Autor: Zeng Zhiwei
Link: https://zhuanlan.zhihu.com/p/96633352
Quelle: Zhihu
Ich verwende C# seit zwei oder drei Jahren, und dann wurde ich eines Tages plötzlich nach der grundlegenden Implementierung des C#-Wörterbuchs gefragt. Dies ließ mich darüber nachdenken, dass ich immer in einer Ausleihmentalität war und es einfach verwende. Ich habe nicht darüber nachgedacht und Ich habe überhaupt etwas über die zugrunde liegende Architektur gelernt. Denken Sie darüber nach. Kribbeln auf der Kopfhaut. Beginnen wir mit dem Erlernen einiger Dinge, die ich normalerweise als selbstverständlich verwende. Heute werde ich zunächst den Quellcode des Wörterbuchs lernen.
1. Lernen des Wörterbuch-Quellcodes
Bei der Dictionary-Implementierung analysieren wir es hauptsächlich, indem wir es mit dem Quellcode vergleichen. Die aktuelle Version im Vergleich zum Quellcode ist .Net Framwork 4.8 .
Quellcode-Adresse: dictionary.cs
Hier stellen wir hauptsächlich mehrere Schlüsselklassen und -objekte im Wörterbuch vor.
Folgen Sie dann dem Code, um den Vorgang des Einfügens, Löschens und Erweiterns durchzuführen .
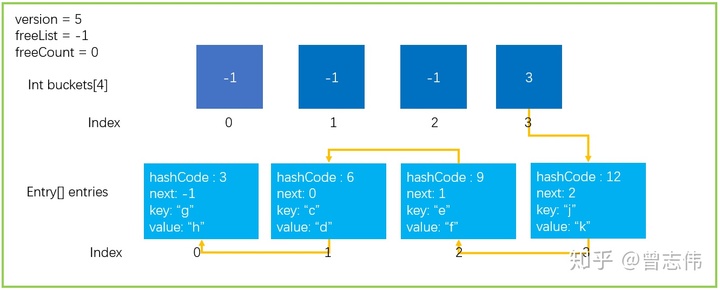
1. Eintragsstruktur
Zuerst führen wir eine Struktur wie Entry ein, deren Definition im folgenden Code gezeigt wird. Dies ist die kleinste Einheit zum Speichern von Daten in einem Dictionary. Add(Key,Value)Elemente, die durch aufrufende Methoden hinzugefügt werden, werden in einer solchen Struktur gekapselt.
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
2. Andere wichtige private Variablen
private int[] buckets; // Hash桶
private Entry[] entries; // Entry数组,存放元素
private int count; // 当前entries的index位置
private int version; // 当前版本,防止迭代过程中集合被更改
private int freeList; // 被删除Entry在entries中的下标index,这个位置是空闲的
private int freeCount; // 有多少个被删除的Entry,有多少个空闲的位置
private IEqualityComparer<TKey> comparer; // 比较器
private KeyCollection keys; // 存放Key的集合
private ValueCollection values; // 存放Value的集合
3. Struktur des Wörterbuchs
private void Initialize(int capacity)
{
int prime = HashHelpers.GetPrime(capacity);
this.buckets = new int[prime];
for (int i = 0; i < this.buckets.Length; i++)
{
this.buckets[i] = -1;
}
this.entries = new Entry<TKey, TValue>[prime];
this.freeList = -1;
}
Wir sehen, dass Dictionary beim Erstellen die folgenden Dinge tut:
- Initialisieren Sie ein this.buckets = new int[prime]
- Initialisieren Sie einen this.entries = new Entry<TKey, TValue>[prime]
- Die Kapazität von Bucket und Einträgen ist die kleinste Primzahl, die größer als die Wörterbuchkapazität ist.
Unter diesen wird this.buckets hauptsächlich für die Hash-Kollision verwendet , und this.entries wird zum Speichern des Wörterbuchinhalts und zum Identifizieren der Position des nächsten Elements verwendet.
