Etapa 10: Resumen del tema (Capítulo 6: Almacenamiento en caché)
- Capítulo 6: Almacenamiento en caché
-
- == 1. Tipo de datos de Redis ==
- == 2. Problema con el comando de teclas ==
- == 3. Estrategia de eliminación de claves caducadas ==
- == 4. Persistencia de Redis ==
- == 5. Problema de almacenamiento en caché ==
- == 6. Atomicidad del caché ==
- == 7. Implementación de LRU Cache (estrategia de eliminación) ==
Capítulo 6: Almacenamiento en caché
1. Tipo de datos de Redis
Requerir
- Domine la estructura subyacente de los tipos de datos comunes
Descripción general
El tipo de datos en realidad describe el tipo de valor. Las claves son todas cadenas. Los tipos de datos comunes (valor) incluyen
- (cadena)cadena(embstr、raw、int)
- (lista) lista (lista rápida, compuesta por múltiples listas ziplist doblemente enlazadas)
- (Tabla de picadillo)hash(ziplist、hashtable)
- (Los elementos de la colección no se pueden repetir.) establecer (intset, tabla hash)
- (Ordenado según el conjunto) conjunto ordenado (ziplist, skiplist)
- (No se usa mucho, solo para estadísticas.)mapa de bits
- (No se usa mucho, solo para estadísticas.)hiperloglog
Cada tipo está representado por la estructura redisObject y cada tipo tiene una codificación diferente (es decir, una estructura de datos subyacente) según la situación.
Cadena
-
Si la cadena almacena un valor entero, la codificación subyacente es
int(4 bytes) y en realidad se usa larga (8 bytes) para el almacenamiento.Ventajas: ① Los números ocupan poco espacio; ② Es conveniente realizar cálculos de datos y no es necesario convertir caracteres en números para realizar cálculos;
-
Si la cadena almacena un valor no entero (un número de coma flotante u otro carácter), existen dos situaciones:
- Longitud <= 39 bytes, use
embstrcodificación para guardar, es decir, guarde las estructuras redisObject y sdshdr juntas, asigne memoria solo una vez - Longitud> 39 bytes, use
rawcodificación para guardar, es decir, la estructura redisObject asigna memoria una vez y la estructura sdshdr asigna memoria una vez y está conectada con punteros
- Longitud <= 39 bytes, use
-
sdshdr se llama cadena dinámica simple, la implementación es algo similar a StringBuilder en java, con las siguientes características
- Almacenar la longitud de los caracteres por separado, que es más eficiente para obtener longitud que char* (char* es la representación de cadena nativa del lenguaje C)
- Admite expansión dinámica para facilitar las operaciones de empalme de cadenas
- Reserve espacio para reducir la asignación de memoria y los tiempos de liberación(Cuando < 1 M, la capacidad es 2 veces la longitud real de la cadena; cuando >= 1 M, la capacidad es la capacidad original + 1 M)
- seguridad binariaPor ejemplo, el char* tradicional usa \0 como carácter final, por lo que los datos binarios como videos e imágenes no se pueden guardar, mientras que sds lee por longitud.
Lista
Pregunta de la entrevista: la diferencia entre lista rápida y lista zip
-
3.2 Inicio,Redis utiliza una lista rápida (lista enlazada grande) como método de codificación. Es una lista enlazada bidireccional y el elemento del nodo es ziplist (lista enlazada pequeña, en la que se almacenan los datos).
- Debido a que es una lista vinculada, no es continua en la memoria.
- La eficiencia de operar la cabeza y la cola es alta , la complejidad del tiempo es O (1) y la complejidad del tiempo promedio para operar otras partes es O (n)
- Se puede configurar el tamaño y la cantidad de elementos de la lista zip en la lista vinculada, y el tamaño predeterminado es 8 kb.
-
ziplist utiliza una pieza continua de memoria para almacenar datos. El objetivo del diseño es permitirEl almacenamiento de datos es más compacto, lo que reduce la sobrecarga de fragmentación y ahorra memoria., su estructura (simplemente entiéndalo) es la siguiente
- zlbytes: registra el número de bytes ocupados por toda la lista zip
- zltail-offset: registra el desplazamiento del nodo de cola
- zllength: registra el número de nodos
- entrada - nodo, 1 ~ N, cada entrada registra la longitud de la entrada anterior (para recorrido en orden inverso), la codificación, la longitud y los datos reales de esta entrada. Para ahorrar memoria, las palabras utilizadas para registrar la longitud son diferente según la longitud real de los datos . El número de secciones también es diferente . Por ejemplo, cuando la longitud de la entrada anterior es 253, se necesita 1 byte, pero si excede 253, se necesitan 5 bytes.
- zlend – etiqueta final
-
ziplist es adecuado para almacenar una pequeña cantidad de elementos; de lo contrario, la eficiencia de la consulta no es alta y el diseño de longitud variable provocará problemas de actualización de la cadena
Picadillo
-
Cuando la cantidad de datos es pequeña, se utiliza ziplist como codificación (el valor clave se trata como dos entradas consecutivas). Cuando la longitud de la clave o el valor es demasiado grande (64) o el número es demasiado grande (512), se convierte a codificación de tabla hash.
-
codificación de tabla hash[Los siguientes son todos puntos clave, por lo que no los señalaré]
-
Función hash, Redis 5.0 usa el algoritmo SipHash
-
Utilice el método de cremallera para resolver conflictos clave (resolver conflictos hash)
-
tiempo de repetición
① Cuando el número de elementos <1 * el número de depósitos, no se requiere expansión
② Cuando el número de elementos > 5 * el número de cubos, se debe ampliar la capacidad
③ Cuando 1 * número de depósitos <= número de elementos <= 5 * número de depósitos, si no se realiza ninguna operación AOF o RDB en este momento, se realizará un refrito
④ Cuando la cantidad de elementos <la cantidad de depósitos / 10, reduzca el tamaño
-
repetir los puntos clave
① Cada diccionario tiene dos tablas hash y el número de depósitos es 2 n 2^n2n , generalmente se usa ht[0], ht[1] es nulo al principio y, al expandirse, el nuevo tamaño de la matriz es el número de elementos * 2
② Repetición progresiva (para evitar que un tiempo sea demasiado largo), es decir, no todos los depósitos se migran a la vez, pero solo se migra un depósito a esta tabla CRUD cada vez.
③ repetición activa (activa) , en el bucle principal del servidor, reserve 1 s cada 100 ms para la migración activa
④ Durante el proceso de repetición, se agrega una nueva operación ht[1] y otras operaciones operan primero ht[0], si no, entonces se opera ht[1]
⑤ Todos los CRUD en redis son de un solo subproceso, por lo que el refrito debe ser seguro para subprocesos.
-
Conjunto ordenado
-
Cuando la cantidad de datos es pequeña, se utiliza ziplist como codificación y se ordena por puntuación. Cuando la longitud de la clave o el valor es demasiado grande (64) o el número es demasiado grande (128), se convierte a skiplist + codificación de tabla hash., la razón para adoptar ambos es
- Al usar solo la tabla hash, CRUD es O (1), pero para realizar operaciones ordenadas, se requiere clasificación, lo que genera complejidad adicional de tiempo y espacio.
- Solo usando skiplist, aunque se conservan las ventajas de las operaciones de rango, aumenta la complejidad del tiempo.
- Aunque se utilizan dos estructuras al mismo tiempo, debido al uso de punteros, los elementos no ocupan doble memoria.
