Directorio de artículos
descripción general

Idea principal
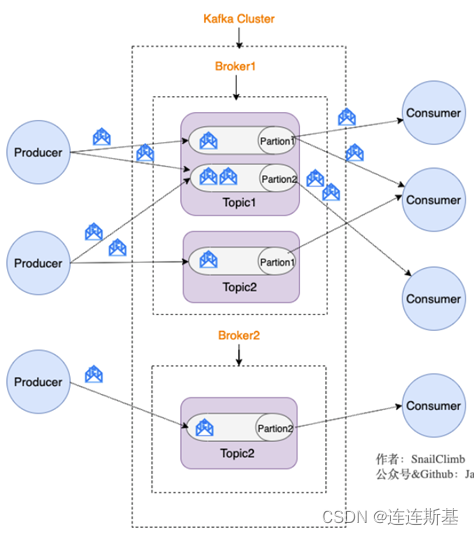
Kafka publica mensajes publicados por productores sobre temas, y los consumidores que necesitan estos mensajes pueden suscribirse a estos temas.
La siguiente imagen también nos lleva a varios conceptos importantes de Kafka:
-
Productor : La parte que produce el mensaje.
-
Consumidor : parte que consume mensajes.
-
Agente (agente/instancia única de Kafka) : puede considerarse como una instancia de Kafka independiente.
- Varios corredores de Kafka forman un clúster de Kafka.
- Cada Broker contiene los dos conceptos importantes de Tema y Partición.
-
Tema (tema) : el productor envía mensajes a un tema específico y el consumidor consume mensajes suscribiéndose a un tema (tema) específico.
-
Partición (partición/cola) : la partición es parte del tema. Un tema puede tener varias particiones, y las particiones del mismo tema se pueden distribuir en diferentes corredores, lo que significa que un tema puede centrarse
en varios corredores: las particiones en Kafka en realidad pueden convertirse en mensajes Una cola dentro de una cola. -
Grupo de consumidores : en el mismo grupo de consumidores, varios consumidores se suscriben al mismo tema y solo un consumidor puede recibir el mensaje.
