Aprendizaje profundo desde cero en C++ moderno: funciones de costos

1. Descripción
En el aprendizaje automático, normalmente modelamos problemas como funciones. Por tanto, gran parte de nuestro trabajo consiste en encontrar formas de aproximar funciones utilizando modelos conocidos. En este caso, la función de costos juega un papel central.
Esta historia es una continuación de nuestra discusión anterior sobre convoluciones . Hoy presentaremos el concepto de funciones de costos, mostraremos ejemplos comunes y aprenderemos a codificarlas y trazarlas. Como siempre, C++ puro y Eigen desde cero.
2. Acerca de esta serie
En esta serie , aprenderemos a codificar algoritmos de aprendizaje profundo imprescindibles, como convoluciones, retropropagación, funciones de activación, optimizadores, redes neuronales profundas y más, utilizando únicamente C++ simple y moderno.

La historia es: Función de costo en C++
Aprendizaje profundo desde cero en C++ moderno [3/8]: Funciones de activación
Aprendizaje profundo desde cero en C++ moderno: [4/8] Descenso de gradiente
Aprendizaje profundo desde cero en C++ moderno: [5/8] Convolución
...y más próximamente.
3. Modelado en aprendizaje automático
Como ingenieros de IA, solemos definir cada tarea o problema como una función.
Por ejemplo, si estamos desarrollando un sistema de reconocimiento facial, nuestro primer paso es definir el problema como una función que asigna imágenes de entrada a identificadores:

Para un sistema de diagnóstico médico, podemos definir una función para asignar síntomas a diagnósticos:

Podemos escribir un modelo para proporcionar una imagen dada una secuencia de palabras:
Es una lista interminable. Usar funciones para representar tareas o problemas es una forma simplificada de implementar sistemas de aprendizaje automático.
La pregunta frecuente es: ¿cómo se sabe la fórmula F() ?
4. Funciones aproximadas
De hecho, no es factible definir F(X) usando una fórmula o secuencia de reglas (algún día explicaré por qué).
En general, en lugar de encontrar o definir la función correcta F(X), intentamos encontrar una aproximación de F(X) . Llamemos a esta aproximación mediante la función de hipótesis , o simplemente H(X).
A primera vista, esto no tiene sentido: si necesitamos encontrar una función aproximada H(X ), ¿por qué no intentamos encontrar F(X) directamente ?
La respuesta es: conocemos H(X). Aunque sabemos muy poco sobre F(X), sabemos casi todo sobre H(X) : su fórmula, parámetros, etc. Lo único que no sabemos sobre H(X) son los valores de sus parámetros.
De hecho, la principal preocupación del aprendizaje automático es encontrar formas de determinar los valores de parámetros apropiados para un problema y unos datos determinados. Veamos cómo podemos implementarlo.
En terminología de aprendizaje automático, H (X) se conoce como una " aproximación de F(X) ". La existencia de H(X) está cubierta por el teorema de aproximación general .
5. Función de costos y teorema de aproximación universal
Considere una situación en la que conocemos el valor de la entrada y la salida correspondiente, pero no conocemos la fórmula. Por ejemplo, sabemos que si la entrada es, entonces el resultado es.XY = F(X)F(X)X = 1.0F(1.0)Y = 2.0
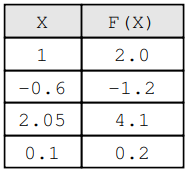
4 Mapeo de X y F(X)
Ahora, considere que tenemos una función conocida y queremos saber si es una buena aproximación de . Por lo tanto, calculamos y encontramos el .H(X)H(X)F(X)T = H(1.0)T = 1.9
¿Qué tan malo es este valor, ya que sabemos cuál es el valor real?T = 1.9Y = 2.0X = 1.0
La métrica utilizada para cuantificar el costo de la diferencia entre y se llama función de costo .YT
Tenga en cuenta que Y es el valor esperado y T es el valor real que adivinamos
H(X)
El concepto de función de costos está en el corazón del aprendizaje automático. Tomemos como ejemplo la función de costos más común.
6. Error cuadrático medio
La función de costos más famosa es el error cuadrático medio :
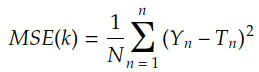
donde Ti está dada por la convolución de Xi con el núcleo k :
![]()
Hablamos de la convolución en una historia anterior.
