Hola a todos, este problema les trae un caso de red neuronal recurrente en red neuronal. Según el modelo LSTM bidireccional, la tarea de clasificación de texto se completa. El conjunto de datos proviene de Kaggle y se realiza la clasificación de texto de reseñas de películas.
Las reseñas de películas pueden contener emociones ricas: como gustos, disgustos, etc. El análisis de sentimientos es un problema de clasificación de textos, es decir, se utiliza para determinar si la emoción expresada por una determinada información textual pertenece a una emoción positiva o a una emoción negativa.
Esta práctica utiliza el conjunto de datos de reseñas de películas de IMDB para realizar análisis de opiniones sobre reseñas de películas mediante un LSTM bidireccional.
Directorio de artículos
1. Tratamiento de datos
El conjunto de datos de reseñas de películas de IMDB es un conjunto de datos de clasificación binaria clásica sobre reseñas de películas. IMDB filtra las opiniones positivas y negativas según la puntuación. Si la puntuación es ≥ 7 \ge 7 ≥ 7, se considera una opinión positiva; si la puntuación es ≤ 4 \le4 ≤ 4, se considera una opinión negativa . El conjunto de datos contiene datos del conjunto de entrenamiento y del conjunto de prueba, cada uno de los cuales consta de 25 000 piezas. Cada pieza de datos es una parte de la evaluación real de una película por parte del usuario, así como las tendencias emocionales de la audiencia hacia esta película. La estructura del directorio es la siguiente
├── train/
├── neg # 消极数据
├── pos # 积极数据
├── unsup # 无标签数据
├── test/
├── neg # 消极数据
├── pos # 积极数据
Elija una parte de los datos de revisión de la película en el directorio test/neg, el contenido es el siguiente:
“Cover Girl” es un musical mediocre de la Segunda Guerra Mundial que no tiene absolutamente nada memorable, salvo por su canción característica, “Long Ago and Far Away”.
El modelo LSTM no puede procesar directamente datos de texto y es necesario convertir las palabras del texto en representaciones vectoriales, que se denominan incrustaciones de palabras. Para mejorar la eficiencia de la conversión, cada palabra del texto generalmente se convierte en una identificación digital por adelantado, y luego la conversión de vectores se realiza utilizando el método presentado en la Sección 1. Por lo tanto, es necesario preparar un diccionario (Vocabulario) para convertir cada palabra del texto a su ID de serie en el diccionario. Al mismo tiempo, se debe establecer una palabra especial [UNK] para representar la palabra desconocida. Al procesar texto, si encuentra una palabra que no está en el vocabulario, siempre se procesará como [UNK].
1.1 Carga de datos
Los datos originales del conjunto de entrenamiento y del conjunto de prueba son 25 000 piezas respectivamente. En esta sección, el conjunto de prueba original se divide en dos partes, que se utilizan respectivamente como conjunto de verificación y conjunto de prueba, y se almacenan en el ./datasetdirectorio. Los datos se pueden cargar en la memoria utilizando el siguiente código:
import os
# 加载数据集
def load_imdb_data(path):
assert os.path.exists(path)
trainset, devset, testset = [], [], []
with open(os.path.join(path, "train.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
trainset.append((sentence, sentence_label))
with open(os.path.join(path, "dev.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
devset.append((sentence, sentence_label))
with open(os.path.join(path, "test.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
testset.append((sentence, sentence_label))
return trainset, devset, testset
# 加载IMDB数据集
train_data, dev_data, test_data = load_imdb_data("./dataset/")
# 打印一下加载后的数据样式
print(train_data[4])
(“la premisa de una scrooge afroamericana en la ciudad moderna y en apuros fue inspirada, pero nada más en esta película lo es. barrio negro en el que habita. No hay duda de las buenas intenciones de las personas involucradas. Parte del problema es que las raíces de la historia no se traducen bien en el entorno urbano de esta película, y el guión no logra que la actualización funcione. , el mensaje constante sobre compartir y dar se repite sin cesar, el público se cansa mucho antes de que la película llegue a su familiar final. Esta es una película con un mensaje que no sabe cuándo parar. en el papel principal, la talentosa cicely tyson ofrece una actuación demasiado tensa y, en ocasiones, las líneas son difíciles de entender.la novela de charles dickens ha sido adaptada tantas veces, es una lucha adaptarla de una manera que la haga fresca y relevante, a pesar de su mensaje muy relevante.”, '0')
De los resultados de salida, cada muestra cargada contiene dos partes: una cadena de texto y una etiqueta.
