Directorio de artículos
1. Introducción al conjunto de datos KITTI
1.1 Introducción
- Descripción general
El conjunto de datos KITTI es actualmente el más grande del mundo.Conjunto de datos de evaluación de algoritmos de visión por computadora en escenarios de conducción autónoma. Este conjunto de datos se utiliza para evaluar el rendimiento de tecnologías de visión por computadora como estéreo, flujo óptico, odometría visual, detección de objetos 3D y seguimiento 3D en un entorno de vehículo.
KITTI contiene datos de imágenes reales recopiladas en escenas urbanas, rurales y de carreteras. Cada imagen contiene hasta 15 vehículos y 30 peatones, así como varios grados de oclusión y truncamiento.
El conjunto de datos de detección de objetos 3D consta de 7481 imágenes de entrenamiento y 7518 imágenes de prueba y los datos de nubes de puntos correspondientes, incluidos un total de 80256 objetos etiquetados. - Plataforma de recopilación de datos
El vehículo de recopilación de datos de Kitti tiene un lidar velodyne de 64 líneas en la parte superior . Hay cuatro cámaras en el frente , a saber, cam0 ~ 3, de las cuales 0 y 1 son cámaras en escala de grises y 2 y 3 son cámaras RGB. El sistema de coordenadas de lidar sigue la regla de la mano derecha, mientras que el sistema de coordenadas de la cámara sigue la regla de la mano izquierda , como se muestra en la figura.

Para generar imágenes estereoscópicas binoculares, se instalaron cámaras del mismo tipo a 54 cm de distancia. Dado que la resolución y el contraste de la cámara a color no son lo suficientemente buenos, también se utilizan dos cámaras estereoscópicas en escala de grises, que se instalan a 6 cm de distancia de la cámara a color.
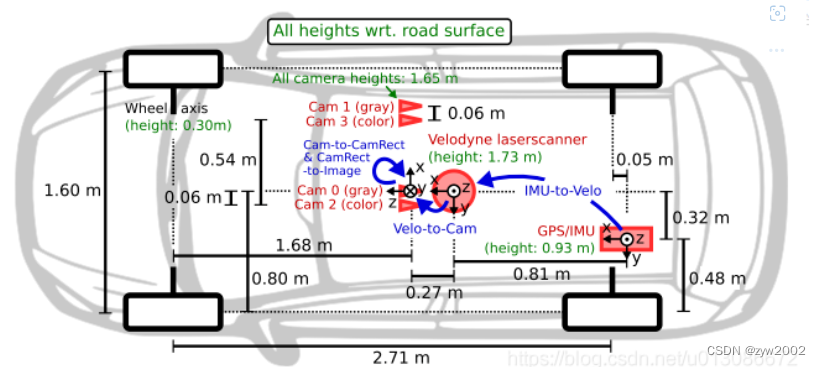
Las cuatro cámaras se han sometido a una estricta corrección de posición para garantizar que yz tenga el mismo valor y x sea coaxial . Si desea convertir el sistema de coordenadas de lidar y cámara, cam0 se usa como punto de referencia de forma predeterminada, es decir, si cam0 se transfiere a velodyne, simplemente transfiera directamente. Para convertir otras cámaras a velodyne, primero debe cambiar a cam0 y luego a velodyne. La conversión de coordenadas de la cámara y el láser se explicará en detalle más adelante.
