1. Descripción
En esta serie , aprenderemos a escribir algoritmos de aprendizaje profundo imprescindibles, como convoluciones, retropropagación, funciones de activación, optimizadores, redes neuronales profundas y más, usando solo C++ simple y moderno.
En esta historia, presentaremos el ajuste de núcleos de convolución 2D a los datos mediante la introducción del algoritmo de descenso de gradiente . Codificaremos todo en C++ moderno y Eigen usando convoluciones y el concepto de función de costo presentado en la historia anterior .

Esta historia es: Gradient Descent en C++, ver otras historias:
0 — Conceptos básicos de la programación moderna de aprendizaje profundo en C++
1 — Codificación de convolución 2D en C++
2 — Función de costo usando Lambda
...y más próximamente.
2. Aproximación de funciones como problema de optimización
Si ha leído nuestras charlas anteriores, ya sabe que en el aprendizaje automático la mayor parte del tiempo nos enfocamos en usar datos para encontrar aproximaciones .
Por lo general, obtenemos una aproximación de la función al encontrar los coeficientes que minimizan el valor del costo . Por tanto, nuestro problema de aproximación se transforma en un problema de optimización, donde tratamos de minimizar el valor de la función de coste.
3. Función de coste y descenso de gradiente
La función de costo calcula el costo de aproximar la función objetivo F(X ) usando la función H(X ) . Por ejemplo, si H(X) es una convolución entre la entrada X y el núcleo k , la función de costo MSE está dada por:
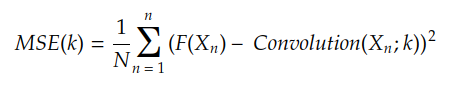
Usualmente hacemos Y n = F (Xn), el resultado es:
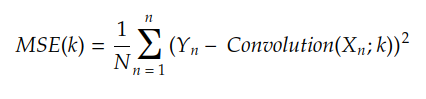
MSE es el error cuadrático medio y es la función de costo presentada en la historia anterior
Por lo tanto, nuestro objetivo es encontrar el valor del kernel k m que minimice MSE(k) . El algoritmo más básico (pero más poderoso) para encontrar k m es el descenso de gradiente.
