1. SEBlock (mecanismo de atención del canal)
La compresión se realiza primero en la dimensión H*W y la agrupación promedio global promedia cada canal en un valor.
(B, C, H, W) ---- (B, C, 1, 1)
Utilice la correlación de cada dimensión del canal para calcular el peso
(B, C, 1, 1) --- (B, C//K, 1, 1) --- (B, C, 1, 1) --- sigmoideo
Multiplica las características originales para obtener las ponderadas.
import torch
import torch.nn as nn
class SELayer(nn.Module):
def __init__(self, channel, reduction = 4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) //自适应全局池化,只需要给出池化后特征图大小
self.fc1 = nn.Sequential(
nn.Conv2d(channel, channel//reduction, 1, bias = False),
nn.ReLu(implace = True),
nn.Conv2d(channel//reduction, channel, 1, bias = False),
nn.sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y_out = self.fc1(y)
return x * y_out2. CBAM (atención de canal + mecanismo de atención espacial)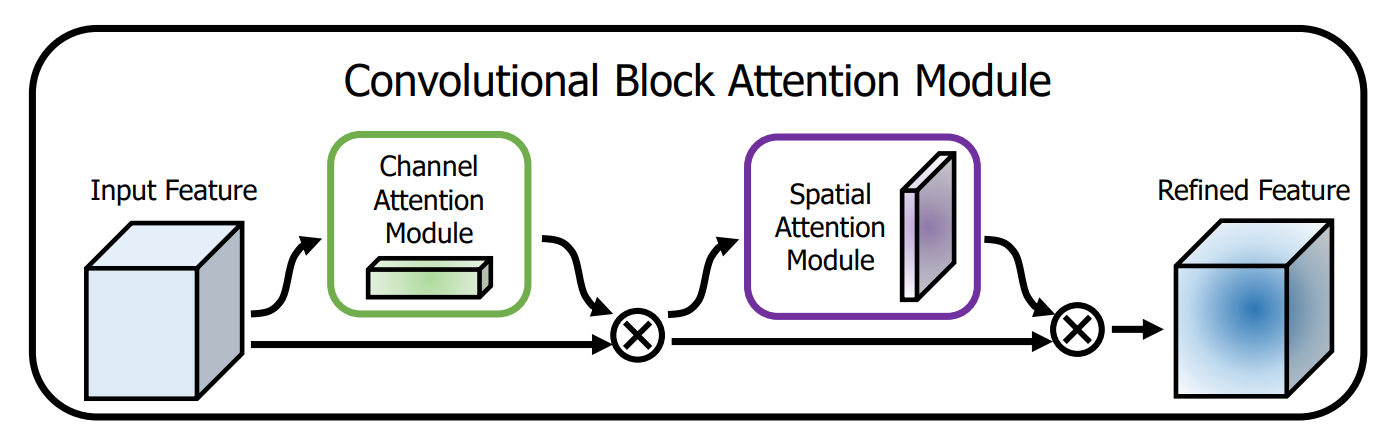
Existen tanto mecanismos de atención de canal como mecanismos de atención espacial en CBAM.
La atención del canal es aproximadamente la misma que SE, pero la agrupación máxima global y la agrupación promedio global se agregan en paralelo.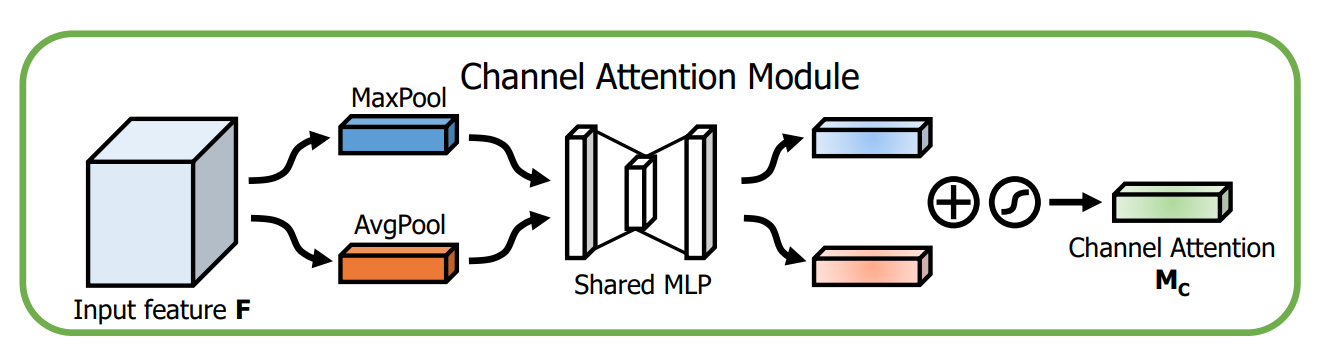
Mecanismo de atención espacial: primero realice la agrupación máxima y la agrupación media en la dimensión del canal, luego fusione en la dimensión del canal y MLP realiza la combinación de características. Las características finales se multiplican con las características originales. 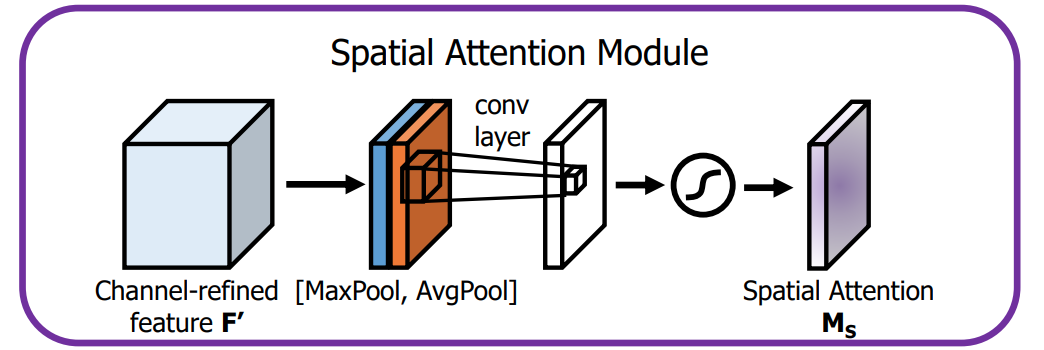
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, channel, rate = 4):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Sequential(
nn.Conv2d(channel, channel//rate, 1, bias = False)
nn.ReLu(implace = True)
nn.Conv2d(channel//rate, channel, 1, bias = False)
)
self.sig = nn.sigmoid()
def forward(self, x):
avg = sefl.avg_pool(x)
avg_feature = self.fc1(avg)
max = self.max_pool(x)
max_feature = self.fc1(max)
out = max_feature + avg_feature
out = self.sig(out)
return x * out
import torch
import torch.nn as nn
class SpatialAttention(nn.Module):
def __init__(self):
super(SpatialAttention, self).__init__()
//(B,C,H,W)---(B,1,H,W)---(B,2,H,W)---(B,1,H,W)
self.conv1 = nn.Conv2d(2, 1, kernel_size = 3, padding = 1, bias = False)
self.sigmoid = nn.sigmoid()
def forward(self, x):
