1. Estructura de memoria JVM
1. La estructura de memoria de la JVM se divide aproximadamente en
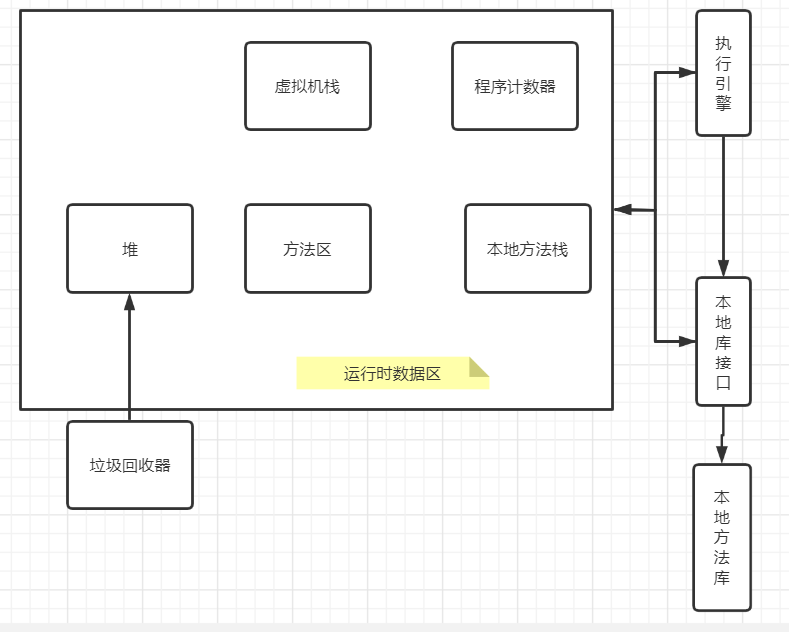
Montón
Compartir hilo. Todas las instancias de objetos y matrices se asignan en el montón. El objeto que maneja principalmente el coleccionista.
Área de método
También llamada área estática, compartida por subprocesos. Almacene información de clase, constantes, variables estáticas y código compilado por el compilador justo a tiempo.
Method Area (Área de método), al igual que el montón de Java, es un área de memoria compartida por cada subproceso Se utiliza para almacenar datos como información de clase, constantes, variables estáticas y código compilado por el compilador instantáneo que ha sido cargado por la máquina virtual. Aunque la especificación de la máquina virtual de Java describe el área del método como una parte lógica del montón, tiene un alias llamado Non-Heap (non-heap), que debe distinguirse del montón de Java.
Pila de métodos (pila JVM)
Hilo privado. Almacene tablas de variables locales, pilas de operaciones, enlaces dinámicos, salidas de métodos y punteros de objetos.
Cada subproceso tendrá una pila privada. La llamada al método en cada subproceso creará un marco de pila en esta pila. Varios tipos de datos básicos (boolean, byte, char, short, int, float, long, double) y referencias de objetos (tipo de referencia, que no son equivalentes al objeto en sí) conocidos durante la compilación se almacenan en la pila de métodos. El espacio de memoria requerido para la tabla de variables locales se asigna durante la compilación. Al ingresar un método, se determina completamente cuánto espacio de variables locales necesita asignar el método en el marco, y el tamaño de la tabla de variables locales no cambiará durante la ejecución del método.
Pila de métodos nativos
Hilo privado. Servir el método nativo utilizado por la máquina virtual. Por ejemplo, cuando Java utiliza servicios de interfaz escritos en c o c++, el código se ejecuta en esta área. Las pilas de métodos nativos (Native Method Stacks) son muy similares a las pilas de máquinas virtuales. La diferencia es que la pila de la máquina virtual sirve a la máquina virtual para ejecutar métodos Java (es decir, códigos de bytes), mientras que la pila de métodos nativos sirve a los métodos nativos utilizados por la máquina virtual.
