Directorio de artículos
- mysql
-
- concepto basico
- índice
-
- 5. Clasificación del índice
- 6. El principio de coincidencia más a la izquierda del índice conjunto.
- 6.1 Desplazamiento del índice conjunto
- 7. Consulta de rango del índice conjunto.
- 8. ¿Cuándo es necesario o no crear un índice?
- 9. ¿Existe alguna forma de optimizar el índice?
- 10. ¿En qué circunstancias el índice dejará de ser válido?
- 11. ¿Qué conteo tiene el mejor desempeño?
- asuntos
-
- 12. ¿Cuáles son las cuatro características de los negocios?
- 13. ¿Qué tecnología utiliza el motor InnoDB para garantizar las características de las transacciones?
- 14. ¿Qué problemas causará la concurrencia de transacciones?
- 15. ¿Cuáles son los niveles de aislamiento de las transacciones?
- 16. Introduzca el registro de transacciones de MySQL.
- 17. ¿Qué es MVCC?
- 18. ¿Cómo se implementan los niveles de aislamiento de transacciones?
- 19. ¿Cómo solucionar la lectura fantasma?
- Cerrar
- registro
-
- 23. ¿Cuáles son las funciones del registro de deshacer, el registro de rehacer y el registro bin? ¿cuál es la diferencia?
- 24. ¿Por qué necesitas un grupo de buffer?
- 25. ¿Por qué se requiere una confirmación en dos fases, cómo es el proceso de confirmación y cuáles son los problemas?
- 26. Separación de lectura y escritura de MySQL, ¿cómo sincronizar el maestro y el esclavo, cómo resolver el problema del retraso de sincronización?
- optimización SQL
- Redis
-
- concepto basico
- estructura de datos
- Modelo de red de subprocesos de Redis
- Persistencia de Redis
- Diseño de caché de Redis
- Redis maestro-esclavo, clúster de corte
- combate redis
mysql
concepto basico
1. ¿Cuáles son los tres paradigmas de la base de datos?
- La primera forma normal: enfatiza la atomicidad de la columna, es decir, cada columna de la tabla de la base de datos es un elemento de datos atómicos indivisible.
- Segunda forma normal: los atributos de la entidad dependen completamente de la clave primaria.
- Tercera forma normal: cualquier atributo no clave no depende de otros atributos no clave.
2. ¿Cuál es el proceso de ejecución de MySQL?
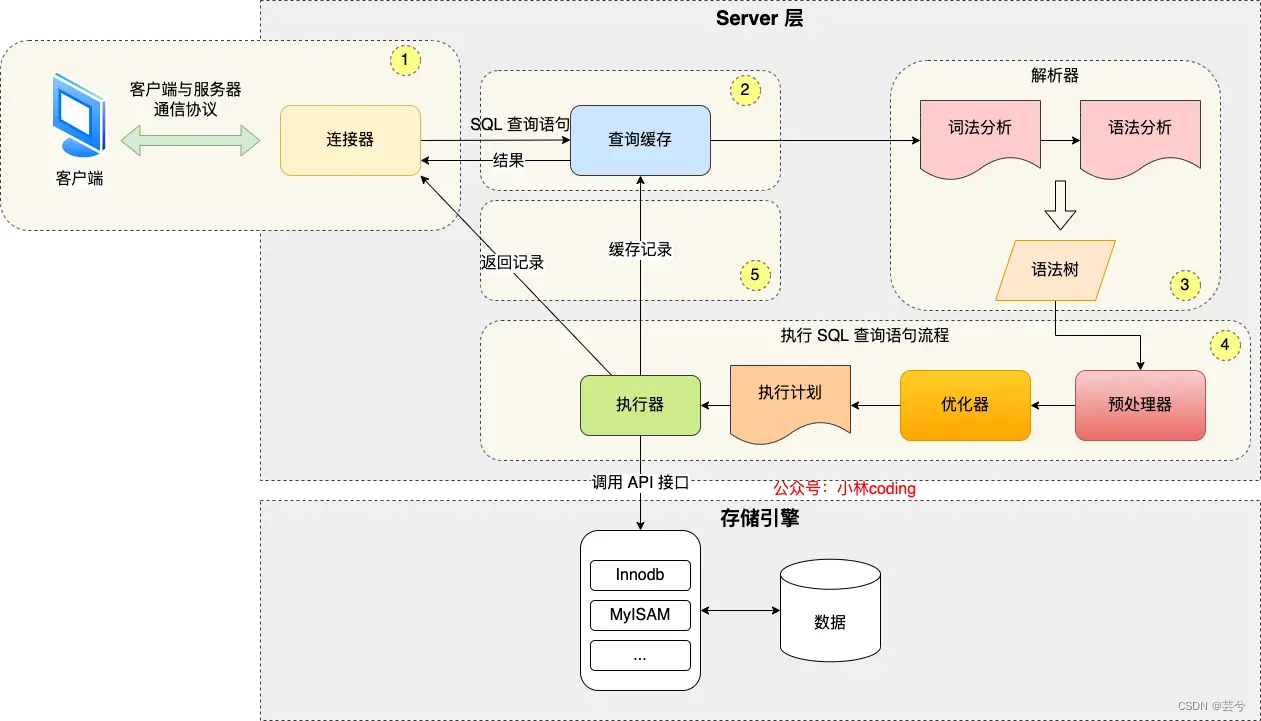
- Conéctese al conector MySQL a través de TCP. El cliente envía una solicitud de conexión al conector MySQL a través de una conexión TCP y el conector realizará la verificación de permisos y la asignación de recursos de conexión en la solicitud.
- Caché de consultas. (MySQL primero buscará los datos almacenados en caché en el caché de consultas. Los datos almacenados en caché se guardan como clave-valor y la clave es SQL, valor y resultado de la consulta SQL. Si el caché llega, MySQL no analizará la declaración de la consulta, pero devuelve directamente el valor al final del cliente). Si no se accede al caché, la ejecución continuará y, una vez completada, el resultado de la consulta se almacenará en el caché. Dado que la tasa de aciertos de caché de MySQL es relativamente baja, a partir de la versión 8.0 de MySQL, la etapa de caché de consultas se elimina directamente.
- Analizar SQL. El analizador MySQL realiza un análisis léxico de declaraciones SQL , identifica palabras clave, crea un árbol de sintaxis SQL y luego realiza un análisis gramatical para determinar si el SQL es legal.
- Ejecute SQL. El proceso de ejecución de SQL incluye
- preparar, la etapa de preprocesamiento. Principalmente completa la detección de si la tabla o campo consultado existe y reemplaza los símbolos en select * con todas las columnas de la tabla.
- optimizar, etapa de optimización. El optimizador optimiza el plan de ejecución de la declaración de consulta SQL en función del costo de la consulta.
- ejecutar, la fase de ejecución. Según el plan de ejecución generado por el optimizador, los registros se leen del motor de almacenamiento y se devuelven al cliente.
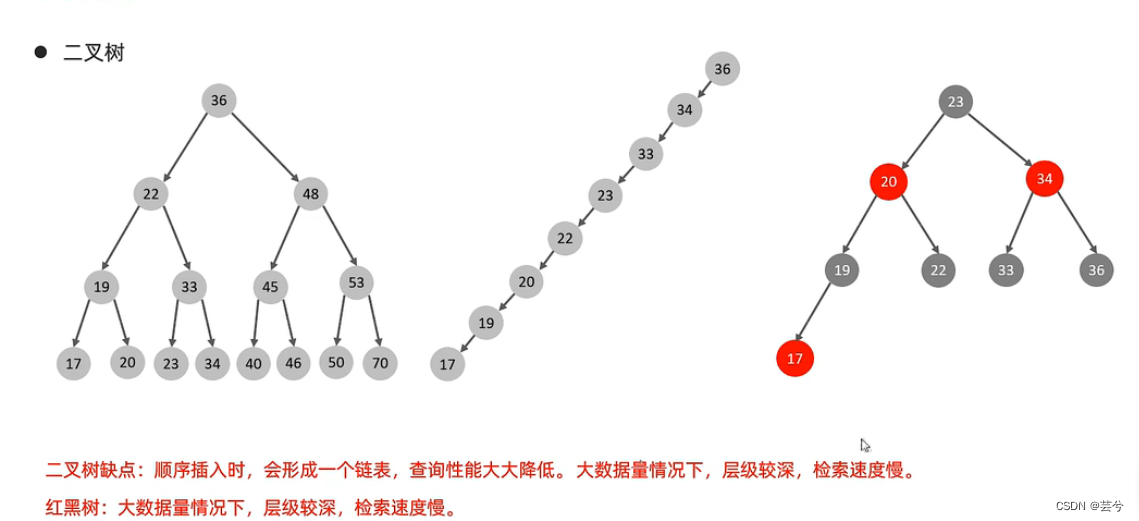
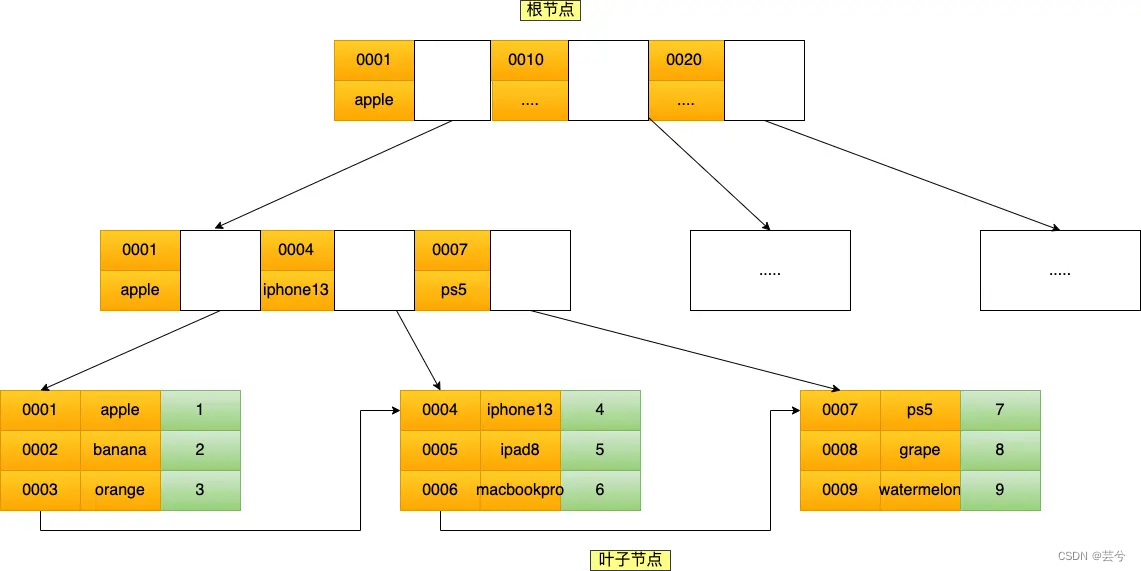
3. ¿Árbol B/B+?
Debido a que la base de datos lee datos del disco, lleva mucho tiempo. Para mejorar la eficiencia del acceso a los datos, es necesario reducir el nivel de acceso a los datos tanto como sea posible.
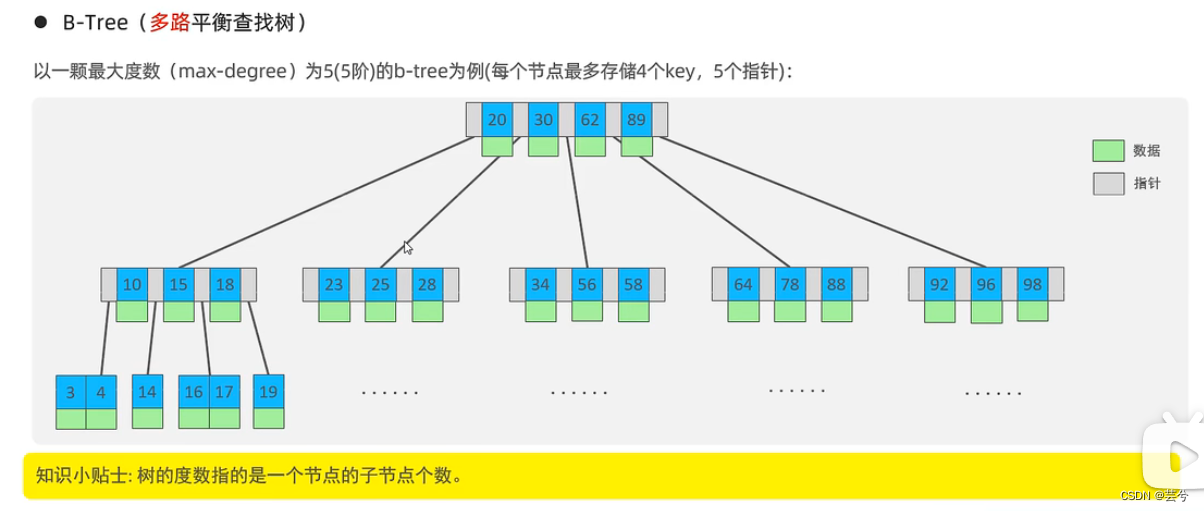
- B-Tree (árbol de búsqueda equilibrado multidireccional) es
un árbol B con un grado máximo de 5 (quinto orden), y cada nodo puede almacenar hasta 4 claves (5 rangos de datos, que constan de 4 valores de datos, por lo que cada B -tree La cantidad de datos de un nodo es 1 menos que la cantidad de punteros (ramas), 5 punteros (5 ramas).
- Árbol B+: una variante del árbol, todos los elementos aparecerán en los nodos hoja, los datos de los nodos que no son hoja solo sirven como índice y todos los nodos hoja formarán una lista enlazada unidireccional.
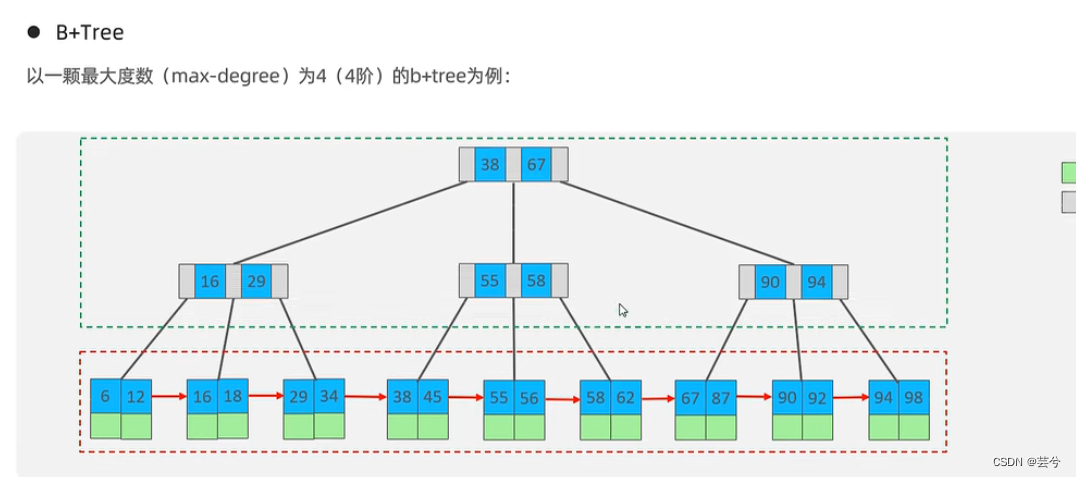
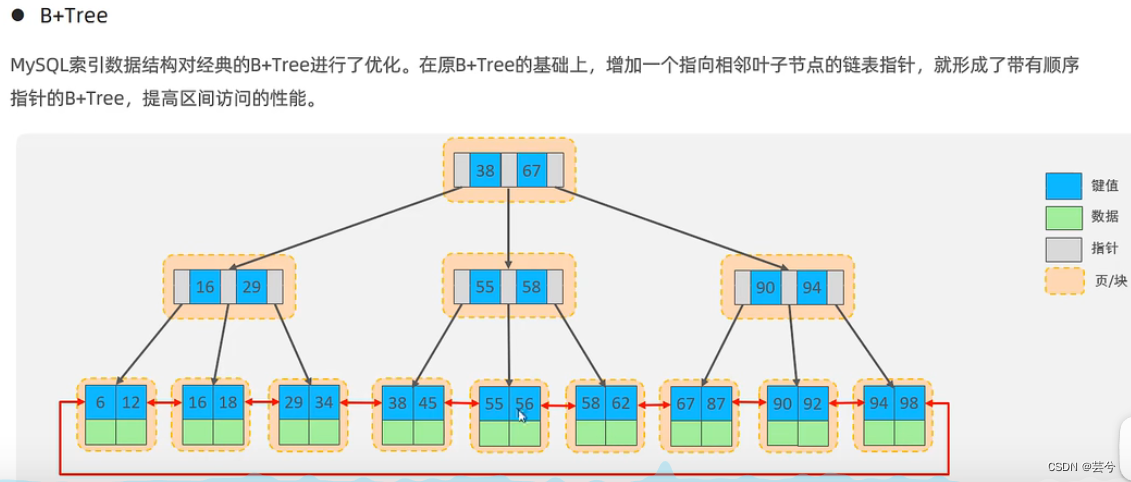
- El árbol B + de MySQL optimiza aún más el árbol B + clásico. Sobre la base del árbol B + original, se agrega un puntero de lista vinculada que apunta a los nodos de hoja adyacentes para formar un árbol B + con punteros secuenciales para proporcionar rendimiento de acceso a intervalos .