El descenso de gradiente utiliza el gradiente de la función de costo para encontrar el costo mínimo. Para entender qué es un gradiente, hablemos de las superficies de costes.
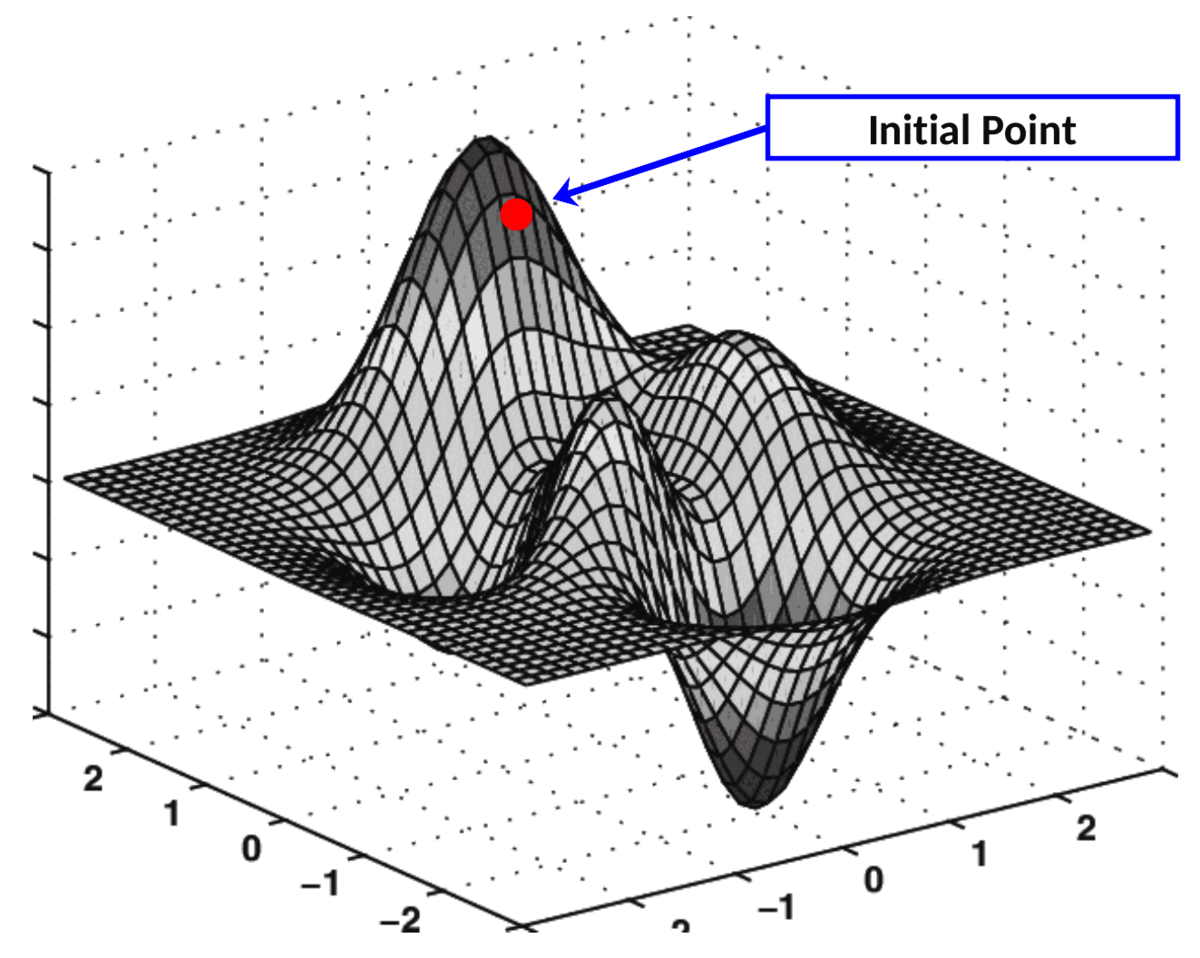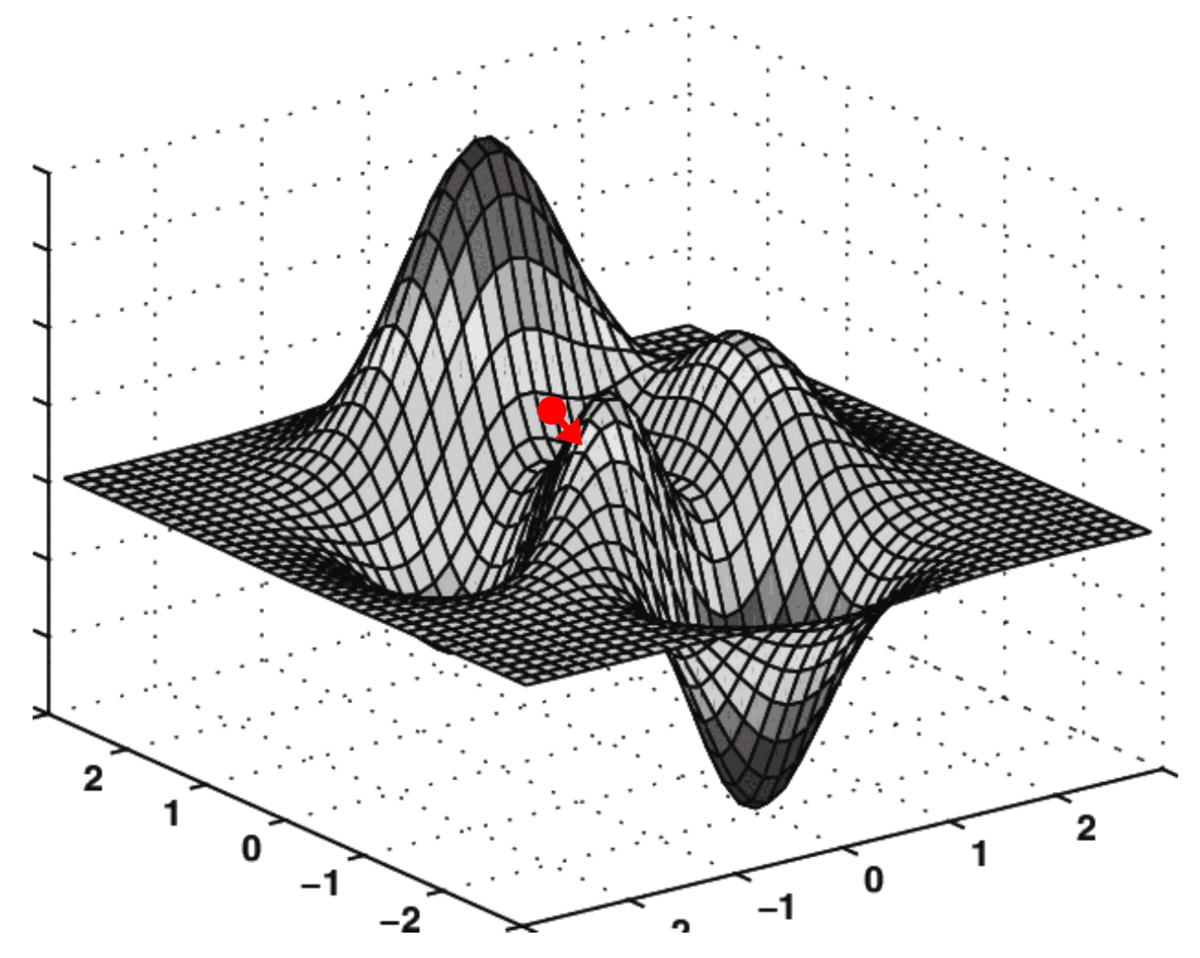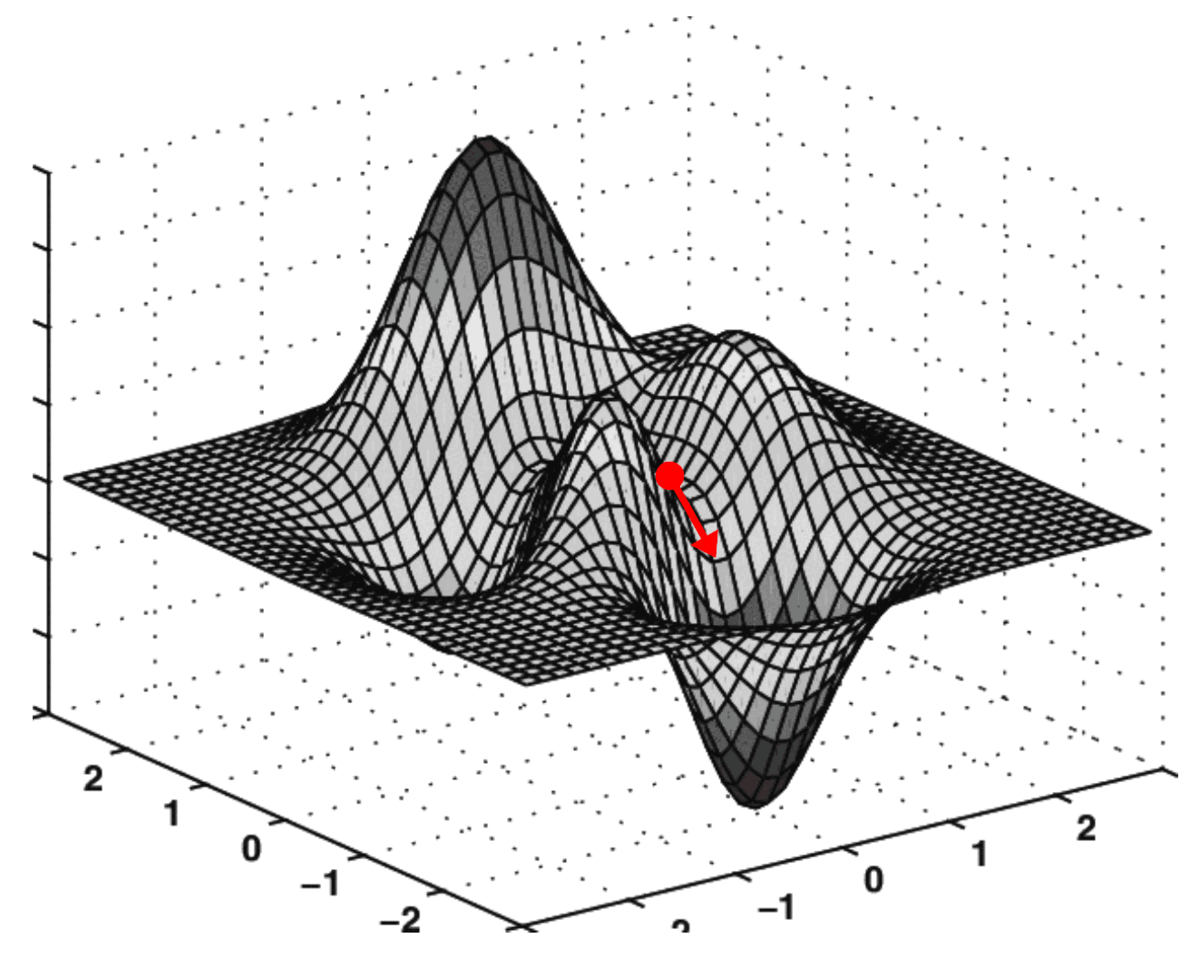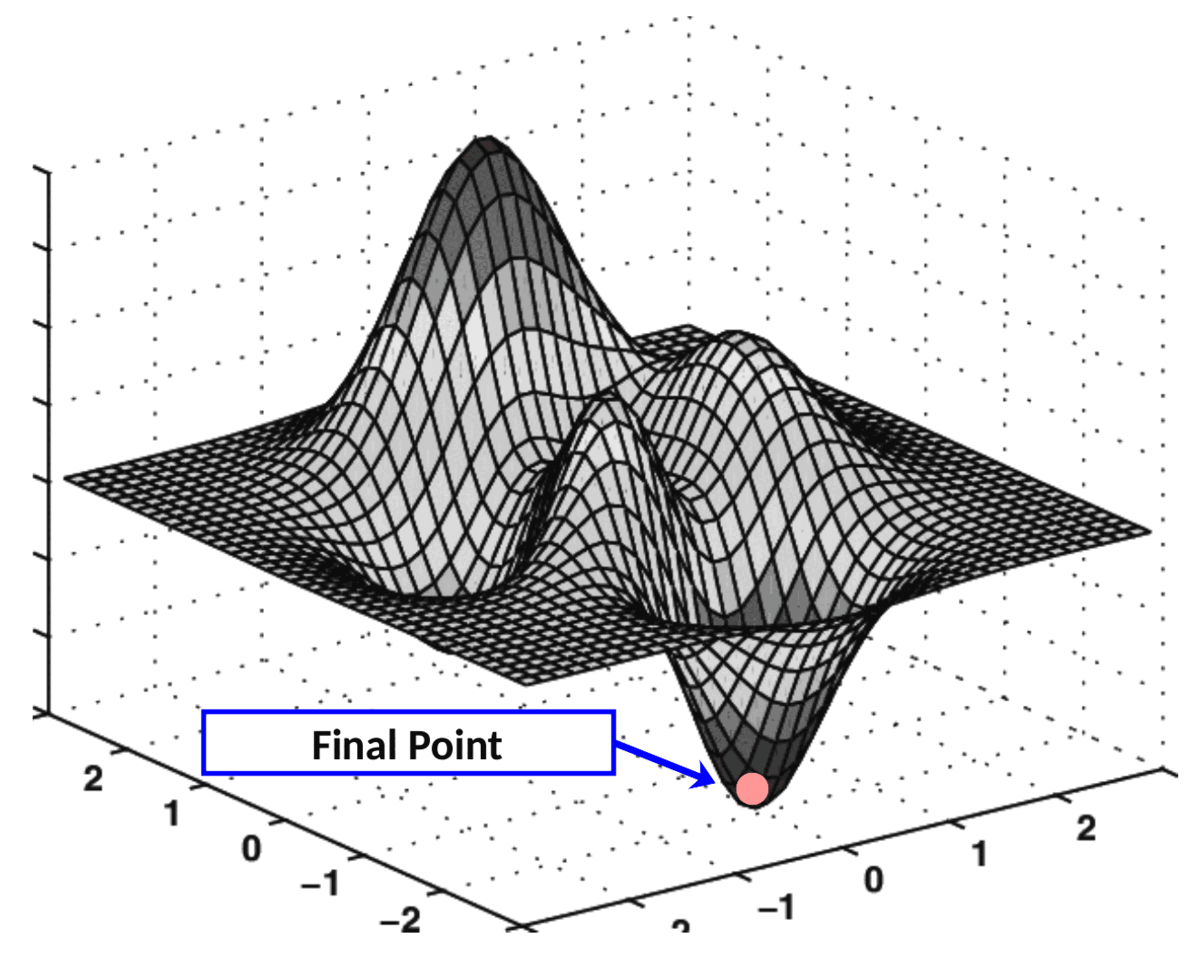
4. Dibujar la superficie de coste
Para facilitar la comprensión, supongamos temporalmente que el kernel consta de solo dos coeficientes. Si graficamos el valor de MSE(k) para cada combinación posible , terminamos con una superficie como esta:k[k00, k01][k00, k01]

En cada punto, la superficie tiene una inclinación hacia el eje 0k₀₀ y otra inclinación hacia el eje 0k₀₁ :(k00, k01, MSE(k00, k01))
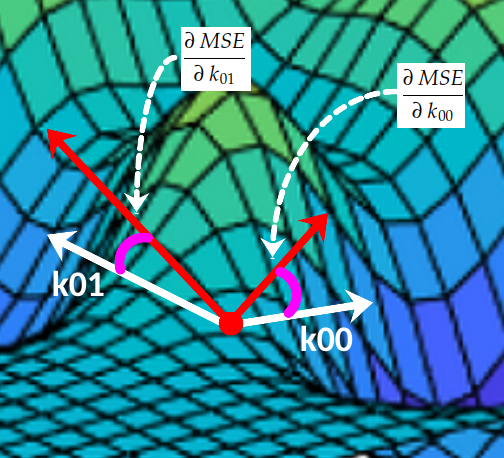
Derivada parcial
