Hay muchas formas de implementar modelos de máquinas en producción. Uno de los enfoques comunes es implementarlo como un servicio web. El tipo más popular es la API REST. Su función es implementar y ejecutar 24 horas al día, 7 días a la semana, esperando recibir solicitudes JSON de los clientes, extraer la entrada y enviarla al modelo ML para predecir el resultado. Luego, el resultado se incluye en una respuesta y se devuelve al usuario.

Recomendación: utilice el editor NSDT para crear rápidamente escenas 3D programables
1. Modo de implementación simple
Empiece a buscar en Google esta pregunta con "implementar el aprendizaje automático como una API REST". Recibirás un millón de resultados. Si te esfuerzas y lees esto. En muchos de los resultados principales, verá un patrón común para resolver este problema, como se muestra en la imagen a continuación.
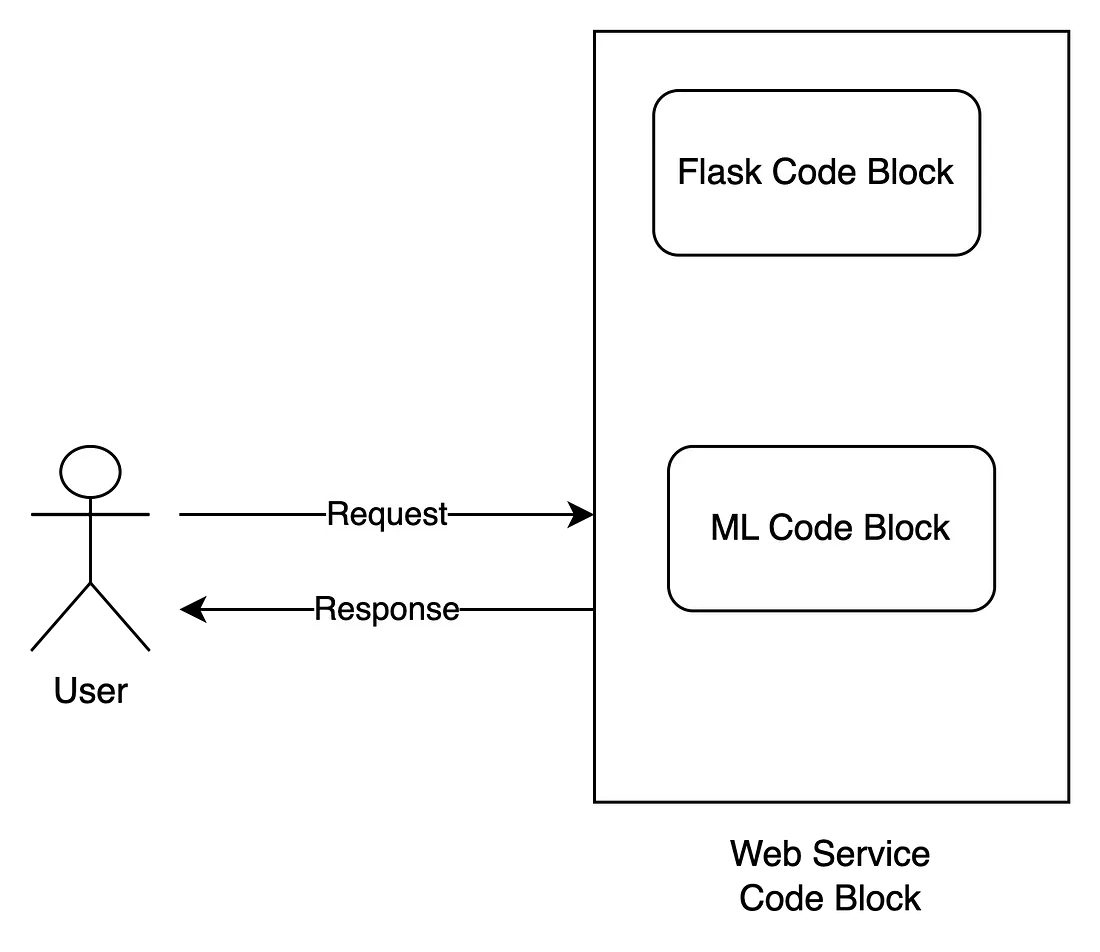
La forma popular es que necesitamos un marco web (Flask, Diango o FastAPI) para construir la API. A continuación, necesitaremos aprendizaje automático para tomar la información y devolver una predicción. Para ayudar a que el sistema se ejecute en producción, necesitamos empaquetar WSGI adicional (si usamos Flask) o ASGI (si usamos FastAPI) fuera del módulo web.
Vale la pena señalar aquí que el modelo de aprendizaje automático en este enfoque generalmente se implementa en el mismo bloque de código que el marco web (Flask/FastAPI/…). Esto significa que el modelo de aprendizaje automático se ejecuta en el mismo proceso que el módulo web. Esto causa muchos problemas:
- Para un proceso Flask/FastAPI, solo se puede iniciar un proceso de modelo ML.
- En un momento de ejecución, el modelo ML solo puede manejar una solicitud
- Si queremos escalar la aplicación, podemos usar WSGI (como guvicorn) o ASGI (como uvicorn) para crear muchos procesos hijos, lo que aumenta la cantidad de módulos web y modelos de aprendizaje automático, ya que se implementan en el mismo proceso. .
