
fondo
La calidad de los datos es uno de los requisitos previos y garantías importantes para la eficacia de las aplicaciones derivadas del big data. El rápido desarrollo de las necesidades comerciales de la Estación B y la visión de incubar aplicaciones más profundas y competitivas basadas en big data en el futuro requieren que nuestra plataforma de datos proporcione datos en tiempo real, precisos y confiables en los que todas las empresas puedan confiar. fiestas. Se puede decir que los datos confiables son la encarnación de la competitividad central de la plataforma de big data. Por lo tanto, en el proceso de construcción de la plataforma de big data de la estación B, la plataforma de calidad de datos se ha convertido en una parte indispensable, porque su misión es acompañar la calidad de los datos de la plataforma de big data.
Plataforma de calidad
componentes de la plataforma
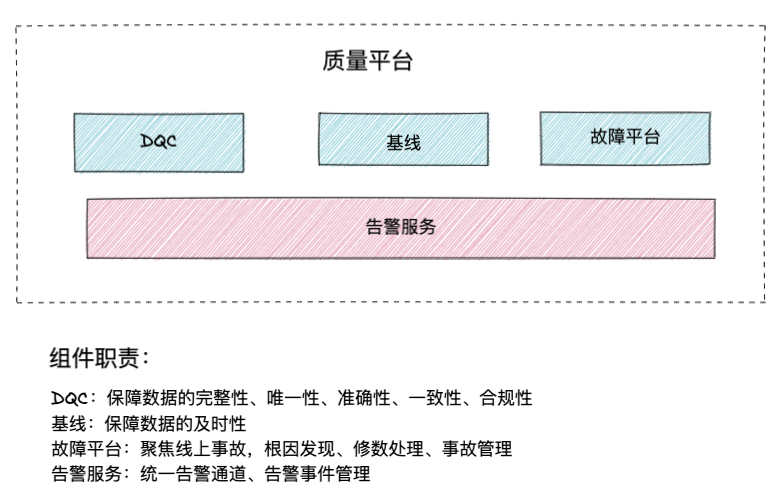
Introducción al DCC
Diagrama de funciones

El principal vínculo de trabajo de DQC es básicamente similar al de los sistemas de monitoreo ordinarios como Prometheus. El proceso incluye la recopilación de datos, la inspección de datos y la notificación de alarmas. Es necesario minimizar el impacto en el funcionamiento normal de los objetos monitoreados y, al mismo tiempo, Al mismo tiempo, alarmar oportunamente las anomalías de los objetos monitoreados.
Hay funciones fuera de línea y en tiempo real.
DQC fuera de línea: se utiliza principalmente para garantizar los datos producidos por tareas fuera de línea. La regla de activación es principalmente notificar a DQC que recopile después de que se complete la tarea de programación fuera de línea y luego verificar y emitir alarmas de acuerdo con el umbral. Por lo general, el usuario configura las reglas de inspección, que generalmente entrarán en vigor después de que se complete la siguiente tarea.
DQC en tiempo real: principalmente para fuentes de datos Kafka. Kafka es un componente básico muy importante en la plataforma de big data, especialmente en el almacén de datos en tiempo real y se utiliza con más frecuencia. Generalmente, los datos en una determinada ventana se recopilan e inspeccionan en un ciclo de inspección fijo de acuerdo con las reglas. Normalmente el usuario configura las reglas de verificación, que generalmente entrarán en vigor después del siguiente período de datos.
CCD en tiempo real
La primera versión del plan.
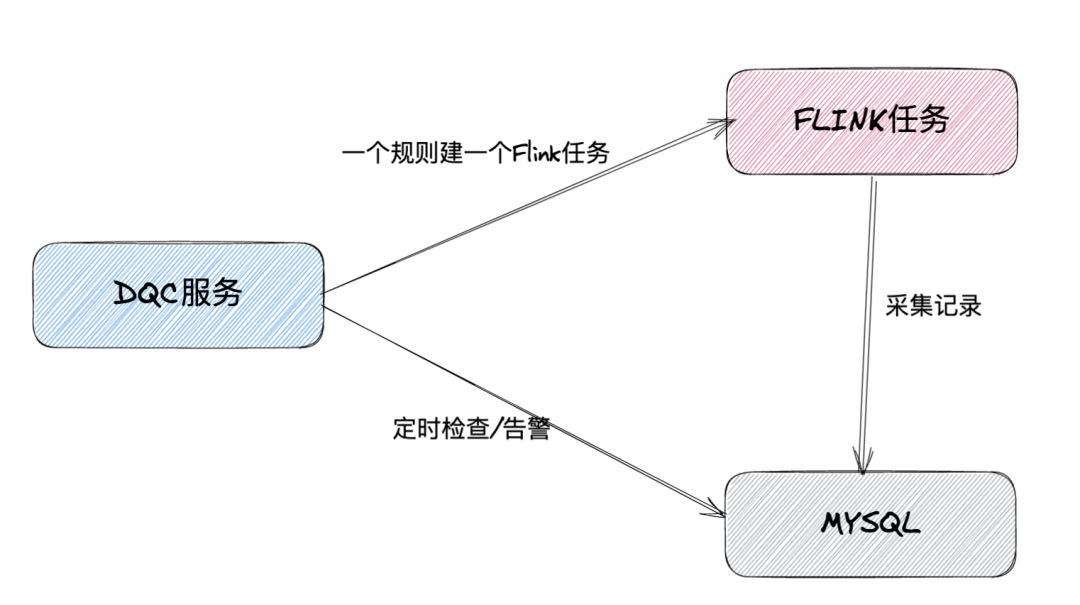
El marco principal para la computación de flujo dentro de la empresa es Flink, y todos los DQC en tiempo real también utilizan el marco informático Flink.
DQC en tiempo real es mucho más complicado que DQC fuera de línea, porque sus tareas de recopilación de datos siempre están en ejecución y es difícil actualizar reglas o agregar objetos de recopilación a una tarea que ya se está ejecutando.
Por lo tanto, en la primera versión de la solución, cada vez que el usuario agrega un objeto de colección o una regla, el servicio DQC regenerará una nueva tarea de Flink para que el usuario complete la colección y escriba los resultados de la colección en MySQL. Al mismo tiempo, la verificación de la regla de calidad se activa periódicamente, el resultado de la verificación se escribe en MySQL y se determina una notificación de alarma en función del resultado de la verificación.
Esta solución tiene una estructura simple, pero aún existen las siguientes desventajas:
Baja utilización de recursos: debido a una regla de inspección y una tarea de recopilación de datos, las tareas de Flink están inactivas la mayor parte del tiempo, especialmente en algunos temas con poco tráfico.