-
Puntos clave de skiplist : lista vinculada de varios niveles, reglas de clasificación, hacia atrás, nivel (intervalo, avance)
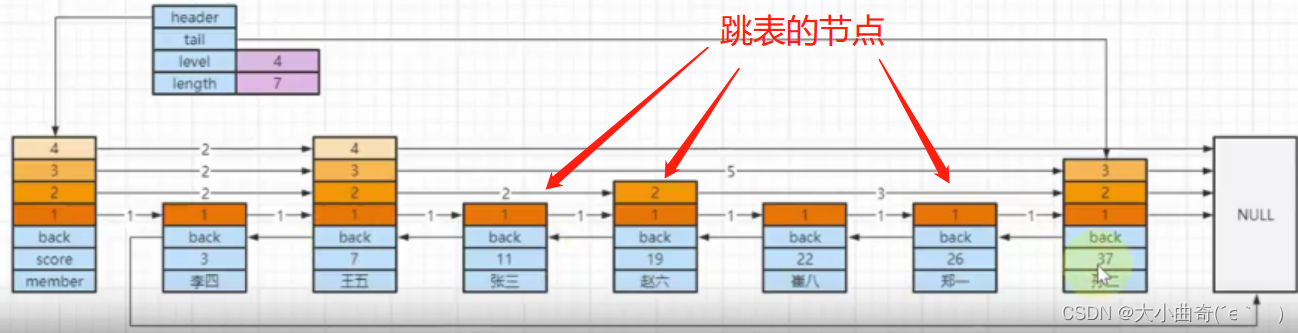
- puntuación almacena puntuaciones, miembros almacena datos,Ordenar por puntuación, si las puntuaciones son las mismas entonces ordenar por miembro
- hacia atrás almacena el puntero del nodo anterior (conveniente para recorrido inverso)
- Cada nodo almacena información de nivel (nivel), el mismo nodo puede tener varios niveles y cada nivel tiene atributos:
- puntero de avance al siguiente nodo en la misma capa (puntero de avance, conveniente para recorrido de orden positivo)
- span se utiliza para calcular clasificaciones. No todas las tablas de salto implementan span. Es exclusivo de la implementación de Redis.
-
Las listas vinculadas de varios niveles pueden acelerar las consultas y reducir la cantidad de consultas, la regla es, comenzando desde arriba
-
Si es más grande que el del lado derecho de la misma capa, continúa mirando hacia la derecha en la misma capa.
-
igualmente encontrado
-
Menos que el lado derecho de la misma capa o el lado derecho es NULL, vaya a la siguiente capa y repita los pasos 1 y 2.
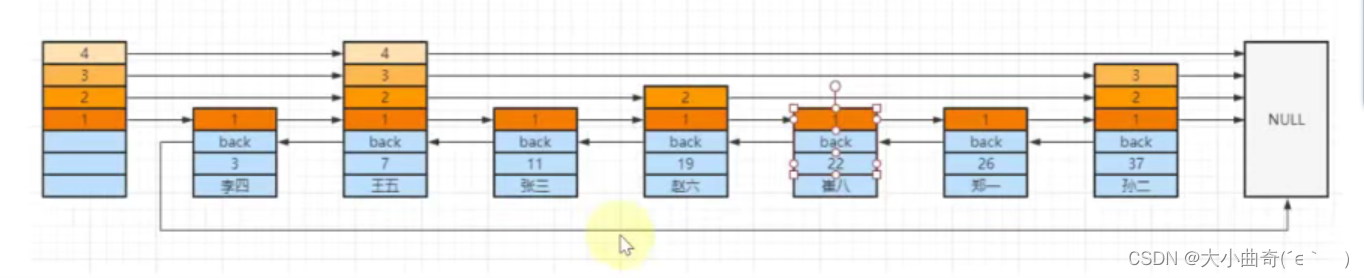
-
- Tomemos como ejemplo la búsqueda de [Cui Ba]
- Busque el nodo [王五] de la capa superior (4) a la derecha, 22 > 7 y continúe hacia la derecha, pero el lado derecho es NULL, la siguiente capa
- Encuentre el nodo [Sun Er] en la tercera capa a la derecha del nodo [王五], 22 <37, la siguiente capa
- En la segunda capa del nodo [Wang Wu], vaya a la derecha para encontrar el nodo [Zhao Liu], 22 > 19, continúe hacia la derecha para encontrar el nodo [Sun Er], 22 < 37, la siguiente capa
- Encuentre el nodo [Cui Ba] en la primera capa del nodo [Zhao Liu] a la derecha, 22 = 22, regrese
Aviso
- Cuando la cantidad de datos es pequeña, la mejora del rendimiento de la tabla de omisión no se puede reflejar. La complejidad temporal de la consulta de la tabla de omisión es log 2 (N) log_2 (N)iniciar sesión _2( N ) , equivalente al rendimiento del árbol binario
2. Problema de comando de teclas
Pregunta de la entrevista: Redis tiene 100 millones de claves. ¿El uso del comando de claves afectará los servicios en línea?
Requerir
- Comprender el impacto de los comandos ineficientes en Redis de un solo subproceso
Descripción del problema
- Redis tiene 100 millones de claves. ¿El uso del comando de claves afectará los servicios en línea?
respuesta
- La complejidad temporal del comando de teclas es O ( n ) O (n)O ( n ) , n es el número total de claves, si n es grande, el rendimiento será muy bajo
- El comando de ejecución de Redis se ejecuta en un solo hilo. Si un comando se ejecuta demasiado lento, bloqueará otros comandos. Un tiempo de bloqueo prolongado puede incluso provocar una conmutación por error de Redis.
Plan de mejora【Importante】
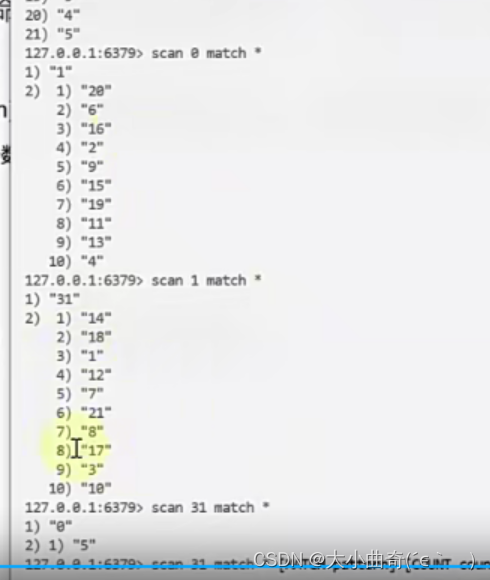
- Puede utilizar el comando
scande sustitución de comandoskeys, la sintaxisscan 起始游标 match 匹配规则 count 提示数目y el valor de retorno para representar el siguiente punto de partida.- Aunque la complejidad temporal del comando de escaneo sigue siendo O ( n ) O (n)O ( n ) , pero se ejecuta paso a paso a través del cursor y no provoca un bloqueo prolongado.
- Puede utilizar el parámetro de recuento para solicitar el número de claves devueltas (el valor predeterminado es 10)
- El valor de retorno representa el siguiente punto de partida (subíndice del depósito)
- Estado débil, el cliente solo necesita mantener el cursor
- el escaneo puede garantizar que el refrito también funcione normalmente
- La desventaja es que las claves se pueden recorrer repetidamente (cuando se reducen) y la aplicación debe manejar las claves repetidas por sí misma.
3. Estrategia de eliminación de claves caducadas
Requerir
- Comprenda cómo Redis registra el tiempo de vencimiento de la clave
- La estrategia de eliminación de Master Redis para claves caducadas
Registrar el tiempo de vencimiento de la clave
- Cada biblioteca contieneexpira expira diccionario
- Estructura de tabla hash, la clave es un puntero que apunta a la clave real, el valor es una marca de tiempo de tipo largo, precisión de milisegundos
- Cuando se configura una clave para que tenga una hora de caducidad, el puntero y la marca de tiempo de esta clave se agregarán al diccionario de caducidad.
