Prefacio
En la era moderna de Internet, la adquisición y el procesamiento de datos web se han convertido en una de las habilidades importantes. Ya sea para obtener información, realizar investigaciones de mercado o realizar análisis de datos, dominar las técnicas de procesamiento de datos y web scraping puede resultar muy útil. Este artículo presentará el proceso completo desde la carga de la página web hasta el almacenamiento de datos, incluidas las solicitudes de red, el análisis de datos, las medidas anti-rastreo, los rastreadores asíncronos multitarea, el almacenamiento de datos y la programación orientada a objetos. A través del estudio de este artículo, los lectores podrán dominar los principios y técnicas básicos para recopilar información de páginas web, así como también cómo procesar y almacenar esta información.
Todo el proceso de carga de una página web.
Supongamos que ingresamos la URL www.example.com en el navegador y presionamos Enter, ocurrirá el siguiente proceso:
- El navegador verifica el caché local para ver si se ha visitado la página web y, si se ha visitado, muestra directamente el contenido del caché local sin solicitar al servidor.
- Si no hay caché local, el navegador crea una solicitud HTTP para la página web en el servidor www.example.com.
- Se envía la solicitud, el servidor busca el archivo de la página web después de recibir la solicitud y, después de encontrarla, coloca el contenido del archivo de la página web en la respuesta HTTP y lo devuelve al navegador.
- Cuando el navegador recibe el contenido HTML devuelto por el servidor, es como recibir un trozo de patata, hay que lavarlo y cortarlo en trozos antes de cocinarlo. El navegador también necesita analizar HTML, CSS y JS para mostrar una interfaz hermosa.
- El navegador generará un árbol DOM para almacenar la estructura de etiquetas HTML y un árbol CSSOM para almacenar las reglas de estilo CSS.
- El navegador ejecuta el código JavaScript de la página, que puede modificar el DOM o CSSOM.
- El navegador integrará DOM y CSSOM para formar un árbol de representación, determinando el estilo y las coordenadas de cada nodo.
- Diseñe de acuerdo con el árbol de representación, calcule el tamaño y la posición de cada nodo y luego dibuje la página.
- Muestre la página dibujada en la ventana del navegador.
- Cuando hacemos clic o ingresamos, el navegador responderá en tiempo real, volverá a ejecutar JavaScript, ajustará estilos, rediseñará y volverá a dibujar la página.
Te explicaré detalladamente el proceso de carga de la página web en un lenguaje sencillo:
- Xiao Ming ingresa la URL y presiona la tecla Enter, y el navegador comienza a funcionar después de escucharla.
- El navegador primero verifica si Xiao Ming ha visitado este sitio web antes y, de ser así, le muestra a Xiao Ming la página web anterior.
- Si no ha estado aquí, el navegador enviará un correo electrónico al servidor del sitio web, diciendo que quiere ver su sitio web y por favor responda con el contenido de la página web.
- El servidor del sitio web recibe el correo electrónico del navegador, encuentra el archivo de la página web, lo sella en un sobre y lo envía de vuelta al navegador.
- El navegador recibe la respuesta del servidor y abre el sobre, dentro hay un montón de códigos, imágenes y cosas similares.
- El navegador junta estos códigos e imágenes como bloques de construcción, primero crea una estructura de árbol DOM, luego determina el estilo CSS y luego combina los dos árboles en un solo árbol de representación.
- El navegador calcula la posición y el tamaño de cada parte de acuerdo con el árbol de representación y luego dibuja la página web.
- Muestre la página web dibujada a Xiao Ming, y Xiao Ming navega felizmente por la página web.
- Si Xiao Ming hace clic en la página web o ingresa contenido, el navegador volverá a ejecutar el código y volverá a dibujar la página.
Dos formas de renderizado para la carga de páginas web:
- Representación del lado del servidor
- Después de recibir la solicitud del cliente, el servidor utiliza un lenguaje de servidor (como PHP) para generar contenido HTML que integra datos.
- De esta forma, el código fuente obtenido por el navegador ya contiene los datos que deben mostrarse.