Alto consumo de ancho de banda de la red: para diferentes reglas de un tema, se requieren múltiples tareas para consumir. Si el tráfico del tema es intenso, tendrá un gran impacto en el ancho de banda de la red.
Mala estabilidad: la modificación de las reglas requiere reiniciar la tarea de recopilación de datos. Cuando los recursos del clúster son escasos, el inicio puede fallar porque no se pueden solicitar los recursos de YARN/K8s.
El programa de monitoreo en sí consume muchos recursos y está desactualizado ahora que la reducción de costos y la mejora de la eficiencia son la corriente principal. Por lo tanto, necesitamos urgentemente transformar la solución DQC en tiempo real. Existen tres requisitos para el uso de recursos:
Comience una vez, no reinicie nunca más. Evite la competencia de recursos y mejore la disponibilidad del sistema.
Una tarea puede ser compartida por varios temas. En aplicaciones prácticas, parte del tráfico de temas es muy pequeño, lo que hace que las tareas de Flink estén relativamente inactivas la mayor parte del tiempo. Si un Flink puede consumir varios temas más de este tipo, el mismo recurso puede hacer más cosas y la tasa de utilización de recursos es mayor.
Consumo único, verificación de múltiples reglas. Evite el consumo repetido de un tema por parte de múltiples tareas y reduzca el consumo de ancho de banda de la red.
Nuevo plan

Objetivos de diseño:
Precisión del procedimiento de recopilación de DQC en tiempo real;
Puntualidad de las verificaciones de reglas;
Minimizar el consumo de recursos de DQC en tiempo real;
Minimizar el impacto del funcionamiento normal de Kafka;
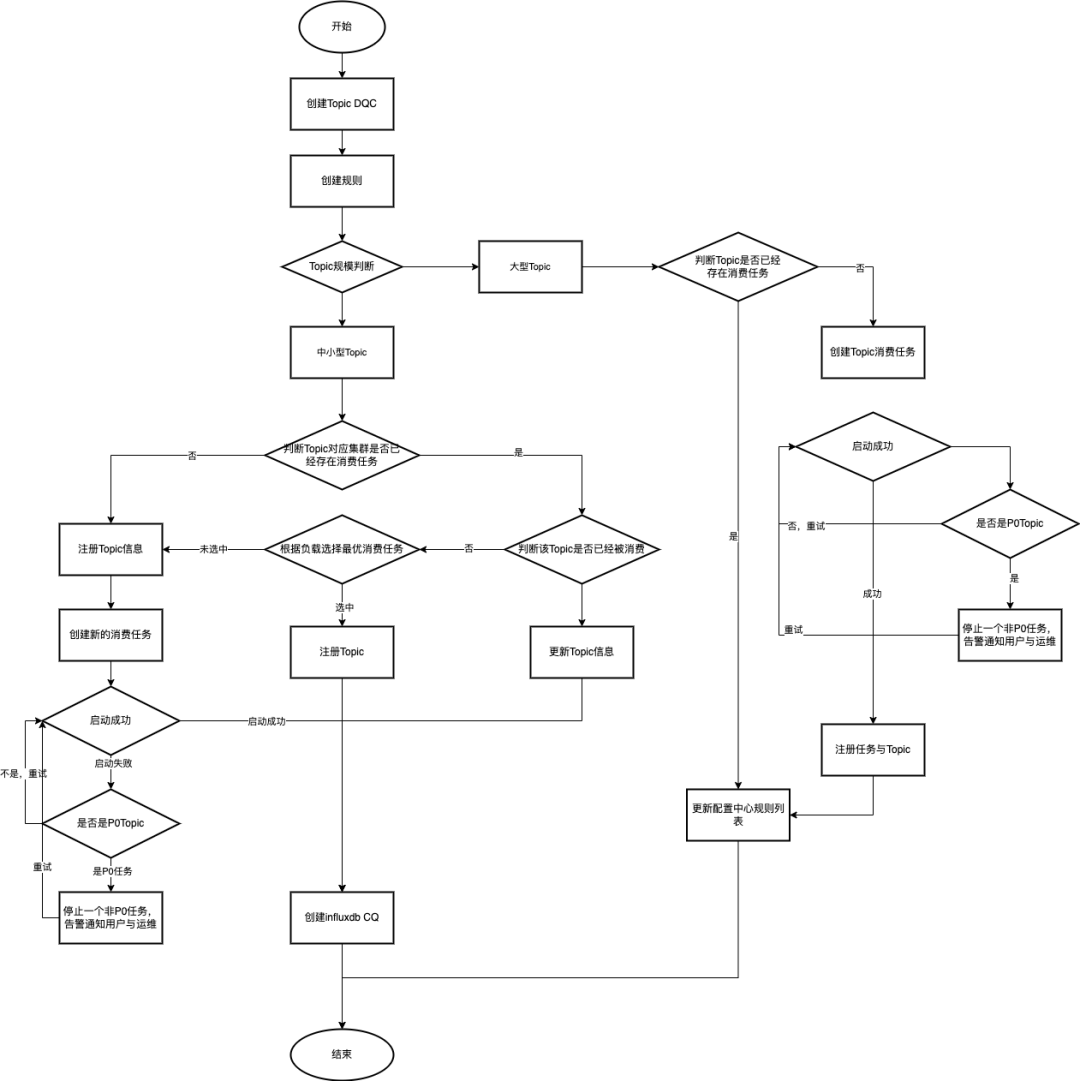
Arquitectura general

Actualmente, hay más de 7000 temas en línea. Para facilitar la gestión, el DQC en tiempo real divide los temas en temas grandes, temas medianos y temas pequeños según el QPS aceptable para Influxdb y la tasa de utilización de las tareas de Flink. Tema pequeño: volumen de mensajes <1000/s, tema mediano: volumen de mensajes (1000/s—10 w/s), tema grande: volumen de mensajes> 10 w/s.
