Wenn Sie jemals versucht haben, ein aus einem CAD-Programm exportiertes 3D-Modell in einen WebGL- oder AR-Dienst hochzuladen, sind Sie wahrscheinlich auf Probleme mit maximalen Dateigrößen, endlosen Fortschrittsbalken und schlechten Bildraten gestoßen.
Die Optimierung der Größe und Leistung von 3D-Daten ist für die Erstellung eines guten interaktiven Online-Erlebnisses von entscheidender Bedeutung. Es ist auch gut für Ihr Endergebnis, da kleinere Dateien weniger Cloud-Speicher benötigen und weniger Daten über ein CDN übertragen werden müssen.
In diesem Artikel wird beschrieben, wie Sie eine automatisierte Pipeline entwerfen, um gut visualisierte 3D-Modelle zu generieren. Auf diese Weise können Sie mit minimalem manuellen Aufwand vollständig detaillierte Modelle erstellen, die für die Verwendung im Web und in AR bereit sind.
Wenn 3D-Modelle zur Herstellung oder Visualisierung in Offline-Renderern erstellt werden, sind sie häufig nicht für die Anzeige auf Handheld-Geräten, Webbrowsern, AR-Apps und anderen Geräten mit geringer Spezifikation geeignet. Das bedeutet, dass Content-Produktionsteams oft viel Zeit damit verbringen, Quellressourcen zu optimieren oder auf Low-End-Geräte zu konvertieren, um eine reibungslose Darstellung und schnelle Downloads zu gewährleisten.
In diesem Artikel befassen wir uns mit der Optimierung von 3D-Assets im Allgemeinen und insbesondere mit der Interaktion dieses Prozesses mit Substance-Materialien und -Bibliotheken.

Empfehlung: Verwenden Sie den NSDT-Editor , um schnell programmierbare 3D-Szenen zu erstellen
Die manuelle Optimierung von 3D-Modellen ist nicht nur mühsam und zeitaufwändig, sondern kann auch leicht zu einem Engpass im Produktionsprozess werden. Das Problem besteht darin, dass die Optimierung grundsätzlich dem Quell-Asset nachgelagert ist, was bedeutet, dass alle Änderungen am Quell-Asset (3D-Modell, Materialien usw.) im optimierten Asset widergespiegelt werden müssen. Daher besteht ein Konflikt zwischen der Möglichkeit, optimierte Inhalte frühzeitig in der Vorschau anzuzeigen, und der Zeit, die für die Optimierung benötigt wird.
Wenn erwartet wird, dass sich das Quellmodell während der Produktion mehrmals ändert, ist es effizienter, es erst nach der Fertigstellung zu optimieren.
Daher ist die Optimierung ein vorrangiges Ziel der Automatisierung. Dies ist kein Ort für künstlerischen Ausdruck. Eine automatisierte Pipeline erkennt, wenn sich ein Aspekt der Asset-Bibliothek ändert, und optimiert die betroffenen Assets erneut.
1. Überblick über die 3D-Optimierungspipeline
Schauen wir uns ein E-Commerce-ähnliches Setup an.

Quell-3D-Modelle können aus vielen verschiedenen Quellen stammen, beispielsweise aus CAD-Paketen, DCC-Paketen usw. Wir gehen davon aus, dass sie neben Scheitelpunkten und Polygonen auch Textur-UV- und Normalinformationen enthalten.
Eine Materialbibliothek ist eine Reihe von Quellmaterialien für ein 3D-Modell. Das Bild unten stammt von Substance Source, was einen guten Ausgangspunkt für Materialien darstellt – aber jedes solche Material könnte auch intern erstellt werden, vielleicht aus einer realen Materialprobe.

Die Materialien von Substance sind prozedural und ermöglichen es Benutzern, Parameter festzulegen und Voreinstellungen zu definieren. Materialien werden zusammen mit anwendungsspezifischen Einstellungen als Materialinstanzen bezeichnet. Beispielsweise könnte das gleiche Ledermaterial als rotes und blaues Ledermaterial instanziiert werden.

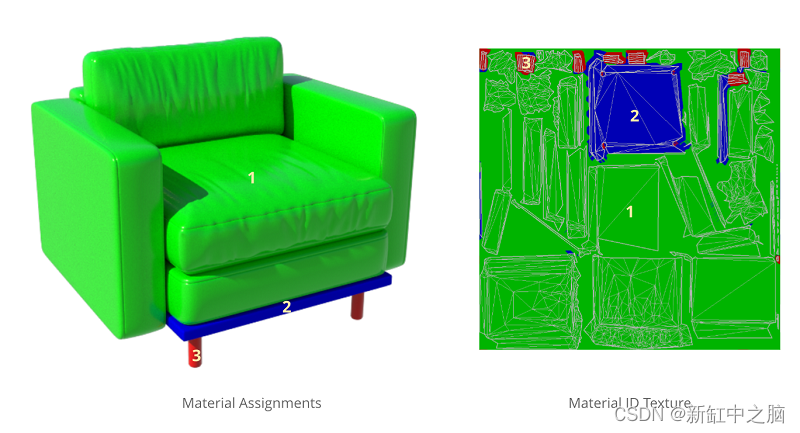
Nachdem wir ein Material ausgewählt haben, ordnen wir es einem bestimmten Teil des Objekts zu. Für ein Sofa können Sie Stoffmaterial für die Kissen und Metall für die Beine angeben:

Modell ohne Material (links) und mit zugewiesenem Material (rechts)
Das gleiche Modell kann auch mehrere Verteilungskonfigurationen haben: In diesem Beispiel kann das gleiche Sofa unterschiedliche Stoff- und Lederkissen haben.

Zwei Materialanordnungen desselben Modells
1.1 Ausgabeziel
Verschiedene Geräte verfügen über unterschiedliche Funktionen, und was in einem Browser auf einem Telefon der vorherigen Generation gut funktionierte, funktioniert möglicherweise ganz anders als auf einem High-End-PC. Deshalb wollten wir in der Lage sein, unterschiedliche Modelle für unterschiedliche Zwecke herzustellen.
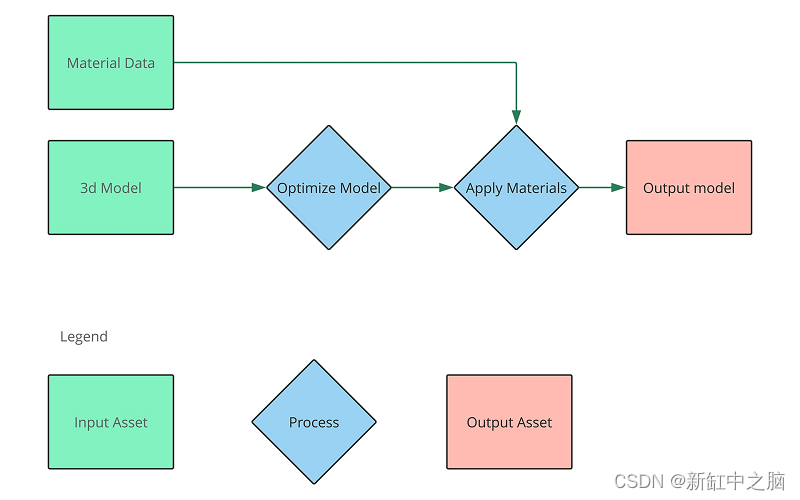
In ihrer einfachsten Form sieht die Pipeline so aus:
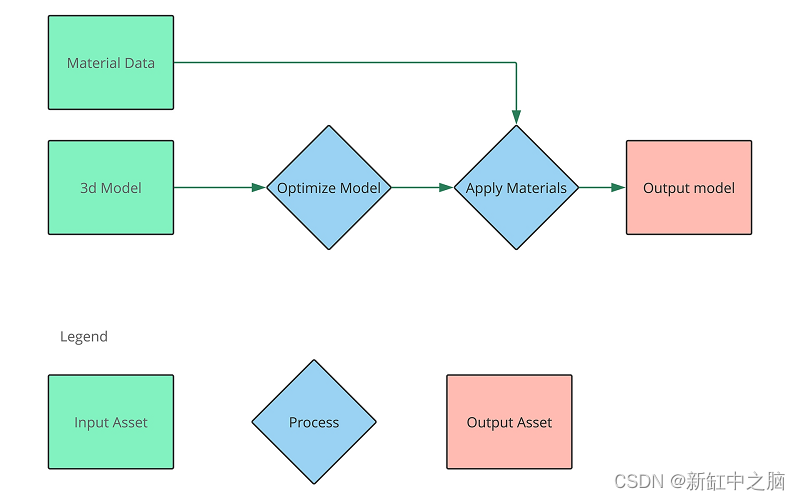
Beachten Sie, dass dieser Prozess die Verarbeitung eines Modells zeigt, die Idee ist jedoch, dass mehrere Objekte mit mehreren Ausgaben aus mehreren Materialkonfigurationen diesen Prozess durchlaufen.
