La inteligencia artificial generativa ha arrasado en la industria tecnológica. En el primer trimestre de 2023, cuando cientos de millones de usuarios adoptan aplicaciones como ChatGPT y GitHub CoPilot, las inversiones en nuevas empresas de IA de próxima generación superaron los 1.700 millones de dólares. Las empresas líderes en tecnología están luchando por desarrollar sus propias estrategias de IA generativa, y muchas luchan por poner las aplicaciones en producción. Incluso los equipos de ingeniería más avanzados enfrentan el desafío de entrenar, implementar y proteger modelos de IA generativa de manera segura, confiable y rentable.
Están surgiendo nuevas tecnologías de infraestructura para la IA generativa. Vemos una gran oportunidad para las nuevas empresas en este espacio, especialmente aquellas que abordan los altos costos asociados con la implementación de modelos en producción, la gestión de datos y la evaluación de modelos.
Recomendación: utilice el editor NSDT para crear rápidamente escenas 3D programables
1. Nueva infraestructura para la IA generativa
2. Modelo básico
Los Foundation Models se entrenan en conjuntos de datos masivos y realizan una amplia gama de tareas. Los desarrolladores utilizan el modelo subyacente como base para potentes aplicaciones de IA generativa como ChatGPT.

Una consideración clave al elegir un modelo base es el código abierto versus el código cerrado; a continuación se detallan los pros y los contras de cada modelo.
Fuente abierta:
- Ventajas: los modelos de código abierto son más fáciles de personalizar, brindan mayor transparencia en los datos de capacitación y brindan a los usuarios un mayor control sobre el costo, la producción, la privacidad y la seguridad.
- Desventajas: Los modelos de código abierto pueden requerir más trabajo para prepararse para la implementación y también requerir más ajustes y capacitación. Si bien los modelos de código abierto pueden ser más costosos de implementar, a escala las empresas tienen más control sobre los costos que los modelos de código cerrado, cuyo uso es menos predecible y los costos pueden salirse de control.
Fuente cerrada:
- Ventajas: los modelos de código cerrado suelen proporcionar infraestructura de alojamiento y entornos informáticos (como GPT-4). También pueden proporcionar extensiones del ecosistema para ampliar las capacidades del modelo, como el complemento ChatGPT de OpenAI. Los modelos de código cerrado también pueden proporcionar más funcionalidad y valor "listos para usar" porque están previamente entrenados y, a menudo, se puede acceder a ellos a través de API.
- Desventajas: los modelos de código cerrado son cajas negras, por lo que los usuarios saben muy poco sobre sus datos de entrenamiento, lo que dificulta la interpretación y el ajuste del resultado. La dependencia de un proveedor también puede generar costos inmanejables; por ejemplo, el uso de GPT-4 se cobra según el tiempo de finalización.
Creemos que el código abierto será una opción más atractiva para los equipos empresariales que crean aplicaciones AO generativas. Como señalan dos investigadores de Google, el modelo de código abierto tiene ventajas en términos de innovación impulsada por la comunidad, gestión de costos y confianza.
3. Puesta a punto y formación
El ajuste fino es el proceso de ajustar los parámetros de un modelo existente mediante el entrenamiento en un conjunto de datos curado para desarrollar "experiencia" para un caso de uso específico.
El ajuste fino puede mejorar el rendimiento y reducir el tiempo y el costo de capacitación al permitir a los desarrolladores aprovechar modelos grandes previamente entrenados.
Hay una variedad de opciones para ajustar modelos previamente entrenados, incluidos marcos de código abierto como TensorFlow y Pytorch, así como soluciones seguras de un extremo a otro como MosiacML. Queremos enfatizar la importancia de etiquetar las herramientas para realizar ajustes: ¡un conjunto de datos limpio y bien seleccionado puede acelerar el proceso de capacitación y mejorar la precisión!
Recientemente, hemos visto mucha actividad en torno a modelos de IA generativa de dominios específicos. Bloomberg lanzó BloombergGPT, su LLM patentado capacitado en datos específicos de la industria financiera. Hippocratic, una startup que está construyendo su propio LLM, capacitado con datos de atención médica para impulsar aplicaciones orientadas al consumidor, recaudó 50 millones de dólares en forma privada de Andreessen Horowitz y General Catalyst. Synteny AI está construyendo un modelo entrenado en afinidades de unión entre proteínas para impulsar un mejor descubrimiento de fármacos. Creemos que los operadores tradicionales están bien posicionados para ajustar modelos potentes basados en sus propios datos patentados y construir su propia ventaja en IA.