productor
ejemplo
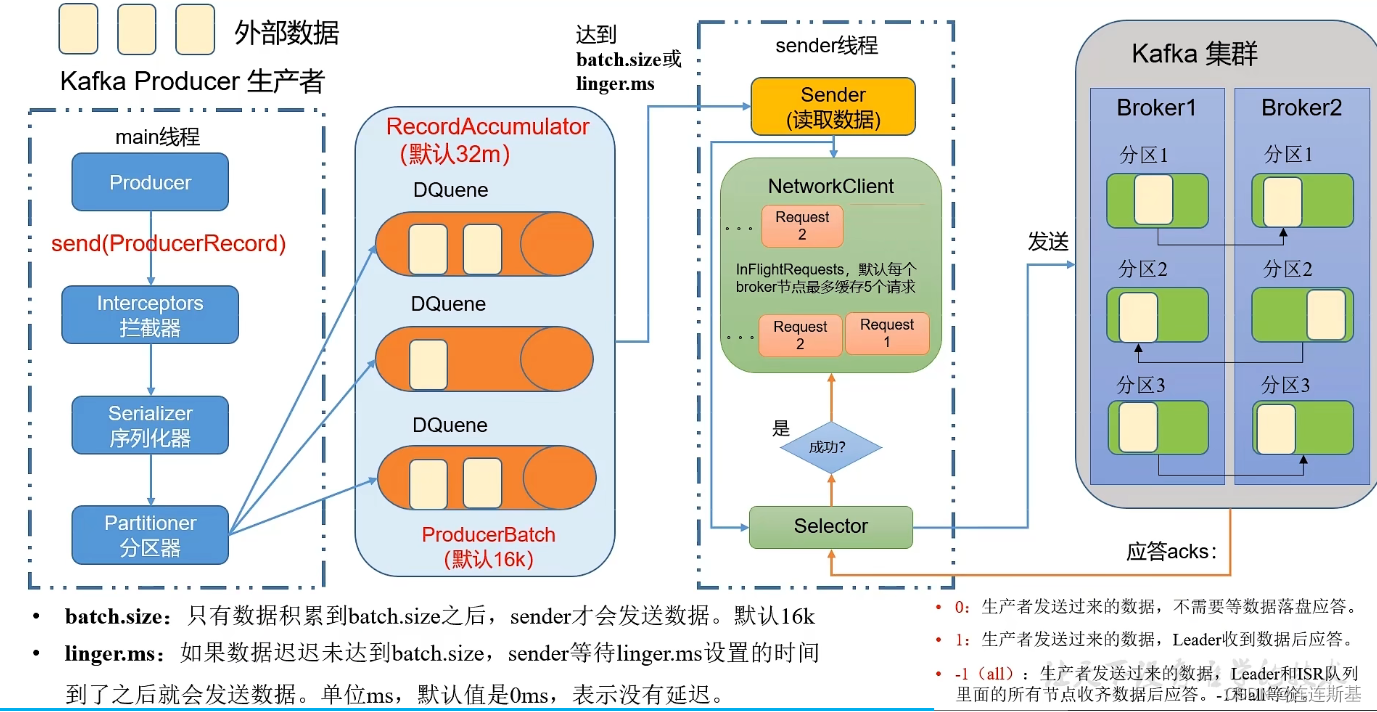
proceso de envío
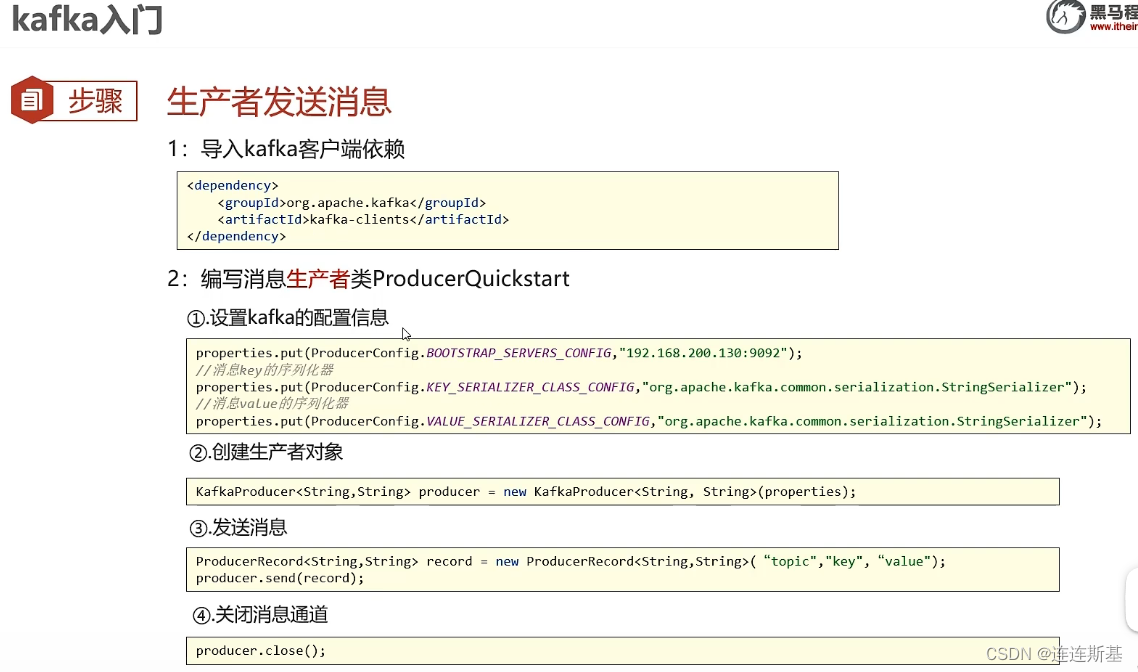
- El final de producción utiliza
kafkaProducerel envío de mensajes, y los mensajes pasan por:拦截器,序列化器ykafka分区器, y se almacenan en el área de acumulación de registrosRecord Accumulator. - El productor de Kafka no envía inmediatamente cada mensaje al clúster de Kafka, sino que coloca un lote de mensajes en la
Record Accumulatorcola de doble extremo para su acumulación y luego los envía juntos para reducir la sobrecarga de la red y mejorar el rendimiento.Record AccumulatorConfiguración que involucra dos parámetros:- lote.tamaño: solo cuando la cantidad de mensajes en la cola de doble extremo alcance el tamaño del lote, se llamará al hilo del remitente para enviar mensajes en lotes.
- linger.ms: si la cantidad de datos no alcanza el tamaño del lote, los datos se enviarán cuando se exceda el tiempo establecido por linger.ms (unidad: ms). El valor predeterminado es 0, lo que significa que no hay demora.
- El hilo del remitente enviará mensajes al mismo corredor para formar una secuencia de solicitud de envío. Si el corredor no responde, almacenará en caché hasta 5 instancias de solicitud.