Die Konzeptpipeline besteht aus zwei Phasen: Optimierung des Modells und anschließende Anwendung des Materials. Beachten Sie, dass die Optimierung des Modells der erste dieser Schritte ist, die Anwendung von Materialien erfolgt anschließend. Das bedeutet, dass jede Änderung am 3D-Modell eine Optimierung und erneute Anwendung des Materials auslöst, Änderungen am Material jedoch ohne erneute Optimierung vorgenommen werden können.
Die Pipeline ist vereinfacht und es könnte mehr Phasen und Abhängigkeiten in einer realen Pipeline geben.
1.2 Überlegungen zur effizienten Automatisierung
Mit einer strukturierten Pipeline wie der oben genannten können wir den Prozess der Generierung optimierter Modelle automatisieren – das heißt, wir können während der gesamten Lebensdauer des Produkts über aktuelle Visualisierungsmodelle verfügen.
Um Asset-Pipelines effektiv betreiben zu können, müssen wir die Beziehungen zwischen Vorgängen verstehen und wissen, welche Daten welche Ergebnisse beeinflussen. Das bedeutet, dass wir bei Änderungen der Quelldaten schnell herausfinden können, was erstellt werden muss.
Einige Beispiele:
- Wenn ein Material in der Materialbibliothek geändert wird, muss jede Ausgabe, die dieses Material verwendet, neu erstellt werden;
- Beim Hinzufügen eines neuen Ausgabeziels müssen alle Modelle für dieses Ziel verarbeitet werden;
- Wenn sich ein 3D-Modell ändert, müssen alle Konfigurationen aller Ziele für dieses Modell neu erstellt werden.
- Wann und wie der automatisierte Prozess ausgelöst werden soll, erfordert ein Gleichgewicht zwischen der Geschwindigkeit, mit der Ergebnisse benötigt werden, und der Menge der verwendeten Rechenleistung. Das Auslösen eines Laufs bei jeder Änderung führt zu schnellen Ergebnissen, kann aber auch bedeuten, dass Sie viel Zeit mit der Arbeit an einem Modell verbringen, das sich bald wieder ändern wird.
Ein anderer Ansatz besteht darin, den Prozess nachts auszuführen, wenn mehr Rechenleistung verfügbar oder günstiger ist. Das bedeutet, dass das neueste Modell jeden Morgen bereit sein sollte.
Es ist auch möglich, Benutzern die Entscheidung zu überlassen, wann der Prozess des Modells ausgeführt werden soll, sodass sie bei Bedarf das neueste Modell erhalten.
Ein häufiges Problem beim Automatisierungsteil von 3D-Workflows ist der Verlust der künstlerischen Kontrolle. Dies sollte nicht der Fall sein, da alle künstlerischen Entscheidungen getroffen werden, bevor die Automatisierung erfolgt. Die Optimierungsphase sollte auf die gleiche Weise betrachtet werden, wie ein als TIFF-Datei gespeichertes Bild in ein JPEG-Format komprimiert werden könnte, bevor es auf einer Website platziert wird. Durch die Automatisierung der Optimierungsphase sollte mehr Zeit für kreative Arbeit frei werden, da Sie keine Zeit für die Optimierung des Bereitstellungsmodells aufwenden müssen.
Die wichtigsten Überlegungen beim Einsatz einer automatisierten Lösung sind, wie und wann die manuelle Behebung erfolgt. Wenn die Ausgabe des Prozesses für ein bestimmtes Modell nicht gut genug ist, besteht oft der Instinkt darin, die generierten Ausgaberessourcen zu korrigieren. Das Problem bei diesem Ansatz besteht darin, dass der Fix jedes Mal erneut angewendet werden muss, wenn das Asset geändert wird (da die Änderung der Automatisierungspipeline nachgelagert ist). Im Allgemeinen sollten alle Ausgabeanpassungen als Einstellungen in der Automatisierungspipeline vorgenommen werden, damit sie beim nächsten Ausführen der Pipeline angewendet werden können. Von manuellen Korrekturen wird abgeraten, es sei denn, Sie sind sicher, dass sich das Modell im endgültigen Zustand befindet.
Eine gute Möglichkeit zur Optimierung besteht darin, Ebeneneinstellungen zu überschreiben. Die Standardwerte der Pipeline können auf der Ebene einzelner Assets überschrieben werden, sodass Sie höhere Qualitätswerte für Assets mit schlechter Leistung festlegen können, ohne dass sich dies auf andere Assets auswirkt.
2. Warum das 3D-Modell optimieren?
Die Optimierung der Eingabedaten ist der Schlüssel zur Erstellung guter 3D-Modelle für Web- und Handheld-Geräte. CAD-Modelle oder Modelle, die für High-End-Rendering erstellt wurden, sind zu detailliert und zu groß, um allgemein für diesen Zweck geeignet zu sein.
Die wichtigsten Dinge, die Sie durch Optimierung verbessern möchten, sind:
- Rendering-Leistung
- Batterielebensdauer
- Downloadgröße
- Speichernutzung
Diese unterschiedlichen Ziele sind häufig aufeinander abgestimmt: Kleinere Modelle rendern normalerweise schneller und verbrauchen weniger Akkustrom auf dem Gerät.
2.1 Bewerten Sie das optimierte Modell
Bevor wir uns mit der Optimierung befassen, ist es wichtig sicherzustellen, dass wir wissen, wie wir die visuelle Qualität der Ergebnisse bewerten können. Der Schlüssel liegt immer darin, das Modell im Hinblick auf seinen Nutzen zu bewerten. Wenn Sie Modelle erstellen, die so gestaltet sind, dass sie in einem 400 x 400 Pixel großen Web-Viewer oder einem Handheld-Gerät gut aussehen, bedeutet das: „Wir werden ein bereitstellen.“ Modell, das zu detailliert und zu umfangreich zum Herunterladen ist.
Wenn es um die Rendering-Leistung geht, ist es ohne Benchmarking nicht immer einfach vorherzusagen, was die besten Ergebnisse liefert, aber es gibt eine Reihe von Heuristiken, die in Kombination tendenziell gute Ergebnisse liefern, wie unten beschrieben. Denken Sie auch daran, dass es auf einem Handheld immer noch wichtig ist, kleiner und schneller zu sein, selbst wenn Sie Ihre Ziel-Framerate und Download-Größe erreichen, da weniger ausgelastete GPUs weniger Batterie verbrauchen. Der Artikel GPU-Leistung für Spielekünstler behandelt dieses Thema ausführlicher und ist eine gute Quelle, um zu verstehen, was ein schnelles Rendern von 3D-Modellen ausmacht.
2.2 Anzahl der Polygone
Die Anzahl und Dichte der Polygone ist ein wichtiger Faktor für ein schnelles Rendern und Herunterladen von Modellen. Mehr Polygone und Eckpunkte bedeuten, dass die GPU mehr Berechnungen durchführen muss, um das Bild zu generieren.
GPUs eignen sich im Allgemeinen besser zum Rendern größerer und gleichmäßiger großer Polygone. GPUs sind hochgradig parallel und für größere Polygone optimiert. Je kleiner und dünner die Polygone sind, desto mehr Parallelität wird in den schattierten Bereichen verschwendet. Dieses Problem wird als Überfärbung bezeichnet und im oben verlinkten Artikel behandelt.
