Recientemente, me pidieron que fuera un rastreador, pero debido a una falta de comunicación en la etapa inicial, hubo varias rondas de reelaboración. (todavía reelaborando)
Finalmente tuvo éxito, hizo un proyecto de código empaquetado y exe
exe se parece a esto

Después de hacer clic, puede obtener una interfaz escrita por tkinter, como se muestra en la figura:
Puede obtenerlo en el escritorio después de hacer clic en

Sin más preámbulos, el catálogo es el siguiente.
Tabla de contenido
función de tiempo de definición
Rastrear la generación de enlaces del sitio web de destino
La función de rastreo del sitio web de destino
función para configurar la caja
función para configurar el botón
Funciones adicionales para configurar el texto de fondo
Y una línea de código que no debes olvidar escribir después de que termine tkinter (muy importante)
Acerca del tutorial de empaquetado exe
Crear un entorno virtual para exe
para ver todos los entornos virtuales
Configuración del entorno virtual
Visualización de la ruta de embalaje
código completo
import requests
import json
import pandas as pd
import time
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为
import datetime
import tkinter as tk
import openpyxl
#爬虫代做+v:j1yzbzjpzyxz
#时间函数
def getdate(self,beforeOfDay):
today = datetime.datetime.now()
# 计算偏移量
offset = datetime.timedelta(days=-beforeOfDay)
# 获取想要的日期的时间
re_date = (today + offset).strftime('%Y-%m-%d')
return re_date
#zgzf采购网网页生成函数
def getSearchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
for o in range(3):
a=o+1
url_list=url_list+["https://search.ccgp.gov.cn/bxsearch?searchtype=2&page_index="+str(a)+"&bidSort=&buyerName=&projectId=&pinMu=&bidType=&dbselect=bidx&kw="+search_list[i]+"&start_time="+getdate(0,3)+"&end_time="+str(datetime.datetime.now().strftime('%Y-%m-%d'))+"&timeType=2&displayZone=陕西&zoneId=&pppStatus=0&agentName="]
return url_list
#zgzf采购网网页爬取函数
def ccgp():
web_list=[]
region_list=[]
time_list=[]
dady_list=[]
title_list=[]
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
for p in range(len(getSearchlist())):
time.sleep(6)
url2 =getSearchlist()[p]
response2 = requests.get(url= url2,headers=header)
response2.encoding = 'utf-8'
wb_data2 = response2.text
html = etree.HTML(wb_data2)
www=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li/a/@href')
for i in range(len(www)):
i=i+1
web_list=web_list+html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a/@href')
title_list=title_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a[@href]/text()')).split("\\r\\n ")[1].split("\\r\\n")[0]]
time_list=time_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("['")[1].split(" ")[0]]
dady_list=dady_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("|")[1].split("\\r\\n ")[0]]
ww=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/a/text()')
if ww==[]:
region_list=region_list+['None']
else:
region_list=region_list+html.xpath('//div/div/div[1]/ul/li['+str(i)+']/span/a[@href="javascript:void(0)"]/text()')
i=i-1
a=pd.DataFrame({'标题':title_list,'地区':region_list,'时间':time_list,'采购人':dady_list,'详细网址':web_list})
a=a[a['地区']=='陕西']
a.to_excel(excel_writer = r"F:\\desktop\\导出结果(爬虫中国政府采购网).xlsx")
return a
#陕西省政府采购网
def get_ccgpshaanxi_Searchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
url_list=url_list+["http://www.ccgp-shaanxi.gov.cn/freecms/rest/v1/notice/selectInfoMoreChannel.do?&siteId=a7a15d60-de5b-42f2-b35a-7e3efc34e54f&channel=&title=&content="+search_list[i]+"®ionCode=¬iceType=&operationStartTime="+getdate(0,1)+"%2000:00:00&operationEndTime="+str(datetime.datetime.now().strftime('%Y-%m-%d'))+"%2023:59:59&currPage=1&pageSize=10&cityOrArea="]
return url_list
def ccgpshaanxi():
title=[]
dady=[]
agency=[]
web=[]
reigon=[]
budget=[]
issue_time=[]
notice=[]
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