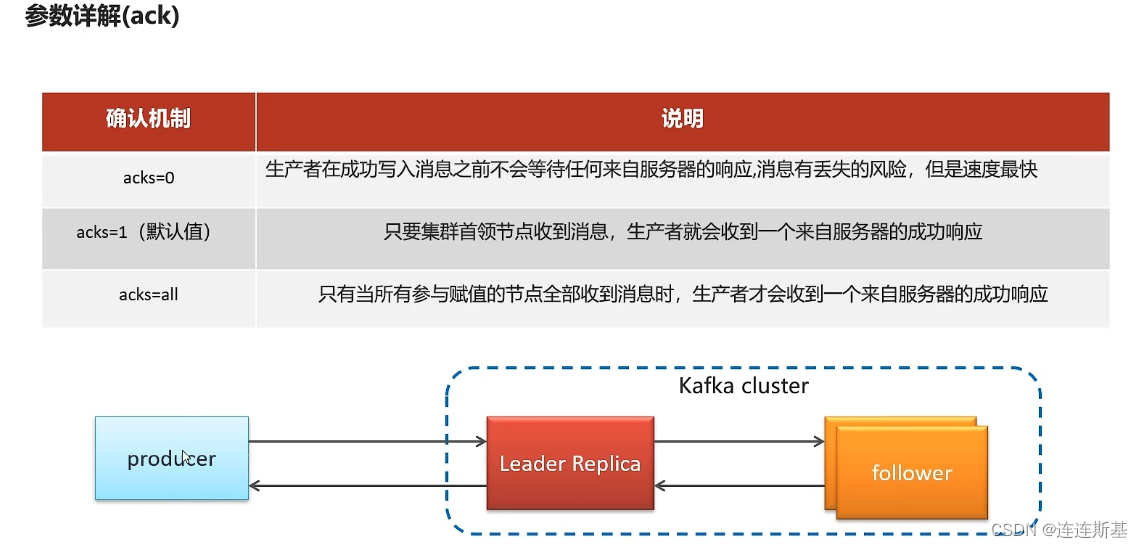
- El mecanismo de confirmación de confirmación para enviar solicitudes:
- ack=0: el broker responde cuando recibe el mensaje
- ack = 1: el intermediario recibió el mensaje y el líder hizo una copia de seguridad del disco y respondió
- ack = 2: el intermediario responde solo después de recibir el mensaje, y tanto la copia de seguridad líder como los ISR (nodos que deben sincronizarse para la copia de seguridad y el almacenamiento) se colocan en el disco.
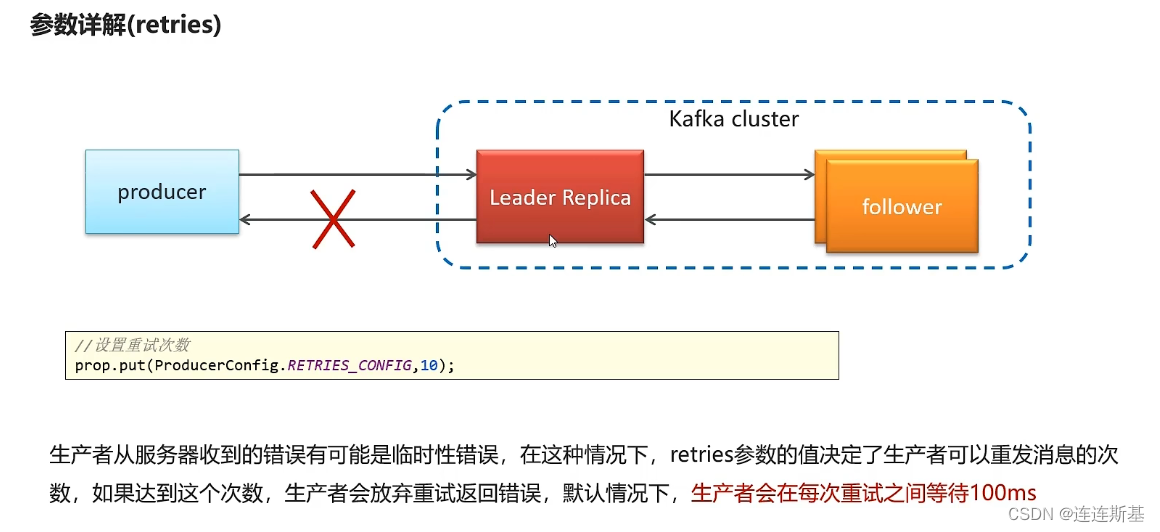
- Si la solicitud de envío falla, lo volverá a intentar. Si la respuesta de confirmación del corredor no se ha recibido más allá del número de configuraciones de reintento, se abandonará el reintento y se devolverá un error.
