El título original de este artículo "Cómo se implementan los servidores de alta concurrencia y alto rendimiento", comuníquese con el autor para reimprimirlo.
1. Introducción a la serie
1.1 Objeto del artículo
Como desarrollador de tecnología de mensajería instantánea, los conceptos técnicos relacionados con el alto rendimiento y la alta concurrencia se han entendido desde hace mucho tiempo. Qué grupo de subprocesos, copia cero, multiplexación, controlado por eventos, epoll, etc. están al alcance de su mano, tal vez esté familiarizado con frameworks técnicos con estas características técnicas tales como: Java's Netty , Php's workman , Go's gnet, etc. Pero cuando se trata de la práctica presencial o técnica, cuando te encuentras con dudas sin resolver, sabes que lo que tienes es solo la piel.
Regrese a lo básico y vuelva a la esencia, ¿cuáles son los principios subyacentes detrás de estas características técnicas? Cómo comprender los principios detrás de estas tecnologías de una manera fácil de comprender y sin esfuerzo es exactamente lo que compartirá la serie de artículos "Comprensión del alto rendimiento y la alta concurrencia desde la raíz".
1.2 Origen del artículo
He recopilado una gran cantidad de recursos y artículos relacionados con tecnologías de mensajería instantánea como mensajería instantánea y envío de mensajes, desde el marco de mensajería instantánea de código abierto inicial MobileIMSDK hasta la versión en línea de la obra maestra de programación de redes clásica " Explicación detallada de TCP / IP ", hasta la mensajería instantánea. programática de desarrollo El artículo "Una entrada es suficiente para principiantes: desarrollo de mensajería instantánea móvil desde cero " e " Introducción perezosa a la programación de redes ", " Introducción a la programación de redes con discapacidades cerebrales ", " Programación de redes de alto rendimiento ", " No apto para programación de redes conocidas "serie de artículos.
Cuanto más se adentra en las profundidades del conocimiento, más siente que sabe muy poco sobre la tecnología de mensajería instantánea. Entonces, más tarde, para permitir que los desarrolladores comprendan mejor las características de las redes (especialmente las redes móviles) desde la perspectiva de la tecnología básica de telecomunicaciones, recopilé y compilé una serie de artículos de alto nivel sobre la " Introducción a la tecnología de comunicación básica cero para Desarrolladores de mensajería instantánea "en todas las disciplinas . Esta serie de artículos ya es el límite de conocimiento de la tecnología de comunicación en red para los desarrolladores de mensajería instantánea ordinarios Con estos materiales de programación de red antes, es básicamente suficiente para resolver los puntos ciegos del conocimiento en la comunicación en red.
Para el desarrollo de sistemas de mensajería instantánea como IM, el conocimiento de la comunicación en red es realmente muy importante, pero vuelve a la esencia de la tecnología para darse cuenta de estas características técnicas de la comunicación en red en sí: incluyendo el grupo de subprocesos, copia cero, multiplexación y multiplexación. mencionado anteriormente. Impulsado por eventos, etc., ¿cuál es su naturaleza? ¿Cuál es el principio subyacente? Este es el propósito de organizar esta serie de artículos, espero que les sea de utilidad.
1.3 Directorio de artículos
" Comprender el alto rendimiento y la alta concurrencia desde la raíz (6): fácil de comprender, cómo se implementan los servidores de alto rendimiento " (* este artículo)
1.4 Resumen de este artículo
Continuando con el artículo anterior " Comprensión del alto rendimiento y alta concurrencia desde la raíz (5): sistema operativo en profundidad y comprensión de las rutinas en alta concurrencia ", este artículo es el sexto artículo (y el final) de alto rendimiento y alta concurrencia serie.
Este artículo es el final de esta serie de artículos. Podrá comprender cómo un servidor típico utiliza las tecnologías individuales explicadas en los primeros 5 artículos para lograr un alto rendimiento y una alta concurrencia.
Este artículo ha sido publicado simultáneamente en la cuenta oficial del "Círculo de tecnología de mensajería instantánea" , bienvenido a seguirlo. El enlace de la cuenta oficial es: haga clic aquí para ingresar .
2. El autor de este artículo
A petición del autor, no se proporcionan nombres reales ni fotografías personales.
La principal dirección técnica del autor de este artículo es back-end de Internet, servidor de alta concurrencia y alto rendimiento y tecnología de motor de búsqueda. Agradezca al autor por compartir desinteresadamente.
3. Introducción
Al leer este artículo, ¿alguna vez pensó en cómo el servidor le envió este artículo?
Es simple decir: ¿ no es solo una solicitud de usuario? El servidor recupera este artículo de la base de datos de acuerdo con la solicitud y luego lo envía de vuelta a través de la red.
En realidad, es un poco complicado: ¿cómo maneja el servidor miles de solicitudes de usuarios en paralelo? ¿Qué tecnologías están involucradas en esto?
Este artículo está aquí para responder a esta pregunta.

