prefacio
La razón para hacer este proyecto es que csdn me recomendó una pregunta y respuesta antes: el desarrollo de una aplicación móvil basada en el género de predicción de nombres de aprendizaje automático. Hice clic y descubrí que alguien ya lo había respondido. Hice clic en el enlace y eché un vistazo. Buen chico, ¿no es esto mirar hacia arriba en la tabla para calcular la probabilidad? Tiene una relación de medio centavo con el aprendizaje automático. Y creo que es una tontería usar nombres para predecir el género. Lo revisé y descubrí que una empresa patriótica muy conocida y una empresa extranjera tienen API que proporcionan nombres para predecir el género. Parece que puedes intentarlo.
Las quejas terminaron y el resultado final es el primero:
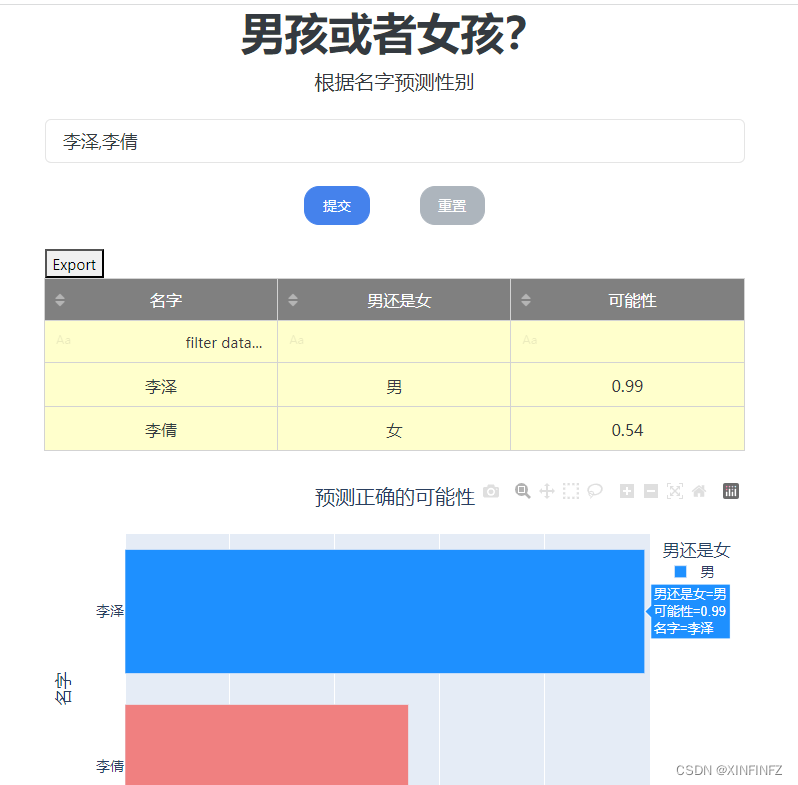
la precisión aún es posible, admite la consulta por lotes de nombres y la velocidad de respuesta de toda la página web también es muy rápida.
ambiente
Estoy usando python3.10 y necesito instalar los siguientes paquetes:
numpy
pandas
pypinyin
tensorflow-cpu
plotly (página web)
guión (página web)
método
1. Cómo obtener el conjunto de datos de nombres y géneros . Al principio, busqué de dónde procedía la base de datos utilizada detrás del artículo de búsqueda de tabla. Encontré su mapa de frecuencia de nombres en github, pero no pude encontrar la base de datos original. Se dice que fue tomada de algún kaifangjilu filtrado. Pensé que este tm no es ilegal, ¿no hay medios legales para obtener tales recursos de conjuntos de datos? Todavía encontré un conjunto de datos de 1,2 millones de nombres y géneros de personas en github:
haga clic y busque el archivo Chinese_Names_Corpus_Gender (120W).txt
2. Cómo extraer características de los nombres chinos y convertirlos a idiomas que las máquinas puedan entender. Después de mucha deliberación, decidí convertir primero el chino a pinyin sin notación fonética y luego convertir cada letra en un número alfabético. Resulta que el efecto es realmente bueno.