4. ¿Cómo se almacena una fila de registros MySQL?
Tome el motor de almacenamiento predeterminado de MySQL, InnoDB, como ejemplo:
cada vez que creamos una base de datos, /var/lib/mysql/se creará un directorio llamado base de datos en el directorio, y luego los archivos que guardan la estructura de la tabla y los datos de la tabla se almacenarán en este directorio. El directorio contiene:
- db.opt: almacena el juego de caracteres predeterminado de la base de datos actual y las reglas de verificación de caracteres .
- t_order.frm: almacena información de definición de estructura de tabla.
- t_order.ibd: almacenar información de datos de la tabla . A partir de MySQL 5.6.6, los datos de cada tabla en MySQL se almacenan en un archivo .ibd independiente, llamado archivo de espacio de tabla exclusivo .
Un espacio de tabla consta de segmentos, extensiones, páginas y filas.
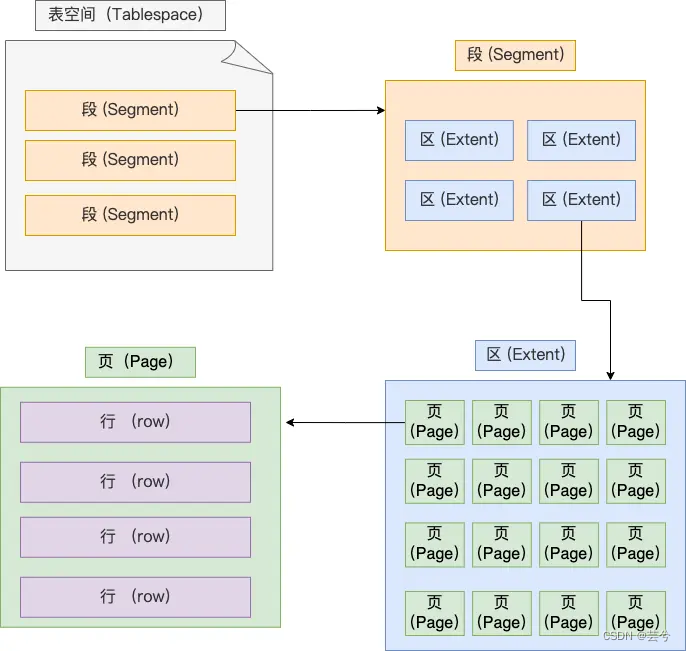
- Fila - fila: cada registro se almacena por fila
- Página - página: los registros se almacenan en filas, pero la base de datos se lee en unidades de páginas . El tamaño predeterminado de cada página es 16 KB, es decir, se garantiza un máximo de 16 KB de espacio de almacenamiento continuo.
- Extensión: el motor de almacenamiento InnoDB utiliza el árbol B+ para organizar los datos. En el árbol B+, los datos de cada fila están vinculados a través de una lista doblemente vinculada. Si el espacio de almacenamiento se asigna en unidades de páginas, la ubicación física entre dos páginas adyacentes en el vínculo list No es continuo, lo que provoca una gran cantidad de E/S aleatorias durante la consulta del disco, lo que provoca un bajo rendimiento. Para resolver el problema de la E/S aleatoria, las posiciones físicas de las páginas adyacentes en la lista vinculada también son adyacentes, por lo que se puede utilizar E/S secuencial . Específicamente, cuando la cantidad de datos en la tabla es grande, al asignar espacio para un índice, ya no se asigna en unidades de páginas, sino en unidades de extensión. El tamaño de cada área es de 1 MB. Para páginas de 16 KB, 64 páginas consecutivas se dividirán en un área, de modo que las posiciones físicas de las páginas adyacentes en la lista vinculada también sean adyacentes y se puedan utilizar E / S secuenciales.
- Segmento: el espacio de tabla se compone de varios segmentos, generalmente divididos en:
- Segmento de índice: una colección de áreas que almacenan nodos que no son hoja del árbol B+
- Segmento de datos: una colección de áreas que almacenan los nodos de hoja del árbol B+
- Segmento de reversión: una colección de áreas que almacenan datos de reversión.
Los datos de cada fila en MySQL generalmente se almacenan en formato de fila Cmpact:
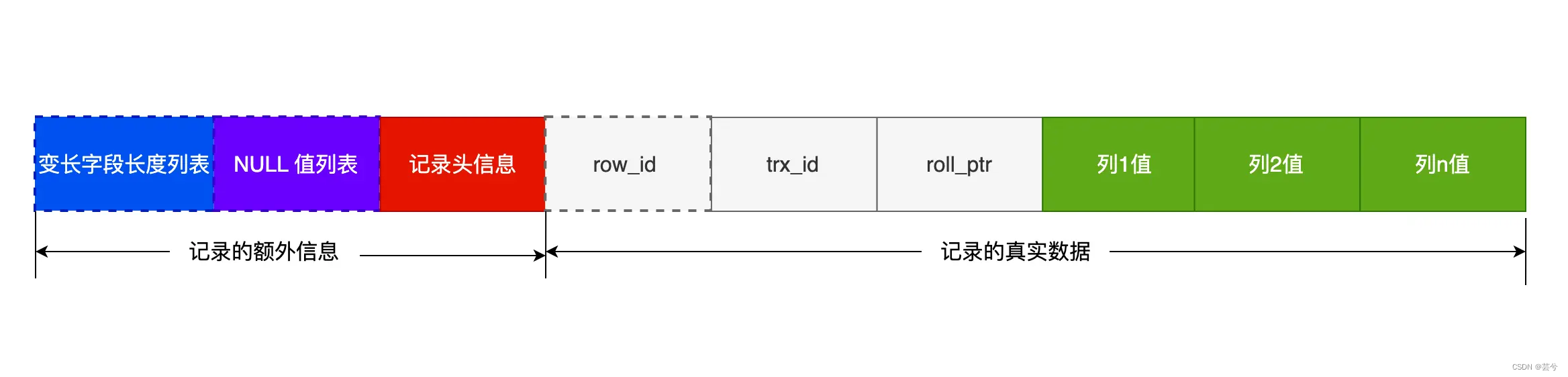 un registro completo se divide en:
un registro completo se divide en:
- información extra
- 1. Lista de longitud de campo de longitud variable: solo aparece cuando la tabla de datos tiene campos de longitud variable y se utiliza para almacenar la longitud real de los datos del campo de longitud variable.
- 2. Lista de valores NULL: solo aparece en tablas con campos que permiten nulos. La lista de valores NULL utiliza bits binarios para indicar si los datos están vacíos. El valor del bit es 1, que significa que es nulo, y 0, que significa que no está vacío. Debe estar representado por el byte completo (8 bits), y si es insuficiente rellenar 0 en el bit alto.
- 3. Registre la información del encabezado, que incluye:
- delete_mask: indica si este dato se elimina.
- next_record: la siguiente posición de registro.
- record_type: tipo de registro, 0 significa registro normal, 1 significa nodo no hoja del árbol B+, 2 significa registro mínimo, 3 significa registro máximo.
- datos reales
- 1. Campos ocultos
- row_id: si no se establece ninguna clave principal, se genera row_id como clave principal.
- trx_id: identificación de transacción
- roll_pointer: puntero de reversión, registra el puntero de la versión anterior.
- 2. Campo de datos: campo de columna común.
- 1. Campos ocultos
índice
5. Clasificación del índice
-
Por
「数据结构」clasificación: índice de árbol B+, índice Hash, índice de texto completo. -
Por
「物理存储」clasificación: índice agrupado (índice de clave primaria), índice secundario (índice auxiliar).- Los nodos hoja del árbol B+ indexados por la clave primaria (agrupación) almacenan datos reales, y todos los registros de usuario completos se almacenan en los nodos hoja del árbol B+ indexados por la clave primaria;
- Los nodos hoja del árbol B+ del índice secundario (auxiliar) almacenan el valor de la clave principal, no los datos reales.
-
Por
「字段特性」clasificación: índice de clave primaria, índice único, índice común, índice de prefijo.- Índice de clave principal: creada en el campo de clave principal , una tabla puede tener como máximo uno, no se permiten valores nulos y, por lo general, se crean juntos cuando se crea la tabla.
- Índice único: construido sobre el campo ÚNICO , una tabla puede tener múltiples índices únicos, el valor de la columna de índice debe ser único, pero se permiten valores nulos.
- Índice ordinario: construido sobre campos ordinarios .
- Índice de prefijo: un índice creado a partir de los primeros caracteres de un campo de tipo de carácter, en lugar de un índice creado para todo el campo. Se puede crear un índice de prefijo en una columna cuyo tipo de campo sea char, varchar, binario o varbinary .
-
Clasificados por "número de campos": índice de una sola columna, índice combinado.
- Al combinar varios campos en un índice, el índice se denomina índice compuesto.
6. El principio de coincidencia más a la izquierda del índice conjunto.
Por ejemplo, para combinar los campos product_no y name en la tabla de productos en un índice conjunto (product_no, nombre), la forma de crear un índice conjunto es la siguiente:CREATE INDEX index_product_no_name ON product(product_no, name);
Los nodos que no son hojas del árbol B + del índice conjunto (product_no, nombre) utilizan los valores de los dos campos como el valor clave del árbol B +. Al consultar datos, primero compare por el campo product_no y luego compare por el campo de nombre cuando el número de producto sea el mismo. Por lo tanto, cuando se utiliza un índice conjunto, existe un principio de coincidencia más a la izquierda, es decir, la coincidencia del índice se realiza primero en el extremo izquierdo. Cuando utilice un índice conjunto para consultas, si no sigue el **"principio de coincidencia más a la izquierda"**, el índice conjunto fallará, por lo que no podrá aprovechar la función de consulta rápida del índice.
Por ejemplo, si crea un índice conjunto (a, b, c), si las condiciones de la consulta son las siguientes, puede hacer coincidir el índice conjunto (debido al optimizador de consultas, el orden del campo a en la cláusula donde no es importante):
donde a=1;
donde a=1 y b=2 y c=3;
donde a=1 y b=2;
Sin embargo, si las condiciones de la consulta son las siguientes, debido a que no se cumple el principio de coincidencia más a la izquierda, el índice conjunto no podrá coincidir y el índice conjunto dejará de ser válido:
donde b=2;
donde c=3;
donde b=2 y c=3;
6.1 Desplazamiento del índice conjunto
Cuando se utiliza un índice conjunto, si hay una gran cantidad de situaciones que deben devolverse a la tabla, la inserción del índice puede ayudar a optimizar y las condiciones de filtrado se procesan en la capa del motor.
Por ejemplo: utilice una tabla de usuarios tuser y cree un índice conjunto (nombre, edad) en la tabla. 
Si hay un requisito ahora: recupere todos los usuarios cuyo nombre en la tabla sea Zhang y cuya edad sea 10 años. Entonces, la declaración SQL se escribe así:
select * from tuser where name like '张%' and age=10;
Usando el índice pushdown, el campo de nombre encontrado que comienza con Zhang se filtrará según la edad = 10, se obtendrán todos los ID coincidentes y luego se devolverán a la tabla para obtener todos los resultados.
Si no se utiliza el índice pushdown, se buscará de acuerdo con la primera condición y se devolverá a la capa del servidor, y la capa del servidor se filtrará de acuerdo con la segunda condición.
El pushdown del índice en realidad se refiere a entregar algunas de las cosas de las que la capa superior (capa de servicio) es responsable a la capa inferior (capa del motor) para su procesamiento.
7. Consulta de rango del índice conjunto.
P1: seleccione * de t_table donde a > 1 y b = 2, ¿qué campo del índice conjunto (a, b) utiliza el árbol B+ del índice conjunto?
P1 En esta declaración de consulta, solo el campo a usa el índice conjunto para la consulta de índice, pero el campo b no usa el índice conjunto porque los valores del campo b están desordenados en el alcance de los registros del índice secundario que cumplen la condición a > 1 .
P2: seleccione * de t_table donde a >= 1 y b = 2, ¿qué campo del índice conjunto (a, b) utiliza el árbol B+ del índice conjunto?
Para el rango de registros de índice secundario que coinciden con a = 1, los valores del campo b están "ordenados", por lo que se utilizará el índice combinado del campo b.
P3: SELECCIONE * DE t_table DONDE a ENTRE 2 Y 8 Y b = 2, ¿qué campo del índice conjunto (a, b) utiliza el árbol B+ del índice conjunto?
P4: SELECCIONE * DESDE t_user DONDE nombre como 'j%' y edad = 22, ¿qué campo del índice conjunto (nombre, edad) utiliza el árbol B+ del índice conjunto?
Q3 y Q4 son iguales que Q2.
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。注意,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。
8. ¿Cuándo es necesario o no crear un índice?
La mayor ventaja de la indexación es mejorar la velocidad de las consultas, pero la indexación también tiene desventajas, como: aumentar la sobrecarga de almacenamiento y aumentar los costos de mantenimiento del índice.
¿Cuándo se deben utilizar los índices?
- Campos con restricciones únicas , como códigos de productos;
- Un campo que se usa a menudo , que puede mejorar la velocidad de consulta de toda la tabla. Si la condición de consulta no es un campo, se puede establecer un índice conjunto.
- A menudo se usa para los campos GROUP BY y ORDER BY , de modo que no sea necesario volver a ordenar al realizar consultas , porque todos sabemos que todos los registros en B + Tree se ordenan después de que se establece el índice.
¿Cuándo no es necesario crear un índice?
- Hay muchos datos duplicados en el campo.
- Los datos de la tabla son demasiado pequeños.
- Los campos actualizados con frecuencia no necesitan crear índices
9. ¿Existe alguna forma de optimizar el índice?
- Optimización del índice de prefijo: puede reducir el tamaño del campo de índice, pero también tiene limitaciones, como que el
order byíndice de prefijo no se puede usar y el índice de prefijo no se puede usar como índice de cobertura. - Construyendo un índice conjunto, un índice de cobertura. Reduzca las consultas recurrentes.
- Es mejor incrementar automáticamente la clave principal para reducir las divisiones de páginas.
- Es mejor configurar el índice para que no esté vacío, y la presencia de valores nulos hará que el optimizador sea más complicado al realizar la selección del índice.
- Evitar la invalidación del índice.
10. ¿En qué circunstancias el índice dejará de ser válido?
- Usar != o <> invalida el índice.
- El uso de una coincidencia aproximada izquierda o izquierda en el índice significa que
like %xxuno olike %xx%ambos métodos provocarán que el índice falle. Debido a que el árbol de índice B+ se almacena en orden según el "valor de índice", solo se puede comparar según el prefijo. - Utilice cálculos de funciones o expresiones en índices.
- Conversiones de tipos implícitas para índices
- Coincidencia del índice conjunto no más a la izquierda
- Para la cláusula o en la cláusula where, si la condición antes de o es una columna de índice, pero la columna de condición después de o no es una columna de índice, el índice no será válido.
11. ¿Qué conteo tiene el mejor desempeño?
count() es una función de agregación. El parámetro de la función puede ser no solo el nombre del campo, sino también cualquier otra expresión. La función de count() es contar los registros que cumplen con las condiciones de la consulta, cuántos están especificados por el función .参数不为 NULL 的记录
1 Esta expresión es un número simple, nunca es NULL, por lo que count(1) es el número de todos los registros en la tabla de estadísticas. Entonces hay:
count(1) = count(*)

recuento (1), recuento (*), recuento (campo de clave principal) al ejecutar, si hay un índice secundario en la tabla, el optimizador seleccionará el índice secundario para escanear.
Por lo tanto, si desea ejecutar count(1), count(*) y count (campos de clave principal), intente crear un índice secundario en la tabla de datos, de modo que el optimizador use automáticamente el índice secundario con el key_len más pequeño. para escanear, en comparación con escanear el índice de clave principal será más eficiente.
asuntos
12. ¿Cuáles son las cuatro características de los negocios?
