Directorio de artículos
Prefacio
Estoy muy feliz de conocerte en el nivel 16. En este punto, has completado el aprendizaje de conocimientos de todos los niveles, ¡felicidades!
Pero eso no significa que este nivel pueda tomarse a la ligera, porque todavía tenemos cosas muy importantes que lograr.
Realizaremos una revisión general del conocimiento anterior de los rastreadores y crearemos un marco de conocimiento. Cuando obtenga requisitos de rastreador más adelante, podrá estar al tanto de ellos y no entrar en pánico.
Como muchas materias, los reptiles son suficientes para empezar, pero en realidad el aprendizaje no tiene fin. Por lo tanto, le proporcionaré una guía de ruta para el aprendizaje avanzado: ¿qué más puede aprender si desea seguir mejorando con los rastreadores?
Y si hay reptiles, naturalmente habrá anti-reptiles. Centrémonos en qué métodos anti-reptiles están disponibles y qué estrategias están disponibles para lidiar con los anti-reptiles.
Siempre creo que cada tema tendrá un núcleo espiritual que se trasciende a sí mismo, sería una lástima que solo domines las habilidades pero no puedas descubrir la belleza del tema. Entonces, al final de este nivel, te dejé una breve carta para hablar sobre las cosas detrás de este curso.
Comencemos ahora.
Revisión general de rastreadores.
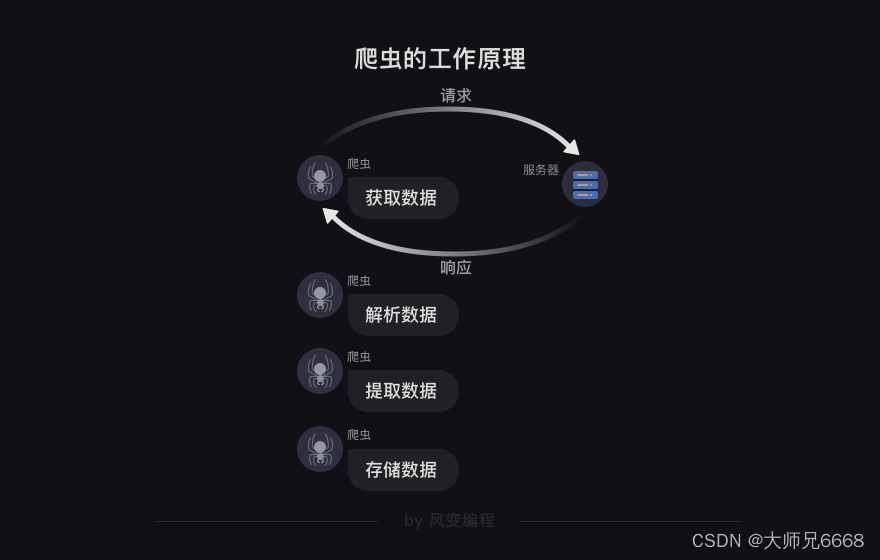
Todavía recuerdo que comenzaba con este diagrama, que se usaba para describir cómo funcionaba el navegador:

Solicitudes y respuestas. Estas dos cosas constituyen casi todo el contenido de aprendizaje que aprenderemos más adelante.
En el nivel 0, cuando hablamos de rastreadores, utilizamos programas para obtener datos que nos sean útiles en Internet. Lo que hace el programa, los pasos más críticos son "solicitud" y "respuesta".
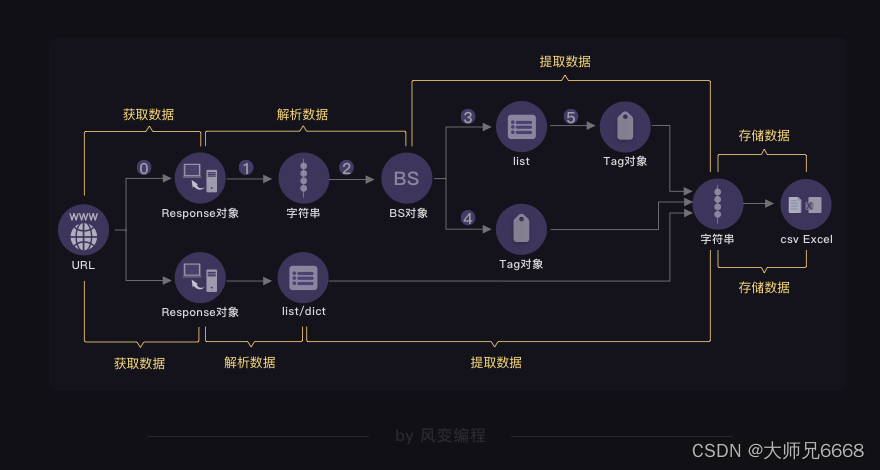
En base a esto, definimos los "cuatro pasos del rastreador": obtener datos (incluidas dos acciones de solicitud y respuesta), analizar datos, extraer datos y almacenar datos.
Al mismo tiempo, también aprendimos el método de solicitud más simple: request.get()
import requests
url = ''
response = requests.get(url)

herramienta
Si quieres hacer bien tu trabajo, primero debes afilar tus herramientas, necesitamos una herramienta con la que podamos ver todas las solicitudes para que podamos completar los cuatro pasos del rastreador. Esta herramienta se llama Red.
La red puede registrar todas las solicitudes realizadas por el navegador. Los que usamos más comúnmente son: ALL (ver todo)/XHR (solo ver XHR)/Doc (Documento, la solicitud 0 suele estar aquí) A veces también miramos: Img (solo ver imágenes)/Media (solo ver Archivos multimedia)/Otro. Finalmente, JS y CSS son códigos front-end, responsables de iniciar solicitudes e implementación de páginas, Font es la fuente del texto, y entender WS y Manifest requiere conocimientos de programación de redes, si no estás especializado en esto, no necesitas entiendelo.
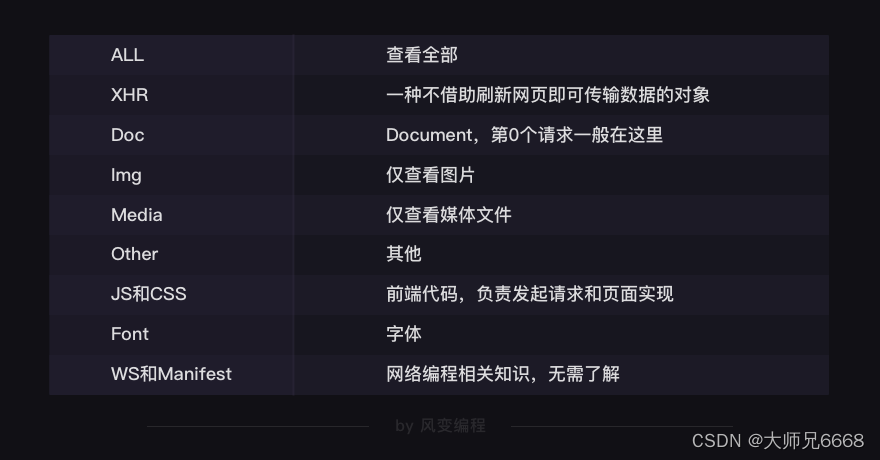
Constituyen todo el contenido de Elements, que son las coloridas páginas web que sueles ver.
En los rastreadores, lo más habitual es que utilicemos XHR y Doc. Podemos encontrar el código fuente de una página web en Doc, y la información que no se puede encontrar en el código fuente de la página web generalmente se puede encontrar en XHR. Con su existencia, las personas pueden cargar contenido nuevo sin tener que actualizar/saltar de la página web. Hoy, si ha aprendido el concepto de "sincronización/asíncrono", también puede decir que XHR nos ayuda a implementar solicitudes asincrónicas.