Estrategia de eliminación de clave caducada
-
Eliminación perezosa
- Al ejecutar un comando para leer o escribir una base de datos, verificará si la clave ha caducado antes de ejecutar el comando, si ha caducado, la clave se eliminará.
-
Eliminar regularmente
-
Redis tiene un servidor de procesador de tareas programadoCron, que es responsable del procesamiento periódico de tareas. Se ejecuta una vez cada 100 ms de forma predeterminada (control de parámetros hz), que incluye: ① procesamiento de claves caducadas, ② repetición de la tabla hash, ③ actualización de resultados estadísticos, ④ persistencia , ⑤ final de la limpieza de clientes caducados
-
Para procesar claves caducadas: recorra la biblioteca en secuencia y ejecute las siguientes operaciones dentro del tiempo especificado (predeterminado 2,5 ms) (elimine un poco cada vez)
① Seleccione aleatoriamente 20 claves del diccionario de caducidad de cada biblioteca para verificarlas y elimínelas si están caducadas.
② Si la eliminación llega a 5, repita el paso ①. Si no se alcanza, pase a la siguiente biblioteca.
③ Si el trabajo no se completa dentro del tiempo especificado, espere la siguiente ronda de operación serverCron.
-
4. Persistencia de Redis
Requerir
- Dominar la persistencia de AOF y la reescritura de AOF
- Persistencia RDB maestra
- Más información sobre la persistencia híbrida
Persistencia AOF
- AOF -Agregue cada comando de escritura al archivo aof . Al reiniciar, se ejecutará cada comando en el archivo aof para reconstruir los datos de la memoria.
- El registro AOF es un registro posterior a la escritura , es decir, el comando se ejecuta primero y luego se registra el registro.
- Redis para rendimiento,No hay verificación de sintaxis en el comando al iniciar sesión en aof. Si el registro se registra primero, los comandos con errores de sintaxis se registrarán en el registro.
- Hay tres estrategias de sincronización al grabar registros AOF
AlwaysEscritura sincrónica [alta seguridad, bajo rendimiento], el registro se escribe en el disco y luego se devuelve, básicamente no se pierden datos, pero el rendimiento no es alto- ¿Por qué básicamente no se pierde? Debido a que aof está escrito en el bucle de eventos serverCron, y lo que se escribe esta vez son los datos almacenados temporalmente en el búfer aof en el ciclo anterior, por lo que aún se puede perder como máximo un ciclo de datos.
EverysecEscriba cada segundo, el registro se escribe en el búfer de memoria del archivo AOF, los datos del búfer de memoria se vacían en el disco cada segundo y se pierden hasta un segundo de datos.NoEl sistema operativo escribe [alto rendimiento, baja seguridad], el registro se escribe en el búfer de memoria del archivo AOF y el sistema operativo decide cuándo vaciar los datos en el disco.
reescritura de AOF
- Para problemas causados por archivos AOF que son demasiado grandes
- El tamaño del archivo está limitado por el sistema operativo.
- El archivo es demasiado grande y la eficiencia de escritura disminuye.
- El archivo es demasiado grande y la recuperación es muy lenta
- Reescribir es reducir múltiples operaciones en la misma clave.
- Por ejemplo, si cambio una clave 100 veces, se registran 100 registros de modificación en el aof, pero en realidad solo el último es válido.
- La reescritura no requiere operar el registro aof existente, solo necesita generar el comando correspondiente según el estado actual de los datos de la memoria y registrarlo en un nuevo archivo de registro.
- El proceso de reescritura se completa con otro subproceso en segundo plano y no bloquea el proceso principal.
- Proceso de reescritura de AOF
- Al crear un subproceso, se generará una instantánea de la memoria (que registra el estado actual) en función del proceso principal. Solo necesita recorrer la memoria del subproceso y escribir el comando correspondiente a cada clave en un nuevo archivo de registro. (es decir, reescribir el registro).
- Si se ejecuta un nuevo comando en este momento, la memoria del proceso principal se modificará y no afectará la memoria del proceso secundario, y el nuevo comando se registrará.
重写缓冲区 - Espere hasta que se procesen todas las claves del proceso secundario y luego
重写缓冲区escriba las instrucciones incrementales grabadas en el registro de reescritura. - Durante este período, el antiguo registro AOF todavía está funcionando. Cuando se complete la reescritura, el antiguo registro AOF será reemplazado por el registro de reescritura.
persistencia de RDB
- RDB: escribe todos los datos de la memoria en el disco en formato binario
- El archivo de datos correspondiente es
dump.rdb - La ventaja es que la recuperación es rápida.
- El archivo de datos correspondiente es
- Hay dos comandos relacionados
- guardar: ejecutado en el proceso principal, bloqueará otros comandos
bgsave- Crear un subproceso para su ejecución para evitar el bloqueo, que es el método predeterminado- El proceso hijo no bloqueará el proceso principal, pero aún así se bloqueará durante la creación del proceso hijo. Cuanto mayor sea la memoria, mayor será el tiempo de bloqueo.
- bgsave también utiliza el mecanismo de instantánea: si se escriben datos nuevos durante la persistencia de RDB, la modificación de nuevos datos ocurre en el proceso principal y el proceso secundario escribe los datos antiguos en el archivo RDB, de modo que la nueva modificación no afectará a RDB. funcionar
- Pero estos nuevos datos no se agregarán al archivo RDB [Si hay cambios durante la copia de seguridad, la información se perderá si la máquina deja de funcionar durante la siguiente copia de seguridad]
- Desventajas : Puede controlar el ciclo de ejecución de rdb ajustando el parámetro de guardar en redis.conf, pero este ciclo es difícil de comprender.
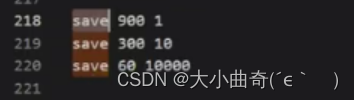
- Si se ejecuta con frecuencia, el rendimiento se verá afectado.
- Si se ejecuta ocasionalmente, se perderán más datos fácilmente si la máquina falla.
Persistencia híbrida
- A partir de 4.0, Redis admite la persistencia híbrida, es decir, usar RDB como copia de seguridad completa y AOF como copia de seguridad incremental entre dos RDB.
- Elemento de configuración
aof-use-rdb-preambleutilizado para controlar si se habilita la persistencia híbrida, el valor predeterminado es no - Durante la persistencia, todos los datos se almacenan en el registro AOF. La primera mitad del registro está en formato RDB binario y la segunda mitad es el registro de comandos AOF.
- La próxima vez que se ejecute RDB, se sobrescribirá el archivo de registro anterior.
- Elemento de configuración
- Ventajas y desventajas
- Combina las ventajas de RDB y AOF, con una velocidad de recuperación rápida, incrementos representados por AOF, datos más completos (según la estrategia de sincronización) y sin necesidad de reescribir AOF.