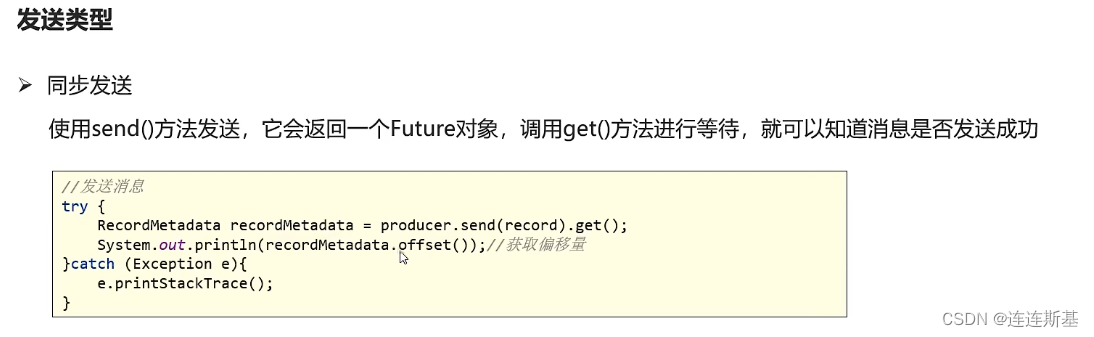
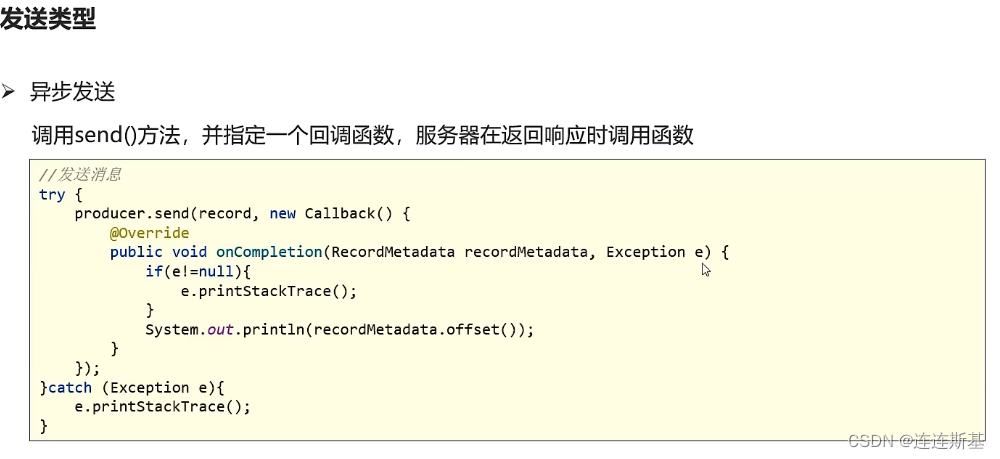
Enviar mensajes de forma sincrónica/asincrónica
Configuración de parámetros del productor
ack - mecanismo de reconocimiento
reintentos - número de reintentos
compresión_tipo - tipo de compresión de mensaje
Preguntas sobre experiencia de producción