En cuanto a dónde se ocultan los datos, en el nivel 6 proporcionamos una solución:
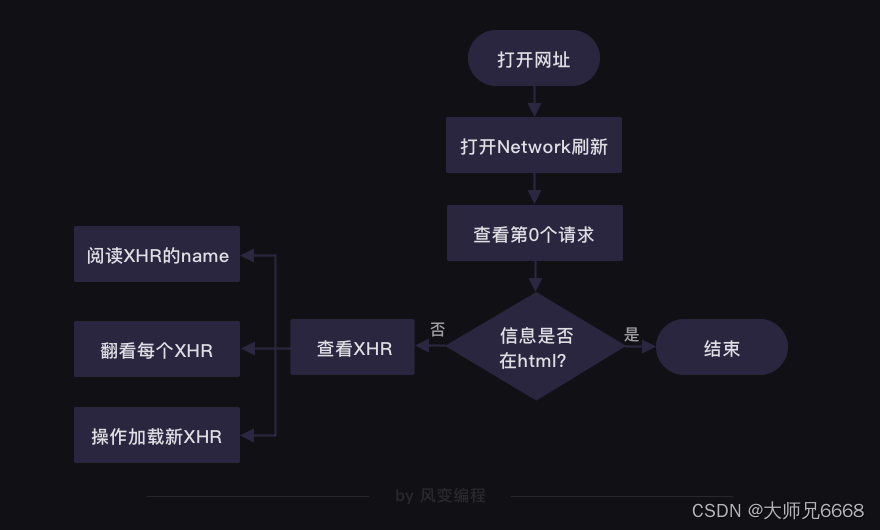
Florecen dos flores, una a cada lado.
Análisis y extracción (1)
Cuando los datos están ocultos en el código fuente de la página web, tenemos una cadena completa de "rastreadores de cuatro pasos". Aquí, la biblioteca más importante se llama BeautifulSoup, que puede proporcionar un conjunto completo de soluciones de análisis y extracción de datos. El uso es el siguiente:
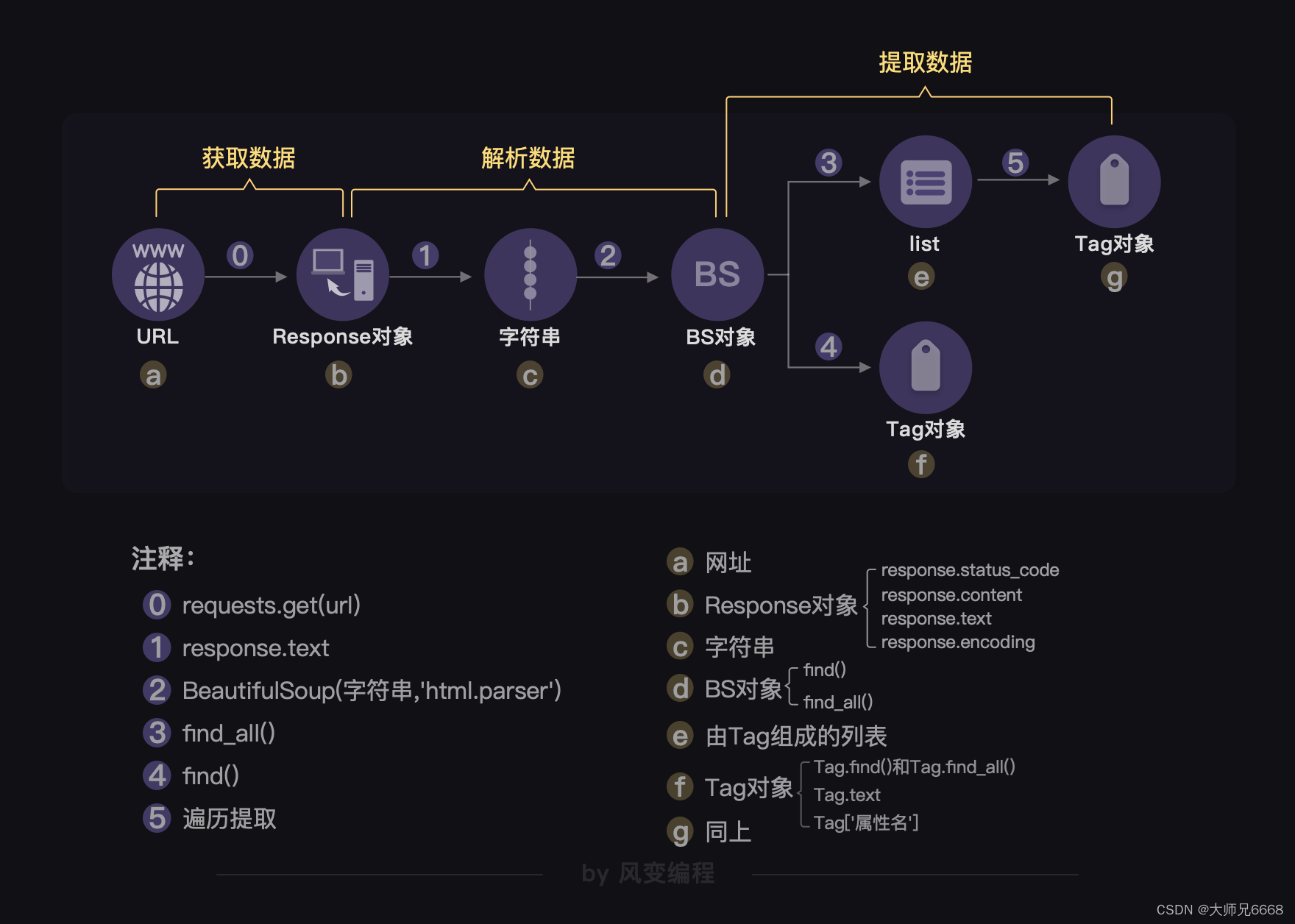
Podemos escribir código como este:
import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
res_foods = requests.get('http://www.xiachufang.com/explore/')
# 获取数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 解析数据
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含菜名和URL的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 查找包含食材的<p>标签
list_all = []
# 创建一个空列表,用于存储信息
for x in range(len(tag_name)):
# 启动一个循环,次数等于菜名的数量
list_food = [tag_name[x].text[18:-15],tag_name[x].find('a')['href'],tag_ingredients[x].text[1:-1]]
# 提取信息,封装为列表
list_all.append(list_food)
# 将信息添加进list_all
print(list_all)
# 打印
# 以下是另外一种解法
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 查找最小父级标签
list_all = []
# 创建一个空列表,用于存储信息
for food in list_foods:
tag_a = food.find('a')
# 提取第0个父级标签中的<a>标签
name = tag_a.text[18:-15]
# 菜名,使用[18:-15]切掉了多余的信息
URL = 'http://www.xiachufang.com'+tag_a['href']
# 获取URL
tag_p = food.find('p',class_='ing ellipsis')
# 提取第0个父级标签中的<p>标签
ingredients = tag_p.text[1:-1]
# 食材,使用[1:-1]切掉了多余的信息
list_all.append([name,URL,ingredients])
# 将菜名、URL、食材,封装为列表,添加进list_all
print(list_all)
# 打印
Aquí quiero enfatizar el problema de la codificación. Incluso muchos veteranos de los rastreadores a menudo tropiezan con la codificación, así que no cometa errores también. Cuando haya un problema con la decodificación automática de Response.text, no dude en utilizar Response.encoding='' para modificar la codificación usted mismo.
Análisis y extracción (2)
Miremos el otro lado de las cosas: cuando los datos aparecen en XHR.
El tipo de datos más importante transmitido por XHR está escrito en formato json y, al igual que html, estos datos pueden almacenar una gran cantidad de contenido de forma organizada. El tipo de datos de json es "texto", en el lenguaje Python lo llamamos cadena. Podemos convertir fácilmente datos en formato json en listas/diccionarios, y también podemos convertir diccionarios/listas en datos en formato json.
¿Cómo analizar datos json? La respuesta es la siguiente:
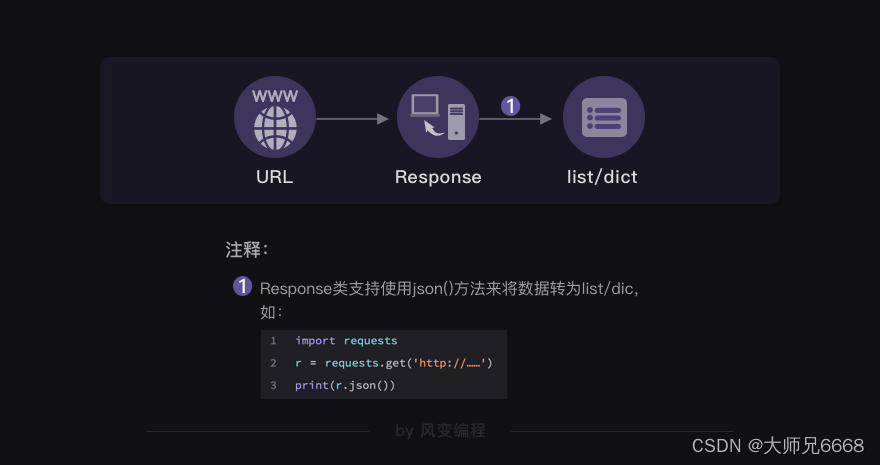
Naturalmente, la extracción no es difícil; después de todo, se ha convertido en una lista/diccionario. Estás muy familiarizado con las listas/diccionarios. Finalmente, tienes esta imagen en tu mente:
Una petición más poderosa
Lo interesante es la solicitud en sí. En estudios anteriores, en realidad solo hay un parámetro en request.get(), que es la URL.