Específicamente como se muestra en la siguiente figura:
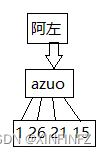
el código
El código se divide en tres partes, código de preparación de datos, código de entrenamiento de datos y código de aplicación de página web.
código de preparación de datos
Primero, convierta el archivo txt descargado en un archivo csv:

elimine la parte frontal y luego cambie el sufijo del archivo, se convierte en un archivo csv clásico separado por comas .
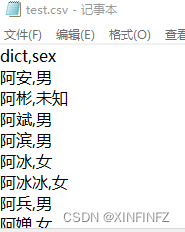
A continuación, comience a leer y procesar datos:
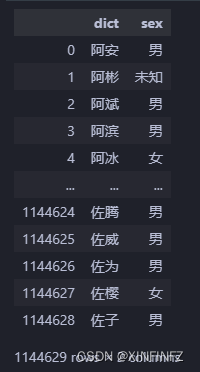
import pandas as pd
df = pd.read_csv("test.csv")
df
Aquí lo ejecuto en el cuaderno y el resultado es el siguiente:
Primero necesitamos convertir el género a 0,1 para hombre y mujer:
df['sex'].replace(['男', '女','未知'],
[0, 1, 2], inplace=True)
Luego convierta por lotes los nombres y guárdelos en un nuevo archivo csv:
from pypinyin import lazy_pinyin
import time
count = 0
a1 = time.time()
for x in df['dict']:
list_pinyin = lazy_pinyin(x) #["a","zuo"]
c = ''.join(list_pinyin) #["azuo"]
num_pinyin = [max(0.0, ord(char)-96.0) for char in c]
num_pinyin_pad = num_pinyin + [0.0] * max(0, 20 - len(num_pinyin))
df['dict'][count] = num_pinyin_pad[:15] #为了使输入向量固定长度,取前15个字符。
count+=1
a2 = time.time()
if count % 10000 == 0:
print(a2-a1)
df.to_csv('after_2.csv')
Aquí se tarda mucho, porque la cantidad de datos es grande, se tarda como media hora, dejo que imprima el tiempo de ejecución cada 10.000 datos, que se pueden eliminar. Luego hay un detalle que como se necesita ingresar el modelo, se debe fijar la longitud del vector, es decir, el nombre corto se llena con 0, y el nombre largo se corta, y siempre se toman las primeras quince letras . Puede salir después de guardar el csv.
código de entrenamiento de datos
Primero lea los datos, porque se encontró que el rendimiento de la clasificación binaria es mejor, por lo que excluimos los nombres con un género de 2, que se desconoce.
import pandas as pd
import numpy as np
df = pd.read_csv('after_2.csv')
df_binary = df[df['sex']!=2]
Prepare el vector de entrada:
import json
test_list = df_binary['dict'].values.tolist()
for i in range(len(test_list)):
test_list[i] = eval(test_list[i])
X = np.array(test_list,dtype = np.float32)
y = np.asarray(df_binary['sex'].values.tolist())
La forma de X es (1050353, 15), y la forma de y es (1050353,).
Divida el conjunto de entrenamiento y el conjunto de prueba:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,test_size=0.2,random_state=0)
Preparar el modelo:
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dense
from tensorflow.keras.optimizers import Adam
def lstm_model(num_alphabets=27, name_length=15, embedding_dim=256):
model = Sequential([
Embedding(num_alphabets, embedding_dim, input_length=15),
Bidirectional(LSTM(units=128, recurrent_dropout=0.2, dropout=0.2)),
Dense(1, activation="sigmoid")
])
model.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.001),
metrics=['accuracy'])
return model
Solo hay una capa de LSTM, y la CPU también se puede entrenar fácilmente (refiriéndose a entrenar una época toma media hora)
