Escriba el directorio aquí:
- 1. Construcción de desarrollo de big data [entorno del sistema] en Ubuntu:
- 2. [Entorno Java] Descarga, instalación y solución de problemas de jdk:
- 3. [Entorno de marco de Big Data] Descargue e instale el marco de Hadoop
- 4. Instale Idea (Java IDE) en Linux
- 5. Instalación de [entorno de colmena]:
- 6. [MySql]
1. Construcción de desarrollo de big data [entorno del sistema] en Ubuntu:
1. Desarrollo de una máquina virtual con un solo sistema Linux (no recomendado):
Si necesita desarrollar en un sistema Linux, se recomienda configurar un espacio de usuario separado para el desarrollo (para evitar interferencias).
Por qué crear nuevos usuarios:
Los usuarios son independientes entre sí, al igual que diferentes sistemas de clonación. La creación de nuevos usuarios facilita nuestro trabajo de desarrollo independiente.
Sin embargo, este método no se recomienda por las siguientes razones:
Consejo: en una máquina virtual, en realidad no se recomienda configurar un segundo usuario en una máquina virtual para el desarrollo de big data, porque si el sistema falla, otros usuarios no podrán usarlo, por lo que aún se recomienda abrir un nuevo sistema para llevar a cabo de forma independiente el desarrollo de big data.
Aunque no se recomienda, aún necesitamos anotar el proceso para su referencia.
(1) Cree un nuevo usuario desde la línea de comando (opcional):
1. Cree un nuevo usuario:
sudo useradd -m 用户名 -s /bin/bash
2. Establecer contraseña de usuario:
sudo passwd 用户名
3. Agregue derechos de administrador al usuario (agregue el usuario al grupo "sudo"):
sudo adduser 用户名 sudo
(2) Cree un nuevo usuario en la configuración del sistema (opcional):
primero busque [Usuarios] en la configuración, desbloquéelo y luego haga clic en [Agregar] en la esquina superior derecha para agregar
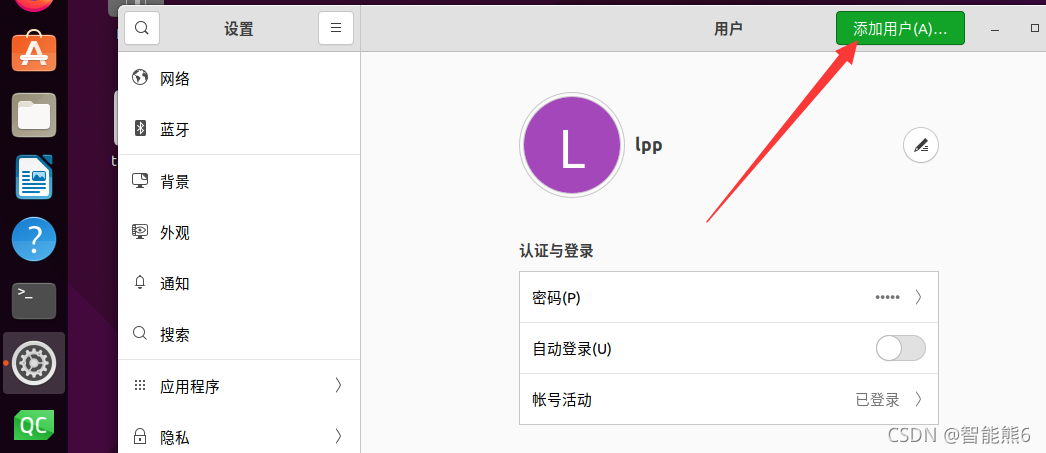
el administrador para facilitar nuestro desarrollo.
