En primer lugar, lo que Colmena?
Colmena es la esencia: el HQL / SQL en MapReduce se ejecuta en Hadoop, puede ser visto como un motor de análisis de SQL
Hadoop Hive se basa en un almacén de datos de herramientas, puede mapear la estructura del archivo de datos en una tabla, y proporciona similar a SQL consulta.
mesa de colmena es directorio de archivos HDFS, una tabla corresponde a un nombre de directorio, si hay una partición, entonces los valores de partición subdirectorio correspondientes.
Colmena Tutorial: Colmena de la wiki
Dos, la arquitectura de la colmena:
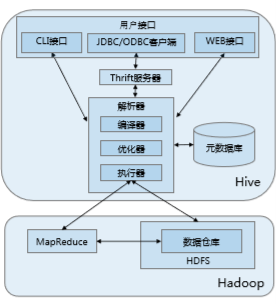
1. Interfaz de usuario:
(1) de la CLI: Colmena también se iniciará una copia cuando se inicia
(2) cliente JDBC: encapsula Thrift, aplicaciones Java, el servidor puede conectarse a la colmena otro proceso que se ejecuta en el host y el puerto especificado por
(3) controlador ODBC Client :: ODBC permite que las aplicaciones que las conexiones de protocolo de apoyo ODBC a la colmena.
servidor 2.Thrift: comunicación basada en la toma de corriente, el apoyo entre lenguajes
3. analizador (analizar la instrucción a ser ejecutada):
(1) compilador: análisis de la declaración, el análisis, compilación, desarrollar planes de trabajo consulta
(2) Optimizer: Evolución reglas de ensamblaje: la construcción de la columna, bajo presión predicado
(3) de actuador: llevará a cabo todas las órdenes de trabajo.
4. base de datos de yuanes:
Colmena de datos se compone de dos partes: los archivos de datos y metadatos. Los metadatos se utilizan para almacenar información básica de la colmena repositorio, se almacena en una base de datos relacional, como MySQL, Derby. Los metadatos incluyen: una base de datos de atributos columna de información, nombres de tabla y particiones de tabla y sus atributos, tablas, tabla de contenido y otros datos se encuentran.
En tercer lugar, el mecanismo de operación de la colmena
1. Un usuario de interfaz a un usuario conectado colmena, publicado Colmena SQL;
2.Hive analizar la consulta y formular un plan de consulta ;
3.Hive convertir la consulta en trabajos de MapReduce ;
4.Hive implementación de MapReduce de Hadoop en puestos de trabajo.
Cuatro, ventajas y desventajas de la colmena
almacén de datos Localización, análisis de datos y el cálculo de la dirección de la deflexión
1. Ventajas:
(1) adecuada para el manejo de grandes cantidades de datos
(2) tomar ventaja de la CPU cluster de computación de recursos, los recursos de almacenamiento, la computación paralela
(3) Clase SQL, generado automáticamente MapReduce
(4). Escalabilidad
2. Desventajas:
(1) una expresión HQL finito .Hive
Baja (2) la eficiencia .Hive: Colmena trabajo MR genera automáticamente, por lo general no inteligente; sintonía HQL difícil, tamaño de grano grueso; pobre capacidad de control.
Para ineficiencias: SparkSQL la aparición de la Sql mejorar efectivamente la eficacia operativa de la análisis sobre Hadoop.
Cinco, Colmena escena aplicable
1. El análisis de datos y almacenamiento de datos en masa
2. Data Mining
3. No es adecuado para los algoritmos y cálculos complejos, no es adecuado para la consulta en tiempo real
En sexto lugar, el uso de la colmena
(A) la conexión de la colmena
Uso HiveServer2, Beeline, conexión Cli
tipo de datos (Ii) .Hive
| clasificación |
tipo |
descripción |
Ejemplos |
| Los tipos primitivos |
BOOLEANA |
verdadero Falso |
CIERTO |
|
|
TINYINT |
1-byte entero con signo -128-127 |
1Y |
|
|
SMALLINT |
2-byte entero con signo -32768 a 32767 |
1S |
|
|
EN T |
Con firmada número entero de 4 bytes |
1 |
|
|
EMPEZANDO |
8-byte entero con signo |
1L |
|
|
FLOTADOR |
4-byte de precisión simple número de coma flotante 1,0 |
|
|
|
DOBLE |
8 bytes de doble precisión de punto flotante |
1.0 |
|
|
DEICIMAL |
De precisión arbitraria decimal con signo |
1.0 |
|
|
CUERDA |
String, de longitud variable |
“A”, 'b' |
|
|
VARCHAR |
cadenas de longitud variable |
“A”, 'b' |
|
|
CARBONIZARSE |
cadena de longitud fija |
“A”, 'b' |
|
|
BINARIO |
matriz de bytes |
no puede ser representado |
|
|
TIMESTAMP |
sello de tiempo, la precisión de nanosegundos |
122327493795 |
|
|
FECHA |
fecha |
'03/29/2016' |
| tipo complejo |
FORMACIÓN |
Conjunto ordenado del mismo tipo |
array (1,2) |
|
|
MAPA |
clave-valor, clave debe ser un tipo primitivo, el valor puede ser cualquier tipo |
mapa ( 'a', 1, 'b', 2) |
|
|
STRUCT |
Establecer campo, pueden ser diferentes tipos |
struct ( '1', 1,1.0), named_stract ( 'col1', '1', 'col2', 1, 'ClO3', 1,0) |
|
|
UNIÓN |
Un valor dentro de un rango limitado de |
create_union (1, 'a', 63) |
(C) .Hive mesa de operaciones y
Datos de metadatos almacenados composición +
Colmena también tiene una base de datos, la base de datos puede ser creado por CREAR BASE DE DATOS. La biblioteca por defecto es la biblioteca por defecto.