1.2 Construyendo la clase Dataset
Primero, construimos la clase IMDBDataset para la gestión de datos, que hereda de la clase paddle.io.DataSet.
Dado que la entrada aquí es una secuencia de texto, es necesario convertir cada palabra en el ID del número de serie de la palabra en el vocabulario, y luego consultar el vector de palabras correspondiente a estas palabras de acuerdo con el ID del vocabulario. El proceso es el mismo que que en el apartado 6.1 La operación de vectorización digital, tras obtener la palabra vector, se introducirá en el modelo para su posterior cálculo. Esto se puede hacer usando el método words_to_id en la clase IMDBDataset. Específicamente, el vocabulario word2id_dict se usa para mapear cada palabra en la secuencia a un número numérico correspondiente, lo cual es conveniente para una mayor conversión en un vector de palabras. Cuando una palabra en la secuencia no está incluida en el vocabulario, la palabra será reemplazada por [UNK] de manera predeterminada. El método words_to_id usa una tabla hash como se muestra en la Figura 6.14 para la conversión.
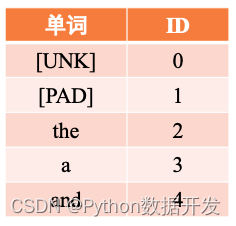
Figura 6.14 Ejemplo de tabla de palabras word2id
El código se implementa de la siguiente manera:
import paddle
import paddle.nn as nn
from paddle.io import Dataset
from utils.data import load_vocab
class IMDBDataset(Dataset):
def __init__(self, examples, word2id_dict):
super(IMDBDataset, self).__init__()
# 词典,用于将单词转为字典索引的数字
self.word2id_dict = word2id_dict
# 加载后的数据集
self.examples = self.words_to_id(examples)
def words_to_id(self, examples):
tmp_examples = []
for idx, example in enumerate(examples):
seq, label = example
# 将单词映射为字典索引的ID, 对于词典中没有的单词用[UNK]对应的ID进行替代
seq = [self.word2id_dict.get(word, self.word2id_dict['[UNK]']) for word in seq.split(" ")]
label = int(label)
tmp_examples.append([seq, label])
return tmp_examples
def __getitem__(self, idx):
seq, label = self.examples[idx]
return seq, label
def __len__(self):
return len(self.examples)
# 加载词表
word2id_dict= load_vocab("./dataset/vocab.txt")
# 实例化Dataset
train_set = IMDBDataset(train_data, word2id_dict)
dev_set = IMDBDataset(dev_data, word2id_dict)
test_set = IMDBDataset(test_data, word2id_dict)
print('训练集样本数:', len(train_set))
print('样本示例:', train_set[4])
Número de muestras del conjunto de entrenamiento: 25000
muestras Ejemplos: ([2, 976, 5, 32, 6860, 618, 7673, 8, 2, 13073, 2525, 724, 14, 22837, 18, 164, 416, 8, 10, 24, 701, 611, 1743, 7673, 7, 3, 56391, 21652, 36, 271, 3495, 5, 2, 11373, 4, 13244, 8, 2, 2157, 350, 4, 328, 4118, 12, 48810, 52, 7, 60, 860, 43, 2, 56, 4393, 5, 2, 89, 4152, 182, 5, 2, 461, 7, 11, 7321, 7730, 86, 7931, 107, 72, 2 , 2830, 1165, 5, 10, 151, 4, 2, 272, 1003, 6, 91, 2, 10491, 912, 826, 2, 1750, 889, 43, 6723, 4, 647, 7, 2535, 38, 39222, 2, 357, 398, 1505, 5, 12, 107, 179, 2, 20, 4279, 83, 1163, 692, 10, 7, 3, 889, 24, 11, 141, 118, 50, 6, 28642, 8, 2, 490, 1469, 2, 1039, 98975, 24541, 344, 32, 2074, 11852, 1683, 4, 29, 286, 478, 22, 823, 6, 5222, 2, 1490, 6893, 883, 41, 71, 3254, 38, 100, 1021, 44, 3, 1700, 6, 8768, 12, 8, 3, 108, 11, 146, 12, 1761, 4, 92295, 8, 2641, 5 , 83, 49, 3866, 5352], 0)
1.3 Encapsulando el cargador de datos
