Comenzando con el aprendizaje profundo de Python
Capítulo 1: Introducción al aprendizaje profundo de Python: configuración del software ambiental
Capítulo 2: Introducción al aprendizaje profundo de Python: uso del conjunto de datos de procesamiento de datos
Capítulo 3: Uso de TensorBoard y TochVision para la visualización de datos
Capítulo 4: Introducción a Unet, Unet++ y Unet3+ en UNet- Familia
Capítulo 5: Producción de conjuntos de datos personales
Aprendizaje familiar Unet
Prefacio
Recientemente aprendí sobre los modelos Unet, Unet ++ y UNet3 +, investigué un poco sobre estos tres y los usé como contenido del informe en la reunión del grupo. El efecto fue bueno, así que, aunque todavía recuerdo algunos, escribí un blog. para registrarlo para facilitar el seguimiento. Revisión, tengo que decir que el modelo Unet sigue siendo muy poderoso. No es de extrañar que el modelo Unet sea muy popular ahora y valga la pena aprenderlo.
1. Modelo de red FCN totalmente convolucional
El nombre completo del modelo de red FCN es modelo de red totalmente convolucional, que es un modelo de segmentación semántica propuesto por Jonathan Long y otros en un artículo "Redes totalmente convolucionales para segmentación semántica" en 2015. Este modelo puede considerarse como el trabajo pionero del aprendizaje profundo en el campo de la segmentación semántica. La sombra del modelo FCN se puede ver en los modelos de segmentación semántica posteriores. Su estructura de modelo es muy similar a la de CNN, por lo que este modelo también puede considerarse como una actualización de la red neuronal convolucional CNN.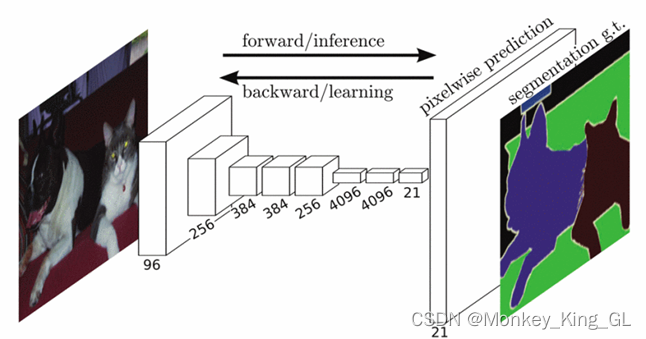
La idea central de FCN:
1. Reemplazar la capa completamente conectada de CNN con una capa convolucional , de modo que FCN pueda adaptarse a la entrada de imágenes de cualquier tamaño y también pueda hacer que la red genere un mapa de calor en lugar de una etiqueta de categoría única.
2. Agregue una operación de aumento de muestreo (deconvolución) para aumentar el muestreo del mapa de características convolucionadas al tamaño de la imagen original y luego realizar una clasificación a nivel de píxeles, convirtiendo así la tarea de segmentación en un problema de clasificación.
3. Utilice omitir conexión , es decir, agregue mapas de características de diferentes profundidades durante el proceso de muestreo ascendente. Esto no solo puede completar los datos detallados perdidos durante el proceso de reducción de resolución, sino que también retiene la información espacial de la imagen original, lo que hace que el modelo tenga mayor precisión y solidez. Es por eso que los modelos de red FCN incluyen FCN32, FCN16 y FCN8, como se muestra a continuación.

2. Modelo de codificación Unet
La propuesta del modelo FCN se ha convertido en la piedra angular del aprendizaje profundo para resolver problemas de segmentación. Sin embargo, se puede decir que la introducción del modelo Unet ha llevado el aprendizaje profundo para resolver problemas de segmentación a un nuevo nivel. El modelo Unet en el artículo "U-Net: redes convolucionales para la segmentación de imágenes biomédicas" se propuso en 2015, el mismo año que FCN, pero aún es posterior a FCN. El modelo Unet puede considerarse líder en el campo de la segmentación de imágenes médicas. También obtiene mapas de características mediante la reducción de resolución y luego el aumento de muestras para restaurar la imagen original. Sin embargo, el modelo Unet tiene muchas características únicas. Es precisamente por estas Características que tiene el modelo de red U-Net. Sigue estando de moda.