Tenga en cuenta que tenemos n pares ( Yn , Tn), cada uno de los cuales es una combinación del valor esperado Yi y el valor real Tn . Por ejemplo:
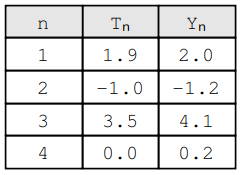
Por lo tanto, el MSE se evalúa de la siguiente manera:
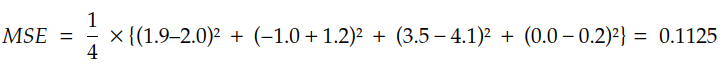
Podemos escribir la primera versión de MSE de la siguiente manera:
auto MSE = [](const std::vector<double> &Y_true, const std::vector<double> &Y_pred) {
if (Y_true.empty()) throw std::invalid_argument("Y_true cannot be empty.");
if (Y_true.size() != Y_pred.size()) throw std::invalid_argument("Y_true and Y_pred sizes do not match.");
auto quadratic = [](const double a, const double b) {
double result = a - b;
return result * result;
};
const int N = Y_true.size();
double acc = std::inner_product(Y_true.begin(), Y_true.end(), Y_pred.begin(), 0.0, std::plus<>(), quadratic);
double result = acc / N;
return result;
};Ahora que sabemos cómo calcular MSE, veamos cómo usarlo para aproximar funciones.
7. Utilice MSE para encontrar la intuición de los mejores parámetros.
Supongamos que tenemos un mapa F(X) generado sintéticamente:
F(X) = 2*X + N(0, 0.1)donde N(0, 0,1) representa valores aleatorios extraídos de una distribución normal con media = 0 y desviación estándar = 0,1. Podemos generar datos de muestra con:
#include <random>
std::default_random_engine dre(time(0));
std::normal_distribution<double> gaussian_dist(0., 0.1);
std::uniform_real_distribution<double> uniform_dist(0., 1.);
std::vector<std::pair<double, double>> sample(90);
std::generate(sample.begin(), sample.end(), [&gaussian_dist, &uniform_dist]() {
double x = uniform_dist(dre);
double noise = gaussian_dist(dre);
double y = 2. * x + noise;
return std::make_pair(x, y);
});Si trazamos este ejemplo usando cualquier software de hoja de cálculo, obtendremos algo como esto:
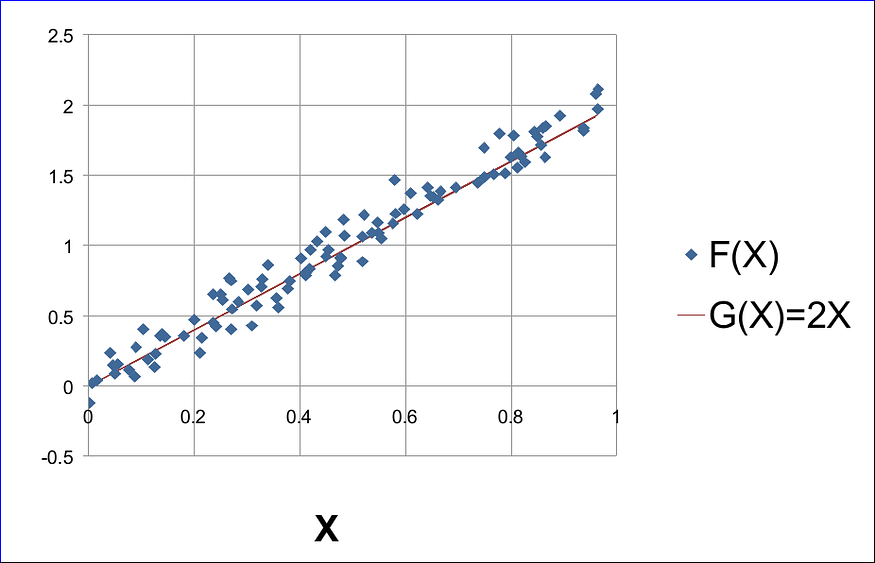
Tenga en cuenta que conocemos las fórmulas para G(X) y F(X). En la vida real, sin embargo, estas funciones generadoras son un secreto no contado del fenómeno subyacente. Aquí, en nuestro ejemplo, solo los conocemos porque estamos generando datos sintéticos para ayudarnos a comprender mejor.