4. Procesos múltiples
El método más antiguo y sencillo de la historia para procesar varias solicitudes en paralelo es utilizar varios procesos .
Por ejemplo, en el mundo de Linux, podemos usar llamadas al sistema como fork y exec para crear múltiples procesos. Podemos recibir solicitudes de conexión de usuarios en el proceso principal y luego crear procesos secundarios para manejar las solicitudes de los usuarios.
como esto:

Las ventajas de este método son:
- 1) La programación es simple y fácil de entender;
- 2) Dado que el espacio de direcciones de cada proceso está aislado entre sí, una caída del proceso no afectará a otros procesos;
- 3) Aproveche al máximo los recursos de múltiples núcleos.
Las ventajas del procesamiento en paralelo multiproceso son obvias, pero las desventajas también son obvias:
- 1) El espacio de direcciones de cada proceso está aislado entre sí. Esta ventaja también se convertirá en una desventaja, es decir, será más difícil la comunicación entre procesos. Es necesario utilizar el mecanismo de comunicaciones entre procesos (IPC, comunicaciones entre procesos) para Piense en Ud. ¿Ahora sabe qué mecanismo de comunicación entre procesos y luego le permite implementarlo en el código? Obviamente, la programación de la comunicación entre procesos es relativamente complicada y el rendimiento también es un gran problema;
- 2) Sabemos que el costo de crear un proceso es mayor que el de los hilos, y la creación y destrucción frecuentes de procesos sin duda aumentará la carga sobre el sistema.
Afortunadamente, además de los procesos, también tenemos hilos.

5. Subprocesos múltiples
¿No es caro crear un proceso? ¿No es difícil comunicarse entre procesos? Nada de esto es un problema para los hilos.
¿Qué? Si aún no conoce los subprocesos, consulte este artículo "En lo más profundo de la computadora, entienda los subprocesos y los grupos de subprocesos ", aquí hay una explicación detallada de cómo proviene el concepto de subprocesos.
Dado que los subprocesos comparten el espacio de direcciones del proceso, la comunicación entre subprocesos no requiere naturalmente ningún mecanismo de comunicación, simplemente lea la memoria directamente.
El costo de creación y destrucción de hilos también se reduce. Debes saber que los hilos son como cangrejos ermitaños. La casa (espacio de direcciones) es un proceso, y es solo un inquilino. Por lo tanto, es muy liviano y el costo de creación y la destrucción también es muy pequeña.

Podemos crear un hilo para cada solicitud, incluso si un hilo está bloqueado debido a la realización de operaciones de E / S, como leer la base de datos, etc., no afectará a otros hilos.
como esto:
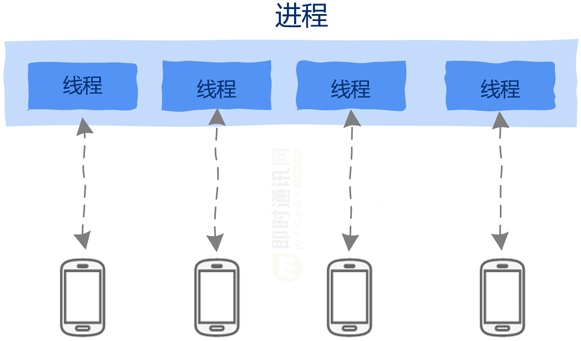
Pero, ¿son los hilos perfectos y curan todas las enfermedades? Obviamente, el mundo de la informática nunca ha sido tan simple.
Debido a que los subprocesos comparten el espacio de direcciones del proceso, esto brinda comodidad a la comunicación entre subprocesos y, al mismo tiempo, trae problemas sin fin.
Es precisamente porque el espacio de direcciones se comparte entre subprocesos, una falla de subproceso hará que todo el proceso se bloquee y salga. Al mismo tiempo, la comunicación entre subprocesos es simplemente demasiado simple, tan simple como la comunicación entre subprocesos solo necesita leer la memoria directamente, y también es lo suficientemente simple como para causar problemas. Es extremadamente fácil, como interbloqueos, sincronización y exclusión mutua entre subprocesos, etc. Estos son extremadamente propensos a errores. Una parte considerable del valioso tiempo de innumerables programadores es utilizado para resolver los problemas interminables causados por el subproceso múltiple.
Aunque los subprocesos también tienen deficiencias, son más ventajosos que los multiprocesos. Sin embargo, no es práctico utilizar simplemente subprocesos múltiples para resolver problemas de alta concurrencia.
Porque aunque la sobrecarga de creación de subprocesos es menor que el proceso, todavía tiene sobrecarga. Para un servidor altamente concurrente con decenas de miles de cientos de miles de enlaces, la creación de decenas de miles de subprocesos tendrá problemas de rendimiento, incluido el uso de memoria y la interacción. Subprocesos Traspaso, es decir, los gastos generales de programación.
Por lo tanto, debemos pensar más.