Registro de contador de programa
Hilo privado. Algunos artículos también están traducidos a PC Register (Registro de PC), lo mismo. Puede verse como un indicador de número de línea del código de bytes ejecutado por el subproceso actual. Apunta a la siguiente instrucción a ejecutar.
Se puede considerar como un indicador del número de línea del código de bytes que ejecuta el subproceso actual. En el modelo conceptual de la máquina virtual, el trabajo del intérprete de código de bytes es cambiar el valor de este contador para seleccionar la siguiente instrucción de código de bytes que se ejecutará. Funciones básicas como bifurcación, bucle, salto, manejo de excepciones y recuperación de subprocesos dependen de este contador. El contador del programa en la JVM también es la única área en la especificación de la máquina virtual de Java que no especifica ninguna condición OutOfMemoryError. Un subproceso JVM solo puede ejecutar el código de un método en cualquier momento, y el método puede ser un método Java o un método nativo.
enfocar
La atención se centra en las diversas partes del tiempo de ejecución de la memoria de Java, las tres áreas del contador del programa, la pila de la máquina virtual y la pila de métodos locales viven y mueren con subprocesos. Los marcos de pila en la pila entran y salen de la pila de manera ordenada a medida que el método entra y sale. No hay necesidad de pensar demasiado en la recuperación de la memoria en estas áreas, porque cuando finaliza el método o el subproceso, la memoria se recuperará de forma natural. Sin embargo, el montón de Java y el área del método son diferentes: la memoria requerida por múltiples clases de implementación en una interfaz puede ser diferente, y la memoria requerida por múltiples ramas en un método puede ser diferente. La asignación de esta parte de la memoria es dinámica y solo podemos saber qué objetos se crearán durante la ejecución del programa. Esta parte de la memoria es el foco de nuestra atención.
2. memoria principal jvm y memoria de trabajo
La memoria principal incluye principalmente el área del método local y el montón. Cada subproceso tiene una memoria de trabajo, y la memoria de trabajo incluye principalmente dos partes, una es la pila privada que pertenece al subproceso y el registro para copiar algunas variables de la memoria principal (incluido el contador de programa PC y el área de caché donde funciona la taza).
- Todas las variables se almacenan en la memoria principal (parte de la memoria de la máquina virtual), compartida por todos los subprocesos.
- Cada subproceso tiene su propia memoria de trabajo, que es una copia de ciertas variables en la memoria principal.Todas las operaciones sobre variables por subprocesos deben realizarse en la memoria de trabajo, y las variables en la memoria principal no se pueden leer ni escribir directamente.
- Los subprocesos no pueden acceder directamente a las variables en la memoria de trabajo de cada uno, y la transferencia de variables entre subprocesos debe completarse a través de la memoria principal.
Los problemas de concurrencia de subprocesos múltiples de Java eventualmente se reflejarán en el modelo de memoria de Java.La llamada seguridad de subprocesos no es más que controlar el acceso ordenado o la modificación de un recurso por parte de múltiples subprocesos. Para resumir el modelo de memoria de Java, hay dos problemas principales a resolver: visibilidad y orden.
Múltiples subprocesos no pueden pasar la comunicación de datos entre sí, y la comunicación entre ellos solo puede llevarse a cabo a través de variables compartidas. El modelo de memoria de Java (JMM) estipula que el jvm tiene memoria principal, y la memoria principal es compartida por varios subprocesos. Cuando un objeto es nuevo, también se ubica en la memoria principal. Cada subproceso tiene su propia memoria de trabajo, que almacena una copia de algunos objetos en la memoria principal. Por supuesto, el tamaño de la memoria de trabajo del subproceso es limitado. Cuando un hilo opera un objeto, la secuencia de ejecución es la siguiente:
- Copie variables de la memoria principal a la memoria de trabajo actual (leer y cargar)
- Ejecutar código, cambiar el valor de la variable compartida (usar y asignar)
- Actualizar el contenido relacionado con la memoria principal con datos de la memoria de trabajo (almacenar y escribir)
2.1 La palabra clave volátil
Cualquier variable modificada por volátil no se copia en la memoria de trabajo, y cualquier modificación se escribe en la memoria principal a tiempo. Por lo tanto, todos los subprocesos pueden ver la modificación de las variables modificadas por Valatile inmediatamente, pero volatile no puede garantizar que la modificación de las variables esté en orden.