mejorar el rendimiento
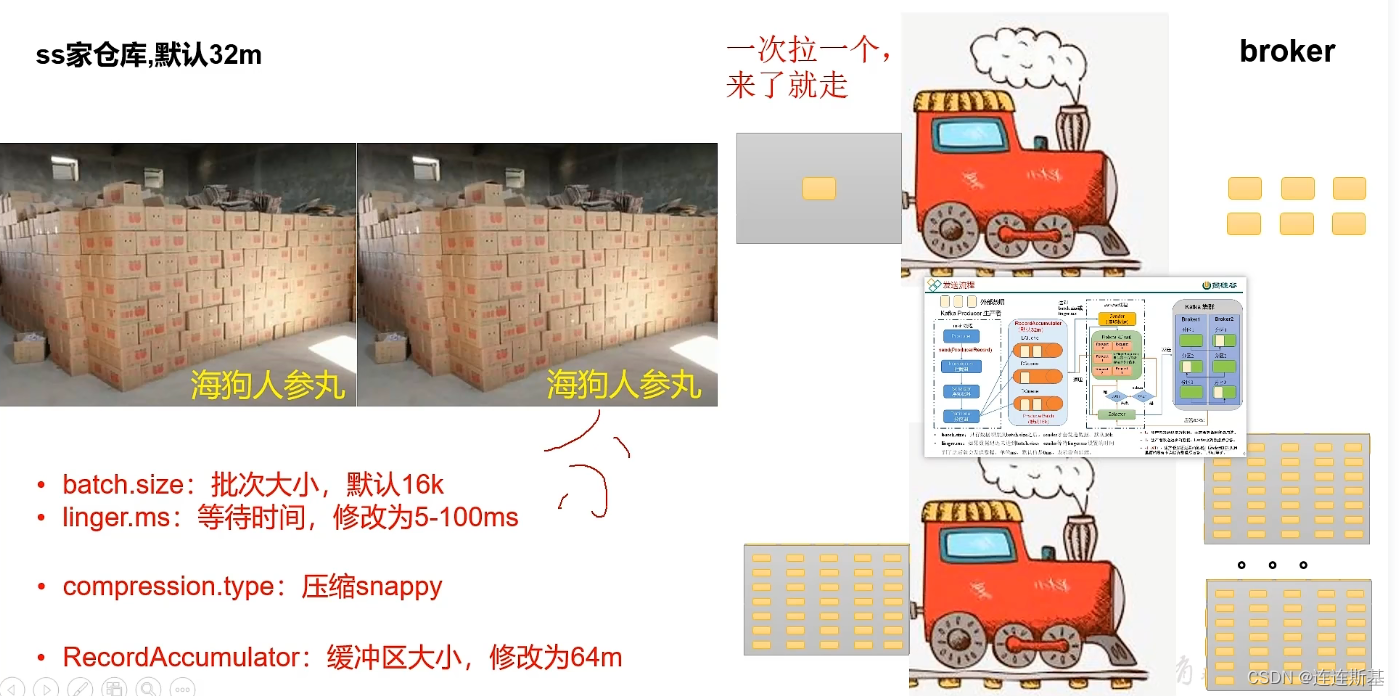
- Aumentar
batch.size, cooperar para extender el tiempo de espera.linger.ms - Especificar
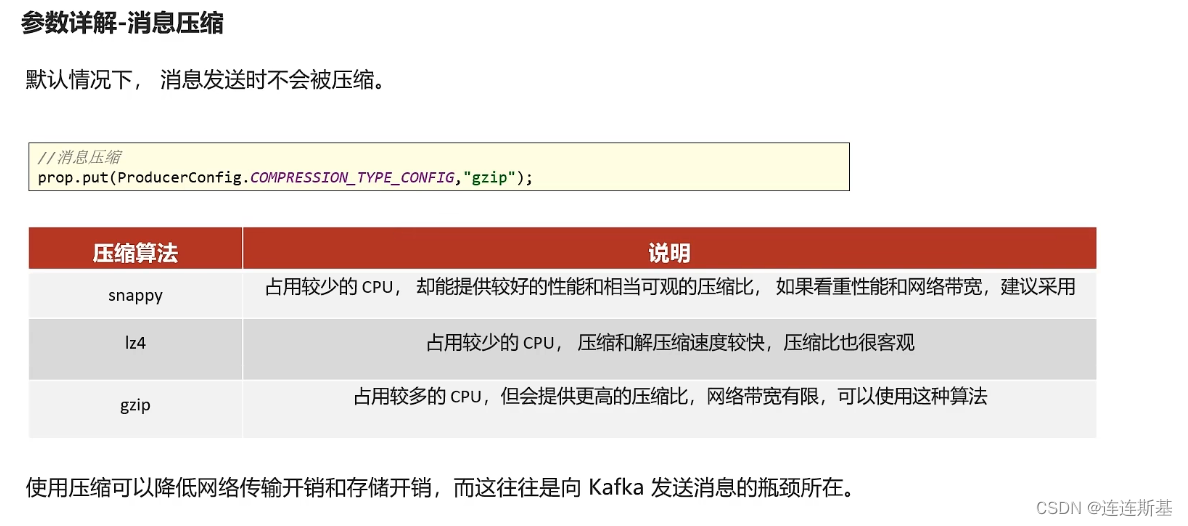
compression.typepara comprimir el mensaje. - Aumente adecuadamente
RecordAccumulatorel tamaño del búfer de trabajo pendiente.