Pero, de hecho, esta solicitud puede tener múltiples parámetros.
params nos permite solicitar datos con parámetros: ¿Qué página quiero? ¿Palabras clave que quiero buscar? ¿Cuantos datos quiero?
encabezados, encabezados de solicitud. ¿Qué le dice al servidor, cuál es mi dispositivo/navegador? ¿De qué página vengo?
Más tarde, descubrirá que además de la solicitud de obtención, existe otro método de solicitud: publicar. La diferencia entre publicar y obtener es que obtener es un parámetro de visualización de texto claro y publicar es un parámetro de visualización de texto no claro. Después de aprender a publicar, tienes dos parámetros más disponibles:
En la solicitud de publicación, usamos datos para pasar parámetros y su uso es muy similar a los parámetros.
Galletas, el nombre chino es "pequeñas galletas". Pero no tiene nada que ver con las "galletas". Su función es permitir que el servidor "te recuerde". Por ejemplo, generalmente cuando inicias sesión en un sitio web, verás una opción marcada "Recordarme" en la página de inicio de sesión. Si hace clic en la casilla de verificación, el servidor generará una cookie y la vinculará a su cuenta. Luego, informa a su navegador sobre la cookie, lo que le permite almacenar la cookie en su computadora local. La próxima vez que el navegador acceda al blog con cookies, el servidor sabrá quién es usted y podrá acceder directamente sin tener que volver a introducir su cuenta y contraseña.
En este punto, consideremos el caso extremo. Su código podría verse así:
import requests
# 定义url_1,headers和data
url_1 = 'https://…'
headers = {
'user-agent':''}
data = {
}
login_in = requests.post(url,headers=headers,data=data)
cookies = login_in.cookies
# 完成登录,获取cookies
url_2 = 'https://…'
params = {
}
# 定义url和params
response = requests.get(url,headers=headers,params=params,cookies=cookies)
# 带着cookies重新发起请求
almacenamiento
Obtenga datos de varias maneras, analice y extraiga datos de varias maneras. Lo llevará a la última parada: almacenar datos.
Hay muchas formas de almacenar datos, las más comunes son: csv y excel.


#csv写入的代码:
import csv
csv_file=open('demo.csv','w',newline='')
writer = csv.writer(csv_file)
writer.writerow(['电影','豆瓣评分'])
csv_file.close()

#csv读取的代码:
import csv
csv_file=open('demo.csv','r',newline='')
reader=csv.reader(csv_file)
for row in reader:
print(row)

#Excel写入的代码:
import openpyxl
wb=openpyxl.Workbook()
sheet=wb.active
sheet.title='new title'
sheet['A1'] = '漫威宇宙'
rows= [['美国队长','钢铁侠','蜘蛛侠','雷神'],['是','漫威','宇宙', '经典','人物']]
for i in rows:
sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')

#Excel读取的代码:
import openpyxl
wb = openpyxl.load_workbook('Marvel.xlsx')
sheet=wb['new title']
sheetname = wb.sheetnames
print(sheetname)
A1_value=sheet['A1'].value
print(A1_value)
Más rastreadores
Desde la perspectiva de los cuatro pasos de un rastreador, hay pocos rastreadores en el mundo que no puedas manejar. Debido a que puedes simular todas las solicitudes con código Python, sabes cómo analizar todas las respuestas. Cuando obtenga requisitos de rastreador más adelante, podrá estar al tanto de ellos y no entrar en pánico.
Pero ¿qué pasa si hay tantos datos que rastrear que el programa se ralentiza? Utilice corrutinas.
Sincrónico y asincrónico -
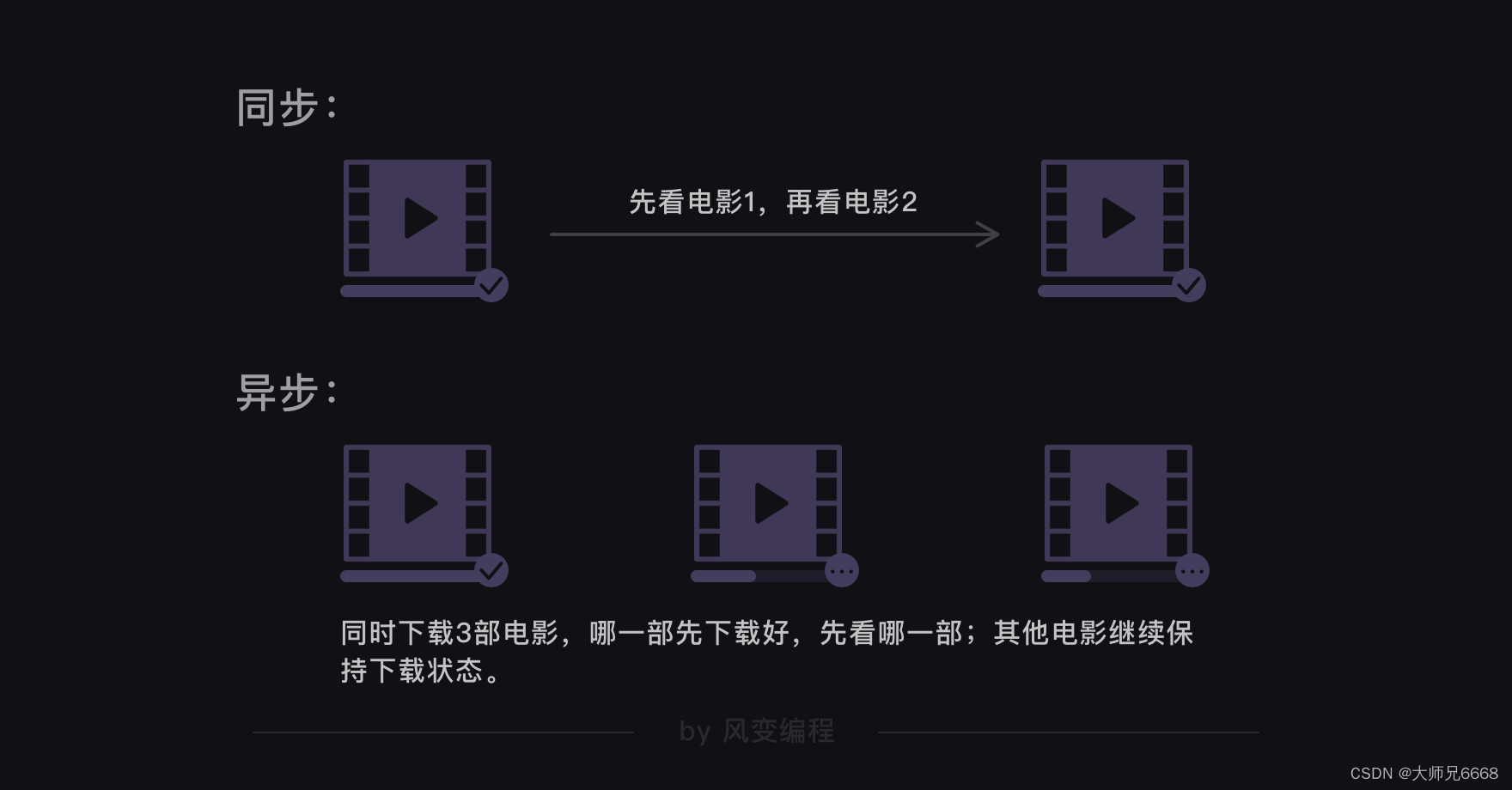
La multicorrutina es un método asincrónico no preventivo. Mediante el uso de múltiples corrutinas, se pueden ejecutar múltiples tareas de rastreo de forma alternativa y asincrónica.