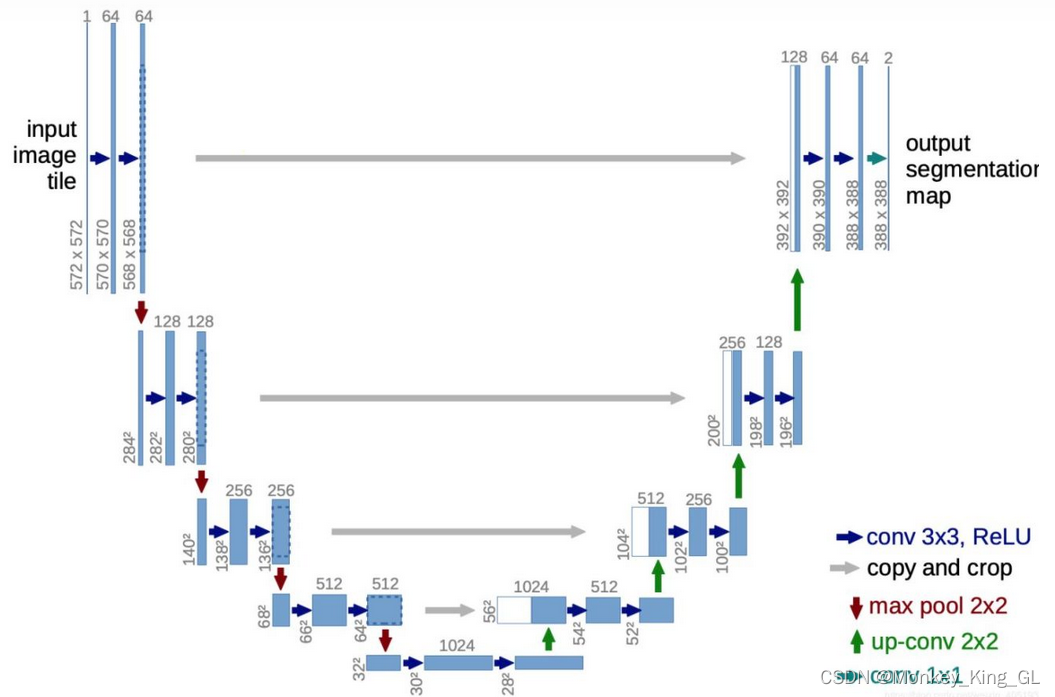
Características únicas del modelo U-Net:
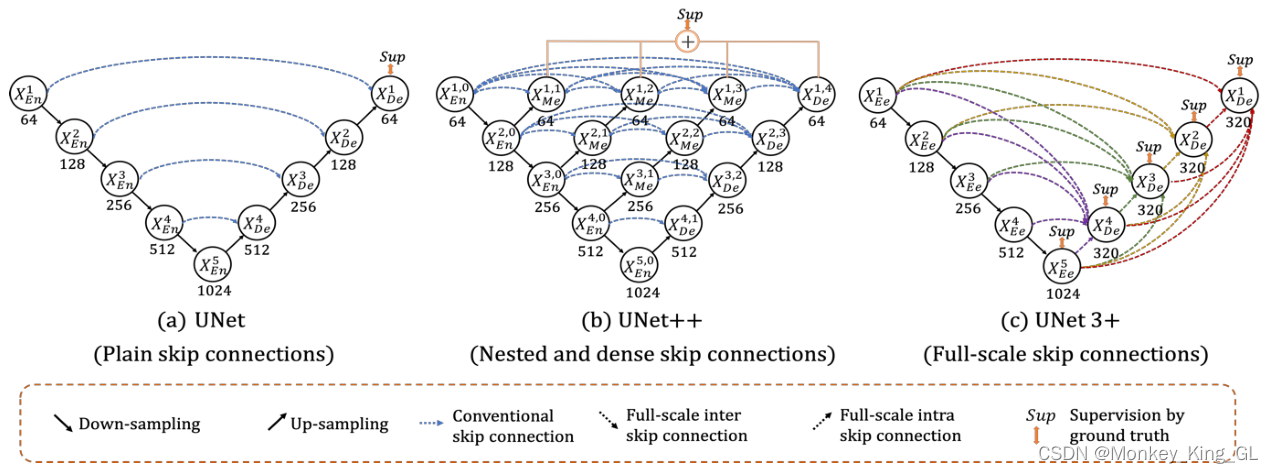
1. La estructura del modelo es completamente simétrica:
la estructura del modelo U-Net es completamente diferente de CNN y FCN: la mitad izquierda se muestra hacia abajo y la mitad derecha se muestra hacia arriba.