- Atomicidad: una transacción es una unidad mínima de operación indivisible, o todas tienen éxito o todas fallan.
- Coherencia: cuando se completa una transacción, todos los datos deben ser coherentes.
- Aislamiento: el mecanismo de aislamiento proporcionado por el sistema de base de datos garantiza que las transacciones se ejecuten en un entorno independiente que no se vea afectado por operaciones concurrentes externas.
- Persistencia: una vez que una transacción se confirma o revierte, sus cambios en los datos de la base de datos son permanentes.
13. ¿Qué tecnología utiliza el motor InnoDB para garantizar las características de las transacciones?
Rehacer registro ejecuta el registro nuevamente, es decir, escribe primero el registro modificado cuando cambian los datos. Para garantizar la persistencia de los datos, incluso si hay un error en el envío, se pueden ejecutar nuevamente de acuerdo con el registro de rehacer.
Deshacer registro Registro de reversión, utilizado para registrar la información antes de modificar los datos.
- Atomicidad: la atomicidad está garantizada por el registro de deshacer (registro de reversión). Si la transacción falla a la mitad, se revertirá de acuerdo con el registro de deshacer.
- Persistencia: La persistencia se garantiza a través del registro de rehacer (registro de reejecución), si la modificación de datos falla, la modificación se realiza nuevamente de acuerdo con el registro de rehacer.
- Aislamiento: a través de MVCC (control de concurrencia de múltiples versiones) y el mecanismo de bloqueo, se garantiza que las transacciones no se verán afectadas por la concurrencia durante la ejecución.
- Consistencia: garantice la coherencia de los resultados de la ejecución de transacciones mediante la atomicidad, la persistencia y el aislamiento.
14. ¿Qué problemas causará la concurrencia de transacciones?
- Lectura sucia: una transacción lee datos que no han sido confirmados por otra transacción.
- Lectura no repetible: una transacción lee el mismo registro sucesivamente, pero los datos leídos dos veces son diferentes, lo que se denomina lectura no repetible.
- Lectura fantasma: cuando una transacción consulta datos según las condiciones, no hay una fila de datos correspondiente, pero al insertar datos, se descubre que esta fila de datos ya existe, como si hubiera aparecido un "fantasma".
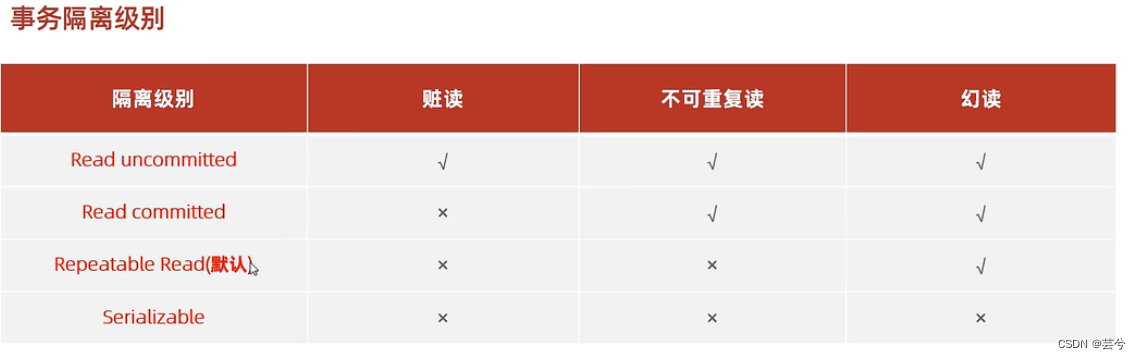
15. ¿Cuáles son los niveles de aislamiento de las transacciones?
Cuando se ejecutan varias transacciones al mismo tiempo, se puede encontrar el fenómeno de "lectura sucia, lectura no repetible y lectura fantasma". La gravedad de estos tres fenómenos se clasifica de la siguiente manera:

- Leer no confirmado (leer no confirmado), lo que significa que cuando una transacción no se ha confirmado, otras transacciones pueden ver los cambios que realiza;
- Lectura confirmada (lectura confirmada), lo que significa que después de confirmar una transacción, otras transacciones pueden ver los cambios que realiza;
- La lectura repetible se refiere a los datos vistos durante la ejecución de una transacción, que siempre son consistentes con los datos vistos cuando se inicia la transacción El nivel de aislamiento predeterminado del motor MySQL InnoDB;
- Serializable: se agregará un bloqueo de lectura y escritura al registro. Cuando varias transacciones leen y escriben este registro, si ocurre un conflicto de lectura y escritura, la transacción a la que se accede posteriormente debe esperar a que se complete la transacción anterior para continuar con la ejecución;
Para diferentes niveles de aislamiento, los fenómenos que pueden ocurrir durante transacciones concurrentes también son diferentes:
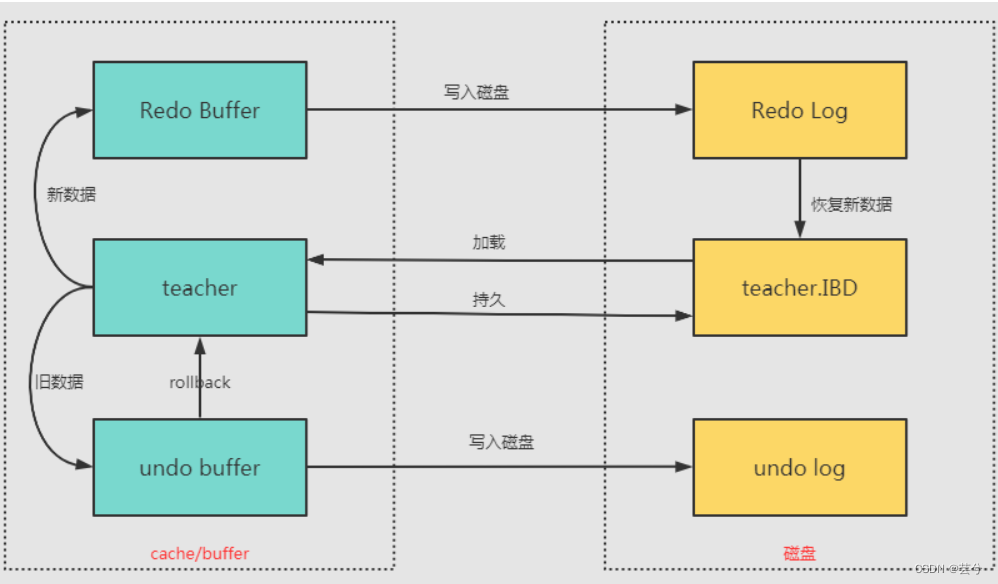
16. Introduzca el registro de transacciones de MySQL.
-
Registro de rehacer: el registro de rehacer no se escribe con la confirmación de la transacción, sino que comienza a escribirse en rehacer durante la ejecución de la transacción. En el momento en que se debe evitar una falla, todavía hay páginas sucias que no se han escrito en el disco. Cuando se reinicia el servicio MySQL, se rehace de acuerdo con el registro de rehacer, para lograr la función de conservar los datos de la transacción que no han ingresado al disco.
-
Registro de deshacer: el registro de deshacer se utiliza para revertir registros de fila a una versión determinada. Antes de confirmar la transacción, Deshacer guarda los datos de la versión no confirmada y los datos del registro de deshacer se pueden usar como una instantánea de la versión anterior de los datos para que la lean otras transacciones simultáneas. Es un producto que parece darse cuenta de la atomicidad de las transacciones y se utiliza para realizar el control de concurrencia de múltiples versiones en el motor de almacenamiento MySQL innodb.
-
registro de contenedor. El binlog de MySQL es un registro binario que registra todos los cambios en la estructura de la tabla de la base de datos (como CREAR, ALTERAR TABLA) y modificaciones de los datos de la tabla (INSERT, ACTUALIZAR, ELIMINAR). Binlog no registra operaciones como SELECT y SHOW, porque dichas operaciones no modifican los datos en sí. El binlog de MySQL se registra en forma de eventos y también incluye el tiempo consumido por la ejecución de la declaración . El registro binario de MySQL es seguro para transacciones. El objetivo principal del binlog es la replicación y recuperación.
17. ¿Qué es MVCC?
La implementación de MVCC (control de concurrencia de múltiples versiones) se realiza guardando una instantánea de los datos en un momento determinado. Dependiendo de la hora de inicio de la transacción, cada transacción puede ver datos diferentes para la misma tabla al mismo tiempo.
El principio de implementación de MVCC se basa en los campos ocultos en la tabla MySQL: row_id (ID de clave primaria oculta), trx_id (ID de transacción) y roll_ptr (puntero de reversión). El puntero de reversión apunta a la versión anterior de este registro y se registra. en el registro de deshacer. De acuerdo con la identificación de la transacción y el puntero de reversión, puede ubicar la cadena de versiones del registro de deshacer y leer la vista (ReadView) de la versión correspondiente.
Reglas de acceso a la versión:
MVCC mantiene una estructura ReadView, que incluye principalmente la lista de transacciones TRX_ID {TRX_ID_1, TRX_ID_2,…} no enviadas por el sistema actual, y los valores mínimos TRX_ID_MIN y TRX_ID_MAX de la lista. Durante la operación SELECT, juzgue si la instantánea de la fila de datos se puede utilizar de acuerdo con la relación entre TRX_ID, TRX_ID_MIN y TRX_ID_MAX de la instantánea de la fila de datos:
- TRX_ID <TRX_ID_MIN, lo que indica que la instantánea de la fila de datos se cambió antes de todas las transacciones actuales no confirmadas, por lo que se puede utilizar.
- TRX_ID> TRX_ID_MAX, lo que indica que la instantánea de la fila de datos se cambió después de que se inició la transacción, por lo que no se puede utilizar.
- TRX_ID_MIN <= TRX_ID <= TRX_ID_MAX, es necesario juzgar según el nivel de aislamiento:
- Confirmar lectura: si TRX_ID está en la lista TRX_ID, significa que la transacción correspondiente a la instantánea de la fila de datos no se ha confirmado y la instantánea no se puede utilizar. De lo contrario, se ha enviado y se puede utilizar.
- Lectura repetible: Ninguno de los dos se puede utilizar.
Lectura de instantánea y lectura actual
1. Lectura de instantánea: la selección en MVCC opera con los datos de la instantánea y no es necesario bloquearla.
2. Lectura actual: la operación de modificación de datos en MVCC (adición, eliminación y modificación) debe bloquearse para leer los datos más recientes.
18. ¿Cómo se implementan los niveles de aislamiento de transacciones?
- Para las transacciones en el nivel de aislamiento "lectura no confirmada", dado que los datos modificados por transacciones no confirmadas se pueden leer, es bueno leer los datos más recientes directamente;
- Para las transacciones en el nivel de aislamiento de "serialización", se evita el acceso paralelo agregando bloqueos de lectura y escritura;
- Para las transacciones en los niveles de aislamiento de "lectura confirmada" y "lectura repetible", se implementan a través de la Vista de lectura y su diferencia radica en el momento de crear la Vista de lectura.
- El nivel de aislamiento de lectura repetible es generar una Vista de lectura cuando se inicia una transacción y luego usar esta Vista de lectura durante toda la transacción.
- El nivel de aislamiento de confirmación de lectura es generar una nueva vista de lectura cada vez que se leen datos.
19. ¿Cómo solucionar la lectura fantasma?
El nivel de aislamiento de lectura repetible (nivel de aislamiento predeterminado) del motor MySQL InnoDB propone soluciones para evitar lecturas fantasma según diferentes métodos de consulta:
-
Para lecturas instantáneas (declaraciones de selección ordinarias), las lecturas fantasmas se resuelven a través de MVCC. Bajo el nivel de aislamiento de lectura repetible, los datos vistos durante la ejecución de la transacción siempre son consistentes con los datos vistos cuando se inicia la transacción. Incluso si otras transacciones insertan un dato en el medio, los datos no se pueden consultar. Así que es bueno para evitar el problema de lectura fantasma.
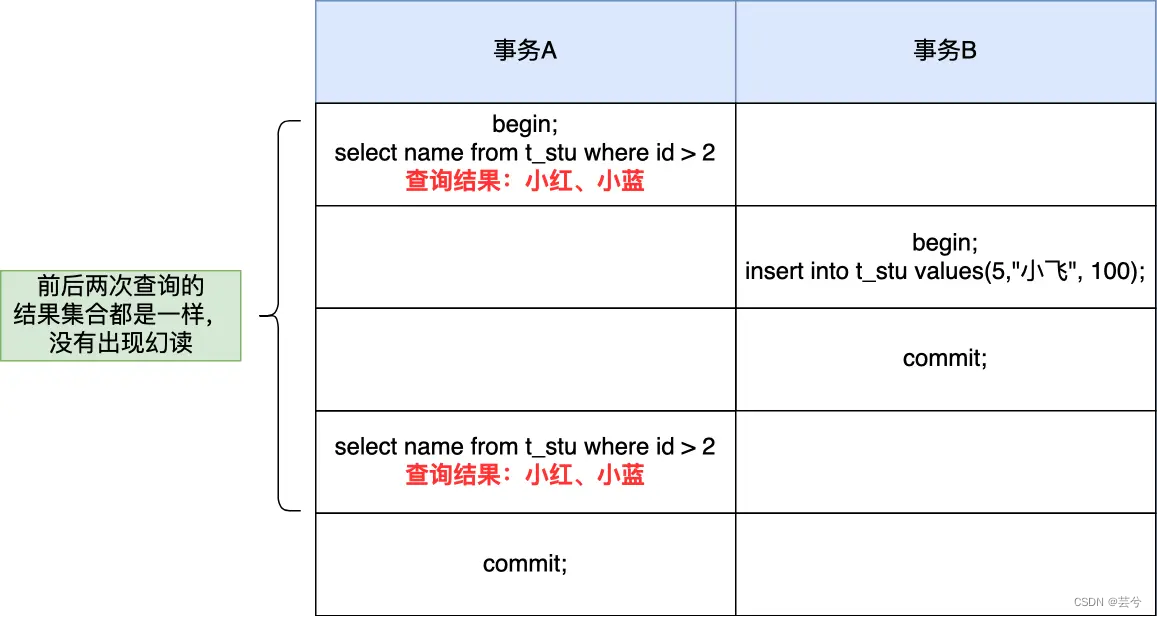
-
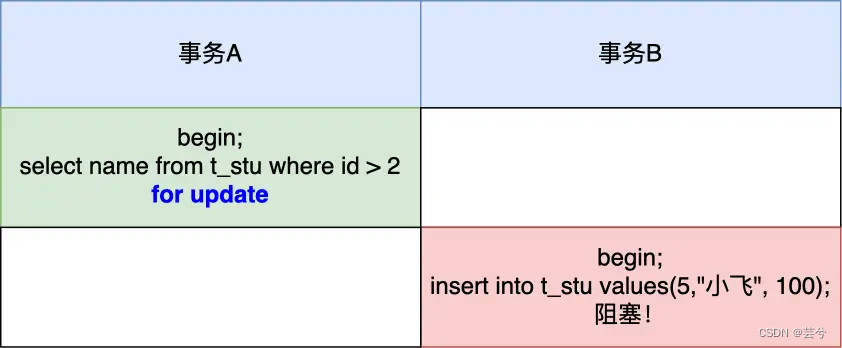
Para la lectura actual (select... para actualización y otras declaraciones), el bloqueo de siguiente tecla (bloqueo de registro + bloqueo de espacio) se usa para resolver la lectura fantasma, porque cuando se ejecuta la instrucción select... para actualización, el Se agregará el bloqueo de la siguiente clave. Si otra transacción inserta un registro dentro del rango del bloqueo de la siguiente clave, la instrucción de inserción se bloqueará y no se podrá insertar con éxito, por lo que es muy bueno evitar el problema de la lectura fantasma.
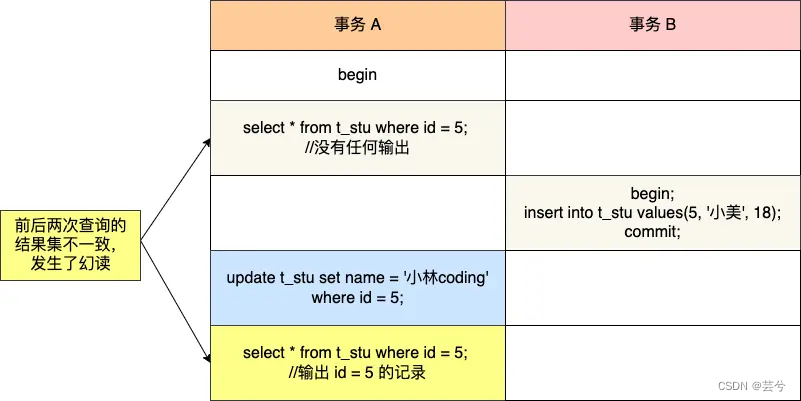
Se dan dos ejemplos de escenarios de lectura fantasma.