具体的传感器参数如下:
2 × cámaras en escala de grises PointGray Flea2 (FL2-14S3M-C), 1,4 megapíxeles, CCD Sony ICX267 de 1/2”, obturador global 2
× cámaras en color PointGray Flea2 (FL2-14S3C-C), 1,4 megapíxeles, CCD Sony ICX267 de 1/2”, obturador global
4 lentes Edmund Optics, 4 mm, ángulo de apertura ∼ 90 ◦, ángulo de apertura vertical de la región de interés (ROI) ∼ 35 ◦ 1
× escáner láser 3D giratorio Velodyne HDL-64E, 10 Hz , 64 haces, resolución angular de 0,09 grados, precisión de distancia de 2 cm, recopilación de ∼ 1,3 millones de puntos/segundo, campo de visión: 360◦ horizontal, 26,8◦ vertical, alcance: 120 m 1 × sistema de navegación inercial y GPS OXTS RT3003, 6
ejes , 100 Hz, L1/L2 RTK, resolución: 0,02 m/0,1◦
- Sistema coordinado
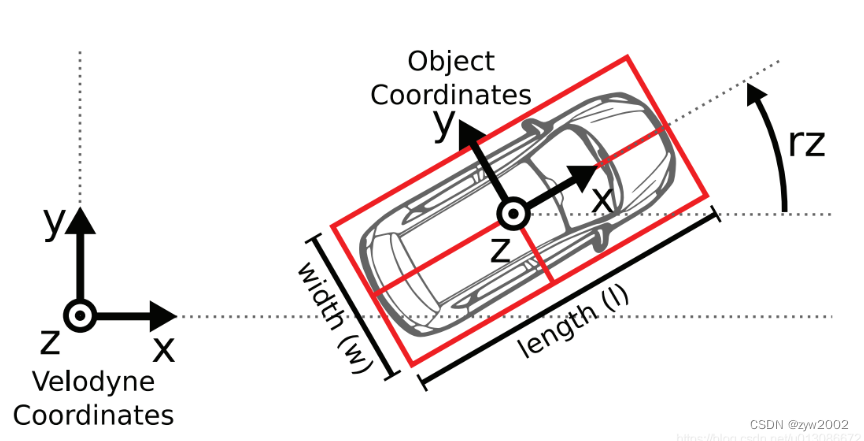
Para facilitar la calibración de los datos del sensor, la dirección del sistema de coordenadas se especifica de la siguiente manera:
- cámara: x = derecha, y = abajo, z = adelante
- velodyne: x = adelante, y = izquierda, z = arriba
- GPS/IMU: x = adelante, y = izquierda, z = arriba
1.2 Descargar
- Sitio web oficial del conjunto de datos
Dirección de descarga del sitio web oficial del conjunto de datos- Enlace de descarga de Baidu Netdisk
: https://pan.baidu.com/s/1-4WchJlcZ2guwcfbHqrdFw
Código de extracción: grys
Se recomienda utilizar el enlace de descarga de Baidu Cloud Disk.(Porque el archivo es muy grande y la velocidad de descarga desde el sitio web oficial es muy lenta).
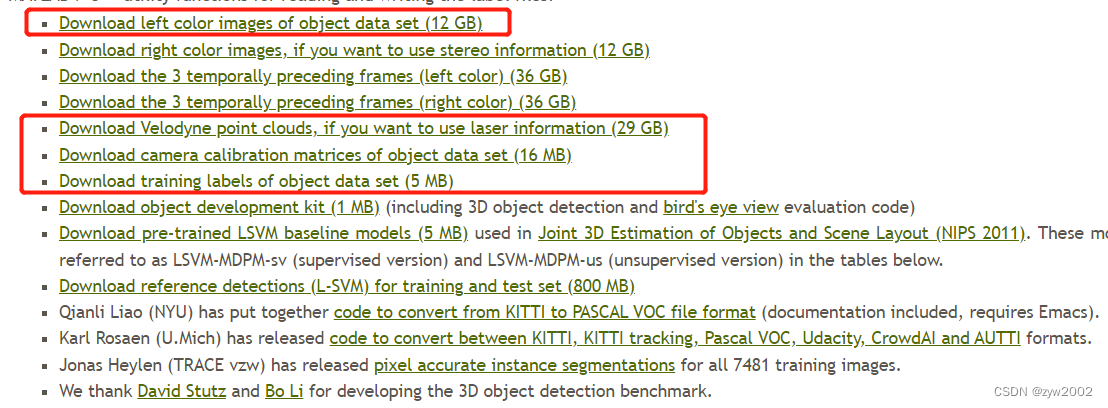
Ingrese al sitio web oficial, el cuadro rojo en la imagen a continuación indica los datos que necesitamos:
- Datos de imagen en color (12 GB)
- Datos de nube de puntos (29 GB)
- Datos de corrección de la cámara (16 MB)
- Datos de etiqueta (5 MB).