analisis de CASO:
Los temas grandes, medianos y pequeños se administran por separado y se utilizan diferentes rutas para la recopilación de datos. Todos los datos de los temas pequeños, medianos y pequeños se importan a la tabla completa (los campos se filtrarán de acuerdo con las reglas de inspección) y luego, use la función Influxdb CQ para agregarlos y almacenarlos en la tabla CQ para completar la recopilación de datos, mientras que el tema grande calcula directamente los datos de agregación finales en la tarea de Flink y los almacena en la tabla CQ;
Tabla de escala completa de Influxdb: utilizada por temas pequeños y medianos, guarda la cantidad total de datos en el tema (los campos se filtrarán de acuerdo con las reglas de inspección) y el tiempo de validez general es de una hora;
Tabla CQ de Influxdb: se utilizarán todos los temas y los datos agregados de los temas se guardarán para la verificación de reglas. El tiempo de validez general es de dos semanas;
Dinámica de temas: puede agregar o eliminar temas monitoreados durante el tiempo de ejecución sin reiniciar la tarea Fllink;
Reglas dinámicas: puede agregar, eliminar y modificar reglas de monitoreo de temas durante el tiempo de ejecución sin reiniciar la tarea Fllink;
Gestión de recursos DQC: esto incluye dos partes, una tarea de Flink y un recurso de Influxdb, utilice racionalmente estos dos recursos y asigne y administre dinámicamente el tema o las reglas del tema;
Solución de temas pequeños y medianos
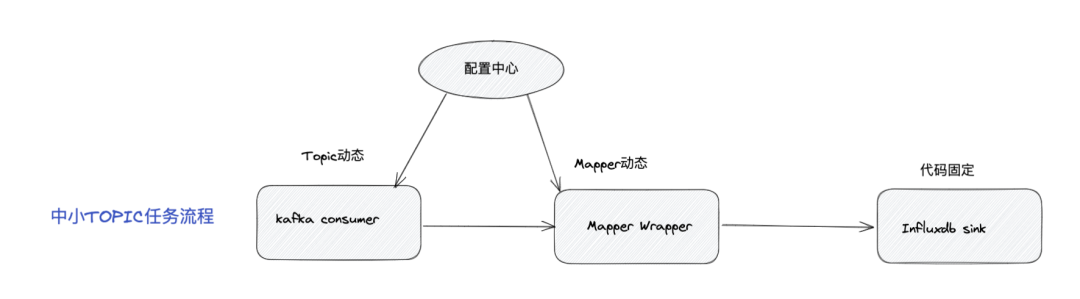
Importe todos los datos a la tabla completa (los campos se filtrarán según las reglas de inspección)
Dinámica de soporte de temas y mapeadores:
El tema es dinámico y la lista de temas se mantiene en el centro de configuración. KafkaConsumer puede percibir cambios de configuración para lograr la adición y eliminación dinámica de temas;
Mapper es dinámico. De acuerdo con la lista de temas de consumo, el formato de datos internos del tema y las reglas DQC correspondientes, la lógica de procesamiento de Mapper se forma dinámicamente y se envía a Mapper Warpper;
Solución de temas pequeños y medianos: kafkaconsumer
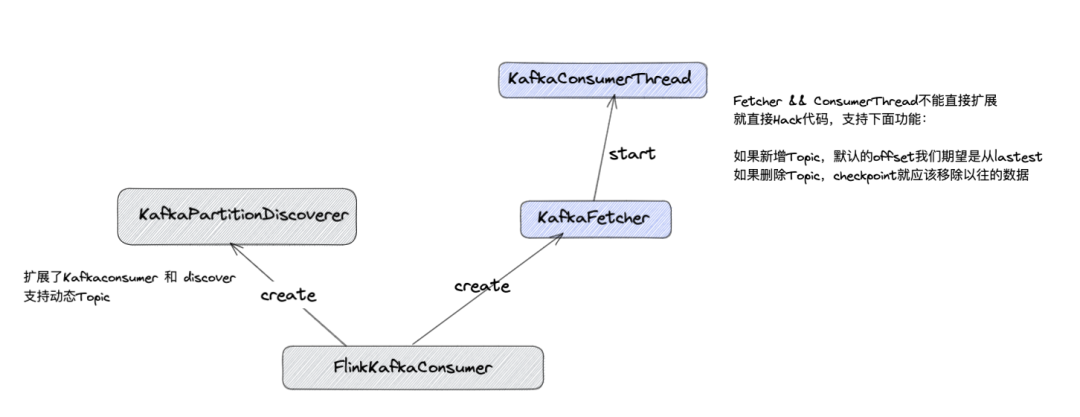
Solución: debido a la mano de obra y el tiempo de desarrollo, un nuevo consumidor Kafka que admite temas dinámicos no está completamente desarrollado, pero FlinkKafkaConsumer se amplía y KafkaFetcher && KafkaConsumerThread se maneja mediante piratería.
Solución de temas pequeños y medianos: Mapper

Solución: forme el código de bytes de Mapper de acuerdo con TopicList, contenido del tema y reglas DQC, guárdelo en el centro de configuración en Base64 y obtenga Mapper Wrapper dinámicamente para formar un nuevo Mapper para reemplazar al antiguo Mapper.
Solución de gran tema
Debido al gran tráfico de temas grandes, si se utiliza la misma solución para temas pequeños y medianos, causará una gran presión tanto en el ancho de banda de la red como en el almacenamiento subyacente. Por lo tanto, elegimos otra solución: un solo tema, una sola tarea + dinámica de reglas.
Cada tarea de Flink solo consume un tema. En esta tarea, debemos poder percibir dinámicamente los cambios en las reglas de inspección para este tema y marcar los flujos de datos consumidos en tiempo real de acuerdo con las reglas de inspección. Presione Windows para agregar.

Lógica dinámica: las reglas son dinámicas y la metainformación de las reglas se mantiene en el centro de configuración. FlatMap puede detectar los cambios de las reglas y generar los registros afectados por las reglas hacia atrás para su agregación.
Dinámica de reglas
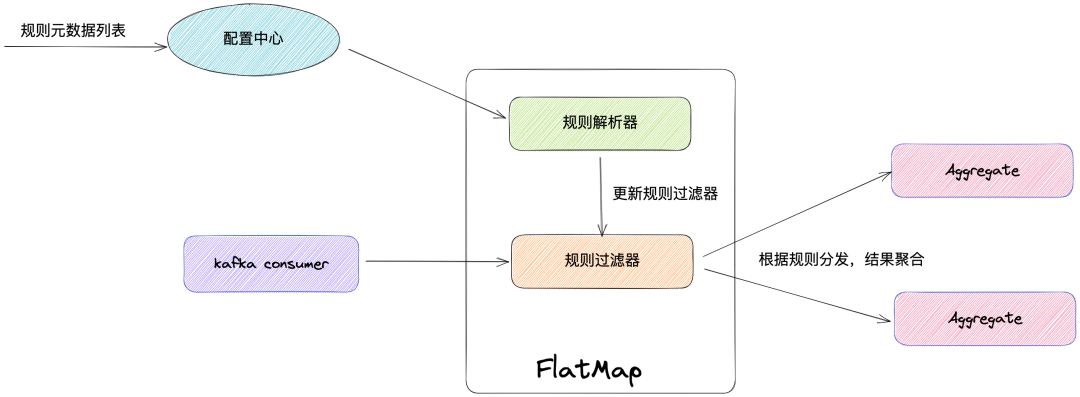
Para reducir el costo de aprendizaje del usuario, en esta solución, somos consistentes con la configuración DQC fuera de línea y el usuario puede filtrar los datos a través de la cláusula SQL personalizada donde para lograr una inspección de calidad más refinada. El analizador de reglas realizará un análisis léxico en la cláusula donde en SQL y generará los filtros correspondientes para el filtrado de datos. Después de marcar los registros que cumplen con las reglas, la ID de la regla se generará hacia atrás de acuerdo con la ID de la regla y luego el operador de agregación. realizará la agregación local.
hinchazón de datos
La expansión de datos puede ocurrir durante el proceso de salida a la ventana para su agregación después del marcado de reglas.