tren:
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping
# Step 1: Instantiate the model
model = lstm_model(num_alphabets=27, name_length=15, embedding_dim=256)
# Step 2: Split Training and Test Data
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=0)
# Step 3: Train the model
callbacks = [
EarlyStopping(monitor='val_accuracy',
min_delta=1e-3,
patience=5,
mode='max',
restore_best_weights=True,
verbose=1),
]
history = model.fit(x=X_train,
y=y_train,
batch_size=64,
epochs=3,
validation_data=(X_test, y_test),
callbacks=callbacks)
# Step 4: Save the model
model.save('boyorgirl.h5')
# Step 5: Plot accuracies
plt.plot(history.history['accuracy'], label='train')
plt.plot(history.history['val_accuracy'], label='val')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
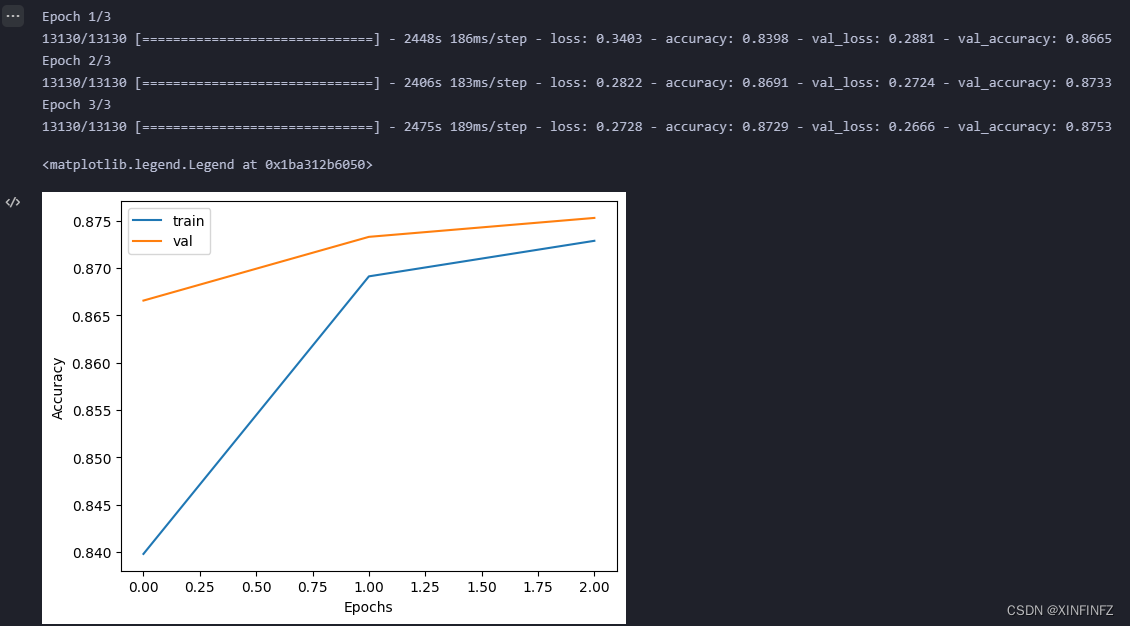
La parte de la red es una rueda construida por otros. La usé directamente. Debido a que la velocidad de entrenamiento es relativamente lenta, solo entrené durante tres rondas aquí. La tasa de precisión del conjunto de entrenamiento y el conjunto de prueba están mejorando, lo que está cerca de 0,88, lo que significa seguir entrenando, todavía hay margen de mejora:
código de desarrollo web
Esta pieza es relativamente larga, por lo que no la explicaré. Cabe señalar que configuré la aplicación al final para que se ejecute en el puerto 3000 en 0.0.0.0. Es decir, si la instalas en el servidor, puede acceder directamente a la dirección IP del servidor y agregar el número de puerto para acceder a la página web. Si es una vista local, configure 127.0.0.1 . Además, debe preparar un archivo de explicación faq.md
en el mismo directorio , que se encuentra en la parte inferior de la página web para obtener una explicación, como la siguiente imagen:

import os
import pandas as pd
import numpy as np
import re
from tensorflow.keras.models import load_model
from pypinyin import lazy_pinyin
import plotly.express as px
import dash
from dash import dash_table
import dash_bootstrap_components as dbc
from dash import dcc
from dash import html
from dash.dependencies import Input, Output, State
pred_model = load_model('boyorgirl.h5')
# Setup the Dash App
external_stylesheets = [dbc.themes.LITERA]
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
# Server
server = app.server
# FAQ section
with open('faq.md', 'r') as file:
faq = file.read()
# App Layout
app.layout = html.Table([
html.Tr([
html.H1(html.Center(html.B('男孩或者女孩?'))),
html.Div(
html.Center("根据名字预测性别"),
style={
'fontSize': 20}),
html.Br(),
html.Div(
dbc.Input(id='names',
value='李泽,李倩',
placeholder='输入多个名字请用逗号或者空格分开',
style={
'width': '700px'})),
html.Br(),
html.Center(children=[
dbc.Button('提交',
id='submit-button',
n_clicks=0,
color='primary',
type='submit'),
dbc.Button('重置',
id='reset-button',
color='secondary',
type='submit',
style={
"margin-left": "50px"})
]),
html.Br(),
dcc.Loading(id='table-loading',
type='default',
children=html.Div(id='predictions',
children=[],
style={
'width': '700px'})),
dcc.Store(id='selected-names'),