A continuación se muestra el código de muestra:
import gevent,time,requests
from gevent.queue import Queue
from gevent import monkey
monkey.patch_all()
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
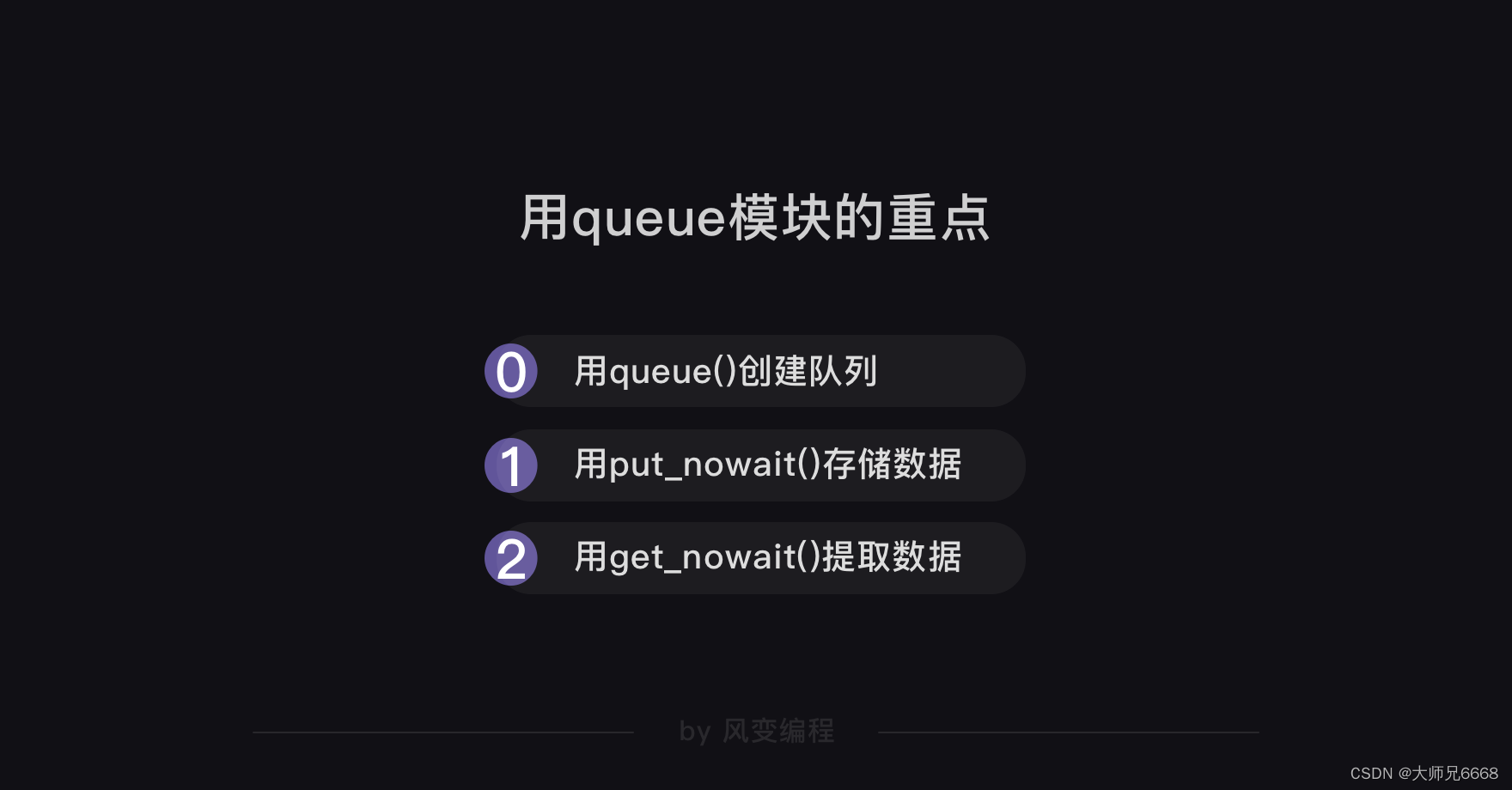
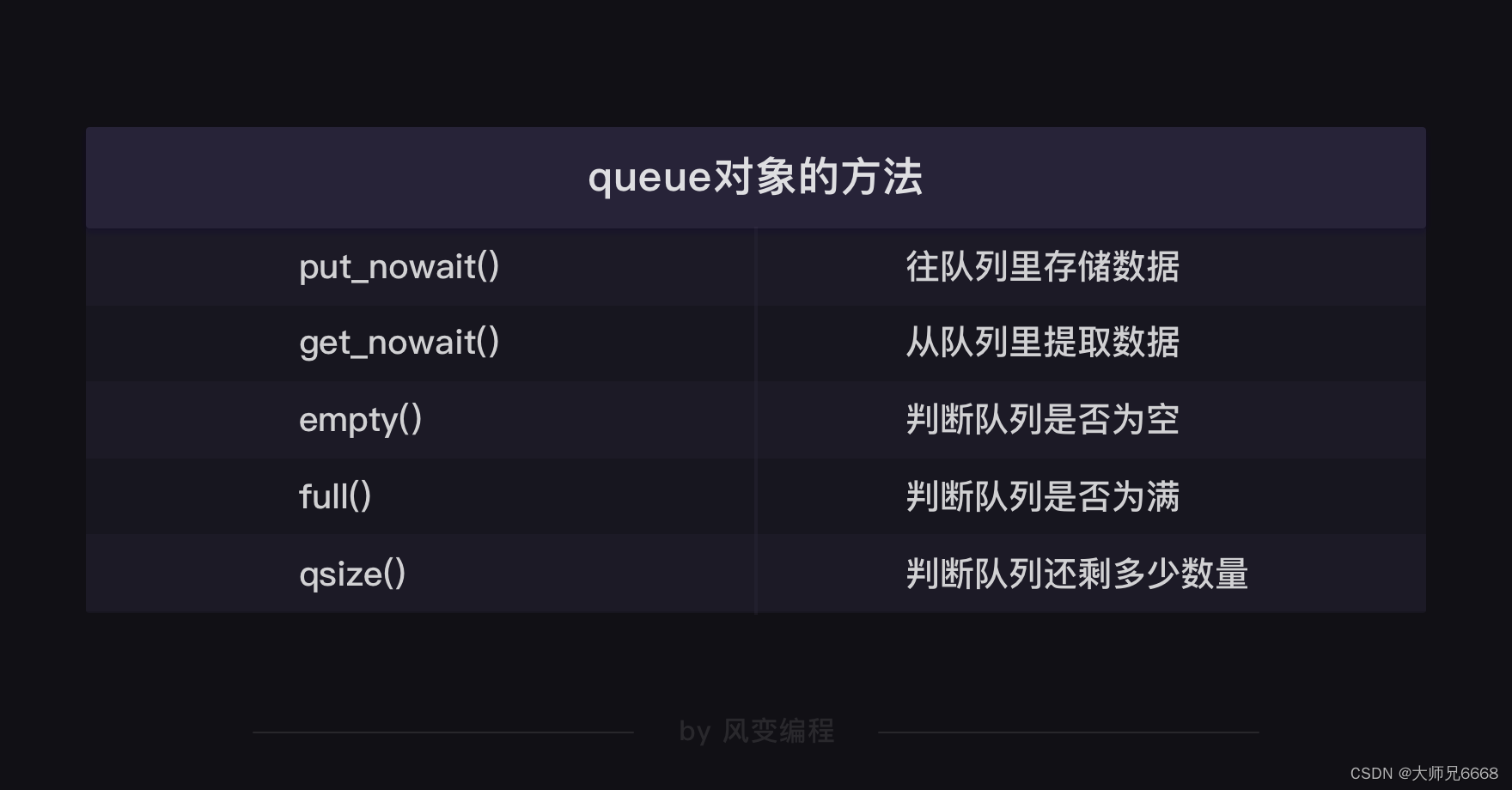
work = Queue()
for url in url_list:
work.put_nowait(url)
def crawler():
while not work.empty():
url = work.get_nowait()
r = requests.get(url)
print(url,work.qsize(),r.status_code)
tasks_list = [ ]
for x in range(2):
task = gevent.spawn(crawler)
tasks_list.append(task)
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
Rastreador más potente: marco
A medida que escriba más y más código de rastreador, un marco integral que resuelva todos los problemas del rastreador le resultará cada vez más atractivo.
