidor responda (el código de estado 200 indica una respuesta normal) antes de rastrear al siguiente sitio web. Por ejemplo, el primero rastrea primero la URL de Baidu, espera a que el servidor responda y luego rastrea la URL de Sina, y así sucesivamente hasta que se completa todo el rastreo.
Para permitirle ver de manera más intuitiva el tiempo que le toma al rastreador completar la tarea, importé el módulo de tiempo para registrar la hora de inicio y finalización del programa. La impresión final es el tiempo que le tomó al rastreador rastrear estos 8 sitios web.
¿Qué sería diferente si usáramos múltiples rutinas para rastrear?
Puede ejecutar el siguiente código para verlo primero (ejecútelo directamente para experimentar).
from gevent import monkey
monkey.patch_all()
import gevent,time,requests
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
def crawler(url):
r = requests.get(url)
print(url,time.time()-start,r.status_code)
tasks_list = []
for url in url_list:
task = gevent.spawn(crawler,url)
tasks_list.append(task)
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
resultado de la operación:
https://www.baidu.com/ 0.13728904724121094 200
https://www.sina.com.cn/ 0.14090418815612793 200
https://www.163.com/ 0.1483287811279297 200
https://www.qq.com/ 0.1953425407409668 200
https://www.tmall.com/ 0.24243402481079102 200
http://www.ifeng.com/ 0.2494034767150879 200
http://www.sohu.com/ 0.3105161190032959 200
http://www.iqiyi.com/ 0.7928042411804199 200
0.7928953170776367
Una vez ejecutado el programa, se imprimen la URL, el tiempo de ejecución de cada solicitud, el código de estado y el tiempo final dedicado a rastrear 8 sitios web.
A través del tiempo de ejecución de cada solicitud, podemos saber que el rastreador rastreó 8 sitios web de forma asincrónica, porque el tiempo de finalización de cada solicitud no está en orden. Por ejemplo, cuando probé y ejecuté este código, el primer sitio web rastreado fue Sohu, seguido de Phoenix, no Baidu y Sina.
Y el intervalo entre el tiempo de finalización de cada solicitud es muy corto: puede pensar que estas solicitudes se inician casi "simultáneamente".
Al comparar el tiempo final dedicado al rastreo sincrónico y asincrónico, se puede ver que el método de rastreo asincrónico que utiliza múltiples corrutinas es de hecho más rápido que el método de rastreo sincrónico.
De hecho, la cantidad de datos rastreados en nuestro caso es todavía relativamente pequeña y no puede reflejar directamente la mayor diferencia de velocidad. Si está rastreando una gran cantidad de datos, el uso de múltiples corrutinas tendrá una ventaja de velocidad más significativa.
Por ejemplo, hice una prueba: al pasar de rastrear 8 sitios web a rastrear 80 sitios web, me tomó aproximadamente 17,3 segundos rastrear usando el método de rastreo sincrónico, pero solo tomó aproximadamente 4,5 segundos rastrear usando el rastreo asincrónico de múltiples corrutinas. La eficiencia aumentó en un 280%+.

Ahora, veamos el código que acabamos de usar gevent línea por línea.
Recordatorio: antes de importar la biblioteca gevent, primero debe instalarla. Si desea operarlo en su computadora local, debe instalarlo localmente. (Método de instalación: computadora con Windows: ingrese el comando en la terminal: pip install gevent, presione la tecla enter; computadora Mac: ingrese el comando en la terminal: pip3 install gevent, presione la tecla enter)
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests。
start = time.time()
#记录程序开始时间。
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
#把8个网站封装成列表。
def crawler(url):
#定义一个crawler()函数。
r = requests.get(url)
#用requests.get()函数爬取网站。
print(url,time.time()-start,r.status_code)
#打印网址、请求运行时间、状态码。
tasks_list = [ ]
#创建空的任务列表。
for url in url_list:
#遍历url_list。
task = gevent.spawn(crawler,url)
#用gevent.spawn()函数创建任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
#记录程序结束时间。
print(end-start)
#打印程序最终所需时间。
El código anterior involucra la sintaxis de gevent, algunas de las cuales quizás aún no entiendas, no entres en pánico, te las explicaré en detalle una por una.
Líneas 1 y 3 de código: el módulo mono se importa de la biblioteca gevent y este módulo puede convertir el programa en un programa asincrónico. Monkey.patch_all(), su función es en realidad como si en tu computadora a veces apareciera "¿Quieres usar un parche para corregir la vulnerabilidad o actualizar?" Puede parchear el programa para que pase a modo asíncrono en lugar de modo síncrono. También se le llama "parche de mono".
Antes de importar otras bibliotecas y módulos, debemos importar el módulo mono y ejecutar Monkey.patch_all(). De esta manera, el programa se puede parchear primero. También puedes entender que esta es una forma estandarizada de escribir.
Línea 5 de código: importamos la biblioteca gevent para ayudarnos a implementar múltiples rutinas, el módulo de tiempo para ayudarnos a registrar el tiempo requerido para el rastreo y el módulo de solicitudes para ayudarnos a rastrear 8 sitios web.