El primer ejemplo:
tiempo1: la transacción A consulta el registro con ID 5, pero descubre que no se puede consultar.
tme2: La transacción B inserta un registro con id 5.
time3: La transacción B confirma la transacción.
time4: cuando la transacción A inserta el registro con ID 5, descubre que ya existe un registro y se produce una lectura fantasma.
El segundo ejemplo:
tiempo1: la transacción A primero ejecuta la "declaración de lectura de instantánea": seleccione * de t_test donde id > 100 y obtiene 3 registros.
time2: la transacción B inserta un registro con id= 200 y lo envía;
time3: la transacción A ejecuta la "declaración de lectura actual" seleccione * de t_test donde id > 100 para actualizar y luego obtiene 4 registros, la lectura fantasma también ocurre en este momento Fenómeno .
El nivel de aislamiento de lectura repetible de MySQL no resuelve completamente la lectura fantasma, pero evita en gran medida la aparición de lectura fantasma.
Cerrar
20. ¿Qué tipo de bloqueos tiene MySQL?
-
Bloqueo global: el bloqueo global se utiliza principalmente para la copia de seguridad lógica de toda la base de datos , de modo que durante la copia de seguridad de la base de datos, los datos en el archivo de copia de seguridad no serán diferentes de los esperados debido a la actualización de los datos o la estructura de la tabla. Mientras está bloqueada, la base de datos es de sólo lectura.
-
Bloqueo a nivel de tabla: bloquea toda la tabla.
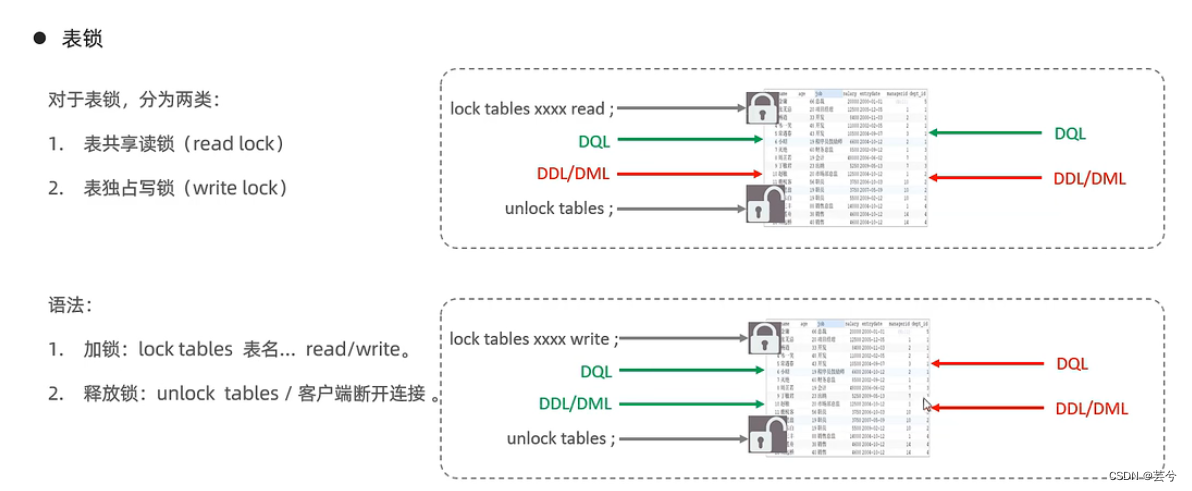
- Bloqueo de mesa:
- Bloqueo de lectura compartida de la tabla: el cliente 1 ejecuta
lock table score read;
la puntuación de la tabla y pasará a ser de solo lectura. En este momento, si el cliente 1 quiere agregar, eliminar o modificar la puntuación de la tabla, se informará un error. Si el cliente 2 quiere agregar , elimine o modifique la puntuación de la tabla, entrará en el estado de espera y esperará al cliente 1. Después del desbloqueo, se enviará la declaración de modificación del cliente 2. - Bloqueo de escritura exclusivo de la tabla: el cliente 1 se ejecuta:
lock tables score write;
el cliente 1 leerá y escribirá exclusivamente la puntuación de la tabla, y se bloqueará la lectura y escritura de otros clientes.
- Bloqueo de lectura compartida de la tabla: el cliente 1 ejecuta
- Bloqueo de metadatos (MDL): el proceso de bloqueo del bloqueo de metadatos lo controla automáticamente el sistema y no es necesario usarlo explícitamente, y se agrega automáticamente al acceder a una tabla.
- Al realizar operaciones CRUD en una tabla, se agregan bloqueos de lectura MDL (compartidos);
- Al cambiar la estructura de la tabla, se agrega el bloqueo de escritura (exclusivo) en el bloqueo de metadatos.
- Los bloqueos de lectura y los bloqueos de lectura no se excluyen entre sí, por lo que pueden operar varios subprocesos en la misma tabla. Los bloqueos de lectura y escritura y los bloqueos de escritura son mutuamente excluyentes para garantizar la seguridad de la operación de cambio de la estructura de la tabla. Por lo tanto, si dos subprocesos quieren agregar campos a una tabla al mismo tiempo, uno de ellos no comenzará a ejecutarse hasta que el otro termine de ejecutarse.
- Bloqueos de intención:
意向锁的目的是为了快速判断表里是否有记录被加锁。los bloqueos de intención compartidos y los bloqueos de intención exclusivos son bloqueos a nivel de tabla, que no entrarán en conflicto con los bloqueos compartidos a nivel de fila y los bloqueos exclusivos, y no habrá conflictos entre bloqueos de intención, solo con bloqueos de tabla compartidos (bloqueos de tablas... .leer) y conflicto de bloqueos de tabla exclusivos (bloquear tablas...escribir).
- Bloqueo de mesa:
-
Bloqueos de nivel de fila: los bloqueos de nivel de fila operan en los datos de fila correspondientes cada vez, con la menor probabilidad de conflicto y el mayor grado de concurrencia. Los índices de InnoDB se organizan en función de índices. Los bloqueos de fila se implementan bloqueando los índices en el índice. en lugar de El candado agregado al registro.
- Bloqueo de fila (bloqueo de registro, bloqueo de registro): el bloqueo agregado a cada registro se puede dividir en:
- Bloqueo compartido (S, lectura): permite que una transacción lea una fila, evita que otras transacciones adquieran bloqueos exclusivos, lectura-lectura compartida y lectura-escritura exclusión mutua.
- Bloqueo exclusivo (X, escritura): permite que las transacciones que adquieren bloqueos exclusivos actualicen los datos y evita que otras transacciones adquieran bloqueos compartidos y exclusivos, es decir, exclusión mutua de lectura y escritura y exclusión mutua de escritura y escritura.
- Al realizar altas, eliminaciones y modificaciones, se agrega automáticamente un bloqueo exclusivo. Al ejecutar la selección, no se agregan bloqueos de forma predeterminada, pero los bloqueos se pueden agregar manualmente mediante declaraciones.
- Bloqueo de espacio (bloqueo de espacio): solo existe en el nivel de aislamiento de lectura repetible, el propósito es resolver el fenómeno de la lectura fantasma en el nivel de aislamiento de lectura repetible.
- Bloqueo de fila (bloqueo de registro, bloqueo de registro): el bloqueo agregado a cada registro se puede dividir en:
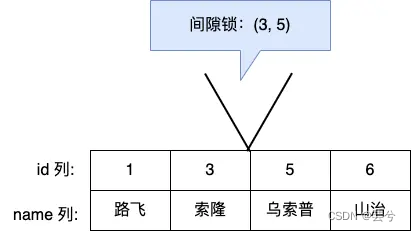
* Bloqueo de tecla siguiente: Es una combinación de Bloqueo de registro + Bloqueo de espacio, que bloquea un rango y bloquea el registro en sí.
21. ¿Cómo agrega MySQL bloqueos a nivel de fila?
Las reglas de bloqueo a nivel de fila son más complicadas y los formularios de bloqueo son diferentes en diferentes escenarios.
El objeto del bloqueo es el índice . La unidad básica de bloqueo es el bloqueo de la siguiente tecla , que se compone de bloqueo de registro y bloqueo de espacio . Intervalo, la tecla adyacente bloquea la siguiente tecla, lo que equivale a agregar el límite derecho del intervalo de bloqueo en la base del rango de bloqueo del bloqueo de espacio, es decir, la siguiente clave, correspondiente al bloqueo de registro
Sin embargo, los bloqueos de siguiente clave degeneran en bloqueos de registro o bloqueos de espacio en algunos escenarios.
¿Cuál es la escena? Para resumir,在能使用记录锁或者间隙锁就能避免幻读现象的场景下, next-key lock 就会退化成记录锁或间隙锁。
- Consulta equivalente de índice único.
- Cuando el registro consultado "existe", después de ubicar este registro en el árbol de índice, el bloqueo de la siguiente clave en el índice del registro degenerará en un "bloqueo de registro".
- Cuando el registro de consulta es "inexistente", después de que el árbol de índice encuentre el primer registro más grande que el registro de consulta, el siguiente bloqueo de clave en el índice del registro degenerará en un "bloqueo de espacio".
- Consulta de rango de índice único
- Para la consulta de rango de "mayor o mayor que o igual a", debido a que existe una condición de consulta equivalente, si el registro de la consulta equivalente existe en la tabla, el bloqueo de siguiente clave en el índice del registro degenerará en un bloqueo de registro.
- Para la consulta de rango de "menor o menor o igual a", depende de si el registro del valor de la condición existe en la tabla:
- Cuando el registro del valor de la condición no está en la tabla, no importa que sea una consulta de rango con la condición de "menor que" o "menor o igual que", cuando se escanea el registro que termina la consulta de rango, el siguiente -El bloqueo de clave del índice del registro degenerará en un bloqueo de espacio, y otros Para los registros escaneados, los bloqueos de siguiente clave se agregan a los índices de estos registros.
- Cuando el registro del valor de la condición está en la tabla, si es una consulta de rango de la condición "menor que", cuando se escanea el registro que finaliza la consulta de rango, el bloqueo de siguiente tecla del índice del registro degenerará en un bloqueo de espacio y otros registros escaneados, todo es agregar bloqueos de siguiente clave en los índices de estos registros; si se escanea la consulta de rango de la condición "menor o igual a", el índice de bloqueo de siguiente clave de el registro no degenerará en un bloqueo de espacio cuando se escanee el registro que finaliza la consulta de rango. Para otros registros escaneados, se agregan bloqueos de siguiente clave a los índices de estos registros.
- Consulta equivalente de índice no único: cuando se utiliza un índice no único para una consulta equivalente, debido a que hay dos índices, uno es el índice de clave principal y el otro es el índice no único (índice secundario), por lo que al bloquear, ambos Todos Los índices están bloqueados, pero cuando el índice de clave principal está bloqueado, solo los registros que cumplan las condiciones de la consulta bloquearán su índice de clave principal.
- Cuando el registro consultado "existe", dado que no es un índice único, debe haber un registro con el mismo valor de índice, por lo que el proceso de consulta equivalente al índice no único es un proceso de escaneo hasta que se escanea el primer registro secundario no calificado. detiene el escaneo y luego, durante el proceso de escaneo, se agrega un bloqueo de siguiente clave al registro de índice secundario escaneado, y para el primer registro de índice secundario que no cumple con las condiciones, el bloqueo de siguiente clave del índice secundario Los bloqueos de clave degeneran en cerraduras de espacio. Al mismo tiempo, se agregan bloqueos de registros a los índices de clave principal de los registros que cumplen las condiciones de la consulta.
- Cuando el registro consultado "no existe", se escanea el primer registro de índice secundario no calificado y el siguiente bloqueo de clave del índice secundario degenerará en un bloqueo de espacio. Como no hay ningún registro que cumpla con la condición de consulta, el índice de clave principal no se bloqueará.
- Consulta de rango de índice no único: para consultas de rango de índice no único, el bloqueo de siguiente clave del índice no degenerará en bloqueos de espacio y bloqueos de registro , es decir, todas las consultas de rango de índice no único se agregan con bloqueos de clave adyacentes.
- Consulta sin índice: si la declaración de consulta de lectura está bloqueada, la columna de índice no se usa como condición de consulta o la declaración de consulta no usa la consulta de índice, el escaneo es un escaneo de tabla completo. Luego, se agregará un bloqueo de siguiente clave al índice de cada registro, lo que equivale a una tabla completa bloqueada. En este momento, si otras transacciones agregan, eliminan o modifican la tabla, se bloquearán.
因此,在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
22. ¿En qué circunstancias MySQL provocará un punto muerto? ¿Como lidiar con?

etapa time1: transacción A más bloqueo de espacio, rango (20, 30)
etapa time2: transacción B más bloqueo de espacio, rango (20, 30)
间隙锁的意义只在于阻止区间被插入,因此是可以共存的。Un bloqueo de brecha adquirido por una transacción no impedirá que otra transacción adquiera un bloqueo de brecha en el mismo rango de brechas. No hay diferencia entre bloqueos de brecha compartidos y exclusivos. No entran en conflicto entre sí y tienen la misma función, es decir , dos transacciones pueden contener simultáneamente el mismo bloqueo de brecha. Bloqueo de brecha para brechas comunes.
Etapa Time3: la transacción A intenta agregar un bloqueo de intención a la posición con ID 25, pero descubre que la transacción B ha establecido un bloqueo de espacio entre (20,30), el bloqueo falla, se bloquea y espera a que la transacción B libere el espacio. cerrar con llave.
Etapa Time4: la transacción B intenta agregar un bloqueo de intención a la posición con ID 26, pero descubre que la transacción A ha establecido un bloqueo de espacio entre (20,30), el bloqueo falla, se bloquea y espera a que la transacción A libere el espacio. cerrar con llave.
La transacción A y la transacción B esperan mutuamente para liberar el bloqueo, lo que cumple las cuatro condiciones del punto muerto: exclusión mutua, posesión y espera, no ocupación y espera circular, por lo que se produce un punto muerto.
registro
23. ¿Cuáles son las funciones del registro de deshacer, el registro de rehacer y el registro bin? ¿cuál es la diferencia?
- El registro de deshacer tiene dos funciones principales:
- Registre el estado antes de que se ejecute la transacción, realice la reversión de la transacción y garantice la atomicidad de la transacción. Durante el procesamiento de la transacción, si ocurre un error o el usuario ejecuta una declaración ROLLBACK, MySQL puede usar los datos históricos en el registro de deshacer para restaurar los datos al estado antes de que comenzara la transacción.
- Uno de los factores clave para realizar MVCC (control de concurrencia de múltiples versiones). MVCC se implementa a través de ReadView + deshacer registro. El registro de deshacer guarda múltiples copias de datos históricos para cada registro. Cuando MySQL ejecuta una lectura instantánea (declaración de selección ordinaria), seguirá la cadena de versiones del registro de deshacer para encontrar registros que satisfagan su visibilidad de acuerdo con la información en la Vista de lectura. de la transacción.
- El registro de rehacer tiene dos funciones principales:
- Registre el estado del final de la ejecución de la transacción para garantizar la durabilidad de la transacción. Si ocurre un bloqueo después de confirmar la transacción, la ejecución de la transacción se puede reanudar a través del registro de rehacer después del reinicio.
- El método de escritura del registro de rehacer utiliza una operación de adición: el registro de rehacer no se escribe directamente en el disco, sino que primero se escribe en el búfer de registro de rehacer y luego el registro de rehacer en el búfer de registro de rehacer se escribe secuencialmente en el disco. El momento de vaciar el disco incluye (MySQL se apaga normalmente] El volumen de escritura del búfer de registro de rehacer es mayor que la mitad de la capacidad, y el subproceso en segundo plano de InnoDB persistirá el búfer de registro de rehacer en el disco cada 1 segundo y cada vez que se realice una transacción se envía, también puede elegir el parámetro para colocar el búfer del registro de rehacer en el disco), configurar La operación de escritura de MySQL ha cambiado de [escritura aleatoria] a escritura secuencial en el disco, lo que mejora el rendimiento de ejecución.