- Representación del cliente
- Una vez que el navegador obtiene el código fuente HTML devuelto por el servidor, comienza a analizarlo y renderizarlo.
- Al ejecutar código JavaScript, se pueden lograr efectos dinámicos e interacciones en páginas web.
- La integración de datos y contenido de la página se realiza localmente en el navegador.
- Este método de renderizado requiere la red F12 para encontrar los datos requeridos en Fetch/XHR o JS.
- El registro del conservador puede registrar las páginas que ha visitado. Marque esta casilla para evitar el impacto de la página web 302 y la redirección.
Es importante diferenciar entre renderizado del lado del servidor y del lado del cliente. La representación del lado del servidor puede reducir la presión del cliente y la representación del lado del cliente puede proporcionar una mejor experiencia interactiva. El desarrollo web moderno suele combinar las ventajas de ambos métodos de renderizado.
Secciones en el panel Red:
- Los encabezados
solicitan encabezados y encabezados de respuesta, que muestran toda la información del encabezado HTTP de solicitudes y respuestas, incluidos encabezados comunes y encabezados personalizados. Se ampliarán y mostrarán encabezados importantes, como User-Agent, Cookie, Referer, etc. - Solicitud de carga útil
La carga útil muestra el cuerpo de datos enviado al servidor, como los datos del formulario o el cuerpo JSON de la solicitud POST.
La vista previa de respuesta muestra el contenido del resultado de la respuesta recibida, como código HTML, archivos de imagen, datos JSON, etc. - Solicitud de cookies
Cookies muestra información relacionada con las cookies en el encabezado de la solicitud.
Cookies de respuesta muestra el contenido de la cookie establecido en el encabezado de respuesta.
Puede ver el proceso de entrega de cookies. - El iniciador
muestra la información del recurso que inició la solicitud, como img/script/link introducido por etiquetas HTML, etc.
Comprender las dependencias entre recursos. - Duración acumulada del tiempo
: el tiempo total que lleva todo el proceso de solicitud.
Detalles de tiempo a nivel de bloque: muestra el tiempo empleado en cada fase, como cola, resolución de nombre de dominio, conexión TCP, conexión segura TLS y respuesta de solicitud.
Identifique fácilmente los cuellos de botella en el rendimiento. - La respuesta
muestra el código de estado de la respuesta (200, 404, etc.) y la fuente de la respuesta (respuesta del servidor, caché del navegador, etc.)
para identificar rápidamente si la solicitud fue exitosa. - Las condiciones de filtrado
se pueden filtrar por método, nombre de dominio, tipo, texto y otras condiciones, y las condiciones de filtrado se pueden guardar cuando se usan en combinación.
Uso de la biblioteca de solicitudes:
Instalar
pip install requests
OBTENER solicitud
Las solicitudes GET se utilizan para obtener datos del servidor. Pasa datos de solicitud a través de parámetros de la URL.
import requests
params = {
'key1': 'value1', 'key2': 'value2'}
response = requests.get('http://httpbin.org/get', params=params)
print(response.url)
# http://httpbin.org/get?key1=value1&key2=value2
Las solicitudes convertirán automáticamente el tipo de diccionario de parámetros en parámetros de URL.
También puedes unir parámetros directamente en la URL:
import requests
response = requests.get('http://httpbin.org/get?key1=value1&key2=value2')
Ejemplo de búsqueda de Baidu
https://www.baidu.com/s?tn=85070231_38_hao_pg&wd=Summary
https://www.baidu.com/s?tn=85070231_38_hao_pg&wd=%E6%80%BB%E7%BB%93
params = {'tn ': '85070231_38_hao_pg', 'wd': 'Resumen'}

Solicitud de publicación
La solicitud POST se utiliza para enviar datos al servidor. Pasa parámetros a través del cuerpo de la solicitud.
import requests
data = {
'key1': 'value1', 'key2': 'value2'}
response = requests.post('http://httpbin.org/post', data=data)
print(response.text)
# {
# "form": {
# "key1": "value1",
# "key2": "value2"
# }
# }
Las solicitudes codificarán automáticamente el diccionario de datos en formato de formulario.