for p in range(len(get_ccgpshaanxi_Searchlist())):
url2 =get_ccgpshaanxi_Searchlist()[p]
response2 = requests.get(url= url2,headers=headers)
response2 .encoding = 'utf-8'
wb_data_2 = response2.text
html = etree.HTML(wb_data_2)
for i in range(len(json.loads(wb_data_2)['data'])):
title=title+[json.loads(wb_data_2)['data'][i]['title']]
web=web+["http://www.ccgp-shaanxi.gov.cn/freecms"+json.loads(wb_data_2)['data'][i]['htmlpath']]
reigon=reigon+[json.loads(wb_data_2)['data'][i]['regionName']]
issue_time=issue_time+[json.loads(wb_data_2)['data'][i]['openTenderTime']]
notice=notice+[json.loads(wb_data_2)['data'][i]['noticeTime']]
budget=budget+[str(json.loads(wb_data_2)['data'][i]['budget'])]
dady=dady+[str(json.loads(wb_data_2)['data'][i]['purchaser'])]
a=pd.DataFrame({'标题':title,'发布时间':issue_time,'notice':notice,'预算(元)':budget,'发布地区':reigon,'详细网址1':web,'甲方':dady})
a.to_excel(excel_writer=r"F:\\desktop\\导出结果(陕西省政府采购网).xlsx")
return a
#陕西省招投标平台
def get_bulletin_Searchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
url_list=url_list+["http://bulletin.sntba.com/xxfbcmses/search/bulletin.html?searchDate="+getdate(0,2)+"&dates=2&categoryId=88&industryName=&area=&status=&publishMedia=&sourceInfo=&showStatus=&word="+str(search_list[i])]
return url_list
def bulletin():
title=[]
web=[]
reigon=[]
issue_time=[]
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
for x in range(len(get_bulletin_Searchlist())):
response3 = requests.get(url=get_bulletin_Searchlist()[x],headers=headers)
time.sleep(6)
wb_data3 = response3.text
html = etree.HTML(wb_data3)
jishu=html.xpath('//table//tr/td/a/text()')
for i in range(len(jishu)):
i=i+2
title=title+[str(html.xpath('//table//tr['+str(i)+']/td/a/text()')).split('t')[6].split('\r')[0]]
web=web+[str(html.xpath('//table//tr['+str(i)+']/td/a/@href')).split("'")[1]]
reigon=reigon+[str(html.xpath('//table//tr['+ str(i) +']/td[3]/span/text()')).split('t')[6].split('\r')[0]]
issue_time=issue_time+[str(html.xpath('//table//tr ['+ str(i) +']/td[5]/text()')).split('t')[6].split('\r')[0]]
i=i-2
a=pd.DataFrame({'标题':title,'原网址':web,'发布时间':issue_time,'发布地区':reigon})
a.to_excel(excel_writer = r"F:\\desktop\\导出结果(陕西省招标投标公共服务平台).xlsx")
return a
#设计按钮
from tkinter import *
root= tk.Tk()
root.title('爬虫招标信息采集——中国陕西')
root.geometry('400x240') # 这里的乘号不是 * ,而是小写英文字母 x
btn1 = Button(root,text="中国政府采购网",command=ccgp())
btn1.place(relx=0.2,rely=0.4, relwidth=0.3, relheight=0.1)
btn1.pack()
btn2 = Button(root,text="陕西省政府采购网",command=ccgpshaanxi())
btn2.place(relx=0.4,rely=0.4, relwidth=0.6,relheight=0.1)
btn2.pack()
btn3 = Button(root,text="陕西省招标投标公共服务平台",command=bulletin())
btn3.place(relx=0.6,rely=0.4, relwidth=0.9,relheight=0.1)
btn3.pack()
theLabel = tk.Label(root,text="点击按钮获得今日招投标信息",justify=tk.LEFT,compound = tk.CENTER,font=("华文行楷",20),fg = "grey")
theLabel.pack()
root.mainloop()
# In[ ]:
El siguiente es el análisis del código.
Primero, la sección de referencia de la biblioteca.
referencia de la biblioteca
import json
import pandas as pd
import time
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为
import datetime
import tkinter as tk
import openpyxlDebido a que estoy más acostumbrado a Xpath, este proyecto de rastreador también usa Xpath para hacer.
En particular, la biblioteca openpyxl en la parte inferior originalmente no estaba dentro de mi rango de referencia, pero después de que se encapsuló la función, el exe informó un error. Según el mensaje de error, no se encontró la biblioteca openpyxl, así que instalé la biblioteca y la importé, y el error se resolvió.
función de tiempo de definición
#时间函数
def getdate(self,beforeOfDay):
today = datetime.datetime.now()
# 计算偏移量
offset = datetime.timedelta(days=-beforeOfDay)
# 获取想要的日期的时间
re_date = (today + offset).strftime('%Y-%m-%d')
return re_date¡Esta función de tiempo es súper útil! ! !