confiabilidad de los datos
La confiabilidad de los datos está garantizada por el mecanismo de respuesta ACK:
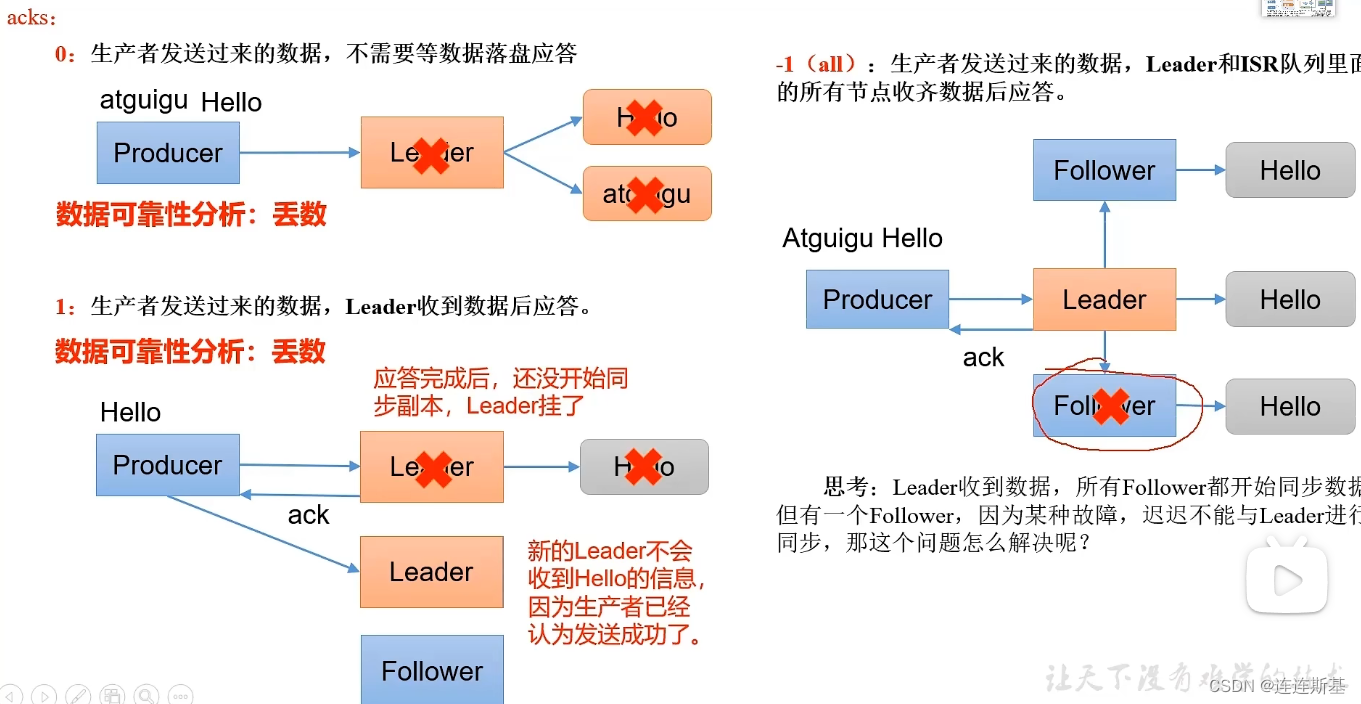
cuando ACK se establece en todos, es necesario asegurarse de que tanto la copia de seguridad líder como la copia de seguridad ISR se coloquen en el disco antes de responder. ¿Qué pasa si un nodo ISR falla durante el período?
长期未向leader发送同步通信请求或同步数据,将被提出ISR,该时间阈值由replica.lag.time.max.msConfiguración de parámetros, el valor predeterminado es 30s

Duplicación de datos: idempotencia y transacciones
idempotencia
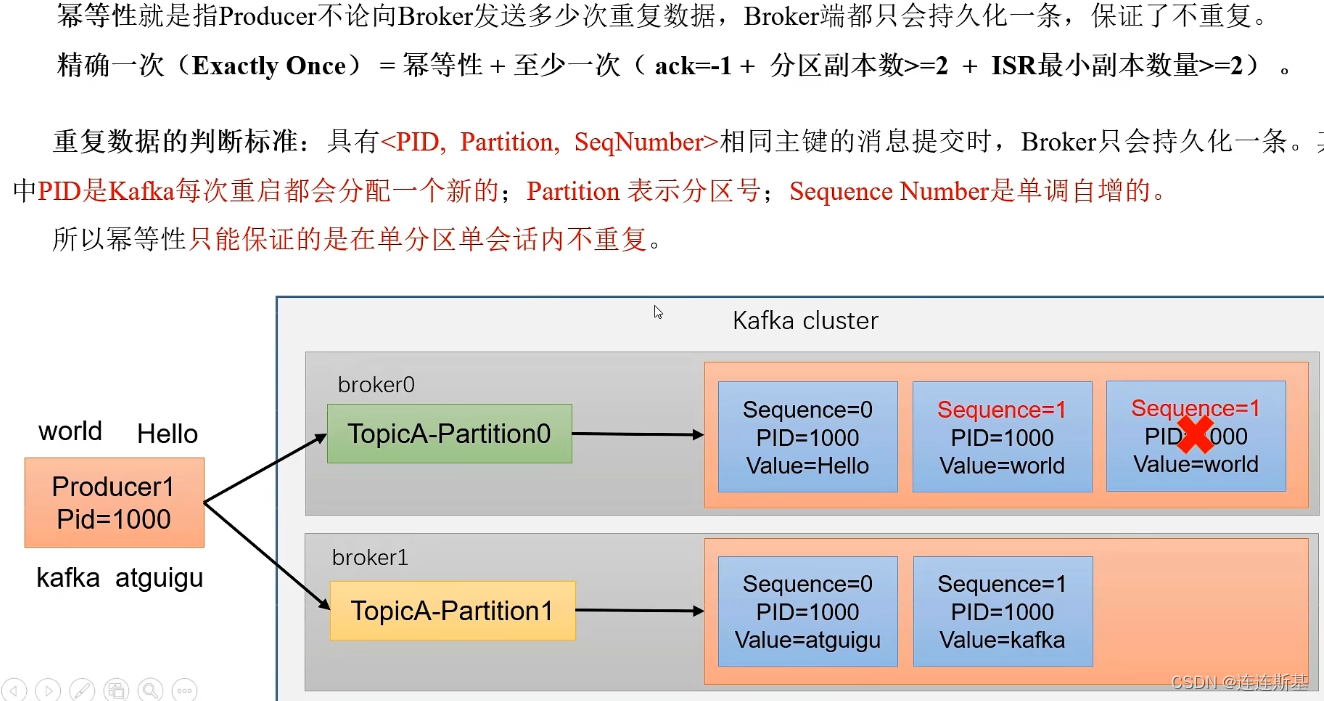
Idempotencia significa que no importa cuántos datos duplicados envíe el Productor al Broker, el Broker solo conservará un dato para garantizar que no se duplique.