4. Wörterbuch – Vorgang hinzufügen
public void Add(TKey key, TValue value) {
Insert(key, value, true);
}
int targetBucket = hashCode % buckets.Length;
Nehmen wir Dictionary<int,string> als Beispiel, um zu zeigen, wie Elemente zu Dictionary hinzugefügt werden:
Zuerst erstellen wir ein Wörterbuch, und dann ist die Kapazität von Bucket und Einträgen eine minimale Primzahl 7, die größer als die Kapazität des Wörterbuchs ist :
Dictionary<int, string> test = new Dictionary<int, string>(6);

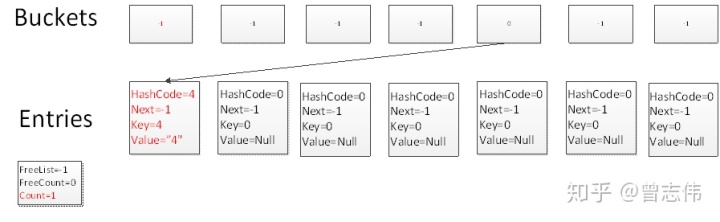
Test.Add(4,"4")
Gemäß dem Hash-Algorithmus: int targetBucket = hashCode % Buckets.Length; Buckets.Length ist gleich 7 , 4.GetHashCode()%7= 4 , also kollidiert es mit dem Slot mit Index 4 in Buckets. Zu diesem Zeitpunkt seit Count ist 0, daher wird das Element auf dem 0. Element in Einträgen platziert und Count wird nach dem Hinzufügen zu 1.
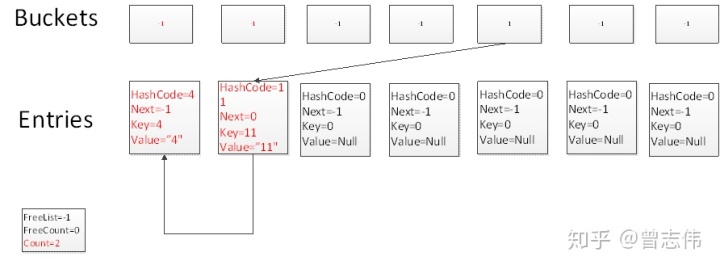
Test.Add(11,"11")
Gemäß dem Hash-Algorithmus 11.GetHashCode()%7= 4 kollidiert es erneut mit dem Slot mit Index 4 in Buckets. Da der Wert in diesem Slot nicht mehr -1 ist, ist Count=1 zu diesem Zeitpunkt, also ist dieser neue Wert hinzugefügt. Die Elemente werden in das Array mit dem Index 1 in Einträgen eingefügt, und der Buckets-Slot zeigt auf den Eintrag mit dem Index 1, und der Eintrag mit dem Index 1 befindet sich unter dem Eintrag mit dem Index 0.
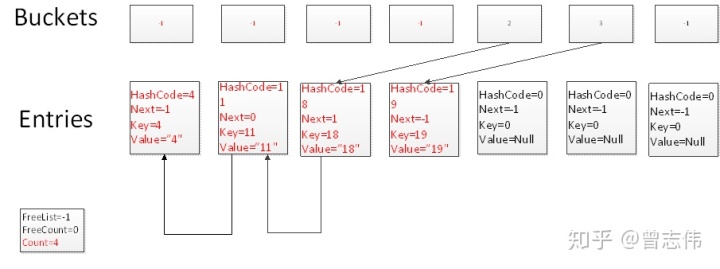
Test.Add(18,"18")
Test.Add(19,"19")
5. Wörterbuch – Vorgang entfernen
Test.Remove(4)
Wenn wir ein Element löschen, verwenden wir eine Kollision und suchen dreimal entlang der verknüpften Liste, um mit der Taste 4 die Position des Elements zu finden, und löschen das aktuelle Element. Zeigen Sie die Position von FreeList auf die Position des aktuell gelöschten Elements und setzen Sie FreeCount auf 1

Die gelöschten Daten bilden eine FreeList-verknüpfte Liste. Beim Hinzufügen von Daten werden die Daten zuerst zur FreeList-verknüpften Liste hinzugefügt. Wenn die FreeList leer ist, wird sie nach Anzahl geordnet.