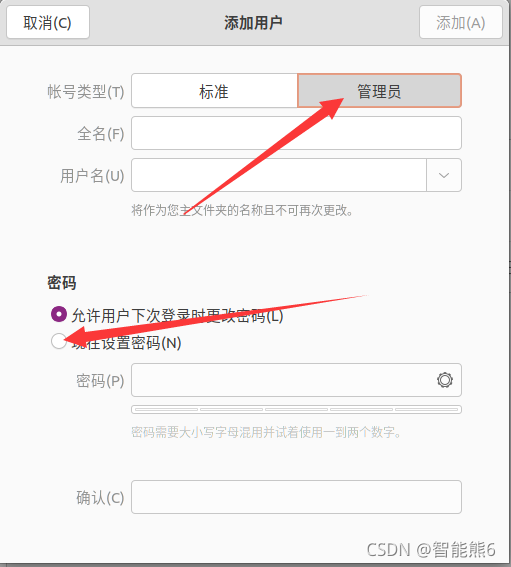
Luego reinicie la máquina virtual, seleccione nuestro usuario recién creado e ingrese el nuevo usuario (como un nuevo sistema)
El método anterior es sólo de referencia, pero no se recomienda, debe elegir según su situación real.
2. Desarrollo de un sistema Linux independiente de la máquina virtual (recomendado):
Abra otro Ubuntu en la máquina virtual VM y luego desarrolle en este sistema.
En este "nuevo" sistema, también necesitamos:
(1) Actualizar la herramienta apt
sudo apt-get update
(2) Utilice la herramienta apt para instalar el editor Vim (utilizado para escribir código):
sudo apt-get install vim
(3) Instale el servidor ssh (el cliente debe instalarse de forma predeterminada)
sudo apt-get install openssh-server
//因为已经默认安装了客户端(client),所以我们只需要安装服务端(server)即可
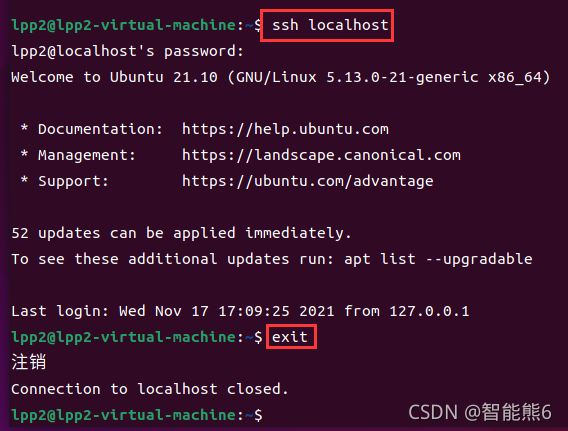
(4) Después de la instalación, use el comando ssh para intentar iniciar sesión (ver si la instalación se realizó correctamente):
ssh localhost
Si hay verificación, simplemente ingrese sí y luego inicie sesión nuevamente después de descargar la configuración.
(5) Cerrar sesión:
exit
Configure el inicio de sesión sin contraseña en el servidor ssh:
después de salir,