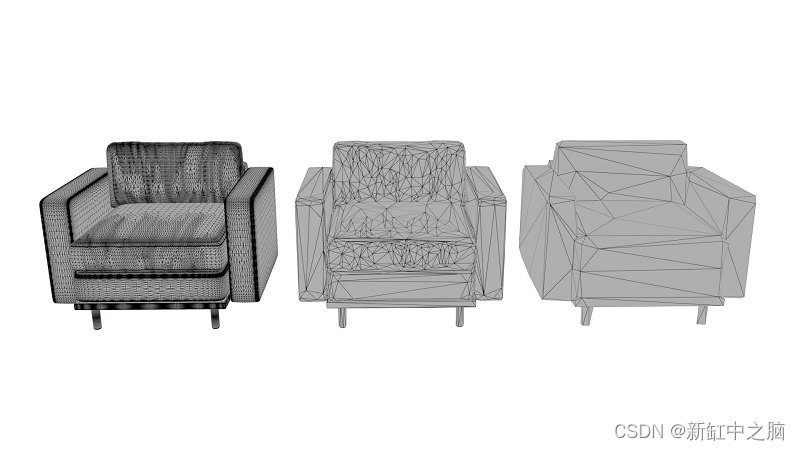
Im Allgemeinen ist es am besten, sich das Drahtmodell des resultierenden Modells anzusehen und sicherzustellen, dass das Drahtmodell nicht sehr dicht ist, wenn Sie das Modell in der Größe visualisieren, in der Sie es anzeigen möchten.
Eine effektive Möglichkeit, die Anzahl der Polygone zu reduzieren, ohne auf Details zu verzichten, ist die Verwendung von Normalkarten. Die Idee dahinter ist, dass wir empfindlicher darauf reagieren, wie Licht mit Objekten interagiert, als darauf, wie ihre Silhouetten interagieren. Das bedeutet, dass wir Details von Dreiecksdaten in Normalkarten verschieben können (d. h. vom Modell in die Textur) und größere Polygone verwenden und dennoch Details aus Rohdaten in der Beleuchtung erhalten können.
Hier ist das gleiche Modell optimiert, ohne (links) und (rechts) eine Normalkarte mit Details des Originalmodells:

Durch die Optimierung des Modells auf ein Niveau, bei dem sich die meisten kleinen Details in der Normalkarte befinden, erhält das Netz auch eine bessere UV-Karte. Kleine Details und scharfe Kanten stellen bei der Erstellung von UV-Karten oft ein Problem dar. Einfachere Modelle haben tendenziell weniger große Diagramme, weniger verschwendeten Füllraum und weniger sichtbare Nähte – was bei Modellen mit automatischer UV-Zuordnung ein Problem sein kann.
2.3 GPU-Draw-Aufrufe
Draw-Aufrufe geben an, wie oft der Renderer mit der GPU kommunizieren muss, um ein Objekt zu rendern. Im Allgemeinen muss die GPU benachrichtigt werden, wenn Sie von einem Objekt zu einem anderen wechseln oder eine andere Textur verwenden möchten. Das bedeutet, dass das Rendern von Objekten, die in mehrere Teile aufgeteilt sind oder viele verschiedene Materialien verwenden, teurer ist, wenn dasselbe Modell nur aus einem Netz und einem Satz Texturen besteht.
2.4 Texturauflösung
GPUs sind gut darin, Texturen mit einer Auflösung auszuwählen, die den Anzeigedimensionen des Modells entspricht, und die Leistungs- und Qualitätsprobleme zu vermeiden, die mit der Verwendung einer zu hohen Texturauflösung verbunden sind. Angesichts der Anzeigeeinschränkungen des übertragenen Modells ist es leicht, unnötig hochauflösende Texturen einzubinden. Sie werden nicht in voller Auflösung angezeigt, was zu unnötigen Downloadzeiten für Benutzer führt.
2.5 Überziehen
Überzeichnen entsteht beim Rendern von Polygonen, die hinter anderen Polygonen landen. Bei den meisten Objekten ist eine gewisse Überzeichnung unvermeidbar. Bei einfachen Betrachtungsszenarien kann es jedoch auch Polygone geben, die nie sichtbar sind, egal wie der Benutzer mit dem Modell interagiert. Stellen Sie sich zum Beispiel ein Sofa vor, dessen Sitzkissen als separater Gegenstand auf dem Sofagestell platziert ist. In Fällen, in denen der Benutzer das Kissen nicht entfernen kann, sind die Unterseite des Kissens und der Teil des Rahmens, auf dem das Kissen aufliegt, nie sichtbar.

Eine gute Optimierungslösung kann diese unnötigen Bereiche identifizieren und eliminieren, sodass Polygone in unsichtbaren Bereichen nicht heruntergeladen oder gerendert werden müssen. Darüber hinaus wird in vielen texturierten Szenen Texturbildraum diesen unsichtbaren Polygonen zugewiesen, was bedeutet, dass Sie Texturdaten verschwenden, sich negativ auf die Downloadgröße auswirken und die Texturauflösung in tatsächlich sichtbaren Bereichen verringern.
2.6 Die Rolle der Modelloptimierung beim Schutz geistiger Eigentumsrechte
Wenn schließlich mit Daten aus CAD-Programmen gearbeitet wird, enthalten 3D-Modelle oft Details darüber, wie ein Produkt hergestellt wird. Eine optimierte Lösung entfernt interne Objekte und wandelt kleine Details in Normal Maps und Texturinformationen um. Dies macht es schwierig, ein Produkt anhand eines Modells zurückzuentwickeln, das nur zur Visualisierung verwendet wird.
3. Die Grundlage einer guten Pipeline
Die Implementierung einer automatisierten Pipeline, die alle oben genannten Punkte umfasst, kann eine herausfordernde Aufgabe sein. Aber wenn Sie die Grundlagen richtig beherrschen, können Sie sich später viel Ärger ersparen.
3.1 Datenlayout
Eine Voraussetzung für jede erfolgreiche Automatisierungsmaßnahme ist ein strukturierter Umgang mit Daten. Es ist entscheidend, eine klare Vorstellung davon zu haben, welche Materialbibliotheken verwendet werden und welche Materialien welchen Objekten zugeordnet sind. Sie möchten dieses Material auch für die Pipeline sichtbar machen, damit die Pipeline Änderungen verfolgen kann, sodass Sie keine Zeit mit der erneuten Verarbeitung von Dingen verschwenden, die sich nicht geändert haben.
Alle Daten sollten in einem zentralen Repository gespeichert werden und dürfen keine Verweise auf Daten außerhalb dieses Repositorys zulassen, um sicherzustellen, dass das gesamte Quell-Asset gefunden werden kann, ohne dass ein zusätzliches freigegebenes Netzwerklaufwerk (oder ein anderer potenzieller Speicherort) bereitgestellt werden muss. Bei der Auswahl eines Datenformats sollten diese in sich abgeschlossen sein oder alle Verweise auf andere Dateien sollten leicht zugänglich sein, um die Nachverfolgung zu erleichtern.
3.2 Abhängigkeitsverfolgung
Durch die Verfolgung der Beziehungen zwischen Assets können Sie nur das wiederherstellen, was sich geändert hat. Je detaillierter Ihre Abhängigkeitsverfolgung und Jobausführung ist, desto kleiner werden Ihre inkrementellen Asset-Builds sein.
Angenommen, Ihre Abhängigkeitsverfolgung behandelt eine Materialbibliothek als eine einzige undurchsichtige Einheit. Wenn Sie eine Änderung an einem Material vornehmen, wird eine Neukonstruktion jedes Modells erzwungen, um alle Materialdaten auf dem neuesten Stand zu halten. Wenn Sie einzelne Materialänderungen verfolgen, dürfen nur die Objekte neu erstellt werden, die das geänderte Material verwenden.
3.3 Ausführung
Nachdem Sie Abhängigkeiten aufgelöst haben, müssen Sie schließlich mehrere Build-Aufgaben ausführen, um die gewünschte Ausgabe zu erzeugen. Diese Aufgaben sind in der Regel weitgehend unabhängig und können parallel ablaufen. Das bedeutet, dass der Build-Prozess über mehrere CPUs oder Maschinen hinweg skaliert werden kann. Der Ausführungsteil umfasst die Planung dieser Aufgaben und die Sicherstellung, dass die entsprechenden Tools aufgerufen werden, um die gewünschte Ausgabe zu erzeugen.