2. Adoptar una estructura de codificación y decodificación (Codificador-Decodificador):
1) Codificador: el codificador en su conjunto presenta una estructura que se reduce gradualmente, reduciendo continuamente la resolución del mapa de características para capturar información contextual. El codificador se divide en 4 etapas. En cada etapa, la capa de agrupación máxima se usa para reducir la resolución y luego se usan dos capas convolucionales para extraer características. El mapa de características final se reduce 16 veces; 2
) Decodificador: presentación del decodificador La expansión La estructura que es simétrica con el codificador repara gradualmente los detalles y las dimensiones espaciales del objeto segmentado para lograr un posicionamiento preciso. El decodificador se divide en 4 etapas: en cada etapa, el mapa de características de entrada se muestrea y se empalma con el mapa de características de la escala correspondiente en el codificador, y luego se utilizan dos capas convolucionales para extraer características. se amplía 16 veces
3. Conexión de omisión estilo U-Net:
la función de la conexión de omisión aquí es la misma que la de FCN, las cuales son restaurar el mapa de características mediante muestreo superior Contiene más información semántica de bajo nivel , haciendo que los resultados sean más refinados. Pero se llama conexión de salto estilo U-net para distinguirla de la conexión de salto estilo FCN. La diferencia es que la conexión de salto estilo Unet es el empalme y la fusión de las dimensiones del canal , mientras que la conexión de salto estilo FCN es solo una simple suma. de píxeles correspondientes .
El modelo U-Net se ve muy bien en todos los aspectos, pero cuando supe esto, tenía muchas preguntas en mente:
- ¿Es necesario reducir la resolución del modelo U-Net cuatro veces como el modelo del artículo para llamarlo modelo U-Net?
- ¿Es necesaria la reducción de resolución para las redes de segmentación?
- ¿El muestreo ascendente tiene que esperar hasta que finalice el muestreo descendente antes de comenzar con el muestreo ascendente?
Estas dudas finalmente fueron resueltas en un blog escrito por el proponente del modelo de red UNet++. Enlace: https://zhuanlan.zhihu.com/p/44958351.
1. ¿Es necesario reducir la resolución del modelo U-Net cuatro veces como el modelo del artículo para llamarlo modelo U-Net?
Respuesta: Personalmente creo que esta afirmación es incorrecta. El modelo U-Net debe hacer referencia a una idea y una estructura, como aplicar la estructura codificador-decodificador al modelo, la estructura del modelo es completamente simétrica y el estilo U-Net omitir conexiones. , etc., no debemos limitarnos a qué convolución usar, cuántas capas usar, cómo reducir la resolución, cuál es la tasa de aprendizaje y qué optimizador usar. Estos son parámetros relativamente intuitivos. De hecho, estos parámetros no lo son. dado en el periódico. Es el mejor, por lo que no tiene mucho sentido prestarles atención.