Líneas 21, 23 y 25 de código: hemos definido una función de rastreo. Mientras se llame a esta función, se ejecutará [rastreará el sitio web con request.get()] e [imprimir URL, tiempo de ejecución de la solicitud, código de estado ] tarea.
Línea 33 de código: debido a que gevent solo puede procesar los objetos de tarea de gevent y no puede llamar directamente a funciones ordinarias, debe usar gevent.spawn() para crear el objeto de tarea.
Una cosa a tener en cuenta aquí: los parámetros de gevent.spawn() deben ser el nombre de la función que se llamará y los parámetros de la función. Por ejemplo, gevent.spawn(crawler,url) crea una tarea que ejecuta la función del rastreador. Los parámetros son el nombre de la función del rastreador y su propia URL de parámetro.
Línea 35 de código: use la función de agregar para agregar la tarea a la lista de tareas de task_list.
Línea 37 de código: llamar al método joinall en la biblioteca gevent puede iniciar la ejecución de todas las tareas. gevent.joinall (tasks_list) es ejecutar todas las tareas en la lista de tareas task_list y comenzar a rastrear.

Resuma los puntos clave del uso de gevent para implementar el rastreo de múltiples rutinas:

En este punto, hemos completado el uso práctico de gevent para capturar 8 sitios web y también tenemos una comprensión general de la sintaxis básica de gevent.
Entonces, ¿qué podemos hacer si queremos rastrear no 8 sitios web, sino 1000 sitios web?
Usando la sintaxis de gevent que acabamos de aprender, podemos usar gevent.spawn() para crear 1000 tareas de rastreo y luego usar gevent.joinall() para ejecutar estas 1000 tareas.
Pero este método tiene problemas: ejecutar 1.000 tareas significa iniciar 1.000 solicitudes a la vez, solicitudes maliciosas que provocarán la caída del servidor del sitio web.