Estas dos pendientes son las derivadas parciales de la curva MSE con respecto a los ejes O k₀₀ y O k ₀₁ , respectivamente . En cálculo usamos mucho la notación ∂ para denotar derivadas parciales:
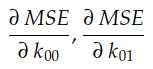
Estas dos derivadas parciales juntas constituyen el gradiente del MSE con respecto a los ejes O k₀₀ y O k₀₁ . Este gradiente se utiliza para impulsar la ejecución del algoritmo de descenso de gradiente de la siguiente manera:
Aplicaciones prácticas del descenso de gradiente
El algoritmo que realiza esta "navegación" sobre una superficie de coste se denomina descenso de gradiente.
5. Descenso de gradiente
El pseudocódigo de descenso de gradiente se describe de la siguiente manera:
gradient_descent:
initialize k, learning_rate, epoch = 1
repeat
k = k - learning_rate x ∇Cost(k)
until epoch <= max_epoch
return kEl valor de learning_rate x ∇Cost(k) a menudo se denomina actualización de ponderación . Podemos restaurar el comportamiento de descenso de gradiente con:
for each iteration:
calculate the weight update
subtract it from the parameter kComo sugiere el nombre, Cost(k) es la función de costo para la configuración k . El propósito del descenso de gradiente es encontrar el valor de k que minimiza el costo (k) .
learning_rate suele ser un escalar como 0.1, 0.01, 0.001 o algo así. Este valor controla el tamaño del paso durante la optimización.
El algoritmo repite max_epoch veces. A veces, detenemos el algoritmo antes, es decir, incluso si epoch < max_epoch , en caso de que Cost(k) sea demasiado pequeño.
Por lo general, nos referimos a parámetros como learning_rate y max_epoch con los nombres de hiperparámetros .
Para implementar el descenso de gradiente, lo último que necesitamos saber es cómo calcular el gradiente de C(k) . Afortunadamente, en el caso de que la función de costo sea MSE, encontrar ∇Cost(k) es trivial, como se mencionó anteriormente.