Los datos de la imagen en color, los datos de la nube de puntos y los datos de corrección de la cámara incluyen entrenamiento (7481) y prueba (7518), y los datos de la etiqueta solo tienen datos de entrenamiento.
2. Análisis de datos
2.0 Estructura del conjunto de datos
Organice el conjunto de datos de acuerdo con el método de organización oficial del conjunto de datos KITTI en OpenPCDet
data
│── kitti
│ │── ImageSets
│ │── testing
│ │ ├── calib & image_2 & velodyne
│ │── training
│ │ ├── calib & image_2 & label_2 & planes & velodyne
image_2Es decir, la fotografía (.png) tomada con la cámara en color número 2;calibParámetros externos (.txt) correspondientes a cada cuadro;label_2Es la información de anotación de cada cuadro (.txt);velodyneEs el archivo de nube de puntos (.bin) obtenido por Velodyne64.
2.1 Conjuntos de imágenes
La información de la lista de conjuntos de datos generalmente incluye las siguientes tres partes:
- train.txt: información de la lista de conjuntos de entrenamiento
- test.txt: información de la lista del conjunto de prueba
- val.txt: información de la lista de conjuntos de verificación
2.2 Pruebas y capacitación
2.2.1 calibrar
El archivo calib son los datos de corrección de cámaras, radares, navegación inercial y otros sensores. Tomando el archivo "000001.txt" como ejemplo, el contenido es el siguiente:
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
-
P0~P3P rec ( yo ) P_ {rect} ^ {(i)}PAGrec t( yo ): Matriz de proyección de cámara corregida R 3 ∗ 4 R^{3*4}R3 ∗ 4
0, 1, 2 y 3 representan el número de cámara, 0 representa la cámara en escala de grises de la izquierda, 1 representa la cámara en escala de grises de la derecha, 2 representa la cámara en color de la izquierda y 3 representa la cámara en color de la derecha.
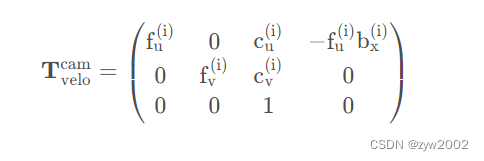
dondebx (i) b_x^{(i)}bX( yo )Representa el valor de referencia en metros relativo a la cámara de referencia 0 -
R0_rectR rect (i) R_{rect}^{(i)}Rrec t( yo ): Matriz de rotación de cámara corregida R 3 ∗ 3 R^{3*3}REn el cálculo real de 3 ∗ 3
, la matriz de 3x3 debe expandirse a una matriz de 4x4 agregando un vector de todos los ceros en la cuarta fila y columna, y estableciendo el valor del índice de (4, 4) en 1. -
Tr_velo_to_cam(T velocam) (T_{velo}^{cam})( tvelo _ _ _estoy _) :Matriz de rotación y traslación del radar a la cámara 0(R 3 ∗ 4 R^{3*4}R3 ∗ 4 )
En el cálculo real, la matriz de 3x4 debe expandirse a una matriz de 4x4 agregando un vector de cuarta fila [0,0,0,1]. Esta matriz en realidad consta de dos partes, una es la matriz de rotación de 3x3 y la otra es el vector de traslación de 1x3.

-
Tr_imu_to_velo(T velocidad) (T_{velocidad}^{velocidad})( tsoy tuvelo _ _ _) :Matriz de rotación y traslación desde navegación inercial o dispositivo GPS a cámara(R 3 ∗ 4 R^{3*4}R3 ∗ 4 )
Si desea proyectar el punto x en el sistema de coordenadas lidar a la imagen en color (P2) y a la izquierda, puede usar la siguiente fórmula:
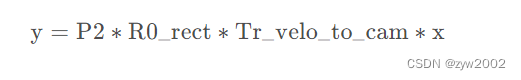
Si desea proyectar el punto x en el sistema de coordenadas lidar a Para otras cámaras, simplemente reemplace la matriz P2 (como la cámara en color P3 a la derecha).