2.2 palabra clave sincronizada
Java utiliza la palabra clave sincronizada como uno de los medios para garantizar el orden de la ejecución en un entorno concurrente de subprocesos múltiples. Cuando un fragmento de código modifica una variable compartida, este fragmento de código se convierte en un mutex o una sección crítica.Para garantizar la corrección de la variable compartida, sincronizado marca la sección crítica.
Un subproceso ejecuta el proceso de código de sección crítica de la siguiente manera:
- obtener bloqueo de sincronización
- borrar la memoria de trabajo
- Copie la copia variable de la memoria principal a la memoria de trabajo
- Calcula estas variables
- Escribir variables desde la memoria de trabajo de vuelta a la memoria principal
- liberar bloqueo
Se puede ver que sincronizado no solo garantiza la concurrencia y el orden de los subprocesos múltiples, sino que también asegura la visibilidad de la memoria de los subprocesos múltiples.
2. El proceso de análisis de memoria de la ejecución del programa.
Código de muestra:
public class Person {
String name;
int age;
public void show(){
System.out.println("姓名:"+name+",年龄:"+age);
}
}
public class TestPerson {
public static void main(String[ ] args) {
// 创建p1对象
Person p1 = new Person();
p1.age = 24;
p1.name = "张三";
p1.show();
// 创建p2对象
Person p2 = new Person();
p2.age = 35;
p2.name = "李四";
p2.show();
}
}
Análisis de memoria del proceso de ejecución de código anterior (comprenda con la ayuda de la figura anterior):
1. Establezca el marco de pila desde el método main(), porque el método principal es el punto de entrada del programa y el valor de args es nulo
2. Cree un objeto p1 y el valor de la variable p1 es nulo porque es un tipo de referencia
3. New Person() ejecuta el método de construcción y se debe abrir un nuevo marco de pila Person() en la pila de la máquina virtual.
4. En este momento, se agregará un objeto al montón. El valor predeterminado de name en el objeto es nulo y el valor predeterminado de age es 0.
5. Hay una clase de Persona en el área de métodos, y la información específica del método show() se almacenará en la clase de Persona
6. Si show() en el área de método tiene una dirección, el show en el montón apunta al show() en el área de método, asumiendo que la dirección del objeto en el montón es 0x1024, dado que Persona p1 = nuevo objeto Persona() está asignado a p1, la dirección de p1 es 0x1024, y p1 en el marco de la pila principal() apunta al objeto en el montón
7. Después de ejecutar Person p1 = new Person(), se abre el marco de pila Person()
8. p1.age = 24 para la operación de asignación, el nombre en la dirección ya no es nulo y el valor se convierte en 24
9. p1.name = "Zhang San" para la operación de asignación, "Zhang San" no es un tipo de datos básico, String es equivalente a una clase (clase) en Java y pertenece al tipo de datos de referencia, en el grupo de constantes de cadena en el área de método, proporcione la dirección para nombrar
10. La llamada p1.show() creará un marco de pila llamado p1.show() en la pila de la máquina virtual. Este marco de pila tiene un parámetro predeterminado this, y la dirección es 0x1024. Esto corresponde al método actualmente llamado
11. Ejecute p1.show(), imprima el nombre y la edad, y extraiga el marco de pila de p1.show()
12. De manera similar, después de crear el objeto p2, el proceso de ejecución del código es el mismo que el de p1, y repita los pasos 2-10
13. Finalmente, el marco de la pila principal se extrae y la pila de la máquina virtual se recicla, el procesador de basura recicla el montón y el área del método también se borra en la memoria.