6. Encuentra el gradiente MSE
Hasta ahora hemos visto que las componentes del gradiente son las pendientes de la superficie de costo para cada eje 0 k ij . También vemos que el gradiente de MSE ( k ) con respecto al coeficiente j- de cada i , kernel k viene dado por:
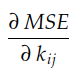
Recordemos que MSE(k) viene dado por:
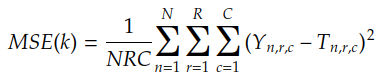
donde n es el índice de cada par ( Y n, T n) y r & c son los índices de los coeficientes de la matriz de salida:
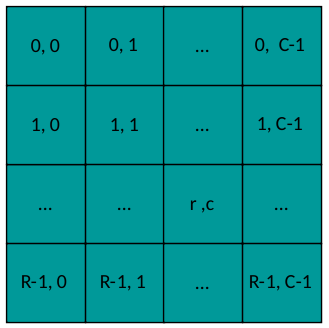
diseño de salida
Usando la regla de la cadena y la regla de combinación lineal, podemos encontrar el gradiente MSE de la siguiente manera:
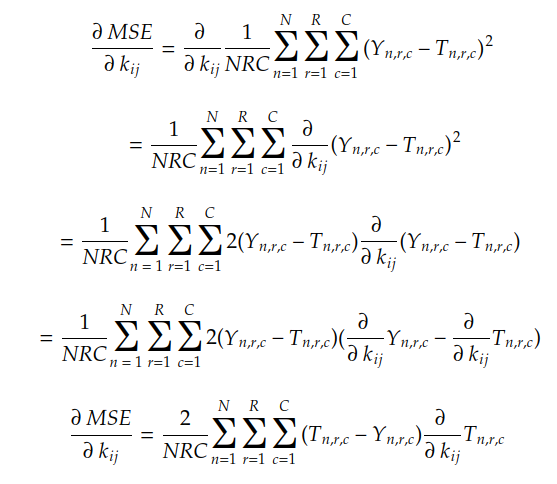
Como se conocen los valores de N , R , C , Y n y T n, lo único que necesitamos calcular es la derivada parcial de cada coeficiente en T n con respecto al coeficiente kij . En el caso de convolución con relleno P, esta derivada viene dada por:
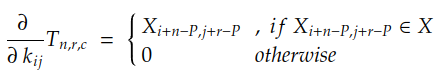
Si desarrollamos la suma de r y c , podemos encontrar que el gradiente viene dado por:
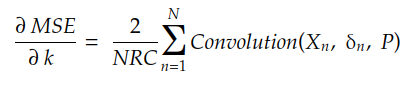
donde δn es la matriz:
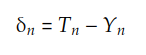
El siguiente código hace esto:
auto gradient = [](const std::vector<Matrix> &xs, std::vector<Matrix> &ys, std::vector<Matrix> &ts, const int padding)
{
const int N = xs.size();
const int R = xs[0].rows();
const int C = xs[0].cols();
const int result_rows = xs[0].rows() - ys[0].rows() + 2 * padding + 1;
const int result_cols = xs[0].cols() - ys[0].cols() + 2 * padding + 1;
Matrix result = Matrix::Zero(result_rows, result_cols);
for (int n = 0; n < N; ++n) {
const auto &X = xs[n];
const auto &Y = ys[n];
const auto &T = ts[n];
Matrix delta = T - Y;
Matrix update = Convolution2D(X, delta, padding);
result = result + update;
}
result *= 2.0/(R * C);
return result;
};Ahora que sabemos cómo obtener gradientes, implementemos el algoritmo de descenso de gradiente.
7. Descenso de gradiente de codificación
Finalmente, nuestro código de descenso de gradiente está aquí:
auto gradient_descent = [](Matrix &kernel, Dataset &dataset, const double learning_rate, const int MAX_EPOCHS)
{
std::vector<double> losses; losses.reserve(MAX_EPOCHS);
const int padding = kernel.rows() / 2;
const int N = dataset.size();
std::vector<Matrix> xs; xs.reserve(N);
std::vector<Matrix> ys; ys.reserve(N);
std::vector<Matrix> ts; ts.reserve(N);
int epoch = 0;
while (epoch < MAX_EPOCHS)
{
xs.clear(); ys.clear(); ts.clear();
for (auto &instance : dataset) {
const auto & X = instance.first;
const auto & Y = instance.second;
const auto T = Convolution2D(X, kernel, padding);
xs.push_back(X);
ys.push_back(Y);
ts.push_back(T);
}
losses.push_back(MSE(ys, ts));
auto grad = gradient(xs, ys, ts, padding);
auto update = grad * learning_rate;
kernel -= update;
epoch++;
}
return losses;
};Este es el código base. Podemos mejorarlo de varias formas, por ejemplo:
- usando la pérdida de cada instancia para actualizar el kernel. Esto se llama Stochastic Gradient Descent (SGD) , que es muy útil en escenarios del mundo real;
- agrupar instancias en lotes y actualizar el kernel después de cada lote, lo que se denomina Minibatch ;
- Utilice un programa de tasa de aprendizaje para reducir la tasa de aprendizaje entre épocas ;
- En esta línea podemos conectar un optimizador como Momentum , RMSProp o Adam. Hablaremos de los optimizadores en la siguiente historia;
kernel -= update; - Traiga un conjunto de validación o use alguna arquitectura de validación cruzada ;
- Reemplazo de bucles anidados con vectorización para rendimiento y uso de CPU (como se mencionó en la historia anterior);
for(auto &instance: dataset) - Agregue devoluciones de llamada y ganchos para personalizar más fácilmente nuestro ciclo de entrenamiento.