1、将 Velodyne 坐标中的点 x 投影到左侧的彩色图像中 y,使用公式 y = P2 * R0_rect * Tr_velo_to_cam * x
2、将 Velodyne 坐标中的点 x 投影到右侧的彩色图像中 y,使用公式 y = P3 * R0_rect * Tr_velo_to_cam * x
3、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,使用公式 R0_rect * Tr_velo_to_cam * x
4、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,再投影到编号为 2 的相机(左彩色相机)的照片上,使用公式 P2 * R0_rect * Tr_velo_to_cam * x
2.2.2 imagen_2
El archivo de imagen se almacena en formato PNG de 8 bits y el atlas es el siguiente:
2.2.3 etiqueta_2
El archivo de etiqueta es la etiqueta y los datos de evaluación del objeto en KITTI. Tomando el archivo "000001.txt" como ejemplo, el estilo incluido es el siguiente:
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10
Cada fila representa un objeto y cada fila tiene 16 columnas que representan diferentes significados, de la siguiente manera:
-
Columna 1 (cadena): representa
un total de 9 categorías de categorías de objetos (tipo), a saber: automóvil, camioneta, camión, peatón, persona sentada, ciclista, tranvía, varios, DontCare.
La etiqueta DontCare indica que el área no se ha marcado, por ejemplo, porque el objeto objetivo está demasiado lejos del lidar. Para evitar que las áreas que originalmente son objetos de destino pero que no están etiquetadas por algún motivo se cuenten como falsos positivos durante el proceso de evaluación (principalmente cálculo de precisión), el script de evaluación ignorará automáticamente los resultados de la predicción del área DontCare. -
Columna 2 (número de coma flotante): representa si el objeto está truncado (truncado).
El valor flota entre 0 (no truncado) y 1 (truncado). El número indica el grado en que el objeto abandona el límite de la imagen. -
Columna 3 (entero): representa si el objeto está ocluido (ocluido),
los números enteros 0, 1, 2 y 3 representan respectivamente el grado de oclusión. -
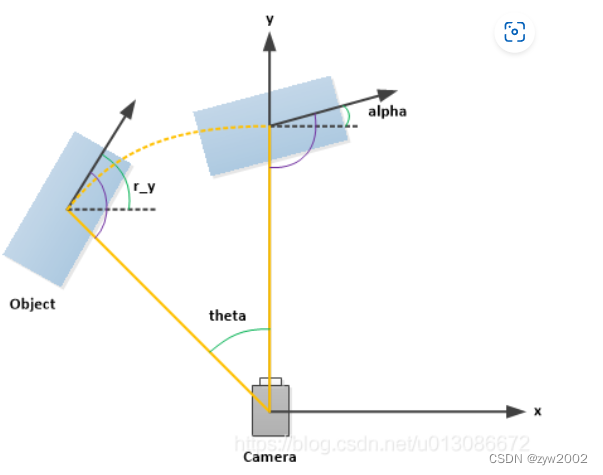
Columna 4 (radianes): El ángulo de observación (alfa) del objeto
oscila entre: -pi ~ pi (unidad: rad), que representa la distancia desde el origen de la cámara hasta el centro del objeto en el sistema de coordenadas de la cámara, con el origen de la cámara como centro. La línea de conexión es el radio. Gire el objeto alrededor del eje y de la cámara hacia el eje z de la cámara. En este momento, el ángulo entre la dirección del objeto y el eje x de la cámara (como se muestra en la imagen) figura a continuación, el eje y es perpendicular a la pantalla) -
Columnas 5 a 8 (números de punto flotante): el tamaño del cuadro delimitador 2D (bbox) del objeto. Los