- El registro bin se utiliza principalmente para la recuperación de copias de seguridad y la recuperación maestro-esclavo. Después de que MySQL complete una operación de actualización, la capa del servidor también generará un binlog. El archivo binlog es un registro que registra todos los cambios en la estructura de la tabla de la base de datos y las modificaciones de los datos de la tabla, y no registra las operaciones de consulta.
deshacer registro y rehacer registro
undo log记录的是事务提交前的数据状态,redo log记录的是事务提交之后的数据状态
rehacer registro da registro bin
1. Los objetos aplicables son diferentes: binlog es el registro implementado por la capa de servidor
de MySQL , que puede ser utilizado por todos los motores de almacenamiento, redo log es el registro implementado por el motor de almacenamiento Innodb ;
2. El método de escritura es diferente:
binlog es escritura adjunta. Cuando un archivo está lleno, se creará un nuevo archivo para continuar escribiendo. El registro anterior no se sobrescribirá y se guardará el registro completo.
El registro de rehacer se escribe cíclicamente y el tamaño del espacio de registro es fijo (el buff del registro de rehacer tiene un tamaño fijo). Cuando está completamente escrito, comienza desde el principio y lo que se guarda es el registro de la página sucia que tiene no se ha descargado al disco.
3. Diferentes propósitos:
binlog se usa para respaldo y recuperación, replicación maestro-esclavo,
redo log se usa para recuperación de fallas como cortes de energía.
24. ¿Por qué necesitas un grupo de buffer?
El motor de almacenamiento Innodb diseña un grupo de búfer (Buffer Pool) para mejorar el rendimiento de lectura y escritura de la base de datos. Cuando se inicia MySQL, InnoDB solicitará un espacio de memoria continuo para Buffer Pool y luego dividirá las páginas una por una según el tamaño predeterminado de 16 KB . Las páginas en Buffer Pool se denominan páginas de caché.
- Al leer datos, si los datos existen en el grupo de búfer, el cliente los leerá directamente en el grupo de búfer; de lo contrario, los leerá desde el disco.
- Al modificar datos, si los datos existen en el Buffer Pool, modifique directamente la página donde se encuentran los datos en el Buffer Pool y luego configure su página como una página sucia (los datos de la memoria de esta página son inconsistentes con los datos del disco), para reducir la E/S del disco, no escribe páginas sucias en el disco inmediatamente y luego el subproceso en segundo plano elige un momento adecuado para escribir páginas sucias en el disco.
Además de almacenar en caché "páginas de índice" y "páginas de datos", Buffer Pool también incluye Deshacer páginas , insertar cachés, índices hash adaptables, información de bloqueo y más.
25. ¿Por qué se requiere una confirmación en dos fases, cómo es el proceso de confirmación y cuáles son los problemas?
Una vez confirmada la transacción, tanto el registro de rehacer como el registro bin se conservan en el disco, pero estas dos son lógicas independientes y puede haber un estado semi-exitoso, es decir, solo uno de los registros de rehacer y bin tiene éxito. . El registro de rehacer determinará el estado de los datos de la base de datos maestra y el registro bin determinará el estado de los datos de la base de datos esclava. Solo uno de los registros de rehacer y el registro bin se vacía con éxito, lo que provocará inconsistencia entre el registro maestro y el esclavo.
Para resolver este problema, MySQL completa internamente el envío de la transacción X en dos etapas: preparación y confirmación.
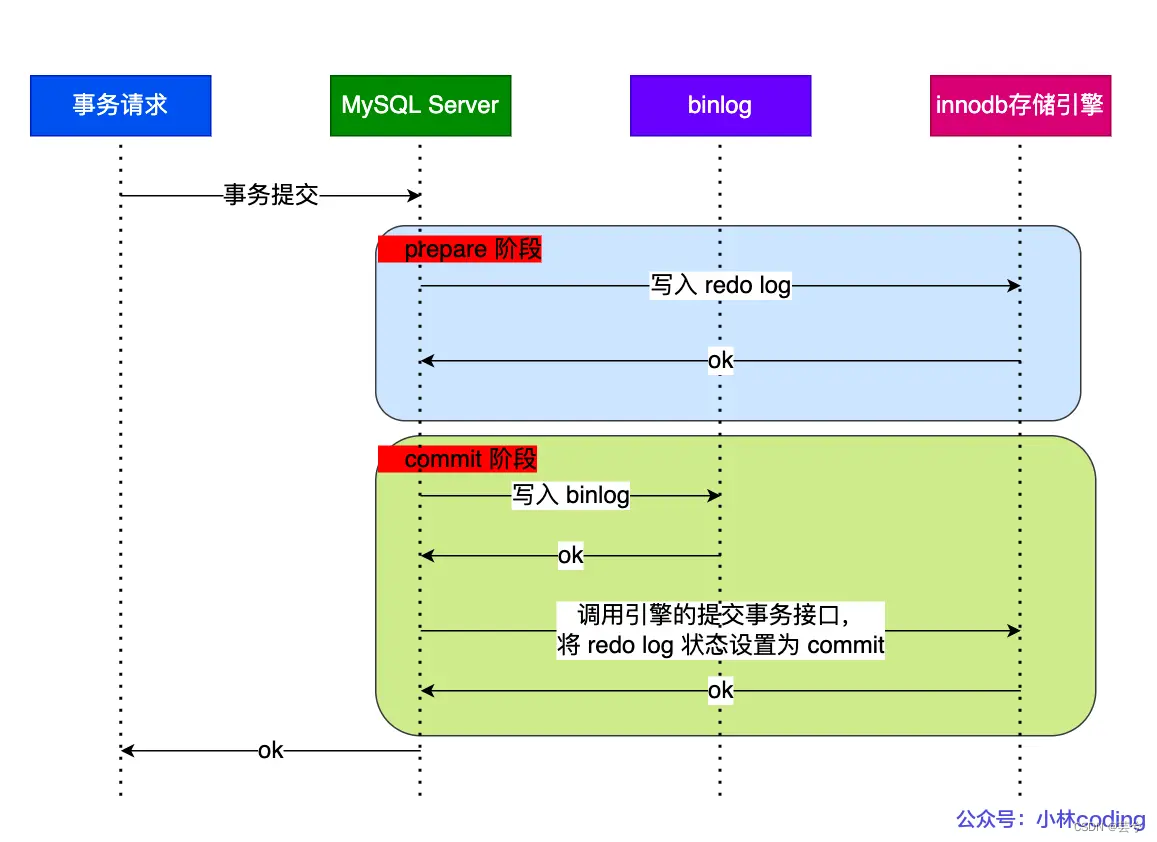
- Fase de preparación: escriba XID (ID de transacción) en el registro de rehacer, establezca el estado de la transacción correspondiente al registro de rehacer para prepararlo y luego conserve el registro de rehacer en el disco.
- Fase de confirmación: escriba el XID en el binlog, luego persista el binlog en el disco, luego llame a la interfaz de transacción de confirmación del motor y establezca el estado del registro de rehacer en confirmación.
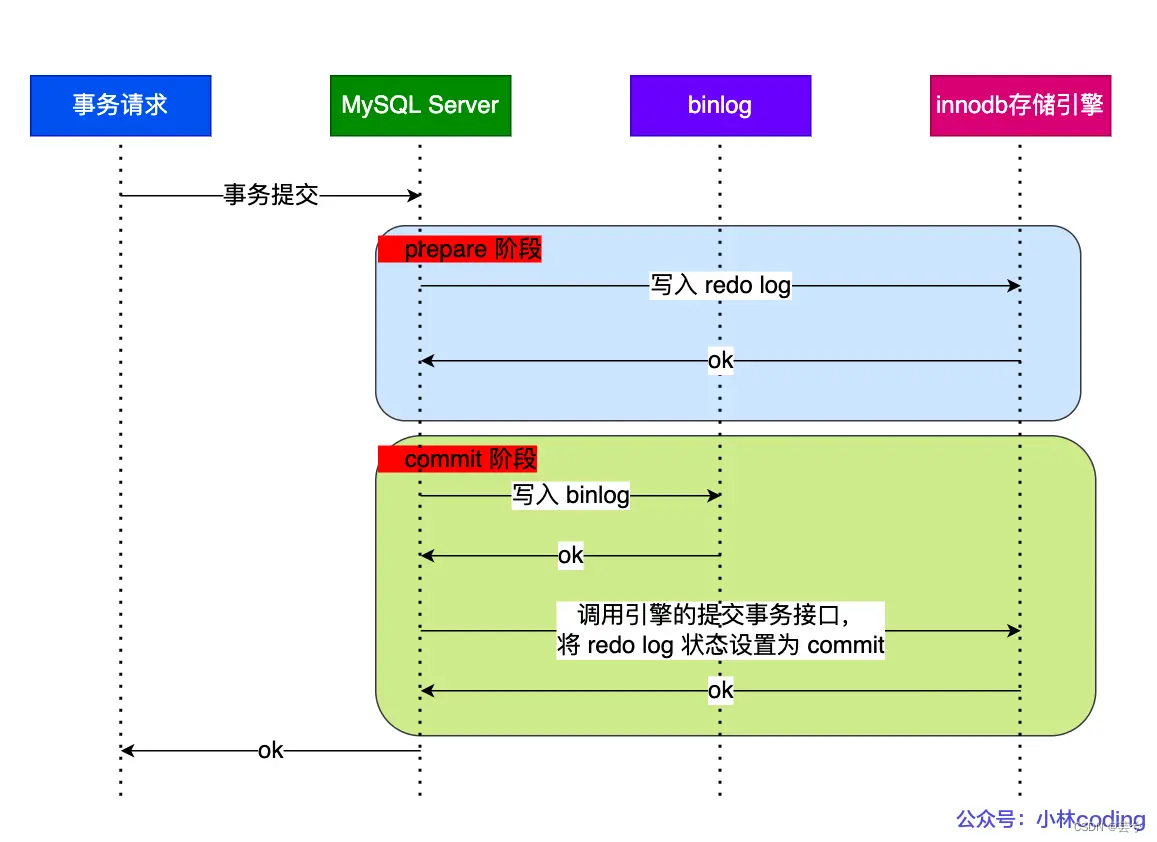
Bajo el mecanismo de confirmación de dos fases, puede decidir si revertir la transacción o confirmarla comparando si hay una identificación de transacción registrada en el registro de rehacer en el registro bin. Si lo hay, la transacción se confirma y de lo contrario, la transacción se revierte. De esta forma, se puede garantizar la coherencia de los dos registros, redo log y binlog.
Aunque la confirmación en dos fases resuelve el problema de coherencia del registro, también tiene problemas:
- Gran cantidad de E/S de disco: para la configuración "doble 1", cada envío de transacción realizará dos fsync (vaciado de disco), uno es el vaciado del registro de rehacer y el otro es el vaciado de binlog.
- La competencia de bloqueo es feroz: aunque el compromiso de dos fases puede garantizar que el contenido de los dos registros de la "transacción única" sea consistente, en el caso de la "transacción múltiple", no puede garantizar que el orden de compromiso de los dos sea el mismo. consistente, por lo tanto, la base del proceso de la confirmación de dos fases Además, se debe agregar un bloqueo para garantizar la atomicidad de la confirmación, a fin de garantizar que el orden de confirmación de los dos registros sea consistente en el caso de múltiples transacciones. .
26. Separación de lectura y escritura de MySQL, ¿cómo sincronizar el maestro y el esclavo, cómo resolver el problema del retraso de sincronización?
Al configurar una base de datos maestra MySQL (responsable de la escritura y actualización de datos) y múltiples bases de datos esclavas (responsables de la consulta de datos), a través del mecanismo de sincronización maestro-esclavo, los requisitos comerciales de la consulta se asignan a las bases de datos esclavas, lo que reduce la carga. en la base de datos maestra, mejorando así el rendimiento de la base de datos.
El proceso de sincronización maestro-esclavo:
1. Antes de que se completen los datos de actualización de cada transacción, el maestro escribe registros de operación (adición, eliminación, modificación) en el archivo binlog de manera adjunta.
2. El esclavo abre un subproceso de E/S y establece una conexión con el maestro. El trabajo principal es leer el registro bin del maestro. Si el progreso de la lectura ha seguido el ritmo del maestro, se pone en modo de suspensión y espera a que el maestro genere nuevos eventos. El propósito final del subproceso de E/S es escribir el maestro en el registro de retransmisión del registro de reenvío.
3. El subproceso SQL del esclavo leerá el registro de retransmisión y ejecutará los eventos SQL en el registro de forma secuencial, de modo que los datos de la biblioteca esclava sean coherentes con los de la biblioteca maestra.
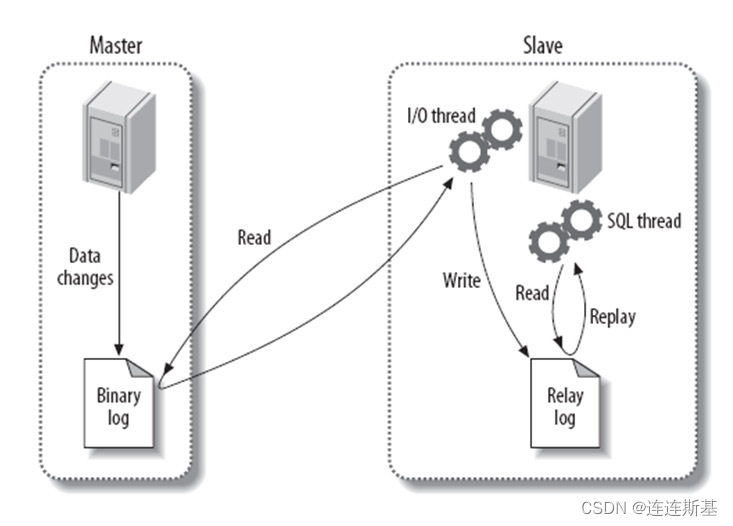
En el mecanismo de sincronización maestro-esclavo anterior, inevitablemente habrá un retraso entre los datos de la biblioteca esclava y los datos más recientes de la biblioteca maestra. Un breve retraso es aceptable, pero en algunos casos, este retraso será muy grave:
- 1. Consultar las necesidades comerciales es el factor principal, lo que genera demasiada presión por parte de la base de datos y ralentiza la ejecución de SQL.
- 2. La biblioteca maestra ejecuta una transacción que requiere mucho tiempo y el retraso en la transmisión a la biblioteca esclava es mayor.
Por las razones anteriores, puedes utilizar:
- Un maestro y varios esclavos comparten la presión de la biblioteca esclava.
- Para la clasificación de empresas, las empresas importantes con altos requisitos en tiempo real se consultan directamente a través de la base de datos principal.
- Al utilizar el mecanismo semisincrónico, la biblioteca principal solo necesita esperar a que al menos una biblioteca esclava reciba y escriba en el archivo de registro de retransmisión, y la biblioteca principal no necesita esperar a que todas las bibliotecas esclavas devuelvan ACK a la biblioteca principal. . Después de que la biblioteca principal reciba este ACK, puede devolver la confirmación de "transacción completa" al cliente.
- Utilice la replicación paralela para iniciar varios subprocesos desde la biblioteca para leer los registros de diferentes bibliotecas en el registro de retransmisión en paralelo y luego reproducirlos en paralelo en la biblioteca correspondiente.
optimización SQL
26. ¿Cómo localizar SQL y optimizar el rendimiento de las declaraciones SQL?
Utilice las herramientas de análisis de rendimiento SQL proporcionadas por MySQL:
- Registro de consultas lentas: registra el registro de todas las declaraciones SQL cuyo tiempo de ejecución excede los parámetros especificados.
show variables like 'slow_query_log';Puede ver el estado habilitado del registro de consultas lentas a través de la declaración . - Detalles del perfil: el uso de los detalles del perfil nos permite comprender dónde se gasta el tiempo de SQL.
explainUtilice el plan de ejecución explicativo, es decir, agregue la suma antes de la declaración SQLdescpara analizar la ejecución de la declaración SQL, si se utiliza el índice, el número de bytes en el índice y el tipo de conexión.
- Vea MySQL
慢查询日志y localice la identificación de SQL. - Usando
profileDetalles, puede ver dónde se dedica el tiempo específico de la consulta. - Usando
explainodesc+ declaración SQL, puede analizar el plan de ejecución de la declaración SQL, y hay dos campos que merecen nuestra atención:- tipo: si se utiliza un índice y el tipo de índice utilizado, la eficiencia del valor del campo de mayor a menor es:
- const: consulta equivalente para clave primaria o índice único
- eq_ref: generalmente ocurre en consultas asociadas y la condición asociada es la clave principal de la tabla o el único índice no vacío.
- ref: ref se usa generalmente para consultas equivalentes de índices no agrupados.
- ref_or_null: en la herencia de ref, también es necesario encontrar el resultado nulo. Dado que la consulta de valor nulo necesita escanear la información de la fila de todo el árbol de índice, será más lenta que ref.
- index_merge: varios resultados se fusionarán en uno y se unificarán nuevamente en la consulta de la tabla.
