En la primera mitad de 2023, el uso generalizado de API (como OpenAI) para crear una infraestructura basada en modelos de lenguaje a gran escala (LLM) dará forma en gran medida al campo del software.
LangChain y LlamaIndex han jugado un papel importante en esta tendencia. En la segunda mitad de 2023, la reducción del umbral del modelo de ajuste fino (o ajuste de comando) en el flujo de trabajo de operación y mantenimiento de LLMOps se ha convertido básicamente en el proceso estándar en la industria. El desarrollo de esta tendencia se debe principalmente a las siguientes razones. y otros métodos, Llama 2 se puede ajustar en una sola tarjeta T4, lo que antes era inimaginable: 2. La capacidad de procesar datos confidenciales dentro de la empresa, 3. Después del ajuste, se puede desarrollar para superar ChatGPT y GPT. en ciertas tareas específicas -4 y otros potenciales de rendimiento del modelo. Los LLMOps incluyen principalmente:
- Ajuste de LLM: desde el lanzamiento de LLaMA, el ajuste de instrucciones se ha vuelto cada vez más popular;
- Creación de un marco LLM: bibliotecas como LangChain y LlamaIndex se encargan de esto, lo que le permite consultar bases de datos vectoriales, mejorar la memoria del modelo o proporcionar varias herramientas.
- Técnicas de optimización para la inferencia: a medida que los LLM crecen en tamaño, se vuelve cada vez más importante aplicar técnicas de optimización para garantizar que el modelo se pueda utilizar de manera eficiente para la inferencia. Las técnicas incluyen cuantificación de peso (4 bits, 3 bits), poda, destilación de conocimientos, etc.
- Implementación de LLM: estos modelos se pueden implementar localmente como llama.cpp o en la nube como Text Generative Inference de Huggingface o vLLM.
La seguridad de los datos es algo que toda empresa debe tomar en serio. Para mejorar la productividad, reducir costos y aumentar la eficiencia, deben aceptar las herramientas que aportan las nuevas tecnologías. El despliegue de la privatización sigue siendo muy atractivo para las empresas. La herramienta del modelo de lenguaje grande combinada con los datos de la empresa puede mejorar enormemente la productividad de la empresa.
¿Preguntas sobre cómo mejorar el rendimiento de una aplicación LLM cuando el LLM previamente capacitado no funciona como se esperaba o deseaba? En la actualidad, existen aproximadamente dos enfoques.
Generación aumentada de recuperación (RAG) o ajuste fino del modelo, RAG: este enfoque integra capacidades de recuperación (o búsqueda) en la generación de texto LLM. Combina un sistema de recuperación, que obtiene fragmentos de documentos relevantes de un gran corpus, y LLM, que utiliza la información de estos fragmentos para generar respuestas. Básicamente, RAG ayuda al modelo a "encontrar" información externa para mejorar su respuesta. LangChain y LlamaIndex pertenecen al método RAG.