En la vida real, todo lo que sabemos es la suposición de que una función hipotética H(X) definida por H(X) = kX podría ser una buena aproximación de F(X) . Por supuesto, todavía no conocemos el valor de k .
Veamos cómo usar MSE para encontrar el valor apropiado de k . De hecho, es tan simple como trazar el MSE para un rango de k diferentes:
std::vector<std::pair<double, double>> measures;
double smallest_mse = 1'000'000'000.;
double best_k = -1;
double step = 0.1;
for (double k = 0.; k < 4.1; k += step) {
std::vector<double> ts(sample.size());
std::transform(sample.begin(), sample.end(), ts.begin(), [k](const auto &pair) {
return pair.first * k;
});
double mse = MSE(ys, ts);
if (mse < smallest_mse) {
smallest_mse = mse;
best_k = k;
}
measures.push_back(std::make_pair(k, mse));
}
std::cout << "best k was " << best_k << " for a MSE of " << smallest_mse << "\n";Muchas veces, este programa genera algo como esto:
best k was 2.1 for a MSE of 0.00828671
Si trazamos MSE(k) con k, podemos ver un hecho muy interesante:
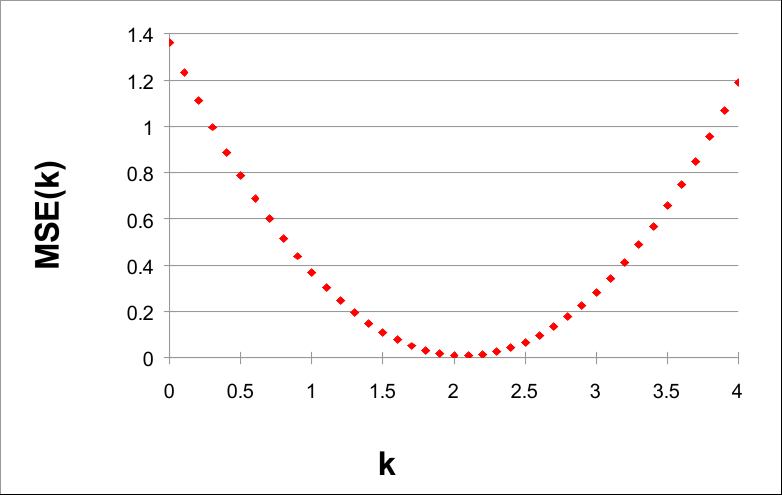
k de 0 a 4 en pasos de 0,1
Tenga en cuenta que el valor de MSE(k) es más pequeño alrededor de k = 2. De hecho, 2 es el parámetro de la función genérica G(X) = 2X .
Dados los datos y utilizando un tamaño de paso de 0,1, se puede encontrar un pequeño valor de MSE(k) cuando k = 2,1 . Esto muestra que H(X) = 2,1X es una buena aproximación de F(X) . De hecho, si trazamos F(X), G(X) y H (X), tenemos:
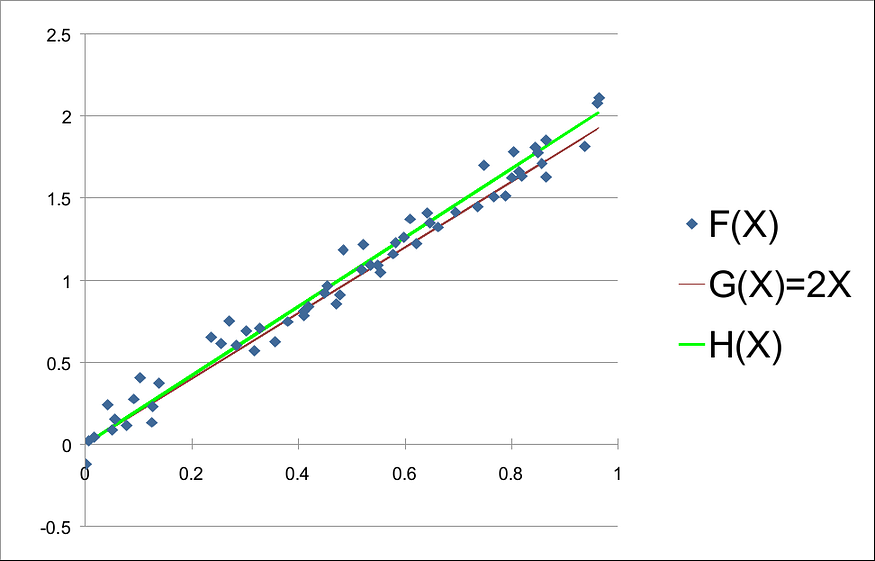
Del gráfico anterior podemos darnos cuenta de que H(X ) en realidad se aproxima a F (X). Sin embargo, podemos intentar utilizar tamaños de paso más pequeños, como 0,01 o 0,001, para encontrar una mejor aproximación.