Varios conceptos:
- PID (ID de productor): ID de productor, Kafka asignará uno nuevo cada vez que se reinicie
- Partición: número de partición
- Número de secuencia: número de secuencia que aumenta monótonamente
Criterios para juzgar datos duplicados: cuando se envían mensajes con la misma clave principal <PID, Partición, Número de secuencia>, Broker solo persistirá en un mensaje. La idempotencia solo puede garantizar que no haya duplicaciones dentro de una sola partición y una sola sesión.
Cómo utilizar la idempotencia: el parámetro de apertura enable.idempotencese establece de forma predeterminada en verdadero, se cierra falso
asuntos del productor
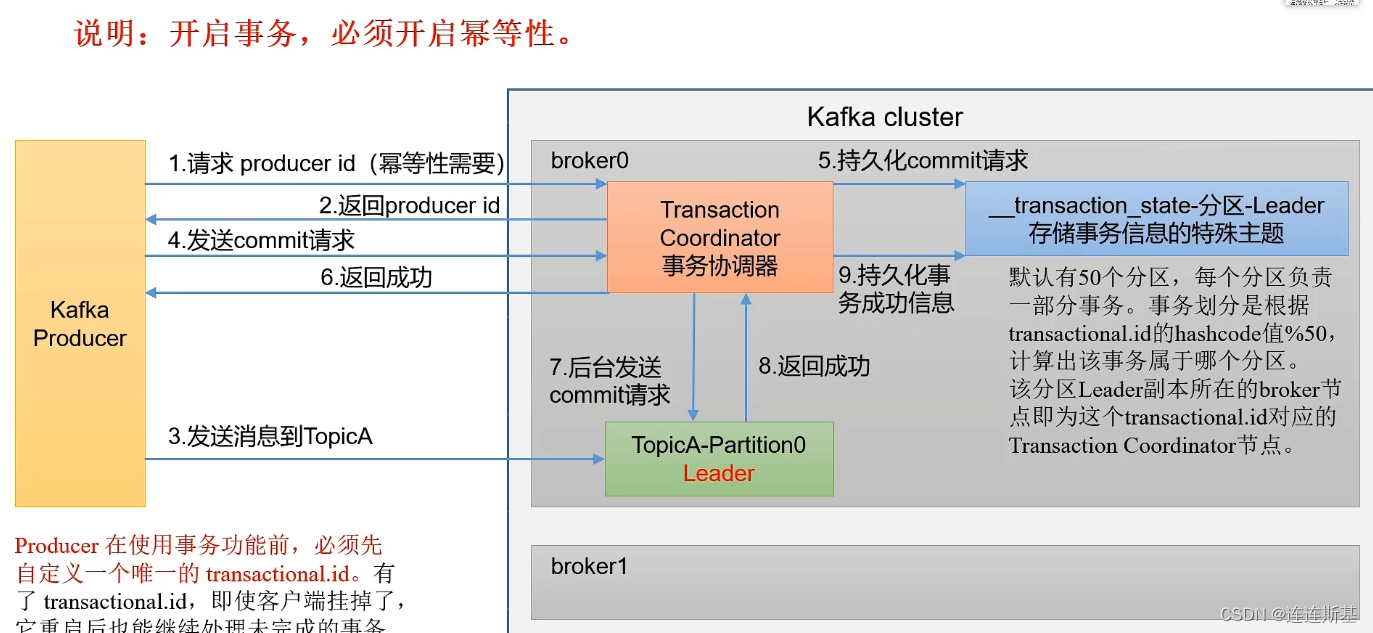
La idempotencia solo puede garantizar que los mensajes no se repitan cuando hay una sola partición y una sola sesión. Una vez que Kafka cuelga, es posible que aún se generen datos duplicados. En este caso, se necesitan transacciones del productor.