cuatro números son xmin, ymin, xmax, ymax (unidad: píxel), que representan las coordenadas de la esquina superior izquierda e inferior. Esquina derecha del cuadro delimitador 2D. -
Columnas 9 a 11 (números de punto flotante): las dimensiones del objeto 3D
son alto, ancho y largo (unidad: metros) -
Columnas 12 a 14 (números de punto flotante): las ubicaciones de los objetos 3D
son x, y y z (unidad: metros). Tenga en cuenta que xyz aquí es el punto central del objeto 3D en el sistema de coordenadas de la cámara. -
Columna 15 (número de radianes):
El rango de valores de la dirección espacial (rotación_y) del objeto 3D es: -pi ~ pi (unidad: rad), que representa, en el sistema de coordenadas de la cámara, el ángulo de dirección global del objeto. (la dirección de avance del objeto y el ángulo entre el eje x del sistema de coordenadas de la cámara), como se muestra en la siguiente figura. -
Columna 16 (número de coma flotante): Confianza de detección (puntuación)
2.2.4 aviones
# Plane
Width 4
Height 1
-1.851372e-02 -9.998285e-01 -5.362310e-04 1.678761e+00
2.2.5 velodino
El archivo velodyne son los datos de medición del lidar (rotación continua alrededor de su eje vertical (en sentido antihorario)). Tomando el archivo "000001.bin" como ejemplo, el contenido es el siguiente:
8D 97 92 41 39 B4 48 3D 58 39 54 3F 00 00 00 00
83 C0 92 41 87 16 D9 3D 58 39 54 3F 00 00 00 00
2D 32 4D 42 AE 47 01 3F FE D4 F8 3F 00 00 00 00
37 89 92 41 D3 4D 62 3E 58 39 54 3F 00 00 00 00
E5 D0 92 41 12 83 80 3E E1 7A 54 3F EC 51 B8 3D
7B 14 70 41 2B 87 96 3E 50 8D 37 3F CD CC 4C 3E
96 43 6F 41 7B 14 AE 3E 3D 0A 37 3F E1 7A 14 3F
2F DD 72 41 5E BA C9 3E 87 16 39 3F 00 00 00 00
FA 7E 92 41 5E BA 09 3F 58 39 54 3F 00 00 00 00
66 66 92 41 EC 51 18 3F CF F7 53 3F 00 00 00 00
A4 70 92 41 77 BE 1F 3F CF F7 53 3F 00 00 00 00
A4 70 92 41 8D 97 2E 3F 58 39 54 3F 00 00 00 00
...
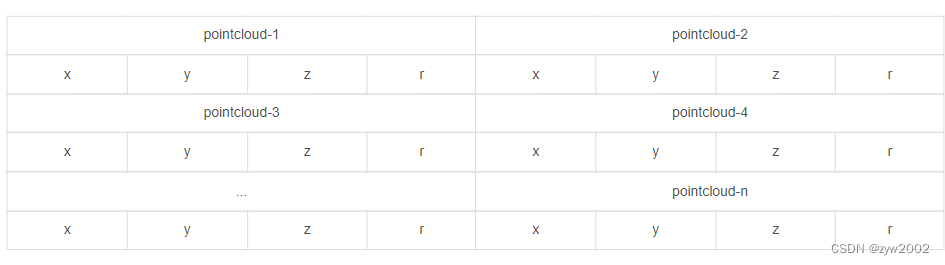
Los datos de la nube de puntos se almacenan en formato de archivo binario de punto flotante, cada línea contiene 8 datos, cada dato está representado por un número hexadecimal de cuatro dígitos (número de punto flotante) y cada dato está separado por espacios. Los datos de una nube de puntos se componen de cuatro datos de punto flotante, que representan respectivamente x, y, z, r (intensidad o valor de reflexión) de la nube de puntos . La nube de puntos se almacena como se muestra en la siguiente tabla:
3. Descarga y organización de conjuntos de datos.
- Enlace de descarga de Baidu Netdisk
: https://pan.baidu.com/s/1-4WchJlcZ2guwcfbHqrdFw
Código de extracción: grys
Descargue el archivo en el cuadro a continuación desde Baidu Cloud Disk.