Beispiele für Aufgaben, die in der Optimierungspipeline ausgeführt werden, sind:
- Netzoptimierung
- Texturwiedergabe
- Texturkomprimierung
- Szenenaufbau
3.4 Caching
Zwischenergebnisse während des Build-Prozesses können zwischengespeichert werden, um inkrementelle Builds zu beschleunigen. Ein Beispiel ist die optimierte Low-Poly-Ausgabe. Dies wird wahrscheinlich nicht direkt als Asset funktionieren, da Texturen angewendet werden müssen, bevor es bereitgestellt werden kann. Dieses Low-Poly-Asset kann jedoch als Zwischenschritt zwischengespeichert werden. Wenn ein in einer Anlage verwendetes Material aktualisiert wird, muss es auf diese Weise nicht neu erstellt werden, und der Prozess kann vereinfacht werden, um eine erneute Optimierung zu vermeiden.
Caching ist eine praktische Lösung für dieses Problem, da der Cache geleert werden kann, ohne dass Daten verloren gehen, die nicht wiederhergestellt werden können. Dadurch wird sichergestellt, dass die Größe kontinuierlich reduziert werden kann, um ein gutes Gleichgewicht zwischen inkrementeller Build-Leistung und temporärer Datenspeicherung zu erreichen.
4. Beispiel einer 3D-Asset-Optimierungspipeline
Um diesem etwas abstrakten Artikel etwas Konkretheit zu verleihen, habe ich beschlossen, eine einfache Implementierung einer Asset-optimierten Pipeline zu erstellen.
Mein Ziel ist es hier, verschiedene Aspekte der Pipeline aufzuzeigen, wobei ein besonderer Schwerpunkt darauf liegt, zu zeigen, wie die Materialien von Substance am Workflow zur Anlagenoptimierung beteiligt sind.
Das Ziel dieser Pipeline besteht darin, aus hochauflösenden 3D-Möbelmodellen automatisch Modelle zu generieren, die klein und schnell zu rendern sind. Die Pipeline ist hauptsächlich in Python implementiert und für die native Ausführung auf einem einzelnen Windows-Computer konzipiert.
Die ursprünglich beschriebene Pipeline sieht folgendermaßen aus:
Wenn wir Details zum Verarbeitungsfeld hinzufügen, erhalten wir das folgende Ergebnis:
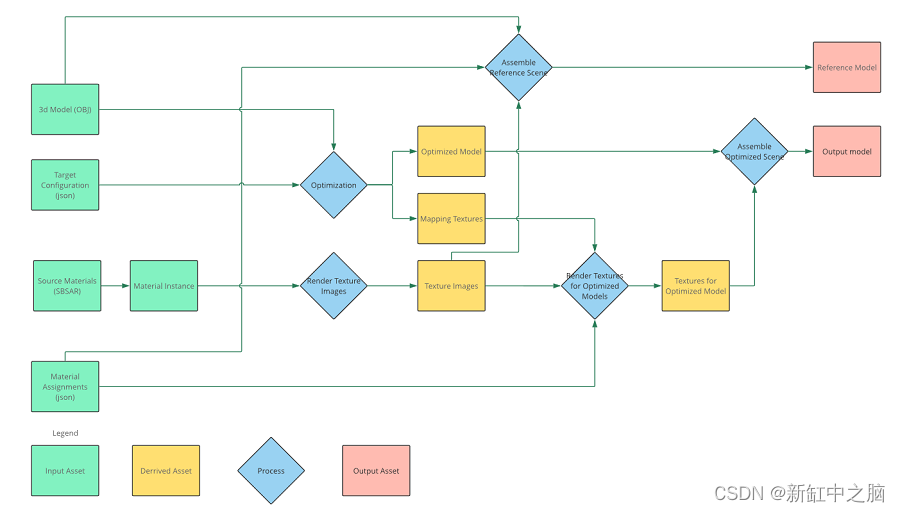
Hier ist ein Überblick über ein einzelnes optimiertes Modell anhand der Beispielpipeline. Diese Pipeline kann auf mehrere Modelle und mehrere Massen desselben Modells angewendet werden. Abgeleitete Assets stellen Zwischenausgaben dar, die vom Build-System zwischengespeichert werden können, um inkrementelle Builds zu beschleunigen.
4.1 Daten
Die Daten in dieser Pipeline sind eine Reihe von Dateien auf der Festplatte, um die Dinge so einfach wie möglich zu halten. Sie sind unterteilt in:
- Mesh: .obj-Datei
- Quellmaterial: Substance .sbsar-Datei
- Materialbibliothek: Eine .json-Datei, die auf eine .sbsar-Datei verweist, plus zusätzliche Einstellungen zur Auswahl von Voreinstellungen, Parametern und Materialskalierung.
- Materialzuweisungen: .json-Dateien, die Teile des Modells mit Materialinstanzen und Maßstäben für jedes Modell verknüpfen.
- Pipeline: Ein .json-Dokument, das das optimierte Zielprofil beschreibt (z. B. Mobil, VR usw.).
- Job: Ein .json-Dokument, das beschreibt, welche Modelle optimiert werden sollen, welche Materialanordnungen verwendet werden sollen und über welche Pipelines die Ausgabe generiert werden soll.
4.2 OBJ als Mesh-Dateiformat
Der Grund, warum ich OBJ-Dateien für die Geometrie verwende, ist die Einfachheit. Sie sind einfach zu erstellen und zu teilen. Da sie textbasiert sind, können sie auch leicht bearbeitet werden, wenn der Gruppenname fehlt oder aus irgendeinem Grund falsch ist.
Die Hauptbeschränkung der Netze in der Pipeline besteht darin, dass das UV-Diagramm auf die UV-Seite passen muss. Sie können nicht zum Kacheln von Materialien auf Formen verwendet werden, sie können sich jedoch überlappen oder auf verschiedenen Seiten liegen, wenn dies gewünscht wird. Idealerweise sollten alle UV-Diagramme im Verhältnis zu ihrer Größe im Weltraum des Modells dimensioniert sein, sodass Texturen auf allen Teilen im gleichen Maßstab angewendet werden.
Unten sehen Sie zwei verschiedene UV-Layouts desselben Modells. Das Layout auf der linken Seite verursacht Probleme, da sein Diagramm die UV-Kachelgrenze überschreitet; im Gegensatz dazu funktioniert das Layout auf der rechten Seite normal.

4.3 Materialbibliothek
Das verwendete Materialbibliotheksformat ist eine benutzerdefinierte .json-Datei, nicht das MTL-Format von .obj. Das MTL-Format unterstützt weder das Binden von Substanzmaterialien noch das Festlegen von Verfahrensparametern. Daher habe ich beschlossen, ein einfaches benutzerdefiniertes Format mit diesen Funktionen einzuführen.
Hier ist ein Beispiel einer Materialinstanz aus der Materialbibliothek:
{
// ...
// Leather is the name of the instance
"Leather": {
// sbsar file referenced
"sbsar": "${assets}/material_library/sbsar/Sofa_Leather.sbsar",
"parameters": {
// These are parameters on the sbsar
"normal_format": 1,
"Albedo_Color": [
0.160,
0.160,
0.160,
1
],
"Roughness_Base": 0.353
},
"scale": [
// A material relative scale for the UV
20.0,
20.0
]
}
// Additional material instances
// ...
}
In der Beispielpipeline werden alle Materialinstanzen in einer einzigen Materialbibliotheksdatei gespeichert.
Diese Materialien basieren auf der PBR-Metallrauheit unter Verwendung der folgenden Karten:
- Grundfarbe: Grundfarbkarte
- Normal: Normale Karte
- Rauheit: Rauheitskarte
- Metallisch: Metallische Karte
4.4 Materialzuordnung
Eine Materialzuweisung ist eine separate Datei, die ein Teil im Modell einer bestimmten Materialinstanz zuordnet. Zu den Materialzuweisungen gehören auch modellspezifische Skalierungsfaktoren, um Unterschiede zwischen den Texturdiagrammskalen verschiedener Modelle auszugleichen.
Die Trennung der Materialzuweisung von der Geometrie ermöglicht es Benutzern, demselben Modell unterschiedliche Materialkonfigurationen zuzuweisen oder Materialkonfigurationen zwischen Modellen zu teilen, die denselben Gruppennamen haben.