6. Wörterbuch – Größenänderungsvorgang (Kapazitätserweiterung)
Aufmerksame Freunde möchten vielleicht fragen, nachdem sie den Add-buckets、entries Vorgang gesehen haben: Handelt es sich nicht nur um zwei Arrays? Was ist, wenn das Array voll ist? Als nächstes folgt der Vorgang „Größe ändern“ (Kapazitätserweiterung) , den ich einführen möchte, um unsere Kapazität zu buckets、entrieserweitern .
6.1 Auslösebedingungen für Erweiterungsvorgänge
Zunächst müssen wir wissen, unter welchen Umständen Expansionsmaßnahmen durchgeführt werden;
Die erste Situation ist natürlich, dass das Array voll ist und es keine Möglichkeit gibt, neue Elemente zu speichern. Wie in der Abbildung unten gezeigt.
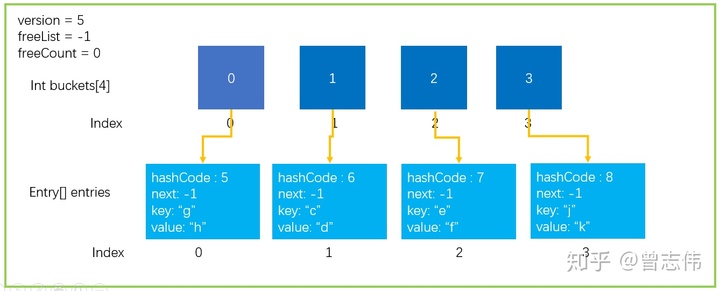
Zweitens treten im Wörterbuch zu viele Kollisionen auf, die die Leistung erheblich beeinträchtigen und Erweiterungsvorgänge auslösen.
Hash-Operationen führen unweigerlich zu Konflikten. Die Zipper-Methode wird im Wörterbuch verwendet , um das Konfliktproblem zu lösen. Schauen Sie sich jedoch die Situation im Bild unten an. Alle Elemente fallen genau auf Buckets[3], was zu einer zeitlichen Komplexität von O(n) führt und die Suchleistung sinkt;
6.2 So führen Sie einen Kapazitätserweiterungsvorgang durch
Um Ihnen eine klare Demonstration zu geben, wird die folgende Datenstruktur simuliert , ein Wörterbuch der Größe 2, unter der Annahme, dass der Kollisionsschwellenwert 2 beträgt; jetzt wird die Hash-Kollisionserweiterung ausgelöst.
- 1. Beantragen Sie Buckets und Einträge, die doppelt so groß sind wie die aktuelle Größe
- 2. Kopieren Sie vorhandene Elemente in neue Einträge
- 3. Wenn es sich um eine Hash-Kollisionserweiterung handelt, verwenden Sie die neue HashCode-Funktion, um den Hash-Wert neu zu berechnen.
- 4. Für jedes Eintragselement bestimmt Bucket = newEntries[i].hashCode % newSize die Position der neuen Buckets.
- 5、重建hash链,newEntries[i].next=buckets[bucket]; Buckets[Bucket]=i;
Fokuspunkt
In Bezug auf das Implementierungsprinzip von Dictionary gibt es zwei Schlüsselalgorithmen:
- Einer davon ist der Hash- Algorithmus.
- Einer wird zur Lösung von Hash-Kollisionskonflikten verwendet .