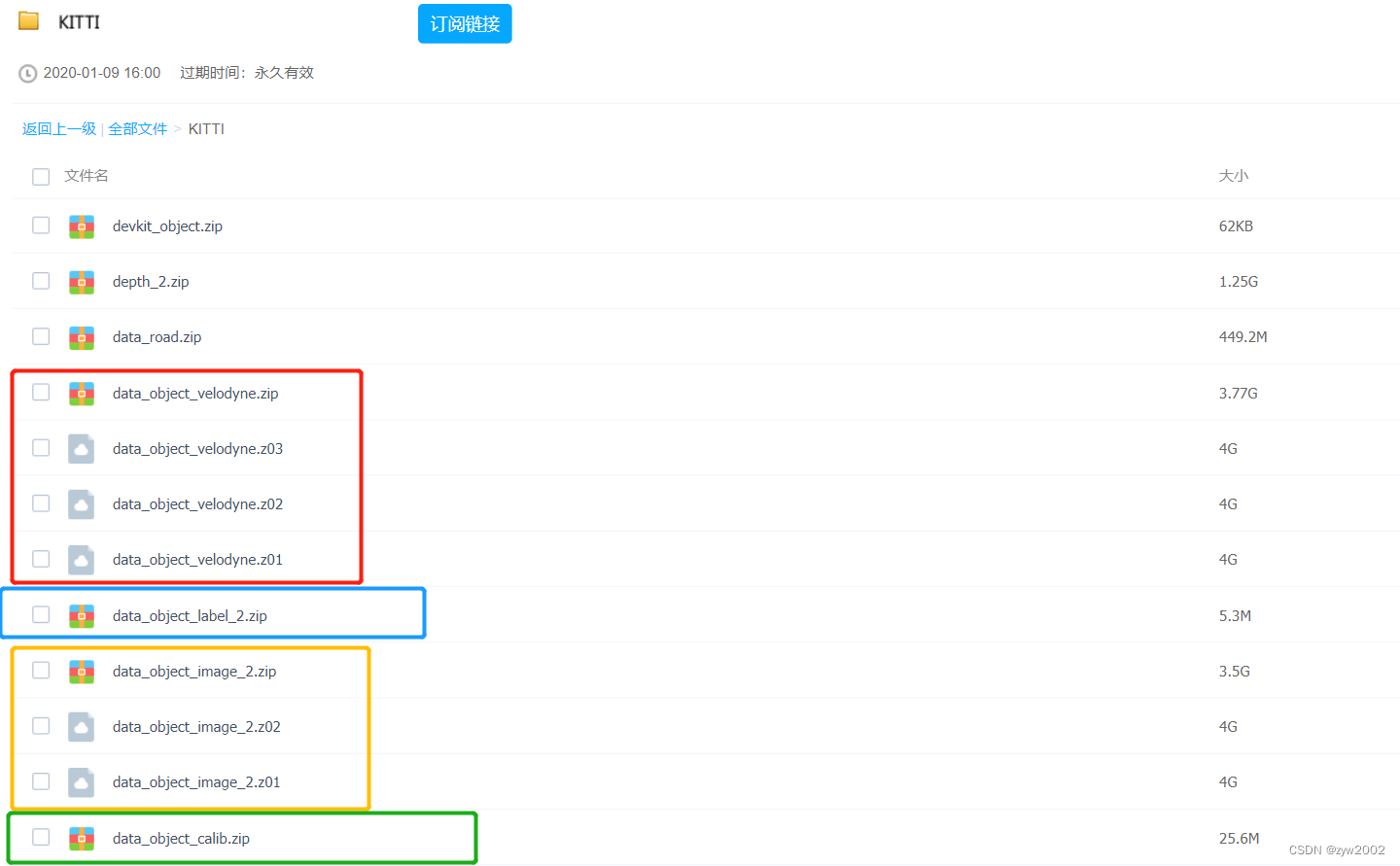
Entre ellos
xxx.zip, yxxx.z01, se encuentran los archivos de subpaquete, que deben descargarse en su totalidad antesxxx.z02dexxx.z03poder descomprimirlos.
Luego cargue todos los paquetes comprimidos descargados al servidor en la nube a través de xftp.
Cómo descomprimir archivos subempaquetados, tomemos data_object_image_2.zipcomo ejemplo.