(1) use el comando ssh-keygen para generar una clave:
cd ~/.ssh/
ssh-keygen -t rsa
Luego sigue presionando Enter.
(2) Agregue la clave a la autorización:
cat ./id_rsa.pub >> ./authorized_keys
Si no sabe cómo operarlo, puede consultar la siguiente imagen de cómo lo hice: ¡
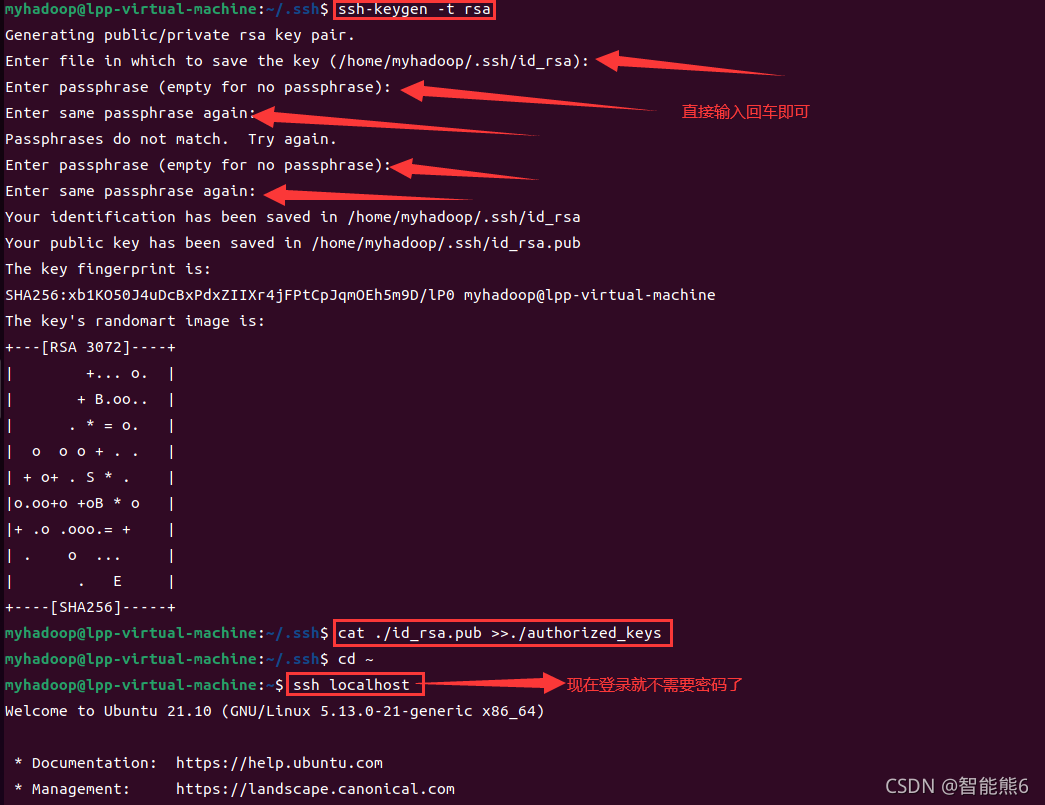
Listo! ! ! Como se muestra en la imagen, ahora no necesita ingresar una contraseña para iniciar sesión en ssh.
2. [Entorno Java] Descarga, instalación y solución de problemas de jdk:
El marco de big data se basa en el lenguaje Java, por lo que es necesario crear un entorno de desarrollo Java en el sistema:
Hipervínculo, haz clic en mí ==》
3. [Entorno de marco de Big Data] Descargue e instale el marco de Hadoop
1. Instalación de Baidu:
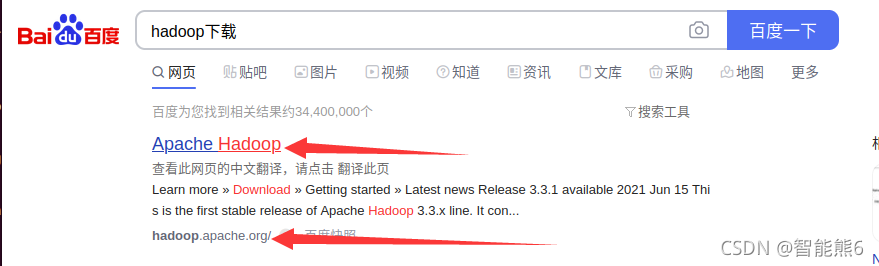

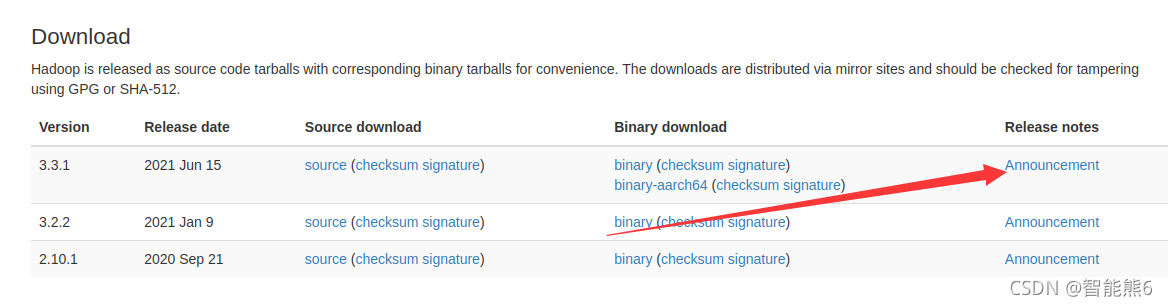
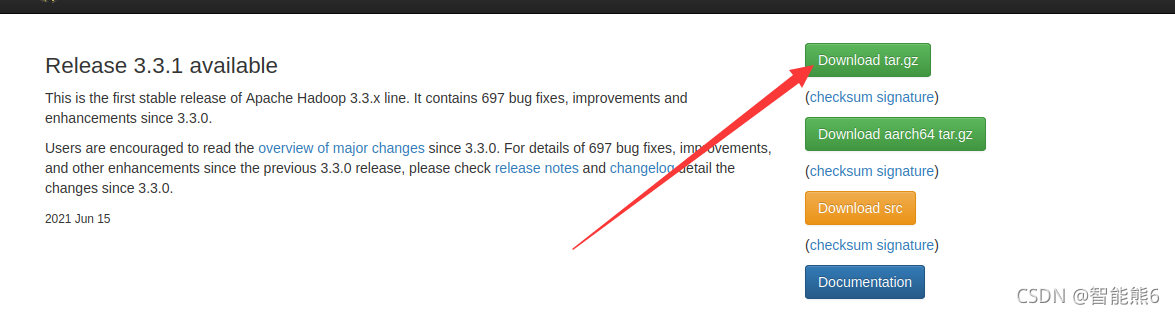
Luego:
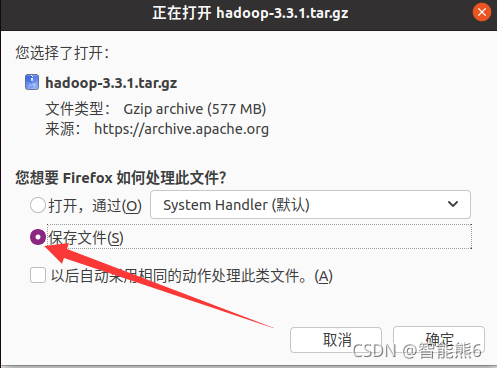
(1) Descomprima e instale:
Tenga en cuenta que si su directorio se vuelve chino, necesitará (c está en mayúscula):
sudo tar -zxf ~/下载/hadoop-3.3.1.tar.gz -C /usr/local
sudo tar -zxf ~/Downloads/hadoop-3.3.1.tar.gz -C /usr/local
(2) Modifique el nombre del archivo:
cd /usr/local
sudo mv ./hadoop-3.3.1/ ./hadoop