Después de construir la clase Dataset, construimos el DataLoader correspondiente para la iteración de datos por lotes. A diferencia del DataLoader en los capítulos anteriores, el DataLoader aquí necesita introducir las siguientes dos funciones:
- Límite de longitud: la longitud de la secuencia debe controlarse dentro de un cierto rango para evitar que algunos datos sean demasiado largos y afecten el efecto general del entrenamiento.
- Relleno de longitud: los modelos de redes neuronales generalmente requieren que las longitudes de secuencia de los datos en el mismo lote sean las mismas, pero cuando se agrupan, las secuencias de diferentes longitudes generalmente se colocan en el mismo lote, por lo que las secuencias deben ser rellenadas.
Para el límite de longitud, usamos el parámetro max_seq_len para truncar el texto que es demasiado largo.
Para el relleno de longitud, primero contamos la longitud máxima de la secuencia en el lote de datos, y llenamos la secuencia corta con algunos marcadores de posición [PAD] que no tienen un significado especial, y rellenamos la longitud hasta la longitud máxima del lote, de modo que podemos hacer que los datos del mismo lote se vuelvan regulares. Por ejemplo, dadas dos oraciones:
- Oración 1: Esta película fue una mierda.
- 句子2: Me quedé atascado en el tráfico de camino al cine.
Complete las dos oraciones anteriores para convertirse en:
- 句子1: Esta película fue una porquería [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
- 句子2: Me quedé atascado en el tráfico de camino al teatro.
Específicamente, esta sección define una función collate_fn para truncar y completar datos. Esta función se puede pasar a DataLoader como una función de devolución de llamada. Antes de devolver un lote de datos, DataLoader llama a esta función para procesar los datos y devuelve los datos de secuencia procesados y etiquetas correspondientes.
Además, después de completar la secuencia corta con el marcador de posición [PAD], cuando se realiza la tarea de clasificación de texto, la posición [PAD] no es necesaria de forma predeterminada, por lo que se debe usar la variable seq_lens para representar la longitud real de la no - Posición de [PAD] en la secuencia. seq_lens se puede obtener y devolver cuando la función collate_fn procesa datos por lotes. Cabe señalar que dado que la clase RunnerV3 obtiene datos de acuerdo con los datos de entrada y la información de la etiqueta de forma predeterminada, es necesario devolver los datos de la secuencia y la longitud de la secuencia como una tupla como datos de entrada para facilitar que RunnerV3 analice los datos.
El código se implementa de la siguiente manera:
from functools import partial
def collate_fn(batch_data, pad_val=0, max_seq_len=256):
seqs, seq_lens, labels = [], [], []
max_len = 0
for example in batch_data:
seq, label = example
# 对数据序列进行截断
seq = seq[:max_seq_len]
# 对数据截断并保存于seqs中
seqs.append(seq)
seq_lens.append(len(seq))
labels.append(label)
# 保存序列最大长度
max_len = max(max_len, len(seq))
# 对数据序列进行填充至最大长度
for i in range(len(seqs)):
seqs[i] = seqs[i] + [pad_val] * (max_len - len(seqs[i]))
return (paddle.to_tensor(seqs), paddle.to_tensor(seq_lens)), paddle.to_tensor(labels)
Personalicemos un lote de datos para probar la función collate_fn Aquí asumimos que max_seq_len es 5 y luego definimos dos datos con longitudes de secuencia de 6 y 3, respectivamente, y los pasamos a la función collate_fn.