1 comprende dos tipos de alojamiento y mesas exteriores
(1) El almacenamiento de datos
Tabla administrado: directorio de almacenamiento de datos en el almacén.
La tabla externa: Cualquier directorio de almacenamiento de datos de HDFS.
(2) los datos eliminados
Tabla administrado: quitar metadatos y datos.
La tabla externa: eliminar sólo los metadatos .
(3) Crear una tabla
Hosting tabla: CREATE TABLE nombre_tabla (attr1 CADENA);
外部表: CREATE EXTERNO TABLE nombre_tabla (attr1 STRING) UBICACIÓN 'camino';
Un enfoque de partición de datos puede acelerar las consultas. Tabla -> Partición -> barril.
2. Partición (clasificación a nivel de carpeta llevado a cabo)
(1) Partición columna de datos no se almacenan realmente, pero la tabla de particiones anidado directorio bajo el directorio.
Ejemplo:
![]()
datos:

(2) La mesa puede ser dividido (de acuerdo con el ejemplo anterior es para particionar el ventilador ID) en varias dimensiones.
(3) particiones pueden acotar la consulta de búsqueda para mejorar la eficiencia.
(4) cuando la partición es crear una tabla con el PARTITION BY cláusula definido.
(5) cargar datos en una partición declaraciones carga especificada valor partición utilizada, y que se mostrará.
(6) Uso mostrar las particiones declaración para ver cuál es el siguiente tabla de particiones de la colmena.
(7) utilizando el SELECT declaración a ver datos en una partición especificada, colmena sólo escanean los datos de partición especificada.
(8) Mesa de la colmena se divide en dos particiones, particiones estáticas y dinámicas particiones. Estático y particiones dinámicas de particionamiento la diferencia de tiempo es importar datos, nombre de la partición se introduce manualmente, o datos para determinar la partición de datos (normalmente a través de las convenciones de nomenclatura de acuerdo con la colmena por un tabique para ayudarnos a Colmena generado automáticamente particiones ). Para los grandes datos de importación a granel, es evidente que el uso de particionamiento dinámico es más simple y conveniente

3. barril (split clasificada dentro del archivo)
(1) barril está fijado sobre la estructura de tabla adicional, puede mejorar la consulta de rendimiento. Propicio para hacer un mapa de lado join ()
(2) un muestreo más conveniente y eficaz utilizar
(3) el uso de racimo por columnas, y el número de cubos para ser divididos se divide cláusula especifica la bañera utilizado.
crear bucketed_user tabla (int id, nombre de cadena) con clústeres (id) en 4 cubos;
(4) los datos del cubo de que puede hacer para ordenar. Uso ordenadas según la cláusula.
crear bucketed_user tabla (int id, nombre de cadena) con clústeres (id) ordenados según (asc id) en 4 cubos;
(5) no recomienda nuestros propios puntos de barriles, se recomienda dejar la colmena divide el barril.
(6) minutos antes de que el cubo se llena los datos necesarios para proporcionar hive.enforce.bucketing conjunto a verdadero . (Crear se inserta el barril en la bañera cuando se les pregunta de datos de otras tablas, proceso dinámico)
insertan bucket_users mesa de sobreescritura seleccionar * de los usuarios;
(7) prácticamente se corresponde con el archivo de partición de salida MapReduce bañera: el mismo número de barriles y reducir las tareas generadas por un trabajo.
4. El formato de almacenamiento
Colmena de Table de almacenamiento a partir de dos dimensiones: "Formato de línea" (formato de filas) y "File Format" (formato de archivo).
Formato (1) Línea:
El almacenamiento de datos en un formato de filas. De acuerdo con los términos de la colmena, la definición definida por el formato de línea SerDe , es decir, la serialización y deserialización. Es decir, los datos de la consulta, archivo SerDe en bytes de datos en forma de filas deserializados como un objeto en la forma de funcionamiento interno filas de datos de la colmena utilizado. Colmena al insertar datos en una tabla, la secuencia de la herramienta Colmena representación interna línea de datos en una secuencia de bytes escritos en el archivo de salida en forma y listo.
(2) Formatos de archivo
El formato de archivo más simple es un archivo de texto plano, pero también se puede utilizar el formato de columna y orientado a archivo binario orientado a líneas. Los archivos binarios pueden ser archivo secuencial, Avro, fichero de recursos, ORC, archivo de parquet.
5. Los datos de importación
Presentación de (1) Insertar el modo de datos: la inserción de hojas múltiples, inserto de cerramiento dinámico.
(2) Modo de carga introdujo
(3) Los gatos manera: echa un vistazo a los datos, cree una tabla
6. modificar y tablas de borrado
Colmena utilizando el "modo de lectura", por lo que después de crear la tabla, es muy flexibles modificaciones de apoyo a la definición de la tabla . Pero en general, tenemos que estar atentos, en muchos casos, para asegurarse de que modifique los datos para adaptarse a la nueva estructura.
(1) Cambiar nombre tabla
(2) modificar la definición de la columna
(3) Tabla de Delete
(4) cortar fuera de la mesa (la estructura de la tabla almacenada, la tabla de datos vacío)