Debido a que muchos sitios web de ofertas almacenan información en sitios web que incluyen tiempo
Por ejemplo
Búsqueda de Anuncios de Adquisiciones_Red de Adquisiciones Gubernamentales de China
(El sitio web se ve así)
http://search.ccgp.gov.cn/bxsearch?searchtype=2&page_index=1&bidSort=0&buyerName=&projectId=&pinMu=0&bidType=0&dbselect=bidx&kw=%E7%9A%84&start_time=2022%3A07%3A02&end_time=2022%3A08%3A02&timeType=3&displayZone=&zoneId=&pppStatus=0&agentName=El enlace a este sitio web contiene ----- start_time=2022%3A07%3A02&end_time=2022%3A08%3A02
Es la expresión de hora y fecha en la URL
La función de obtención de fecha es para calcular
La fecha obtenida al adelantar varios días según la fecha actual
Por ejemplo: ingrese getdate(,2)
Puede obtener la fecha dos días antes de la fecha de hoy
Consulte el código para generar la lista de rastreadores de China Government Procurement Network para conocer el uso detallado.
Rastrear la generación de enlaces del sitio web de destino
def getSearchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
for o in range(3):
a=o+1
url_list=url_list+["https://search.ccgp.gov.cn/bxsearch?searchtype=2&page_index="+str(a)+"&bidSort=&buyerName=&projectId=&pinMu=&bidType=&dbselect=bidx&kw="+search_list[i]+"&start_time="+getdate(0,3)+"&end_time="+str(datetime.datetime.now().strftime('%Y-%m-%d'))+"&timeType=2&displayZone=陕西&zoneId=&pppStatus=0&agentName="]#自行解析的网站链接
return url_listComo se muestra en la figura, ingrese palabras clave para obtener la URL del sitio web que contiene la información del día.
La función de rastreo del sitio web de destino
def ccgp():
web_list=[]
region_list=[]
time_list=[]
dady_list=[]
title_list=[]
###建立爬取字段
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
###设置当前爬取请求头
for p in range(len(getSearchlist())):
time.sleep(6)###这个网站请求过快会被屏蔽,所以使用time.sleep(6)暂停六秒再进行请求
url2 =getSearchlist()[p]###依次遍历前面getSearchlist()中包含的网站
response2 = requests.get(url= url2,headers=header) ###开始请求
response2.encoding = 'utf-8'
wb_data2 = response2.text
html = etree.HTML(wb_data2)
www=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li/a/@href')###获取该页有多少条信息需要爬取
for i in range(len(www)):###根据需要信息条数进行遍历
i=i+1
###开始爬取 web_list=web_list+html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a/@href')
title_list=title_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a[@href]/text()')).split("\\r\\n ")[1].split("\\r\\n")[0]]
time_list=time_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("['")[1].split(" ")[0]]
dady_list=dady_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("|")[1].split("\\r\\n ")[0]]
ww=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/a/text()')
if ww==[]:
region_list=region_list+['None']
else:
region_list=region_list+html.xpath('//div/div/div[1]/ul/li['+str(i)+']/span/a[@href="javascript:void(0)"]/text()')
i=i-1
a=pd.DataFrame({'标题':title_list,'地区':region_list,'时间':time_list,'采购人':dady_list,'详细网址':web_list})
###筛选爬取地区
a=a[a['地区']=='陕西']
###导出为excel
a.to_excel(excel_writer = r"F:\\desktop\\导出结果(爬虫中国政府采购网).xlsx")
return a
El rastreo de los otros dos sitios web es básicamente similar al de la Red de Compras del Gobierno de China.