Cuestiones que se abordarán en la privatización de LLM
Para los usuarios finales, la implementación privatizada de LLM en la empresa es el método de acceso y la fuente del contenido de acceso.
- Basado en el modelo de lenguaje grande de código abierto/modelo de lenguaje grande de desarrollo propio SFT, se utilizará dentro de la empresa en forma de API/APP/complementos web;
- Construya un mapa de conocimiento/base de datos basado en los datos de la empresa dentro de la empresa y los datos públicos relacionados con la industria, y el modelo de lenguaje grande se refiere al mapa de conocimiento/base de datos construido para proporcionar respuestas más precisas;
El diagrama de bloques del sistema de implementación de la privatización empresarial es el siguiente: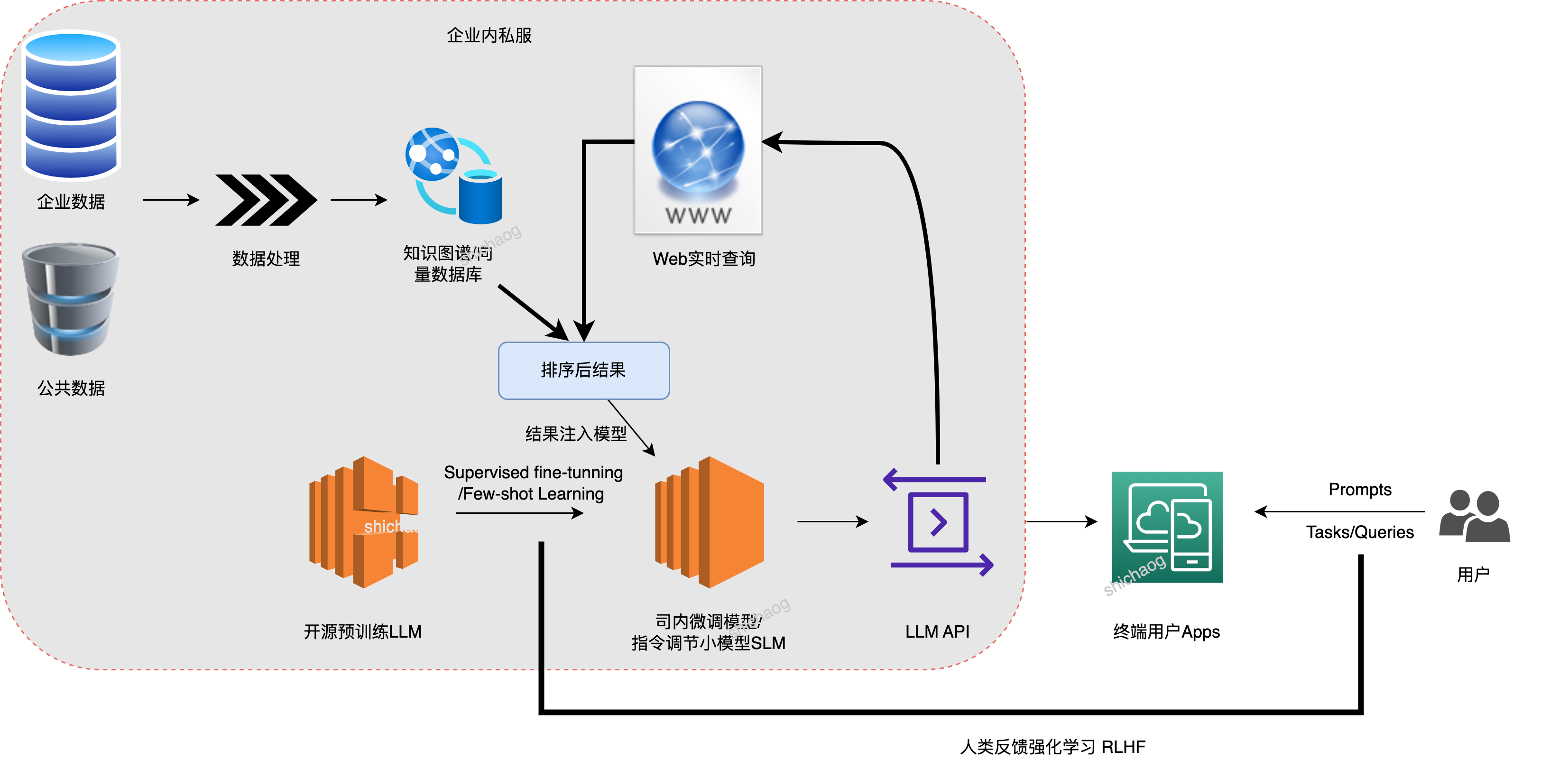
En consecuencia, es necesario considerar los siguientes cinco aspectos:
Entrenamiento y ajuste de modelos: entrene y ajuste modelos de lenguaje grandes para mejorar su rendimiento y precisión.
Limpieza y preprocesamiento del conjunto de datos: limpieza y preprocesamiento del conjunto de datos sin procesar para generar un conjunto de datos adecuado para entrenar modelos de lenguaje grandes.
Implementación y gestión del modelo: implemente el modelo de lenguaje a gran escala capacitado en el entorno de producción y adminístrelo y manténgalo.
Optimización y escalamiento del rendimiento: optimización del rendimiento y escalamiento de modelos de lenguaje grandes para mejorar su eficiencia y escalabilidad.
Protección de seguridad y privacidad: protección de seguridad y privacidad para modelos de lenguajes grandes para evitar problemas de seguridad como la divulgación de información confidencial y ataques de piratas informáticos.
Para el entrenamiento del modelo, está Huggingface rtl , y luego está Microsoft deepspeed , y las mejoras continuas surgen sin cesar.
Y los datos están en manos de la empresa y la limpieza de datos en la página web no es adecuada para la empresa. Para las empresas, los permisos de seguridad y privacidad son un gran problema. Este artículo primero analiza los gráficos de conocimiento y las bases de datos vectoriales.
En las bases de datos relacionales tradicionales, los datos suelen estar organizados en forma de tablas. Sin embargo, el surgimiento de la era de la IA ha traído consigo una gran cantidad de datos no estructurados, incluidas imágenes, audio y texto. No es apropiado almacenar estos datos en formato tabular y es necesario utilizar algoritmos de aprendizaje automático para convertir estos datos en representaciones vectoriales de "características". La aparición de la base de datos de vectores tiene como objetivo resolver el almacenamiento y procesamiento de estos vectores.