Dado que este método de crear directamente 1000 tareas no es recomendable, ¿podemos crear solo 5 tareas, pero cada tarea rastrea 200 sitios web?
Supongamos que tenemos 1000 tareas, luego creamos 5 tareas y el código para cada tarea para rastrear 200 sitios web se puede escribir de la siguiente manera (este código es solo para visualización y no se puede ejecutar):
from gevent import monkey
monkey.patch_all()
import gevent,time,requests
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/'
……
#假设有1000个网址
]
def crawler(url_list):
#定义一个crawler()函数。
for url in url_list:
r = requests.get(url)
print(url,time.time()-start,r.status_code)
tasks_list = [ ]
#创建空的任务列表。
for i in range(5):
task = gevent.spawn(crawler,url_list[i*200:(i+1)*200])
#用gevent.spawn()函数创建5个任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
Lamento decirles que todavía habrá problemas con esto. Incluso si usamos gevent.spawn() para crear 5 tareas para rastrear 200 sitios web respectivamente, estas 5 tareas se ejecutan de forma asincrónica, pero cada tarea (rastrear 200 sitios web) es internamente sincrónica.
Esto significa que si una tarea se está ejecutando y un sitio web que desea rastrear ha estado esperando una respuesta, incluso si otras tareas han completado el rastreo de 200 sitios web, todavía no puede completar el rastreo de 200 sitios web.
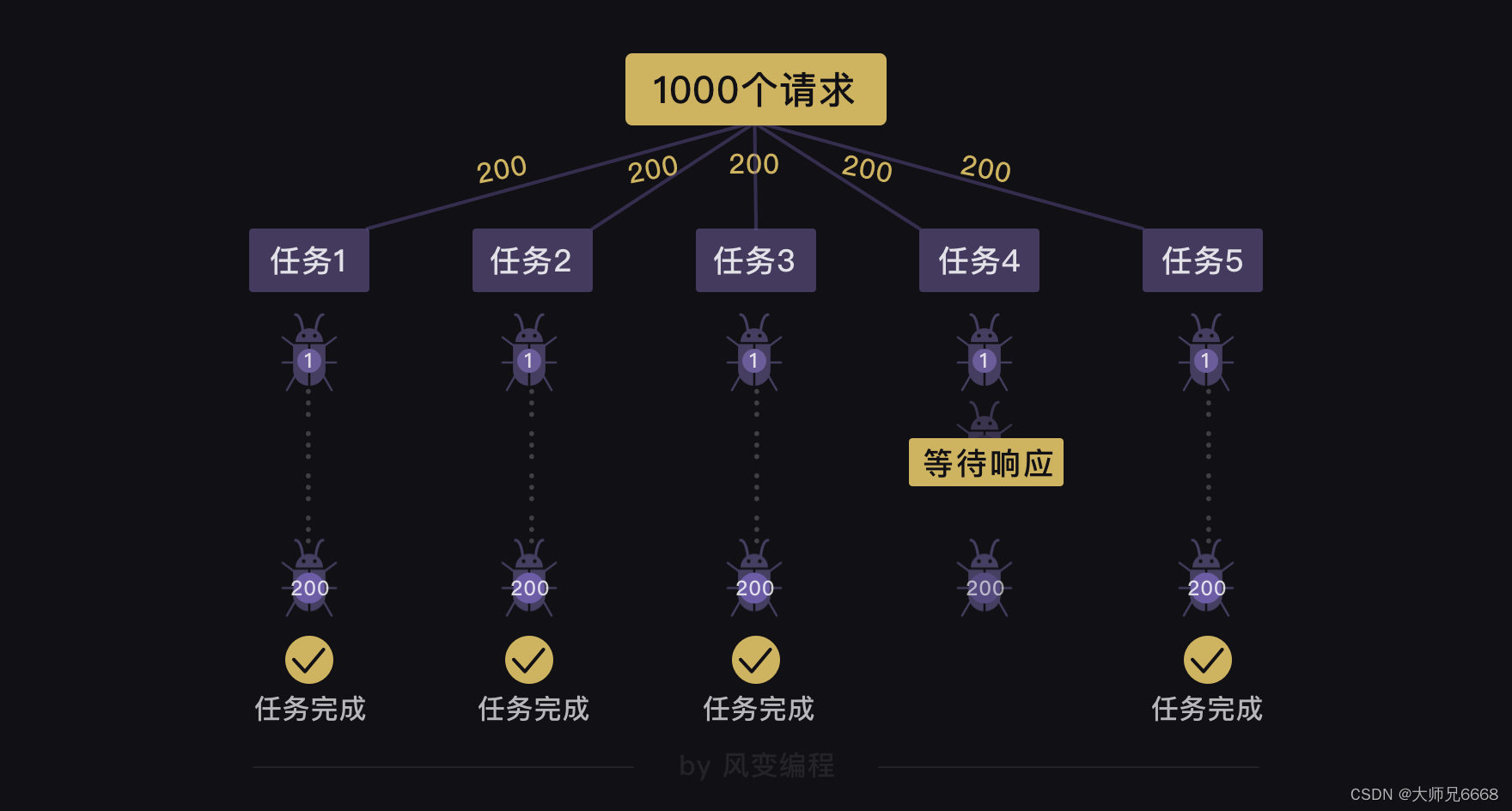
Este método no funciona, entonces, ¿qué otros métodos existen?
En este momento podemos inspirarnos en casos de la vida real. Piense en cómo un banco maneja 1000 clientes en un día.
El banco abrirá múltiples ventanas para manejar negocios, lo que permitirá a los clientes hacer cola para obtener un número, y el sistema de llamadas del banco asignará a los clientes a diferentes ventanas para manejar negocios.
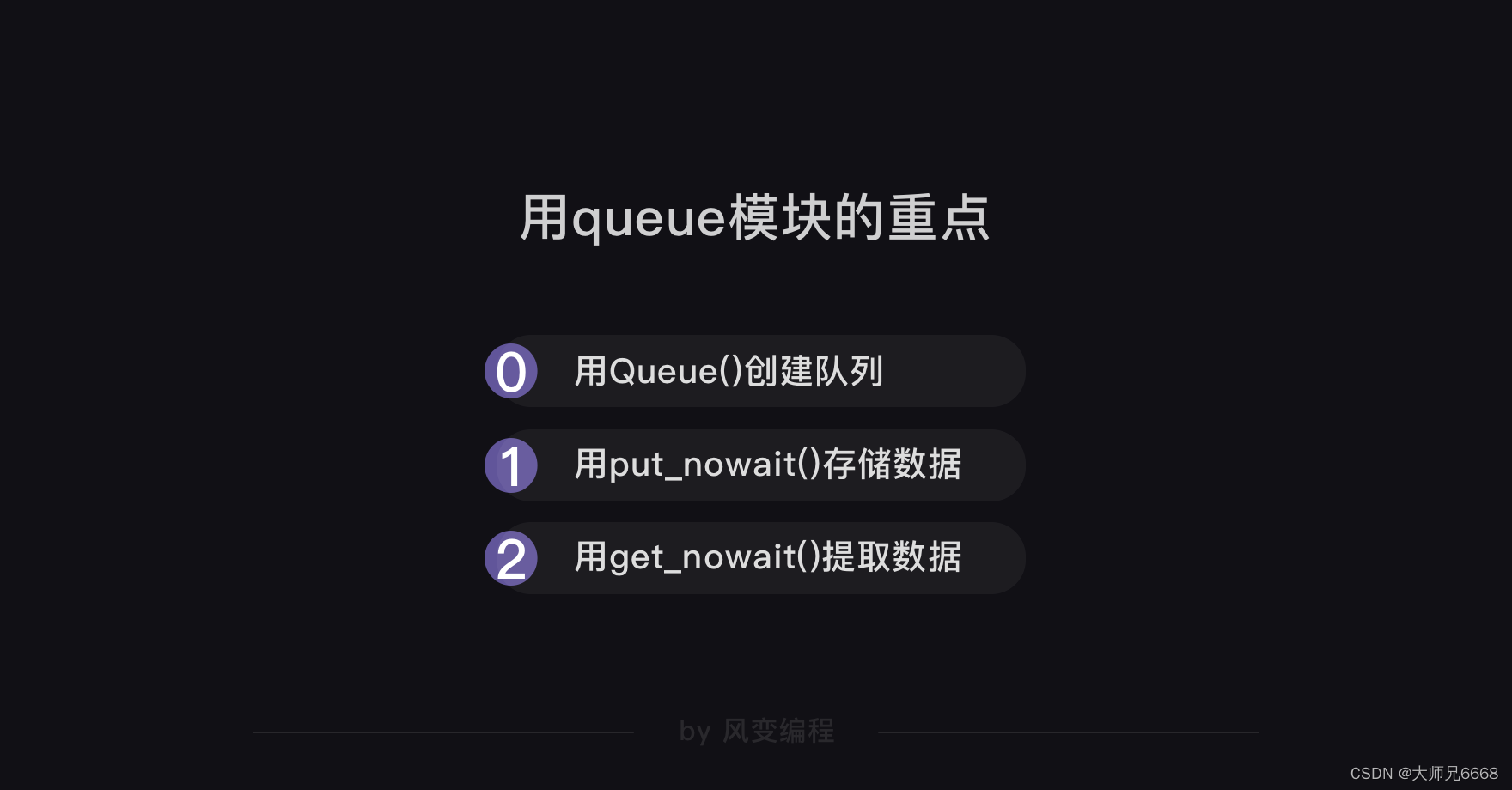
En la biblioteca gevent, también hay un módulo que puede implementar este módulo de cola de funciones.
