Correo electrónico del autor del artículo: [email protected] Dirección: Huizhou, Guangdong
▲ El programa de este capítulo
⚪ Flume para dominar proyectos de tráfico de sitios web—>Conectividad Kafka;
⚪ Dominar la construcción del sistema empresarial en tiempo real de proyectos de tráfico de sitios web;
1. Canal—>Conexión Kafka
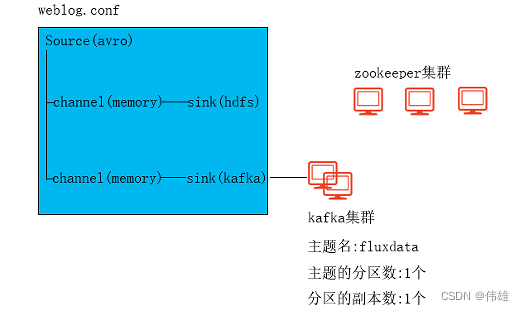
1. Pasos de implementación
1. Inicie tres servidores.
2. Inicie el clúster Zookeeper.
Instrucciones de ejecución:
sh /home/software/zookeeper-3.4.8/bin/zkServer.sh inicio
3. Inicie el clúster Kafka.
4. Crea un tema de Kafka.
Instrucciones de ejecución:
sh kafka-topics.sh --create --zookeeper hadoop01:2181
--factor de replicación 1 --particiones 1 --datos de flujo de temas
5. Inicie Hadoop.
6. Configure el canal e inícielo.
En el directorio de datos de Flume, ejecute el siguiente comando:
../bin/flume-agent -n a1 -c ./ -f ./weblog.conf
-Dflume.root.logger = INFORMACIÓN, consola
Un ejemplo del archivo de configuración weblog.conf es el siguiente:
a1.fuentes = r1