- Incompatible con versiones anteriores del formato de archivo redis
5. Problemas de almacenamiento en caché
Requerir
- Penetración de caché maestra
- Dominar la avalancha de caché
- Penetración de caché maestra
- Omisión maestra de caché y coherencia de caché
Desglose de caché
-
El desglose de la caché se refiere a :Existe una determinada clave de punto de acceso tanto en el caché como en la base de datos. Cuando caduca, debido a la gran cantidad de usuarios concurrentes, el caché no se lee al mismo tiempo y la base de datos se lee al mismo tiempo, lo que abruma la base de datos;
-
Solución
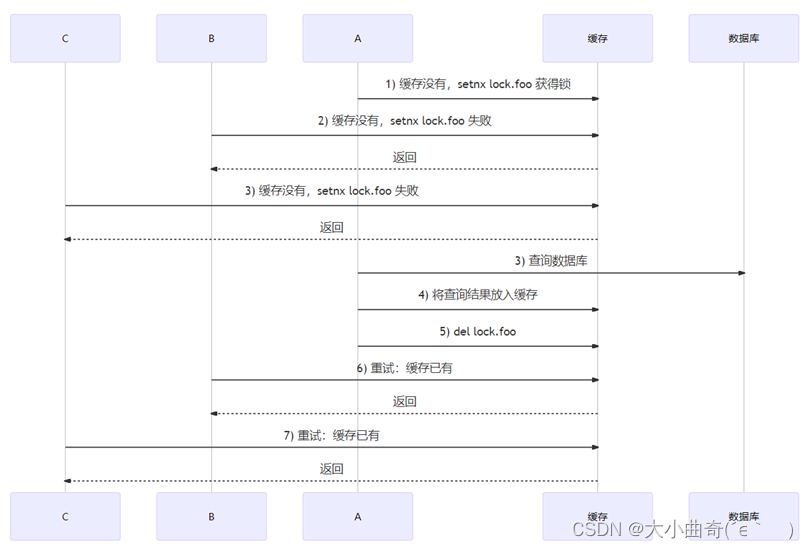
- Los datos del hotspot no caducan 【Recomendado】
- bien【No hay caché de consultas, consulte la base de datos y coloque los resultados en el caché.】 Estos tres pasos son para bloquear. En este momento, solo un cliente puede obtener el bloqueo y otros clientes serán bloqueados. Cuando se libera el bloqueo, el caché ya tiene datos y otros clientes no necesitan acceder a la base de datos. Pero afectará el rendimiento (solución con pérdidas)
avalancha de caché
-
Caso 1 :Dado que una gran cantidad de claves tienen el mismo tiempo de vencimiento establecido (los datos existen tanto en el caché como en la base de datos), una vez que se alcanza el tiempo de vencimiento, estas claves en conjunto dejan de ser válidas, lo que hace que todas las solicitudes de acceso a estas claves ingresen a la base de datos.
¿Bloquear una determinada llave puede solucionar la avalancha? :No -
Solución:
- Escalonar el tiempo de vencimiento: agregue un valor aleatorio al tiempo de vencimiento (como 1 ~ 5 minutos)
- Degradación del servicio: pausar la caché de consultas de datos no principales, devolver información predefinida (página de error, valor nulo, etc.) (solución con pérdida)
-
Caso 2 :La instancia de Redis falló y una gran cantidad de solicitudes ingresaron a la base de datos.
-
Solución:
- Precaución: Cree un clúster de alta disponibilidad
- Caché multinivel (construya un caché local): La desventaja es que la complejidad de la implementación es alta.
- Disyuntor: una vez que se produce una avalancha a través del monitoreo, el acceso a la caché se suspende hasta que se restablece la instancia y se devuelve información predefinida (solución con pérdidas)
- Limitación actual: una vez que el volumen de acceso a la base de datos excede el umbral a través del monitoreo, limite la cantidad de solicitudes para acceder a la base de datos (solución con pérdidas)
penetración de caché
-
La penetración de caché se refiere a:Si una clave no existe en el caché o en la base de datos, al acceder a la clave se ingresará a la base de datos cada vez.
- Probablemente sea explotado por solicitudes maliciosas
- La avalancha de caché y el desglose de caché están presentes en la base de datos, pero el caché falta temporalmente.
- Tanto la avalancha de caché como la penetración de caché pueden recuperarse de forma natural, pero la penetración de caché no.
-
Solución
-
Si la base de datos no tiene ninguna, el valor nulo asociado con esta clave inexistente también se colocará en la caché.,La desventaja es que dicha clave no tiene ninguna función comercial y ocupa espacio en vano.
-
filtro de floración(un complemento)
Agregar antes del caché y la base de datos
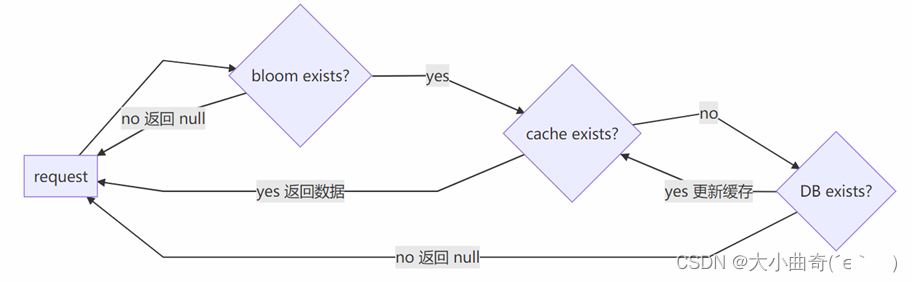
①Se pueden utilizar filtros para determinar si una clave no existe. Si encuentra estas claves inexistentes, simplemente filtrelas.
②Todas las claves deben estar precargadas en el filtro Bloom
③Los filtros Bloom no se pueden eliminar, por lo que los datos eliminados por la consulta definitivamente penetrarán(el filtro de cuco puede resolver esto) -
Problema de coherencia de la caché: omitir la caché
Omitir caché
-
Cache Aside es una estrategia común para usar el caché
-
Reglas de consulta
- Leer el primer caché
- Si lo golpean, regrese directamente
- Si falta, verifique la base de datos (base de datos), coloque el resultado en el caché y luego regrese
-
Agregar, eliminar y modificar reglas
- Agregar nuevos datos,Guardar directamente en la base de datos(base de datos)
- Modificar y eliminar datos,Primero actualice la base de datos (base de datos), luego elimine el caché[Eventualmente consistente, cuando los requisitos de coherencia de los datos no son altos, habrá inconsistencias temporales, pero eventualmente serán consistentes]
¿Por qué necesitamos operar primero la biblioteca y luego el caché?
- Supongamos que tanto la biblioteca de operaciones como el caché se pueden operar con éxito. Si el caché se opera primero, habrá una alta probabilidad de inconsistencia entre la base de datos y el caché.