Hier ist ein Beispiel für eine Materialzuweisungskonfiguration:
{
// Legs is the name of the part in OBJ file
// If similar scenes share part names the same
// material assignment file can be used for all of them
"Legs": {
// Material refers to a material instance
// in the library
"material": "Metal",
// Scale is the scale of the material associated with this
// part. It will be multiplied by the scale from the
// material instance
"scale": [
1.0,
1.0
]
},
// Additional assignments to other parts
"Cushions": {
"material": "Leather",
"scale": [
1.0,
1.0
]
},
"Frame": {
"material": "Wood",
"scale": [
1.0,
1.0
]
}
}
4.5 GLB als Ausgabeformat
Eine .glb-Datei ist eine Version von .gltf, bei der Netzdaten, Szenendaten und Texturen in einer einzigen Datei gepackt sind. Ich verwende .glb als Ausgabeformat für diesen Prozess, da es sich um eine kompakte Dateidarstellung von Netzen, Materialien und allen generierten Texturen handelt und eine breite Branchenunterstützung für Web- und mobile 3D-Viewer bietet.
4.6 Pipeline-Definition
Die Pipeline beschreibt verschiedene Aspekte der Optimierung, die für eine bestimmte Zielhardware durchgeführt werden sollen.
Eine Beispielpipeline sieht folgendermaßen aus:
{
"import": {
// Resolution for reference source textures
// Insufficient resolution in the source textures
// will come out as blurry areas in the model
// Must be an integer power of 2
"material_resolution": 2048
},
"reference": {
// Enable or disable reference model
// creation
"enable": true
},
"optimize": {
// Target size in pixels for which the model
// quality should be optimized. Anything above
// 2000 will be very time consuming to produce
"screen_size": 600,
// Resolution for the utility maps for the model
"texture_resolution": 1024,
// Bake tangent space using Substance Automation
// Toolkit if true, use Simplygon if false
"bake_tangent_space_SAT": true,
"remeshing_settings": {
// Angle in degrees between surfaces in
// a vertex to split it with discrete
// normals
"hard_edge_angle": 75
},
"parameterizer_settings": {
// How much stretching is allowed inside
// a chart in the generated UV layout for
// the model
"max_stretch": 0.33,
// How prioritized large charts are for the
// UV layout
"large_charts_importance": 0.2
}
},
"render": {
// Texture resolution for the atlas
// for the optimized model. Should typically
// be the same as the texture_resolution in
// optimize
"texture_resolution": 1024,
// Offset for mip map selection. 0 is default,
// Negative values gives sharper and noisier results
// Positive values give blurrier results
"mip_bias": 0,
// Enable FXAA post processing on the map to give
// smoother edges between different materials
// (doesn't apply to normal maps)
"enable_fxaa": true,
// Blurring of the material id mask before compositing
// to give smoother borders between materials
// (doesn't apply to the normal map)
"mask_blur": 0.25,
// Enable FXAA post processing on the normal map to
// give smoother edges between different materials
"enable_fxaa_normal": true,
// Blurring of the material id mask before compositing
// the normal map to give smoother borders between
// materials
"mask_blur_normal": 0.25,
// Clean up edges around charts on normal maps
"edge_clean_normal_maps": false,
// Normal map output format and filtering
// For most cases 8 bpp is enough but
// for low roughness and 16bpp is needed to avoid
// artifacts
"output_normal_map_bpp": 8,
// Enable dithering for the normal map. Typically only
// relevant for 8 bpp maps
"enable_normal_map_dithering": true,
// Dithering intensity. Represents 1/x. Use 256 to
// get one bit of noise for an 8bpp map
"normal_map_dithering_range": 256,
// Paths to tools for compositing materials and
// transforming normal maps
"tools": {
"transfer_texture": "${tools}/MultiMapBlend.sbsar",
"transform_normals": "${tools}/transform_tangents.sbsar"
}
}
}
4.7 Hausaufgaben
Ein Job ist der Einstiegspunkt für die Angabe aller Modell-, Materialzuweisungs- und Pipelineprozesse. Hier ist ein Beispiel für einen Job:
{
// Scenes to optimize
"scenes": {
"sofa-a1": {
// OBJ file with geometry in
"mesh": "${assets}/meshes/sofa-a1.obj",
// Different material variations to produce for this model
"material_variations": {
// These are references to material assignment files
"sofa-a1-leather": "${assets}/material_bindings/leather.json",
"sofa-a1-fabric": "${assets}/material_bindings/fabric.json"
}
},
// Additional scenes goes here
// ...
},
// The material library with material instances in to use
"material_library": "${assets}/material_library/material_library.json",
"pipelines": {
// A pipeline to run for the scenes
"lq": {
// Reference to the definition file
"definition": "${assets}/pipelines/lq.json",
// Paths for reference models and optimized models for
// this pipeline
"output_reference": "${outputs}/lq/reference",
"output_optimized": "${outputs}/lq/optimized"
},
// Additional pipelines to run
// ...
}
}
4.8 Python als Kernsprache der Pipeline
Zur Implementierung der Pipeline wird Python verwendet. Es ist eine weithin unterstützte Sprache und verfügt über Funktionen, die viele unserer Probleme sofort lösen. Ich möchte dabei Bindungen für mehrere Tools verwenden, damit ich mich ganz auf den Aufbau der Pipeline konzentrieren kann, anstatt Brücken zu anderen Anwendungen zu bauen.
4.9 SCons-Abhängigkeitsverfolgung und -ausführung
Das für die Pipeline verwendete Abhängigkeitsverfolgungs- und Ausführungssystem ist das SCons-Build-System. Es handelt sich um ein Python-basiertes Build-System, das Abhängigkeiten verfolgt und versucht, die Kosten inkrementeller Builds zu minimieren, indem nur Daten neu erstellt werden, die sich seit dem letzten Build geändert haben. Dies bedeutet, dass es als Executor fungiert und auch die Zwischenspeicherung von Zwischenergebnissen für uns übernimmt.
Die Verwendung eines Python-basierten Build-Systems ist praktisch, da es die Interaktion mit Build-Vorgängen trivial macht. Es ist auch im pip-Modulsystem verfügbar und kann von jedem mit einer Python-Umgebung problemlos installiert werden.
Die Pipeline unterstützt auch die direkte Ausführung als Python-Skript, was das Debuggen erleichtert. Wenn Sie eine Pipeline direkt über ein Skript ausführen, wird jede Ausführung von Grund auf neu erstellt und es erfolgt keine parallele Verarbeitung unabhängiger Aufgaben.
4.10 Polygonoptimierung
Zur Optimierung verwende ich den Remesher 2.0 von Simplygon. Simplygon gilt als Goldstandard für Polygonoptimierung in der Gaming-Branche und kann sehr kompakte Netze mit viel Kontrolle erzeugen. Es verfügt über mehrere verschiedene Optimierungsstrategien, die in verschiedenen Szenarien angewendet werden können, aber der Einfachheit halber habe ich eine für die Pipeline ausgewählt.
Der Remester verfügt über viele Eigenschaften, die zur Optimierung des Netzes erforderlich sind:
- Es optimiert das Modell aggressiv und kann bei richtiger Anwendung oft gute Ergebnisse mit um Größenordnungen weniger Polygonen erzielen.
- Es bereinigt die gesamte interne Geometrie des Modells, reduziert Überzeichnung und Texturzuweisungen zu unsichtbaren Oberflächen und entfernt irrelevante oder proprietäre Informationen aus dem Modell.
- Es erstellt einen neuen Texturatlas für das gesamte Modell, was bedeutet, dass es mit der gleichen Menge an Texturdaten wie ein einzelner Zeichenaufruf gerendert werden kann, unabhängig davon, wie das Modell ursprünglich eingerichtet wurde.
- Es generiert eine Zuordnung vom Quellnetz zum Zielnetz, sodass Texturen, Normalen usw. auf dem Quellnetz korrekt und mit hoher Qualität auf das optimierte Modell übertragen werden können.
- Es kann auf eine bestimmte Anzeigegröße optimiert werden. Wenn Sie ein Modell mit vorhersehbarer Qualität in einem Viewer mit einer bestimmten Größe oder Auflösung anzeigen möchten, können Sie diese Informationen als Zielauflösung angeben; Ihr Ergebnis wird ein Modell sein, das dieser Größe entspricht. Der Remesterizer kann auch Texturgrößen für diese bestimmte Qualität vorschlagen, obwohl diese Funktionalität in dieser Pipeline nicht verwendet wird.