módulo de cola
Cuando usamos múltiples rutinas para rastrear y necesitamos crear una gran cantidad de tareas, podemos usar el módulo de cola.
Cola se traduce al chino como cola. Podemos usar el módulo de cola para almacenar tareas y convertirlas en una cola ordenada, como el método de numeración en una ventana bancaria. Porque la cola es en realidad una estructura de datos ordenada que se puede utilizar para acceder a los datos.
De esta manera, la corrutina puede extraer la tarea de la cola y ejecutarla hasta que la cola esté vacía y la tarea se complete. Al igual que el personal de la ventanilla del banco maneja el negocio del cliente basándose en los números del sistema de numeración, si no hay un número nuevo, significa que el negocio del cliente ha sido procesado.
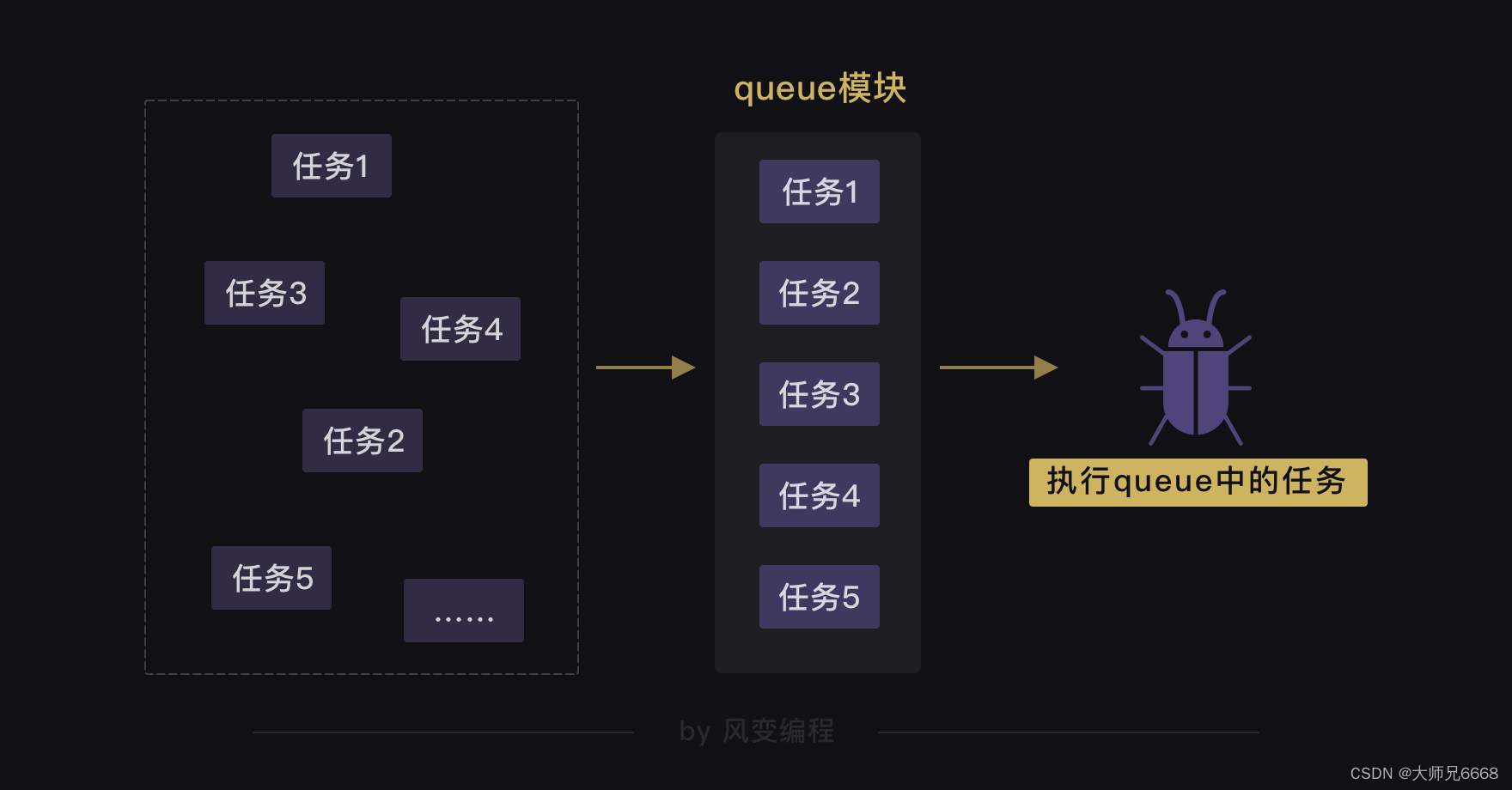
A continuación, echemos un vistazo práctico a cómo podemos usar el módulo de cola y la rutina para cooperar. Todavía tomamos el rastreo de 8 sitios web como ejemplo.