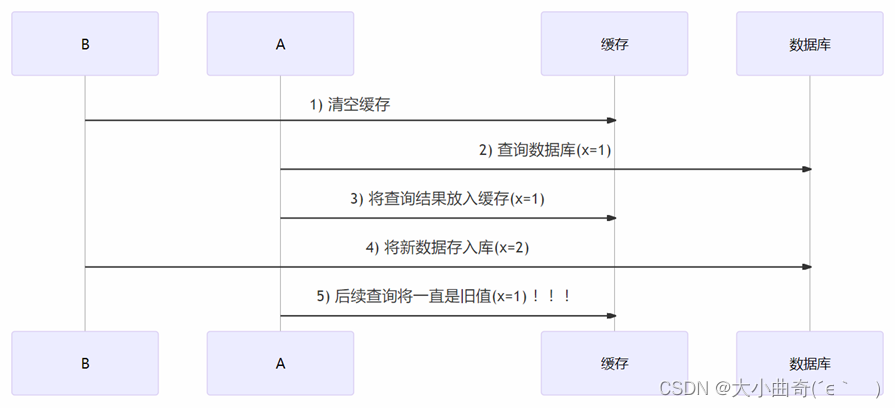
Análisis de coherencia: primero borre el caché y luego actualice la biblioteca
Análisis de coherencia: primero actualice la biblioteca y luego borre el caché
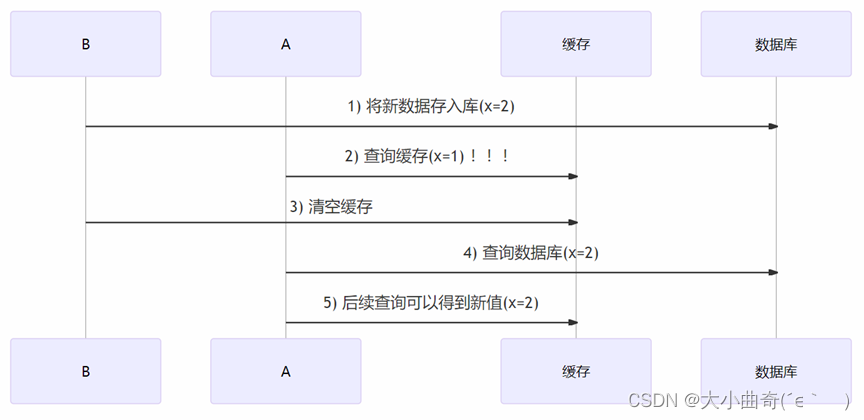
-
Habrá inconsistencias temporales, pero eventualmente serán consistentes.
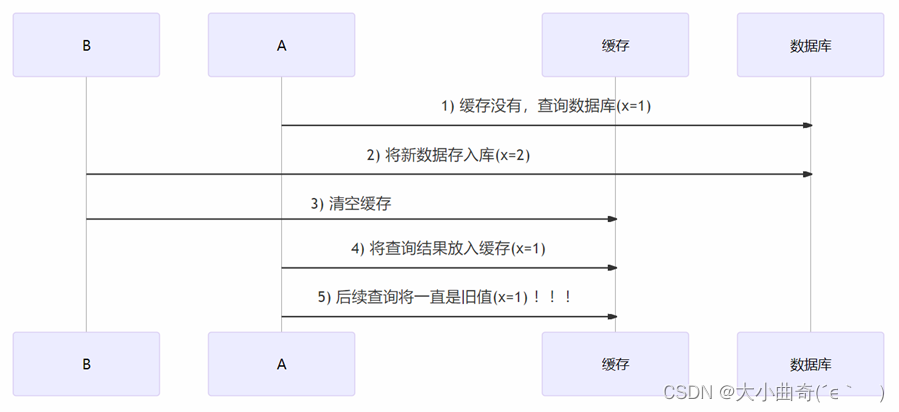
-
Suponiendo que cuando el hilo de consulta A consulta datos, los datos almacenados en caché dejan de ser válidos debido a la expiración del tiempo, o es la primera consulta, habrá inconsistencia como se muestra en la figura anterior, pero la posibilidad de que esto suceda es muy pequeña
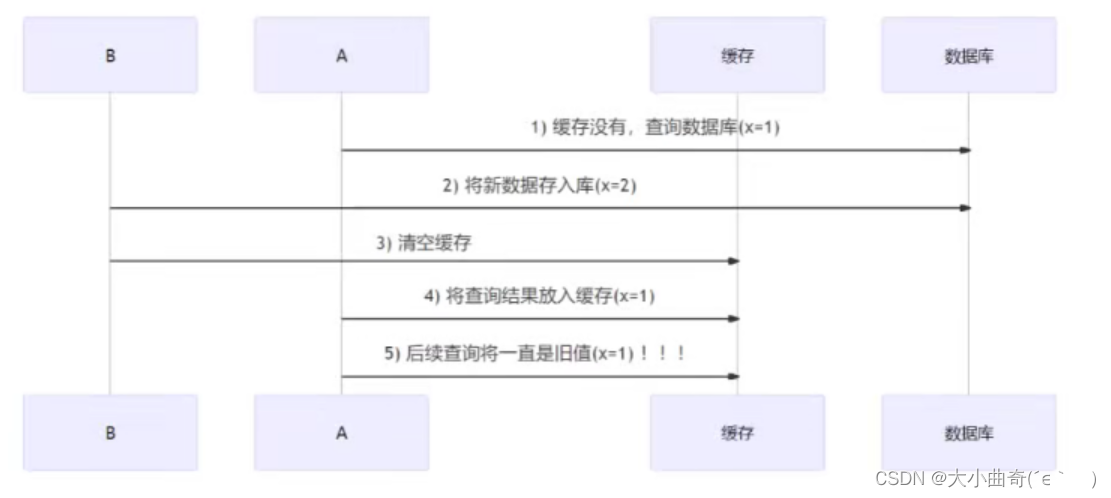
.
Utilice candados para resolver la coherencia.
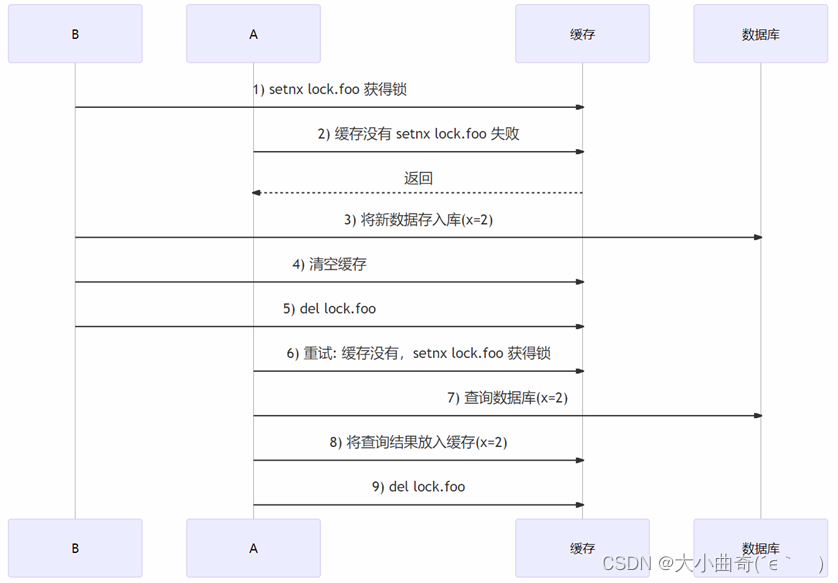
- Desventajas: afecta el rendimiento y el diseño de cerraduras distribuidas es más complejo
6. Atomicidad del caché
Requerir
- Comprender las limitaciones de las transacciones de Redis
- Comprender el uso del bloqueo optimista para garantizar la atomicidad
- Comprenda cómo utilizar los scripts Lua para garantizar la atomicidad
Limitaciones de las transacciones de Redis : no se admite la reversión
- Un solo comando es atómico., que está garantizado por un solo subproceso de redis
- ¿ Se pueden utilizar varios comandos
multi + execpara garantizar la atomicidad?
Redis multi + execno admite la reversión, por ejemplo, los datos iniciales son los siguientes
set a 1000
set b 1000
set c a
implementar
multi
decr a /*a减1*/
incr b /*b加1*/
incr c
exec
Al ejecutar incr c, este comando falló porque la cadena no admite el incremento automático.,peroLos dos comandos anteriores no se revertirán[ El resultado anterior es que los dos primeros comandos tienen éxito y el último comando falla; ]
Más importante,multi + execLa operación de lectura no tiene sentido.Debido a que el resultado de la lectura no se puede asignar a una variable temporal para operaciones de escritura posteriores, dado que multi + execleer no tiene sentido,No hay garantía de atomicidad de lectura + escritura (una transacción no puede controlar la lectura y la escritura al mismo tiempo), por ejemplo, los datos iniciales son los siguientes
set a 1000
set b 1000
Supongamos que a y b representan los saldos de dos cuentas, ahora obtenga los valores anteriores y realice la transferencia de 500:
get a /* 存入客户端临时变量 */
get b /* 存入客户端临时变量 */
/* 客户端计算出 a 和 b 更新后的值 */
multi
set a 500
set b 1500
exec
Pero si otros clientes modifican aob entre get y multi, la actualización se perderá.
