Después de aprender los conceptos básicos de Python, si quieres avanzar, ¡hagamos algunos algoritmos! Después de todo, los lenguajes de programación son solo herramientas y los algoritmos estructurales son el alma.
¿Cómo puede un novato comenzar con los algoritmos de Python?
Varios hermanos indios crearon una guía para principiantes de varios algoritmos de Python en GitHub. Desde el principio hasta el código, todo se le explica claramente. Para permitir que los novatos entiendan de forma más intuitiva, algunas partes también están equipadas con animaciones.
https://github.com/TheAlgorithms/Python
Este proyecto incluye principalmente dos partes: una es la explicación de los principios básicos de varios algoritmos y la otra es la implementación del código de varios algoritmos.
Implementación de código de algoritmo
La información provista para la implementación del código del algoritmo también es relativamente rica.Además del código Python para los principios básicos del algoritmo, también hay implementaciones de código que incluyen redes neuronales, aprendizaje automático y matemáticas.
Por ejemplo, en la parte de la red neuronal, se dan la red neuronal BP, la red neuronal convolucional, la red neuronal completamente convolucional y el perceptrón.
Ejemplo de código de red neuronal convolucional
El código se guarda en GitHub en formato de archivo Python, y los estudiantes que lo necesiten pueden guardarlo y descargarlo ellos mismos.
https://github.com/TheAlgorithms/Python
Principio del algoritmo
En la parte del principio del algoritmo, presenta principalmente el algoritmo de clasificación, el algoritmo de búsqueda, el algoritmo de interpolación, el algoritmo de búsqueda por salto, el algoritmo de selección rápida, el algoritmo de búsqueda tabú, el algoritmo de encriptación, etc.
Por supuesto, además de las explicaciones de texto, también se proporcionan enlaces a los recursos correspondientes para ayudar a comprender mejor el algoritmo, incluidos enlaces a Wikipedia y sitios web interactivos de animación.
Por ejemplo, en algunas secciones de algoritmos, los enlaces interactivos de animación proporcionados son perfectos para ayudar a comprender el mecanismo operativo del algoritmo.

Dirección de animación interactiva:
https://www.toptal.com/developers/sorting-algorithms/bubble-sort
Algoritmo de clasificación
Ordenamiento de burbuja

La clasificación de burbujas, a veces llamada clasificación de hundimiento, es un algoritmo de clasificación relativamente simple. Este algoritmo se implementa recorriendo la lista que se va a ordenar, intercambiando las posiciones de dos elementos de datos adyacentes que no se ajustan a las reglas de disposición y luego recorriendo repetidamente la lista hasta que no haya más elementos de datos que deban intercambiarse. La lista se ordena cuando no es necesario intercambiar elementos de datos.
algoritmo de ordenación de cubos
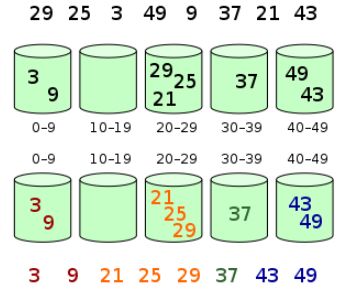
La clasificación por cubos, o la llamada clasificación por contenedores, es un algoritmo de clasificación que funciona dividiendo una matriz en un número finito de cubos. Cada cubeta se ordena individualmente y es posible utilizar otro algoritmo de clasificación o seguir utilizando la clasificación de cubetas de forma recursiva para la clasificación.
tipo de coctel

La clasificación de cóctel, también conocida como clasificación de burbuja dirigida, clasificación de agitación de cóctel, clasificación de agitación (que también puede verse como una variación de clasificación de selección), clasificación de ondulación, clasificación de ida y vuelta o clasificación de hora feliz, es una variación de clasificación de burbuja. La diferencia entre este algoritmo y la clasificación de burbuja es que la clasificación se realiza en secuencia en ambas direcciones.
