fondointroducir
Actualmente, las GPU se utilizan ampliamente en la plataforma de aprendizaje profundo iQiyi. La GPU tiene cientos o miles de núcleos de procesamiento y puede ejecutar una gran cantidad de instrucciones en paralelo, lo que la hace muy adecuada para cálculos relacionados con el aprendizaje profundo. Las GPU se han utilizado ampliamente en modelos CV (visión por computadora) y NLP (procesamiento de lenguaje natural). En comparación con las CPU, generalmente pueden completar el entrenamiento y la inferencia del modelo de manera más rápida y económica.
El modelo CTR (tasa de clics) se usa ampliamente en recomendaciones, publicidad, búsqueda y otros escenarios para estimar la probabilidad de que un usuario haga clic en un anuncio o video. Las GPU se han utilizado ampliamente en el escenario de entrenamiento del modelo CTR, lo que mejora la velocidad de entrenamiento y reduce los costos de servidor requeridos.
Pero en el escenario de inferencia, cuando implementamos directamente el modelo entrenado en la GPU a través del servicio Tensorflow, encontramos que el efecto de inferencia no es ideal. aparece en:
-
La latencia de inferencia es alta. Los modelos de tipo CTR suelen estar orientados al usuario final y son muy sensibles a la latencia de inferencia.
-
La utilización de la GPU es baja y la potencia informática no se utiliza por completo.
Análisis de causa
herramienta de análisis
-
Tensorflow Board, una herramienta proporcionada oficialmente por tensorflow, puede ver visualmente el tiempo que lleva cada etapa en el gráfico de flujo de cálculo y resumir el tiempo total que consumen los operadores.
-
Nsight es un conjunto de herramientas de desarrollo proporcionado por NVIDIA para desarrolladores de CUDA. Puede realizar seguimiento, depuración y análisis de rendimiento de nivel relativamente bajo de programas CUDA.
Conclusión del análisis
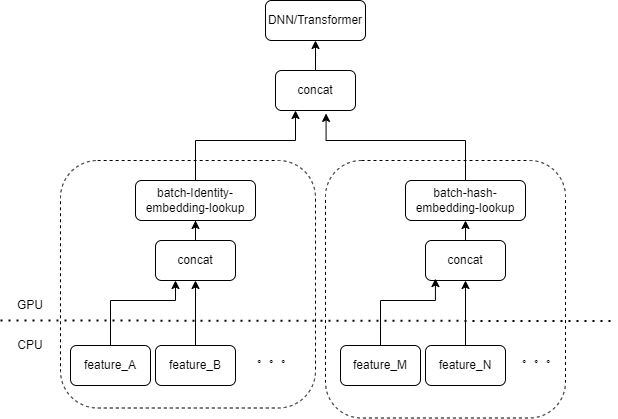
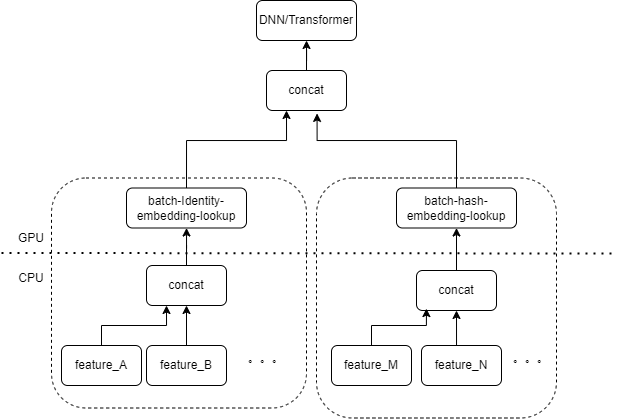
La entrada típica del modelo CTR contiene una gran cantidad de funciones dispersas (como ID de dispositivo, ID de video visto recientemente, etc.). FeatureColumn de Tensorflow procesará estas características. Primero, se realizan operaciones de identidad/hash para obtener el índice de la tabla de incrustación. Después de las operaciones de búsqueda de incrustación y promediado, se obtiene el tensor de incrustación correspondiente. Después de empalmar los tensores de incrustación correspondientes a múltiples características, se obtiene un nuevo tensor y luego ingresa al DNN / Transformador posterior y otras estructuras.
Por lo tanto, cada característica dispersa activará varios operadores en la capa de entrada del modelo. Cada operador corresponderá a uno o varios cálculos de GPU, es decir, cuda kernel. Cada kernel de cuda incluye dos etapas, iniciar el kernel de cuda (la sobrecarga necesaria para iniciar el kernel) y ejecutar el kernel (en realidad, realizar cálculos matriciales en el núcleo de cuda). El operador correspondiente a la búsqueda de identidad/hash/incrustación de características dispersas tiene una pequeña cantidad de cálculo, y el lanzamiento del kernel a menudo lleva más tiempo que el tiempo de ejecución del kernel. En términos generales, el modelo CTR contiene de docenas a cientos de funciones escasas y, en teoría, habrá cientos de núcleos de lanzamiento, que es el principal cuello de botella de rendimiento actual.