- Ich habe in der Vergangenheit bei Simplygon gearbeitet. Einer der Gründe, warum ich in diesem Fall Remesher 2.0 verwende, ist, dass ich damit sehr vertraut bin – mit den Arten von Ergebnissen, die es liefert, und wie ich das Tool konfigurieren kann, damit es besser funktioniert damit.
Simplygon verfügt außerdem über die folgenden Eigenschaften, die es für diese Pipeline geeignet machen:
- Es verfügt über eine Python-API, die alle Optimierungen und Szenenerstellung steuert, wodurch es einfach ist, das Tool in den Rest der Pipeline zu integrieren, die ebenfalls in Python erstellt wird.
- Kann .obj- und .glb-Dateien lesen und schreiben. Dies bietet eine umfassende Kontrolle darüber, wie Materialien und Texturen verwaltet werden. Daher kann das Tool zum Lesen von Quelldaten mit benutzerdefinierten Materialien und zum Schreiben von .glb-Dateien mit mit Substance generierten Texturen verwendet werden.
Remeshing ist eine aggressive Optimierungstechnik, die für Modelle, die aus der Ferne betrachtet werden, sehr effektiv ist. Es eignet sich jedoch nicht für Modelle, die zu genau untersucht werden müssen, da es die Objektumrisse und die Netztopologie stark beeinflussen kann. Daher ist es möglicherweise nicht für jedes Visualisierungsszenario die richtige Lösung. Insbesondere geht die hier verwendete Implementierung nicht gut mit Transparenz um, was in dieser Pipeline vermieden werden sollte. Durch das Aufbrechen der Netztopologie des Objekts können Teile, die zu Animationszwecken oder Ähnlichem getrennt wurden, miteinander verschmelzen. Daher erfordert dieser Vorgang in diesem Fall besondere Aufmerksamkeit.
Es gibt viele andere 3D-Optimierungslösungen, aber Simplygon war aufgrund seiner großen Anzahl an Funktionen und meiner bisherigen Erfahrung damit meine natürliche Wahl.
4.11 Texturierung des optimierten Modells
Ich verwende das Substance Automation Toolkit, um Texturen von einem Quellnetz auf ein optimiertes Netz anzuwenden.
Das Substance Automation Toolkit ermöglichte es mir, alle im Texturübertragungsprozess verwendeten Vorgänge mit Substance Designer zu erstellen und sie über Python-Skripte in der Pipeline aufzurufen. Es ermöglicht mir außerdem, die Optimierung von der Texturgenerierung in zwei separate Phasen zu trennen, was bedeutet, dass SCons die Zwischendateien unabhängig verfolgen können; auf diese Weise lösen Änderungen in den Materialdaten keine Geometrieoptimierung aus, solange das Modell gleich bleibt, da die Die Optimierung selbst ist unabhängig vom Material irrelevant.
4.12 Formatkonvertierung von 3D-Assets
Manchmal müssen Sie möglicherweise .obj oder .gltf in 3D-Assets in anderen Formaten wie DAE, GLB, PLY usw. konvertieren. Sie können in Betracht ziehen, NSDT 3DConvert, ein leistungsstarkes Online-Tool zur Konvertierung von 3D-Formaten, zu Ihrer Optimierungspipeline hinzuzufügen.
5. Pipeline
Die Pipeline besteht aus den folgenden Phasen:
5.1 Textur-Rendering
In dieser Phase schauen wir uns die Material-Rigs aller verarbeiteten Modelle an und rendern Substance PBR-Bilder aller verwendeten Materialien.

5.2 Referenzmodellerstellung
Die Referenzphase kombiniert das Originalmodell mit Rendertexturen, um eine Referenz-GLB-Datei zu generieren.
Diese Referenz-GLB-Datei wird nicht weiterverwendet, ist aber eine gute Ressource für „Vorher“- und „Nachher“-Filmmaterial. Es hilft auch beim Debuggen, ob Probleme in der Ausgabe während der Optimierung oder in den Quelldaten aufgetreten sind.
Aufgrund der im obigen Abschnitt „.obj“ beschriebenen Einschränkungen der eingegebenen UV-Koordinaten wird das UV-Diagramm entsprechend der Materialskala und der Zuordnungsskala skaliert. Dadurch wird sichergestellt, dass die Textur den gleichen Maßstab wie das optimierte Modell hat.
5.3 Optimierung
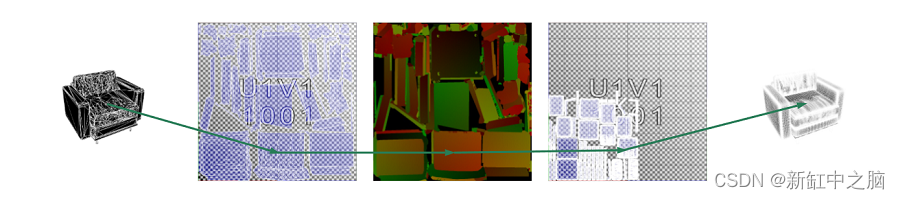
Die Optimierungsphase lädt das Quellmodell und führt den Neuvernetzungsprozess mit Simplygon aus. Während dieses Vorgangs erhält das Modell einen neuen UV-Satz, der nichts mit dem ursprünglichen UV-Satz zu tun hat.
Neben der Neuvernetzung werden auch Simplygon Geometry Casters verwendet, um eine Reihe von Texturen zu generieren und Texturdaten vom Quellmodell an das optimierte Modell zu übertragen. Diese Karten werden im neuen UV-Raum des optimierten Modells dargestellt:
-
Material-ID. Diese Karte kodiert den Materialindex für jedes Texel. Anhand dieser Karte können wir bestimmen, welches Material welchem Punkt im Quellmodell zugeordnet werden soll.
-
UVs. Diese Karte kodiert die UV-Koordinaten des Quellmodells im Texturraum des optimierten Modells. Mithilfe dieser Karte können wir bestimmen, wo in den Texturen des Quellmodells gesucht werden muss, um Daten an das optimierte Modell zu übertragen.
Beachten Sie, dass es sich bei dieser Karte um eine 16-bpp-Karte zwischen 0 und 1 handelt. Aus diesem Grund können wir keine UVs zum Kacheln des Materials verwenden. Die zugewiesenen Materialkacheln werden auf die Textur-Rendering-Phase angewendet.
UV-neu zugeordnete Texturen ermöglichen es uns, die UV-Koordinaten auf dem High-Poly-Modell zu finden, sodass wir das optimierte Modell mit den ursprünglichen UVs texturieren können:
- Umgebungsokklusion des Quellmodells, ausgedrückt im UV-Raum des optimierten Modells. Da die Umgebungsokklusion mithilfe von Details aus dem Quellmodell erstellt wird, werden visuelle Hinweise auf verlorene Geometrie bereitgestellt, indem Bereiche verdeckt werden, die bei der Optimierung möglicherweise verloren gehen.
- Die Weltraumnormalen und Tangenten des Quellmodells im UV-Raum des optimierten Modells. Mithilfe dieser beiden Karten können wir die fehlenden Normalen des Originalmodells erfassen und die auf das Quellmodell angewendete Tangentenraum-Normalenkarte zur weiteren Verarbeitung in den Weltraum übertragen.
- Optimieren Sie die Weltraumnormalen und Tangenten des Modells. Mithilfe dieser Karten können wir die Normalen vom Quellmodell auf die Tangentenraum-Normalenkarte des optimierten Modells übertragen und dabei sowohl die Quellnetznormale als auch die darauf angewendete Tangentenraum-Normalenkarte erfassen.
5.4 Optimieren Sie die Texturwiedergabe des Modells

Bei dieser Phase handelt es sich um einen mehrstufigen Prozess zur Übertragung aller Quellmaterialkarten aus dem Quellmodell mithilfe des Substance Automation Toolkit. Da der Stoffgraph keine Geometrie in die Verarbeitung einbeziehen kann, wird für den Stofftransfer der Graph aus der Optimierungsstufe verwendet. Der grundlegende Prozess verwendet die UV-Transferkarte, um Probenorte auszuwählen, und wählt Texturen basierend auf der Material-ID-Karte aus.