También puedes pasar cadenas directamente:
data = 'key1=value1&key2=value2'
response = requests.post('http://httpbin.org/post', data=data)
Además, se pueden pasar datos JSON:
import json
data = {
'key1': 'value1', 'key2': 'value2'}
data = json.dumps(data)
response = requests.post('http://httpbin.org/post', data=data)
Dos instancias diferentes
Datos del formulario形式
http://www.xinfadi.com.cn/priceDetail.html datos = {'key1':'value1', 'key2': 'value2'}respuesta = request.post('http://httpbin.org/post', data=data)
simplemente pasa el diccionario
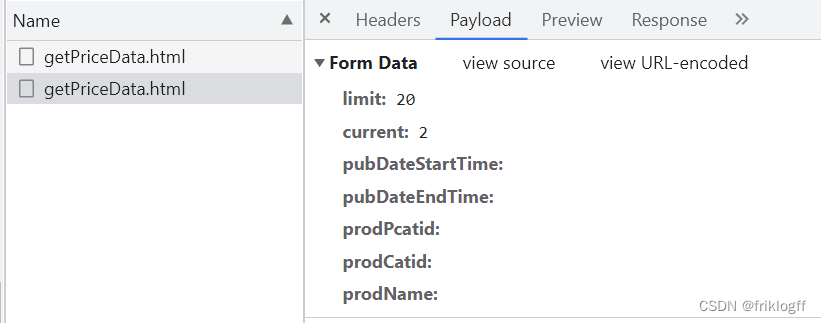
El formulario de solicitud de carga útil
se puede ver visualmente como datos de tipo json.Dos
opciones
- solicitudes.post(url,json={diccionario})
- request.post(url,data=json.dumps({字典}),
headers={ “Tipo de contenido”: “aplicación/json; conjunto de caracteres=UTF-8” })
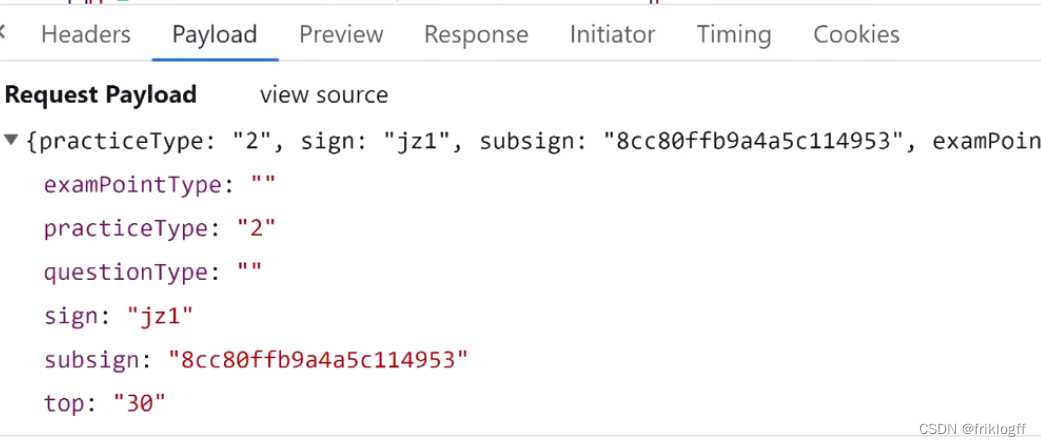
código de estado HTTP
- Serie 200: la solicitud se realizó correctamente, lo que indica que el servidor procesó correctamente la solicitud. Los más comunes incluyen:
- 200 OK: generalmente, este código se devuelve correctamente cuando la solicitud se realiza correctamente.
- 204 Sin contenido: la solicitud se realizó correctamente pero no se devolvió ningún contenido.
- Serie 300: redireccionamiento, que indica que al recurso se le ha asignado un nuevo URI. Los más comunes incluyen:
- 301 movido permanentemente - redirección permanente
- 302 Encontrado - Redirección temporal->ubicación
- 304 No modificado: el recurso no se ha modificado y el caché se usa directamente.