Nota del traductor:
El tipo cóctel es una ligera variante del tipo burbuja. La diferencia es que va de menor a mayor y luego de mayor a menor, mientras que la ordenación de burbujas solo compara cada elemento en la secuencia de menor a mayor. Puede obtener un rendimiento ligeramente mejor que la clasificación de burbujas, porque la clasificación de burbujas solo compara desde una dirección (de menor a mayor) y solo mueve un elemento por bucle.
Tomando la secuencia (2,3,4,5,1) como ejemplo, la clasificación de cócteles solo necesita visitar la secuencia una vez para completar la clasificación, pero si usa la clasificación de burbujas, necesita cuatro veces. Pero en el estado de secuencia de números aleatorios, la eficiencia de la clasificación de cócteles y la clasificación de burbujas es muy pobre.
tipo de inserción

La clasificación por inserción es un algoritmo de clasificación simple e intuitivo. Funciona mediante la construcción de una secuencia ordenada y, para los datos no clasificados, escanea de atrás hacia adelante en la secuencia ordenada, encuentra la posición correspondiente y la inserta. En la implementación de la clasificación por inserción, el espacio extra de la clasificación en el lugar se usa generalmente para la clasificación. Por lo tanto, en el proceso de escaneo de atrás hacia adelante, es necesario desplazar repetidamente los elementos ordenados hacia atrás gradualmente para proporcionar espacio de inserción para el últimos elementos.
ordenar por fusión
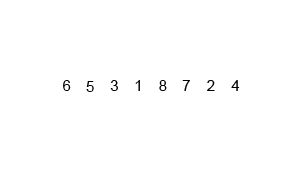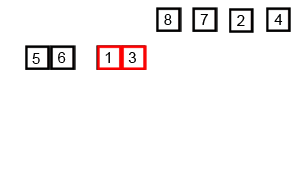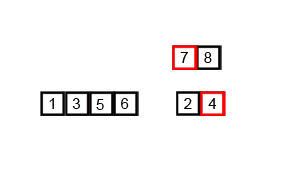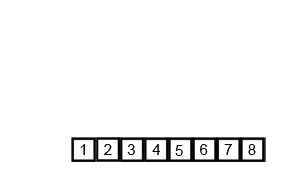
Merge sort (Merge sort o mergesort) es un algoritmo de clasificación efectivo creado en la operación de fusión, con una eficiencia de O (n log n) (notación O grande). Fue propuesto por primera vez por John von Neumann en 1945. Este algoritmo es una aplicación muy típica de Divide and Conquer, y cada capa de recursividad de Divide and Conquer se puede realizar simultáneamente.
Montón
Heap es un algoritmo de clasificación basado en la comparación. Se puede considerar como una clasificación de selección mejorada. Divide su entrada en regiones ordenadas y no ordenadas y reduce iterativamente la región no ordenada extrayendo el elemento más grande y moviéndolo a la región ordenada.
Nota del traductor:
Heap comenzó con la ordenación de montón publicada por J._W._J._Williams en 1964, cuando propuso el árbol de montón binario como la estructura de datos de este algoritmo.
En la cola, el programador extrae repetidamente el primer trabajo de la cola y lo ejecuta, porque en realidad, algunas tareas con poco tiempo esperarán mucho tiempo para terminar, o algunos trabajos que no son cortos pero importantes, también deberían tener prioridad. El montón es una estructura de datos diseñada para resolver este tipo de problemas.
ordenamiento radix
Radix sort (Radix sort) es un algoritmo de clasificación de enteros no comparativo. Su principio es dividir el entero en diferentes números de acuerdo con los dígitos, y luego comparar cada dígito por separado. Dado que los números enteros también pueden representar cadenas (como nombres o fechas) y números de punto flotante en ciertos formatos, la ordenación de raíz no se limita a los números enteros. La invención de la clasificación radix se remonta a la contribución de Herman Hollery en la máquina de tabulación de tarjetas perforadas (Máquina de tabulación) en 1887.
clasificación de selección

La clasificación por selección es un algoritmo de clasificación simple e intuitivo. Funciona de la siguiente manera. Primero encuentre el elemento más pequeño (más grande) en la secuencia sin clasificar, guárdelo al comienzo de la secuencia ordenada, luego continúe buscando el elemento más pequeño (más grande) de los elementos sin clasificar restantes y luego colóquelo al final de la secuencia ordenada . Y así sucesivamente hasta que todos los elementos estén ordenados.