# 先将压缩包合并
zip -s 0 data_object_image_2.zip --out image_02.zip
# 再次解压
unzip image_02.zip
La estructura del archivo después de la descompresión es la siguiente. Como se muestra a continuación, cree un nuevo directorio
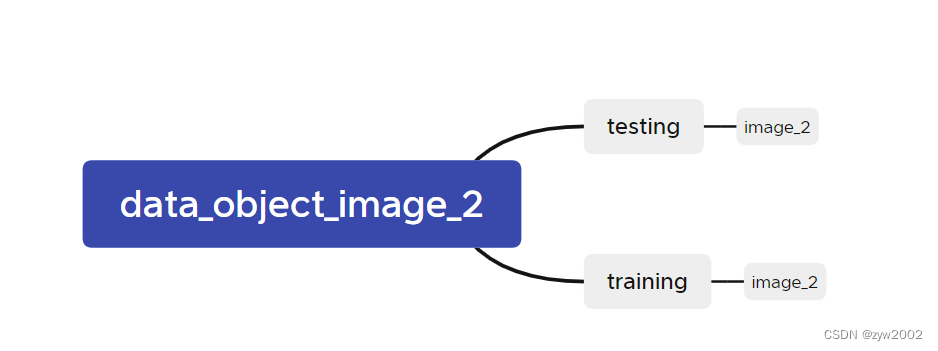
en la carpeta kitti . Luego coloque los archivos obtenidos después de la descompresión en el paso anterior en la carpeta; coloque los archivos obtenidos después de la descompresión en el paso anterior en la carpeta.testingtrainingdata_object_image2/testing/image_2data/kitti/testingdata_object_image2/training/image_2data/kitti/training
Luego crea una nueva carpeta ImageSetse ingresa en ella.
Descargue el archivo del conjunto de datos divididos de Kitti proporcionado oficialmente:test.txt train.txt val.txt trainval.txt
# test.txt
wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/test.txt --no-check-certificate --content-disposition -O test.txt
# train.txt
wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/train.txt --no-check-certificate --content-disposition -O train.txt
# val.txt
wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/val.txt --no-check-certificate --content-disposition -O val.txt
# trainval.txt
wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/trainval.txt --no-check-certificate --content-disposition -O trainval.txt
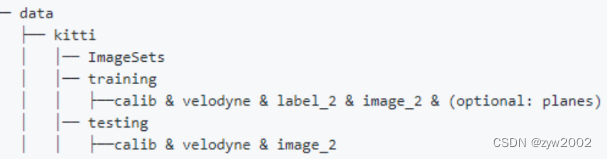
La estructura organizativa final se muestra a continuación:
A veces podemos utilizar el mismo conjunto de datos en varios proyectos, en este caso podemos establecer un vínculo suave.
Por ejemplo, mi conjunto de datos kitti original se descargó /data/zyw/project/data/kitti, pero necesito una carpeta mmdetection3d/datadebajo de la carpeta . Para ahorrar memoria, no copiamos directamente, sino que creamos enlaces suaves.kitti
cd mmdetection3d/data
ln –s /data/zyw/project/data/kitti kitti
4. Visualización
4.1 Software CloudCompare
CloudCompare es potente e instalar este software directamente es el método de visualización más sencillo.