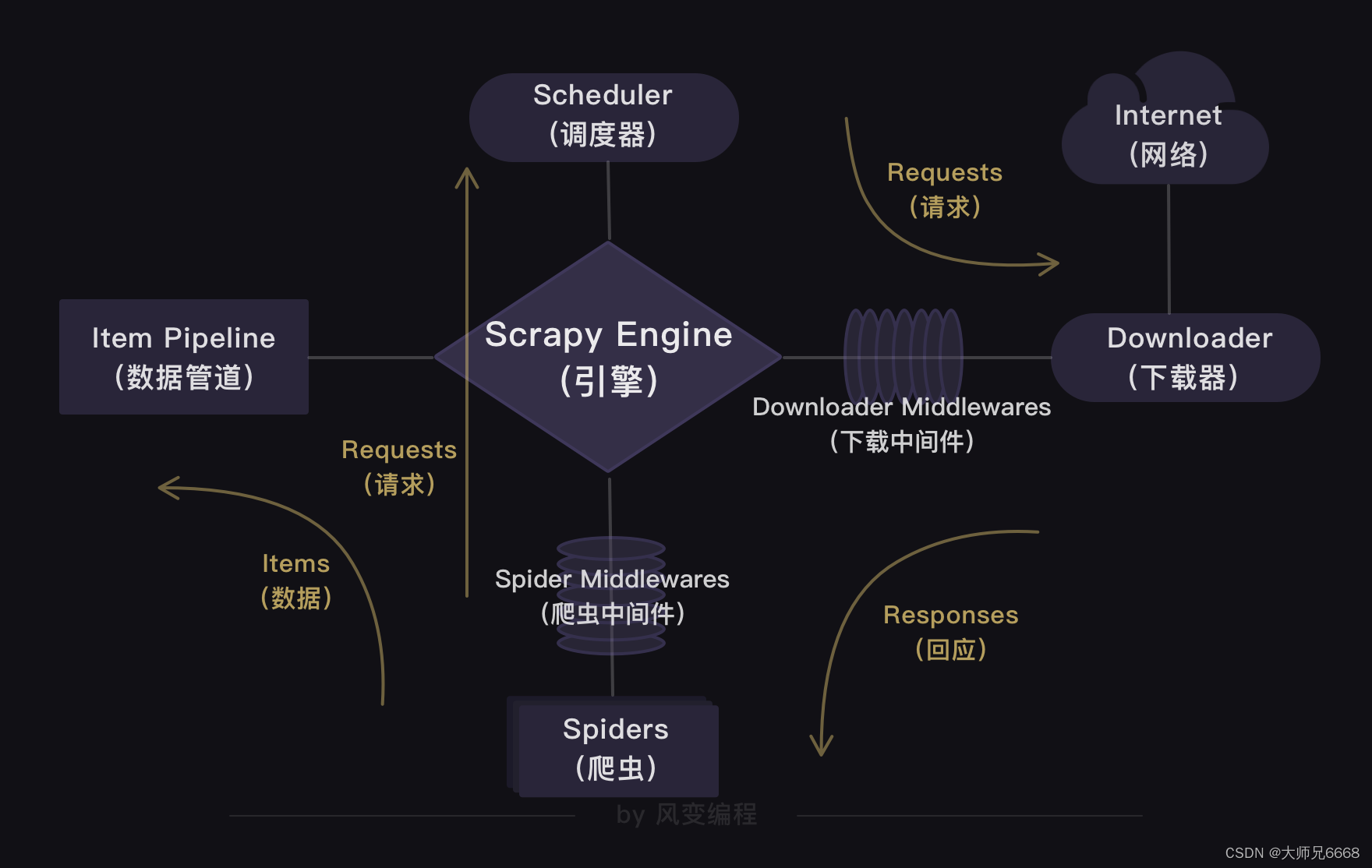
Scrapy aparece ante tus ojos. La estructura de Scrapy——
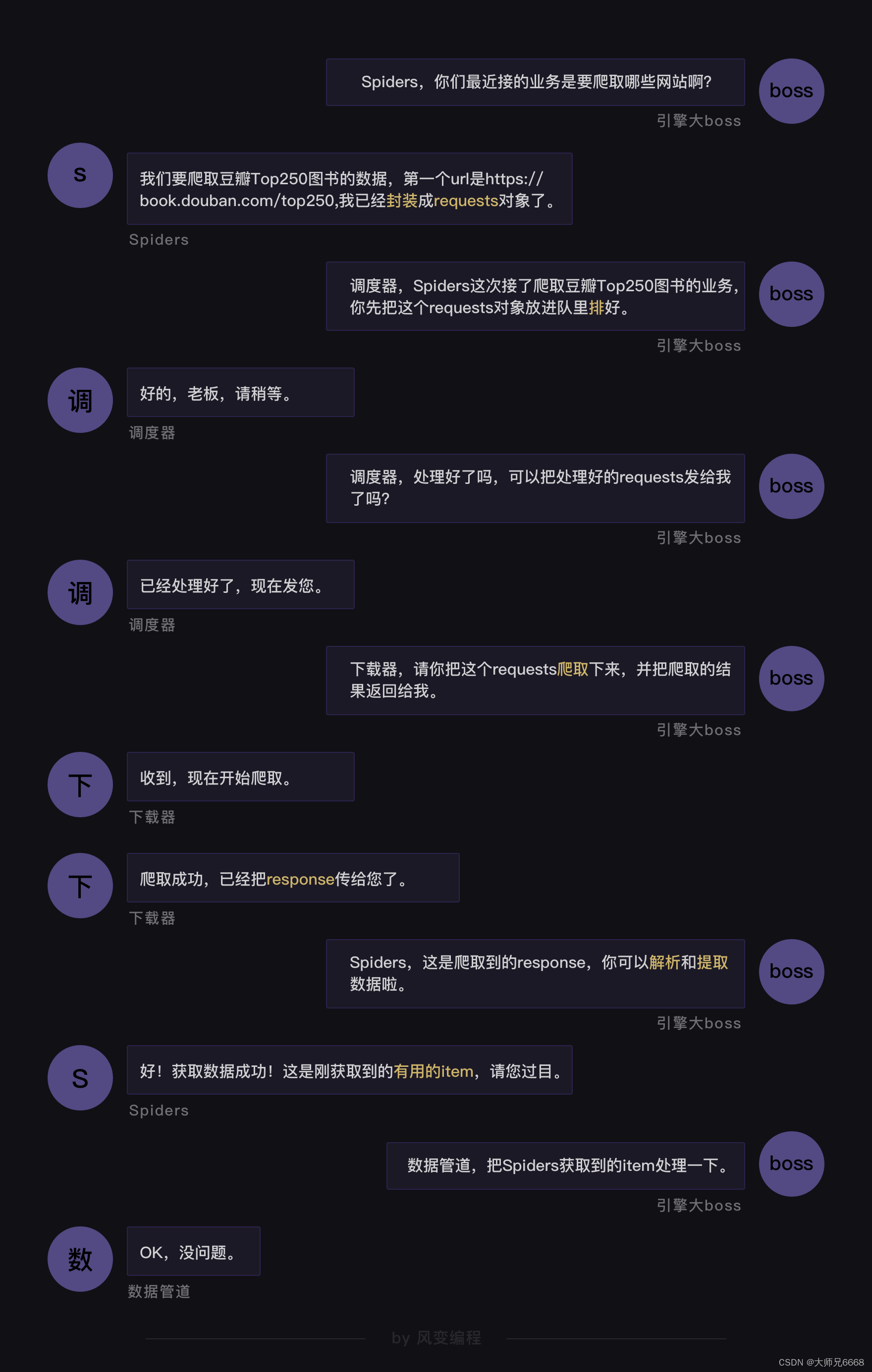
Cómo funciona Scrapy——
Cómo utilizar Scrapy——

Añade alas al reptil.
Además del camino principal de este rastreador desde cero, de la existencia a muchos, de muchos a fuertes. También aprendimos tres herramientas poderosas: selenio, notificaciones por correo electrónico y sincronización.
Le dan alas a los reptiles, lo que les facilita hacer cosas más interesantes.
Primero hablemos de selenio. Aprendimos cómo configurar dos navegadores, el modo visual y el modo silencioso. Ambos tienen sus propias ventajas.