max_seq_len = 5
batch_data = [[[1, 2, 3, 4, 5, 6], 1], [[2,4,6], 0]]
(seqs, seq_lens), labels = collate_fn(batch_data, pad_val=word2id_dict["[PAD]"], max_seq_len=max_seq_len)
print("seqs: ", seqs)
print("seq_lens: ", seq_lens)
print("labels: ", labels)
seqs: Tensor (forma = [2, 5], dtype = int64, place = CPUPlace, stop_gradient = True,
[[1, 2, 3, 4, 5],
[2, 4, 6, 0, 0]])
seq_lens: Tensor(shape=[2], dtype=int64, place=CPUPlace, stop_gradient=True,
[5, 3])
etiquetas: Tensor(shape=[2], dtype=int64, place=CPUPlace, stop_gradient=True,
[1, 0])
Puede verse que la secuencia de longitud 6 en la secuencia original se trunca a 5, mientras que la secuencia de longitud 3 en la secuencia original se rellena a 5 y [PAD]se devuelve la longitud que no es de secuencia.
Luego, pasamos collate_fn a DataLoader como una función de devolución de llamada. Cuando devuelve un lote de datos, puede procesar el lote de datos a través de la función collate_fn. Cabe señalar aquí que los parámetros de palabra clave en la función collate_fn se establecen a través de la función parcial y se devuelve un nuevo objeto de función como collate_fn.
Al usar DataLoader para iterar datos en lotes, es posible que la cantidad de muestras de datos en el último lote no sea suficiente para establecer el tamaño del lote. Puede usar el parámetro drop_last para determinar si descartar los datos del último lote.
max_seq_len = 256
batch_size = 128
collate_fn = partial(collate_fn, pad_val=word2id_dict["[PAD]"], max_seq_len=max_seq_len)
train_loader = paddle.io.DataLoader(train_set, batch_size=batch_size, shuffle=True, drop_last=False, collate_fn=collate_fn)
dev_loader = paddle.io.DataLoader(dev_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn)
test_loader = paddle.io.DataLoader(test_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn)
2. Construcción de modelos
La estructura completa del modelo de esta práctica se muestra en la Figura 6.15.
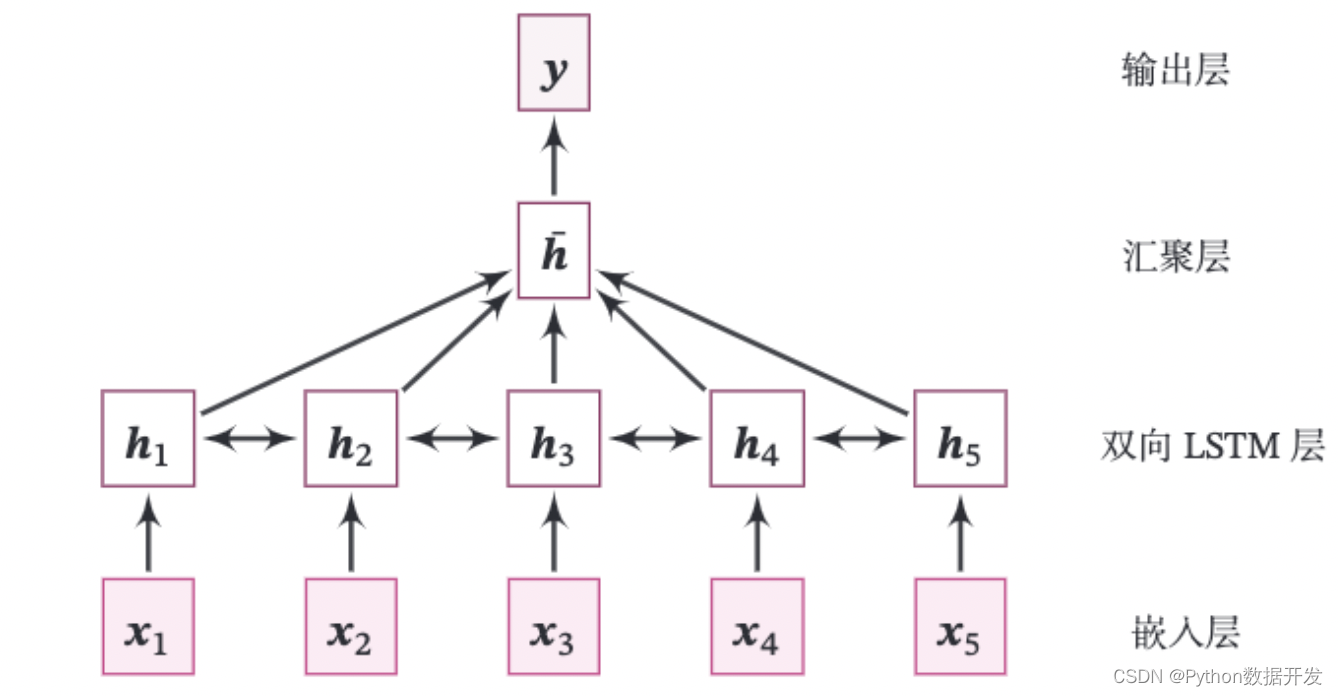
Figura 6.15 Estructura del modelo de clasificación de texto basado en LSTM bidireccional
Consta de las siguientes partes:
(1) Capa de incrustación: vectorizar la secuencia de entrada de números, es decir, asignar cada número a un vector. Esto se hace directamente usando la API de paddle: paddle.nn.Embedding.
class paddle.nn.Embedding(num_embeddings, embedding_dim, padding_idx=Ninguno, sparse=False, weight_attr=Ninguno, nombre=Ninguno)
La API tiene dos parámetros importantes: num_embeddings indica el número de incrustaciones que se utilizarán. embedding_dim representa la dimensión del vector de incrustación.
paddle.nn.Embedding construirá automáticamente una matriz de incrustación bidimensional según [num_embeddings, embedding_dim]. El parámetro padding_idx se refiere al ID de vocabulario correspondiente al marcador de posición [PAD] utilizado para completar la secuencia. Cuando se encuentra este ID durante el proceso de entrenamiento, sus parámetros y gradientes correspondientes se llenarán con 0. En aras de la simplicidad en la implementación, generalmente ponemos [PAD] en primer lugar en el vocabulario, es decir, el ID correspondiente es 0.
(2) Capa LSTM bidireccional: recibe una secuencia de vectores y actualiza las unidades recurrentes con avance y retroceso, respectivamente. Aquí usamos directamente la API de paddle: paddle.nn.LSTM para completar. Solo necesita establecer la dirección del parámetro en bidireccional al definir el LSTM, y puede usar el LSTM bidireccional directamente.
Pensando: Al implementar un LSTM bidireccional, debido a que se debe realizar la finalización de la secuencia, al calcular el LSTM inverso, si el marcador de posición [PAD] afectará la actualización del gradiente del parámetro LSTM. Si es así, ¿cómo eliminar el impacto?
Nota: Al llamar a paddle.nn.LSTM para implementar LSTM bidireccional, puede pasar la longitud real del lote de datos, paddle.nn.LSTM procesará los datos de acuerdo con la longitud de secuencia real, enmascare el marcador de posición [PAD], [PAD] ] la posición devolverá el vector cero.
(3) Capa de agregación: los estados ocultos en todas las posiciones de la capa LSTM bidireccional se promedian como la representación de la oración completa.
(4) Capa de salida: La capa de salida, la probabilidad de clasificación de salida. Aquí puede llamar directamente a paddle.nn.Linear para completar.