Shellsort

ShellSort es una generalización de la ordenación por inserción que permite intercambiar elementos que están muy separados. La idea es organizar la lista de elementos de modo que comience desde cualquier lugar, teniendo en cuenta que cada n-ésimo elemento da una lista ordenada. Tal lista se llama ordenada por h. De manera equivalente, se puede considerar como una lista irregular de h, con cada elemento ordenado individualmente.
topología
Una clasificación topológica, o clasificación topológica de un gráfico dirigido, es una ordenación lineal de sus vértices de modo que para cada borde dirigido uv desde el vértice u hasta el vértice v, u viene antes que v en la clasificación. Por ejemplo, los vértices de un gráfico pueden representar tareas a realizar y los bordes pueden representar restricciones de que una tarea debe realizarse antes que otra; en esta aplicación, la clasificación topológica es simplemente una secuencia válida de tareas. La clasificación topológica es posible si y solo si el gráfico no tiene ciclos dirigidos, es decir, si es un gráfico acíclico dirigido (DAG). Cualquier DAG tiene al menos un tipo topológico, y se conocen algoritmos para construir el tipo topológico de cualquier DAG en tiempo lineal.
Gráfico de líneas complejas de tiempo
Comparación de la complejidad de los algoritmos de clasificación (clasificación de burbujas, clasificación por inserción, clasificación por selección)
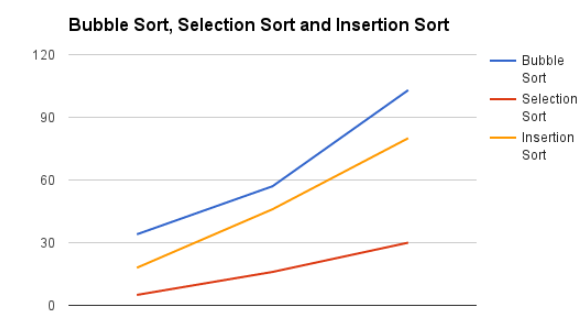
Algoritmo de clasificación de comparación:
Quicksort es un algoritmo muy rápido, pero bastante complicado de implementar. Bubble sort es un algoritmo lento, pero fácil de implementar. Para clasificar conjuntos de datos pequeños, la clasificación por burbuja podría ser una mejor opción.
algoritmo de búsqueda
búsqueda lineal

La búsqueda lineal o búsqueda secuencial es el método utilizado para encontrar el valor objetivo en la lista. Comprueba secuencialmente cada elemento de la lista para el valor de destino hasta que se encuentra una coincidencia o hasta que se buscan todos los elementos.
Suponiendo que hay N elementos en una matriz, el mejor caso es que el valor específico que está buscando sea el primer elemento de la matriz, por lo que solo se requiere una comparación. Y el peor de los casos es que el valor específico que está buscando no está en esta matriz ni en el último elemento de la matriz, lo que requiere N comparaciones.
Búsqueda binaria binaria

La búsqueda binaria, también conocida como búsqueda de semiintervalo o búsqueda logarítmica, se utiliza para encontrar la posición de un valor objetivo en una matriz ordenada. Compara el valor objetivo con el elemento medio de la matriz, si no son iguales, se elimina la mitad del objetivo y la búsqueda continúa en la mitad restante hasta que tiene éxito.
búsqueda de interpolación
La búsqueda por interpolación es un algoritmo para buscar claves en una matriz ya ordenada por el valor de la clave.