(3) Modificar los permisos de archivos:
sudo chown -R 用户名 ./hadoop
(4) Verifique la versión actual (y verifique si la instalación se realizó correctamente):
./hadoop/bin/hadoop version
(5) Crear una nueva carpeta (entrada) para facilitar la gestión de nuestros archivos:
cd /usr/local/hadoop
mkdir input
(6) Copie el archivo de configuración a la nueva carpeta:
cp ./etc/hadoop/*.xml ./input
(7) Ejecute una instancia de Grep para verificar si la instalación se realizó correctamente:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep ./input ./output 'dfs[a-z.]+'
(8) Ver resultados:
cat ./output/*
2. Instalación del sistema de archivos distribuido Hadoop pseudo (un sistema Linux):
(1) Ingrese al directorio de instalación de Hadoop (usr/local/hadoop)
(2) Generalmente, los archivos de configuración se colocan en el directorio etc, así que busquemos:
(3), finalmente configúrelo así (simplemente cópielo, pero preste atención al nombre de la versión correspondiente y la ruta):
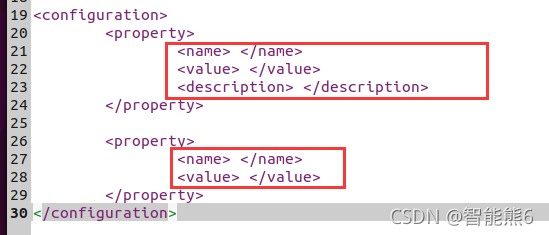
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Este es el segundo archivo de configuración:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(4) Guarde las modificaciones en los dos archivos de configuración anteriores.