- Para algunas tareas pesadas, los modelos de aprendizaje automático pueden tardar mucho tiempo (incluso segundos) en ejecutar la inferencia. Debido a que se crean en el mismo bloque de código en el módulo web, bloquea otras solicitudes mientras debemos esperar a que se completen todas las tareas antes de procesar la siguiente.
Entonces, ¿hay una mejor manera? Para tareas pesadas y de larga duración, ¿hay alguna forma de procesarlas sin bloquear las solicitudes de los clientes? Hoy, voy a cubrir un enfoque que puede no ser nuevo pero que no parece haberse aplicado a la implementación del aprendizaje automático ML en producción: usar un sistema distribuido de cola de tareas.
2. ¿Qué es una cola de tareas?
Las colas de tareas se utilizan como mecanismo para distribuir el trabajo entre subprocesos o máquinas.
La entrada a una cola de tareas es una unidad de trabajo, llamada tarea, y un proceso de trabajo dedicado monitorea constantemente la cola para realizar nuevos trabajos. – Apio Github
Una cola de tareas es una herramienta que le permite ejecutar diferentes programas de software en máquinas/procesos/hilos separados. En una aplicación, hay algunas partes (tareas) que muchas veces se ejecutan durante mucho tiempo o no sabemos cuándo han terminado. Para estas tareas, es mejor ejecutarlas en procesos separados o máquinas distribuidas y, cuando se completen, se nos notificará los resultados de la verificación. Esto no bloquea otras partes. Esto es adecuado para tareas de larga duración, como enviar correos electrónicos, extraer contenido web o, en este caso, ejecutar modelos de aprendizaje automático. Consideremos la descripción a continuación.
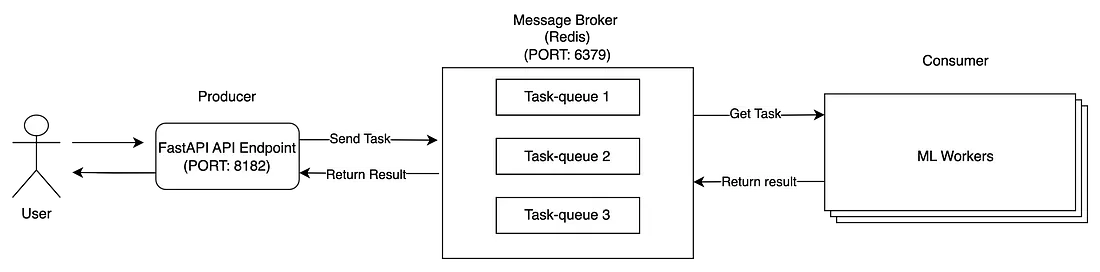
La arquitectura de la cola de tareas distribuida consta de tres módulos principales: productores, consumidores y intermediarios de mensajes.
- El cliente envía una solicitud a nuestra aplicación Flask (Productor).
- Los productores envían mensajes de tareas a Message Broker.
- Los trabajadores de ML (consumidores) consumen mensajes de un intermediario de mensajes. Una vez completada la tarea, guarde el resultado en Message Broker y actualice el estado de la tarea.
- Después de enviar una tarea al intermediario de mensajes, las aplicaciones FastAPI también pueden monitorear el estado de la tarea desde el intermediario de mensajes. Cuando el estado está completo, recupera el resultado y lo devuelve al cliente.
Los tres módulos se inician en diferentes procesos o máquinas distribuidas para que puedan vivir de forma independiente. Existen muchas herramientas para desarrollar colas de tareas, distribuidas en varios lenguajes de programación, y en este blog, me centraré en Python y usaré Celery, la herramienta de colas de tareas más popular para proyectos de Python. Para obtener más información sobre los beneficios de Celery y el sistema de cola de tareas distribuidas, consulte esta excelente explicación. Ahora, pasemos a la siguiente pregunta.
3. Modelo de predicción del tiempo de viaje.
Para ilustrar esto, intentaré crear un modelo simple de aprendizaje automático que pueda ayudar a predecir el tiempo de viaje promedio teniendo en cuenta un lugar de recogida, un lugar de entrega y la duración del viaje. Este será un modelo de regresión. Tenga en cuenta que no me estoy centrando en crear el modelo de precisión en este blog, sino simplemente en usarlo para configurar la API del servicio web. Los pesos del modelo y cómo construimos el modelo se pueden encontrar en este enlace.