4. Almacenamiento y recuperación de datos
El almacenamiento para memoria a largo plazo y recuperación de datos es un desafío de infraestructura complejo y costoso, que presenta una oportunidad para que las nuevas empresas creen soluciones más eficientes. Las bases de datos vectoriales han surgido como una solución poderosa para el entrenamiento de modelos y los sistemas posteriores de recuperación y recomendación. Esto hace que las bases de datos vectoriales sean una de las bases más importantes para la IA generativa:
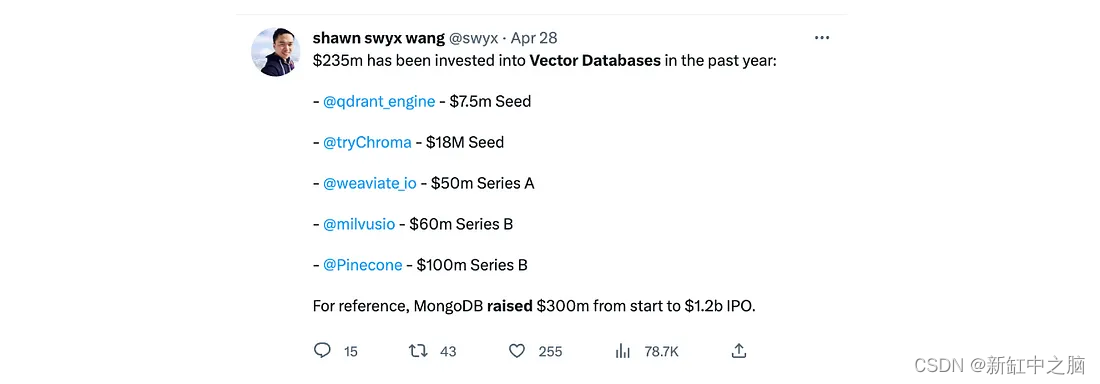
Las bases de datos vectoriales se pueden utilizar para admitir una variedad de aplicaciones, incluida la búsqueda semántica (una técnica de búsqueda de datos), la búsqueda de similitudes (encontrar datos similares utilizando funciones compartidas) y los sistemas de recomendación. También dotan a los modelos de memoria a largo plazo, lo que ayuda a reducir las alucinaciones (respuestas seguras realizadas por la IA pero no justificadas por datos de entrenamiento).
Vemos muchas oportunidades para la innovación aquí. No hay garantía de que los enfoques actuales de búsqueda y recuperación semántica de bases de datos sigan siendo los más eficientes (velocidad y costo) y más efectivos (cobertura); Cohere lanzó recientemente su punto final Rerank, un método de búsqueda y recuperación que no requiere migración. al sistema de recuperación de bases de datos vectoriales. También hemos visto equipos que utilizan LLM como motores de inferencia adjuntos a bases de datos vectoriales. Estamos entusiasmados de ver cómo evoluciona la categoría de almacenamiento y recuperación de datos y cómo surgen más empresas emergentes.
5. Supervisión del modelo: seguimiento, observabilidad e interpretabilidad
Los tres términos relacionados con la supervisión a menudo se usan indistintamente; sin embargo, describen diferentes pasos en la evaluación de un modelo durante y después de la producción. El monitoreo implica rastrear el desempeño, incluida la identificación de fallas, interrupciones y tiempo de inactividad. La observabilidad es el proceso de comprender si el desempeño es bueno o malo, o evaluar la salud de un sistema. Al final, la interpretabilidad consiste en interpretar el resultado; por ejemplo, explicar por qué el modelo tomó una determinada decisión.
La supervisión es un elemento básico de las pilas de MLOps más tradicionales, y los titulares como Arize han comenzado a crear productos para equipos que implementan modelos de IA generativa. Sin embargo, los modelos de caja negra y de código cerrado pueden ser difíciles de supervisar y dar cuenta de las alucinaciones sin acceso a los datos de entrenamiento. Los lotes recientes de YC han generado varias empresas para abordar estos desafíos, incluidas Helicone y Vellum, destacando los primeros desarrollos en el campo. En particular, ambos centran la información en el seguimiento de la latencia y el uso, lo que sugiere que el costo sigue siendo el mayor problema para la formación de equipos de IA generativa.
6. Modelo de seguridad, protección y cumplimiento
A medida que las empresas lleven los modelos de IA generativa a producción, la seguridad y el cumplimiento de los modelos serán cada vez más importantes. Para que las empresas confíen en los modelos de IA generativa, necesitan un conjunto de herramientas para evaluar con precisión los modelos en cuanto a imparcialidad, sesgo y toxicidad (generación de contenido inseguro u odioso). También creemos que los equipos que implementen modelos necesitarán herramientas que les ayuden a implementar sus propias barreras de seguridad.
Los clientes empresariales también están profundamente preocupados por amenazas como la extracción de datos confidenciales, el envenenamiento de datos de capacitación y la fuga de datos de capacitación (especialmente datos confidenciales de terceros). En particular, Arthur AI lanzó recientemente su nuevo producto, Arthur Shield, el primer firewall para LLM que evita funciones como la inyección instantánea (manipulación de resultados con entradas maliciosas), la filtración de datos y la generación de lenguaje tóxico.
Vemos una gran oportunidad en el middleware de cumplimiento. Las empresas deben asegurarse de que sus aplicaciones de IA generativa no violen los estándares de cumplimiento (derechos de autor, SOC-2, GDPR, etc.). Esto es especialmente importante para la formación de equipos en industrias altamente reguladas como las finanzas y la atención médica. Nos entusiasma ver la innovación tanto de las empresas emergentes como de las ya establecidas; por ejemplo, nuestra empresa de vaqueros, Drata, está bien posicionada para integrar o desarrollar capacidades para el cumplimiento del modelo de IA generativa.
7. Conclusión
Creemos que la IA generativa traerá enormes ganancias de eficiencia a las empresas y creará enormes nuevas oportunidades empresariales en el espacio de la infraestructura. Los dos mayores obstáculos para la adopción son el costo y la seguridad. Las nuevas empresas de infraestructura que adopten estos pilares de valor fundamentales estarán bien posicionadas para tener éxito.
También vemos que el código abierto desempeña un papel importante en la infraestructura de IA generativa. Las empresas emergentes que utilicen este modelo se ganarán más fácilmente la confianza de los usuarios y se beneficiarán de la innovación y el apoyo de la comunidad de código abierto.
Enlace original: Una nueva pila de infraestructura para IA generativa: BimAnt