Descrito por primera vez por WW Peterson en 1957. Las búsquedas de interpolación son similares a cómo las personas buscan nombres en los directorios telefónicos (la clave utilizada para ordenar las entradas de los libros): en cada paso, el algoritmo calcula la posición en el espacio de búsqueda restante, en función de los valores clave en los límites de la el espacio de búsqueda y el El valor de la clave generalmente se puede encontrar mediante interpolación lineal para encontrar el elemento.
Por el contrario, la búsqueda binaria siempre elige la mitad del espacio de búsqueda restante, descartando la mitad o la otra mitad, según la comparación entre la clave encontrada en la posición estimada y la clave buscada. El espacio de búsqueda restante se reduce a la parte anterior o posterior a la posición estimada. La búsqueda lineal solo usa la igualdad porque compara los elementos uno por uno desde el principio, ignorando cualquier orden.
Las búsquedas de interpolación promedio hacen comparaciones log(log(n)) (si los elementos están distribuidos uniformemente), donde n es el número de elementos a buscar. En el peor de los casos (por ejemplo, el valor numérico de la clave aumenta exponencialmente), puede constituir comparaciones O(n).
En una búsqueda secuencial interpolada, la interpolación se usa para encontrar elementos que están cerca del elemento que se busca y luego se usa una búsqueda lineal para encontrar el elemento exacto.
búsqueda de salto
Jump search se refiere al algoritmo de búsqueda de listas ordenadas. Primero verifica el Lkm de todos los elementos, donde K ∈ N, y m es el tamaño del bloque, hasta que se encuentra un elemento más grande que la clave de búsqueda. Para encontrar la posición exacta de la clave de búsqueda en la lista, se realiza una búsqueda lineal en la sublista L[(k-1)m, km].
El valor óptimo de m es √n, donde n es la longitud de la lista L. Debido a que ambos pasos del algoritmo son como máximo √n términos, el algoritmo se ejecuta en tiempo O(√n). Esto es mejor que la búsqueda lineal, pero peor que la búsqueda binaria. La ventaja sobre este último es que una búsqueda de salto solo necesita retroceder una vez, mientras que un binario puede retroceder a un registro n veces.
El algoritmo se puede modificar realizando múltiples niveles de búsquedas de salto en sublistas antes de realizar finalmente una búsqueda lineal. Para la búsqueda de salto de nivel k, el tamaño de bloque óptimo ml (contando desde 1) en el nivel l es n(k1)/k. El algoritmo modificado realizará k saltos hacia atrás y se ejecutará en el tiempo O(kn1/(k+1)).
Algoritmo de selección rápida
Quicksort (Quicksort) es un algoritmo de selección que encuentra el k-ésimo elemento más pequeño de una lista desordenada. Está en principio relacionado con quicksort. Al igual que el ordenamiento rápido, fue propuesto por Tony Hall, por lo que también se le llama algoritmo de selección de Hall. Del mismo modo, es un algoritmo eficiente en aplicaciones prácticas, con una buena complejidad de tiempo promedio, pero la peor complejidad de tiempo no es la ideal. La selección rápida y sus variantes son los algoritmos de selección eficiente más utilizados en aplicaciones prácticas.
La idea general de la selección rápida es la misma que la de la ordenación rápida. Se selecciona un elemento como punto de referencia para dividir los elementos, y los elementos más pequeños y más grandes que el punto de referencia se dividen en dos áreas a la izquierda y a la derecha del punto de referencia. . La diferencia es que la selección rápida no visita recursivamente ambos lados, sino que solo ingresa recursivamente los elementos de un lado para continuar buscando. Esto reduce la complejidad del tiempo promedio de O(n log n) a O(n), aunque el peor de los casos sigue siendo O(n2).
búsqueda tabú
Tabu Search (Tabu Search, TS, también conocido como Tabu Search) es un algoritmo heurístico moderno, que fue propuesto por Fred Glover, profesor de la Universidad de Colorado, alrededor de 1986. Es un método de búsqueda utilizado para escapar de las soluciones óptimas locales. . Primero crea una solución inicial; en base a esto, el algoritmo "se mueve" a una solución adyacente. Mejorar la calidad de la solución en muchos movimientos sucesivos.
contraseña
cifrado césar
El cifrado César, también conocido como cifrado César, cifrado de desplazamiento, código César o desplazamiento de César, es una de las técnicas de cifrado más sencillas y conocidas.