El bloqueo optimista garantiza la atomicidad
watchComando para realizar un seguimiento de key(uno o más) si estos keyestán durante una transacción:
execSólo tendrá éxito si otros clientes no lo han modificado.- Si es modificado por otro cliente, será
execdevueltonil, asegurando así la atomicidad.
Igual que el ejemplo anterior
get a /* 存入客户端临时变量 */
get b /* 存入客户端临时变量 */
/* 客户端计算出 a 和 b 更新后的值 */
watch a b /* 盯住 a 和 b */
multi
set a 500
set b 1500
exec
En este momento, si otros clientes modifican los valores de ayb, exec devolverá nil y los dos comandos establecidos no se ejecutarán, en este momento el cliente puede volver a intentarlo.
El script Lua garantiza la atomicidad
Redis admite scripts Lua, lo que puede garantizar la atomicidad de la ejecución del script Lua y puede reemplazarmulti + exec
Por ejemplo, para resolver el problema anterior, puede ejecutar el siguiente comando
eval "local a = tonumber(redis.call('GET',KEYS[1]));local b = tonumber(redis.call('GET',KEYS[2]));local c = tonumber(ARGV[1]); if(a >= c) then redis.call('SET', KEYS[1], a-c); redis.call('SET', KEYS[2], b+c); return 1;else return 0; end" 2 a b 500
- eval se utiliza para ejecutar scripts lua
- 2 significa que entre los parámetros separados por espacios, los dos primeros son claves y el resto son parámetros ordinarios.
- En el script, puede utilizar
keys[n]para hacer referencia a la enésima clave yargv[n]al enésimo parámetro ordinario. - El que está dentro de las comillas dobles es el script lua, con el siguiente formato
local a = tonumber(redis.call('GET',KEYS[1]));//tonumber把字符串转换成数字
local b = tonumber(redis.call('GET',KEYS[2]));
local c = tonumber(ARGV[1]);
if(a >= c) then
redis.call('SET', KEYS[1], a-c);
redis.call('SET', KEYS[2], b+c);
return 1;
else
return 0;
end
7. Implementación de LRU Cache (estrategia de eliminación)
Requerir
- Domine la implementación de LRU Cache según la lista vinculada
- Comprender los cambios en la implementación de LRU Cache de Redis
Reglas de eliminación de caché LRU
Menos usado recientemente,Eliminar la clave utilizada menos recientemente del caché。
- Con el tiempo, los nuevos permanecen y los viejos se eliminan.
- Si se accede a una clave, se convierte en la última
Estrategia de implementación :
- En el método de lista vinculada , las claves a las que se accedió recientemente se mueven al principio de la lista vinculada, y las claves a las que se accede con poca frecuencia están naturalmente cerca del final de la lista vinculada. Si se excede la capacidad y el límite de número, las claves al final se remoto.
- Método de muestreo aleatorio (utilizado por Redis) . El método de lista enlazada ocupa más memoria. Redis utiliza el método de muestreo aleatorio. Solo se seleccionan 5 claves cada vez. Cada clave registra su último tiempo de acceso. Elija entre estas 5 claves. La más antigua eliminada
Tomando el método de la lista vinculada como ejemplo, las claves a las que se accedió recientemente se mueven al principio de la lista vinculada, y las claves a las que se accede con menos frecuencia están naturalmente más cerca del final de la lista vinculada. Si se excede la capacidad y el límite de número, el Las llaves al final se eliminan.
-
Por ejemplo, los datos originales son los siguientes y la capacidad se especifica como 3

-
En términos de tiempo los nuevos se quedan y los viejos se eliminan, por ejemplo si pones d entonces se elimina la a más antigua.

-
Si se accede a una clave, se convierte en la última, como obtener b, luego b se mueve al encabezado de la lista vinculada

Implementación de la lista vinculada de caché LRU (prueba de código)
- Cómo romper un enlace de nodo
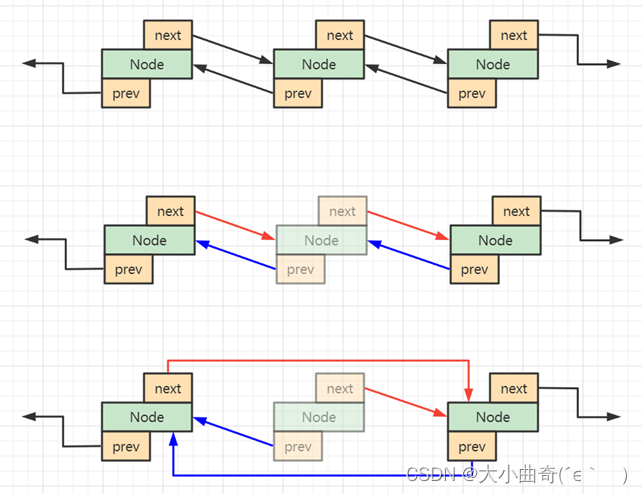
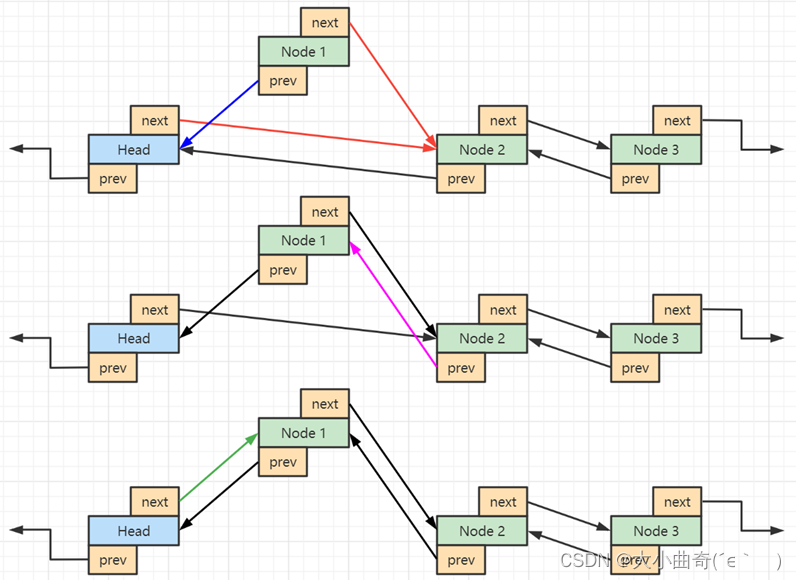
- Cómo vincularse al nodo principal
Código de referencia 1 : (Responder a este código refleja su comprensión de las listas vinculadas)
package day06;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class LruCache1 {
static class Node {
//节点的参数;
Node prev;
Node next;
String key;