El código se puede encontrar en este repositorio.
8. Superficie de costos
La curva de MSE(k) multiplicada por k es un ejemplo unidimensional de superficie de costos .
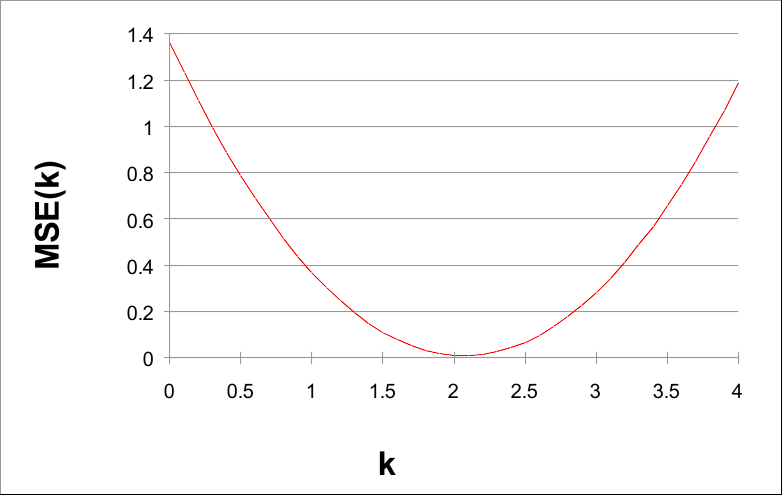
Lo que muestra el ejemplo anterior es que podemos usar el valor mínimo de la superficie de costo para encontrar el valor de mejor ajuste para el parámetro k .
Este ejemplo describe el paradigma más importante del aprendizaje automático: la aproximación de funciones mediante la minimización de funciones de costos .
La figura anterior muestra una superficie de costos unidimensional, es decir, una curva de costos para un k unidimensional dado. En dos dimensiones, es decir, cuando tenemos dos k, es decir, k1 y k2 , la superficie de costos se parece más a una superficie real:
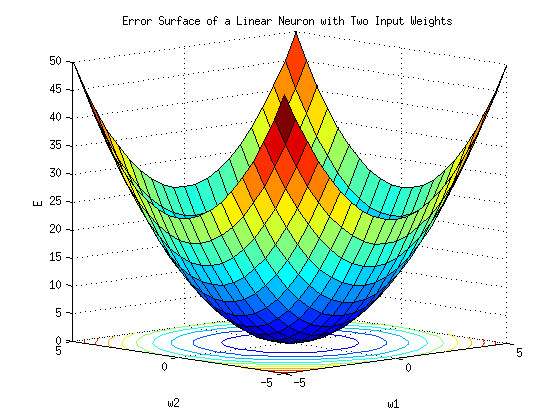
Ya sea que k sea 1D, 2D o de dimensión superior, el proceso para encontrar el mejor k-ésimo valor es el mismo: encontrar el mínimo de la curva de costos.
El valor de costo mínimo también se conoce como mínimo global .
En el espacio 1D, el proceso de encontrar el mínimo global es relativamente sencillo. Sin embargo, en dimensiones grandes, escanear todo el espacio para encontrar el mínimo puede resultar costoso desde el punto de vista computacional. En la siguiente historia, presentaremos algoritmos para realizar esta búsqueda a escala.