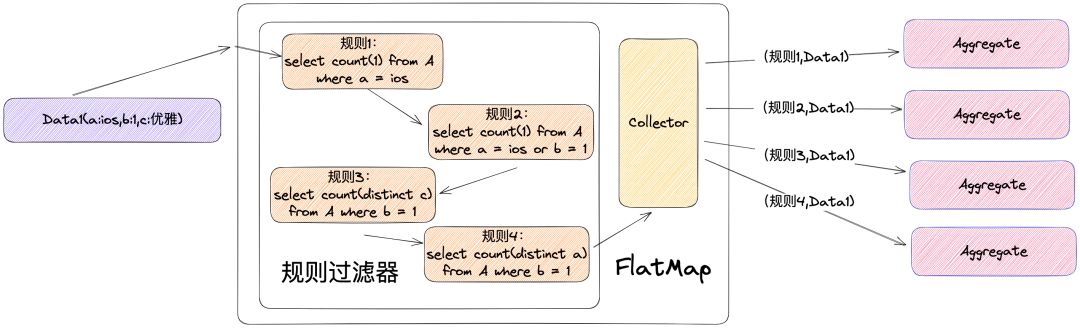
Como se muestra en la figura anterior, cuando los datos ingresan a FlatMap, FlatMap etiquetará los datos con una ID de regla de acuerdo con el filtro de reglas y luego enviará los datos de regreso al operador de agregación, y el operador de agregación los agregará de acuerdo con las reglas. Si un registro no cumple ninguna regla, no se generará al revés. Como se puede ver en la figura anterior, el número de elementos de entrada es 1, el número de elementos de salida es 4 y los datos se expanden 4 veces. Esto se debe a que el formato de los datos que generamos al revés es utilizar el ID de la regla como condición de agrupación. Si un registro cumple con varias reglas, se generarán varios registros. Dado que esta solución está dirigida a un tema amplio, el tráfico en sí es muy grande y, después de ser amplificado por el filtro de reglas, la presión del ancho de banda es muy fuerte, lo que no cumple con la intención del diseño original.
En respuesta a esta situación, hemos realizado dos optimizaciones:
El formato de salida de datos de FlatMap se ajusta a <clave de grupo, RuleIdList, datos>. Combine todos los ID de reglas afectados por los datos y envíelos al revés. Una vez que el operador de agregación recibe los datos, realiza cálculos comerciales basados en RuleIdList.
Usando la arquitectura map->reduce->reduce, los resultados de salida después de marcar las reglas se agregarán localmente primero y luego los datos se resumirán globalmente.

Sin embargo, este diseño no resuelve completamente el problema.
| regla |
lógica de procesamiento |
clave de grupo |
| regla de clase de número de fila de tabla | Acumulación local: al resumir, los resultados del cálculo local se acumulan para obtener el valor resumido | hash de datos |
| Reglas de clase de valor agregado | Acumulación local: al resumir, los resultados del cálculo local se acumulan para obtener el valor resumido | hash de datos |
| Reglas de clase máxima/mínima | Tome el valor máximo/mínimo localmente y tome el valor máximo/mínimo de los resultados del cálculo local al resumir para obtener el valor máximo/mínimo global | hash de datos |
| regla de clase media | Cálculo local <valor acumulado del valor de campo, valor acumulado del número de entradas>, al resumir, combine los resultados del cálculo local para calcular el <valor acumulado del valor de campo, valor acumulado del número de entradas> global para obtener el <valor acumulado global del valor del campo, valor acumulado del número de entradas> | hash de datos |
| Reglas de clase de deduplicación de campos (distintas) | Deduplicar localmente el valor del campo y generarlo al revés, y acumular el número de campos al resumir | valor de campo |
Después de analizar las reglas de calidad DQC en tiempo real, a excepción de las reglas de deduplicación de campos (Distintas), todas las demás reglas son completamente independientes del valor específico de la clave del grupo, porque la lógica empresarial de la agregación parcial es consistente con la final. agregación. Sin embargo, la regla de clase de deduplicación de campos (Distinto) es deduplicar localmente y el número de registros deduplicados se calculará en el resumen final, por lo que la clave de agrupación debe utilizar el valor del campo durante la agregación local. En este sentido, ajustamos el plan de optimización del primer paso:
Cuando el tema no tiene reglas de deduplicación de campos (distintas), todas las reglas se combinan y se generan, y el formato de salida es
Cuando el tema tiene una regla de deduplicación de campos (distinta), todas las reglas se combinarán y generarán, y el formato de salida es <valor de campo, lista ID de regla, datos>
Cuando un tema tiene reglas de deduplicación de múltiples campos (distintas) y utiliza campos diferentes. Fusione la salida de una de ellas con todas las demás reglas de no deduplicación. Las reglas de deduplicación de campos numéricos restantes (distintas) se generan por separado.
La forma final se muestra en la siguiente figura:

Antes de la optimización, debido a la alta tasa de expansión de datos de FlatMap, los operadores de agregación a menudo experimentaban contrapresión, lo que resultaba en una disminución en el rendimiento del consumo.
Después de la optimización, la tasa de exceso de datos se reduce considerablemente, pero aún existe. La tasa de expansión depende de la cantidad de reglas de deduplicación de campos (distintas) y la tasa de expansión es predecible y controlable. En la actualidad, en la plataforma de big data de la Estación B, a excepción de negocios especiales, básicamente no se utilizan tales reglas, pero aún es necesario monitorear el uso de las reglas, aumentar los recursos de manera oportuna o desconectar las reglas. para garantizar la estabilidad de la tarea.
Solución proxy Influxdb
Para adaptar y manejar mejor la conexión entre las solicitudes de lectura y escritura e Influxdb, hemos introducido el servicio proxy Influxdb.