Object value;
public Node(String key, Object value) {
this.key = key;
this.value = value;
}
// 打印节点的信息:node的toString(prev <- node -> next)
public String toString() {
StringBuilder sb = new StringBuilder(128);
sb.append("(");
sb.append(this.prev == null ? null : this.prev.key);
sb.append("<-");
sb.append(this.key);
sb.append("->");
sb.append(this.next == null ? null : this.next.key);
sb.append(")");
return sb.toString();
}
}
//断开节点链接的方法(删除一个节点)
public void unlink(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
//把新节点加入到head头结点之后
public void toHead(Node node) {
node.prev = this.head;
node.next = this.head.next;
this.head.next.prev = node;
this.head.next = node;
}
int limit; //元素上限,超出则删除较老的
Node head; //头结点
Node tail; //尾节点
Map<String, Node> map; //Map集合存放真正的键值,键存放key,值存放每个节点对象
//初始化上面的这些成员
public LruCache1(int limit) {
this.limit = Math.max(limit, 2); //通过参数传进来,最小值设置成2;
this.head = new Node("Head", null);
this.tail = new Node("Tail", null);
head.next = tail;//头结点尾结点相连;
tail.prev = head;//头结点尾结点相连;
this.map = new HashMap<>();//空Map
}
//删除逻辑
public void remove(String key) {
Node old = this.map.remove(key);//调用底层map的remove将key删掉;
unlink(old);//断开节点的连接
}
//查询逻辑
public Object get(String key) {
Node node = this.map.get(key);
if (node == null) {
//如果key在链表中没有
return null;
}
//如果key在链表中有,在链表中断开这个节点,并把它插入到头部;
unlink(node);
toHead(node);
return node.value;//返回值;
}
//新增逻辑;
public void put(String key, Object value) {
Node node = this.map.get(key); //先查一下这个key在链表中有没有
if (node == null) {
//没有
node = new Node(key, value); //创建一个新的节点;
this.map.put(key, node);//存入map;
} else {
//有
node.value = value;//更新一下值
unlink(node); //断开连接
}
toHead(node); //将节点移入头部
if(map.size() > limit) {
//看看当前map的大小是否超出了上限,如果超出了
Node last = this.tail.prev;//找到最后一个节点;
this.map.remove(last.key);//将最后一个节点删掉;
unlink(last); //链表中断开最后一个节点的链接;
}
}
@Override
//cache的toString
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.head);//拼接头结点
Node node = this.head;
while ((node = node.next) != null) {
//遍历链表;
sb.append(node);
}
return sb.toString();
}
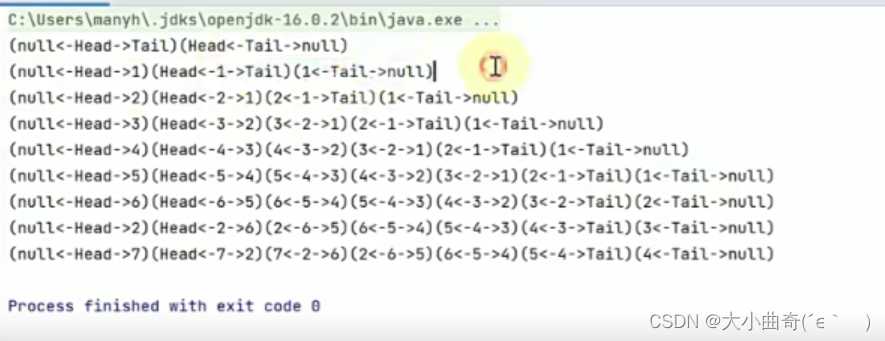
public static void main(String[] args) {
LruCache1 cache = new LruCache1(5); //创建 LruCache的实例,规定上限是5;
System.out.println(cache);
cache.put("1", 1);//添加元素
System.out.println(cache);
cache.put("2", 1);
System.out.println(cache);
cache.put("3", 1);
System.out.println(cache);
cache.put("4", 1);
System.out.println(cache);
cache.put("5", 1);
System.out.println(cache);
cache.put("6", 1);//此时将删除1结点
System.out.println(cache);
cache.get("2");//cache的get方法,此时2到达了头部
System.out.println(cache);
cache.put("7", 1);//cache的put方法,此时又将删除一个节点;
System.out.println(cache);
}
}
Código de referencia dos
Usar herencia de la clase padreLinkedHashMap
package day06;
import java.util.LinkedHashMap;
import java.util.Map;
public class LruCache2 extends LinkedHashMap<String, Object> {
private int limit; //作为元素个数的限制;
public LruCache2(int limit) {
// 1 2 3 4 false
// 1 3 4 2 true ,此时调用2,就把2调到了右侧头部;按访问顺序调整;
super(limit * 4 /3, 0.75f, true);//调用有参构造,参数:长度limit * 4 /3防止扩容,扩容因子,true
this.limit = limit;
}
@Override
//此方法把最老的键值对移除掉;返回true时则移除最老的
protected boolean removeEldestEntry(Map.Entry<String, Object> eldest) {
if (this.size() > this.limit) {
return true;
}
return false;
}
public static void main(String[] args) {
LruCache2 cache = new LruCache2(5);
System.out.println(cache);
cache.put("1", 1);
System.out.println(cache);
cache.put("2", 1);
System.out.println(cache);
cache.put("3", 1);
System.out.println(cache);
cache.put("4", 1);
System.out.println(cache);
cache.put("5", 1);
System.out.println(cache);
cache.put("6", 1);//此时由于新加了一个元素,超出了上限,会将最老的元素移除;
System.out.println(cache);
cache.get("2");
System.out.println(cache);
cache.put("7", 1);
System.out.println(cache);
}
}
Implementación de caché Redis LRU
Redis utiliza un método de muestreo aleatorio, que ocupa menos memoria que el método de lista vinculada. Solo se muestrean 5 claves cada vez. Cada clave registra su tiempo de acceso más reciente . Entre estas 5, se selecciona y elimina la más antigua.