parte de tkinter
#设计按钮
from tkinter import *
root= tk.Tk()
root.title('爬虫招标信息采集')
root.geometry('400x240') # 这里的乘号不是 * ,而是小写英文字母 x
btn1 = Button(root,text="1号采购网",command=ccgp())
btn1.place(relx=0.2,rely=0.4, relwidth=0.3, relheight=0.1)
btn1.pack()
btn2 = Button(root,text="2号采购网",command=ccgpshaanxi())
btn2.place(relx=0.4,rely=0.4, relwidth=0.6,relheight=0.1)
btn2.pack()
btn3 = Button(root,text="3号招标投标公共服务平台",command=bulletin())
btn3.place(relx=0.6,rely=0.4, relwidth=0.9,relheight=0.1)
btn3.pack()
theLabel = tk.Label(root,text="点击按钮获得今日招投标信息",justify=tk.LEFT,compound = tk.CENTER,font=("华文行楷",20),fg = "grey")
theLabel.pack()
root.mainloop()La parte de tkinter es realmente muy simple. Escriba un cuadro de programa, configure tres botones en el cuadro y haga clic para activar la función del sitio web correspondiente. Dé un ejemplo
función para configurar la caja
root= tk.Tk()
root.title('爬虫招标信息采集——中国陕西')
root.geometry('400x240') # 这里的乘号不是 * ,而是小写英文字母 xfunción para configurar el botón
btn1 = Button(root,text="中国政府采购网",command=ccgp()#触发函数写在这里)
btn1.place(relx=0.2,rely=0.4, relwidth=0.3, relheight=0.1)
btn1.pack()Funciones adicionales para configurar el texto de fondo
theLabel = tk.Label(root,text="点击按钮获得今日招投标信息",justify=tk.LEFT,compound = tk.CENTER,font=("华文行楷",20),fg = "grey")
theLabel.pack()
Y una línea de código que no debes olvidar escribir después de que termine tkinter (muy importante)
root.mainloop()El programa final se ve así.
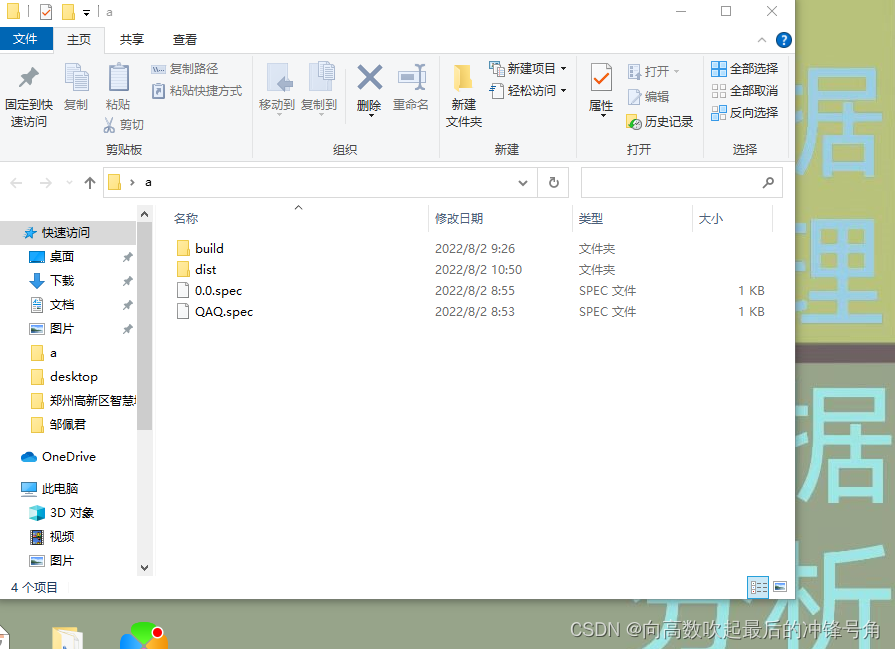
Después de completar todo el trabajo anterior y confirmar que la función está bien, integraremos todas las funciones en un proyecto y lo guardaremos en formato .py
como muestra la imagen
El archivo .py se ve así en pycharm.