Zusätzlich zu den Versorgungs- und Materialkarten werden in dieser Phase der Maßstab und die Parameter jedes Materials in Bezug auf Mipmaps als Eingabe verwendet, um die Kachelung und Filterung zu steuern.
Bei Normalkarten ist der Prozess komplizierter, da nicht nur die Normalkarte des Quelltexturraums abgetastet werden muss, sondern auch die Normalen und Tangenten der Quell- und Zielnetze einbezogen werden, um eine Tangentenraumnormalkarte für das optimierte Modell zu generieren.
Beachten Sie, dass sich der gesamte Vorgang bis nach der Bereitstellung verzögern kann. Wenn das Modell in einer Materialprofilierungsszene verwendet werden soll, kann dieser Prozess mit der Substance-Engine oder dem Substance Automation Toolkit auf dem Server ausgeführt werden, um Bilder bei Bedarf basierend auf Benutzereingaben zu generieren; dies ist viel schneller als die Durchführung einer vollständigen Optimierung Pipeline.
5.5 Endgültige Szenenmontage
Die Szenenkomponente verwendet Simplygon, um optimierte Geometrie zu laden und ihr eine neue Rendermap zum Speichern von GLB-Dateien mit Materialien zuzuweisen.
5.6 Durchführung der Auftragsabwicklung
Die Jobverarbeitung ist als Python-Skript implementiert, das alle Abhängigkeiten für Jobs, Pipelines, Materialbibliotheken usw. versteht und verfolgt.
Die verschiedenen Build-Stufen sind separate Python-Dateien, und die Pipeline wendet die relevanten Parameter und Eingabedateien auf jede Stufe an. Der Inhalt der Datei und der Parameter fungieren als Cache-Schlüssel. Wenn sich also seit der letzten Ausführung nichts davon geändert hat, können Sie das alte Ergebnis wiederverwenden, anstatt es neu zu erstellen.
Das bedeutet, dass wir versuchen, bei jedem Vorgang den kleinsten Parametersatz anzuwenden, um unnötige Neuverarbeitungen zu vermeiden. Als Beispiel für das Bereinigen von Daten werden nur Materialinstanzen, auf die in der verwendeten Materialzuweisungsdatei des Objekts verwiesen wird, als Parameter angewendet. Dadurch wird sichergestellt, dass nur Änderungen an Materialinstanzen, auf die das verarbeitete Modell verweist, einen neuen Build auslösen.
Verarbeitungsskripte können auf zwei Arten ausgeführt werden:
- Build-Modus. In diesem Modus erkennt es alle Build-Vorgänge und führt sie direkt aus Python aus. Beachten Sie, dass hierbei kein Caching berücksichtigt wird und die gesamte Pipeline bei jedem Lauf neu bewertet wird.
- Trockenlaufmodus. In diesem Modus wird die gesamte Abhängigkeitsauflösung durchgeführt, aber anstatt die Pipeline auszuführen, wird eine Liste von Build-Aktionen mit entsprechenden Parametern und allen angegebenen Eingabe- und Ausgabedateien generiert.
Die Ausgabe des Probelaufmodus kann von jedem Build-System genutzt werden, das die Ergebnisse dann parallel in Abhängigkeitsreihenfolge erstellen kann.
5.7 SCons-Skript
Das SCons-Skript führt die Pipeline im Trockenlaufmodus aus und verwendet die Ausgabe, um alle Build-Aufgaben anzugeben.
Es verwendet dieselben Build-Aktionen, die Python-Skripte im Build-Modus verwenden, um Aufgaben auszuführen. SCons ermitteln dann, welche Aufgaben unabhängig sind, und versuchen, so viele Aufgaben wie möglich parallel auszuführen, um sicherzustellen, dass der Build schnell ausgeführt wird. Außerdem wird ermittelt, welche Ziele bereits aktuell sind, und diese unverändert beibehalten, sodass nur die geänderten Ziele erstellt werden.
5.8 Codepaket
Den Code für die Pipeline finden Sie auf Substance Share. Das Paket enthält Installations- und Betriebsanweisungen, damit Sie die Pipeline selbst erkunden können.
6. Ergebnisse
6.1 Ausgabemodell
Der Vergleich besteht hier darin, das erstellte Referenzmodell mit dem optimierten Modell zu vergleichen.
Dies ist nicht unbedingt ein Vergleich mit vergleichbaren Modellen, da die Texturdichte beim Referenzmodell deutlich höher ist, aber es sollte eine Schätzung des Unterschieds zwischen den Modellen liefern. Beachten Sie auch, dass die Zahlen zwischen Ihrem eigenen Lauf und unserem möglicherweise nicht identisch sind, da weder die Optimierung noch der Texturierungsprozess deterministisch sind.
6.2 Beispielleitungen
In diesem Prozess gibt es zwei Linien, LQ und HQ, für niedrige bzw. hohe Qualität. LQ ist aggressiv für die Verwendung mit Modellen in Miniaturbildgröße optimiert. HQ ist für einen 600x600-Pixel-Viewer.
Überprüfen Sie das Modell:

6.3 Anzahl der Polygone
| Modell | Polygonanzahl | HQ-Polygonanzahl | Anzahl der LQ-Polygone |
|---|---|---|---|
| Sofa A1 | 96948 | 2226 | 256 |
| Sofa A2 | 133998 | 1496 | 168 |
| Sofa B1 | 740748 | 2628 | 238 |
| Sofa B2 | 1009690 | 1556 | 118 |
Wie Sie sehen können, ist die Polygonanzahl im optimierten Modell um Größenordnungen niedriger. Beachten Sie auch, dass dichtere Quellmodelle keine wesentlich höhere Polygonzahl erzeugen als Modelle mit niedrigerer Quelldichte. Dies ist eine Funktion, die für einen Prozentsatz der Zielbildschirmgröße und nicht für die ursprüngliche Polygonzahl optimiert. Dies ist wünschenswert, da unterschiedliche CAD-Pakete, Arbeitsabläufe und Designer sehr unterschiedliche Quelldaten erzeugen können. Bei der Visualisierung von Daten möchten wir jedoch eine einheitliche Paketgröße für ein bestimmtes Anzeigeszenario.
6.4 Dateigröße
Die Dateigröße wird durch die Kombination von Polygonen und Texturen bestimmt, die das Bild erzeugen.
| Modell | Referenzgröße HQ | Optimierte Größe des Hauptquartiers | Optimierte Größe LQ |
|---|---|---|---|
| Sofa A1 Leder | 80 MB | 3,4 MB | 0,24 MB |
| Sofa A1 Stoff | 78 MB | 4,4 MB | 0,29 MB |
| Sofa A2 Leder | 80 MB | 3,3 MB | 0,22 MB |
| Sofa A2 Stoff | 82 MB | 4,1 MB | 0,26 MB |
| Sofa B1 Leder | 102 MB | 3,3 MB | 0,26 MB |
| Sofa B1 Stoff | 104 MB | 3,8 MB | 0,29 MB |
| Sofa B2 Leder | 112 MB | 3,4 MB | 0,23 MB |
| Sofa B2 Stoff | 113 MB | 4,0 MB | 0,27 MB |
Wie Sie sehen, gibt es einen großen Unterschied in der Downloadgröße zwischen dem Originalmodell und dem optimierten Modell. Das hat seinen Preis und diese Modelle sind wirklich nicht ideal für eine genaue Betrachtung, aber sie stellen sinnvolle Betrachtungsszenarien dar, bei denen die zusätzlichen Kosten eines höherwertigen Modells unerschwinglich sind. Fairerweise muss man sagen, dass das Referenzmodell nicht auf die Größe optimiert ist, und es kann viel getan werden, um es kleiner zu machen, wenn ein höheres Qualitätsniveau erforderlich ist.
6,5 GPU-Draw-Aufrufe
Das optimierte Modell kombiniert Texturen für alle Materialien in einem einzigen Atlas, was bedeutet, dass sie als ein einziger Zeichenaufruf gerendert werden können.
Die Quellmodelle verwenden drei verschiedene Materialgruppen. Daher übermitteln die meisten Renderer drei Zeichenaufrufe für jedes Modell.