Este problema no se encontró al usar GPU para entrenar el modelo CTR. Debido a que la capacitación en sí es una tarea fuera de línea y no presta atención a los retrasos, el tamaño del lote durante la capacitación puede ser muy grande. Aunque el kernel de lanzamiento aún se ejecutará varias veces, siempre que la cantidad de muestras calculadas al ejecutar el kernel sea lo suficientemente grande, el tiempo promedio dedicado a cada muestra del kernel de lanzamiento será muy pequeño. Para escenarios de inferencia en línea, si se requiere Tensorflow Serving para recibir suficientes solicitudes de inferencia y fusionar lotes antes de realizar los cálculos, la latencia de inferencia será muy alta.
Mejoramiento
Nuestro objetivo es optimizar el rendimiento sin cambiar básicamente el código de capacitación o el marco del servicio. Naturalmente, pensamos en dos métodos: reducir la cantidad de núcleos iniciados y mejorar la velocidad de inicio del núcleo.
Fusión de operadores
La operación básica es fusionar múltiples operaciones u operadores consecutivos en un solo operador. Por un lado, puede reducir la cantidad de inicios del kernel de cuda. Por otro lado, algunos resultados intermedios durante el proceso de cálculo se pueden almacenar en registros o compartir. memoria, y solo en el cálculo. Al final de la subsección, los resultados del cálculo se escriben en la memoria cuda global.
Hay dos métodos principales.
-
Fusión automática basada en compilador de aprendizaje profundo
-
Fusión manual de operadores para empresas
fusión automática
Hemos probado varios compiladores de aprendizaje profundo, como TVM/TensorRT/XLA, y las pruebas reales pueden lograr la fusión de una pequeña cantidad de operadores en DNN, como MatrixMat/ADD/Relu continuo. Dado que TVM/TensorRT necesita exportar formatos intermedios como onnx, es necesario modificar el proceso en línea del modelo original. Entonces usamos tf.ConfigProto() para habilitar el XLA integrado de tensorflow para la fusión.
Sin embargo, la fusión automática no tiene un buen efecto de fusión en los operadores relacionados con funciones escasas.
Fusión manual del operador
Naturalmente, pensamos que si hay varias funciones procesadas por el mismo tipo de combinación FeatureColumn en la capa de entrada, entonces podemos implementar un operador para unir la entrada de múltiples funciones en una matriz como la entrada del operador. La salida del operador es un tensor, y la forma de este tensor es consistente con la forma del tensor obtenido al calcular las características originales por separado y luego concatenarlas.
Tomando como ejemplo la combinación original IdentityCategoricalColumn + EmbeddingColumn, implementamos el operador BatchIdentiyEmbeddingLookup para lograr la misma lógica de cálculo.
Para facilitar el uso de los estudiantes de algoritmos, hemos encapsulado un nuevo FusedFeatureLayer para reemplazar el FeatureLayer nativo. Además de incluir el operador de fusión, también se implementa la siguiente lógica:
-
La lógica fusionada entra en vigor durante la inferencia y la lógica original se utiliza durante el entrenamiento.
-
Las características deben ordenarse para garantizar que las características del mismo tipo se puedan organizar juntas.
-
Dado que la entrada de cada característica es de longitud variable, aquí generamos una matriz de índice adicional para marcar a qué característica pertenece cada elemento de la matriz de entrada.
Para empresas, solo es necesario reemplazar el FeatureLayer original para lograr el efecto de integración.
El núcleo de lanzamiento que se probó originalmente cientos de veces se redujo a menos de 10 veces después de la fusión manual. La sobrecarga de iniciar el kernel se reduce considerablemente.
MultiStream mejora la eficiencia del lanzamiento
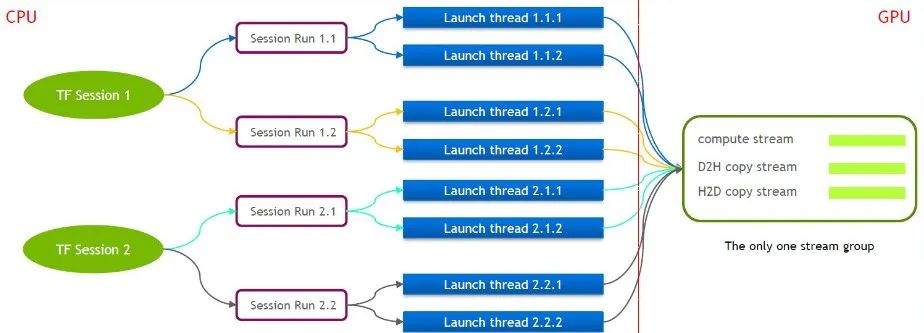
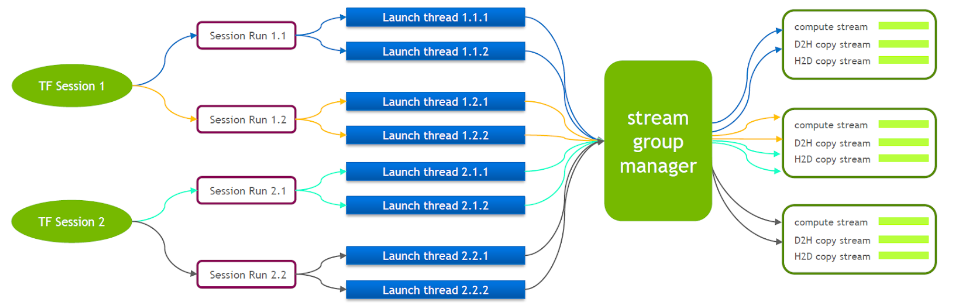
TensorFlow en sí es un modelo de flujo único que contiene solo un grupo Cuda Stream (compuesto por Compute Stream, H2D Stream, D2H Stream y D2D Stream). Varios núcleos solo se pueden ejecutar en serie en el mismo Compute Stream, lo cual es ineficiente. Incluso si el kernel cuda se inicia a través de múltiples sesiones de tensorflow, aún se requiere la cola en el lado de la GPU.