3.1 Descripción general de la API
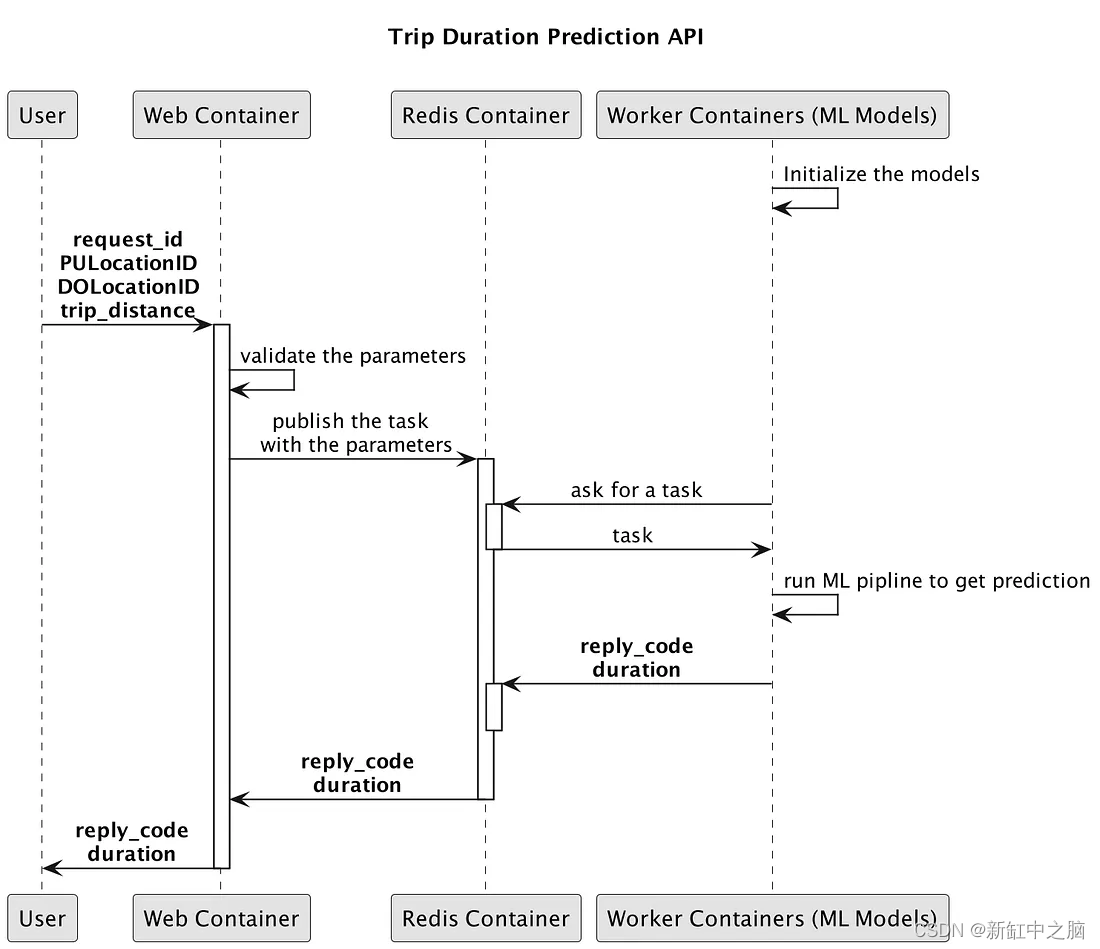
Desarrollaremos una API web para servir modelos de aprendizaje automático, que consta de 3 módulos: modelos web, redis y ML. Estos módulos están acoplados y implementados en contenedores.
├── apps
│ └── api
│ ├── api_routers.py
│ └── main.py
├── boot
│ ├── docker
│ │ ├── celery
│ │ │ ├── cuda90.yml
│ │ │ └── trip
│ │ │ ├── Dockerfile
│ │ │ └── entrypoint.sh
│ │ ├── compose
│ │ │ └── trip_duration_prediction
│ │ │ ├── docker-compose.cpu.yml
│ │ │ ├── docker-compose.dev.yml
│ │ │ ├── docker-compose.yml
│ │ │ ├── docker-services.sh
│ │ │ ├── my_build.sh
│ │ └── uvicorn
│ │ ├── Dockerfile
│ │ ├── entrypoint.sh
│ │ └── requirements.txt
│ └── uvicorn
│ └── config.py
├── config.py
├── core
│ ├── managers
│ ├── schemas
│ │ ├── api_base.py
│ │ ├── health.py
│ │ └── trip.py
│ ├── services
│ │ ├── trip_duration_api.py
│ │ └── trip_duration_prediction_task.py
│ └── utilities
├── repo
│ ├── logs
│ └── models
│ └── lin_reg.bin
├── tasks
│ └── trip
│ └── tasks.py
└── tests
├── http_test
│ └── test_api.py
└── model_test
└── test_trip_prediction_task.py
Aquí están los detalles de la estructura de carpetas del repositorio:
- apps: define la aplicación principal y el enrutador API para el módulo web usando FastAPI
- arranque: defina la imagen de Dockerfile para el módulo web, el módulo ML y el archivo Docker-compose para vincular 3 módulos. También contiene la configuración para cada imagen de Docker y el archivo yml correspondiente para el repositorio de paquetes.
- config.py: El archivo de configuración define varias configuraciones sobre CELERY_BROKER_URL, CELERY_RESULT_BACKEND, TRIP_DURATION_MODEL, TRIP_DURATION_THRESHOLD, etc...
- núcleo: define todos los scripts de implementación utilizados en los módulos Web, Redis y Worker.
- repositorio: almacena registros de aplicaciones y tareas cuando se inicia la API. También almacena los pesos del modelo.
- tareas: definir scripts de tareas de apio
- pruebas: define las pruebas unitarias para la API
3.2 Módulo web
En el módulo web, utilizo FastAPI como marco web. FastAPI ofrece muchas características específicas, como: ultrarrápida, integración con Uvicorn, verificación automática de validación de tipo usando Pydantic, generación automática de documentación y más...