Ejecute primero el siguiente código.
from gevent import monkey
monkey.patch_all()
import gevent,time,requests
from gevent.queue import Queue
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
for url in url_list:
work.put_nowait(url)
def crawler():
while not work.empty():
url = work.get_nowait()
r = requests.get(url)
print(url,work.qsize(),r.status_code)
tasks_list = [ ]
for x in range(2):
task = gevent.spawn(crawler)
tasks_list.append(task)
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
resultado de la operación:
https://www.sina.com.cn/ 6 200
https://www.baidu.com/ 5 200
https://www.qq.com/ 4 200
http://www.sohu.com/ 3 200
https://www.163.com/ 2 200
https://www.tmall.com/ 1 200
http://www.ifeng.com/ 0 200
http://www.iqiyi.com/ 0 200
0.9640278816223145
El número después de la URL se refiere a la cantidad de tareas que quedan en la cola. Por ejemplo, el número 6 después de la primera URL significa que quedan 6 tareas en la cola para rastrear otras URL.
Ahora, dividamos el código que acabamos de ejecutar en 4 partes para explicarlo. La primera parte es importar el módulo.
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests
from gevent.queue import Queue
#从gevent库里导入queue模块
Debido a que la biblioteca gevent tiene cola, podemos importar el módulo de cola usando [de gevent.queue import Queue]. Ya hemos explicado otros módulos y códigos al explicar gevent, creo que puedes entenderlos.
La parte 2 es cómo crear una cola y almacenar tareas en la cola.
start = time.time()