Luego,
(5), inicialización-sistema de archivos distribuido (HDFS):
cd /usr/local/hadoop
./bin/hdfs namenode -format
Luego
(6), inicie - Sistema de archivos distribuido (HDFS):
si el directorio no está aquí, primero cd a este
cd /usr/local/hadoop
./sbin/start-dfs.sh
(7) Después del inicio, ingrese jpspara ver el proceso Java que se está ejecutando actualmente:
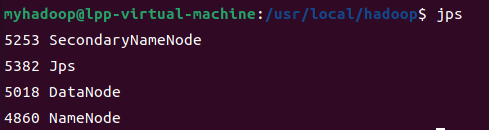
[Opcional] Además, puede ingresar el siguiente comando de formato para ver los comandos relacionados que se pueden usar en el sistema de archivos distribuido:
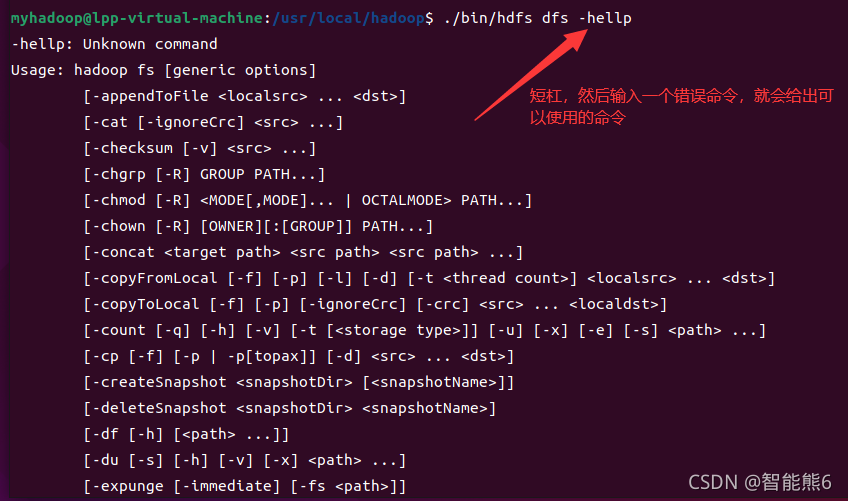
Luego: configuración del lado hdfs (sistema de archivos distribuido):
1. En el lado de hdfs, use su comando 创建文件夹目录:
./bin/hdfs dfs -mkdir -p /user/hadoop/input
2. Utilice el comando put 上传本地的配置文件para ir a la carpeta recién creada en el lado hdfs (sistema de archivos distribuido)
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
3. Ejecute la instancia de Grep para probar:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
4. Ver los resultados:
./bin/hdfs dfs -cat /user/hadoop/output/*

Nota: Cuando necesite volver a ejecutar el programa, deberá eliminar la carpeta de entrada creada previamente en el lado hdfs:
el comando para eliminar la carpeta en el lado del sistema de archivos distribuido es el siguiente:
./bin/hdfs dfs -rm -r /user/hadoop/input
Detenga la ejecución del lado hdfs (si es necesario):
/usr/local/hadoop/sbin/stop-dfs.sh
4. Instale Idea (Java IDE) en Linux
Debido a que necesita escribir lenguaje Java, este entorno de desarrollo integrado (IDE) Java es esencial:
首先你也可以在应用商店里安装,有手就行,我就不啰嗦了。
Lo siguiente solo presenta el método de instalación del sitio web oficial:
(1) Primero, por supuesto, idea de Baidu, luego ingrese al sitio web oficial y descargue la versión comunitaria (no necesito decir más sobre esto)
(2) Después de hacer clic en descargar:
(3) Una vez completada la descarga, es un paquete comprimido tar.gz. Una vez que escuchamos el paquete comprimido, primero debemos descomprimirlo (porque necesitamos usarlo): aquí lo descomprimimos directamente en el directorio local
.