Veamos cómo iniciar la aplicación FastAPI: boot/docker/uvicorn/entrypoint.sh, aquí es donde inicio la aplicación FastAPI
#!/usr/bin/env sh
USERNAME="$(id -u -n)"
MODULE="apps.api"
SOCKET="0.0.0.0:8182"
MODULE_APP="${MODULE}.main:app"
CONFIG_PATH="boot/uvicorn/config.py"
REPO_ROOT="repo"
LOGS_ROOT="${REPO_ROOT}/logs/apps/api"
LOGS_PATH="${LOGS_ROOT}/daemon.log"
sudo mkdir -p ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${REPO_ROOT} && \
gunicorn \
--name "${MODULE}" \
--config "${CONFIG_PATH}" \
--bind "${SOCKET}" \
--log-file "${LOGS_PATH}" \
"${MODULE_APP}"
Luego, defino el enrutador API y el esquema de mensajes: apps/api/api_routers.py:
import os
import json
from typing import Dict
from loguru import logger
from fastapi import Request, APIRouter
import config
from core.schemas.trip import TripAPIRequestMessage, TripAPIResponseMessage
from core.schemas.health import Health
from core.services.trip_duration_api import TripDurationApi
API_VERSION = config.API_VERSION
MODEL_VERSION = config.MODEL_VERSION
api_router = APIRouter()
@api_router.get("/health", response_model=Health, status_code=200)
def health() -> Dict:
return Health(
name=config.PROJECT_NAME, api_version=API_VERSION, model_version=MODEL_VERSION
).dict()
@api_router.post(
f"/{config.API_VERSION}/trip/predict",
tags=["Trips"],
response_model=TripAPIResponseMessage,
status_code=200,
)
def trip_predict(request: Request, trip_request: TripAPIRequestMessage):
api_service = TripDurationApi()
results = api_service.process_raw_request(request, trip_request)
return results
core/schemas/trip.py:
from core.schemas.api_base import APIRequestBase, APIResponseBase
class TripAPIRequestMessage(APIRequestBase):
PULocationID: int
DOLocationID: int
trip_distance: float
class Config:
schema_extra = {
"example": {
"request_id": "99999",
"PULocationID": 130,
"DOLocationID": 250,
"trip_distance": 3.0,
}
}
class TripAPIResponseMessage(APIResponseBase):
duration: float
class Config:
schema_extra = {"example": {"reply_code": 0, "duration": 12.785509620119132}}
core/services/trip_duration_api.py:
import collections
import celery
from loguru import logger
from fastapi import Request
from fastapi.encoders import jsonable_encoder
import config
from core.schemas.trip import TripAPIRequestMessage, TripAPIResponseMessage
from core.utilities.cls_time import Timer
task_celery = config.CeleryTasksGeneralConfig
celery_app = celery.Celery()
celery_app.config_from_object(task_celery)
class TripDurationApi:
# pylint: disable=too-many-instance-attributes
def call_celery_matching(
self,
pu_location_id: int,
do_location_id: int,
trip_distance: float,
):
"""
:type celery_result: celery.result.AsyncResult
"""
celery_result = celery_app.send_task(
task_celery.task_process_trip,
args=[
pu_location_id,
do_location_id,
trip_distance,
],
queue=task_celery.task_trip_queue,
)
return celery_result
def process_api_request(self):
celery_result = self.call_celery_matching(
self.trip_request.PULocationID,
self.trip_request.DOLocationID,
self.trip_request.trip_distance,
)
results: dict = {}
try:
results = celery_result.get(timeout=60)
celery_result.forget()
results = results or {}
except celery.exceptions.TimeoutError:
results = {}
reply_code: int = results.pop("reply_code", 1)
duration: float = float(results.pop("duration", 0.0))
self.response = TripAPIResponseMessage(reply_code=reply_code, duration=duration)
self.status_code = 200
self.timings = results.pop("timings", {})
self.results = results
A continuación, defino una clase llamada trip_duration_api.py donde manejo la lógica de solicitud.
- En la función Process_request_api, recopila información de la solicitud.
- La función call_celery_matching se agregará como una tarea a una cola de Redis del agente de mensajes implementada en otro contenedor. Los módulos de aprendizaje automático implementados en otros contenedores extraerán el trabajo de Redis y comenzarán a procesarlo. El resultado es una promesa que notificará al backend del módulo web cuando el trabajador haya completado la tarea o cuando haya transcurrido el tiempo previsto. Preste atención a las líneas 29 y 35, donde debe ingresar task_celery.task_process_trip como nombre de la tarea de Apio y task_celery.task_trip_queue como cola de Apio.
- Las líneas 12 a 14 ayudan al módulo web a conectarse con el módulo ML a través de Celery
Todo está combinado y integrado en una única imagen acoplable.