- Serie 400: error del cliente, que indica que la solicitud tiene un error de sintaxis o que la solicitud no se puede completar. Los más comunes incluyen:
- 400 Solicitud incorrecta: hay un error de sintaxis en el mensaje de solicitud
- 401 No autorizado: se requiere información de autenticación
- 403 Prohibido: el servidor rechazó la solicitud
- 404 No encontrado: el recurso solicitado no existe
- Serie 500: error interno del servidor que indica que el servidor no pudo completar la solicitud. Los más comunes incluyen:
- 500 Error interno del servidor - Error interno del servidor
- 503 Servicio no disponible: el servidor está sobrecargado temporalmente o en mantenimiento
Operación anti-rastreo simple:
Encabezado de solicitud:
-
Agente de usuario: identifica la información del navegador del cliente, que se puede utilizar para la detección anti-rastreo e indica qué dispositivo utilizó el usuario para enviar la solicitud.
- Copiado directamente desde el navegador y utilizado para disfrazar el dispositivo de acceso.
-
Cookie: el sitio web se utiliza para rastrear la sesión. Puede detectar cookies anormales para implementar anti-rastreo. Es una cadena registrada por el servidor en el navegador y escrita en un archivo local. Su función es mantener la sesión con el servidor. En el lado del servidor se llama sesión. (Las solicitudes HTTP son solicitudes sin estado)
-
- Copie directamente desde el navegador, adecuado para escenarios simples.
-
- Utilice request.session() para mantener automáticamente la sesión y manejar set-cookie, que es adecuado para escenarios complejos. Si la página web utiliza JS para mantener cookies, debe manejarlo usted mismo.
-
-
Referer: identifica la página de origen, se utiliza para detectar cuál era la URL anterior. Se puede detectar el referer para evitar enlaces activos.
- Copie directamente la URL de la página de origen para falsificar la fuente de acceso.
-
Parámetros personalizados de la página web: este es el más difícil de manejar, es necesario analizar el algoritmo de parámetros mediante ingeniería inversa para encontrar la lógica del código que genera los parámetros.
Encabezado de respuesta:
- Ubicación: dirección de redireccionamiento 302, que se puede configurar para saltar a páginas que son difíciles de analizar para evitar el rastreo.
- Set-Cookie: Establece cookies, que se pueden utilizar para guardar cookies que son difíciles de falsificar para implementar el control de acceso.
- Los sitios web también pueden agregar varios parámetros a estos encabezados para verificación de acceso, telemetría de sesión abierta, etc. para identificar el comportamiento del rastreador.
Uso de solicitudes. Sesión:
Crear objeto de sesión
import requests
session = requests.Session()
Primero importe el módulo de solicitudes y luego llame a request.Session() para crear un objeto de sesión.
Establecer encabezado de solicitud
Puede preestablecer encabezados de solicitud a través del atributo de encabezados del objeto Sesión. Estos encabezados se aplicarán a todas las solicitudes emitidas por esta instancia de Sesión:
session.headers = {
'User-Agent': 'Mozilla/5.0',
'Authorization': 'Bearer xxxxxxxxxxxxx'
}
Establecer cookies
session.cookies.update({
'name': 'value',
'foo': 'bar'
})
Las cookies en la solicitud se pueden configurar mediante el atributo de cookies de la sesión.
Enviar petición
response = session.get(url, params=params)
response = session.post(url, data=data)
Puede utilizar get(), post() y otros métodos del objeto Session para enviar solicitudes.
Cerrar la sesión
session.close()
Cuando termine de usarse la sesión, puede llamar al método close() para cerrar el objeto de sesión.
En comparación con el uso directo de funciones como request.get()/post(), los beneficios de usar el objeto Session son:
- Evite la transferencia repetida de parámetros y mejore la eficiencia
- Procesar cookies automáticamente para mantener el estado
- Gestión conveniente de encabezados de SOLICITUDES y Cookies
Métodos de análisis de datos.
Tres formas de analizar datos HTML:
- expresiones regulares
- Obtener parte del código js (cadena) en html
- Compile expresiones regulares usando re.compile()
- El método re.findall() extrae contenido coincidente del texto basándose en reglas regulares
- Adecuado para extraer cadenas de patrones fijos del texto
import re
html = '<script>var data = "abc"</script>'
pattern = re.compile(r'var data = "(.*)"')
result = pattern.findall(html)
- Llame a xpath() para extraer el nodo especificado
- Se utiliza para analizar estructuras html regulares.