#记录程序开始时间
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
#创建队列对象,并赋值给work。
for url in url_list:
#遍历url_list
work.put_nowait(url)
#用put_nowait()函数可以把网址都放进队列里。
Queue() se puede utilizar para crear un objeto de cola, lo que equivale a crear una cola vacía sin límite en la cantidad de almacenamiento. Si pasamos parámetros a Queue(), como Queue(10), significa que esta cola solo puede almacenar 10 tareas.
Después de crear el objeto de cola, podemos llamar al método put_nowait de este objeto para almacenar cada una de nuestras URL en la cola vacía que acabamos de crear.
Esta línea de código work.put_nowait(url) almacena los 8 sitios web recorridos en la cola.
La parte 3 es definir la función de rastreo y cómo extraer la URL que se acaba de almacenar en la cola.
def crawler():
while not work.empty():
#当队列不是空的时候,就执行下面的程序。
url = work.get_nowait()
#用get_nowait()函数可以把队列里的网址都取出。
r = requests.get(url)
#用requests.get()函数抓取网址。
print(url,work.qsize(),r.status_code)
#打印网址、队列长度、抓取请求的状态码。
La función de rastreo definida aquí tiene tres códigos más que quizás no comprenda:
1. while not work.empty():
2.url = work.get_nowait()
3.work.qsize().
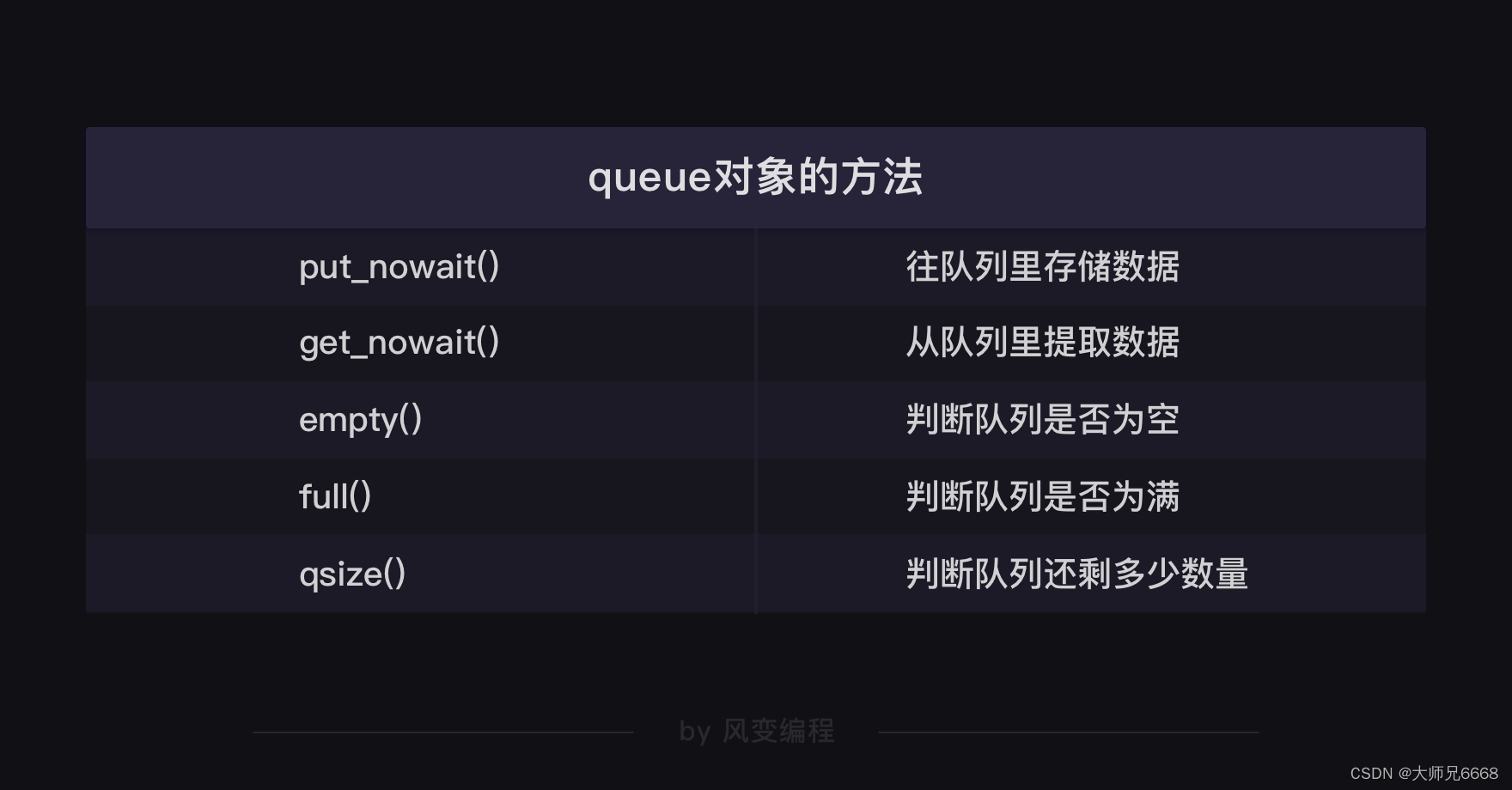
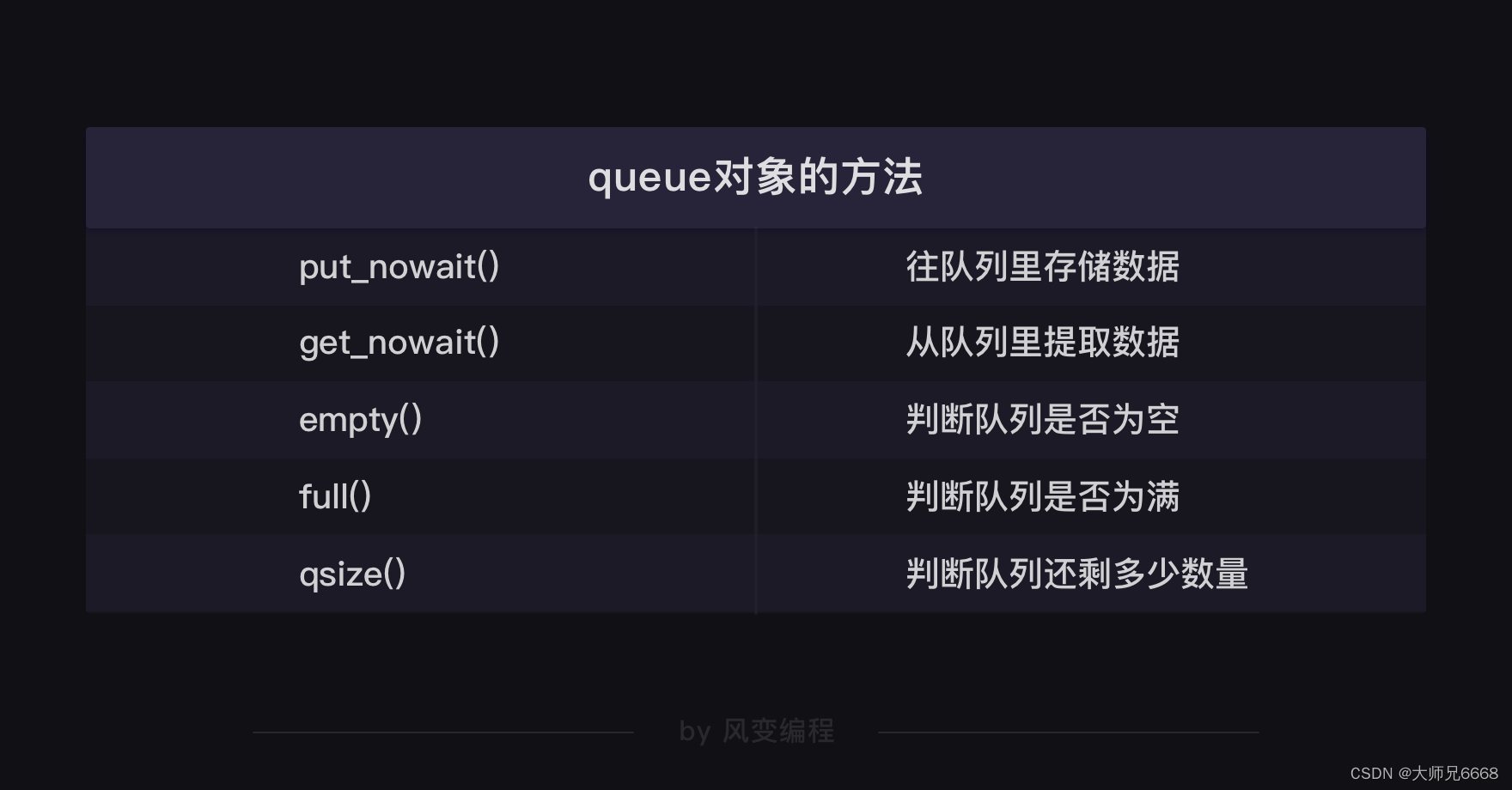
Estos tres códigos involucran tres métodos del objeto de cola:
método vacío, que es el método get_nowait usado para determinar si la cola está vacía,
método qsize, que se usa para extraer datos de la cola
y que se usa para determinar cuánto hay. dejados en la cola cantidad.