Podemos olvidarnos de estas mejoras por un momento. Ahora, la atención se centra en comprender cómo se utilizan los gradientes para actualizar los parámetros (núcleos en nuestro caso). Este es un concepto central fundamental en el aprendizaje automático actual y un factor clave para avanzar en temas más avanzados.
Pongamos esto en acción con un experimento ilustrativo para ver cómo funciona este código.
Ocho, el experimento real: reparar el detector de bordes Sobel
En la última historia, aprendimos que podemos aplicar un filtro Sobel Gx para detectar bordes verticales:
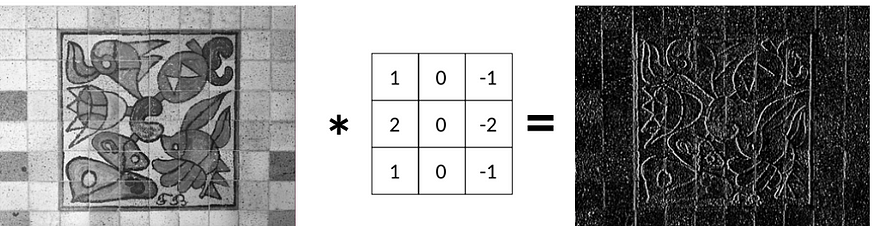
Ahora, la pregunta es: dada la imagen original y la imagen de borde, ¿hemos logrado recuperar el filtro Sobel Gx ?

En otras palabras, ¿podemos ajustar un kernel dada una entrada X y una salida esperada Y?
La respuesta es sí, usaremos el descenso de gradiente para hacer esto.
9. Cargar y preparar datos
Primero, leemos algunas imágenes de una carpeta usando OpenCV. Les aplicamos el filtro Gx y los almacenamos en pares en nuestro objeto de conjunto de datos:
auto load_dataset = [](std::string data_folder, const int padding) {
Dataset dataset;
std::vector<std::string> files;
for (const auto & entry : fs::directory_iterator(data_folder)) {
Mat image = cv::imread(data_folder + entry.path().c_str(), cv::IMREAD_GRAYSCALE);
Mat formatted_image = resize_image(image, 640, 640);
Matrix X;
cv::cv2eigen(formatted_image, X);
X /= 255.;
auto Y = Convolution2D(X, Sobel.Gx, padding);
auto pair = std::make_pair(X, Y);
dataset.push_back(pair);
}
return dataset;
};
auto dataset = load_dataset("../images/");Usamos la utilidad de ayuda .resize_image para formatear cada imagen de entrada para que quepa en una cuadrícula de 640x640

Centre cada imagen en una cuadrícula negra de 640x640 como se muestra arriba sin estirar la imagen simplemente cambiando su tamaño. cambiar el tamaño de la imagen
Usamos el filtro Gx para generar la salida real Y para cada imagen. Ahora, podemos olvidarnos de este filtro. Lo recuperaremos de los datos usando descenso de gradiente y convolución 2D.
10. Ejecuta el experimento
Al conectar todas las piezas, finalmente podemos ver el rendimiento del entrenamiento:
int main() {
const int padding = 1;
auto dataset = load_dataset("../images/", padding);
const int MAX_EPOCHS = 1000;
const double learning_rate = 0.1;
auto history = gradient_descent(kernel, dataset, learning_rate, MAX_EPOCHS);
std::cout << "Original kernel is:\n\n" << std::fixed << std::setprecision(2) << Sobel.Gx << "\n\n";
std::cout << "Trained kernel is:\n\n" << std::fixed << std::setprecision(2) << kernel << "\n\n";
plot_performance(history);
return 0;
}La siguiente secuencia ilustra el proceso de ajuste:

Al principio, el núcleo está lleno de números aleatorios. Por lo tanto, en la primera época, la imagen de salida suele ser una salida en negro.
Sin embargo, después de algunas épocas, el descenso de gradiente comienza a ajustar el kernel al mínimo global.