sudo tar -zxf ~/Downloads/ideaIC-2021.2.3.tar.gz -C /usr/local
Si su directorio está en chino, debe cambiarlo a:
sudo tar -zxf ~/下载/ideaIC-2021.2.3.tar.gz -C /usr/local
(4) Después de descomprimir, ingresaremos a su directorio y encontraremos que viene con un método de instalación:
(5) Ábrelo y verás que dice ejecutar ./idea.sh,
es simple, solo ingresa la ruta de el comando Puede ejecutar el comando:
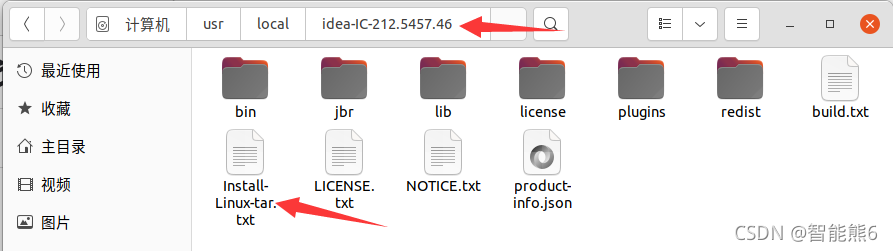
/usr/local/idea-IC-212.5457.46/bin/idea.sh
Verá aparecer la interfaz de instalación.
Normalmente el siguiente paso es suficiente.
5. Instalación de [entorno de colmena]:
1. Ingrese al sitio web oficial de Baidu:
http://www.apache.org/dyn/closer.cgi/hive/
2. Ingrese a la página de descarga:
3. Seleccione una versión:
4. Descargue su versión binaria:
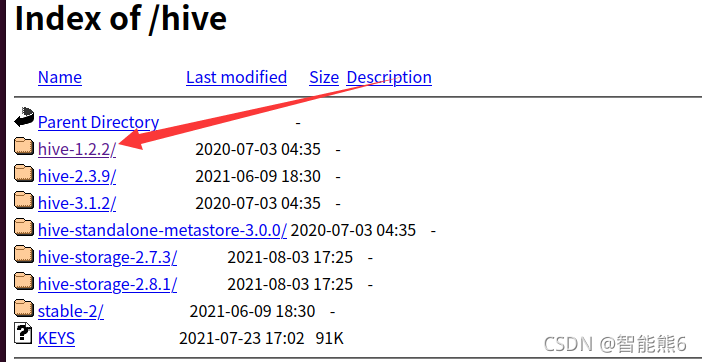
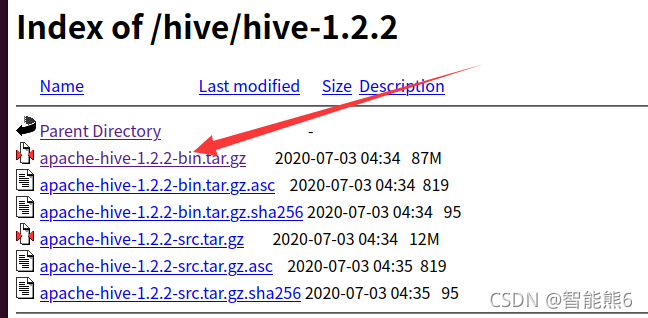
5. Descomprima el paquete comprimido .tar.gz en /usr/local y luego cambie el nombre del archivo, como antes:
Copiar:
(1) Descomprimir e instalar:
Tenga en cuenta que si su directorio se ha cambiado a chino, necesita (c está en mayúscula):
sudo tar -zxf ~/下载/apache-hive-1.2.2-bin.tar.gz -C /usr/local
sudo tar -zxf ~/Downloads/apache-hive-1.2.2-bin.tar.gz -C /usr/local
(2) Modifique el nombre del archivo (el nombre original es demasiado largo):
cd /usr/local
sudo mv ./apache-hive-1.2.2-bin/ ./hive
(3) Modificar los permisos de archivos (otorgar permisos):
sudo chown -R 用户名 ./hive
(4) Para facilitar el uso de los comandos, establezca variables de entorno:
abra el archivo de configuración:
vim ~/.bashrc
Ingrese las variables de entorno, guarde y salga:
(Si no lo sabe, consulte: Enlace》》》 )
#定义它的路径
export HIVE_HOME=/usr/local/hive
#将他的bin路径给环境变量
export PATH=${
PATH}:${HIVE_HOME}/bin
#hadoop也要给个路径:
export HADOOP_HOME=/usr/local/hadoop
Entonces la configuración entra en vigor inmediatamente:
source ~/.bashrc
Luego ingrese: comando colmena para ver el efecto.