Archivo Docker web:
ARG VM_BASE
FROM $VM_BASE
ARG VM_USER
ARG VM_HOME
ARG VM_CODE
ARG VM_PIP
COPY . $VM_CODE
WORKDIR $VM_CODE/
RUN rm -rf libs
RUN apk add --no-cache sudo \
&& apk add --no-cache --virtual .build-deps gcc musl-dev g++\
&& pip install --no-cache-dir -r $VM_PIP \
&& apk del .build-deps
RUN apk add --no-cache bash
RUN adduser --disabled-password --gecos '' $VM_USER \
&& addgroup sudo \
&& adduser $VM_USER sudo \
&& echo '%sudo ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers \
&& chown -R $VM_USER $VM_HOME
USER $VM_USER
WORKDIR $VM_CODE/
EXPOSE 8182
ENTRYPOINT ["boot/docker/uvicorn/entrypoint.sh"]
3.3 Módulo de trabajador
En el apio, cada pieza de trabajo que se puede realizar en un proceso o máquina independiente se denomina tarea. Las tareas pueden variar desde extraer contenido web hasta enviar correos electrónicos o incluso modelos complejos de máquinas en ejecución. Las tareas se pueden activar en tiempo de ejecución o periódicamente. Una vez implementado, cada hilo de trabajo puede ejecutarse en un proceso, un hilo verde... dependiendo del tipo de Apio que estemos usando. Para comprender mejor los grupos de ejecución de Celery, puede leer más en este blog. En esta API, elijo gevent del tipo de grupo de apio. El punto de entrada para Celery se puede encontrar en boot/docker/celery/trip/entrypoint.sh
#!/usr/bin/env bash
USERNAME="$(id -u -n)"
MODULE="tasks.trip"
REPO_ROOT="repo"
LOGS_ROOT="${REPO_ROOT}/logs/tasks/trip"
LOGS_PATH="${LOGS_ROOT}/daemon.log"
sudo mkdir -p ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${REPO_ROOT} && \
source activate venv && \
python -m celery worker \
-A ${MODULE} \
-Q ${MODULE} \
-P gevent \
--prefetch-multiplier=1 \
--concurrency=4 \
--loglevel=INFO \
--logfile="${LOGS_PATH}"
Tenga en cuenta que en la línea 18, mi tipo de apio elegido es gevent. El multiplicador de captación previa es la cantidad de mensajes que se van a captar previamente a la vez, lo que significa que solo reservará una tarea por proceso de trabajo a la vez. La simultaneidad es la cantidad de subprocesos verdes creados por instancia de Celery.
Configuración de apio
La configuración del apio se define en config.py:
class CeleryTasksGeneralConfig:
task_trip_queue = "tasks.trip"
task_trip_prefix = "tasks.trip.tasks"
task_process_trip = f"{task_trip_prefix}.predict_ride"
broker_url = os.environ.get("CELERY_BROKER_URL", None)
result_backend = os.environ.get("CELERY_RESULT_BACKEND", None)
worker_prefetch_multiplier = int(
os.environ.get("CELERY_WORKER_PREFETCH_MULTIPLIER", 1)
)
El archivo anterior contiene toda la configuración necesaria para que se ejecute Celery. Las líneas 6 y 7 configuran la URL del proxy y el backend resultante (Redis en este caso). Estas configuraciones se tomarán del archivo env de la imagen de Docker, que explico más adelante al definir Docker-Compose.
Cuando un productor envía un mensaje a un intermediario de mensajes, necesita definir qué tarea consumir y en qué cola. Luego, según el nombre de la cola y el nombre de la tarea, Celery puede enviar el mensaje al hilo de trabajo consumidor correcto que procesa esa tarea. Entonces, en la línea 2, defino el nombre de la cola como "tasks.trip" y el nombre_tarea como "tasks.trip.tasks.predict_ride". Recuerde que estos parámetros se utilizan en el archivo core/services/trip_duration_api.py cuando el módulo web ejecuta las tareas de Celery.
Tareas de apio
Las tareas de apio se implementan en tareas/trip/tasks.py
import celery
import config
from core.utilities.cls_loguru_config import loguru_setting
from core.services.trip_duration_prediction_task import TripDurationTask
loguru_setting.setup_app_logging()
app = celery.Celery()
app.config_from_object(config.CeleryTasksGeneralConfig)
app.autodiscover_tasks(["tasks.trip"])
@celery.shared_task(time_limit=60, soft_time_limit=60)
def predict_ride(pu_location_id: int, do_location_id: int, trip_distance: float):
return TripDurationTask().process(pu_location_id, do_location_id, trip_distance)
Las líneas 9 a 11 son donde asigno las tareas a los nombres de tareas correspondientes. De esta manera, cuando el cliente llame a la tarea de viaje en el futuro, Celery activará la ejecución de la tarea en el archivo de script. En la línea 14, establecí el tiempo máximo para ejecutar la tarea en 60 segundos, lo que significa que si la tarea no se completa dentro de los 60 segundos, la tarea fallará y se notificará el error al cliente.