Ejercicio práctico 6.5 : Mejore el operador LSTM en la Sección 6.3.1.1 para admitir muestras de secuencias de diferentes longitudes en un lote.
La capa de incrustación, la capa LSTM bidireccional y la capa lineal en el modelo anterior se pueden implementar llamando directamente a la API de Paddle. Aquí solo necesitamos implementar el operador de la capa de agregación. Cabe señalar que aunque el LSTM integrado de la paleta voladora devolverá un vector cero a la posición [PAD] después de pasar la longitud real de los datos del lote, teniendo en cuenta el desacoplamiento entre la capa de agregación y el modelo que procesa el datos de secuencia, en esta sección En la implementación de la capa de agregación, la posición [PAD] está enmascarada.
Operador de capa de agregación
El operador de la capa de agrupación promedia los estados ocultos en todas las posiciones de la capa LSTM bidireccional como una representación de la oración completa. Aquí implementamos el operador AveragePooling para la agregación de estados ocultos. Primero, el vector de longitud de secuencia se usa para generar una matriz de máscara (Mask), que se usa para enmascarar el vector de la posición [PAD] en la secuencia de texto, y luego se suma el vector de la secuencia y luego se toma la media. El código se implementa de la siguiente manera:
Combinando los módulos anteriores, la implementación del código es la siguiente:
class AveragePooling(nn.Layer):
def __init__(self):
super(AveragePooling, self).__init__()
def forward(self, sequence_output, sequence_length):
sequence_length = paddle.cast(sequence_length.unsqueeze(-1), dtype="float32")
# 根据sequence_length生成mask矩阵,用于对Padding位置的信息进行mask
max_len = sequence_output.shape[1]
mask = paddle.arange(max_len) < sequence_length
mask = paddle.cast(mask, dtype="float32").unsqueeze(-1)
# 对序列中paddling部分进行mask
sequence_output = paddle.multiply(sequence_output, mask)
# 对序列中的向量取均值
batch_mean_hidden = paddle.divide(paddle.sum(sequence_output, axis=1), sequence_length)
return batch_mean_hidden
Resumen Modelo
Los operadores anteriores se agregan y combinan en el modelo de clasificación final. El código se implementa de la siguiente manera:
class Model_BiLSTM_FC(nn.Layer):
def __init__(self, num_embeddings, input_size, hidden_size, num_classes=2):
super(Model_BiLSTM_FC, self).__init__()
# 词典大小
self.num_embeddings = num_embeddings
# 单词向量的维度
self.input_size = input_size
# LSTM隐藏单元数量
self.hidden_size = hidden_size
# 情感分类类别数量
self.num_classes = num_classes
# 实例化嵌入层
self.embedding_layer = nn.Embedding(num_embeddings, input_size, padding_idx=0)
# 实例化LSTM层
self.lstm_layer = nn.LSTM(input_size, hidden_size, direction="bidirectional")
# 实例化聚合层
self.average_layer = AveragePooling()
# 实例化输出层
self.output_layer = nn.Linear(hidden_size * 2, num_classes)
def forward(self, inputs):
# 对模型输入拆分为序列数据和mask
input_ids, sequence_length = inputs
# 获取词向量
inputs_emb = self.embedding_layer(input_ids)
# 使用lstm处理数据
sequence_output, _ = self.lstm_layer(inputs_emb, sequence_length=sequence_length)
# 使用聚合层聚合sequence_output
batch_mean_hidden = self.average_layer(sequence_output, sequence_length)
# 输出文本分类logits
logits = self.output_layer(batch_mean_hidden)
return logits
3. Formación modelo
Esta sección se basará en RunnerV3 para el entrenamiento. Primero, especifique los hiperparámetros para el entrenamiento del modelo, y luego configure el modelo, el optimizador, la función de pérdida y los indicadores de evaluación. Se usa la función de pérdida, y la función de pérdida calculará paddle.nn.CrossEntropyLossinternamente los resultados de la predicción. softmaxEl modelo de predicción digital La salida de la capa de salida logitsno necesita ser normalizada usando softmax Después de definir los componentes relevantes del Runner, se puede realizar el entrenamiento del modelo. El código se implementa de la siguiente manera.