(5) Modifique el archivo de configuración: hive-site.xml en /usr/local/hive/conf
y ejecute el siguiente comando:
cd /usr/local/hive/conf
Cambiar el nombre del archivo: eliminar la última plantilla.
mv hive-default.xml.template hive-default.xml
Por supuesto, también puedes usar ningún comando:
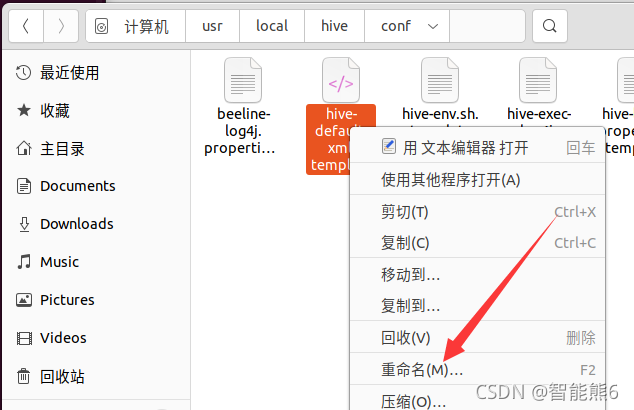
Cree un nuevo hive-site.xmlarchivo de configuración: use el editor vim:
cd /usr/local/hive/conf
vim hive-site.xml
hive-site.xmlAgregue la siguiente información de configuración en :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
Luego, dos puntos, wq guardar y salir.
6. [MySql]
1. Instalación:
sudo apt-get install mysql-server
2. Inicie mysql
service mysql start
3. Utilice el comando root (si no, ingrese sudo passwd root para establecer la contraseña)
su

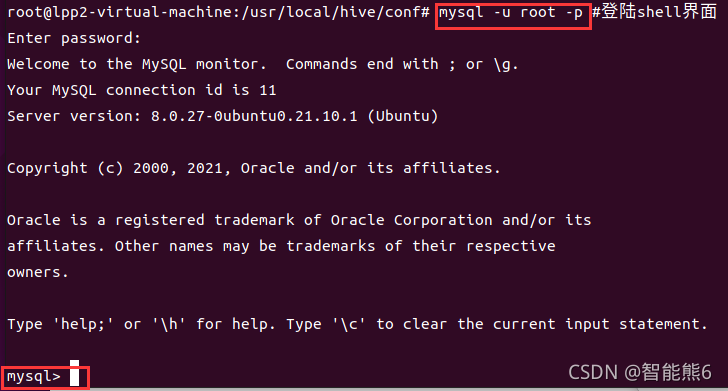
4. Inicie sesión en la interfaz de shell mysql.
mysql -u root -p
5. Cree una nueva base de datos de colmena.
mysql>Abajo:
create database hive;
#Esta base de datos de colmena corresponde a la colmena de localhost:3306/hive en hive-site.xml y se utiliza para guardar metadatos de colmena.
6. Configure mysql para permitir el acceso a la colmena:
mysql>Siguiente:
grant all on *.* to hive@localhost identified by 'hive';
# Otorgue todos los permisos a todas las tablas en todas las bases de datos al usuario de Hive. La siguiente colmena es la contraseña de conexión configurada en hive-site.xml.
7. Actualice la tabla de relación de permisos del sistema MySQL
mysql>:
flush privileges;
8. Iniciar la colmena
(1) Primero inicie el clúster hadoop:
start-all.sh
(2) Iniciar la colmena nuevamente
hive