2. ¿Es necesaria la reducción de resolución para las redes de segmentación?
Respuesta: Primero debemos comprender que la función de la reducción de resolución es aumentar la robustez ante algunas pequeñas perturbaciones de la imagen de entrada, como la traducción, rotación, etc. de la imagen, reducir el riesgo de sobreajuste, reducir la cantidad de cálculo y aumentar el tamaño del campo receptivo. Si la imagen es pequeña, tiene un solo color, el objeto es relativamente simple y es fácil extraer características. Si reducir o no la resolución tiene poco impacto en la predicción del modelo, ¿por qué molestarse en disminuir y luego aumentar la resolución?
3. ¿El muestreo ascendente tiene que esperar hasta que se complete el muestreo descendente antes de comenzar con el muestreo ascendente?
Respuesta: Podemos entender esta pregunta de esta manera. ¿Cuál será el efecto de reducir la resolución del modelo U-Net una, dos y tres veces antes de aumentar la resolución? Modelos Unet de una, dos, tres y cuatro capas. De esta manera podremos entonces conocer la respuesta a esta pregunta.
La desventaja de Unet es que solo tiene conexiones entre las mismas capas y existe una brecha en la generación de información entre las capas superior e inferior.
3. Modelo Unet++
Como sugiere el nombre, el modelo U-net++ es una versión mejorada del modelo U-Net, que proviene del artículo "UNet++: A Nested U-Net Architecture for Medical Image Segmentation" . No solo integra las ideas estructurales del Modelo Unet, pero también resuelve las deficiencias del modelo Unet. El autor estaba pensando en ese momento, dado que el modelo Unet no necesariamente tiene que reducirse cuatro veces para ser óptimo, ¿cuántas veces se debe reducir para hacerlo bien? El autor realizó un experimento de comparación de diferentes modelos de capas (como se muestra a continuación), y el experimento muestra que la mejor estructura del modelo varía según el conjunto de datos.
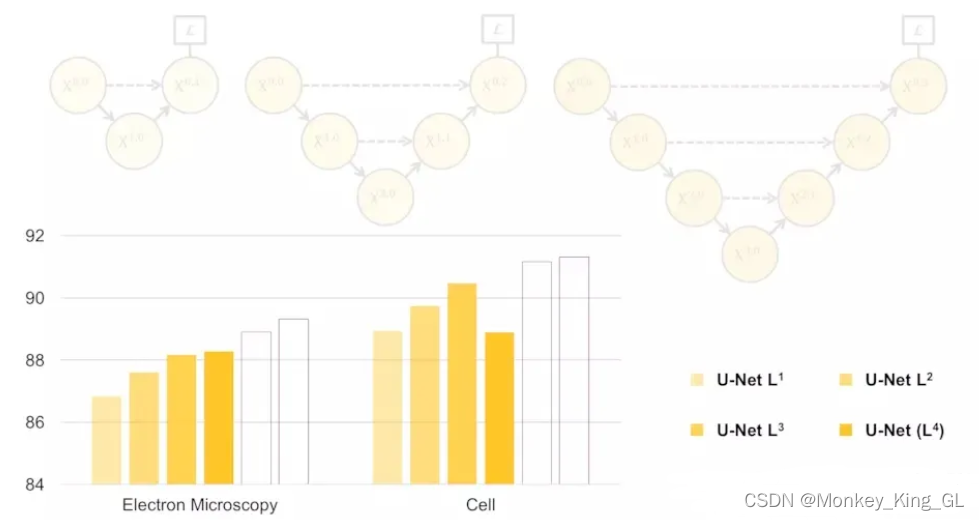 Dado que el número de tiempos de reducción de resolución del modelo no es un valor determinado, ¿necesitamos comparar el entrenamiento y las pruebas del modelo de estas diferentes capas antes de entrenar el modelo? Creo que no es necesario, de lo contrario sería demasiado problemático, podemos integrar estos modelos en un solo modelo y dejar que la red aprenda modelos de diferentes profundidades por sí misma, obteniendo así la estructura básica del modelo Unet ++.