Es un cifrado de sustitución en el que cada letra del texto sin formato se reemplaza por una letra en un número fijo de posiciones en el alfabeto. Por ejemplo, desplazar a la izquierda por 3, D será reemplazado por A, E se convertirá en B, y así sucesivamente.
El método lleva el nombre de Julio César, quien originalmente lo usó en su correspondencia privada. El paso de cifrado realizado por el cifrado César se usa a menudo como parte de un esquema más complejo, como el cifrado Vigenère, y todavía tiene una aplicación moderna en el sistema ROT13. Como todos los cifrados de sustitución de una sola letra, los cifrados César son fáciles de descifrar y son esencialmente inseguros para las comunicaciones en la práctica moderna.
Cifrado Vigenère
Un cifrado de Vigenère es un método para cifrar texto alfabético mediante el uso de una serie de cifrados César intercalados basados en letras clave. Es una forma alternativa de varias letras.
Cifrado de Vigenère Este método fue propuesto por primera vez por Giovan Battista Bellaso en su libro de 1553 "La cifra del". Sin embargo, el esquema fue luego mal utilizado en Blaise de Vigenère en el siglo XIX y ahora es ampliamente conocido como el "cifrado de Vigenère".
Aunque el cifrado es fácil de entender e implementar, ha resistido todos los intentos de descifrarlo durante tres siglos, de ahí el nombre le chiffre indé chiffrable (en francés, "cifrado incomprensible"). Friedrich Kasiski fue el primero en publicar un método general para descifrar el cifrado de Vigenère en 1863.
cifra de transposición
Un cifrado de transposición es un método de cifrado mediante el cual las posiciones que ocupan las unidades de texto sin formato (generalmente caracteres o grupos de caracteres) se desplazan de acuerdo con un sistema convencional, de modo que el texto cifrado constituye una disposición de texto sin formato. Es decir, cambia el orden de las unidades (se reordena el texto plano).
Matemáticamente, se utiliza una función de dos caracteres para cifrar la posición del carácter y una función inversa para descifrar.
RSA (Rivest-Shamir-Adleman)
El algoritmo de cifrado RSA es un algoritmo de cifrado asimétrico. RSA se usa ampliamente en el cifrado de clave pública y el comercio electrónico. RSA fue propuesto en 1977 por Ronald Rivest, Adi Shamir y Leonard Adleman. Los tres trabajaban en el MIT en ese momento. RSA se compone de las letras iniciales de sus tres apellidos.
En 1973, el matemático Clifford Cocks, que trabajaba en GCHQ, propuso un algoritmo equivalente en un documento interno, pero fue clasificado hasta 1997. hacerse público.
ROT13
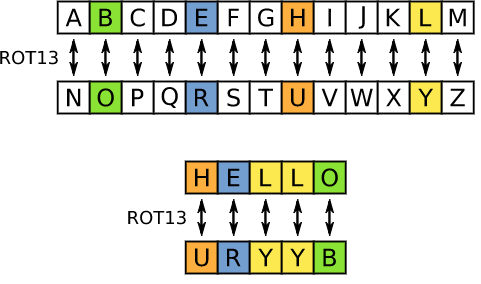
ROT13 ("rotar 13 posiciones", a veces con el guión ROT-13) es un cifrado de sustitución de letra simple que reemplaza una letra con la letra 13 después del alfabeto. ROT13 es un caso especial del cifrado César desarrollado en la antigua Roma.
Debido a que hay 26 letras (2×13) en el alfabeto latino básico, ROT13 es el inverso de sí mismo, es decir, para deshacer ROT13 se requiere el mismo algoritmo, por lo que se pueden usar las mismas acciones para codificar y decodificar. Este algoritmo proporciona poca seguridad criptográfica y, a menudo, se cita como un ejemplo clásico de cifrado débil.