Tarea de predicción del tiempo de viaje
import pickle
import collections
# import boto3
from loguru import logger
import config
from core.utilities.cls_time import DictKeyTimer
from core.utilities.cls_constants import APIReply
# s3 = boto3.resource("s3")
# TRIP_DURATION_MODEL_KEY = config.ModelConfig.s3_trip_model_key()
# TRIP_DURATION_MODEL_BUCKET = config.ModelConfig.s3_bucket()
TRIP_DURATION_MODEL_PATH = config.ModelConfig.trip_duration_model()
with open(TRIP_DURATION_MODEL_PATH, "rb") as f_in:
dv, model = pickle.load(f_in)
def preprare_feature(pu_location_id: int, do_location_id: int, trip_distance: float):
features = {}
features["PU_DO"] = f"{pu_location_id}_{do_location_id}"
features["trip_distance"] = trip_distance
return features
class TripDurationTask:
@classmethod
def process(cls, pu_location_id: int, do_location_id: int, trip_distance: float):
try:
timings = collections.OrderedDict()
step_name = "feature_prepare"
with DictKeyTimer(timings, step_name):
features = preprare_feature(
pu_location_id, do_location_id, trip_distance
)
step_name = "model_predict"
with DictKeyTimer(timings, step_name):
pred = cls.predict(features)
logger.info(f"Predict duration:{pred}")
result = {
"duration": pred,
"reply_code": APIReply.SUCCESS,
"timings": timings,
}
# pylint: disable=broad-except
except Exception:
result = {
"duration": 0.0,
"reply_code": APIReply.ERROR_SERVER,
"timings": timings,
}
return result
@classmethod
def predict(cls, features: dict):
X = dv.transform(features)
preds = model.predict(X)
return float(preds[0])
El archivo anterior es la ubicación principal donde se implementa el modelo ML. Desde la línea 17 a la línea 19, cargo los pesos del modelo almacenados en la carpeta repositorio/modelos. El resto se explica por sí mismo, ya que el modelo de regresión toma datos que incluyen el lugar de recogida, el lugar de destino y la distancia de viaje, y luego predice el tiempo de viaje.
4. Conecta todo con Docker Compose
Como expliqué al principio, necesitamos 3 módulos: módulos Web, Redis y ML. Para conectar estas tres partes y permitirles comunicarse entre sí, utilizo docker-compose para definir tres definiciones de imágenes de Docker. Cuando se inicia la aplicación, se crean tres contenedores correspondientes y se comunican entre sí en la red acoplable. Los detalles se pueden encontrar en boot/docker/compose/trip_duration_prediction/docker-compose.yml.
version: "2.3"
services:
web:
build:
context: "${DC_UNIVERSE}"
dockerfile: "${WEB_VM_FILE}"
args:
VM_BASE: "${WEB_VM_BASE}"
VM_USER: "${WEB_VM_USER}"
VM_HOME: "${WEB_VM_HOME}"
VM_CODE: "${WEB_VM_CODE}"
VM_PIP: "${WEB_VM_PIP}"
platform: linux/amd64
image: ${DOCKER_IMAGE_PROJECT_ROOT_NAME}_web:${COMMIT_ID}
ports:
- "${HTTP_PORT}:8182"
volumes:
- "${HOST_REPO_DIR}:${WEB_VM_CODE}/repo"
restart: always
environment:
VERSION: "${WEB_VERSION}"
PROJECT_APP: "${WEB_VM_PROJECT_APP}"
REDIS_HOST: "redis"
REDIS_PORT: "${REDIS_PORT}"
CELERY_BROKER_URL: "redis://redis:${REDIS_PORT}"
CELERY_RESULT_BACKEND: "redis://redis:${REDIS_PORT}"
redis:
image: redis:latest
restart: on-failure
expose:
- "${REDIS_PORT}"
command: redis-server --port "${REDIS_PORT}"
worker:
build:
context: "${DC_UNIVERSE}"
dockerfile: "${WORKER_VM_FILE}"
args:
VM_BASE: "${WORKER_VM_BASE}"
VM_USER: "${WORKER_VM_USER}"
VM_HOME: "${WORKER_VM_HOME}"
VM_CODE: "${WORKER_VM_CODE}"
VM_CONDA: "${WORKER_VM_CONDA}"
platform: linux/amd64
volumes:
- "${HOST_REPO_DIR}:${WORKER_VM_CODE}/repo"
image: ${DOCKER_IMAGE_PROJECT_ROOT_NAME}_worker:${COMMIT_ID}
restart: always
runtime: nvidia
environment:
NVIDIA_VISIBLE_DEVICES: "0"
PROJECT_APP: "${WORKER_VM_PROJECT_APP}"
REDIS_HOST: "redis"
REDIS_PORT: "${REDIS_PORT}"
CELERY_BROKER_URL: "redis://redis:${REDIS_PORT}"
CELERY_RESULT_BACKEND: "redis://redis:${REDIS_PORT}"
.env 文件包含运行 docker-compose 时运行的所有参数,可以在 boot/docker/compose/trip_duration_prediciton/.env中找到。
DC_UNIVERSE=../../../..
HTTP_PORT=8182
REDIS_PORT=6379
GPU_MEMORY_SET=800
WEB_VERSION=v1
WEB_VM_FILE=boot/docker/uvicorn/Dockerfile
WEB_VM_BASE=python:3.8-alpine
WEB_VM_USER=docker
WEB_VM_HOME=/home/docker
WEB_VM_CODE=/home/docker/workspace
WEB_VM_PIP=./boot/docker/uvicorn/requirements.txt
WEB_VM_PROJECT_APP=apps.api
WORKER_VM_FILE=boot/docker/celery/trip/Dockerfile
WORKER_VM_BASE=nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04
WORKER_VM_USER=docker
WORKER_VM_HOME=/home/docker
WORKER_VM_CODE=/home/docker/workspace
WORKER_TORCH_DIR=/home/docker/.torch/models
WORKER_VM_CONDA=./boot/docker/celery/cuda90.yml
WORKER_VM_PROJECT_APP=tasks.trip
5. Pruebe la aplicación
Ejecute toda la aplicación. Como puede ver en la imagen a continuación, cuando inicio la API, hay tres contenedores ejecutándose.