6. Impulsado por eventos: bucle de eventos
Hasta ahora, cuando mencionamos la palabra "paralelo", pensamos en procesos e hilos.
Pero: ¿Puede la programación paralela depender únicamente de estas dos tecnologías? ¡Ese no es el caso!
Existe otra tecnología paralela ampliamente utilizada en la programación de GUI y en la programación de servidores, que es la programación impulsada por eventos muy popular en los últimos años: la concurrencia basada en eventos.
PD: Los programadores que se dedican al desarrollo de mensajería instantánea del lado del servidor ciertamente no son extraños. ¿Qué significa la interfaz EvenLoop en el famoso marco de programación de red de alto rendimiento Java NIO Netty ? (Para el principio de alto rendimiento del marco Netty, puede lea esta " Guía para principiantes: hasta ahora el análisis más exhaustivo de los principios de alto rendimiento y la arquitectura del marco de Netty ).
No crea que esta es una tecnología difícil de entender, de hecho, el principio de la programación impulsada por eventos es muy simple.
Esta técnica requiere dos materias primas:
- 1) evento ;
- 2) Una función que maneja eventos, esta función generalmente se llama manejador de eventos;
El resto es simple: solo necesita esperar en silencio a que llegue el evento. Cuando llegue el evento, verifique el tipo de evento y busque la función de procesamiento de eventos correspondiente según el tipo, que es el controlador de eventos, y luego llame el evento directamente El controlador está bien.

Eso es !
Lo anterior es todo el contenido de la programación impulsada por eventos, ¡es muy simple!
De la discusión anterior, podemos ver que: necesitamos recibir eventos continuamente y luego procesar eventos, por lo que necesitamos un bucle (se pueden usar bucles while o for), este bucle se llama bucle de eventos.
Así es como se usa el pseudocódigo:
while (verdadero) {
evento = getEvent ();
manejador (evento);
}
Lo que se debe hacer en el bucle de eventos es en realidad muy simple, solo espere a que se traiga el evento y luego llame a la función de procesamiento de eventos correspondiente.
Nota: Este código solo necesita ejecutarse en un hilo o proceso, y solo este ciclo de eventos puede manejar múltiples solicitudes de usuario al mismo tiempo.
Es posible que algunos estudiantes aún no entiendan: ¿Por qué un ciclo de eventos de este tipo puede manejar múltiples solicitudes al mismo tiempo?
La razón es simple: para un servidor de comunicaciones de red, la mayor parte del tiempo cuando se procesa una solicitud de usuario se dedica a operaciones de E / S, como lectura y escritura de base de datos, lectura y escritura de archivos, lectura y escritura de red, etc. Cuando llega una solicitud, es posible que deba consultar la base de datos y otras operaciones de E / S después de un procesamiento simple. Sabemos que la E / S es muy lenta. Después de iniciar la E / S, podemos continuar procesando sin esperar a que se complete la E / S. Operación / O. La siguiente solicitud del usuario.