Luego aprendí cómo usar .get('URL') para obtener datos y cómo analizarlos y extraerlos.
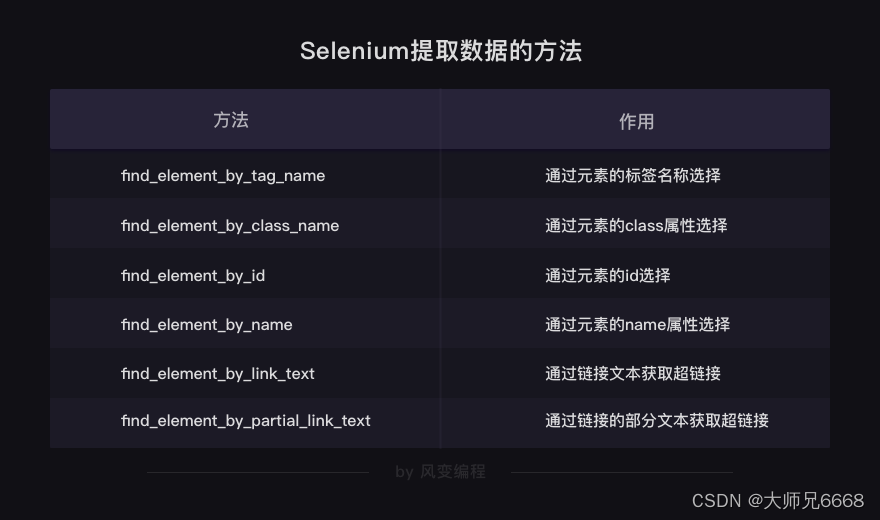
En este proceso, el proceso de conversión de objetos:

Además del método anterior, también puede utilizar BeautifulSoup para analizar y extraer datos, la premisa es obtener primero el código fuente de la página web en formato de cadena.
HTML源代码字符串 = driver.page_source
Y algunas formas de automatizar el funcionamiento del navegador.
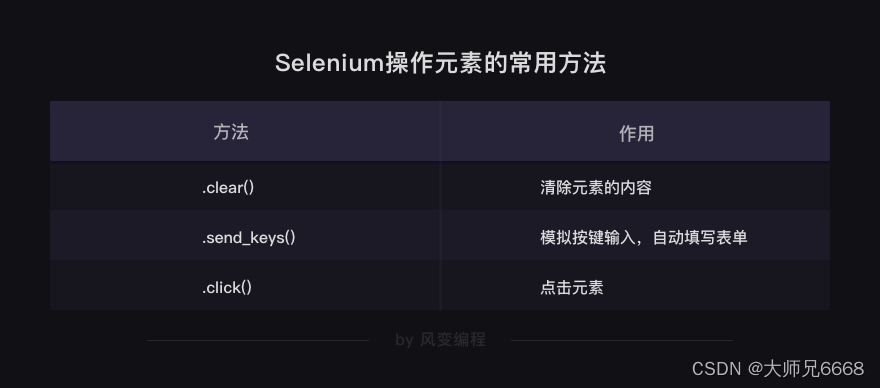
En cuanto al correo electrónico, es un proceso como este:

Los módulos que queremos utilizar son smtplib y email, el primero se encarga del proceso de conexión al servidor, inicio de sesión, envío y salida. Este último se encarga de rellenar el título y el cuerpo del correo electrónico.
El último código de muestra se ve así:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#引入smtplib、MIMEText和Header
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址应为字符串格式
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以调用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器。
account = input('请输入你的邮箱:')
#获取邮箱账号,为字符串格式
password = input('请输入你的密码:')
#获取邮箱密码,为字符串格式
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
#以上,皆为登录邮箱。
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱。
content=input('请输入邮件正文:')
#输入你的邮件正文,为字符串格式
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码
subject = input('请输入你的邮件主题:')
#输入你的邮件主题,为字符串格式
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
#以上,为填写主题和正文。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
#以上为发送邮件和退出邮箱。
Hablemos de tiempos. Elegimos el módulo de programación. Su uso es muy simple. El documento oficial lo describe así:
El siguiente código es un ejemplo:
import schedule
import time
#引入schedule和time
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(10).minutes.do(job) #部署每10分钟执行一次job()函数的任务
schedule.every().hour.do(job) #部署每×小时执行一次job()函数的任务
schedule.every().day.at("10:30").do(job) #部署在每天的10:30执行job()函数的任务
schedule.every().monday.do(job) #部署每个星期一执行job()函数的任务
schedule.every().wednesday.at("13:15").do(job)#部署每周三的13:15执行函数的任务
while True:
schedule.run_pending()
time.sleep(1)
#15-17都是检查部署的情况,如果任务准备就绪,就开始执行任务。
Lo anterior es todo lo que hemos aprendido en la serie de niveles del rastreador.
Guía de ruta avanzada del rastreador
Como dijimos antes, una introducción básica al aprendizaje de los reptiles es suficiente, pero en realidad, el aprendizaje no tiene fin. A continuación, hablaremos sobre qué más puede aprender si desea continuar aprendiendo sobre los rastreadores en profundidad.
Según nuestra ruta de aprendizaje sobre rastreadores, la guía avanzada también se divide en estas secciones: análisis y extracción, almacenamiento, análisis y visualización de datos (nuevo), más rastreadores, marcos y otros.
Para obtener este conocimiento, ya puede dominar muchos métodos simples de uso estudiando los documentos oficiales usted mismo. Para algunos conocimientos complejos, especialmente aquellos que requieren capacitación en proyectos, puede que le resulte difícil aprenderlos. Esta parte se resolverá y compartiré con usted cuando haga mi propia investigación en el futuro.
Analizar y extraer
Cuando decimos que necesitamos aprender a analizar y extraer, nos referimos a aprender bibliotecas de análisis. Además del análisis BeautifulSoup y la propia biblioteca de análisis de Selenium utilizadas en nuestros niveles, también habrá: xpath/lxml, etc. Pueden tener una sintaxis diferente, pero los principios subyacentes son los mismos. Puede comenzar fácilmente y utilizarlos en algunos escenarios adecuados.
Si la biblioteca de análisis anterior tiene poco impacto, ya sea que la aprenda o no, le recomendaría solemnemente que aprenda expresiones regulares (re módulo). Las expresiones regulares son poderosas: le permiten establecer un complejo conjunto de reglas usted mismo y luego encontrar contenido relevante que cumpla con las condiciones del texto de destino. Por ejemplo, cuando estemos en el nivel 6, rastrearemos la letra de una canción y el texto que obtengamos estará lleno de varios símbolos.

Según el conocimiento que aprendimos antes, solo podemos cortarlo una y otra vez e incansablemente. Pero utilizando reglas habituales, este problema se puede resolver fácilmente.
almacenamiento
En cuanto a almacenamiento, el conocimiento que tenemos actualmente es csv y excel. No son módulos muy difíciles y te recomendaría leer su documentación oficial para aprender más sobre su uso. De esta forma, también será de gran ayuda para el trabajo diario automatizado de oficina.
Pero cuando la cantidad de datos se vuelve enorme (esto no es nada nuevo en el mundo de los rastreadores) y la relación entre los datos, debería ser difícil usar una simple mesa plana bidimensional para transportarlos. Bueno, necesitas ayuda de una base de datos.
Le recomiendo que comience a aprender con las dos bibliotecas MySQL y MongoDB, una de ellas es un representante típico de una base de datos relacional y la otra es un representante típico de una base de datos no relacional.
Por supuesto, es posible que sienta curiosidad por saber qué es una base de datos relacional y qué es una base de datos no relacional. En pocas palabras, diseñé dos tablas, una para almacenar la información de la cuenta (apodo, avatar, etc.) de los usuarios de Fengbian Programming y la otra para almacenar los registros de aprendizaje de los usuarios. Las dos tablas están relacionadas mediante ID de usuario únicos. Esta es una base de datos relacional. Sin esta característica, naturalmente se trata de una base de datos no relacional.
Aprender bases de datos requiere que estés expuesto a otro lenguaje: SQL. Pero no es difícil aprender, ¡vamos!
Análisis y visualización de datos.
Tener grandes cantidades de datos tiene un significado muy limitado. Los datos deben analizarse para crear un valor más profundo. Por ejemplo: no tiene mucho sentido obtener las direcciones y los datos de ingresos de las tiendas McDonald's en China, pero si se puede resumir la estrategia óptima de los restaurantes de comida rápida a partir de ella, puede guiar las decisiones comerciales.