Por este motivo, el equipo técnico de NVIDIA mantiene su propia rama de Tensorflow para soportar la ejecución simultánea de múltiples Stream Groups. Esto se utiliza para mejorar la eficiencia del lanzamiento del kernel cuda. Hemos trasladado esta función a nuestro servicio Tensorflow.
Cuando se está ejecutando Tensorflow Serving, es necesario activar Nvidia MPS para reducir la interferencia mutua entre múltiples contextos CUDA.
Optimización de copias de datos pequeños
Según la optimización anterior, hemos optimizado aún más la copia de datos pequeños. Después de que Tensorflow Serving deserializa los valores de cada característica de la solicitud, llama a cudamemcpy varias veces para copiar los datos del host al dispositivo. La cantidad de llamadas depende de la cantidad de funciones.
Para la mayoría de los servicios CTR, en realidad se mide que cuando el tamaño del lote es pequeño, será más eficiente unir primero los datos en el lado del host y luego llamar a cudamemcpy de una vez.
Fusionar lotes
En el escenario de GPU, es necesario habilitar la combinación por lotes. De forma predeterminada, Tensorflow Serving no fusiona solicitudes. Para utilizar mejor las capacidades de computación paralela de la GPU, se pueden incluir más muestras en un cálculo directo. Activamos la opción enable_batching de Tensorflow Serving en tiempo de ejecución para fusionar por lotes varias solicitudes. Al mismo tiempo, debe proporcionar un archivo de configuración por lotes, enfocándose en configurar los siguientes parámetros. Las siguientes son algunas de nuestras experiencias.
-
max_batch_size: el número máximo de solicitudes permitidas en un lote, que puede ser un poco mayor.
-
batch_timeout_micros: el tiempo máximo de espera para fusionar un lote. Incluso si el número del lote no alcanza max_batch_size, se calculará inmediatamente (la unidad es microsegundos). En teoría, cuanto mayor sea el requisito de retraso, menor será la configuración aquí. Lo mejor es configurarlo en menos de 5 milisegundos.
-
num_batch_threads: Máximo de subprocesos de inferencia simultáneos después de activar MPS, se puede configurar entre 1 y 4. Si hay más, aumentará el retraso.
Cabe señalar aquí que la mayoría de las características escasas ingresadas al modelo de clase CTR son características de longitud variable. Si el cliente no llega a un acuerdo especial, la duración de una determinada característica puede ser inconsistente en múltiples solicitudes. Tensorflow Serving tiene una lógica de relleno predeterminada, que rellena las funciones correspondientes con ceros para solicitudes más cortas. Para funciones de longitud variable, -1 se usa para representar nulo. El relleno predeterminado de 0 en realidad cambiará el significado de la solicitud original.
Por ejemplo, la identificación del video visto más recientemente por el usuario A es [3,5] y la identificación del video visto más recientemente por el usuario B es [7,9,10]. Si se completa de forma predeterminada, la solicitud se convierte en [[3,5,0], [7,9,10]]. En el procesamiento posterior, el modelo pensará que A ha visto recientemente 3 videos con ID 3, 5, 0.
Por lo tanto, modificamos la lógica de finalización de la respuesta de Tensorflow Serving. En este caso, la lógica de finalización será [[3,5,-1], [7,9,10]]. El significado de la primera línea sigue siendo que se vieron los vídeos 3 y 5.
efecto final
Después de varias optimizaciones mencionadas anteriormente, la latencia y el rendimiento han satisfecho nuestras necesidades y se han implementado en los servicios de transmisión en cascada y push personalizados recomendados. Los resultados del negocio son los siguientes:
-
El rendimiento aumenta más de 6 veces en comparación con el contenedor GPU nativo de Tensorflow.
-
La latencia es básicamente la misma que la de la CPU, lo que satisface las necesidades empresariales.
-
Al soportar el mismo QPS, el costo se reduce en más del 40%
Quizás tú también quieras ver
Este artículo se comparte desde la cuenta pública de WeChat: Equipo de productos de tecnología iQIYI (iQIYI-TP).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Plan de creación de fuentes OSC ". Los que están leyendo pueden unirse y compartir juntos.