Ahora debe comprender: aunque la solicitud del usuario anterior no se ha procesado, en realidad podemos procesar la siguiente solicitud del usuario. Esto también es paralelo, y este paralelo se puede manejar mediante programación dirigida por eventos.
Esto es como un camarero en un restaurante: un camarero no puede esperar a que el próximo cliente haga un pedido, sirva comida, coma y pague al próximo cliente. Cuando un cliente termina de realizar un pedido, se ocupará directamente del siguiente cliente, y cuando el cliente haya terminado de comer, volverá a pagar la factura por sí mismo.
Véalo: el mismo camarero puede manejar varios clientes al mismo tiempo. Este camarero es equivalente al bucle de eventos aquí. Incluso si el bucle de eventos solo se ejecuta en un hilo (proceso), puede manejar múltiples solicitudes de usuario al mismo tiempo .
Creo que tiene una comprensión clara de la programación impulsada por eventos, por lo que la siguiente pregunta es, ¿cómo obtener este evento, cuál es el evento?
7. Fuente del evento: multiplexación IO
En el artículo " Sistema operativo en profundidad, comprensión completa de la multiplexación de E / S ", sabemos que todo en el mundo Linux / Unix es un archivo, y nuestros programas realizan operaciones de E / S a través de descriptores de archivo. Por supuesto, sockets en la red la programación no es una excepción.
Entonces, ¿cómo manejamos múltiples descriptores de archivos al mismo tiempo?
La tecnología de multiplexación IO se utiliza para resolver este problema: a través de la tecnología de multiplexación IO, podemos monitorear múltiples descripciones de archivos a la vez, cuando un determinado "archivo" (en realidad puede ser un conector en la comunicación de red) se puede notificar. es de lectura o escritura.
De esta forma, la tecnología de multiplexación IO se ha convertido en el proveedor de materia prima del bucle de eventos, proporcionándonos continuamente varios eventos, de manera que se resuelve el problema de la fuente del evento.

Por supuesto: para obtener una explicación detallada de la tecnología de multiplexación de E / S, consulte " Sistema operativo en profundidad, comprensión completa de la multiplexación de E / S ", este artículo es un artículo programático, por lo que no lo repetiré.
Hasta ahora: ¿Se han resuelto todos los problemas relacionados con el uso de la implementación basada en eventos de la programación concurrente? El problema de la fuente del evento está resuelto.Cuando se obtiene el evento, se llama al manejador correspondiente y parece que ya está.
¿Piensa si hay alguna otra pregunta?

8. Problema: bloqueo de E / S
Ahora: Podemos usar un hilo (proceso) para llevar a cabo una programación paralela basada en eventos, y no hay más problemas como varios bloqueos, exclusión mutua de sincronización, puntos muertos, etc. que hacen que la gente se moleste en el multihilo.
Pero: nunca ha existido una tecnología que pueda resolver todos los problemas de la informática, no hay ninguno ahora y no lo habrá en el futuro previsible.
¿Hay algún problema con el método anterior?
No olvide que nuestro bucle de eventos se ejecuta en un subproceso (proceso). Aunque esto resuelve el problema de subprocesos múltiples, ¿qué sucede si se requiere una operación de E / S al procesar un evento?
En el artículo " Sistema operativo en profundidad, comprensión de la E / S y la tecnología de copia cero ", explicamos cómo se implementa la lectura de archivos más comúnmente utilizada en el nivel inferior. Este método de E / S más utilizado por los programadores se llama bloqueo de E / S.
En otras palabras: cuando realizamos operaciones IO, como leer un archivo, si el archivo no se lee, entonces nuestro programa (hilo) será bloqueado y suspendido. Esto no es un problema en multiproceso, porque el sistema operativo aún puede programar otros hilos.
Pero: hay un problema en un bucle de eventos de un solo subproceso, porque cuando realizamos operaciones de bloqueo de E / S en el bucle de eventos, todo el subproceso (bucle de eventos) se suspenderá y el sistema operativo no tendrá otros subprocesos para programar. Debido a que solo hay un bucle de eventos en el sistema que procesa las solicitudes de los usuarios, cuando el hilo del bucle de eventos se bloquea y suspende, no se pueden procesar todas las solicitudes de los usuarios. ¿Se imagina que su solicitud se suspende cuando el servidor está procesando otras solicitudes de usuarios para leer la base de datos?
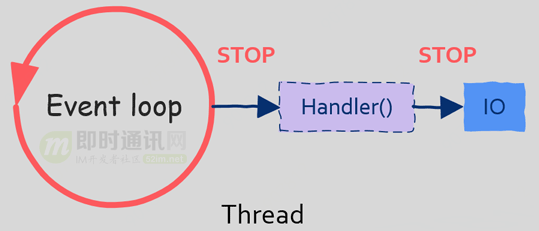
Por lo tanto: Hay una precaución cuando la programación dirigida por eventos es no permitir que se inicie el bloqueo de E / S.
Algunos estudiantes pueden preguntar, si no se puede iniciar el bloqueo de IO, ¿cómo realizar las operaciones de IO?
PD: hay IO de bloqueo, hay IO sin bloqueo. Seguimos discutiendo.
9. Solución: E / S sin bloqueo
Para superar los problemas causados por el bloqueo de E / S, los sistemas operativos modernos han comenzado a proporcionar un nuevo método para iniciar solicitudes de E / S. Este método es E / S asincrónico. En consecuencia, el bloqueo de IO es IO síncrono. Para los dos conceptos de sincronización y asincronía, consulte " Comprensión del alto rendimiento y alta concurrencia desde la raíz (4): sistema operativo en profundidad, comprensión completa de la sincronización y la asincronía ".
Cuando se realiza una E / S asincrónica, suponga que se llama a la función aio_read (para una API de E / S asincrónica específica, consulte la plataforma del sistema operativo específico), es decir, lectura asincrónica. Cuando llamamos a esta función, podemos regresar inmediatamente y continuar con otras cosas, aunque el El archivo puede ser No se ha leído, por lo que no bloquea el hilo de llamada. Además, el sistema operativo también proporciona otros métodos para que el subproceso de llamada detecte si la operación de E / S está completa.
De esta forma, el problema de las llamadas de bloqueo de E / S también se resuelve con la ayuda del sistema operativo.