2. Hash -Algorithmus
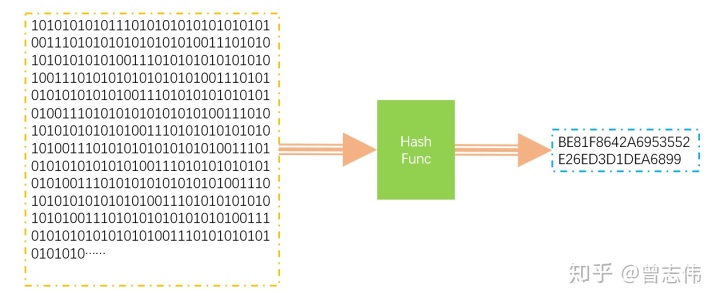
Der Hash - Algorithmus ist ein digitaler Digest- Algorithmus, der einen Binärdatensatz variabler Länge einem Datensatz kürzerer Binärlänge zuordnet .
Die Funktion, die den Hash-Algorithmus implementiert, wird Hash-Funktion genannt . Die Hash-Funktion weist die folgenden Eigenschaften auf.
Wenn dieselben Daten einer Hash-Operation unterzogen werden, müssen die erhaltenen Ergebnisse dieselben sein.HashFunc(key1) == HashFunc(key1)
Wenn Hash-Operationen für verschiedene Daten ausgeführt werden, können die Ergebnisse gleich sein (es kommt zu Hash-Kollisionen ).key1 != key2 => HashFunc(key1) == HashFunc(key2).Der
Hash-Vorgang ist irreversibel und die Originaldaten können nicht per Schlüssel abgerufen werden.key1 => hashCodeAberhashCode ==> key1.
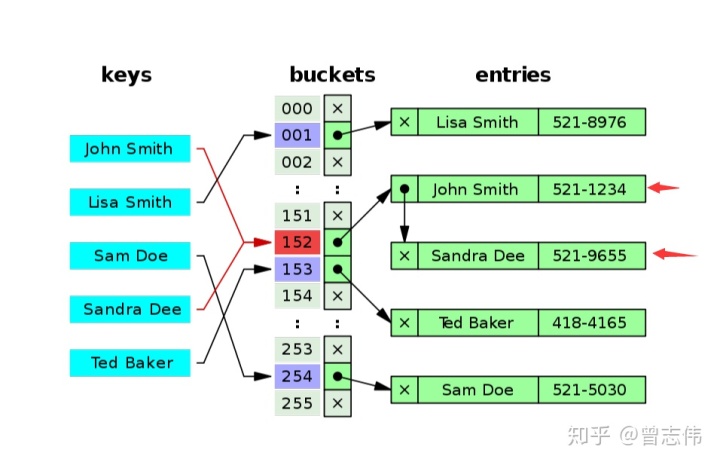
Die folgende Abbildung zur Hash-Kollision wird anschaulich erklärt. Aus der Abbildung ist ersichtlich, dass beide Sandra Deenach John Smithder Hash-Operation in 02Positionen fallen, was zu Kollisionen und Konflikten führt.

Zu den gängigen Algorithmen zum Erstellen von Hash-Funktionen gehören die folgenden.
- 1. Direkte Adressierungsmethode: Nehmen Sie das Schlüsselwort oder einen linearen Funktionswert des Schlüsselworts als Hash-Adresse. Das heißt, H(key)=key oder H(key) = a·key + b, wobei a und b Konstanten sind (eine solche Hash-Funktion wird als eigene Funktion bezeichnet),
Die Anwendung hierfür ist beispielsweise für die Maske unserer Weltkarte. Wir verwenden direkt die Koordinaten x * 1000 + die Koordinaten y, um den Schlüssel zu erhalten.
- 2. Zahlenanalysemethode: Ermitteln Sie die Zahlenmuster und verwenden Sie diese Daten so weit wie möglich, um eine Hash-Adresse mit geringer Konfliktwahrscheinlichkeit zu erstellen.