Por supuesto, el objeto de cola tiene más que solo estos métodos: por ejemplo, existe el método vacío para determinar si la cola está vacía y también existe el método completo correspondiente para determinar si la cola está llena.
¿Crees que el objeto de cola tiene tantos métodos que no puedes recordarlos todos a la vez? De hecho, no es necesario que los memorice de memoria. Se adjunta una tabla de métodos del objeto de cola. Solo necesita consultar la tabla cuando la use.
Hemos terminado de explicar las primeras 3 partes del código. Si puede comprender cómo crear una cola, cómo almacenar datos en la cola y cómo extraer datos de la cola, significa que domina los contenidos clave del módulo de cola.
Seguir el código de la Parte 3 es permitir que el rastreador utilice múltiples rutinas para realizar tareas y rastrear los códigos de los 8 sitios web en la cola (centrándose en el código comentado).
def crawler():
while not work.empty():
url = work.get_nowait()
r = requests.get(url)
print(url,work.qsize(),r.status_code)
tasks_list = [ ]
#创建空的任务列表
for x in range(2):
#相当于创建了2个爬虫
task = gevent.spawn(crawler)
#用gevent.spawn()函数创建执行crawler()函数的任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#用gevent.joinall方法,执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
print(end-start)
Este proceso se puede explicar con una imagen:
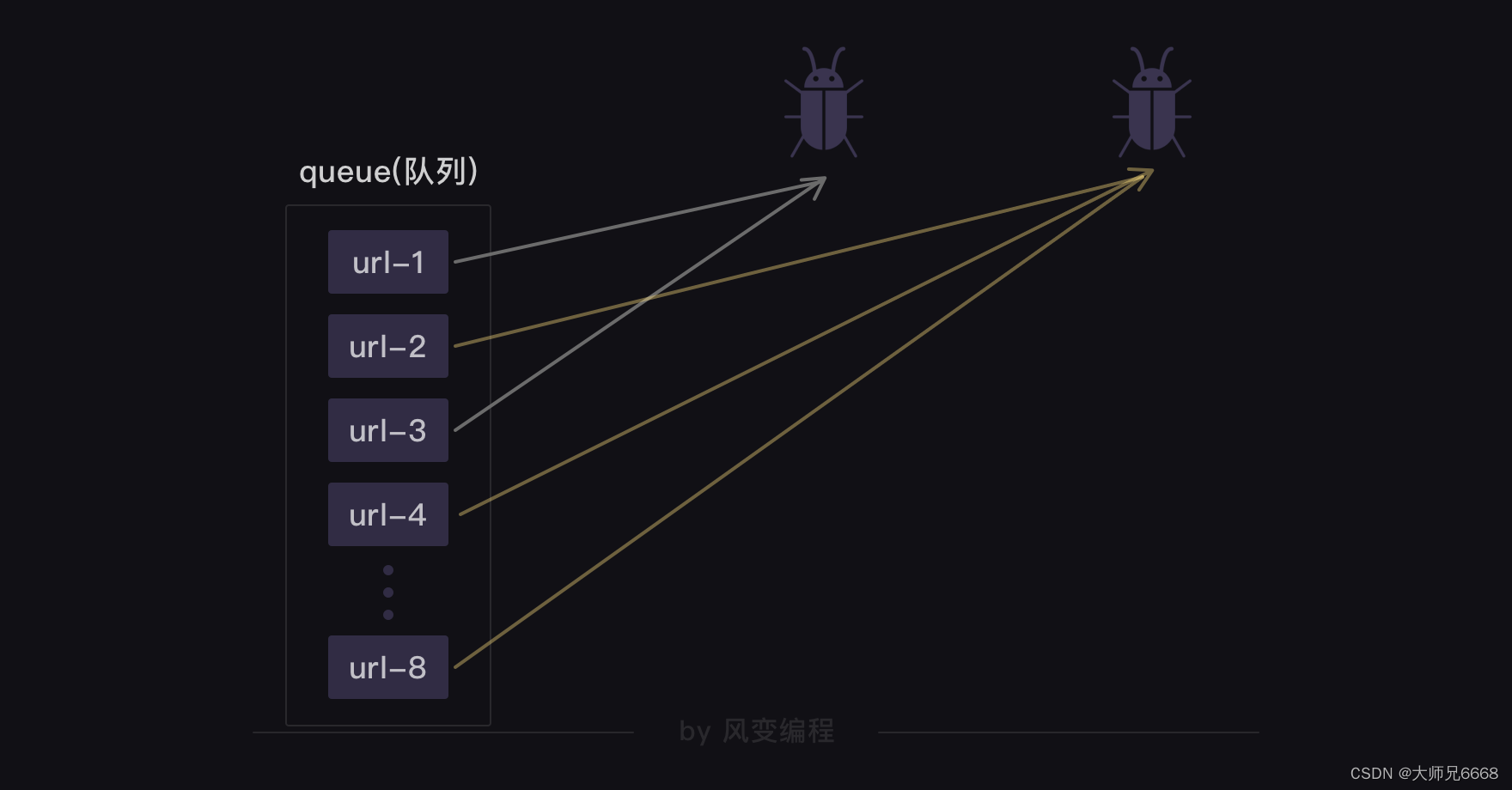
Creamos dos rastreadores que pueden rastrear de forma asincrónica. Tomarán la URL de la cola y realizarán la tarea de rastreo. Una vez que un rastreador toma una URL, otro rastreador no puede recuperarla y otro rastreador tomará la siguiente URL. Hasta que se hayan recuperado todas las URL y la cola esté vacía, el rastreador dejará de funcionar.
El código completo para rastrear 8 sitios web utilizando tecnología de rutina y colas es el siguiente:
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests
from gevent.queue import Queue
#从gevent库里导入queue模块
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
#创建队列对象,并赋值给work。
for url in url_list:
#遍历url_list
work.put_nowait(url)
#用put_nowait()函数可以把网址都放进队列里。
def crawler():
while not work.empty():
#当队列不是空的时候,就执行下面的程序。
url = work.get_nowait()
#用get_nowait()函数可以把队列里的网址都取出。
r = requests.get(url)
#用requests.get()函数抓取网址。
print(url,work.qsize(),r.status_code)
#打印网址、队列长度、抓取请求的状态码。
tasks_list = [ ]
#创建空的任务列表
for x in range(2):
#相当于创建了2个爬虫
task = gevent.spawn(crawler)
#用gevent.spawn()函数创建执行crawler()函数的任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#用gevent.joinall方法,执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
