Mecanismo de atención GAM
Mecanismo de atención GAM: un mecanismo de atención "global" que abarca dimensiones de canales espaciales y retiene información para amplificar las interacciones interdimensionales "globales".
Dirección del artículo: Mecanismo de atención global: retener información para mejorar las interacciones espaciales-canal
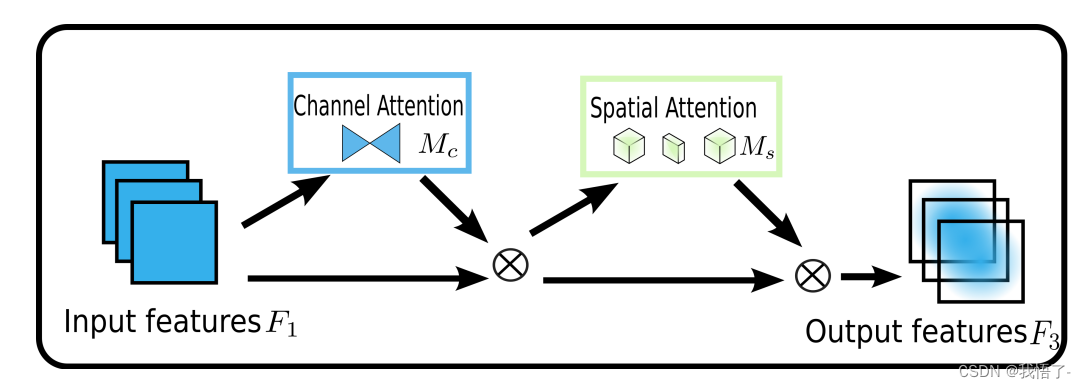
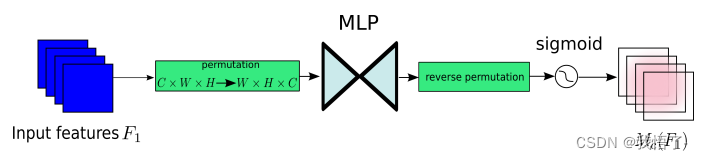
Submódulo de atención del canal
El submódulo de atención del canal utiliza una disposición tridimensional para preservar la información en tres dimensiones. Luego, utiliza un MLP (perceptrón multicapa) de dos capas para amplificar la dependencia interdimensional del espacio-canal. (MLP es una estructura codificador-decodificador, igual que BAM, y su relación de compresión es r); el submódulo de atención del canal se muestra en la figura:
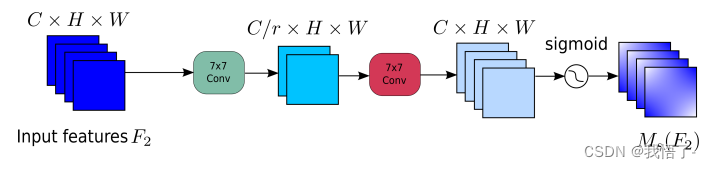
Submódulo de atención espacial
En el submódulo de atención espacial, para centrarse en la información espacial, se utilizan dos capas convolucionales para la fusión de información espacial. La misma relación de reducción r que BAM también se utiliza desde el submódulo de atención del canal. Al mismo tiempo, la operación de agrupación máxima tiene un impacto negativo porque reduce el uso de información. La operación de agrupación se elimina aquí para preservar aún más el mapeo de características. Por lo tanto, el módulo de atención espacial a veces aumenta significativamente el número de parámetros. Para evitar que los parámetros aumenten significativamente, en ResNet50 se adopta la convolución de grupo con Channel Shuffle. El submódulo de atención espacial sin convolución de grupo se muestra en la figura:
Código:
import torch.nn as nn
import torch
class GAM_Attention(nn.Module):
def __init__(self, in_channels, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), in_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(in_channels)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2).sigmoid()
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
x = torch.randn(1, 64, 20, 20)
b, c, h, w = x.shape
net = GAM_Attention(in_channels=c)
y = net(x)
print(y.size())