Bei der Analyse einer Reihe von Daten, beispielsweise des Geburtsdatums einer Gruppe von Mitarbeitern, stellen wir fest, dass die ersten paar Ziffern des Geburtsdatums ungefähr gleich sind. In diesem Fall ist die Wahrscheinlichkeit eines Konflikts sehr hoch, aber wir stellen fest, dass dies der Fall ist Jahr, Monat und Tag. Die letzten Ziffern, die den Monat und das spezifische Datum darstellen, sind sehr unterschiedlich. Wenn die letzteren Ziffern zur Bildung einer Hash-Adresse verwendet werden, wird die Wahrscheinlichkeit eines Konflikts erheblich verringert.
- 3. Square-the-Middle-Methode: Nehmen Sie die mittleren Ziffern des quadrierten Schlüsselworts als Hash-Adresse.
- 4. Faltmethode: Schneiden Sie das Schlüsselwort in mehrere Teile mit der gleichen Anzahl von Ziffern. Der letzte Teil kann unterschiedliche Ziffern haben, und dann wird die Überlagerungssumme dieser Teile (übertragen entfernt) als Hash-Adresse verwendet.
- 5. Zufallszahlenmethode: Wählen Sie eine Zufallsfunktion und verwenden Sie den Zufallswert des Schlüsselworts als Hash-Adresse. Sie wird normalerweise in Situationen verwendet, in denen die Schlüsselwortlänge unterschiedlich ist.
- 6. Restmethode teilen und verlassen: Nehmen Sie den Rest, der erhalten wird, nachdem das Schlüsselwort durch eine Zahl p geteilt wurde, die nicht größer als die Länge der Hash-Tabelle m ist, als Hash-Adresse.
Das heißt, H(key) = key MOD p, p<=m. Das Schlüsselwort kann nicht nur direkt modulo sein, sondern auch nach Faltung, Quadrierung und anderen Operationen moduloisiert werden. Die Wahl von p ist sehr wichtig. Im Allgemeinen wird eine Primzahl oder m verwendet. Wenn p nicht gut gewählt ist, kann es leicht zu Kollisionen kommen.
7. Hash-Bucket-Algorithmus
Wenn es um den Hash-Algorithmus geht, denkt jeder an die Hash-Tabelle . Ein Schlüssel kann den HashCode schnell abrufen, nachdem er von der Hash-Funktion berechnet wurde. Durch die Zuordnung von HashCode kann er den Wert direkt abrufen.
Der Wert von HashCode ist jedoch im Allgemeinen gleich sehr groß, oft 2^32. Oben ist es unmöglich, für jeden HashCode eine Zuordnung anzugeben.
Aufgrund eines solchen Problems wird der generierte HashCode in segmentierter Form zugeordnet und jedes Segment wird als Bucket bezeichnet . Ein üblicher Hash-Bucket besteht darin, den Rest des Ergebnisses direkt zu übernehmen.
Nehmen Sie an, dass der generierte HashCode 2 ^ 32 Werte haben kann, teilen Sie ihn dann in Segmente auf und verwenden Sie
8
Buckets für die Zuordnung. Dann
bucketIndex = HashFunc(key1) % 8
kann ein solcher Algorithmus verwendet werden, um zu bestimmen, welchem spezifischen Bucket der HashCode zugeordnet ist.
Dictionary verwendet den Hash-Bucket-Algorithmus
int hashCode =comparer.GetHashCode(key)&0x7FFFFFFF;
int targetBucket = hashCode %buckets.Length;
3. Algorithmus zur Lösung von Hash-Kollisionskonflikten
Bei einem Hash-Algorithmus treten unweigerlich Konflikte auf, daher ist der Umgang mit Konflikten nach ihrem Auftreten ein sehr kritischer Punkt. Zu den gängigen Konfliktlösungsalgorithmen gehören derzeit die Zipper-Methode (wird in der Dictionary-Implementierung verwendet), die offene Adressierungsmethode und die Re-Hash-Methode . Gemeinsame Gesetze zur Zoneneinteilung bei Verschüttungen
1. Zipper-Methode ( offenes Hashing ): Erstellen Sie eine einfach verknüpfte Liste widersprüchlicher Elemente und speichern Sie die Kopfzeigeradresse an der Position des entsprechenden Buckets in der Hash-Tabelle. Auf diese Weise kann nach dem Auffinden des Speicherorts des Hash-Tabellen-Buckets das Element durch Durchlaufen der einfach verknüpften Liste gefunden werden.
