Análisis de datos simple y visualización de datos con Python
Este artículo trata principalmente sobre la exploración preliminar del análisis de datos y una comprensión simple del proceso general de análisis de datos.
Fuente de datos : De un proyecto en la plataforma Kaggle: Explore el
código fuente de datos de salarios de empleados de la ciudad de San Francisco y datos originales : https: // github.com/yb705 / SF-Salaries
Primero, necesitamos importar algunas bibliotecas de terceros numpy, pandas, etc., para realizar algunas configuraciones iniciales para la visualización de datos e importar datos sin procesar:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline#在ipython或者是jupyter notebook上可以显示图片
plt.style.use("fivethirtyeight")
sns.set_style({
'font.sans-serif':['SimHei','Arial']})
original=pd.read_csv('C:\\Users\\1994y\\Desktop\\Salaries.csv')
Exploración preliminar de datos
Luego, primero debemos observar los datos para ver si faltan valores y el formato de los datos:
original.info()
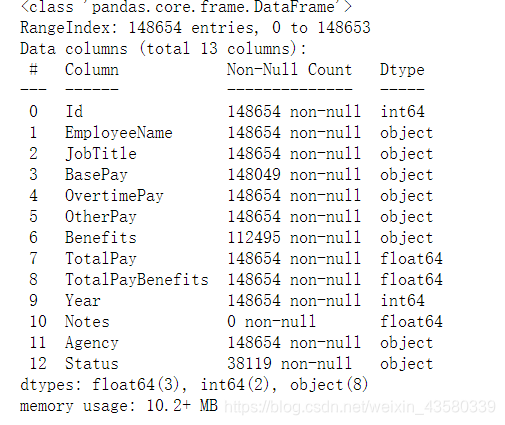
Puede ver que faltan valores, así que preste atención a las partes con valores perdidos en la siguiente operación.
También puede ver el formato de datos en la columna dtype. Quiero recordarles a todos que algunos datos parecen números, pero en realidad es un formato de cadena. Si tenemos operaciones aritméticas u otras operaciones digitales, necesitamos convertir estos datos. Int tipo o tipo de flotador.
objlist = ['BasePay', 'OvertimePay', 'OtherPay', 'Benefits']
for obj in objlist:
original[obj] = pd.to_numeric(original[obj], errors = 'coerce')
original.info()

Eso es todo. Además de to_numeric (), también puede utilizar el método astype () para la conversión de formato de datos.
Luego, primero podemos comprender aproximadamente algunos de estos datos, como el año:
original['Year'].unique()
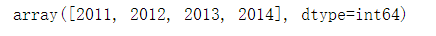
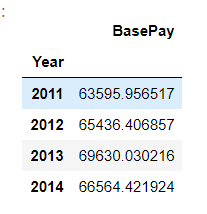
Salario base anual medio:
original.groupby(["Year"])[["BasePay"]].mean()
También puedes encontrar a la persona con menor salario:
original[original['TotalPayBenefits'] == original['TotalPayBenefits'].min()]

¿Es esta la persona que todavía debe dinero y por qué es negativo?
La persona que paga más horas extra:
original[original['OvertimePay'] == original['OvertimePay'].max()]

Por desgracia, el salario por las horas extraordinarias es más alto que el salario oficial del bloguero, lo cual es incómodo.
También puede utilizar el mecanismo groupby de pandas para realizar estadísticas de agrupación para ver el promedio de los respectivos salarios básicos de PT (tiempo parcial) y FT (tiempo completo):
original.groupby('Status')['BasePay'].mean()