Finalmente, en la última época, la salida es casi igual a la verdad del suelo. En este punto, el valor de pérdida se mueve asintóticamente al valor más bajo. Comprobemos el rendimiento de pérdida a lo largo del tiempo:
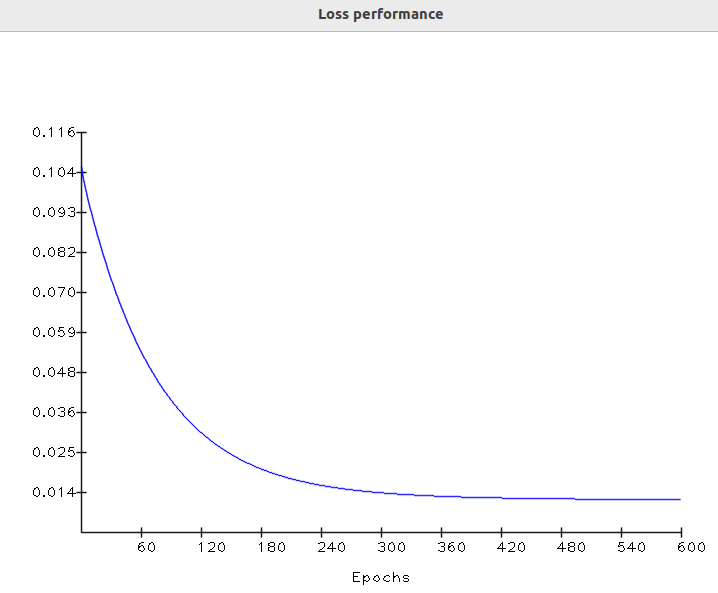
rendimiento de entrenamiento
Esta forma de curva de pérdida es muy común en el aprendizaje automático. Resulta que en la primera época los parámetros eran básicamente valores aleatorios. Esto resulta en una alta pérdida inicial:

Representación de búsqueda algorítmica en superficies de costos
En la última época, el gradiente descendente finalmente hace su trabajo, ajustando el kernel a un valor adecuado, lo que hace que la pérdida converja al mínimo.
Ahora podemos comparar el kernel aprendido con el filtro Gx Sobel original:
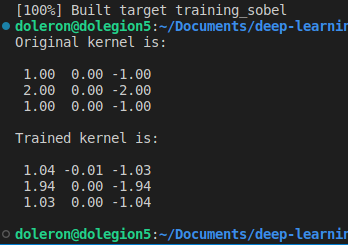
Como esperábamos, el kernel aprendido está muy cerca del kernel original. Tenga en cuenta que esta diferencia aún puede ser menor si entrenamos el núcleo durante más épocas (y usamos una tasa de aprendizaje más pequeña).
El código utilizado para entrenar este núcleo se puede encontrar en este repositorio .
11. Sobre diferenciación yautodiff
En esta historia, usamos reglas de cálculo comunes para encontrar las derivadas parciales MSE. Sin embargo, encontrar la derivada algebraica para una función de costo compleja dada puede ser un desafío en algunos casos. Afortunadamente, los marcos de aprendizaje automático modernos brindan una característica mágica llamada diferenciación automática o simplemente.autodiff
autodiffLleve un registro de cada operación aritmética básica (como la suma o la multiplicación), aplicándoles la regla de la cadena para encontrar las derivadas parciales. Por lo tanto, al usar , no necesitamos fórmulas algebraicas para calcular derivadas parciales, ni siquiera implementarlas directamente.autodiff
Dado que aquí estamos usando fórmulas de costos simples y bien conocidas, no hay necesidad de usar manualmente o incluso resolver diferenciales complejos.autodiff
Cubrir las derivadas, las derivadas parciales y la diferenciación automática con más detalle merece una nueva historia.
12. Conclusión
En esta historia, aprendimos a usar gradientes para ajustar los núcleos a los datos. Introdujimos el descenso de gradiente, que es simple, potente y la base para derivar algoritmos más complejos, como la retropropagación. También realizamos un experimento práctico utilizando gradiente descendente para recuperar el filtro Sobel de los datos.
libro de referencia
Aprendizaje automático, Mitchell
Cálculo 3, Geraldo Ávila (portugués brasileño)
Redes neuronales: fundamentos completos, Haykin
Clasificación de patrones, Duda