import time
import random
import numpy as np
from nndl import Accuracy, RunnerV3
np.random.seed(0)
random.seed(0)
paddle.seed(0)
# 指定训练轮次
num_epochs = 3
# 指定学习率
learning_rate = 0.001
# 指定embedding的数量为词表长度
num_embeddings = len(word2id_dict)
# embedding向量的维度
input_size = 256
# LSTM网络隐状态向量的维度
hidden_size = 256
# 实例化模型
model = Model_BiLSTM_FC(num_embeddings, input_size, hidden_size)
# 指定优化器
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, beta1=0.9, beta2=0.999, parameters= model.parameters())
# 指定损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
# 指定评估指标
metric = Accuracy()
# 实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 模型训练
start_time = time.time()
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=10, log_steps=10, save_path="./checkpoints/best.pdparams")
end_time = time.time()
print("time: ", (end_time-start_time))
[Tren] época: 0/3, paso: 0/588, pérdida: 0,69294
Trace las imágenes de pérdida en los conjuntos de entrenamiento y validación y las imágenes de precisión en el conjunto de validación durante el entrenamiento:
from nndl import plot_training_loss_acc
# 图像名字
fig_name = "./images/6.16.pdf"
# sample_step: 训练损失的采样step,即每隔多少个点选择1个点绘制
# loss_legend_loc: loss 图像的图例放置位置
# acc_legend_loc: acc 图像的图例放置位置
plot_training_loss_acc(runner, fig_name, fig_size=(16,6), sample_step=10, loss_legend_loc="lower left", acc_legend_loc="lower right")
La figura 6.16 muestra la curva de pérdida del modelo de clasificación de texto durante el entrenamiento y la curva de precisión en el conjunto de validación. En la imagen de pérdida, la línea continua representa el cambio de pérdida en el conjunto de entrenamiento y la línea discontinua representa el cambio de pérdida en la validación. Se puede ver que a medida que avanza el proceso de entrenamiento, la pérdida del conjunto de entrenamiento continúa disminuyendo y la pérdida en el conjunto de validación comienza a aumentar después de aproximadamente 200 pasos. Esto se debe a que se produjo un sobreajuste durante el proceso de entrenamiento, y puede optar por guardarlo durante el proceso de entrenamiento. El modelo con el mejor rendimiento en el conjunto de validación resuelve este problema. Como se puede ver en la curva de tasa de precisión, primero la tasa de precisión en el conjunto de validación aumenta significativamente, y luego la la tasa de precisión no aumenta después de unos 200 pasos, y debido al sobreajuste Debido a la combinación de factores, la precisión en el conjunto de validación se reduce ligeramente.