Visualización de
datos La visualización de datos es una gran función para el análisis de datos con Python. Unas pocas líneas de código simple pueden generar una variedad de gráficos geniales y mostrar los datos de manera muy intuitiva, confiando principalmente en las bibliotecas de terceros matplotlib, seaborn para cumplir. (La biblioteca de terceros también es una característica de Python).
Use el gráfico de columnas para ver las 5 ocupaciones principales con el salario promedio más alto en los últimos cuatro años :
Porque planeamos presentarlo en forma de una combinación de sub- gráficos, primero filtramos los datos para estos 4 años:
a=original.loc[original["Year"]==2011]
b=original.loc[original["Year"]==2012]
c=original.loc[original["Year"]==2013]
d=original.loc[original["Year"]==2014]
El siguiente paso es agrupar los cuatro conjuntos de datos y encontrar el salario promedio para cada uno:
a_2011=a.groupby(["JobTitle"])[["TotalPay"]].mean().sort_values(by="TotalPay",ascending=False).reset_index()
a_2011['JobTitle']=a_2011['JobTitle'].str.capitalize()#这里是为了让工作名称即JobTitle的首字母大写,与其他三组一致
b_2012=b.groupby(["JobTitle"])[["TotalPay"]].mean().sort_values(by="TotalPay",ascending=False).reset_index()
c_2013=c.groupby(["JobTitle"])[["TotalPay"]].mean().sort_values(by="TotalPay",ascending=False).reset_index()
d_2014=d.groupby(["JobTitle"])[["TotalPay"]].mean().sort_values(by="TotalPay",ascending=False).reset_index()
f, axs = plt.subplots(2,2,figsize=(20,15))#2x2的子图组合,大小是20x15
sns.barplot(x=a_2011['JobTitle'].head(5), y=a_2011['TotalPay'].head(5), palette="Greens_d",data=a_2011, ax=axs[0,0])#子图的数据,位置等设置
axs[0,0].set_title('2011年SF工资top5',fontsize=15)#标题
axs[0,0].set_xlabel('工作')
axs[0,0].set_ylabel('平均薪资')
sns.barplot(x=b_2012['JobTitle'].head(5), y=b_2012['TotalPay'].head(5), palette="Greens_d",data=b_2012, ax=axs[0,1])
axs[0,1].set_title('2012年SF工资top5',fontsize=15)
axs[0,1].set_xlabel('工作')
axs[0,1].set_ylabel('平均薪资')
sns.barplot(x=c_2013['JobTitle'].head(5), y=c_2013['TotalPay'].head(5), palette="Greens_d",data=c_2013.head(5), ax=axs[1,0])
axs[1,0].set_title('2013年SF工资top5',fontsize=15)
axs[1,0].set_xlabel('工作')
axs[1,0].set_ylabel('平均薪资')
sns.barplot(x=d_2014['JobTitle'].head(5), y=d_2014['TotalPay'].head(5), palette="Greens_d",data=d_2014.head(5), ax=axs[1,1])
axs[1,1].set_title('2014年SF工资top5',fontsize=15)
axs[1,1].set_xlabel('工作')
axs[1,1].set_ylabel('平均薪资')

Los resultados se muestran arriba, y es muy intuitivo ver las ocupaciones con los salarios más altos cada año y sus respectivos salarios.
Utilice el gráfico de líneas para ver los cambios salariales promedio de varias ocupaciones en tres años.
Elegí las cinco ocupaciones con los salarios más altos en 12 años para ver:
job_list=["Chief of Police","Chief, Fire Department","Gen Mgr, Public Trnsp Dept","Executive Contract Employee","Asst Chf of Dept (Fire Dept)"]
A continuación, compilé una función para filtrar el salario de la ocupación correspondiente en los últimos tres años y generar un diccionario:
def check_job(x):
salary_dict={
}
for i in range(len(x["JobTitle"])):
if x.loc[i,'JobTitle'] in job_list:
salary_dict[x.loc[i,'JobTitle']]=x.loc[i,'TotalPay']
return salary_dict
d1=check_job(a_2011)
d2=check_job(b_2012)
d3=check_job(c_2013)
d4=check_job(d_2014)
d4
Uno de los resultados es el siguiente:

Finalmente, el diccionario generado se ordena y queda así:
salary={
'Chief of Police':[321552.11,339282.07,326716.76],
'Chief, Fire Department':[ 314759.6,336922.01,326233.44],
'Gen Mgr, Public Trnsp Dept': [294000.17,305307.89,294000.18],
'Executive Contract Employee': [273776.24,207269.5166666667,278544.71],
'Asst Chf of Dept (Fire Dept)': [270674.81666666665,294846.6766666667,279768.9583333334]}
A continuación, genere un formato de marco de datos a partir del diccionario y genere una imagen:
df=pd.DataFrame(salary,index=["2012","2013","2014"])
df.plot()#生成折线图

