Prefacio
La red de filtrado de texto e imágenes de este artículo se puede utilizar para el aprendizaje, la comunicación y no tiene ningún uso comercial. Si tiene alguna pregunta, comuníquese con nosotros para procesarla.
Este artículo utiliza el marco de rastreo de Python scrapy para recopilar algunos datos del sitio web.
El rastreador de Python, el análisis de datos, el desarrollo de sitios web y otros videos tutoriales de casos son gratuitos para ver en línea
https://www.xin3721.com/eschool/pythonxin3721/
Entorno de desarrollo básico
Python 3.6
pycharm
cómo instalar scrapy
Pip install scrapy se puede instalar en la línea de comando cmd. Pero, en general, habrá tiempos de espera de red.
Se recomienda cambiar la fuente convencional doméstica para instalar pip install -i nombre del paquete de direcciones convencionales domésticas
P.ej:
pip install -i https://mirrors.aliyun.com/pypi/simple/ scrapy
Direcciones de alias de fuente doméstica de uso común:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
Puede recibir errores:
Puede encontrar errores como VC ++ durante la instalación de Scrapy, puede instalar paquetes fuera de línea que eliminan módulos

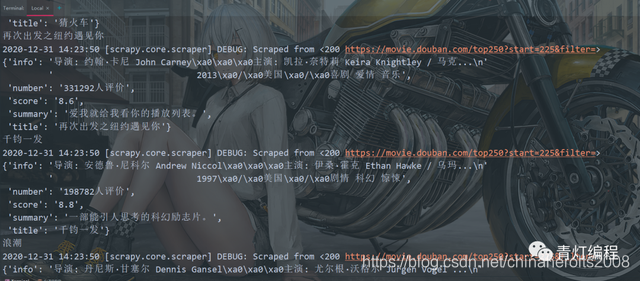
Cómo Scrapy rastrea los datos del sitio web
Este artículo utiliza los datos de Douban Movie Top250 como ejemplo para explicar el proceso básico del marco scrapy para rastrear datos.
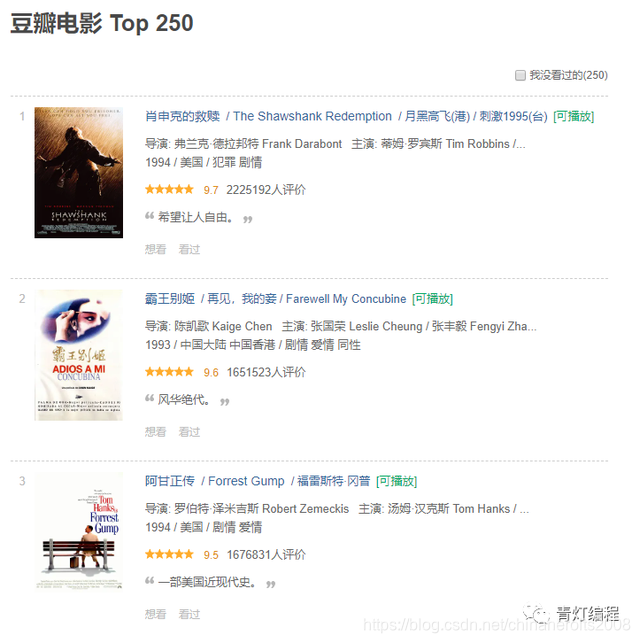
Los datos de Douban Top250 no se analizan demasiado. Los sitios web estáticos y las estructuras de páginas web son muy adecuadas para escribir y rastrear. Por lo tanto, muchos casos básicos de rastreadores se basan en datos de películas de Douban y de películas de Maoyan.
Proceso de creación del proyecto de rastreador de Scrapy
1. Cree un proyecto de rastreador
Seleccione Terminal en Pycharm e ingrese al tutorial básico de Python en Local
scrapy startproject + (nombre del proyecto <unique>)

2.cd para cambiar al directorio del proyecto del rastreador
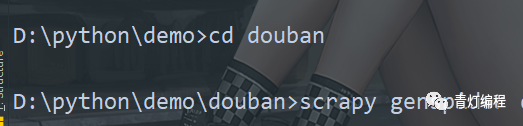
3. Cree un archivo rastreador
scrapy genspider (+ nombre de archivo del rastreador <único>) (+ restricción de nombre de dominio)