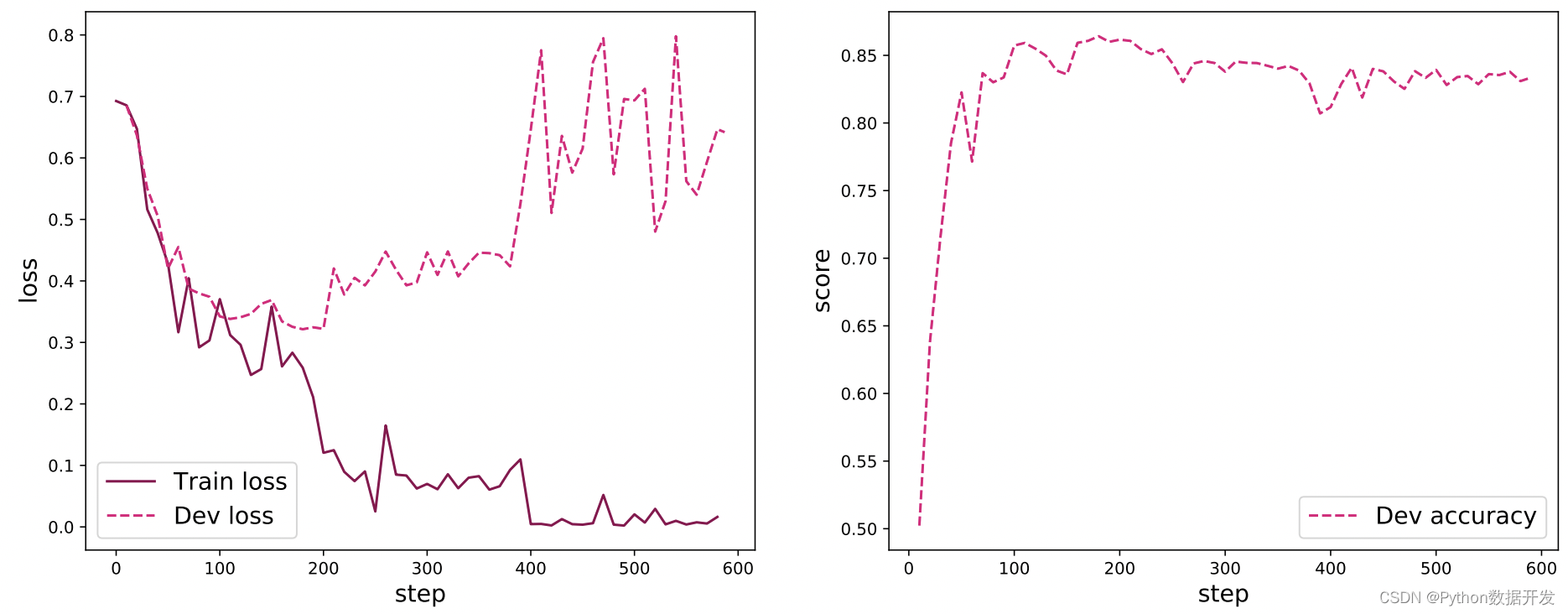
Figura 6.16 Diagrama de variación del modelo de clasificación de pérdida de texto de entrenamiento
4. Evaluación del modelo
Cargue el modelo que mejor se desempeñó durante el entrenamiento, luego use el conjunto de prueba para probar.
model_path = "./checkpoints/best.pdparams"
runner.load_model(model_path)
accuracy, _ = runner.evaluate(test_loader)
print(f"Evaluate on test set, Accuracy: {
accuracy:.5f}")
5. Modelo de predicción
Dada una oración arbitraria, use el modelo entrenado para predecir la polaridad del sentimiento contenida en la oración.
id2label={
0:"消极情绪", 1:"积极情绪"}
text = "this movie is so great. I watched it three times already"
# 处理单条文本
sentence = text.split(" ")
words = [word2id_dict[word] if word in word2id_dict else word2id_dict['[UNK]'] for word in sentence]
words = words[:max_seq_len]
sequence_length = paddle.to_tensor([len(words)], dtype="int64")
words = paddle.to_tensor(words, dtype="int64").unsqueeze(0)
# 使用模型进行预测
logits = runner.predict((words, sequence_length))
max_label_id = paddle.argmax(logits, axis=-1).numpy()[0]
pred_label = id2label[max_label_id]
print("Label: ", pred_label)
6. Resumen
Este capítulo profundiza la comprensión de los conceptos básicos, la estructura de la red y las dependencias de largo alcance de las redes neuronales recurrentes a través de la práctica. Construimos una tarea de suma numérica e implementamos modelos SRN y LSTM a mano para comparar su capacidad de memoria en la tarea de suma numérica. En la parte práctica, utilizamos un modelo LSTM bidireccional para una tarea de clasificación de texto: IMDB Movie Review Sentiment Analysis, y aprendemos cómo convertir datos de texto en representaciones vectoriales a través de una capa incrustada.