La base de las bases de datos vectoriales es la indexación de datos. Con técnicas como la indexación invertida, las bases de datos vectoriales pueden realizar búsquedas de similitud de manera eficiente agrupando e indexando características vectoriales. Las técnicas de cuantificación de vectores ayudan a mapear vectores de alta dimensión en espacios de baja dimensión, reduciendo así los requisitos de almacenamiento y cálculo. Al utilizar técnicas de indexación, las bases de datos vectoriales pueden buscar vectores de manera eficiente mediante diversas operaciones, como la suma de vectores, el cálculo de similitudes y el análisis de conglomerados.
El gran modelo actual basado en datos masivos plantea algunos desafíos a la base de datos:
- Admite grandes cantidades de datos: la generación de modelos de IA a escala requiere grandes cantidades de datos para el entrenamiento con el fin de capturar información semántica y contextual compleja. Como resultado, los volúmenes de datos se están disparando. Las bases de datos vectoriales, como administradores de datos capacitados, desempeñan un papel vital en el manejo y gestión eficiente de cantidades tan grandes de datos.
- Habilite la búsqueda y coincidencia de similitudes precisas: el texto generado a partir de modelos de IA generativos a gran escala a menudo requiere una búsqueda y coincidencia de similitudes para proporcionar respuestas, recomendaciones o resultados coincidentes precisos. Los métodos tradicionales de búsqueda basados en palabras clave pueden resultar insuficientes en términos de semántica y contexto complejos. Las bases de datos vectoriales brillan en este campo, aportando gran relevancia y eficacia para estas tareas.
- Admite procesamiento de datos multimodal: la generación a gran escala de modelos de inteligencia artificial va más allá de los datos de texto y puede procesar datos multimodales, como imágenes y voz. Como sistema integral capaz de almacenar y procesar múltiples tipos de datos, las bases de datos vectoriales respaldan eficazmente el almacenamiento, indexación y consulta de datos multimodales, mejorando su versatilidad.
Algunas bases de datos confidenciales ya admiten esta característica de las bases de datos vectoriales.

SQLite: SQLite es una base de datos integrada liviana que admite el almacenamiento de texto grande, datos binarios y multimedia, y se puede consultar mediante declaraciones SQL. SQLite se usa ampliamente en aplicaciones móviles, pero el rendimiento de las consultas puede verse afectado por el volumen de datos y la complejidad de las consultas.
Realm: Realm es una base de datos móvil que admite el almacenamiento y la gestión de datos estructurados y no estructurados, y proporciona funciones de consulta y sincronización de datos de alto rendimiento. Realm admite el uso de modelos de lenguaje grandes en aplicaciones móviles y puede admitir grandes conjuntos de datos a través de sus capacidades de fragmentación.
Realm Database: Realm Database es una base de datos en la nube lanzada por Realm, que admite una integración perfecta con la base de datos móvil Realm y proporciona funciones de administración y almacenamiento de datos en la nube. Realm Database también admite el uso de modelos de lenguaje grandes en aplicaciones móviles y puede admitir grandes conjuntos de datos a través de sus capacidades de fragmentación.
Las bases de datos móviles como SQLite, Realm y Realm Database pueden admitir modelos de lenguaje grandes, pero los métodos de soporte específicos y el rendimiento pueden variar. Al elegir una base de datos, debe considerar factores como el volumen de datos, la complejidad de las consultas, el rendimiento y la seguridad para elegir el sistema de base de datos que mejor se adapte a sus necesidades.
Neo4j es un sistema de gestión de bases de datos de gráficos (GDMS) que utiliza un modelo de gráfico para almacenar y gestionar datos. Neo4j se puede utilizar para almacenar y gestionar redes relacionales complejas, como redes sociales, redes de cadenas de suministro y gráficos de conocimiento. Neo4j admite consultas y análisis de gráficos rápidos, lo que facilita el descubrimiento de relaciones y patrones en los datos.
MongoDB es un sistema de gestión de bases de datos basado en documentos (DBMS) que utiliza un modelo de documento para almacenar y gestionar datos. MongoDB se puede utilizar para almacenar y gestionar varios tipos de datos, incluidos datos estructurados, semiestructurados y no estructurados. MongoDB es un sistema de base de datos ampliamente utilizado con un sólido soporte para tipos de datos, indexación automática, alta disponibilidad y escalabilidad.
LangChain
LangChain es la mejor herramienta para combinar bases de datos vectoriales, búsqueda de vectores y LLM. Los módulos que admite también se están desarrollando rápidamente y es probable que sean de primer nivel en aplicaciones de lenguajes grandes (que respaldan la investigación + producción).
índice_llama
Libere el poder de los LLM sobre sus datos。