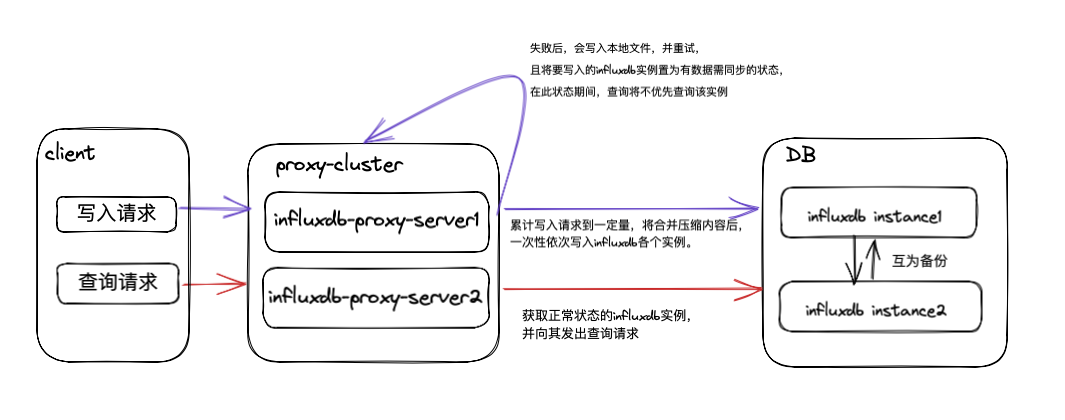
El clúster de fondo de Influxdb contiene varios grupos de instancias, y los datos de cada grupo de instancias no están fragmentados, solo se respaldan entre sí, y la coherencia final está garantizada mediante la doble escritura del proxy.
Durante el proceso de doble escritura, si hay un error de escritura, el proxy Influxdb registrará el contenido de la solicitud fallida en un archivo local y lo volverá a intentar hasta que se escriba correctamente.
Cada nodo de instancia de Influxdb contiene la tabla completa y los datos de la tabla CQ asignados a la instancia.
Optimización de solicitudes de lectura
Al realizar la consulta, el proxy seleccionará el nodo Influxdb óptimo (integridad de datos, rendimiento del nodo) en el back-end para realizar la consulta.
Si todos los nodos de Influxdb en el backend tienen problemas, la consulta se degradará.
Optimizar solicitudes de escritura
Dado que DQC en tiempo real escribe una gran cantidad de datos y es extremadamente frecuente, para reducir la sobrecarga del tráfico de E/S de la red, el proxy Influxdb utiliza compresión gzip y escritura por lotes para mejorar el rendimiento de la escritura.
Después de que el proxy Influxdb se conectó, debido a la gran cantidad de datos escritos en tiempo real durante la operación real, la red IO ha estado en un estado máximo. Después de la investigación, se descubrió que la entrada de datos original era una solicitud que contenía más de 5000 declaraciones de inserción de datos Influxdb completas, y la mayoría de ellas eran la misma base de datos y la misma medida, y cada declaración de inserción tenía demasiadas etiquetas no válidas. Luego optimizamos el protocolo de interfaz para la escritura de datos. Cada solicitud solo se puede escribir en la misma base de datos, se extrae la misma medida y la etiqueta no válida en la declaración de inserción se elimina al mismo tiempo.
Después de la transformación anterior, la sobrecarga del tráfico de E/S de la red se mejoró y disminuyó significativamente.
Garantía de Operación y Mantenimiento
En el proxy Influxdb, se introduce el monitoreo de Prometheus para monitorear los qps de las solicitudes de lectura y escritura, la base de datos escrita, el número y distribución de mediciones, etc. en tiempo real, para fortalecer mejor la utilización de los recursos relacionados.
Admite la gestión de clústeres Influxdb de back-end, incluida la sincronización de datos de nodos, la adición y eliminación de nuevos nodos, la recuperación de datos de nodos, etc.
Esquema de afluenciadb
Escala completa
En el procesamiento de temas pequeños y medianos, elegimos almacenar todos los datos en la base de datos, y cada tema se almacenará por separado como una medición de Influxdb. La estructura de la medición es la siguiente:

tiempo: tiempo de datos
subtarea: campo predeterminado del negocio, número de subtarea de flink consumido
Sinknum: campo predeterminado del negocio, orden de consumo de subtarea
Etiqueta extendida: campo de tema, utilizado para indexar
record_num: campo predeterminado del negocio, el valor es 1, utilizado para calcular las reglas del número de fila
Campo extendido: campo de tema
Campos predeterminados del negocio:En el diseño de la tabla a escala completa, agregamos dos campos de etiquetas adicionales: subtarea y Sinknum. Debido a las características de Influxdb, cuando la hora y la etiqueta de dos registros son exactamente iguales, el registro escrito posteriormente sobrescribirá el anterior. Esta situación puede provocar falsos positivos al calcular las reglas de recuento de filas de la tabla. Por lo tanto, para garantizar que los datos se puedan escribir, agregamos dos campos, subtarea y fregadero. El número de subtarea en el contexto flink utilizado por subtarea y fregadero se implementan utilizando una matriz circular con un rango de valores de 1 a 200. que se utiliza para garantizar que cada registro sea único y no haya problemas de sobrescritura.
Tiempo TTL:La función de la escala completa es principalmente prepararse para el formulario CQ. Influxdb leerá periódicamente la tabla a escala completa, realizará la agregación de datos de acuerdo con las reglas de calidad y escribirá el resultado de la agregación en la tabla CQ. Las características del DQC en tiempo real determinan que los datos de escala completa que se han calculado en la tabla CQ han caducado. Por lo tanto, para evitar el crecimiento ilimitado de recursos, como la cantidad de elementos de datos y números de secuencia, diseñamos el tiempo TTL de la tabla de escala completa en 1 hora, y Influxdb eliminará los registros de la tabla de escala completa que excedan 1 hora. .
La relación entre etiqueta y campo:La etiqueta se usa como índice en Influxdb y generalmente se usa como condición de consulta, mientras que el campo es el valor específico de un evento generado en un momento determinado. En Influxdb, si una consulta no consulta ningún campo, entonces la consulta no tiene sentido y no arrojará ningún resultado. Porque sólo el campo puede reflejar la información en ese momento. Por lo tanto, nuestra empresa reserva un campo record_num como campo de forma predeterminada, y la regla de número de fila de la tabla utilizará este campo primero.
¿Qué campos se almacenarán en Influxdb?