No solo k puede ser de alta dimensión. En problemas prácticos, la salida suele ser también de alta dimensión. Aprendamos a calcular MSE en este caso.
Nueve, MSE sobre producción de alta dimensión
En problemas del mundo real, Y y T son vectores o matrices. Veamos cómo manejar esos datos.
Si el resultado es unidimensional, la formulación anterior de MSE funcionará. Pero si el resultado es multidimensional, necesitamos cambiar un poco la fórmula. Por ejemplo:
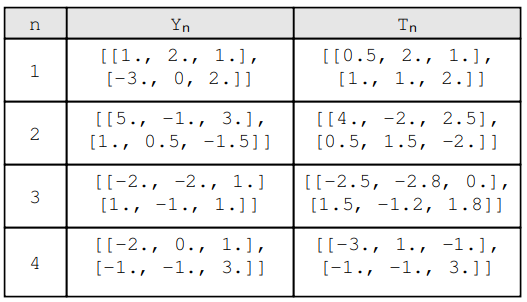
En este caso, Y n y T n no son valores escalares, sino matrices de tamaños. Antes de aplicar MSE a estos datos, debemos cambiar la fórmula de la siguiente manera:(2,3)

En esta fórmula, N es el logaritmo, R es el número de filas y C es el número de columnas de cada par. Como es habitual, podemos implementar esta versión de MSE usando lambdas:
#include <numeric>
#include <iostream>
#include <Eigen/Core>
using Eigen::MatrixXd;
int main()
{
auto MSE = [](const std::vector<MatrixXd> &Y_true, const std::vector<MatrixXd> &Y_pred)
{
if (Y_true.empty()) throw std::invalid_argument("Y_true cannot be empty.");
if (Y_true.size() != Y_pred.size()) throw std::invalid_argument("Y_true and Y_pred sizes do not match.");
const int N = Y_true.size();
const int R = Y_true[0].rows();
const int C = Y_true[0].cols();
auto quadratic = [](const MatrixXd a, const MatrixXd b)
{
MatrixXd result = a - b;
return result.cwiseProduct(result).sum();
};
double acc = std::inner_product(Y_true.begin(), Y_true.end(), Y_pred.begin(), 0.0, std::plus<>(), quadratic);
double result = acc / (N * R * C);
return result;
};
std::vector<MatrixXd> A(4, MatrixXd::Zero(2, 3));
A[0] << 1., 2., 1., -3., 0, 2.;
A[1] << 5., -1., 3., 1., 0.5, -1.5;
A[2] << -2., -2., 1., 1., -1., 1.;
A[3] << -2., 0., 1., -1., -1., 3.;
std::vector<MatrixXd> B(4, MatrixXd::Zero(2, 3));
B[0] << 0.5, 2., 1., 1., 1., 2.;
B[1] << 4., -2., 2.5, 0.5, 1.5, -2.;
B[2] << -2.5, -2.8, 0., 1.5, -1.2, 1.8;
B[3] << -3., 1., -1., -1., -1., 3.5;
std::cout << "MSE: " << MSE(A, B) << "\n";
return 0;
}
Vale la pena señalar que MSE es siempre un valor escalar independientemente de si k o Y son multidimensionales o no.
10. Otras funciones de costos
Además de MSE, en los modelos de aprendizaje profundo suelen aparecer otras funciones de costos. Los más comunes son la entropía cruzada categórica, el log cosh y la similitud del coseno.
Cubriremos estas capacidades en próximas historias, especialmente cuando presentemos la clasificación y la inferencia no lineal .
11. Conclusión y próximos pasos
Las funciones de costos son uno de los temas más importantes del aprendizaje automático. En esta historia, aprendimos cómo codificar la función de costos más comúnmente utilizada, MSE, y cómo usarla para resolver un problema unidimensional. También vimos por qué las funciones de costos son tan importantes para encontrar aproximaciones de funciones.
En la siguiente historia , aprenderemos cómo entrenar un núcleo de convolución a partir de datos utilizando una función de costo. Introduciremos el algoritmo básico para ajustar kernels y discutiremos la implementación de mecanismos de entrenamiento como épocas, condiciones de parada e hiperparámetros.