- Puede obtener atributos, texto y otra información.
- Velocidad de procesamiento rápida
from lxml import etree
html = etree.HTML(resp.text)
result = html.xpath('//li/text()')
XPath de etree devuelve una lista de forma predeterminada.
if ret:
ret[0]
else:
XXX
- hermosasopa
- Cree un objeto BeautifulSoup para analizar .xml, .svg
- Busque en el árbol de documentos usando find()/find_all()
- Obtenga nombre, atributos, texto y otra información
- Puede manejar documentos irregulares
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
result = soup.find_all('li')
En resumen, las expresiones regulares son adecuadas para extraer cadenas de patrones fijos, el análisis lxml es rápido y BeautifulSoup puede manejar documentos "malos".
Métodos de análisis de json y jsonp:
- análisis de datos JSON
- Obtener cadena JSON de la respuesta
resp_text = response.text
- Intente cargar el análisis directamente
try:
data = response.json()
except:
# 处理异常
- Si falla, cargue manualmente el análisis
import json
data = json.loads(resp_text )
- Antes de analizar, asegúrese de imprimir y verificar resp_text para confirmar que esté en formato JSON estándar antes de analizar.
- Si te encuentras con escalada inversa. Es posible que lo que obtenga no coincida con la herramienta de captura de paquetes.
- Recuerde imprimir resp_text primero. Asegúrese de que el contenido devuelto esté en formato json antes de iniciar la conversión.
- análisis de datos JSONP
- Formato JSONP como: XXXXXX({json}) => {json}
- Encuentre una manera de eliminar XXXXXX( ) en los extremos izquierdo y derecho => lo que obtiene es json
- “XXXXXX({json}) “.reemplazar(“XXXXXX(”,””)[:-1]
- Es necesario eliminar la parte que llama al método y conservar la cadena JSON.
- Después de obtener la cadena JSON, cárguela y analícela.

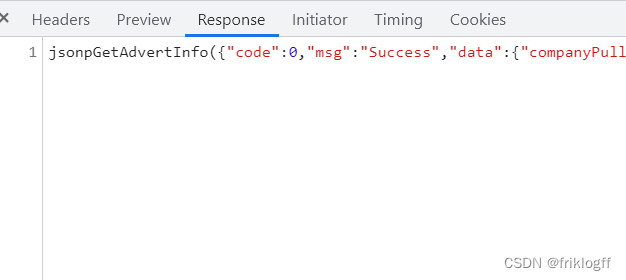
Se puede ver en las dos imágenes anteriores que XXXXXX es el valor de devolución de llamada.
Rastreador asincrónico multitarea. E/S asincrónicas de rutina, multiproceso y subprocesos múltiples
- la diferencia
- Subprocesos múltiples: el espacio de memoria del proceso se comparte entre subprocesos, los costos de cambio de subprocesos son bajos y es adecuado para operaciones con uso intensivo de E/S. Pero no es seguro para subprocesos y requiere un mecanismo de bloqueo.
- Multiproceso: los procesos tienen memoria independiente, el costo es mayor que el de los subprocesos y es adecuado para operaciones con uso intensivo de CPU. La comunicación entre procesos es compleja y requiere IPC.
- Corrutinas: implemente la concurrencia de forma asincrónica en un solo subproceso para reducir el consumo causado por la conmutación. Es adecuado para escenarios con uso intensivo de E/S y puede mejorar enormemente la eficiencia.
- Escena aplicable
- Subprocesos múltiples: rastree una gran cantidad de páginas pequeñas, comparta funciones de análisis entre subprocesos, etc.
- Multiproceso: la escala de datos rastreados es enorme y se requiere un procesamiento de datos intensivo de la CPU.
- Corrutinas: rastreadores asincrónicos que requieren muchas operaciones de E/S para aumentar la concurrencia.