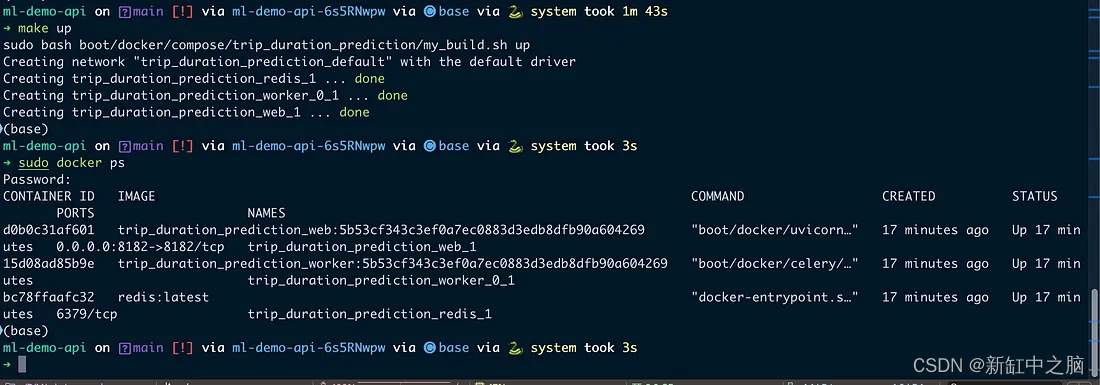
3 contenedores Docker en funcionamiento
El contenedor web se ejecuta en el puerto 8182 y podemos acceder a la documentación de la API a través de la dirección: localhost:8182/docs. Esta es una de las características específicas de FastAPI. Cuando completemos la implementación de la API sin esfuerzo, obtendremos la documentación de Swagger de inmediato.
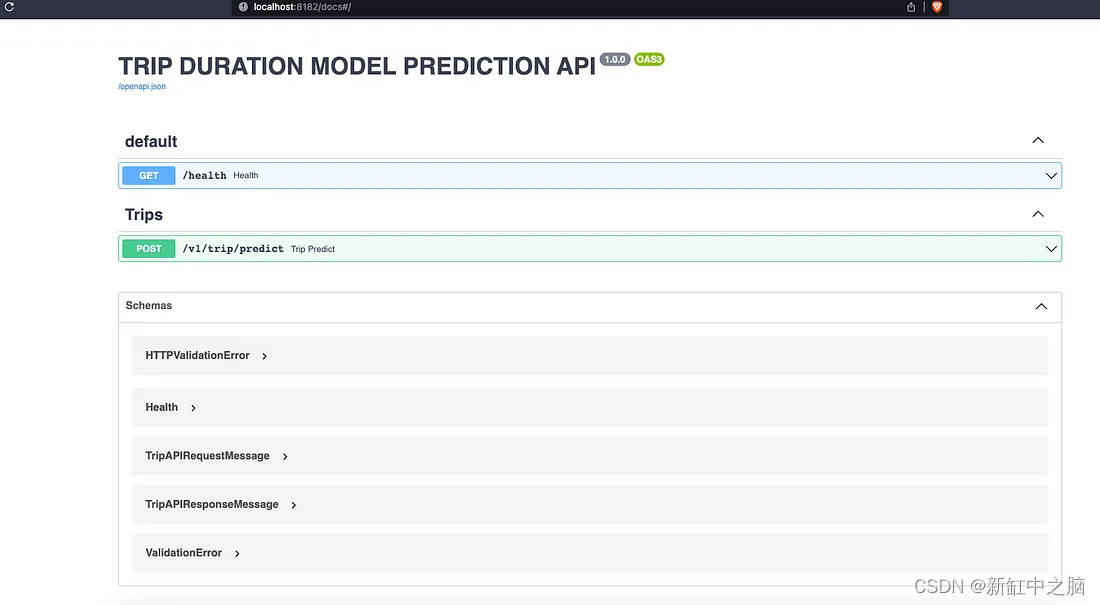
Documentación de API Swagger
Luego, intentemos ejecutar el punto final de API en /v1/trip/predict para ver las predicciones y verificar los resultados del registro.