Al mirar Ctrip.com, todas las opiniones de los usuarios sobre Shenzhen Happy Valley tienen poca importancia. Pero sería muy interesante analizar y resumir qué es lo que realmente les importa a los usuarios a la hora de jugar.
La habilidad aquí se llama análisis de datos. Es visualización para transmitir las conclusiones del análisis de datos de forma intuitiva y poderosa.
En serio, esta no es una habilidad muy sencilla. El análisis de datos de aprendizaje lleva más tiempo que el rastreo. Entonces, en el futuro, definitivamente haré algunos niveles en esta área para ayudar a todos a dominarla.
Si quieres aprenderlo tú mismo, aquí tienes los módulos y bibliotecas que recomiendo: Pandas/Matplotlib/Numpy/Scikit-Learn/Scipy.
Más rastreadores
Cuando tienes demasiados datos para rastrear, empiezas a preocuparte por la velocidad del rastreador. Aquí presentamos una herramienta que permite que varios rastreadores trabajen juntos: las corrutinas.
Estrictamente hablando, esto no funciona al mismo tiempo, pero la computadora cambia rápidamente entre múltiples tareas, lo que hace que parezca que los rastreadores están trabajando al mismo tiempo.
Por tanto, esta forma de trabajar tiene un cuello de botella en la optimización de la velocidad. Entonces, ¿qué más puedes hacer si aún quieres lograr un gran avance?
Ya sabemos que las corrutinas esencialmente usan solo un núcleo de la CPU. El rastreador multiproceso (biblioteca de multiprocesamiento) le permite usar múltiples núcleos de CPU, por lo que puede usar múltiples procesos o una combinación de múltiples procesos y múltiples corrutinas para optimizar aún más el rastreador.
En teoría, siempre que la CPU lo permita, la cantidad de procesos abiertos puede aumentar la velocidad de su rastreador.
¿Qué pasa si la CPU no lo permite? Por ejemplo, mi computadora solo tiene 8 núcleos. Y quiero atravesar 8 procesos, ¿qué debo hacer?
Respuesta, rastreador distribuido. ¿Qué significa eso? Los rastreadores distribuidos permiten que varios dispositivos ejecuten el mismo proyecto.
Creemos una cola compartida, que esté llena de tareas del rastreador para ejecutar. Permita que varios dispositivos obtengan tareas de esta cola compartida y completen su ejecución. Este es un rastreador distribuido.
De esta manera, ya no habrá ningún cuello de botella que limite su rastreador: simplemente agregue más dispositivos. En las empresas, frente a una gran cantidad de tareas de rastreador, también utilizan un enfoque distribuido para realizar operaciones de rastreador.
Para implementar un rastreador distribuido, necesita el contenido del siguiente bloque: el marco.
Rastreador más potente: marco
Actualmente, hemos aprendido brevemente los principios básicos y el uso del marco Scrapy. Y algunos usos más detallados: usar Scrapy para simular el inicio de sesión, almacenar bases de datos, usar proxy HTTP, rastreadores distribuidos... estos aún no se han cubierto.
Pero la buena noticia es que hoy en día usted puede acceder fácilmente a la mayor parte de este conocimiento. Porque dominas su lógica subyacente y el resto son solo algunas cuestiones gramaticales.
Te recomendaría que primero aprendas más sobre el marco Scrapy. Luego, conozca otros marcos excelentes, como: PySpider.
formación de proyectos
Ahora, cuando visita algunos sitios web de contratación y busca las palabras "ingeniero reptil", la descripción del trabajo ya no contiene palabras que puedan resultarle desconocidas.
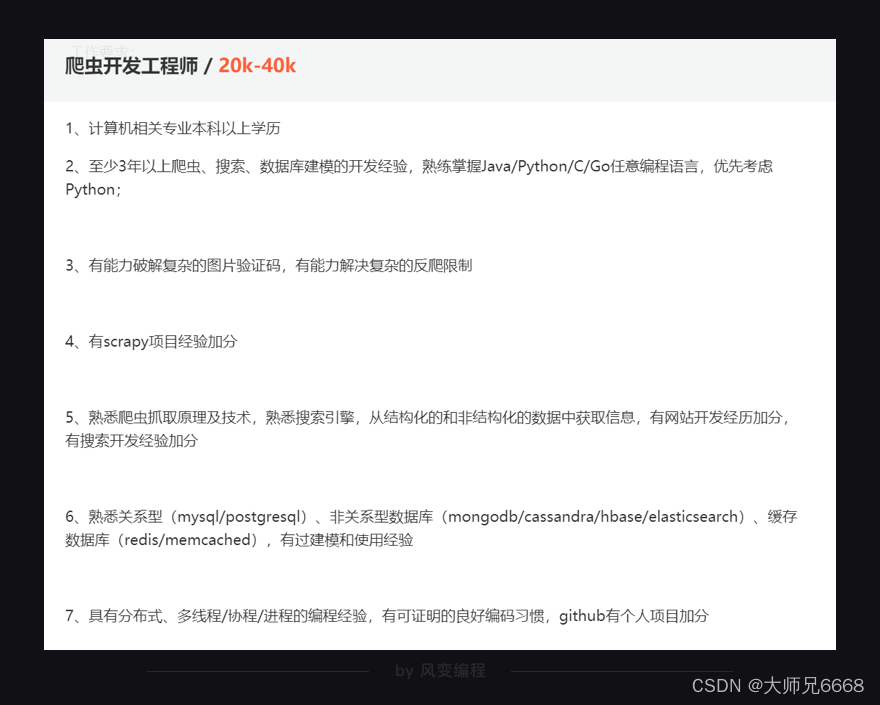
Empiezas a sentir que tal vez si añades algo de conocimiento y estudio, podrás ser competente. Entonces, ¿qué falta en el medio?
Los módulos/bibliotecas/marcos mencionados anteriormente no son tan importantes ya que todos son herramientas fáciles de dominar. Lo más importante para un ingeniero de orugas es pensar para lograr el objetivo.
Creo que ya puede sentir que en todos nuestros niveles basados en proyectos, se siguen estos tres pasos principales: confirmación de objetivos, proceso de análisis e implementación de código (para proyectos complejos, también se requiere la encapsulación de código).
Entre ellos, lo más difícil no es la implementación o encapsulación del código, sino: confirmar un objetivo razonable, analizar cómo lograrlo y diseñar cómo combinar y aplicar estos módulos de herramientas.
Los cuatro pasos del rastreador que aprendimos: obtener datos, analizar datos, extraer datos y almacenar datos sirven para el paso del "proceso de análisis".
¿Dónde están los datos que quiero? ¿Cómo obtener los datos? ¿Cómo obtener datos más rápido? Cómo almacenar mejor los datos... todo esto pertenece a "pensar para lograr objetivos".
Adquirir este tipo de pensamiento requiere mucha práctica práctica en proyectos.
Por lo tanto, me gustaría recomendarle: complete todos los ejercicios de proyectos que proporciono; lea más blogs y casos de aprendizaje de personas mayores en programación en la página de inicio de GitHub; al mismo tiempo, explore operaciones de proyectos más prácticas para enriquecer su experiencia con el rastreador.
En el futuro, si diseño un curso de rastreo más avanzado para enseñar conocimientos sobre regularidad, procesos, distribución, etc., definitivamente pondré una gran cantidad de implementaciones de proyectos en la línea principal.
Resumen de estrategias de respuesta anti-rastreadores
Después de hablar de la guía de rutas avanzada, hablemos de los anti-rastreadores. Casi todo el personal técnico tiene un consenso sobre los anti-rastreadores: los llamados anti-rastreadores nunca pretenden eliminar completamente a los rastreadores; más bien, intentan encontrar formas de limitar el número de visitas de los rastreadores a un rango aceptable y no permitirles Ser demasiado inescrupuloso.
La razón es simple: hasta el final de escribir el código del rastreador, no es diferente de una persona real que accede a Internet. El lado del servidor no tiene forma de saber si se trata de un humano o un rastreador. Si desea prohibir completamente los rastreadores, los usuarios normales tampoco podrán acceder. Así que sólo podemos encontrar maneras de restringir, no de prohibir.