6.6 Überziehen
Die interne Geometrie des optimierten Modells wird bereinigt, was bedeutet, dass es nur sehr wenig unnötiges Überzeichnen gibt.

Als Beispiel für eine reale Situation, in der die Optimierung von Inhalten Auswirkungen haben kann, habe ich ein Adobe Aero-Projekt erstellt, das alle 8 Modelle umfasst. Ein Projekt verwendet das Referenzmodell und ein Projekt verwendet das Optimierungsmodell.
Diese Projekte wurden mit dem Adobe Aero Beta-Desktop erstellt und dann auf einem iPhone mit einer schnellen LTE-Verbindung geöffnet, um die Unterschiede zu vergleichen, wann die Modelle mit dem Gerät synchronisiert wurden, damit sie einsatzbereit waren.
Das erste Problem bestand darin, dass die beiden Sofa B1 und Sofa B2 als zu schwer galten, um im Projekt mit dem Referenzmodell beladen zu werden, sodass sie in der Aero-iPhone-App überhaupt nicht auftauchten. Ihre Quelldaten haben eine deutlich höhere Polygonzahl und sie sind auf die Modellgewichtung begrenzt, um eine gute Leistung der Anwendung sicherzustellen.
6.7 Öffnungszeit
Zeit, das Projekt zu öffnen und zu synchronisieren:
| Modelltyp | offene Zeit |
|---|---|
| Referenz | 4 Minuten 50 Sekunden |
| Optimierung | 32 Sekunden |
6.8 Ausführungszeit Bearbeitungszeit
Die optimierte Pipeline läuft auf einer 6-Kern-Intel Core-7-CPU mit 2,6 GHz. Dadurch werden ein Referenzmodell und ein optimiertes Modell für 2 Materialkonfigurationen für 4 verschiedene Modelle generiert.
| Ausführungsmodus | Ausführungszeit |
|---|---|
| Python-nativ | 14 Minuten 25 Sekunden |
| SCons parallel 6 Kerne | 5 Minuten 50 Sekunden |
Wie Sie sehen, ist der Prozess etwa doppelt so schnell, wenn er über SCons ausgeführt wird. Angesichts der Tatsache, dass 6 Kerne genutzt werden können, mag das ein wenig überraschend sein, aber die Realität ist, dass viele laufende Prozesse von Natur aus Multi-Threaded sind – das heißt, Sie können nicht linear durch Hinzufügen von Kernen skalieren.
Der eigentliche Vorteil von SCons besteht darin, minimale Änderungen an Anlagen vorzunehmen und inkrementell aufzubauen, wobei die Durchlaufzeiten in Sekunden gemessen werden, solange die durchgeführten Vorgänge nicht zeitaufwändig sind und keine Fehler auslösen. Weiter unten hat sich viel verändert.
6.9 Ausführungszeit im Kontext
Wenn Sie sich diese Zahlen ansehen, müssen Sie sie zunächst mit denen vergleichen, die diese Arbeit von Menschen ausführen. Die Erstellung eines Modells mit niedriger Auflösung ist eine zeitaufwändige Aufgabe, die möglicherweise mehrere Stunden in Anspruch nimmt. Dies ist auch eine Aufgabe, die jedes Mal, wenn sich das Quellmodell ändert, in gewissem Umfang erneut durchgeführt werden muss. Die Automatisierung dieses Prozesses ist aus Sicht des Zeitaufwands ein großer Gewinn.
Beachten Sie außerdem, dass der Prozess vor dem Benutzer verborgen bleiben und auf einem separaten Computer ausgeführt werden kann. Dies bedeutet, dass es im Hintergrund des Build-Computers ausgeführt werden kann, um sicherzustellen, dass der Prozess den Benutzer nicht verlangsamt oder die Workstation unnötig belastet.
7. Die Zukunft der Arbeit
Die Beispielpipeline ist sehr begrenzt, soll Ihnen jedoch einen Überblick darüber geben, wie Pipelines es Ihnen ermöglichen, Inhalte effektiver zu optimieren und bereitzustellen. Hier sind einige Verbesserungen, die hinzugefügt werden könnten, um es skalierbar zu machen und besser zu funktionieren.
7.1 Texturkomprimierung
Die Texturen im Modell sind PNG-Dateien. Es gibt verschiedene Möglichkeiten, kleinere Dateien zu erhalten:
- Implementieren Sie pngquant in der Pipeline. Das Tool pngquant ist ein verlustbehafteter .png-Kompressor, der die Größe von .png bei sehr geringem Qualitätsverlust erheblich reduzieren kann und keine spezielle Skalierung im Viewer erfordert
- Derzeit wird an der GPU-Hardware-Texturkomprimierung als .gltf/.glb-Erweiterung gearbeitet. Dies sollte kleinere Dateien und schnellere Ladezeiten ermöglichen.
7.2 Bessere Unterstützung für Substanzparameter
Das aktuelle Materialinstanzformat ist auf die Arbeit mit Skalaren, Vektoren, Booleschen Werten usw. beschränkt. Es kann jedoch zu einem Fehler kommen, wenn Sie versuchen, eine Aufzählungszeichenfolge oder einen Parametertyp einer höheren Ebene zu verwenden.
7.3 Weitere Optimierungsmöglichkeiten/Strategien
Diese Optimierung stellt nur einen einzigen Algorithmus mit einem minimalen Parametersatz bereit. Es kann gute Gründe geben, mehr Optionen und Algorithmen einzuführen, um ein breiteres Spektrum an Objekttypen anzusprechen.
7.4 Netzkomprimierung
.gltf unterstützt die Draco-Mesh-Komprimierung. Sein Prozess wird hier bewertet, aber da die meisten Daten aus Texturen bestehen, gibt es keine wesentlichen Auswirkungen auf die Dateigröße.
7.5 Netzfreigabe
In dieser Pipeline ist das Netz bei verschiedenen Materialänderungen gleich. Eine Einstellung, die Ergebnisse in eine .gltf-Datei statt in eine .glb-Datei schreibt, ermöglicht die gemeinsame Nutzung von Mesh-Daten zwischen verschiedenen Dateien, um weniger Speicherplatz zu verbrauchen.
7.6 Zersetzungsvorgang
Sowohl die Optimierung als auch das Textur-Rendering sind Vorgänge, die durch den Aufruf mehrerer Prozesse implementiert werden. Wenn sie in kleinere Operationen unterteilt werden, können SCons in ihnen mehr Parallelität finden und eine feinkörnigere Abhängigkeitsverfolgung ermöglichen.
7.7 Normale Kartenverkleinerung
Normalkarten werden mithilfe von Mipmaps gefiltert. Dies ist nicht der richtige Filter für Normalkarten. Normale Details, die zu fein sind, um der Rauheit des Objekts gerecht zu werden, können verschoben werden, um die Qualität zu verbessern. Dies wird im Artikel zum LEAN-Mapping beschrieben.
7.8 Asset-Referenz
Aktuelle Asset-Referenzen (.sbsar-Dateien, Meshes usw.) sind lokale Dateipfade. Dieses Setup funktioniert gut auf einem einzelnen Computer. Wenn Sie Ihre Pipeline jedoch auf mehrere Computer skalieren möchten, müssen Sie möglicherweise mithilfe eines URI-Schemas auf die Dateien verweisen, um sicherzustellen, dass auf allen Computern auf strukturierte Weise auf sie verwiesen werden kann.
7.9 Außerkraftsetzungen festlegen
In einem realen Optimierungsprozess wird es einige Assets geben, die Probleme haben oder spezielle Einstellungen erfordern. Eine praktische Möglichkeit, wiederholbare Korrekturen (z. B. Texturauflösung, optimierte Qualität usw.) pro Asset vorzunehmen, ist die Verwendung von Einstellungsüberschreibungen. Dadurch können Benutzer Eigenschaften pro Pipeline und pro Asset überschreiben; diese überschreiben die Standardwerte in der Pipeline.
7.10 Größerer Maßstab
Bei groß angelegten Bereitstellungen kann ein solcher Build-Prozess auf mehrere Maschinen verteilt werden. Dies ist jedoch mit SCons nicht möglich und erfordert ein anderes Build-System.
Ursprünglicher Link: Pipeline-Automatisierung zur 3D-Asset-Optimierung – BimAnt