본질적으로 피크 클리핑은 "데이터베이스에 최종적으로 도달하는 요청 수는 최대한 작아야 한다"는 원칙에 따라 사용자 요청을 더 지연시키고 사용자 액세스 요구 사항을 계층별로 필터링하는 것을 의미합니다.
1. 메시지 큐는 피크 클리핑을 해결합니다.
트래픽 피크를 줄이기 위해 생각하기 가장 쉬운 솔루션은 메시지 대기열을 사용하여 순간 트래픽을 버퍼링하고, 동기식 직접 호출을 비동기식 간접 푸시로 변환하고, 중간에 있는 큐를 사용하여 한쪽 끝에서 순간 트래픽 피크를 흡수하고 이를 평활화하는 것입니다. 다른 쪽 끝 메시지를 밀어냅니다.
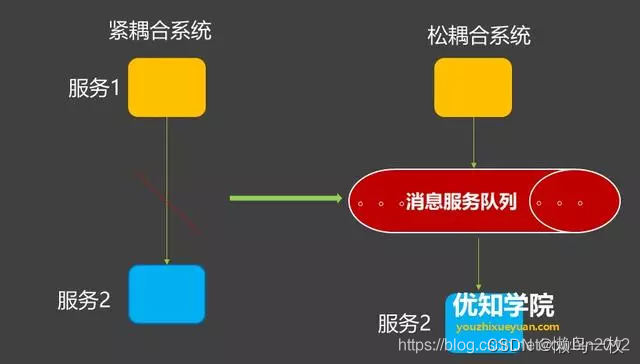
메시지 큐 미들웨어는 주로 애플리케이션 결합, 비동기 메시지, 트래픽 절감과 같은 문제를 해결합니다. 일반적으로 사용되는 메시지 대기열 시스템: 현재 프로덕션 환경에서 가장 일반적으로 사용되는 메시지 대기열에는 ActiveMQ, RabbitMQ, ZeroMQ, Kafka, MetaMQ, RocketMQ 등이 있습니다.
여기서 메시지큐는 상류에서는 홍수를 가두어 하류로 유입되는 최대유량을 줄여 홍수재난을 줄이는 목적을 달성하는 '저수지'와 같다.
2. 트래픽 피크 저감 깔때기: 계층별 피크 저감
반짝 세일 시나리오의 또 다른 방법은 계층화된 요청 필터링을 수행하여 일부 유효하지 않은 요청을 필터링하는 것입니다.
계층적 필터링은 아래 그림과 같이 요청을 처리하기 위해 실제로 "깔때기" 디자인을 사용합니다. 이는

깔때기와 비슷하며, 계층별로 데이터 및 요청의 양을 필터링하고 줄이려고 합니다.
1) 계층적 필터링의 핵심 아이디어
다양한 수준에서 유효하지 않은 요청을 최대한 필터링합니다.
CDN을 통해 수많은 사진과 정적 리소스 요청을 필터링합니다.
그런 다음 Redis와 같은 분산 캐시를 통해 요청을 필터링하는 것이 읽기 요청 업스트림을 가로채는 일반적인 예입니다.
2) 계층적 필터링의 기본원리
시간을 기준으로 쓰기 데이터를 합리적으로 조각화하고 만료된 잘못된 요청을 필터링합니다.
쓰기 요청에 대해 전류 제한 보호를 제공하고 시스템의 처리 용량을 초과하는 요청을 필터링합니다.
해당 읽기 데이터는 강력한 일관성 검증을 거치지 않으므로 일관성 검증으로 인해 발생하는 병목 현상이 줄어듭니다.
작성된 데이터에 대해 강력한 일관성 검증을 수행하고 마지막으로 유효한 데이터만 보관합니다.
결국 유효한 요청은 "퍼널"(데이터베이스) 끝에 있는 요청입니다. 예: 사용자가 실제로 주문에 도달한 경우
주문 및 결제 프로세스에는 강력한 데이터 일관성이 필요합니다.
요약하다
1. 플래시 세일과 같은 동시성이 높은 시나리오 비즈니스의 경우 가장 기본적인 원칙은 시스템 업스트림 요청을 차단하여 다운스트림 압력을 줄이는 것입니다. 프런트 엔드에서 가로채지 못하면 데이터베이스(mysql, oracle 등)에서 읽기-쓰기 잠금 충돌이 발생하고 심지어 교착 상태로 이어질 가능성이 높으며 궁극적으로 눈사태와 같은 시나리오가 발생할 수 있습니다.
2. 동적 자원과 정적 자원을 구분하고, 정적 자원의 서비스 배포를 위해 CDN을 사용합니다.
3. 캐시(redis 등)를 최대한 활용합니다. QPS를 늘려 전체 클러스터의 처리량을 늘립니다.
4. 높은 피크 트래픽은 시스템을 압도하는 중요한 이유이므로 Kafka와 같은 메시지 대기열은 한쪽 끝에서 순간적인 트래픽 피크를 처리하고 다른 쪽 끝에서 메시지를 원활하게 푸시해야 합니다.