Por lo tanto, podemos comprender qué técnicas "anti-rastreadores" están disponibles y luego pensar en cómo lidiar con los "anti-rastreadores".
Algunos sitios web limitarán los encabezados de solicitud, es decir, los encabezados de solicitud, por lo que debemos completar el agente de usuario para declarar nuestra identidad y, a veces, también debemos completar el origen y el referente para declarar la fuente de la solicitud.
Algunos sitios web restringirán el inicio de sesión y no podrá acceder a ellos a menos que inicie sesión. Luego usaremos el conocimiento de cookies y sesiones para simular el inicio de sesión.
Algunos sitios web realizarán algunas interacciones complejas, como configurar "códigos de verificación" para bloquear el inicio de sesión. Esto es más difícil de hacer. Generalmente hay dos soluciones: usamos Selenium para ingresar manualmente el código de verificación; usamos algunas bibliotecas de procesamiento de imágenes para identificar automáticamente el código de verificación (tesserocr/pytesserart/pillow).
Algunos sitios web impondrán restricciones de IP, ¿qué significa esto? Cuando normalmente nos conectamos a Internet, siempre llevamos una dirección IP. Una dirección IP es como un número de teléfono: con el número de teléfono de alguien, puedes hablar con esa persona. Asimismo, con la dirección IP de un dispositivo, puede comunicarse con ese dispositivo.
Utilice un motor de búsqueda para buscar "IP" y también podrá ver su dirección IP.
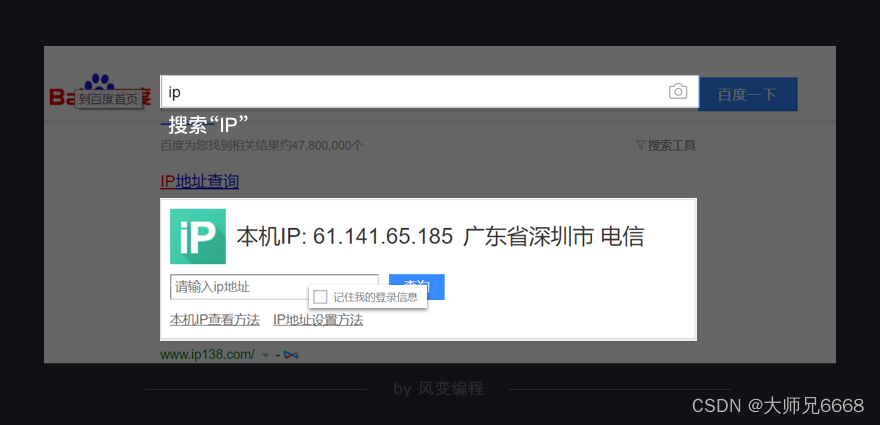
Como se muestra arriba, muestra una determinada dirección IP y el proveedor de servicios de comunicación de red utilizado es Shenzhen Telecom. Si esta dirección IP rastrea el sitio web con demasiada frecuencia, el servidor bloqueará temporalmente las solicitudes de esta dirección IP.
Hay dos soluciones: usar time.sleep() para limitar la velocidad del rastreador; establecer un grupo de proxy de IP (puede buscar servidores proxy de IP disponibles en Internet) y usar otra IP si no se puede usar. La sintaxis aproximada es esta:
import requests
url = 'https://…'
proxies = {
'http':'http://…'}
# ip地址
response = requests.get(url,proxies=proxies)
Las anteriores son las estrategias anti-crawler más comunes en el mercado y las contramedidas correspondientes. Descubrirás que nada puede realmente detenerte. Esto simplemente confirma la frase: los llamados anti-rastreadores nunca eliminan completamente a los rastreadores, sino que encuentran maneras de limitar el número de visitas de los rastreadores a un rango aceptable y no les permiten ser demasiado inescrupulosos.
Las últimas palabras escritas
Siempre he creído que cada tema tiene su propio temperamento único y que tiene un profundo impacto en las personas. Si quieres educar, simplemente enseñar conocimientos a fondo no es suficiente; necesitas expresar ese tipo de cosas.
Los antiguos decían que la "predicación" en "predicar, impartir conocimientos y resolver dudas" es hablar de este tipo de cosas.
Entonces, ¿qué tiene de diferente Reptile?
He consultado a muchas personas mayores a mi alrededor que son muy buenas escribiendo rastreadores: ¿Cómo sueles escribir rastreadores? ¿Qué es lo más importante al escribir un rastreador?
Dieron muchas explicaciones diferentes, pero todas apuntaron a la misma respuesta:
Confirme el objetivo, analice el proceso, primero implemente el código línea por línea para el proceso, encapsulación del código.
Aquí lo más importante es confirmar el objetivo y lo más difícil es el proceso de análisis. Escribir código es algo natural.
En este proceso, encontrará muchas dificultades. Pero no importa, si encuentras dificultades, simplemente estudia y consulta la documentación, siempre encontrarás una solución.
En el mundo de la programación casi nada es imposible.
Fue después de escuchar sus respuestas que diseñé el nivel tal como está ahora: confirmación de objetivos - proceso de análisis - implementación de código (y a veces encapsulación de código) en todas partes.
En este proceso, encontraremos dificultades. Luego, aprendamos nuevos conocimientos y revisemos documentos. Siempre que encontramos nuevos conocimientos, debemos comprender qué son, cómo utilizarlos y utilizarlos de forma práctica.
Para que todos puedan completar mejor el "proceso de análisis" más difícil, hemos propuesto cuatro pasos para los rastreadores: obtener datos, analizar datos, extraer datos y almacenar datos.
Creo que esto es lo que estos 16 niveles del rastreador esperan expresar: no hay meta que no puedas lograr con trabajo duro y sabiduría, y no hay dificultad que no puedas superar con trabajo duro y sabiduría.
Cuando te encuentras con montañas y ríos, construyes caminos y puentes. Las personas que no están dispuestas a pasar la vida en la mediocridad tienen sueños y los sueños son metas.
El objetivo se puede analizar y el proceso se puede realizar.
En este proceso, puede encontrar dificultades. No importa, hay soluciones para cada problema.
Haz caminos cuando encuentres montañas y construye puentes cuando encuentres agua.
Quizás pienses que estoy hablando de sopa de pollo. No, hablo de teoría, hablo de experiencias que te han pasado.
Hablando de teoría, en los últimos años, además de la tecnología, he estado inmerso en una materia llamada “psicología cognitiva”. Lo que estudia es el proceso cognitivo humano. Es realmente interesante de leer.
En este libro, el capítulo que más me impresionó se llama "Resolución de problemas", que analiza cómo las personas resuelven problemas. Finalmente, una conclusión clave es que la forma más efectiva para que los humanos resuelvan problemas es el "análisis de objetivos-medios".
Confirme el objetivo, divídalo capa por capa, convierta el gran problema en un conjunto de pequeños problemas, cada pequeño problema tiene un medio para lograrlo y luego simplemente hágalo. Las cosas parecen ser así de simples.
Pero las cosas no son tan simples.
No sé si todavía recuerdas cómo es el nivel 5. En ese momento, acababas de aprender BeautifulSoup y recibiste una solicitud: rastrea la información de la canción de Jay Chou.
Usted identifica los objetivos, analiza el proceso y luego codifica la implementación. De repente, el resultado fue inesperado: no se obtuvieron los datos deseados.
No sientes pánico por eso, ¿por qué?
Porque cada paso de nuestro proceso se deriva de un razonamiento muy claro. Podemos localizar fácilmente el problema; simplemente retroceda paso a paso.
¿Está mal la extracción? Mira, no. ¿Está mal el análisis? Mira, no. Esa debe ser la forma incorrecta de obtener los datos. Volvamos a analizar el proceso: aprenda nuevos conocimientos - XHR, verifique documentos - analice datos json.
De la misma forma, cuando lo que hacemos no es lo esperado, ¿podemos comprobar si se ejecutó mal? No, ¿es ese el método incorrecto? De lo contrario, debe pensar si existe algún problema con el establecimiento de objetivos.
Sigue pensando así y creo que todo en tu vida puede ser claro y alcanzable. Incluso si algo sale mal, se puede rastrear claramente la fuente.
Despejas el camino a través de montañas y ríos y nunca entras en pánico. Eso es todo lo que quiero decirte.
¡vamos! ¡Con el tiempo te convertirás en el gran dios de tus sueños!