- Dificultad de implementación
- Subprocesos múltiples: el módulo de subprocesos es relativamente simple, pero la dificultad radica en la seguridad de los subprocesos y los problemas de interbloqueo.
- Multiproceso: la comunicación entre procesos y la transferencia de datos son muy complejas de implementar.
- Corrutina: debe comprender la sintaxis asincrónica y la depuración de errores es más difícil.
subprocesos múltiples
- Principio: importe el módulo de subprocesos y utilice la clase Thread para crear subprocesos. El espacio de memoria del proceso se comparte entre subprocesos, no se afecta entre sí y se puede ejecutar al mismo tiempo.
- Ejemplo:
from threading import Thread
import requests
def crawl(url):
r = requests.get(url)
print(r.text)
t1 = Thread(target=crawl, args=('url1',))
t2 = Thread(target=crawl, args=('url2',))
t1.start()
t2.start()
multiprogreso
- Principio: importe el módulo de multiprocesamiento y utilice la clase Proceso para crear un proceso. El proceso tiene un espacio de memoria independiente y necesita comunicarse a través de Queue, Pipe, etc.
- Ejemplo:
from multiprocessing import Process, Queue
def crawler(q):
data = crawl_page()
q.put(data)
q = Queue()
p1 = Process(target=crawler, args=(q,))
p2 = Process(target=crawler, args=(q,))
p1.start()
p2.start()
E/S asincrónicas de rutina
- Principio: utilice la sintaxis async/await para la programación asincrónica. Cuando se encuentra await, cambia a otras rutinas sin bloquear la ejecución del programa.
- Ejemplo:
import asyncio
async def fetch(url):
print('fetching')
return await aiohttp.get(url)
async def main():
await fetch(url1)
await fetch(url2)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
almacenamiento de datos
CSV
- CSV es adecuado para almacenar datos tabulares, como pedidos de comercio electrónico, información del usuario, etc.
- Puede utilizar Excel y otro software para editar y ver datos fácilmente
- Admite el intercambio de datos y se puede importar a una base de datos u otros sistemas.
- Operaciones de módulo csv de uso común en Python
import csv
# 写入CSV文件
with open('data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# 写入标题行
writer.writerow(['ID', 'Name', 'Age'])
# 写入数据行
writer.writerow(['1', '张三', 20])
writer.writerow(['2', '李四', 25])
# 读取CSV文件
with open('data.csv', 'r') as csvfile:
reader = csv.reader(csvfile)
# 读取标题
headers = next(reader)
# 读取每行数据
for row in reader:
print(row)
- Escritura de diccionario en CSV
import csv
with open('data.csv', 'w', newline='') as f:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({
'id': 1, 'name': '张三', 'age': 20})
writer.writerow({
'id': 2, 'name': '李四', 'age': 25})
- Pandas lee y escribe CSV y lo guarda en Excel
import pandas as pd
df = pd.read_csv('data.csv')
df.to_csv('new_data.csv', index=False)
df.to_excel( "hehe.xls", header=False,index=False)
csv es esencialmente un archivo de texto
f = open("data.csv", modew" , encoding="utf-8")f.write("1")
f.write(" , ")
f.write("张三")
f.write(" , ")
f.write( '"张,三"')
f.write(" , ")
f.write("5000")
f.write(" \n ")
f.write(" , ")
f.write("张四")
f.write(" , ")
f.write( '"张,四"')
f.write(" , ")
f.write("5030")
f.write(" \n ")
import pandas
r = pandas.read_csv ( "data.csv " , sep="," , headen=None)
print(r)
r.to_excel( "hehe.xls", header=False,index=False)
mysql
- Tipo de datos: entero, cadena, fecha y hora, etc. Establezca el tipo de campo que cumpla con los requisitos de almacenamiento
- Declaraciones de consulta: SELECCIONAR y DÓNDE filtrar datos, ORDENAR POR clasificación, LIMITAR paginación
- Consulta de unión de tablas: INNER JOIN, IZQUIERDA/DERECHA JOIN y otros métodos para unir varias tablas GetData
- Procesamiento de transacciones: START TRANSACTION to COMMIT, procesando transacciones que contienen múltiples declaraciones SQL
- Operación en Python:
import pymysql
# 连接数据库
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='test')
# 插入数据
cursor = conn.cursor()
cursor.execute("INSERT INTO tb_user VALUES (NULL, '张三', 25)")
conn.commit()
# 查询数据
cursor.execute("SELECT * FROM tb_user")
result = cursor.fetchall()
print(result)
MongoDB
- Almacenamiento de documentos: almacenamiento flexible de datos en formato JSON
- Esquema de datos gratuito, no es necesario definir la estructura de la tabla
- Lenguaje de consulta enriquecido: coincidencia regular, consulta de árbol, consulta de ubicación geográfica, etc.