Dado que el número de tiempos de reducción de resolución del modelo no es un valor determinado, ¿necesitamos comparar el entrenamiento y las pruebas del modelo de estas diferentes capas antes de entrenar el modelo? Creo que no es necesario, de lo contrario sería demasiado problemático, podemos integrar estos modelos en un solo modelo y dejar que la red aprenda modelos de diferentes profundidades por sí misma, obteniendo así la estructura básica del modelo Unet ++.
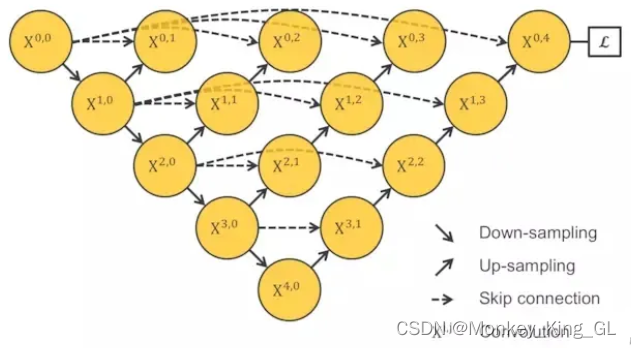
Pero en medio del modelo.X 0,1 , X 0,2 , X 0,3 , X 1,1 , X 1,2 , X 2,1 nodosDebido a que está desconectado de la función LossFunction que finalmente calcula el valor de pérdida, no se puede alcanzar la retropropagación del modelo durante el proceso de entrenamiento, lo que hace que el modelo no pueda entrenarse. Hay dos soluciones para este problema:
- Agregue conexiones cortas entre los nodos intermedios del modelo para que la retropropagación durante el entrenamiento del modelo pueda llegar a cada nodo.
- Agregue un núcleo de convolución 1x1 al nodo 0,1X== , de modo que todo el modelo es similar a la superposición de 1, 2 , 3 y 4 capas de U- Modelos netos.

Puntos de innovación de U-Net ++:
1. Agregar supervisión profunda: la supervisión profunda
consiste en agregar un núcleo de convolución 1x1 al final de cada capa y luego conectarlo a la función de pérdida LossFunction para calcular el valor de pérdida. ¿Cuáles son los beneficios de esto? ? ¿Paño de lana?
1) Haga que el modelo sea más completo y resuelva el problema de que no se puede alcanzar el modelo durante la propagación hacia atrás.
2) Haga que el modelo sea podable, porque nuestro modelo Unet ++ integra modelos Unet de diferentes capas. Durante el proceso de prueba, si el modelo es demasiado grande, afectará la eficiencia de la prueba. Sin embargo, la imagen de entrada solo se propagará hacia adelante durante el proceso de prueba, por lo que descartar la parte profunda del modelo durante la prueba de imágenes pequeñas no tendrá ningún impacto en la salida anterior. Pero en la fase de entrenamiento, debido a que hay propagación hacia adelante y hacia atrás, las partes podadas ayudarán a otras partes a actualizar los pesos. Por lo tanto, agregar operaciones de poda puede mejorar la velocidad de prueba del modelo, lo que también ha sido probado mediante experimentos.
2. Conexión de salto de escala múltiple:
puede capturar características en diferentes niveles e integrarlas mediante la superposición de características. Las características en diferentes niveles, o campos receptivos de diferentes tamaños, tienen diferentes sensibilidades para apuntar a objetos de diferentes tamaños. Por ejemplo, características con Los campos receptivos grandes pueden identificar fácilmente objetos grandes. Sin embargo, en la segmentación real, la información de borde de los objetos grandes y los objetos pequeños en sí se pierden fácilmente mediante el muestreo hacia abajo y hacia arriba de la red profunda. Si se pierde, es posible que necesite la ayuda de pequeños campos receptivos. En este momento, UNet ++ tiene campos receptivos de diferentes tamaños, por lo que el efecto es bueno.