- rango: consulta de rango para cualquier índice, incluidos me gusta, entre, >, <, etc.
- índice: escaneo completo de la tabla, sin índice, pero puede obtener los resultados requeridos en el árbol de índice.
- todo: escaneo completo de la tabla, no todos los resultados de la consulta se pueden obtener del árbol de índice.
- extra: información adicional,
- usando índice (índice de cobertura)
- usando la condición de índice (empuje de índice)
- usando dónde (sin inserción de índice)
- usando temporal (usando una tabla temporal)
- usando filesort (se requiere clasificación adicional después de la consulta).
- tipo: si se utiliza un índice y el tipo de índice utilizado, la eficiencia del valor del campo de mayor a menor es:
- Compruebe si las filas de datos de la tabla son demasiado grandes y considere si debe dividir la base de datos en tablas
- Verifique la ocupación del servidor donde se encuentra la base de datos y considere actualizar el rendimiento del servidor.
Operaciones de optimización de SQL:
1. Inserción por lotes, inserción de secuencia de clave principal, evite conectarse a la base de datos varias veces y use el comando de carga para insertar datos en grandes cantidades.
2. Optimización de la clave principal: para satisfacer las necesidades comerciales, minimice la longitud de la clave principal y asegúrese de que la clave principal se incremente automáticamente.
3. Escenarios comerciales que deben ordenarse, es decir, utilizando el orden por declaración, estableciendo un índice adecuado, el índice conjunto sigue la regla de prefijo más a la izquierda y preste atención al orden de clasificación, que es ascendente de forma predeterminada.
4. Para las declaraciones que deben agruparse y consultarse, incluso las declaraciones que usan agrupar por también se pueden crear con un índice conjunto para acelerar la consulta.
5. Optimización de límite (optimización de paginación súper grande), MySQL no omite filas de desplazamiento, sino que toma desplazamiento + N filas, luego regresa a la fila de desplazamiento anterior y devuelve N filas. Cuando el desplazamiento es particularmente grande, la eficiencia es muy baja , ya sea para controlar el número total de páginas devueltas o para realizar reescrituras de SQL para páginas que superan un determinado umbral.
Utilice el método de subconsulta para localizar la posición del límite primero y luego regresar.
Por ejemplo: SELECCIONE a.* DE la tabla 1 a, (seleccione la identificación de la tabla 1 donde la condición LIMIT 100000,20) b donde a.id=b.id
6. La declaración de actualización debe colocarse de acuerdo con el índice para evitar el escaneo completo de la tabla y el bloqueo de clave se actualiza a un bloqueo de tabla.
27. ¿Cómo optimizar la consulta de datos de tablas grandes?
- índice de construcción
- a través de caché de redis
- Asignación maestro-esclavo, separación lectura-escritura
- La idea central de la subbase de datos y la subtabla es almacenar datos de manera descentralizada, de modo que el volumen de datos de una sola base de datos/tabla se reduzca para aliviar el problema de rendimiento de una sola base de datos, mejorando así el rendimiento general. de la base de datos.
Redis
concepto basico
1. ¿Por qué utilizar Redis como caché de MySQL?
Principalmente porque Redis tiene dos características de alto rendimiento y alta concurrencia.
- Alto rendimiento: el acceso a los datos desde MySQL se lee desde el disco duro, mientras que el uso de Redis se lee desde la memoria, lo que es más eficiente.
- Alta concurrencia: el QPS de un solo Redis puede manejar solicitudes por segundo 10 veces más que MySQL, y la cantidad de solicitudes que pueden tolerarse mediante el acceso directo a Redis es mucho mayor que la del acceso directo a MySQL.
estructura de datos
2. ¿Qué tipos de datos contiene Redis? ¿Cuál es el escenario de uso?
- Los escenarios de aplicación de tipo cadena incluyen: objetos de caché, bloqueos distribuidos e información de sesión compartida.
- Tipo de lista, los escenarios de aplicación incluyen: cola de mensajes. (Sin embargo, hay dos problemas: 1. El productor necesita realizar una identificación global única por sí mismo; 2. Los datos no se pueden consumir en forma de consumo)
- Tipo de hash: objeto de caché, carrito de compras, etc.
- Tipo de conjunto: escenarios únicos y que requieren cálculo de agregación (unión, intersección, diferencia), como me gusta, atención común, actividades de lotería, etc.
- Tipo ZSet: escenarios únicos y de clasificación, como tablas de clasificación, llamadas telefónicas y clasificación de nombres.
- BitMap: escenarios de estadísticas de estado binario, como inicio de sesión, evaluación del estado de inicio de sesión del usuario, número total de usuarios registrados consecutivos, etc.;
- HyperLogLog: escenarios para estadísticas de cardinalidad de datos masivos, como estadísticas UV para millones de páginas web.
- GEO: un escenario donde se almacena información de ubicación geográfica, como Didi llamando a un automóvil.
- Stream: cola de mensajes. En comparación con la cola de mensajes basada en el tipo de Lista, Stream puede generar automáticamente una ID de mensaje única a nivel mundial y admite el consumo de datos en forma de grupos de consumidores, y cada grupo de consumidores suscrito recibirá el envío del mensaje.
3. ¿Cómo se implementan los tipos de datos subyacentes de Redis en los cinco escenarios?
-
La capa inferior de la cadena se implementa mediante SDS (Simple Dynamic String), que incluye la longitud de la cadena, la cantidad de espacio asignado para alloc, el indicador de tipo de encabezado y la matriz de caracteres buf que realmente almacena los datos. La cadena de caracteres tradicional en lenguaje C. Las matrices tienen las siguientes ventajas:
- La longitud de la cadena se puede obtener en tiempo O(1)
- Admite la expansión dinámica y reduce la cantidad de asignaciones de memoria a través del mecanismo de preasignación de memoria.
- Lea el contenido de la cadena de acuerdo con la longitud, no con la marca final '/0', por lo que es seguro para archivos binarios.
-
La capa inferior de la lista se implementa mediante lista rápida. Cada nodo en la lista rápida es un ZipList. Al usar ZipList, la tasa de utilización del espacio de ZipList es mayor. El uso de múltiples conexiones ZipList pequeñas puede acelerar la eficiencia de la aplicación de memoria y encontrar múltiples conexiones pequeñas continuas. memoria, mucho más fácil que encontrar una gran porción de espacio de memoria contiguo.
-
ZipList implementa la capa inferior del hash de forma predeterminada, y la versión superior usa listpack, y las dos entradas adyacentes en ZipList almacenan el campo y el valor respectivamente. Sin embargo, cuando la cantidad de datos es grande, se utilizará Dict para la implementación.
-
La capa inferior de Set se implementa en función de Dict, el archivo almacena los datos de Set y el valor almacena nulos. Cuando los datos almacenados son todos tipos de números enteros, se utiliza el conjunto de números enteros IntSet para implementar.
-
ZSet es una lista ordenada, implementada en base a Dict y skiplist.
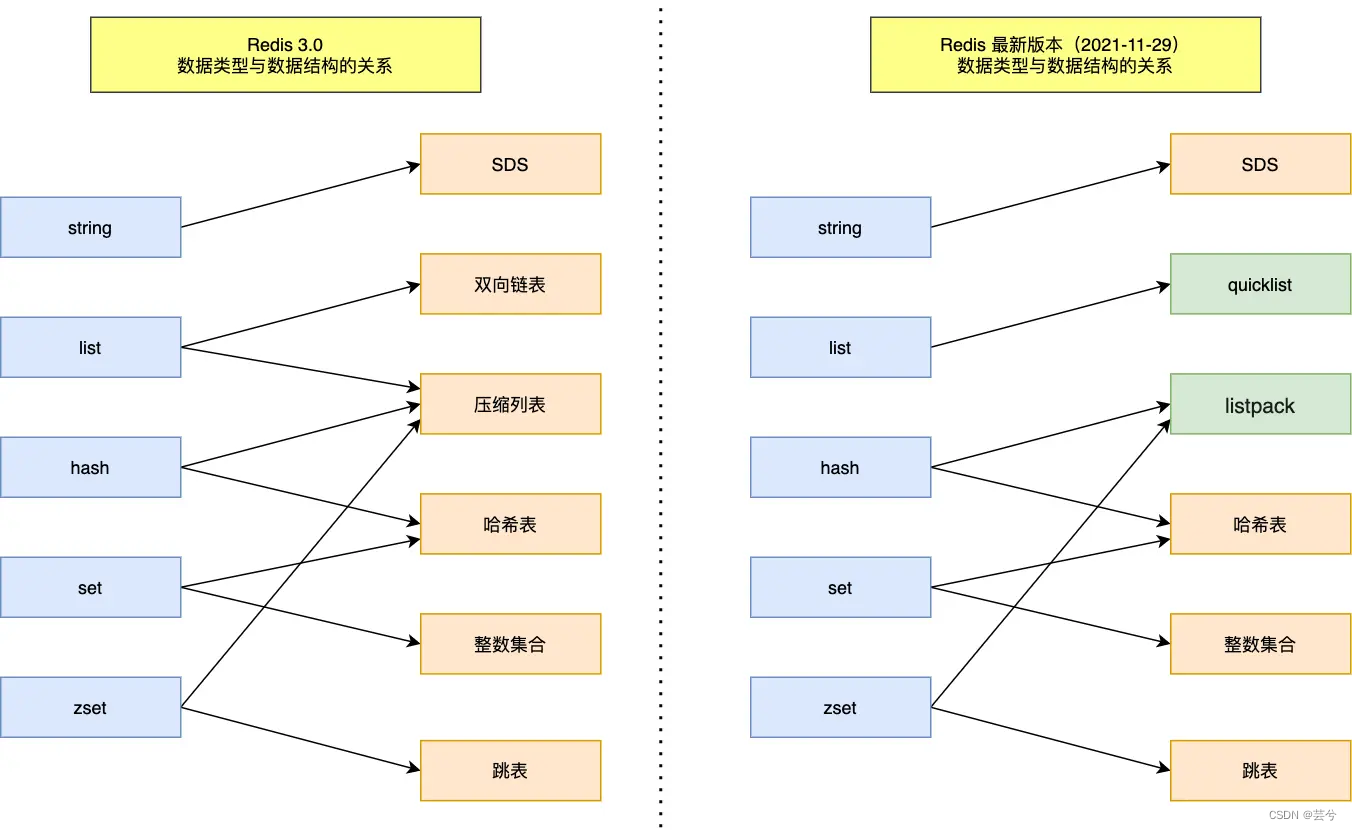
Modelo de red de subprocesos de Redis
4. ¿Redis es de un solo subproceso?
La función principal de Redis, el análisis, la ejecución y el envío de resultados de las instrucciones de adición, eliminación, modificación y consulta de los valores clave de la base de datos se ejecutan mediante un solo subproceso, porque el propio Redis opera en la memoria y la ejecución La eficiencia es muy rápida. Cuando se utilizan subprocesos múltiples, se debe considerar la seguridad de los subprocesos. La sobrecarga de conmutación afectará su eficiencia, pero para algunas funciones no centrales, como el cierre de archivos, el flasheo de AOF, la liberación de memoria y el procesamiento de solicitudes de E/S de red, múltiples -El subproceso se utiliza para mejorar la eficiencia.
La función principal de Redis: recibir solicitudes de instrucciones del cliente, analizar solicitudes, realizar operaciones como lectura y escritura de datos y enviar datos al cliente. Este proceso se completa mediante un hilo (hilo principal), por lo que se puede decir que el núcleo La función de Redis es implementada única por el hilo.
Pero la implementación general de Redis no es de un solo subproceso.
- Redis iniciará 2 subprocesos en segundo plano en la versión 2.6 para manejar las dos tareas de cerrar archivos y flashear AOF respectivamente.
- Después de la versión 4.0 de Redis, se agregó un nuevo subproceso en segundo plano para liberar de forma asincrónica la memoria de Redis, que es un subproceso sin demoras.
- Después de la versión 6.0 de Redis, se utilizan varios subprocesos de E/S para procesar las solicitudes de red.
La razón por la que se crean subprocesos separados para tareas como cerrar archivos, flashear AOF y liberar memoria es porque las operaciones de estas tareas consumen mucho tiempo y, si se completan en el subproceso principal, son propensas a bloquearse.
5. ¿Cuál es el modo de procesamiento de E/S de la red Redis?
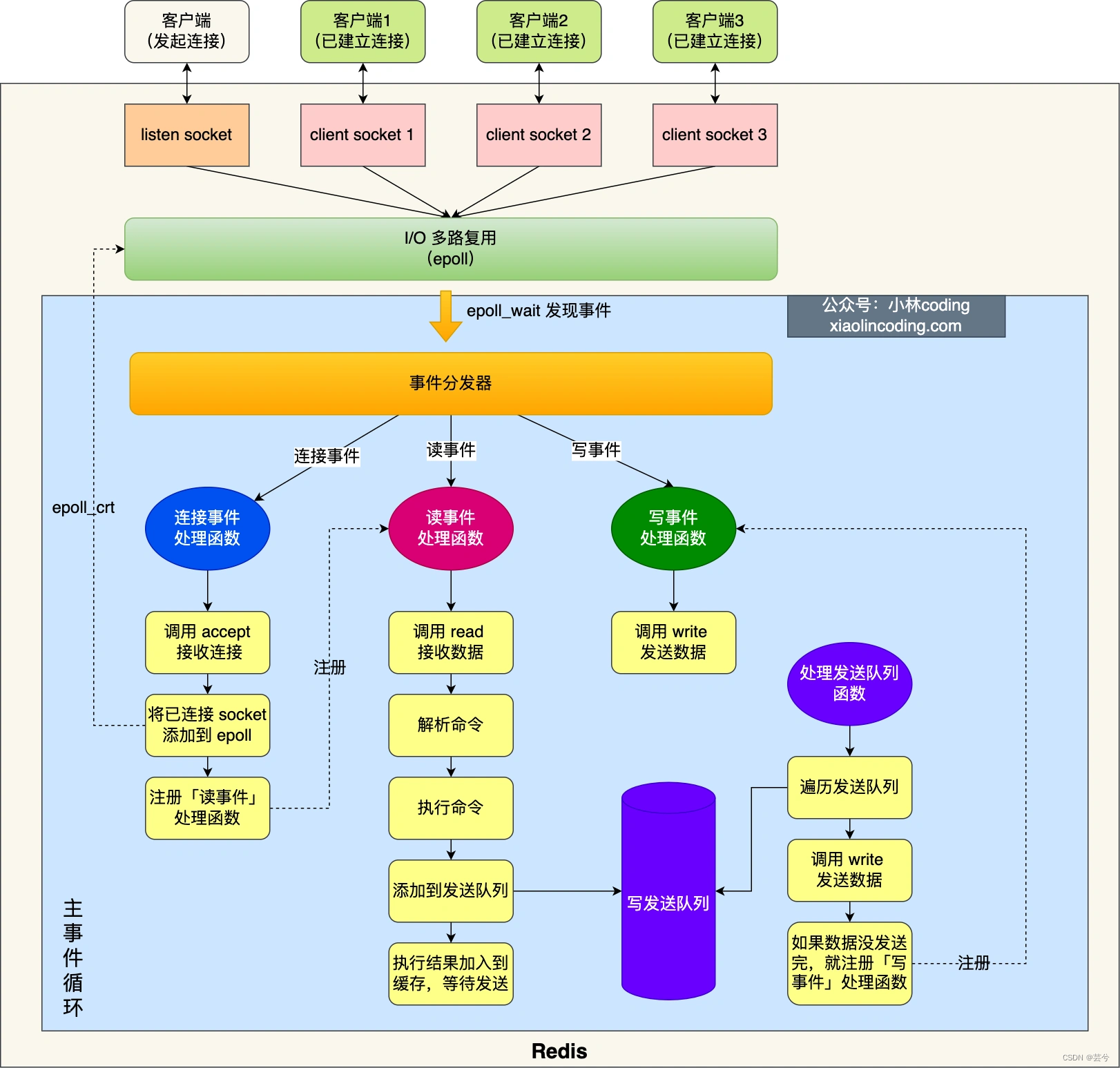
El primer paso: inicialización de Redis:
- Primero llame a epoll_create() para crear un objeto epoll y llame a socket() para crear un socket de servidor.
- Luego llame a bind() para vincular el número de puerto del servidor y llame a listening() para escuchar el socket.
- Llame a epoll_ctl() para agregar el socket de escucha a epoll y registre la función de procesamiento de eventos de conexión al mismo tiempo.