2. Offene Adressierungsmethode (geschlossenes Hashing): Wenn ein Hash-Konflikt auftritt und die Hash-Tabelle nicht voll ist, bedeutet dies, dass eine leere Position in der Hash-Tabelle vorhanden sein muss, dann kann der Schlüssel an der Konfliktposition gespeichert werden. Als nächstes „Leere Position.
3. Re-Hash-Methode: Wie der Name schon sagt, wird der Schlüssel mithilfe anderer Hash-Funktionen erneut gehasht, bis eine nicht widersprüchliche Position gefunden wird.
1. Reißverschlussmethode
2. Offene Adressierungsmethode
Angenommen, es gibt einen Schlüsselcodesatz {1,4,5,6,7,9}, die Kapazität der Hash-Struktur beträgt 10 und die Hash-Funktion ist Hash(key)=key%10. Fügen Sie alle Schlüssel in die Hash-Struktur ein, wie in der Abbildung gezeigt.
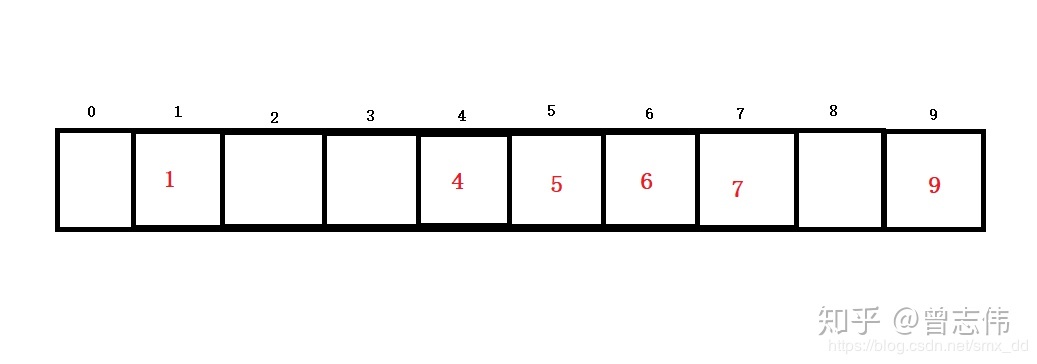
Wenn ein Schlüsselcode 24 in die Struktur eingefügt werden muss, lautet die mithilfe der Hash-Funktion erhaltene Hash-Adresse 4, das Element ist jedoch bereits an dieser Adresse gespeichert und es tritt ein Hash-Konflikt auf.
Lineare Erkennung: Beginnen Sie mit der Position, an der der Hash-Konflikt auftritt, und suchen Sie rückwärts, bis die nächste leere Position gefunden wird. Wenn beispielsweise im obigen Beispiel der Schlüsselcode 24 eingegeben wird, wird nach dem Einfügen eine lineare Erkennung durchgeführt, wie unten gezeigt.

Grenze:
1. Die Verwendung dieser Methode erfordert, dass der Schlüsselcode eine Ganzzahl sein muss, bevor er moduliert werden kann. Daher müssen wir nicht ganzzahlige Typen in ganzzahlige Typen konvertieren .
2. Der numerische Wert des Moduls ist vorzugsweise eine Primzahl, weshalb wir eine Primzahlentabelle erstellen müssen.
3. Problem der Kapazitätserweiterung.