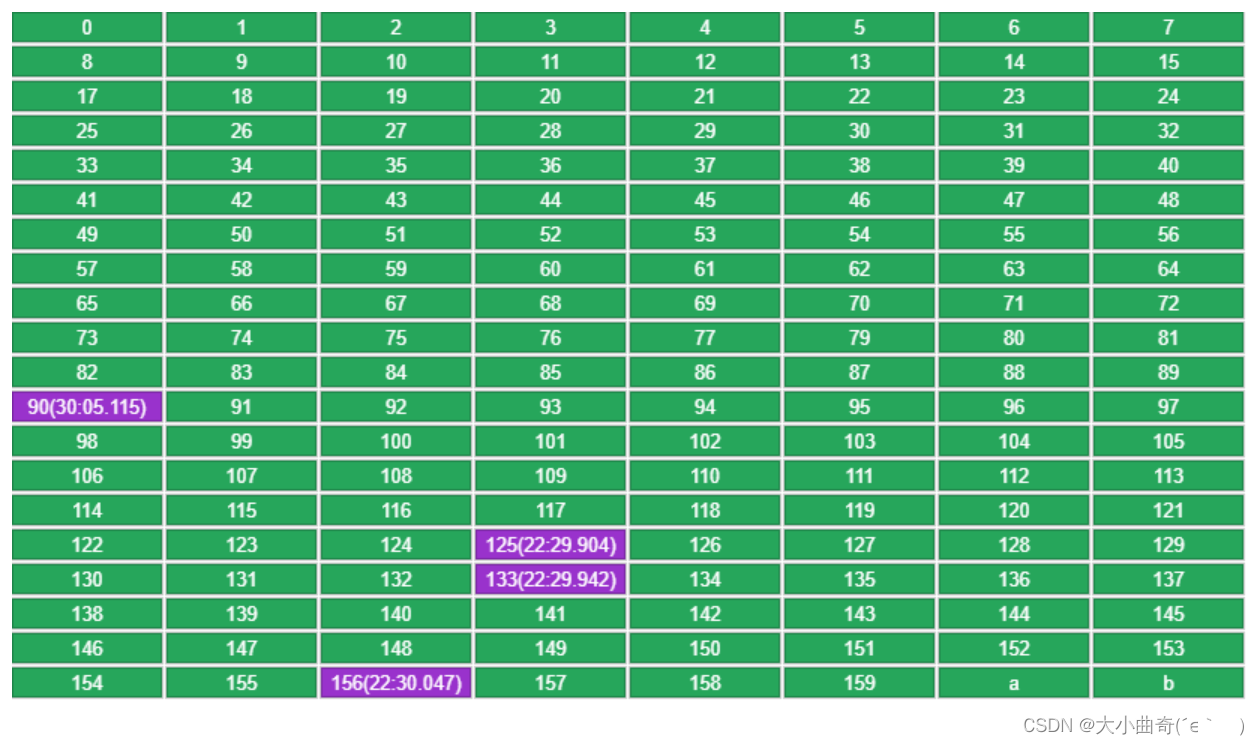
- Por ejemplo, los datos originales son los siguientes, la capacidad se especifica como 160, coloque una nueva clave a
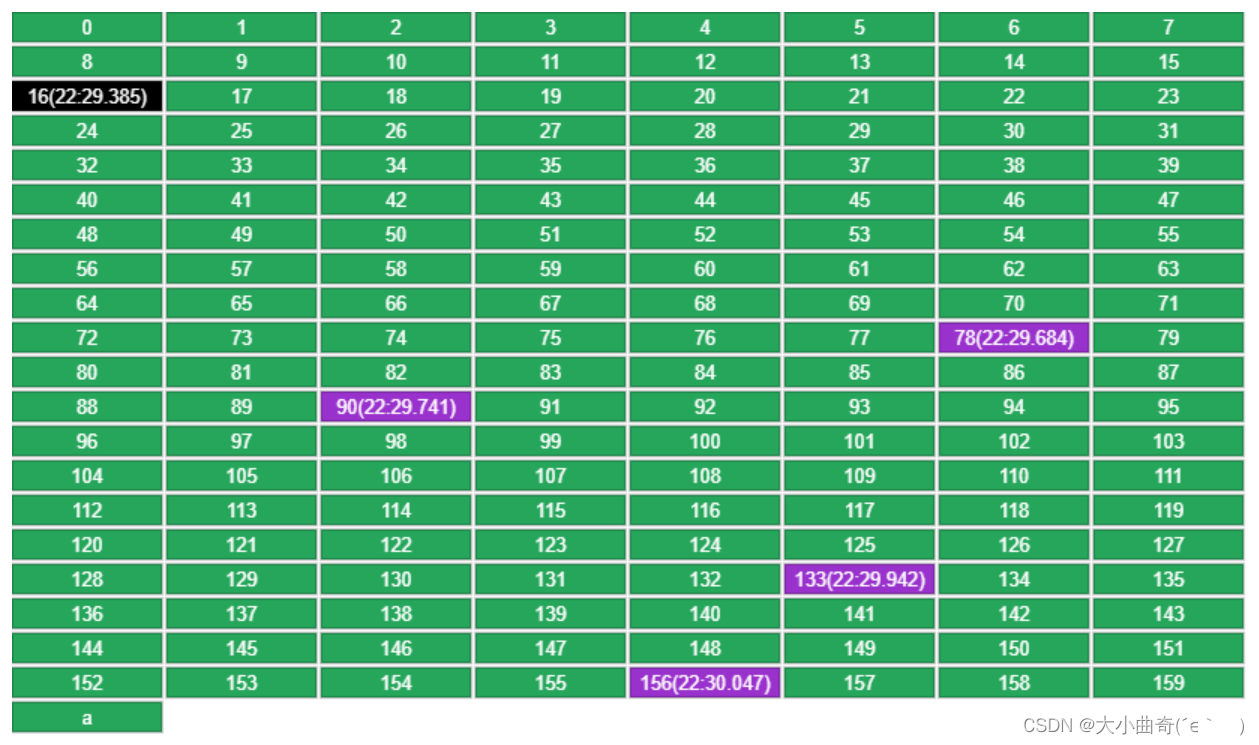
-
Cada clave registra la hora en que se puso en LRU. Entre las 5 claves seleccionadas al azar (16, 78, 90, 133, 156), se eliminará la que tenga la hora más antigua (16).
-
Al volver a poner b se utilizarán las 4 claves restantes de la ronda anterior (78, 90, 133, 156), más una clave aleatoria (125), y se seleccionará la más antigua (78).
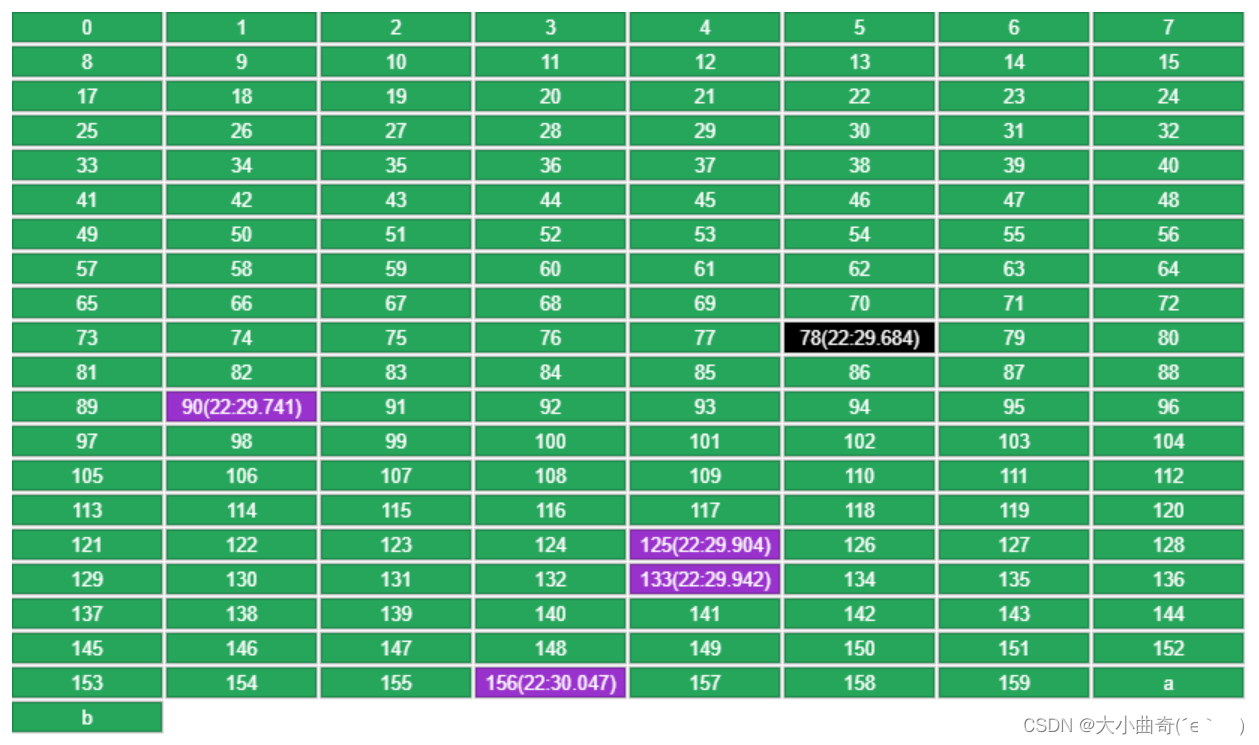
- Si se obtiene una clave, se actualizará su tiempo de acceso (90 en la figura siguiente), evitando así que se elimine en la siguiente ronda.