Bueno, este modelo ha sido modificado por otros grandes para proponer el modelo U-Net3 +. La desventaja de Unet ++ es que aumenta el número de parámetros del modelo. Como se puede ver en la estructura del modelo, tiene muchos más nodos intermedios. que Unet; la segunda es que carece de la capacidad de explorar información suficiente a escala completa, es decir, la estructura del modelo de bajo nivel no agrega el contenido de mapas de características profundos. Esta es la innovación de UNet3+.
4. Modelo Unet3+
Unet3 + ha sido mejorado uno por uno según las deficiencias de Unet ++, su punto de innovación son las deficiencias de Unet ++.
4.1 Conexión de salto mejorada (conexión de salto a gran escala)
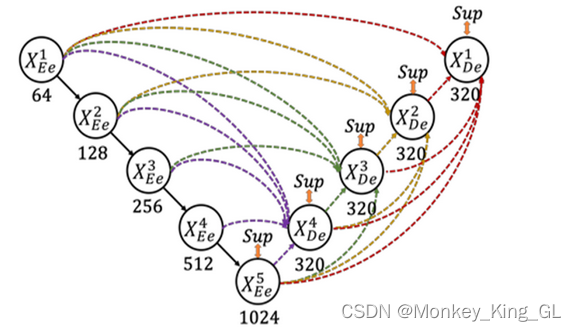
Ya sea conectando UNet simple o conectando UNet++ estrechamente anidado, carecen de la capacidad de explorar suficiente información a escala completa y no logran comprender claramente la ubicación y los límites de los órganos. Unet3+ elimina el denso bloque de convolución de Unet++ y en su lugar propone una conexión de salto de tamaño completo.Las conexiones de salto a escala completa cambian las interconexiones entre codificadores y decodificadores y las conexiones internas entre las subredes de decodificadores, lo que permite que cada capa de decodificador fusione mapas de características de pequeña y misma escala del codificador y mapas de características de gran escala del decodificador, que capturar semántica de grano fino y semántica de grano grueso a escala completa.
Por ejemplo, la siguiente figura es el proceso de generación del mapa de características X 3 De , que combina los mapas de características a pequeña escala X 1 Ee y X 2 Ee del codificador, el mapa de características a gran escala X 4 De X 5 De el decodificador y características de la misma escala Figura X 3 Ee . Sin embargo, debido a que estos