No se puede determinar el número de campos de un tema, son posibles varios o cientos. Al principio no filtramos estos campos y seleccionamos todas las bases de datos, durante la operación encontramos que la llamada al servicio Influxdb-proxy se producía de forma anormal repetidamente. Se encontró un fenómeno tan anormal en la ubicación del problema: la máquina proxy Influxdb consume mucho ancho de banda de la red y un alto uso de CPU. La conclusión final es que cuando Influxdb-proxy escribe en Influxdb, comprimirá los datos, reducirá el consumo de ancho de banda de la red y mejorará el rendimiento de la escritura. Sin embargo, debido a la excesiva información redundante de los datos escritos, el proceso de compresión provocará un muy alto Carga de CPU. La máquina Influxdb-porxy no puede continuar brindando servicios debido a una carga elevada.
Por tanto, eliminar datos redundantes nos lleva al punto de optimización. Después del análisis comercial, no es necesario almacenar la mayoría de los campos de un tema de nuestra tarea. Tomando como ejemplo un TemaA (40 campos) del negocio de transmisión en vivo, calcule las reglas de calidad en un período de tiempo determinado:
| ID de regla |
regla |
SOL empresarial |
Campos que deben almacenarse |
| 1 |
número de filas | seleccione el recuento (1) del tema A | ninguno |
| 2 |
El número de registros de la plataforma IOS. | seleccione recuento (1) del TemaA donde plataforma = 'IOS' | plataforma |
| 3 |
Diferentes números medios de la plataforma Android | seleccione recuento (medio distinto) del TemaA donde plataforma = 'android' | plataforma,media |
De acuerdo con las reglas, descubrimos que los únicos campos que realmente utilizamos son los campos de plataforma y medio, y el resto de los campos son redundantes para el negocio actual. Teniendo en cuenta la situación actual del uso de reglas de calidad en tiempo real, eliminar campos redundantes y almacenar solo la información necesaria puede reducir el consumo de ancho de banda de la red en más del 90%, y la tasa de uso de Influxdb-proxy se ha mantenido en un rango estable. En el uso posterior, este tipo de anomalía nunca se volvió a reproducir.
¿Qué campo se aplicará como etiqueta?
La etiqueta se utiliza como índice en Influxdb. Todas las etiquetas en un registro se denominan Serie de secuencia. De acuerdo con el rendimiento de la máquina, el número de secuencias que cada máquina puede transportar es limitado. La expansión del número de secuencias provocará la lectura. y el rendimiento de escritura de Influxdb cayó bruscamente.
En los primeros días del lanzamiento, se produjo un accidente de este tipo porque no se llevó a cabo el estricto proceso SOP al acceder al tema. Un tema contiene el campo XxxId y el personal de operación y mantenimiento cree erróneamente que este campo es información de diccionario y que el rango de valores es limitado. Por lo tanto, se accede directamente a él como un campo Etiqueta. Como resultado, el campo tiene una cardinalidad alta, lo que hace que el número de secuencias de Influxdb se expanda rápidamente a 300 W en un corto período de tiempo, y Influxdb difícilmente puede proporcionar servicios externos. En la reunión de resumen, para evitar que este tipo de situación vuelva a suceder, formulamos el SOP de acceso al tema y verificamos estrictamente el campo Etiqueta.
La selección del campo Etiqueta es muy importante para la estabilidad de Influxdb. ¿Cómo determinamos qué campo se aplicará como etiqueta?
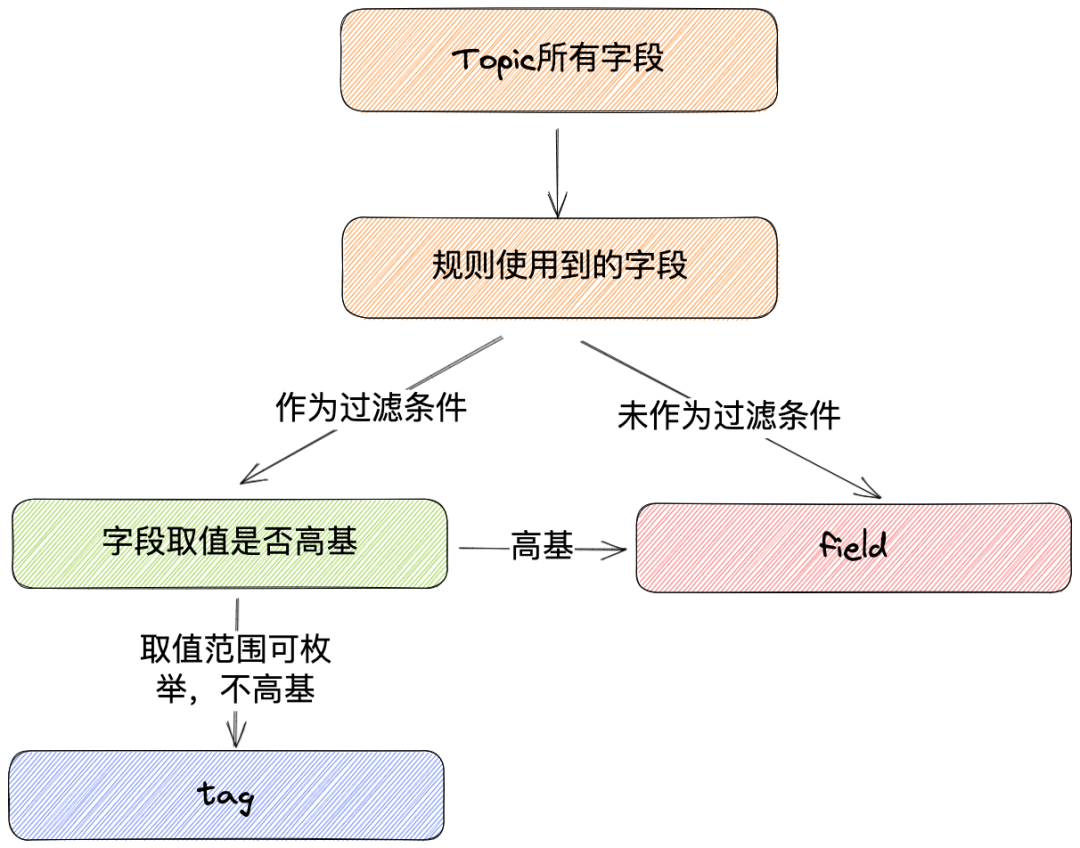
Creemos que el uso del campo de etiqueta debe cumplir los dos puntos siguientes:
La cláusula donde se utiliza como condición de filtro, como por ejemplo la cláusula donde plataforma = 'ios', se seleccionará el campo plataforma para continuar filtrando
El rango de valores del campo se puede enumerar y no hay una base alta. Por ejemplo, el rango de valores del campo de plataforma está en ios, android y web, lo que se ajusta a las características de selección del campo de etiqueta.