Paso 2: Función de bucle de eventos:
una vez completada la inicialización, el hilo principal ingresa a una función de bucle de eventos , que hace principalmente lo siguiente:
- Primero, llame a la función de cola de envío de procesamiento para ver si hay una tarea para enviar. Si hay una tarea de envío, los datos en el búfer de envío del cliente se envían y procesan a través de la función de escritura. Si no se envían en esta ronda, la función de procesamiento de escritura se registrará y se procesará nuevamente después de que epoll_wait lo descubra. .
- A continuación, llame a la función epoll_wait para esperar a que llegue el evento:
- Si es un evento de conexión, llame a aceptar () para obtener el socket conectado, llame a epoll_ctl para agregar el socket conectado a epoll y registre la función de procesamiento de eventos de lectura.
- Si llega el evento de lectura, llame a la función de procesamiento de eventos de lectura, llame a read () para obtener los datos enviados por el cliente, analice el comando, procese el comando, agregue el objeto del cliente a la cola de envío y escriba el resultado de la ejecución en el envío. buffer y espere el envío.
- Si llega un evento de escritura, se llamará a la función de procesamiento de eventos de escritura y se llamará a la función de escritura () para enviar los datos en el búfer de envío del cliente. Si esta ronda de datos no se ha enviado, la función de procesamiento de eventos de escritura continuar registrado Espere a que epoll_wait descubra que se puede escribir antes de procesarlo.
Persistencia de Redis
6. ¿Cómo previene Redis la pérdida de datos?
Todas las operaciones de lectura y escritura de Redis están en la memoria, por lo que el rendimiento de Redis será alto. Sin embargo, cuando Redis falla o se reinicia, los datos en la memoria se perderán. Para garantizar que los datos en la memoria no se pierdan, Redis implementa un mecanismo de persistencia de datos: almacena los datos en el disco para que los datos originales se puedan restaurar desde el disco cuando Redis se reinicie.
Redis tiene los siguientes tres métodos de persistencia de datos:
- Instantánea RDB: escribe los datos de la memoria en un momento determinado en el disco en forma binaria.
- Registro AOF: cada vez que se ejecuta un comando de operación de escritura, escriba el comando en un archivo en forma de anexo;
- El método de persistencia híbrido, después de Redis4.0, integra las ventajas respectivas de AOF y RDB.
7. ¿Cómo realizar una instantánea RDB?
Redis proporciona dos comandos para generar archivos RDB, a saber, guardar y bgsave.
- El comando de guardar se ejecuta en el hilo principal para generar un archivo RDB, que bloqueará el hilo principal. Durante este período, no se pueden ejecutar instrucciones de Redis.
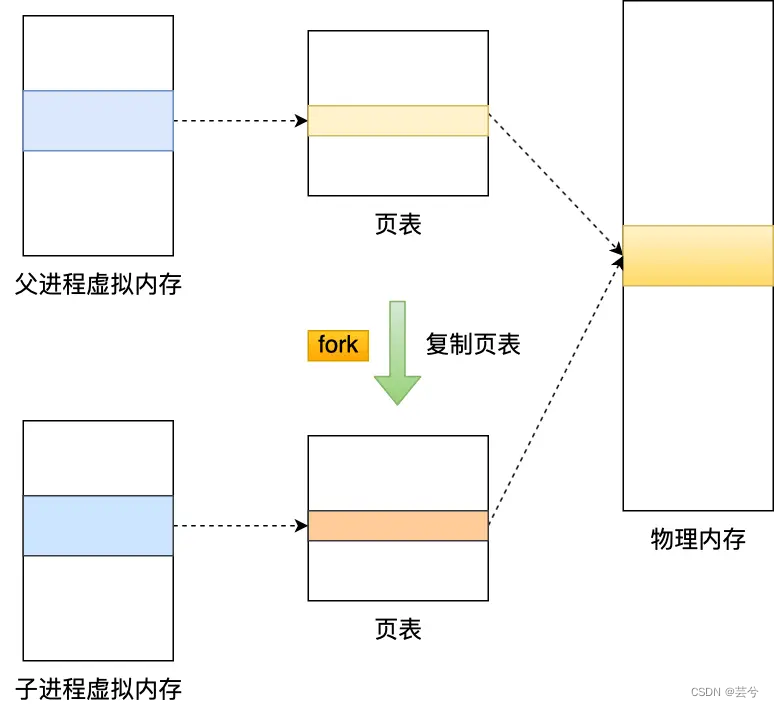
- El comando bgsave, es decir, el guardado en segundo plano, ejecuta el comando bgsave, bifurcará () creará un proceso hijo y copiará la tabla de páginas del proceso padre, pero la memoria física a la que apuntan las tablas de páginas del padre y el hijo Los procesos siguen siendo los mismos. Si se realiza una operación de lectura en este momento, los procesos padre e hijo son mutuos. No afecta, pero si se realiza una operación de escritura, se creará una copia de los datos modificados y luego bgsave El subproceso escribirá la copia en el archivo RDB.
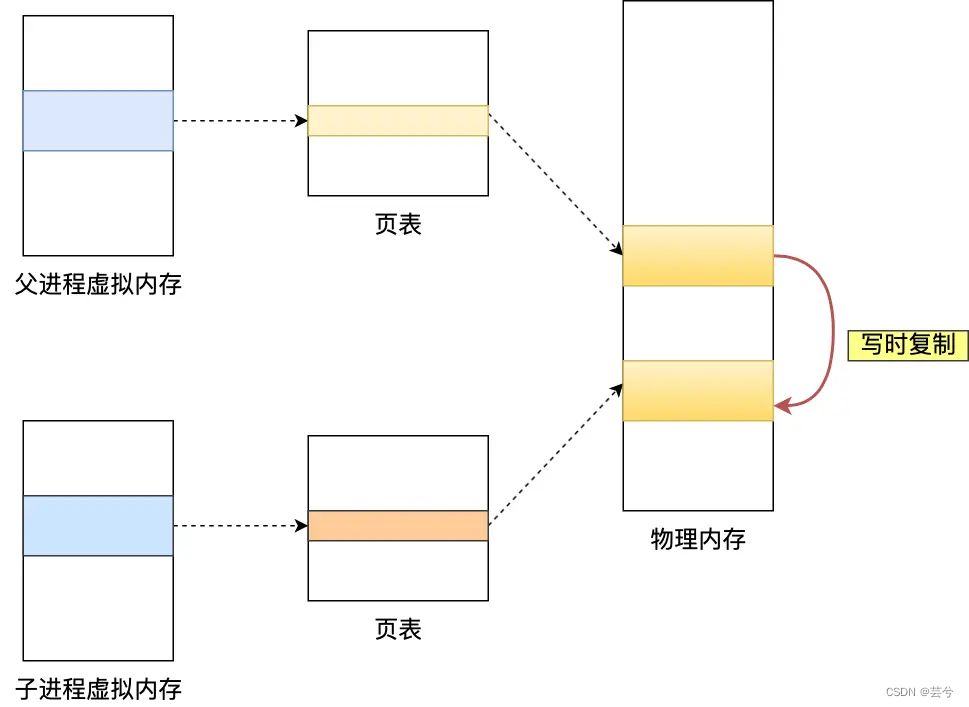
En casos extremos, si se modifica toda la memoria compartida, ¡el uso de memoria en este momento es el doble del original! ! ! . Por lo tanto, Redis debería reservar memoria al usarlo.
8. ¿Cómo realizar el registro AOF?
Concepto AOF:
AOF (solo agregar archivo): después de que Redis ejecuta un comando de operación de escritura, agregará el comando a un archivo y luego, cuando Redis se reinicie, leerá los comandos grabados en el archivo y los ejecutará uno por uno. restaurar datos.
AOF activa la reescritura:
a medida que el registro de AOF ejecuta más y más comandos de operación de escritura, el tamaño del archivo se vuelve cada vez más grande. Cuando el tamaño excede el umbral establecido, Redis habilitará el mecanismo de reescritura de AOF. Si el mecanismo de reescritura no se utiliza antes, si Los dos comandos "establecer nombre xiaolin" y "establecer nombre xiaolincoding" se ejecutan antes y después, estos dos comandos se grabarán en el archivo AOF. Después de usar el mecanismo de reescritura, se leerá el último valor (par clave-valor) del nombre y luego se usará el comando "establecer nombre xiaolincoding" para grabar en el nuevo archivo AOF. No es necesario registrar el primer comando antes, porque pertenece al comando "Historial" y no tiene ningún efecto.
Proceso de reescritura de AOF: el proceso de reescritura de AOF de Redis se realiza
mediante un subproceso en segundo plano . bgwriteaofDurante la reescritura de AOF del subproceso, el proceso principal puede continuar emitiendo solicitudes de comando para evitar bloquear el proceso principal. El proceso secundario de reescritura es de solo lectura en la memoria, convierte el par clave-valor de los datos de la memoria en un comando y luego registra el comando en el registro de reescritura (nuevo archivo AOF).
Si el proceso principal modifica los datos existentes en el registro AOF de reescritura, se producirá una copia en escritura. Redis configura un búfer de reescritura AOF, que bgwriteaofcomienza a usarse después del proceso hijo. Durante la reescritura de AOF, cuando Redis ejecuta un comando de escritura, escribirá el comando de escritura en el búfer AOF y en AOF al mismo tiempo. buffer. Cuando el proceso hijo complete el trabajo de reescritura de AOF, se enviará una señal al proceso principal. Después de que el proceso principal reciba la señal, agregará todo el contenido del búfer de reescritura AOF al nuevo archivo AOF, de modo que el estado de la base de datos guardado por los archivos AOF antiguos y nuevos sea consistente, y el nuevo archivo AOF pasará a llamarse sobrescriba el archivo .AOF existente.
9. ¿Cómo lograr la persistencia híbrida?
- La ventaja de RDB es que solo se guardan los datos registrados en la memoria, la recuperación es rápida y el archivo es pequeño, pero existe el riesgo de pérdida de datos y seguridad insuficiente. La frecuencia de RDB también es difícil de captar. Si la frecuencia es demasiado baja, la pérdida de datos será mayor. Si la frecuencia es demasiado alta, el rendimiento se verá afectado.
- La ventaja de AOF es que hay menos pérdida de datos y es más seguro, pero el archivo AOF suele ser relativamente grande, pero la velocidad de recuperación de datos es lenta.
- Redis 4.0 propone el uso mixto de AOF y RDB para integrar sus respectivas ventajas. Cuando la persistencia híbrida está habilitada, cuando AOF reescribe el registro, el proceso secundario reescrito desde la bifurcación primero escribirá los datos de la memoria compartida con el hilo principal en el archivo AOF en modo RDB, y luego el comando de operación de procesamiento del hilo principal se registrará en el búfer de reescritura, los comandos incrementales en el búfer de reescritura se escribirán en el archivo AOF en modo AOF. Una vez completada la escritura, se notificará al proceso principal para que reemplace el antiguo AOF con el nuevo archivo AOF que contiene el formato RDB y el documento en formato AOF. .
Es decir, durante la persistencia híbrida, la primera mitad del archivo AOF son datos completos en formato RDB y la segunda mitad son datos incrementales en formato AOF.
La ventaja de esto es que al reiniciar Redis para cargar datos, dado que la primera mitad es contenido RDB, la velocidad de carga será muy rápida. Después de cargar el contenido RDB, se cargará la segunda mitad del contenido AOF. El contenido aquí es el comando de operación procesado por el hilo principal durante la reescritura de AOF por el subproceso en segundo plano de Redis, lo que puede reducir la pérdida de datos.
Diseño de caché de Redis
10. ¿Cómo evitar la penetración, la avalancha y la avería de la caché?
penetración de caché
La penetración de la caché se refiere a las solicitudes de los clientes
数据在缓冲中和数据库中都不存在, por lo que la caché nunca tendrá efecto y estas solicitudes se incluirán en la base de datos.
Generalmente existen dos situaciones en las que se produce la penetración de la caché:
- Mal funcionamiento comercial, los datos en el caché y los datos en la base de datos se eliminan por error, por lo que no hay datos en el caché ni en la base de datos;
- Los piratas informáticos atacan maliciosamente y acceden intencionadamente a una gran cantidad de servicios que leen datos inexistentes;
Hay tres opciones comunes:
- 1. Restringir las solicitudes ilegales: en la entrada de la API, juzgue si los parámetros de la solicitud son razonables y si se trata de una solicitud maliciosa.
- 2. Almacene en caché los valores nulos y establezca un TTL más corto. Las solicitudes posteriores llegarán al caché, pero al mismo tiempo, para evitar una gran cantidad de dichos cachés, se borran automáticamente configurando un TTL más corto.
- 3. Utilice el filtro Bloom para determinar si los datos existen. Al escribir datos en la base de datos, use el filtro Bloom para hacer una marca. Cuando el usuario lo solicita, después de que la empresa juzga que el caché no es válido, puede determinar rápidamente si los datos existen consultando el filtro Bloom. Si no existe, no consulte la base de datos.
avalancha de caché
大量缓存数据在同一时间过期(失效)时Si hay una gran cantidad de solicitudes de usuarios en este momento, no se pueden procesar en Redis, por lo que todas las solicitudes acceden directamente a la base de datos, lo que provocará un aumento repentino de la presión sobre la base de datos y provocará una caída grave de la base de datos. , formando así una serie de reacciones en cadena, el sistema falla, este es el problema de la avalancha de caché.
Para el problema de la avalancha de caché: podemos solucionarlo con las siguientes soluciones:
- 1. Codifique aleatoriamente el tiempo de vencimiento del búfer TTL para reducir la probabilidad de falla de la caché colectiva.
- 2. Utilice el clúster de Redis para mejorar la disponibilidad del servicio.
- 3. Agregue una estrategia de limitación actual degradada al negocio de caché
- 4. Agregue caché multinivel a la empresa.
desglose del caché
El problema de avería del caché también se denomina
热点keyproblema. Es un problema高并发访问并且缓存重建业务较复杂的key突然失效了(invalidación de la clave del punto de acceso). Innumerables solicitudes de acceso traerán un gran impacto a la base de datos en un instante y varios subprocesos intentarán reconstruir el caché, lo que provocará un rendimiento deficiente del servidor. . Pero en realidad sólo un hilo que reconstruye el caché es suficiente.
El desglose de caché es muy similar a la avalancha de caché; puede pensar en el desglose de caché como un subconjunto de la avalancha de caché.
Las soluciones comunes son las siguientes:
- 1. No configure TTL para la clave del punto de acceso y actualice el caché de forma asincrónica en segundo plano, o notifique al hilo en segundo plano con anticipación para actualizar el caché y restablecer el tiempo de vencimiento antes de que los datos del punto de acceso estén a punto de caducar;
- 2. Bloquee el proceso de reconstrucción del caché y bloquee otros subprocesos sin bloqueos para garantizar que solo un subproceso comercial reconstruya el caché al mismo tiempo. Sin embargo, el mutex hace que varios subprocesos esperen, lo que seguirá afectando el rendimiento.
- 3. Según la política de vencimiento lógico, configure el campo de vencimiento lógico para el caché
expire. El primer subproceso que encuentra el vencimiento del caché obtiene el bloqueo, inicia un nuevo subproceso, ejecuta el vencimiento de la reconstrucción del caché y devuelve directamente el caché caducado. El resto de los subprocesos que no han adquirido el bloqueo regresarán directamente al caché caducado sin bloquearse hasta que el caché se reconstruya con éxito. Este método es débilmente consistente, pero el rendimiento será mejor.
11. ¿Cómo mantener la coherencia entre la base de datos y el caché?
Las estrategias comunes de actualización de caché incluyen:
- Política de caché aparte
- Estrategia de lectura/escritura (lectura/escritura)
- Política de reescritura
En el desarrollo real, las estrategias de actualización de Redis y MySQL son estrategias de caché aparte (evitar caché).
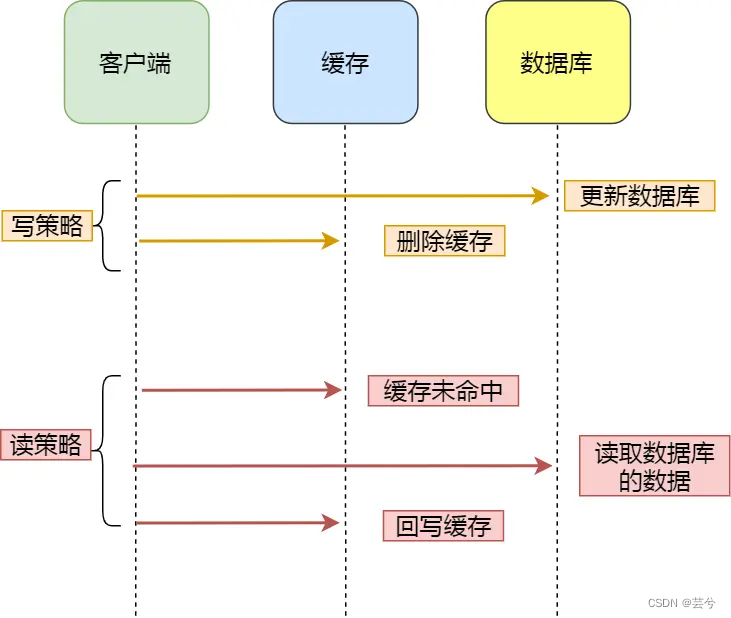
La estrategia Cache Aside (bypass cache) es la más utilizada. La aplicación interactúa directamente con la base de datos y el caché, y es responsable de mantener el caché. Esta estrategia se puede subdividir en una estrategia de lectura y una estrategia de escritura.