Acerca del tutorial de empaquetado exe
La herramienta exe utilizada
En primer lugar, utilizo el compilador de python de la serie anaconda (muy fácil de usar, recomendado por violento enfado), utilizando el indicador de anaconda
Como se muestra en la imagen, esta es la cosa
Después de hacer clic, puede obtener:
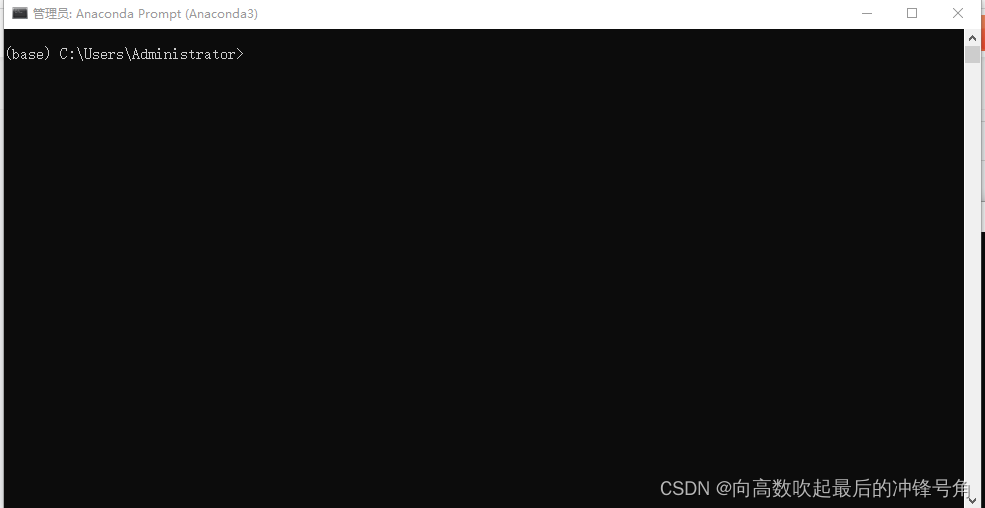
una pequeña caja negra
Esta pequeña caja negra es el foco de nuestra operación y empaquetado de exe. En este proyecto, utilizo un entorno virtual para exe.
Crear un entorno virtual para exe
Primero, ingrese en el pequeño cuadro negro
conda -n XXX(你想起的虚拟环境名字) python=XXX(你想用的python版本编号例如:XXX可以写为3.6)
如果不指定版本
只写
conda -n XXX(你想起的虚拟环境名字)
就好Debe responder (s/n) durante el proceso de creación, Sí, y luego activar el entorno virtual
Antes de la activación:
Después de la activación:
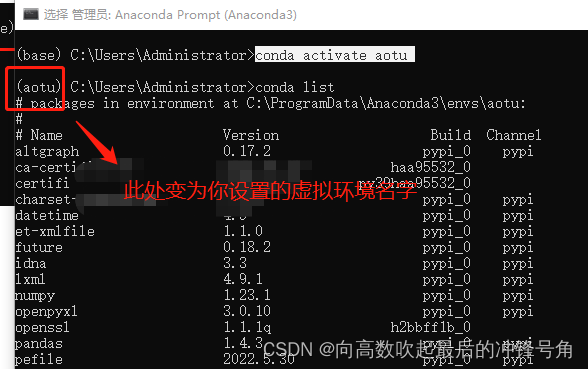
El entorno virtual instalado por conda generará el directorio del entorno virtual en el directorio env bajo el directorio de instalación de anaconda.Si desea encontrar el entorno virtual creado anteriormente, puede buscar en este directorio o ingresar en el cuadro negro
conda info --envspara ver todos los entornos virtuales
Arriba hemos creado y activado el entorno virtual que desea.Después de la creación, puede conda listver las bibliotecas instaladas en el entorno virtual actual.