mapas de características no son consistentes con el tamaño del mapa de características y el número de canales , los mapas de características se fusionan y luego se convolucionan a través de 320 núcleos de convolución 3 * 3, y finalmente el mapa de características de X 3 De se obtiene mediante la operación BN + ReLU. para lograr una fusión de funciones a gran escala. Los mapas de características de otras partes del decodificador también se obtienen de la misma forma. La fórmula específica se expresa de la siguiente manera. Entre ellos, la función C representa la operación de convolución, la función H representa el mecanismo de agregación de características (una capa de convolución + un BN + un ReLU), la función D y la función U representan operaciones de muestreo ascendente y descendente respectivamente, [] representa el empalme y la fusión de dimensiones del canal.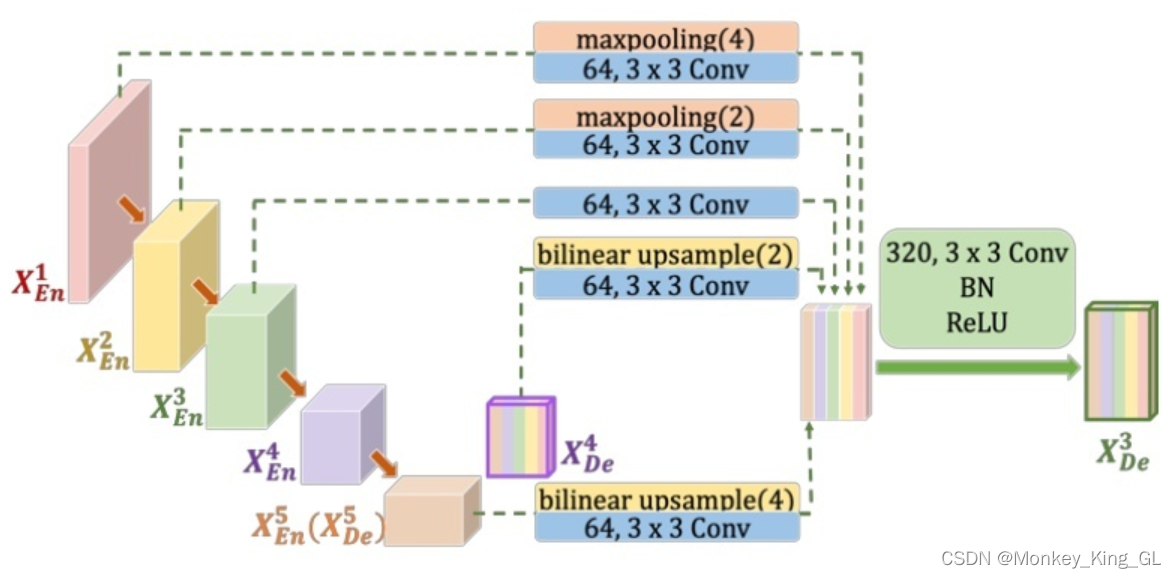
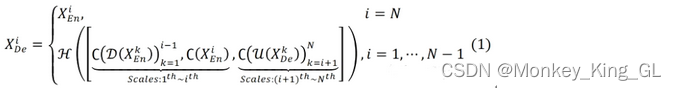
4.2 Supervisión profunda a gran escala
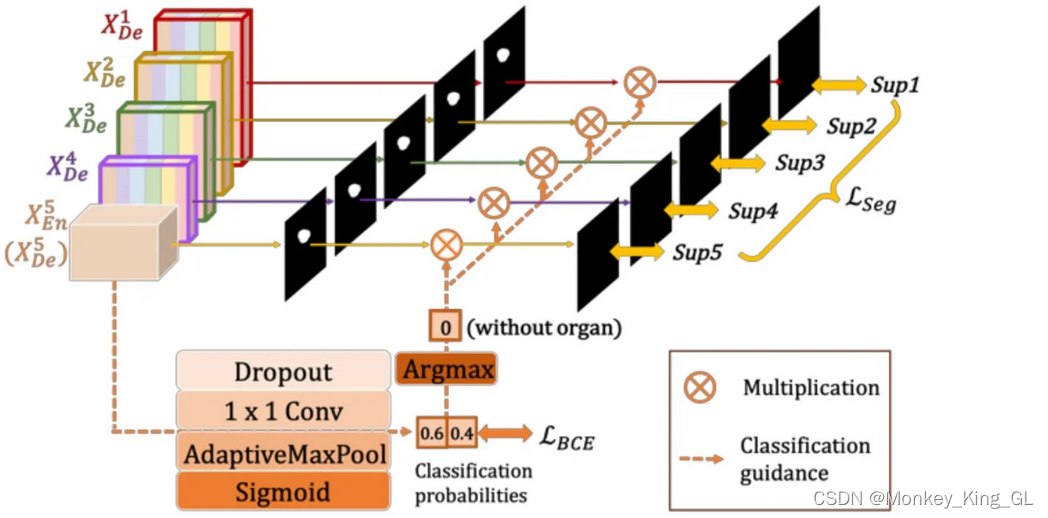
La diferencia entre la supervisión profunda a gran escala de Unet3 + y la supervisión profunda de UNet ++ radica en la ubicación de la supervisión: la primera supervisa los mapas de características generadas por el decodificador de red en cada etapa, mientras que la segunda supervisa las cuatro características en la primera. capa de la red Imágenes (tres de ellas son los mapas de características de salida de los bloques convolucionales en la conexión de salto, y una es el mapa de características finalmente generado por el decodificador). Además, en UNet3+, para lograr una supervisión profunda, la última capa de cada etapa del decodificador se introduce en una capa convolucional simple de 3×3, seguida de un muestreo ascendente bilineal y una función sigmoidea (el muestreo ascendente aquí es para acercar a resolución completa).