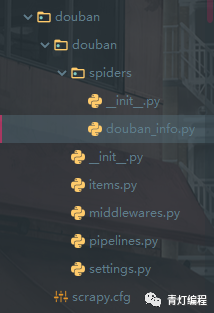
Esto completa la creación de proyectos scrapy y la creación de archivos rastreadores.
Escritura del código del rastreador scrapy
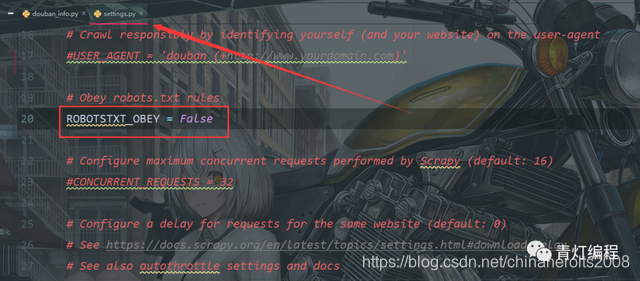
1, desactive el protocolo de robots en el archivo settings.py, el valor predeterminado es True
2. Modifique la URL de inicio en el archivo del rastreador.
start_urls = ['https://movie.douban.com/top250?filter=']
Cambie start_urls por el enlace de la URL de navegación de Douban, que es la dirección URL de la primera página donde rastrea los datos del tutorial de c #
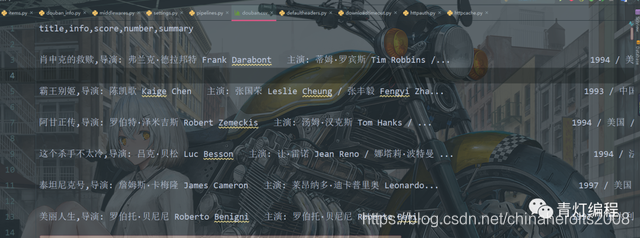
3. Escriba la lógica empresarial para analizar los datos.
El contenido de rastreo es el siguiente:

douban_info.py
import scrapy
from ..items import DoubanItem
class DoubanInfoSpider(scrapy.Spider):
name = 'douban_info'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250?start=0&filter=']
def parse(self, response):
lis = response.css('.grid_view li')
print(lis)
for li in lis:
title = li.css('.hd span:nth-child(1)::text').get()
movie_info = li.css('.bd p::text').getall()
info = ''.join(movie_info).strip()
score = li.css('.rating_num::text').get()
number = li.css('.star span:nth-child(4)::text').get()
summary = li.css('.inq::text').get()
print(title)
yield DoubanItem(title=title, info=info, score=score, number=number, summary=summary)
href = response.css('#content .next a::attr(href)').get()
if href:
next_url = 'https://movie.douban.com/top250' + href
yield scrapy.Request(url=next_url, callback=self.parse)
itmes.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
info = scrapy.Field()
score = scrapy.Field()
number = scrapy.Field()
summary = scrapy.Field()
middlewares.py
import faker
def get_cookies():
"""获取cookies的函数"""
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
response = requests.get(url='https://movie.douban.com/top250?start=0&filter=',
headers=headers)
return response.cookies.get_dict()
def get_proxies():
"""代理请求的函数"""
proxy_data = requests.get(url='http://127.0.0.1:5000/get/').json()
return proxy_data['proxy']
class HeadersDownloaderMiddleware:
"""headers中间件"""
def process_request(self, request, spider):
# 可以拿到请求体
fake = faker.Faker()
# request.headers 拿到请求头, 请求头是一个字典
request.headers.update(
{
'user-agent': fake.user_agent(),
}
)
return None
class CookieDownloaderMiddleware:
"""cookie中间件"""
def process_request(self, request, spider):
# request.cookies 设置请求的cookies, 是字典
# get_cookies() 调用获取cookies的方法
request.cookies.update(get_cookies())
return None
class ProxyDownloaderMiddleware:
"""代理中间件"""
def process_request(self, request, spider):
# 获取请求的 meta , 字典
request.meta['proxy'] = get_proxies()
return None
pipelines.py
import csv
class DoubanPipeline:
def __init__(self):
self.file = open('douban.csv', mode='a', encoding='utf-8', newline='')
self.csv_file = csv.DictWriter(self.file, fieldnames=['title', 'info', 'score', 'number', 'summary'])
self.csv_file.writeheader()
def process_item(self, item, spider):
dit = dict(item)
dit['info'] = dit['info'].replace('\n', "").strip()
self.csv_file.writerow(dit)
return item
def spider_closed(self, spider) -> None:
self.file.close()
setting.py
# Scrapy settings for douban project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'douban'
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'douban.middlewares.DoubanSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.HeadersDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
4. Ejecute el programa tutorial crawler vb.net

Ingrese el comando scrapy crawl + nombre de archivo del rastreador