En el ejemplo anterior, el campo de plataforma se aplicará como etiqueta y el campo medio se aplicará como campo debido a su base alta. En aplicaciones prácticas, los campos que no se pueden usar como etiquetas y deben usarse se almacenarán como campos.
Agregar nuevas reglas, ¿cómo expandir los campos?
Al igual que las bases de datos no estructuradas como mongodb, la medición en Influxdb no requiere un esquema predefinido y tiene buena escalabilidad. Al agregar un nuevo campo, solo necesita especificar el nuevo campo y el valor del campo en la declaración de escritura para completar la adición del campo.
tabla CQ
La tabla CQ almacena el resultado de la agregación de datos en tiempo real según reglas de negocio, su estructura es simple y fija, como se muestra en la siguiente figura:
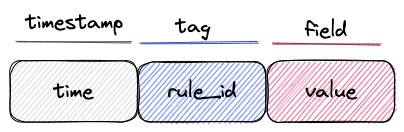
hora: hora de inicio de la ventana de cálculo
rule_id: ID de regla de calidad
valor: el resultado del cálculo de la regla de calidad en la ventana de tiempo
Hay dos fuentes de datos de la tabla CQ:
Escritura agregada programada de tablas a gran escala: se realiza mediante la capacidad básica de consulta continua proporcionada por el propio Influxdb. Confiando en esta capacidad, Influxdb puede ejecutar consultas de forma automática y periódica sobre datos en tiempo real y escribir los resultados de la consulta en la tabla CQ especificada. Actualmente, la consulta continua se ejecuta durante 99 minutos y consume menos de 30 ms.
La tarea de Flink (tema grande) agrega y escribe en tiempo real: las tareas de consumo de temas grandes realizarán cálculos de reglas de calidad dentro de la ventana de tiempo y escribirán los resultados del cálculo en la tabla CQ
Tiempo TTL de la tabla CQ: La tabla CQ es el resultado de la agregación por minutos, y su tiempo TTL se diseña según el negocio. Debido a la existencia de reglas para los tipos de índice de volatilidad, como día a día y semana a semana, el tiempo TTL de la tabla CQ está actualmente establecido en 14 días para evitar falsas alarmas debido a la caducidad y eliminación de datos.
Nivel de agua de afluenciadb
Influxdb es el núcleo de toda la solución y garantizar la estabilidad de Influxdb es una parte muy importante. Por lo tanto, el seguimiento de Influxdb es la máxima prioridad. Después de probar la máquina real que utilizamos, el cuello de botella de escritura actual de una sola máquina es de 150 W/s y el número máximo de secuencias es de alrededor de 200 W. Exceder el valor puede provocar una disminución en el rendimiento de escritura.
Hemos tomado las siguientes medidas al respecto:
Influxdb admite la expansión horizontal. De acuerdo con los metadatos del tema y la información de monitoreo de Influxdb, si el tráfico del tema actual transportado por un determinado Influxdb o el volumen de escritura en tiempo real de Influxdb ha alcanzado el 80% del cuello de botella, el tema recién conectado se escribirá en el nuevo InfluxDB.
Monitoreo del crecimiento del número de secuencia, debido a la limitación del tiempo ttl de los datos, el número de secuencias debe cambiar periódicamente y el valor máximo debe mantenerse dentro de un rango de datos de manera estable. Sin embargo, si el campo de etiqueta no se selecciona correctamente y se selecciona un campo de base alta, el número de secuencias aumentará rápidamente. Cuando se detecta esta situación, es necesario abordar los temas relacionados de manera oportuna para garantizar la estabilidad del servicio.
O&& Situación anormal
Para garantizar la estabilidad de la nueva arquitectura DQC en tiempo real, consideramos principalmente las siguientes excepciones.
Aumento de tráfico, acumulación de mensajes.
Hay dos casos principales de aumento repentino del tráfico y acumulación de mensajes:
Crecimiento predecible en el lado comercial: habrá más situaciones de este tipo, como ciertos eventos de transmisión en vivo, aumentos repentinos de tráfico de temas relacionados, similar a la reciente transmisión en vivo de las finales de League of Legends S12.
Crecimiento impredecible del lado comercial: este tipo de situación será relativamente rara. El maestro de UP subió un determinado video y se convirtió en un éxito. Este fenómeno es impredecible.
Después de la evaluación, cuando se acumulan mensajes, la alarma en ese momento puede ser inexacta, por lo que debemos hacer todo lo posible para evitar la acumulación de mensajes.
En respuesta al crecimiento predecible, aumentaremos los recursos por adelantado para aumentar la capacidad de consumo de las tareas.
En vista de un crecimiento impredecible o cuando los mensajes se acumulan incluso si se aumentan los recursos, creemos que la tarea se está ejecutando en un estado anormal en este momento. La bajaremos y cerraremos las alarmas relevantes activadas por la tarea. Temas de alta prioridad como P0 enviará notificaciones a los usuarios para informarles de las áreas afectadas.
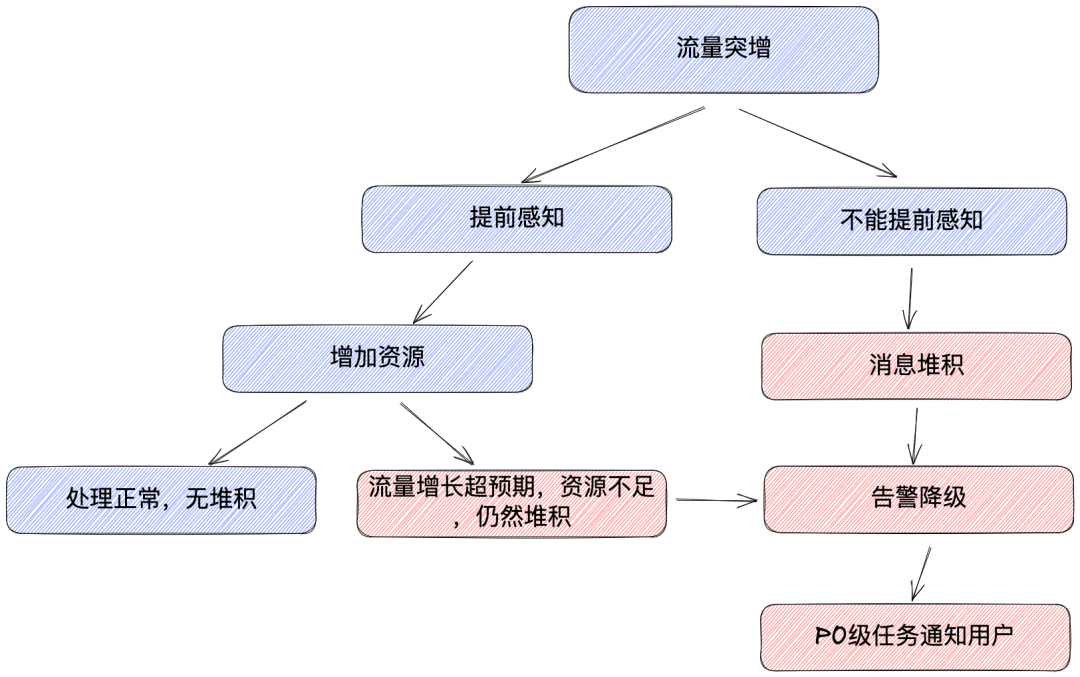
Fallo del programa
Utilice el mecanismo de punto de control de Flink para garantizar una recuperación anormal de las tareas. Pero todavía existen los siguientes problemas.