10. Dificultades de la programación paralela impulsada por eventos
Aunque existe una E / S asíncrona para resolver el problema de que el bucle de eventos puede estar bloqueado, la programación basada en eventos sigue siendo difícil.
En primer lugar: mencionamos que el bucle de eventos se ejecuta en un hilo. Obviamente, un hilo no puede hacer un uso completo de los recursos de varios núcleos. Algunos estudiantes pueden decir que no es suficiente crear varias instancias de bucle de eventos. Hay varios bucles de eventos subprocesos, pero luego volverá a aparecer el problema de subprocesos múltiples.
Otro punto radica en la programación. En el artículo " Comprensión del alto rendimiento y la alta concurrencia desde la raíz (4): sistema operativo en profundidad, comprensión completa de la sincronización y la asincronía", mencionamos que la programación asincrónica debe combinarse con funciones de devolución de llamada ( este método de programación La lógica de procesamiento debe dividirse en dos partes: una parte la maneja el llamante mismo y la otra parte se maneja en la función de devolución de llamada). Este cambio en el método de programación ha aumentado la carga de comprensión de los programadores. La programación basada en programas será difícil de expandir más adelante en el proyecto y el mantenimiento.
Entonces, ¿hay una mejor manera?
Para encontrar una mejor manera, necesitamos resolver la esencia del problema, entonces, ¿cuál es la esencia del problema?

11. Una mejor forma
¿Por qué usamos la programación asincrónica de una manera tan incomprensible?
La razón es: aunque el bloqueo de la programación es fácil de entender, hará que el hilo se bloquee y suspenda.
Tan inteligente, debe preguntarse: ¿Hay alguna manera de combinar una comprensión simple de la E / S sincrónica sin causar que los subprocesos se bloqueen debido a las llamadas sincrónicas?
La respuesta es sí: este es el hilo de nivel de usuario, que es la famosa corrutina (para la corrutina, lea la primera parte de esta serie " Comprensión del alto rendimiento y alta concurrencia desde la raíz (5): sistema operativo en profundidad, "Entendiendo las corrutinas en alta concurrencia ", este artículo no las repetirá).
Aunque la programación basada en eventos tiene varias deficiencias, la programación basada en eventos sigue siendo muy popular en los servidores de alto rendimiento y alta concurrencia de hoy en día, pero ya no es puramente impulsada por eventos basada en un solo hilo, sino bucle de eventos + multi hilo + hilo de nivel de usuario.
Con respecto a esta combinación, también vale la pena elaborar un artículo para explicar, lo discutiremos en detalle en un artículo de seguimiento.

12. Resumen de este artículo
La tecnología de alta concurrencia ha evolucionado desde el multiproceso inicial hasta el actual impulsado por eventos. La tecnología informática también está evolucionando y evolucionando al igual que la biología, pero en cualquier caso, comprender la historia puede brindar una comprensión más profunda del presente. Espero que este artículo pueda ayudarlo a comprender los servidores de alta concurrencia.

Apéndice: Más artículos de alto rendimiento y alta concurrencia
" Programación de redes de alto rendimiento (7): ¿Qué es alta concurrencia? ¡Entiende en una frase! 》
"Un plan original de arquitectura teórica del sistema de mensajería instantánea distribuida (IM) "
" 17 años de práctica: metodología técnica de los productos masivos de Tencent "
Este artículo ha sido publicado simultáneamente en la cuenta oficial de "Instant Messaging Technology Circle".
▲ El enlace de este artículo en la cuenta oficial es: haga clic aquí para ingresar . El enlace de publicación sincrónica es: http://www.52im.net/thread-3315-1-1.html