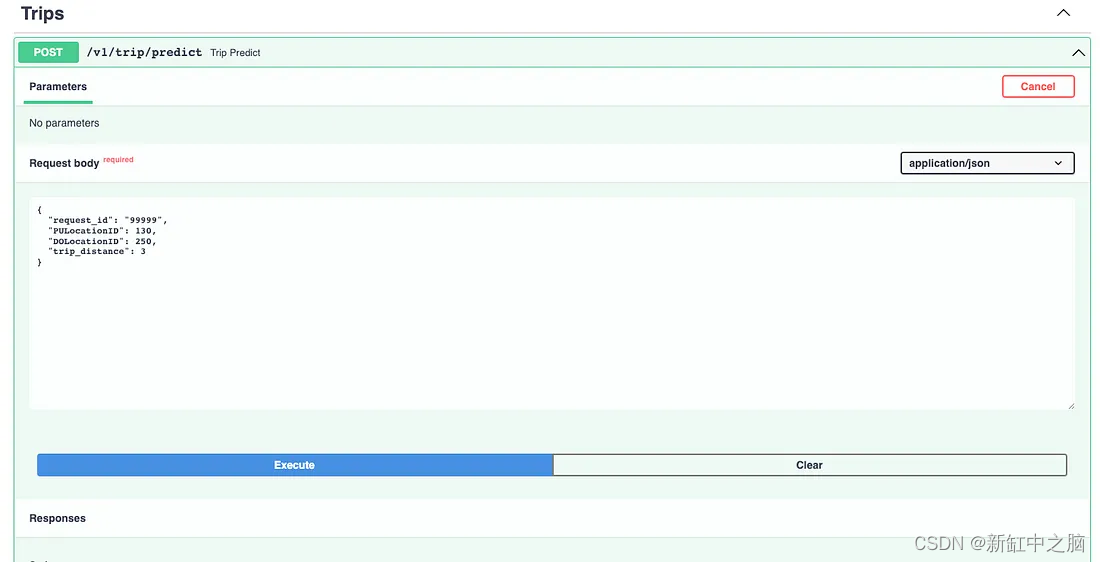
Punto de terminación de predicción de accidente cerebrovascular
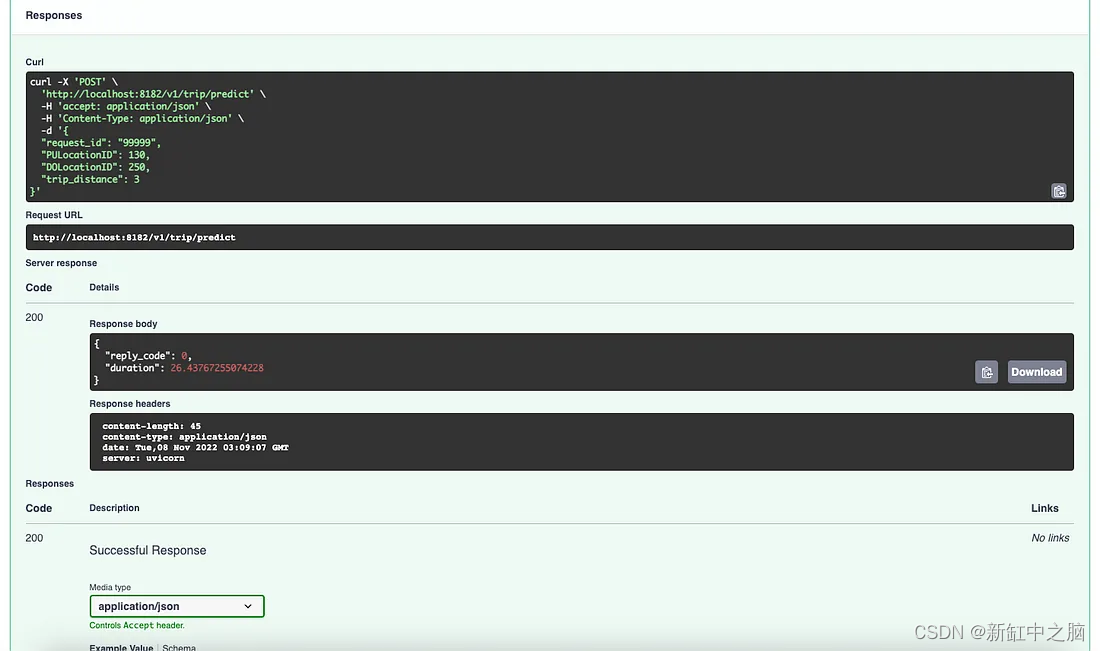
Respuesta de predicción de viaje

Registro para el módulo web
Registro para el módulo de trabajador
Una vez que se envía una solicitud desde el cliente al módulo web, se procesará de forma asincrónica en un hilo de trabajo utilizando Celery como un proceso o hilo separado. Esto trae muchos beneficios:
- Las tareas pesadas se manejan en un proceso/hilo separado, lo que puede ayudar a aumentar la cantidad de solicitudes que podemos manejar, ya que no bloquea las llamadas de los clientes.
- Los módulos de ML se implementan en otro hilo, empaquetados en una imagen acoplable separada, lo que significa que los científicos de datos o los ingenieros de aprendizaje automático pueden conservar su código de implementación y sus paquetes de forma independiente.
- Si la cantidad de solicitudes aumenta, podemos aumentar fácilmente la cantidad de módulos de ML para manejar el aumento de solicitudes, mientras que el módulo web puede permanecer igual.
6. Conclusión
En este blog, presenté cómo utilizar la arquitectura distribuida de la cola de tareas para implementar API que sirven módulos de aprendizaje automático. El uso de Celery, FastAPI y Redis puede ayudar a manejar mejor tareas de larga duración, como tiempos de ejecución de ML, mejorando el rendimiento general.
La idea original fue algo que desarrollé y mejoré mientras trabajaba en mi empresa anterior. Gracias Shan Hong y Jonathan, son excelentes ex colegas, aprendí muchas cosas buenas de ellos.
Si desea consultar el código completo, consulte github.
Enlace original: Implementación del servicio de aprendizaje automático basado en colas: BimAnt