print(end-start)
Intente escribir el código anterior (cualquiera que no practique el rastreo es simplemente un pícaro).
Siempre habrá ganancias si tomas medidas. ¡Felicitaciones, ha terminado de aprender los conocimientos básicos de este nivel, la biblioteca gevent y el módulo Queue para implementar múltiples rutinas!
Revisión extendida
Sin embargo, también quiero ampliar algunos conocimientos nuevos contigo.
A la hora de cocinar ya sabemos que una forma mejor que cocinar primero y luego cocinar es cocinar esperando. Pero en realidad existe una solución más rápida: dejar que una persona se encargue de cocinar y otra persona se encargue de cocinar.
Continuando con nuestro poco conocimiento de la historia de la informática: más tarde, nuestra CPU finalmente evolucionó de un solo núcleo a varios núcleos, y cada núcleo puede funcionar de forma independiente. Las computadoras comenzaron a poder ejecutar realmente múltiples tareas al mismo tiempo (el término se llama ejecución paralela), en lugar de alternar entre múltiples tareas (el término se llama ejecución concurrente).
Por ejemplo, cuando abre el navegador y mira el curso del rastreador, puede abrir el reproductor de música para escuchar canciones y también puede abrir Excel. Para las CPU de varios núcleos, todas estas tareas se ejecutan simultáneamente.
Hoy en día, nuestras computadoras generalmente tienen CPU multinúcleo. En realidad, la rutina múltiple solo ocupa un núcleo de la CPU para ejecutarse y no utiliza completamente otros núcleos. La tecnología que utiliza varios núcleos de CPU para realizar tareas al mismo tiempo se denomina "multiprocesamiento".
Por lo tanto, un programa de rastreo verdaderamente a gran escala no dependerá únicamente de múltiples rutinas para aumentar la velocidad de rastreo. Por ejemplo, se puede decir que el motor de búsqueda Baidu es un programa de rastreo muy grande que, además de depender de múltiples corrutinas, también dependerá de múltiples procesos e incluso de rastreadores distribuidos.
Los rastreadores multiproceso y los rastreadores distribuidos son relativamente complicados, por lo que no entraré en detalles aquí. Los estudiantes que necesitan aprendizaje avanzado pueden hacer su propia investigación.
Finalmente, una revisión de este nivel.
revisar
Sincronización y asincronía:
la multicorrutina es un método asincrónico no preventivo. Mediante el uso de múltiples corrutinas, se pueden ejecutar múltiples tareas de rastreo de forma alternativa y asincrónica.


¡Eso es todo por estos puntos de conocimiento! ¡Nos vemos en el siguiente nivel!