4.3 Módulo guiado por clasificación (CGM)
Este módulo se propuso para resolver el problema de los falsos positivos en imágenes que no son de órganos durante la segmentación de imágenes médicas (lo que significa que se ingresa una imagen sin un órgano objetivo y, después de la prueba del modelo, el resultado muestra que hay un artefacto del órgano objetivo) . Este módulo de guía de clasificación es para obtener una probabilidad de si hay un órgano objetivo después de que la capa más profunda del modelo se somete a una serie de operaciones como abandono, convolución, sigmoide, etc., y luego obtiene una salida única de {0, 1 } con la ayuda de la función Argmax.Luego guíe la salida de cada lado segmentado.
Los puntos de innovación de U-Net3+:
1. Se reduce el número de parámetros del modelo y la estructura del modelo es más simple:
aunque el modelo Unet++ incorpora más información de características que el modelo Unet, lo que hace que el modelo sea más preciso, también aumenta el número de parámetros. de la estructura de la red, lo que resulta en que el entrenamiento del modelo y las velocidades de carrera se hayan reducido mucho. UNet3+ no solo conserva las excelentes características de Unet++, sino que también elimina los nodos intermedios para reducir la cantidad de parámetros del modelo, lo que hace que la estructura del modelo sea más concisa.
2. Conexión de salto a gran escala:
la conexión de salto a gran escala cambia la interconexión entre el codificador y el decodificador y la conexión interna entre las subredes del decodificador, lo que permite que cada capa del decodificador integre información a pequeña escala del codificador y mapas de características en el misma escala, así como mapas de características a gran escala del decodificador, que capturan la semántica de grano fino y la semántica de grano grueso a escala completa.
3. Módulo de guía de clasificación:
el módulo de guía de clasificación proporciona otro objeto de referencia para el modelo. Este módulo puede evitar falsos positivos causados por datos ruidosos y sobresegmentación.
5. Resumen
 Del estudio anterior podemos saber que el rendimiento de Unet3+ es mejor que el de Unet y Unet++, pero ya sea Unet, Unet++ o Unet3+, son las conclusiones a las que llegaron los autores después de muchos experimentos, y vale la pena aprenderlas. todos tienen sus respectivos puntos brillantes. Además de estas dos deformaciones, Unet tiene muchos, muchos otros modelos de deformación, y en conjunto se denominan UNet-Family .
Del estudio anterior podemos saber que el rendimiento de Unet3+ es mejor que el de Unet y Unet++, pero ya sea Unet, Unet++ o Unet3+, son las conclusiones a las que llegaron los autores después de muchos experimentos, y vale la pena aprenderlas. todos tienen sus respectivos puntos brillantes. Además de estas dos deformaciones, Unet tiene muchos, muchos otros modelos de deformación, y en conjunto se denominan UNet-Family .
UNet es un método clásico de diseño de redes que tiene una gran cantidad de aplicaciones en tareas de segmentación de imágenes. También hay muchos métodos nuevos que mejoran sobre esta base e incorporan conceptos de diseño de red más nuevos, pero en la actualidad casi nadie ha realizado una comparación exhaustiva de estas versiones mejoradas.Dado que la misma estructura de red puede mostrar un rendimiento diferente en diferentes conjuntos de datos, en escenarios de tareas específicas, aún es necesario combinar los conjuntos de datos para elegir la red adecuada.。