Análisis de asociación a priori y conjuntos de elementos frecuentes
El análisis de asociación es una tarea de encontrar relaciones en conjuntos de datos a gran escala. Estas relaciones pueden tomar dos formas: conjuntos de elementos frecuentes o reglas de asociación. Los conjuntos de elementos frecuentes son colecciones de elementos que a menudo aparecen en una sola pieza. Las reglas de asociación implican que puede haber una fuerte relación entre dos elementos.

Los conjuntos de elementos frecuentes son colecciones de elementos que a menudo aparecen juntos. El conjunto {vino, pañal, leche de soja} en la figura es un ejemplo de conjuntos de elementos frecuentes. Y el vino de pañales puede ser una regla de asociación, lo que significa que si alguien compra un pañal, también puede comprar vino.
Algoritmo Apriori
El algoritmo Apriori es un algoritmo clásico de minería de datos para extraer conjuntos de elementos frecuentes y reglas de asociación. Apriori significa "de antes" en latín. Cuando se definen problemas, generalmente se utilizan conocimientos o suposiciones a priori, lo que se denomina "a priori". El nombre del algoritmo Apriori se basa en el hecho de que el algoritmo usa la propiedad a priori de la propiedad frecuente del conjunto de elementos, es decir, todos los subconjuntos no vacíos del conjunto frecuente de elementos también deben ser frecuentes. El algoritmo Apriori utiliza un método iterativo llamado búsqueda capa por capa, donde el conjunto de elementos k se utiliza para explorar el conjunto de elementos (k + 1). Primero, al escanear la base de datos, acumule el recuento de cada elemento y recopile los elementos que cumplan con el grado de soporte mínimo para encontrar el conjunto de conjuntos frecuentes de 1 elemento. Este conjunto se denota como L1. Luego, use L1 para encontrar el conjunto L2 de conjuntos frecuentes de 2 ítems, y use L2 para encontrar L3, y así sucesivamente, hasta que el conjunto de ítems k frecuentes ya no se pueda encontrar. Cada Lk encontrado requiere un análisis completo de la base de datos. El algoritmo Apriori utiliza las propiedades a priori de los conjuntos de elementos frecuentes para comprimir el espacio de búsqueda.
Conceptos basicos
Soporte: La proporción de registros en el conjunto de datos que contiene el conjunto con respecto a los registros totales, es decir, la
confianza utilizada para medir la frecuencia de un conjunto en los datos originales. ({P, H}) / soporte ({P})
Elementos y conjuntos de elementos: deje que conjunto de elementos = {item1, item_2, ..., item_m} sea una colección de todos los elementos, donde item_k (k = 1,2, ..., m) se convierte en un elemento. El conjunto de elementos se denomina conjunto de elementos, y el conjunto de elementos que contiene k elementos se denomina conjunto de elementos k.
Transacciones y conjuntos de transacciones: una transacción T es un conjunto de elementos, que es un subconjunto del conjunto de elementos, cada transacción está asociada con un identificador único Tid. Las diferentes transacciones juntas constituyen el conjunto de transacciones D, que constituye la base de datos de transacciones descubierta por las reglas de asociación.
Reglas de asociación: las reglas de asociación son implicaciones de la forma A => B, donde A y B son subconjuntos del conjunto de elementos y no son conjuntos vacíos, mientras que A y B están vacíos.
Soporte: El grado de soporte de la regla de asociación se define de la siguiente manera:
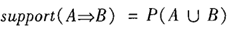
representa la probabilidad de que la transacción contenga la unión de los conjuntos A y B (es decir, cada elemento en A y B). Tenga en cuenta la diferencia con P (A o B), que representa la probabilidad de que una transacción contenga A o B.
Confianza: La confianza de la regla de asociación se define de la siguiente manera:
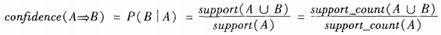
la frecuencia de ocurrencia del conjunto de elementos (conteo de soporte): el número de transacciones que contienen el conjunto de elementos, denominado frecuencia del conjunto de elementos, conteo o conteo de soporte.
Conjunto de elementos frecuentes: si el soporte relativo del conjunto de elementos I cumple con el umbral de soporte mínimo predefinido (es decir, la frecuencia de ocurrencia de I es mayor que el umbral de frecuencia de ocurrencia mínima correspondiente (conteo de soporte)), entonces I es Conjuntos de artículos frecuentes.
Reglas de asociación fuertes: Reglas de asociación que satisfacen el soporte mínimo y la confianza mínima, es decir, las reglas de asociación que deben extraerse.
Minería conjuntos de artículos frecuentes

Código de Python:
"""
# Python 2.7
"""
def load_data_set():
"""
Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition)
Returns:
A data set: A list of transactions. Each transaction contains several items.
"""
data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'],
['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'],
['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']]
return data_set
def create_C1(data_set):
"""
Create frequent candidate 1-itemset C1 by scaning data set.
Args:
data_set: A list of transactions. Each transaction contains several items.
Returns:
C1: A set which contains all frequent candidate 1-itemsets
"""
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1
def is_apriori(Ck_item, Lksub1):
"""
Judge whether a frequent candidate k-itemset satisfy Apriori property.
Args:
Ck_item: a frequent candidate k-itemset in Ck which contains all frequent
candidate k-itemsets.
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
Returns:
True: satisfying Apriori property.
False: Not satisfying Apriori property.
"""
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lksub1:
return False
return True
def create_Ck(Lksub1, k):
"""
Create Ck, a set which contains all all frequent candidate k-itemsets
by Lk-1's own connection operation.
Args:
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
k: the item number of a frequent itemset.
Return:
Ck: a set which contains all all frequent candidate k-itemsets.
"""
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
# pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck
def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
"""
Generate Lk by executing a delete policy from Ck.
Args:
data_set: A list of transactions. Each transaction contains several items.
Ck: A set which contains all all frequent candidate k-itemsets.
min_support: The minimum support.
support_data: A dictionary. The key is frequent itemset and the value is support.
Returns:
Lk: A set which contains all all frequent k-itemsets.
"""
Lk = set()
item_count = {}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk
def generate_L(data_set, k, min_support):
"""
Generate all frequent itemsets.
Args:
data_set: A list of transactions. Each transaction contains several items.
k: Maximum number of items for all frequent itemsets.
min_support: The minimum support.
Returns:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
"""
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data
def generate_big_rules(L, support_data, min_conf):
"""
Generate big rules from frequent itemsets.
Args:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
min_conf: Minimal confidence.
Returns:
big_rule_list: A list which contains all big rules. Each big rule is represented
as a 3-tuple.
"""
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in big_rule_list:
# print freq_set-sub_set, " => ", sub_set, "conf: ", conf
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list
if __name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)
for Lk in L:
print "="*50
print "frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport"
print "="*50
for freq_set in Lk:
print freq_set, support_data[freq_set]
print
print "Big Rules"
for item in big_rules_list:
print item[0], "=>", item[1], "conf: ", item[2]