html.Br(),
dcc.Loading(id='chart-loading',
type='default',
children=html.Div(id='bar-plot', children=[])),
html.Br(),
html.Div(html.Center(html.B('关于该项目')),
style={
'fontSize': 20}),
dcc.Markdown(faq, style={
'width': '700px'})
])
],
style={
'marginLeft': 'auto',
'marginRight': 'auto'
})
# Callbacks
@app.callback([Output('submit-button', 'n_clicks'),
Output('names', 'value')], Input('reset-button', 'n_clicks'),
State('names', 'value'))
def update(n_clicks, value):
if n_clicks is not None and n_clicks > 0:
return -1, ''
else:
return 0, value
@app.callback(
[Output('predictions', 'children'),
Output('selected-names', 'data')], Input('submit-button', 'n_clicks'),
State('names', 'value'))
def predict(n_clicks, value):
if n_clicks >= 0:
# Split on all non-alphabet characters
# Restrict to first 10 names only
names = re.findall(r"\w+", value)
# Convert to dataframe
pred_df = pd.DataFrame({
'name': names})
list_list = []
# Preprocess
for x in names:
list_pinyin = lazy_pinyin(x)
c = ''.join(list_pinyin)
num_pinyin = [max(0.0, ord(char)-96.0) for char in c]
num_pinyin_pad = num_pinyin + [0.0] * max(0, 20 - len(num_pinyin))
list_list.append(num_pinyin_pad[:15])
# Predictions
result = pred_model.predict(list_list).squeeze(axis=1)
pred_df['男还是女'] = [
'女' if logit > 0.5 else '男' for logit in result
]
pred_df['可能性'] = [
logit if logit > 0.5 else 1.0 - logit for logit in result
]
# Format the output
pred_df['name'] = names
pred_df.rename(columns={
'name': '名字'}, inplace=True)
pred_df['可能性'] = pred_df['可能性'].round(2)
pred_df.drop_duplicates(inplace=True)
return [
dash_table.DataTable(
id='pred-table',
columns=[{
'name': col,
'id': col,
} for col in pred_df.columns],
data=pred_df.to_dict('records'),
filter_action="native",
filter_options={
"case": "insensitive"},
sort_action="native", # give user capability to sort columns
sort_mode="single", # sort across 'multi' or 'single' columns
page_current=0, # page number that user is on
page_size=10, # number of rows visible per page
style_cell={
'fontFamily': 'Open Sans',
'textAlign': 'center',
'padding': '10px',
'backgroundColor': 'rgb(255, 255, 204)',
'height': 'auto',
'font-size': '16px'
},
style_header={
'backgroundColor': 'rgb(128, 128, 128)',
'color': 'white',
'textAlign': 'center'
},
export_format='csv')
], names
else:
return [], ''
@app.callback(Output('bar-plot', 'children'), [
Input('submit-button', 'n_clicks'),
Input('predictions', 'children'),
Input('selected-names', 'data')
])
def bar_plot(n_clicks, data, selected_names):
if n_clicks >= 0:
# Bar Chart
data = pd.DataFrame(data[0]['props']['data'])
fig = px.bar(data,
x="可能性",
y="名字",
color='男还是女',
orientation='h',
color_discrete_map={
'男': 'dodgerblue',
'女': 'lightcoral'
})
fig.update_layout(title={
'text': '预测正确的可能性',
'x': 0.5
},
yaxis={
'categoryorder': 'array',
'categoryarray': selected_names,
'autorange': 'reversed',
},
xaxis={
'range': [0, 1]},
font={
'size': 14},
width=700)
return [dcc.Graph(figure=fig)]
else:
return []
if __name__ == '__main__':
app.run_server(host='0.0.0.0', port='3000', proxy=None, debug=False)