-
Estrategia de escritura: primero actualice los datos en la base de datos y luego elimine los datos en el caché.
-
Estrategia de lectura: si los datos leídos llegan directamente al caché, los datos se devuelven directamente; si no hay ningún resultado, los datos se leen de la base de datos y luego se escriben en el caché.
Al escribir datos, actualice la base de datos primero y luego actualice el caché. Puede haber problemas durante la concurrencia:
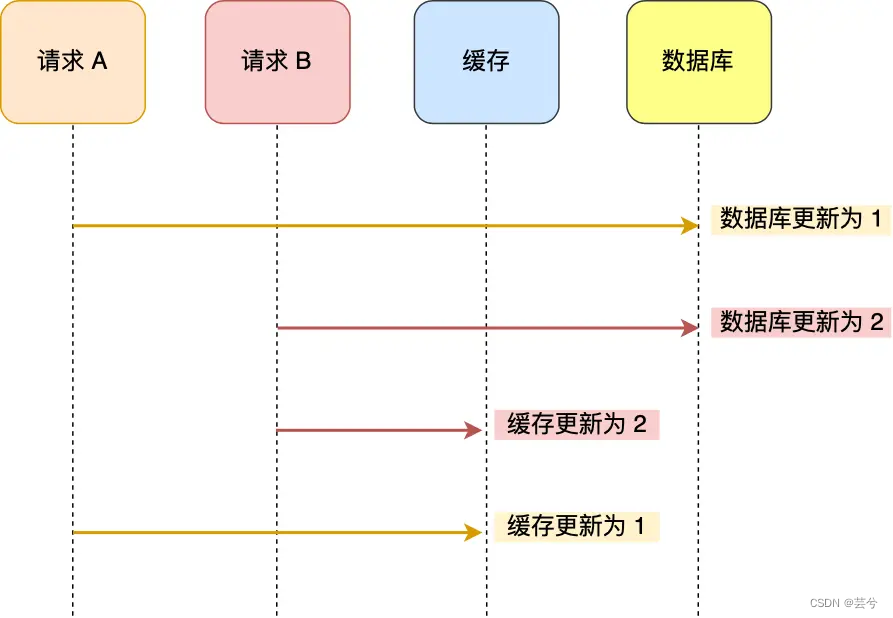
para evitar la inconsistencia entre el caché y los datos anteriores, al escribir datos, elimine el caché después de actualizar la base de datos.
Entonces, ¿por qué actualizar la base de datos primero y luego eliminar el caché?
Debido a que la operación en el caché es más rápida que la operación en la base de datos, primero actualice el caché y luego actualice la base de datos, la diferencia de tiempo entre las inconsistencias de los datos es mayor, lo que resulta en resultados inconsistentes. de la base de datos y el caché ¡La probabilidad es mayor! Pero primero actualice la base de datos y luego elimine el caché, el tiempo para eliminar el caché es más rápido y la diferencia de tiempo en el medio es menor.
12. ¿Cuál es la estrategia de eliminación por vencimiento de Redis?
Siempre que configuramos un TTL para una clave, cuando Redis construye los datos de la clave, también almacenará un diccionario caducado (expire dict). Cuando consultamos una clave, Redis primero verifica si la clave existe en el diccionario caducado. Si no existe se leerá correctamente, si existe comprobará el tiempo de caducidad de la clave y lo comparará con el tiempo actual para detectar si la clave ha caducado.
La estrategia de eliminación vencida adoptada por Redis es eliminación diferida + eliminación regular
El enfoque de la estrategia de eliminación diferida es no eliminar activamente la clave caducada y comprobar si la clave ha caducado cada vez que se accede a ella desde la base de datos, y eliminar la clave si está caducada.
-
Ventajas: debido a que se verifica la caducidad de la clave cada vez que se accede, esta estrategia utiliza muy pocos recursos del sistema, por lo que la estrategia de eliminación diferida es la más amigable con el tiempo de CPU.
-
Desventajas: si una clave ha caducado, pero aún se conserva en la base de datos y no se ha accedido a ella, se desperdicia espacio en la memoria.
Por esta razón, Redis utilizará una estrategia de eliminación regular para cooperar con la estrategia de eliminación diferida anterior.
La estrategia de eliminación habitual es tomar una cierta cantidad de claves de la base de datos "al azar" para inspeccionarlas de vez en cuando y eliminar las claves caducadas.
La eliminación periódica tiene dos modos de trabajo:
- En la función initServer () de Redis, la clave caducada se limpiará de acuerdo con la frecuencia de server.hz, el modo es LENTO y el valor predeterminado es 10 veces por segundo.
- Antes de cada bucle de eventos de Redis, se vuelve a llamar a la función beforeSleep() para realizar la limpieza de las claves caducadas y el modo es RÁPIDO.
- SLOW reproduce frecuencias bajas pero limpia más a fondo. El modelo FAST se ejecuta a altas frecuencias, pero a intervalos cortos.
13. ¿Cuáles son las estrategias de eliminación de memoria de Redis?
Momento de implementar la estrategia de eliminación de memoria:
Redis activará el mecanismo de eliminación de memoria si se encuentra OOM en el método ProcessCommand() para procesar los comandos del cliente.
Redis admite 8 estrategias diferentes para la eliminación de claves: la estrategia de eliminación predeterminada es:
1. no desalojo, no se elimina ninguna clave, pero no se permite escribir nuevos datos cuando la memoria está llena.
Otras estrategias comunes de eliminación de memoria generalmente se dividen en procesar todas las claves y procesar claves con TTL configurado.
2. Incluyendo la eliminación prioritaria de claves que caducarán según el TTL.
3-4 Todas las claves se eliminan aleatoriamente y las claves con TTL se eliminan aleatoriamente.
5-6.Eliminar todas las claves o claves con TTL configurado según el algoritmo LRU.
7-8.Eliminar todas las claves o claves con TTL configurado según el algoritmo LFU.
LRU (usado menos recientemente), usado menos recientemente. Reste la hora del último acceso de la hora actual. Cuanto mayor sea el valor, mayor será la prioridad de eliminación.
LRU se basa en el tiempo y es sensible al tiempo. Recientemente, es más probable que las teclas de acceso rápido emergentes residan en la memoria, y es más probable que las teclas que no se han utilizado durante mucho tiempo se eliminen.
LFU (menos utilizado), el menos utilizado. La frecuencia de acceso de cada clave estará unificada, y cuanto menor sea el valor, mayor será la prioridad de eliminación.
LFU es sensible a la frecuencia y es más adecuado para almacenar claves que contienen múltiples puntos de acceso. El último acceso a una determinada clave fue ayer a las 12:00 del mediodía, y en 5 minutos a las 12:00 de ayer, se realizaron 200 accesos de alta frecuencia. Si hoy todavía hay tal demanda al mediodía, según la estrategia de LFU, las teclas de acceso rápido de ayer residirán en la memoria.
Redis maestro-esclavo, clúster de corte
14. ¿Cuáles son los defectos del principio de replicación maestro-esclavo de Redis?
El esquema de implementación de replicación maestro-esclavo de Redis utiliza múltiples servidores Redis, un maestro y varios esclavos , y los servicios maestro-esclavo adoptan el modo de separación de lectura y escritura . El servidor maestro puede realizar operaciones de lectura y escritura. Cuando ocurre una operación de escritura , la operación de escritura se sincronizará automáticamente con el servidor, y el servidor esclavo generalmente está en modo de solo lectura y recibe el comando de operación de escritura sincronizado desde el servidor maestro.
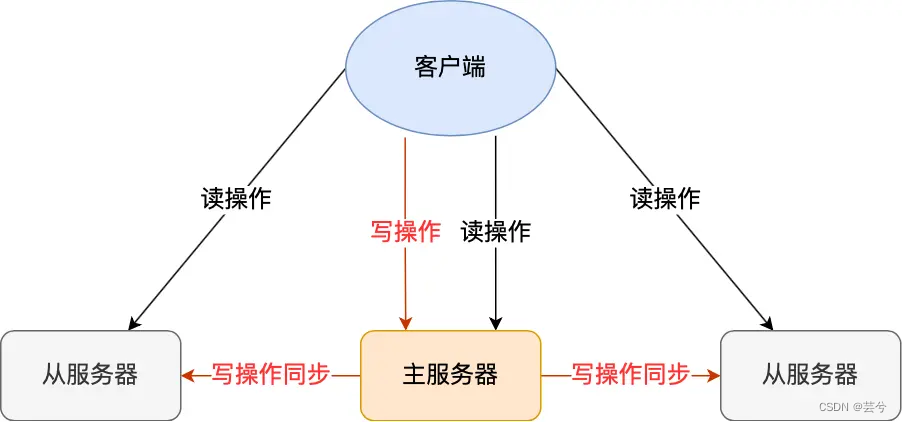
Dado que la replicación de comandos entre los servidores maestro y esclavo es asíncrona, es imposible lograr una gran coherencia entre los datos maestro y esclavo.
El principio de sincronización de datos del servidor maestro-esclavo es el siguiente:
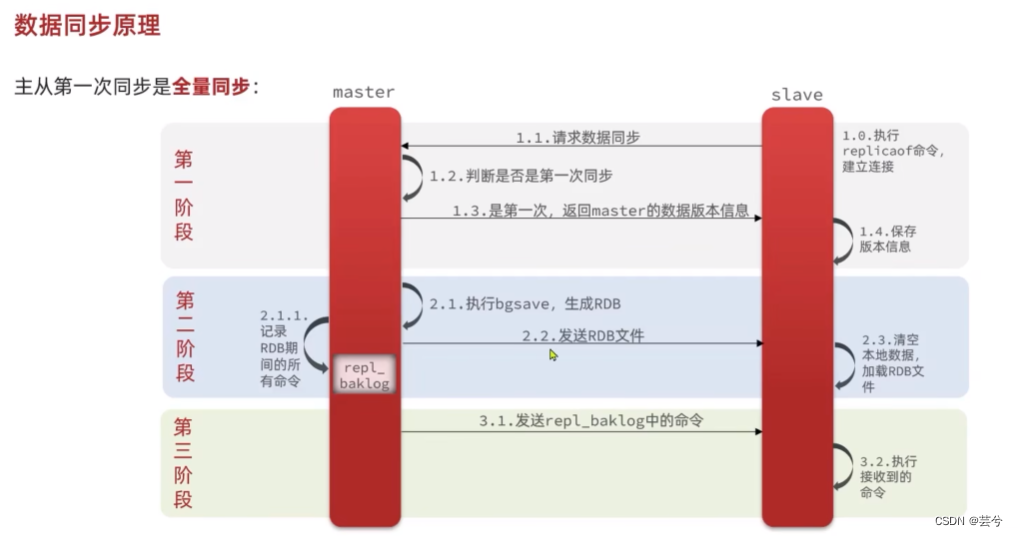
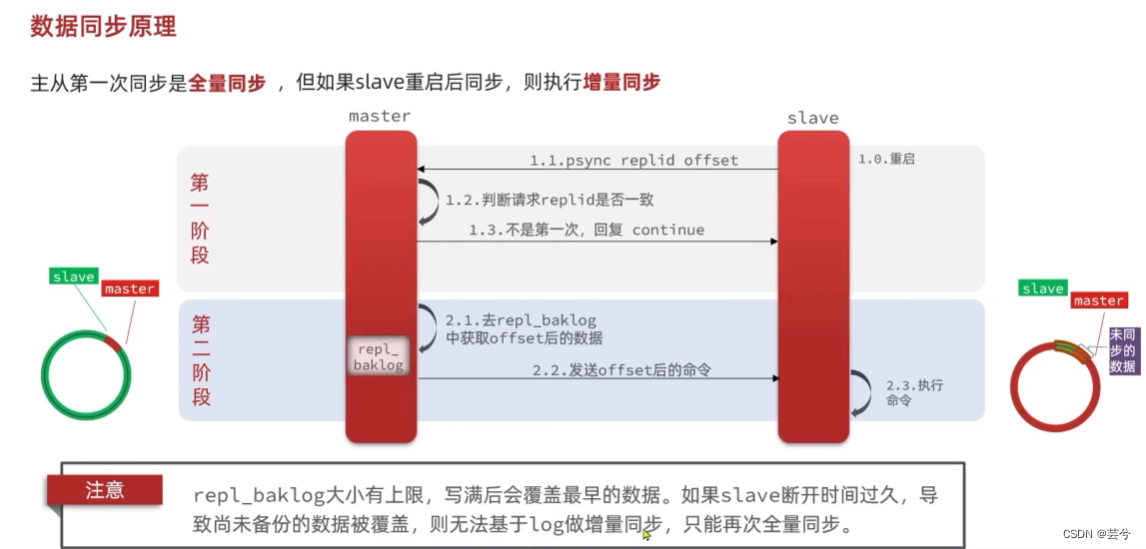
15. ¿Cómo se implementa el mecanismo centinela en el modo maestro-esclavo de Redis?
Redis proporciona un mecanismo Sentinel para realizar la recuperación automática de fallas del clúster maestro-esclavo. Las funciones principales de Sentinel incluyen monitoreo del estado del servidor, recuperación automática de fallas y notificación .
-
Monitoreo del estado del servidor
- El centinela monitorea el estado del servidor según el mecanismo de latido y envía un comando ping a cada instancia del clúster cada 1 segundo; si un centinela descubre que la instancia no responde dentro del tiempo especificado, la instancia se considera subjetivamente desconectada Cuando el número especificado (generalmente mayor que la mitad del número total de centinelas) todos creen subjetivamente que la instancia está fuera de línea y el nodo de la instancia está objetivamente fuera de línea .
- Una vez que se detecta la fuera de línea objetiva del nodo maestro, el primer centinela que encuentre la fuera de línea subjetiva del nodo maestro debe seleccionar uno de los esclavos como nuevo maestro. Bases para la elección:
- Determine el período de tiempo que el nodo esclavo está desconectado del nodo maestro y el esclavo que excede el valor especificado se excluye directamente.
- Determine el valor de prioridad del nodo esclavo; cuanto menor sea el valor, mayor será la prioridad.
- Determine el tamaño de identificación del nodo esclavo en ejecución; cuanto menor sea la identificación, mayor será la prioridad.
-
recuperación automática de fallas
- El esclavo seleccionado ejecuta al esclavo de nadie y se convierte en el nuevo maestro.
- Notifique a todos los demás nodos esclavos que ejecuten el esclavo del nuevo maestro.
- Modifique la configuración del nodo maestro fallido y agregue un esclavo del nuevo maestro.
16. Clúster de fragmentación de Redis
Cuando la cantidad de datos almacenados en caché de Redis es demasiado grande para que un servidor los almacene en caché, es necesario utilizar el esquema de clúster de segmentos de Redis (Redis Cluster), que distribuye los datos en diferentes servidores, para reducir la dependencia del sistema de un solo maestro. nodo, mejorando así el rendimiento de lectura y escritura del servicio Redis.
La solución Redis Cluster utiliza ranuras hash (Hash Slot) para manejar la relación de mapeo entre datos y nodos. En el esquema de Redis Cluster, un clúster de división tiene un total de ranuras hash 16384. Estas ranuras hash son similares a las particiones de datos y cada par clave-valor se asigna a una ranura hash de acuerdo con su clave.
¿Cómo se asignan estas ranuras hash a nodos de Redis específicos? Hay dos opciones:
- Distribución uniforme: cuando se utiliza el comando de creación de clúster para crear un clúster de Redis, Redis distribuirá automáticamente todas las ranuras hash a los nodos del clúster de manera uniforme. Por ejemplo, si hay 9 nodos en el clúster, la cantidad de ranuras en cada nodo es 16384/9.
- Asignación manual: puede usar el comando cluster meet para establecer conexiones manualmente entre nodos para formar un clúster y luego usar el comando cluster addlots para especificar la cantidad de ranuras hash en cada nodo.