Después de ver, como se muestra en la figura:
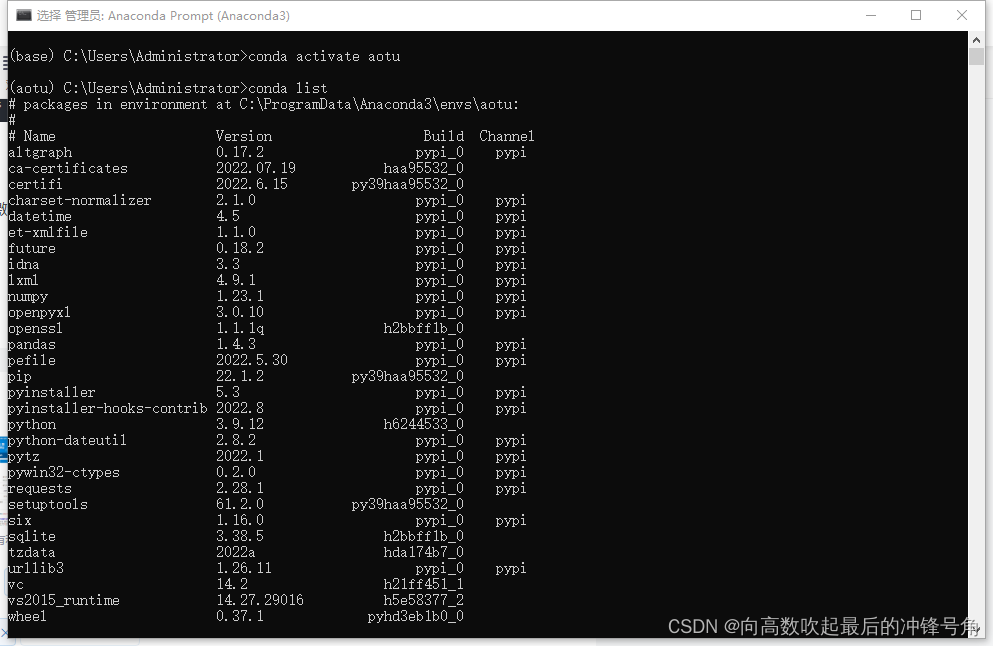
Configuración del entorno virtual
Si encuentra que no hay una biblioteca importada por el archivo py que desea encapsular en el entorno virtual
Se puede resolver por pip en el entorno virtual, de la siguiente manera:
pip install xxx(库名)
解决问题
本次爬虫需要pip的库为
pip install requests
pip install pandas
pip install datetime
pip install lxml
pip install pyinstaller
其中
pip install pyinstaller
必不可少 Visualización de la ruta de embalaje
El siguiente paso es encontrar la ruta del archivo py que necesita exe
Resuelvelo por cd en la cajita negra
Por ejemplo:
Mis archivos se colocan en una carpeta en el escritorio y voy a escribir
cd Desktop\apaquete de comando exe
Pyinstaller -F -w -i XXX(py文件名).pyPantalla de proceso en ejecución
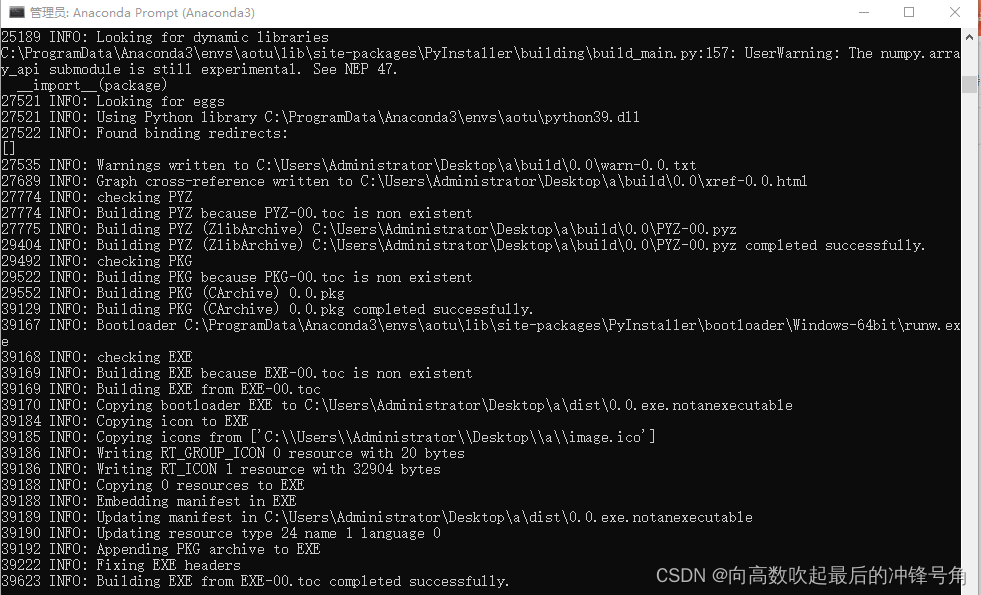
embellecer el logotipo
Si desea cambiar una imagen atractiva para hacer su logotipo
Puede convertir sus imágenes favoritas en formato .ico en línea (el siguiente enlace puede estar satisfecho)
Herramienta en línea de generación de iconos de imagen a ico-ico
Luego coloque las imágenes en formato .ico y los archivos .py en el mismo directorio
usar
Pyinstaller -F -w -i XXX(图片转化ico后的名字).ico XXX(打包程序名).pyresultado
Finalmente, puede obtener el programa exe empaquetado en el archivo dist en esta ruta