Por supuesto, la selección de valores de características de datos es un poco problemática. Si el tiempo se puede alargar un poco más, este gráfico será más intuitivo.
Utilice el mapa de calor para ver la correlación de valores propios. La correlación se
refiere a las leyes que existen entre los valores de dos o más variables en un cierto sentido, y su propósito es explorar la red de correlación oculta en el conjunto de datos. Generalmente, el coeficiente de correlación se utiliza para describir la correlación entre los dos conjuntos de datos, y el coeficiente de correlación se obtiene dividiendo la covarianza por la desviación estándar de las dos variables. El valor del coeficiente de correlación estará entre [-1, 1], -1 Significa una correlación negativa completa y 1 significa una correlación completa. La correlación juega un papel muy importante en el análisis y la minería de datos. En cuanto al rendimiento de relevancia, se puede expresar de manera muy intuitiva con un mapa de calor.
del original["Notes"]#删掉note这个不相关的特征值
plt.figure(figsize=(20,20))
plt.rcParams['font.sans-serif']=['SimHei'] #定义字体避免出现乱码的情况
plt.rcParams['axes.unicode_minus']=False
sns.heatmap(original.corr(),linewidths=0.1,vmax=1.0, square=True, linecolor='white', annot=True)#。corr()就是相关系数
plt.show()
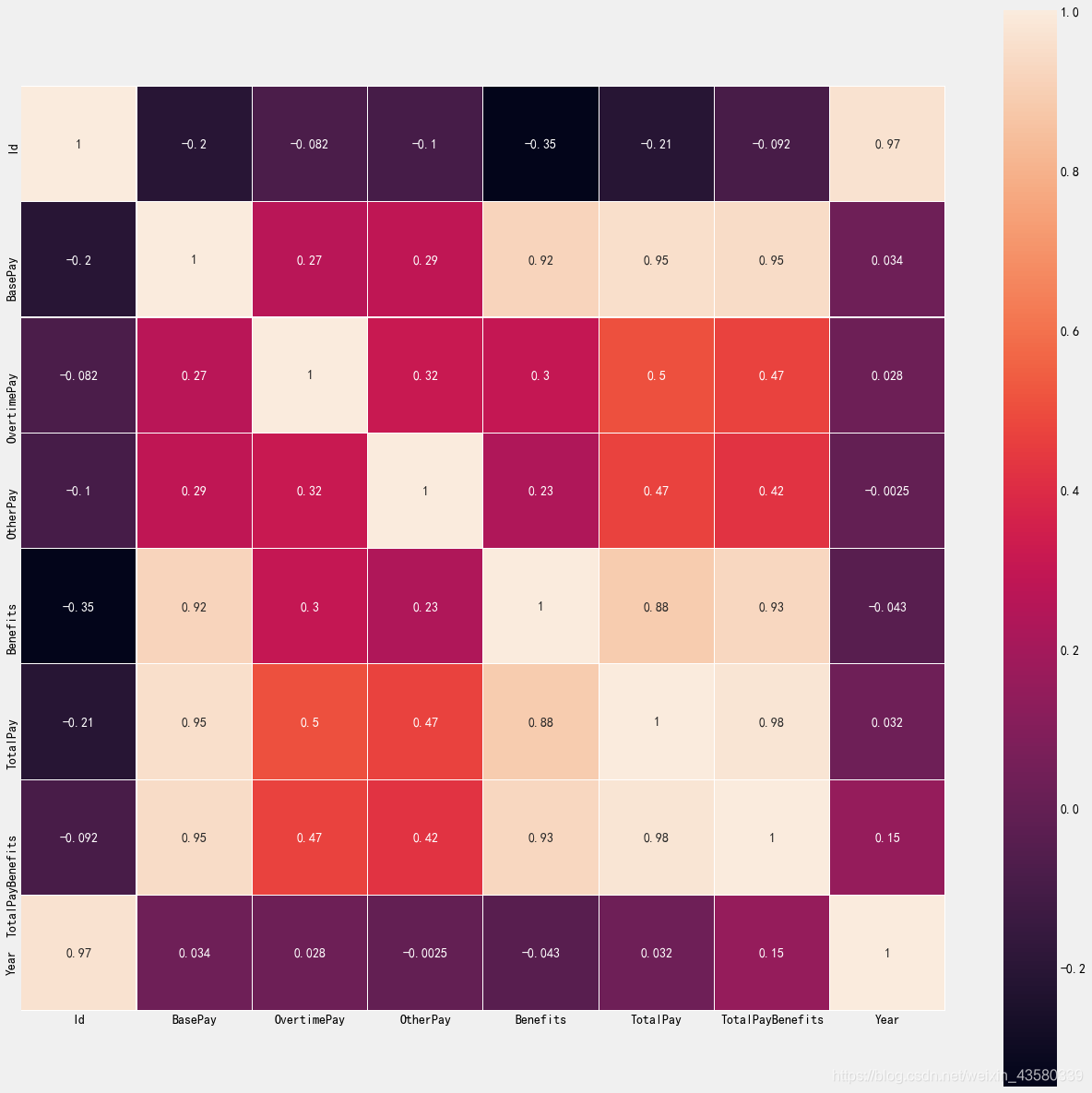
A partir del color y el resultado podemos ver el coeficiente de correlación entre cada atributo, es decir, si se afectan entre sí. Cuanto más claro es el color, más cercano está el coeficiente a 1 y mayor es la correlación.
para resumir
Lo anterior es el proceso simple de análisis de datos y visualización de datos. Espero que todos puedan entenderlo brevemente. De hecho, todavía hay muchos datos que se pueden analizar y los estudiantes interesados pueden estudiar por su cuenta. Si desea obtener más información sobre el proceso de análisis de datos y minería, puede leer otro artículo mío. Elementos del proceso de análisis de datos, minería y aprendizaje automático en python-Tianjin Alquilar un
blogger interno no ha estado en contacto con el análisis de datos durante mucho tiempo, si hay algo espero que todos puedan corregirme si es malo.
Gracias por leer.