mean_f = torch.mean(x, dim = 1, keepdim = True)
max_f = torch.max(x, dim = 1, keepdim = True)
cat = torch.cat([mean_f, max_f], dim = 1)
out = self.conv1(cat)
return x*self.sigmod(out)3. Mecanismo de atención en transformador.
Atención de productos puntuales escalados
La entrada a este mecanismo de atención es QKV.
1. Primero multiplica Q y K.
2.escala
3.softmax
4. Encuentra la salida

import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
def __init__(self, scale):
super(ScaledDotProductAttention, self)
self.scale = scale
self.softmax = nn.softmax(dim = 2)
def forward(self, q, k, v):
u = torch.bmm(q, k.transpose(1, 2))
u = u / scale
attn = self.softmax(u)
output = torch.bmm(attn, v)
return output
scale = np.power(d_k, 0.5) //缩放系数为K维度的根号。
//Q (B, n_q, d_q) , K (B, n_k, d_k) V (B, n_v, d_v),Q与K的特征维度一定要一样。KV的个数一定要一样。Atención multicabezal
Convertir la dimensión del canal QKV a la forma n*C equivale a dividirla en n partes y crear mecanismos de atención respectivamente.
1. QKV de un solo cabezal se convierte en un canal de múltiples cabezales ----- n * new_channel mediante transformación lineal, y luego fusione el cabezal y el lote primero
2. Encuentre el resultado del mecanismo de atención de un solo cabezal.
3. División de dimensiones: fusione el cabezal y el canal finales.
4.Linear obtiene la dimensión de salida final.

import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, n_head, d_k, d_k_, d_v, d_v_, d_o):
super(MultiHeadAttention, self)
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.fc_k = nn.Linear(d_k_, n_head * d_k)
self.fc_v = nn.Linear(d_v_, n_head * d_v)
self.fc_q = nn.Linear(d_k_, n_head * d_k)
self.attention = ScaledDotProductAttention(scale=np.power(d_k, 0.5))
self.fc_o = nn.Linear(n_head * d_v, d_0)
def forward(self, q, k, v):
batch, n_q, d_q_ = q.size()
batch, n_k, d_k_ = k.size()
batch, n_v, d_v_ = v.size()
q = self.fc_q(q)
k = self.fc_k(k)
v = self.fc_v(v)
q = q.view(batch, n_q, n_head, d_q).permute(2, 0, 1, 3).contiguous().view(-1, n_q, d_q)
k = k.view(batch, n_k, n_head, d_k).permute(2, 0, 1, 3).contiguous().view(-1, n_k, d_k)
v = v.view(batch, n_v, n_head, d_v).permute(2, 0, 1, 3).contiguous().view(-1. n_v, d_v)
output = self.attention(q, k, v)
output = output.view(n_head, batch, n_q, d_v).permute(1, 2, 0, 3).contiguous().view(batch, n_q, -1)
output = self.fc_0(output)
return output