Mecanismo de atención ParNet
La atención de ParNet es un mecanismo de atención para tareas de procesamiento de lenguaje natural, que fue propuesto por Google en 2019. La atención de ParNet tiene como objetivo resolver el problema de eficiencia del mecanismo de atención tradicional cuando se trata de secuencias largas.
Cuando el mecanismo de atención tradicional calcula el peso de atención, necesita calcular las posiciones de todas las secuencias de entrada una por una, lo que conduce a una alta complejidad computacional en secuencias largas. Mientras que la atención de ParNet reduce la complejidad computacional al dividir la secuencia en múltiples subsecuencias y realizar cálculos de atención independientes en cada subsecuencia.
Dirección en papel: https://arxiv.org/pdf/2110.07641.pdf
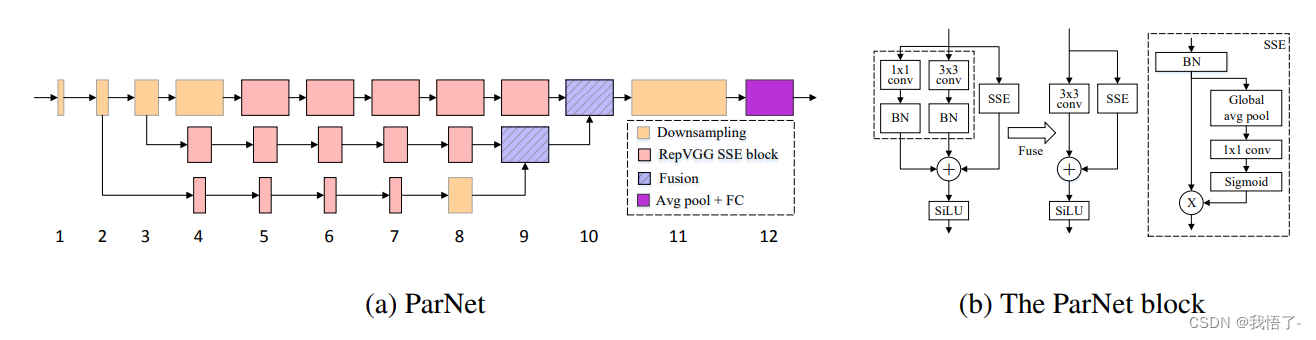
el código se muestra a continuación:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParNetAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sse = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel, channel, kernel_size=1),
nn.Sigmoid()
)
self.conv1x1 = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=1),
nn.BatchNorm2d(channel)
)
self.conv3x3 = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=3, padding=1),
nn.BatchNorm2d(channel)
)
self.silu = nn.SiLU()
def forward(self, x):
b, c, _, _ = x.size()
x1 = self.conv1x1(x)
x2 = self.conv3x3(x)
x3 = self.sse(x) * x
y = self.silu(x1 + x2 + x3)
return y
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
pna = ParNetAttention(channel=512)
output = pna(input)
print(output.shape)