- Operación en Python:
from pymongo import MongoClient
# 连接Mongodb
client = MongoClient('localhost', 27017)
collection = client['testdb']['user']
# 插入文档
data = {
'name': '张三', 'age': 25}
collection.insert_one(data)
# 查询文档
results = collection.find({
'age': {
'$gt': 20}})
for result in results:
print(result)
Redis
- Almacenamiento de pares clave-valor, el valor admite múltiples estructuras de datos
- Proporciona 5 operaciones de estructura de datos: cadena, hash, lista, conjunto y conjunto ordenado
- Soportar transacciones y tener atomicidad.
- Funciones enriquecidas: publicar y suscribirse, caducidad de LRU, etc.
- Operación en Python:
import redis
# 连接Redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 字符串操作
r.set('username', '张三')
# 散列操作
r.hset('user', 'name', '张三')
# 列表操作
r.lpush('list', 1,2,3)
Programación orientada a objetos
Cambios en el pensamiento de programación.
El código que escribimos hasta ahora está orientado a procesos:
- Obtener el código fuente de la página
- Analizar el código fuente de la página.
- Almacenamiento de datos
Orientado a procesos, céntrese en los pasos e implemente funciones paso a paso en orden.
Similar al proceso cuando quiero beber Coca-Cola:
- Levántate del sofá
- Ir a la puerta del refrigerador
- saca la coca cola
- bebe un sorbo
- cerrar la puerta del refrigerador
pensamiento orientado a objetos
El núcleo de la programación orientada a objetos radica en el cambio de forma de pensar:
- Tienes que manipular objetos y hacer que trabajen para ti.
- El resultado final es que puedes beber Coca-Cola.
- Deja que el objeto opere.
Para implementar la orientación a objetos necesita:
- Definir objeto
- Deja que el objeto realice la operación.
Los programadores pueden concebir y crear objetos libremente y luego definir las propiedades y métodos de los objetos.
Crear objeto
Los objetos se pueden crear en Python a través de clases. Las clases son plantillas para objetos y contienen las propiedades y métodos de los objetos.
Definir una clase:
class Cat:
def __init__(self, name, age):
self.name = name
self.age = age
def meow(self):
print("喵喵喵")
tom = Cat("汤姆", 3)
tom.meow()
La programación orientada a objetos puede mejorar la encapsulación, la herencia y la mantenibilidad del código. Es necesario cambiar la forma de pensar en programación, centrándose principalmente en el diseño de objetos y clases.
Resumir
Este artículo proporciona una introducción completa a conceptos y técnicas clave para la carga de páginas web, el procesamiento y el almacenamiento de datos. Tanto si eres principiante como si eres un desarrollador experimentado, puedes beneficiarte mucho de él. Al dominar estas habilidades, los lectores pueden recopilar y procesar datos de red de manera más efectiva, brindando un sólido soporte para diversos escenarios de aplicaciones. Ya sea que esté realizando análisis de datos, recopilación de información o desarrollo de sitios web, este artículo proporciona conocimientos básicos importantes y consejos prácticos. Espero que los lectores puedan aprender, practicar activamente y mejorar continuamente sus habilidades.
Declaración especial: ¡
este tutorial es puramente técnico! ¡Este tutorial no pretende de ninguna manera brindar soporte técnico a aquellos con malas intenciones! ¡Tampoco asumimos ninguna responsabilidad conjunta derivada del mal uso de la tecnología! El propósito de este tutorial es registrar y compartir el proceso de aprendizaje de tecnología.