-
dirección de descarga del sitio web oficial de cloudcompare
Seleccione la versión correspondiente para descargar
-
O descárguelo desde
el enlace Baidu Netdisk (winows64, CloudCompare 2.12.4): https://pan.baidu.com/s/1RWDdMByK1trY–d05-SlHg -
显示-语言翻译-简体中文
Código de extracción: zfjo
- Haga clic
文件:compare
puede abrir archivos de nube de puntos en múltiples formatos,
el efecto de visualización es el siguiente
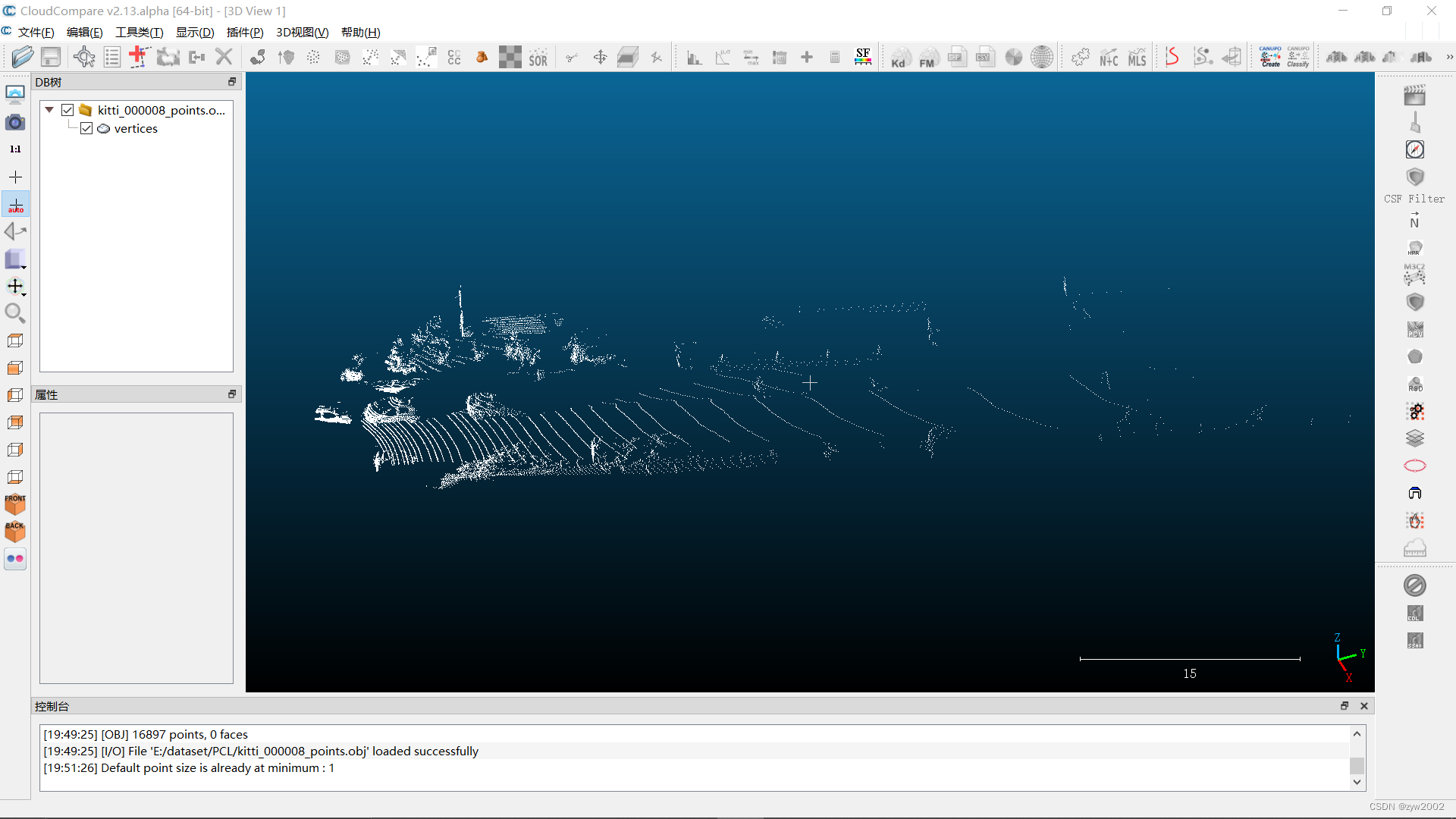
4.2 biblioteca PCL
Visualizar nubes de puntos configurando PCL es relativamente complicado. Para obtener más detalles, consulte el siguiente blog ~
[PCL1.11.0 + win10 + vs2019] Configuración del entorno / conversión y visualización del formato de nube de puntos
referencia
Blog de referencia:
【1】https://blog.csdn.net/i6101206007/article/details/11225682
【2】https://blog.csdn.net/u013086672/article/details/103913361