Tema pequeño y mediano:
En esta solución, los datos deben escribirse en Influxdb. Para mejorar el rendimiento, los datos recibidos en la fase de sumidero no se escribirán en el almacenamiento cada vez, sino que se colocarán primero en el búfer y luego se escribirán cuando la longitud de los datos o el tiempo de espera alcanza el umbral en Influxdb. Por lo tanto, si el programa falla, es posible que se pierdan los datos más recientes del búfer, lo que puede provocar omisiones y falsas alarmas.
En la actualidad, el umbral de tiempo que establecemos es de 10 segundos y el número de registros es 1000. Teniendo en cuenta el costo de guardar los datos en el caché en el sistema de archivos en cada punto de control, creemos que dicha pérdida es aceptable. El anuncio también explicará a los usuarios.
Gran tema:
El uso del mecanismo de punto de control de Flink puede garantizar que la tarea se pueda restaurar desde el último estado. Al escribir en Influxdb, los resultados agregados se sobrescribirán según el tiempo y la información de la etiqueta para evitar la escritura repetida de resultados.
Lo que hay que tener en cuenta es que todos los temas a los que se dirige esta solución tienen mucho tráfico y, si el tiempo de recuperación es demasiado largo, puede producirse una acumulación de datos. Es necesario considerar el esquema de procesamiento de la acumulación de datos.
Repetir consumo
Varias tareas consumen repetidamente el mismo tema, lo que genera más datos escritos en Influxdb, lo que puede generar falsas alarmas.
Nota: el group.id configurado en kafkaconsumer ya no tiene las características de un grupo de consumidores, porque kafkaconsumer usa la API subyacente para asignar TP.
solución:
Una tarea está fuertemente vinculada a un tema. Al asignar un tema a una tarea consumidora, registre la tarea y el tema en la base de datos. Si el mismo tema ya existe, el inicio fallará y se emitirá una alarma.
Combinado con la situación anormal anterior, para garantizar la estabilidad de la nueva arquitectura, tomamos principalmente las siguientes medidas en términos de operación y mantenimiento:
Monitoreo de acumulación y corte de Flink
Monitoreo del estado del clúster Influxdb
Monitoreo del número de secuencia de Influxdb
Con la ayuda de estas medidas, podemos ayudarnos a encontrar problemas y resolverlos a tiempo.
Trabajo de seguimiento de DQC en tiempo real
ingeniería
Aunque la nueva solución ya se lanzó e implementó, debido a que la nueva estructura es un poco más compleja que antes, todavía carece de ingeniería automática. Los desarrolladores trasplantan manualmente las reglas DQC existentes, y la posterior adición de reglas también requiere la participación de los desarrolladores.
Por otro lado, la garantía jerárquica es también un punto de partida de nuestra ingeniería. Los temas del nivel P0 necesitan nuestra protección prioritaria bajo cualquier circunstancia. Los temas de P0 y P1 no se fusionarán ni consumirán en una tarea. Si el inicio de la tarea P0 falla, de acuerdo con la información de excepción de falla, optará por detener una tarea de nivel P1 en ejecución, liberar recursos y usarlos para Inicie la tarea P0 primero. Cuando se detiene la tarea P1, se enviará una alarma al usuario y al personal de operación y mantenimiento para juzgar manualmente si se deben aumentar los recursos de la cola.
En la siguiente etapa, continuaremos haciendo esfuerzos en ingeniería automática y garantías jerárquicas para presentar una mejor experiencia de usuario a los usuarios.
Gestión de tareas de Flink
Ahora que la reducción de costos y la mejora de la eficiencia son la corriente principal, confiar en los diseños dinámicos de temas y reglas dinámicas puede ahorrar una gran cantidad de consumo de recursos del clúster, pero todavía hay espacio para la optimización, es decir, una gestión más refinada de múltiples tareas de Flink. Por ejemplo, en la solución dinámica de temas, ¿se debe agregar un tema dinámicamente a una tarea existente o se debe iniciar una nueva tarea para su consumo? Esto debe juzgarse en conjunto con la carga actual de la tarea.
También existe el problema del cuello de botella del procesamiento independiente de Influxdb. En nuestro plan, Influxdb se puede expandir horizontalmente. Cuando se inicia la tarea de Flink, debe combinar la carga del clúster de Influxdb y la información de la tarea actual para seleccionar el nodo de Influxdb óptimo para escribir datos. .
Efecto sobre el flujo normal
El seguimiento de la calidad de los temas no debería afectar las tareas normales en línea. Actualmente, la cola utilizada por la tarea de calidad todavía está mezclada con otras tareas, lo que puede provocar competencia de recursos, ocupar recursos de la máquina y afectar otras tareas en la máquina, etc., y se ajustará de acuerdo con la planificación de recursos en el futuro.
Si este artículo te resulta útil, ¡no olvides darle "Me gusta", "Me gusta" y "Favorito" tres veces!


La peor era de Internet puede estar aquí
Estoy estudiando en la universidad de Bilibili, especializándome en big data.
¿Qué estamos aprendiendo cuando aprendemos Flink?
193 artículos golpearon violentamente a Flink, debes prestar atención a esta colección
¿Qué estamos aprendiendo cuando aprendemos Spark?
¡Entre todos los módulos de Spark, me gustaría llamar a SparkSQL el más fuerte!
Hard Gang Hive | Resumen de la entrevista de ajuste básico de 40.000 palabras
Una pequeña enciclopedia de metodologías y prácticas de gobernanza de datos
Una pequeña guía para la construcción de retratos de usuarios bajo el sistema de etiquetas.
Artículos que he escrito sobre crecimiento/entrevista/avance profesional
¿Qué estamos aprendiendo cuando aprendemos Hive? "Secuela de Hardcore Hive"