开启事务,必须开启幂等性!
orden de datos

- En una sola partición, debido a que los corredores se reciben en orden, naturalmente se garantiza que todo estará en orden.
- Hay varias particiones y no hay orden entre las particiones. Si desea garantizar el orden, debe mantener una ventana ordenada en el lado del consumidor, recibir y deslizar en orden.
Mecanismo de partición
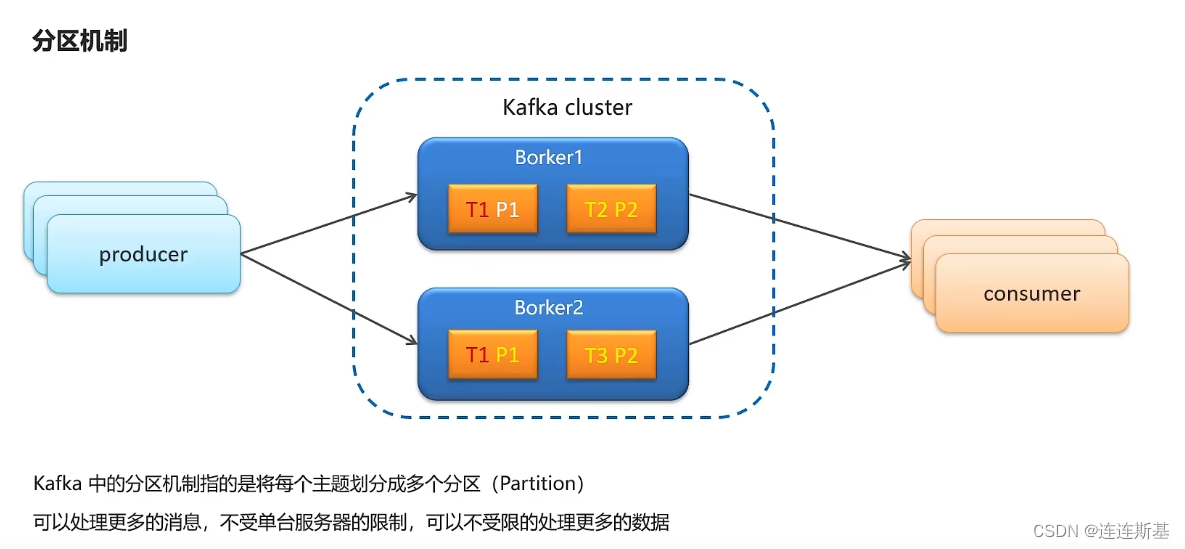
El mecanismo de partición Kafka permite almacenar mensajes en diferentes particiones de diferentes intermediarios.
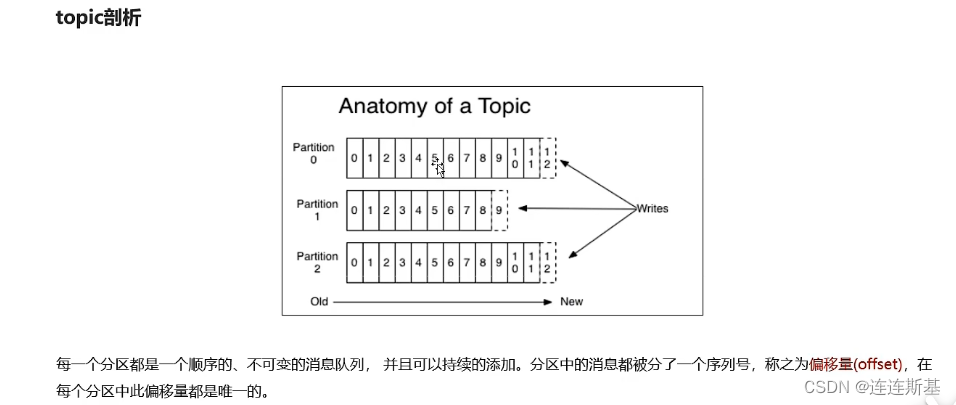
estrategia de partición
El valor predeterminado es el sondeo.
particionador personalizado
Paso 1: Personalice el particionador para implementar la interfaz del Particionador.
Paso 2: reescriba la partición de la función de regla de partición.
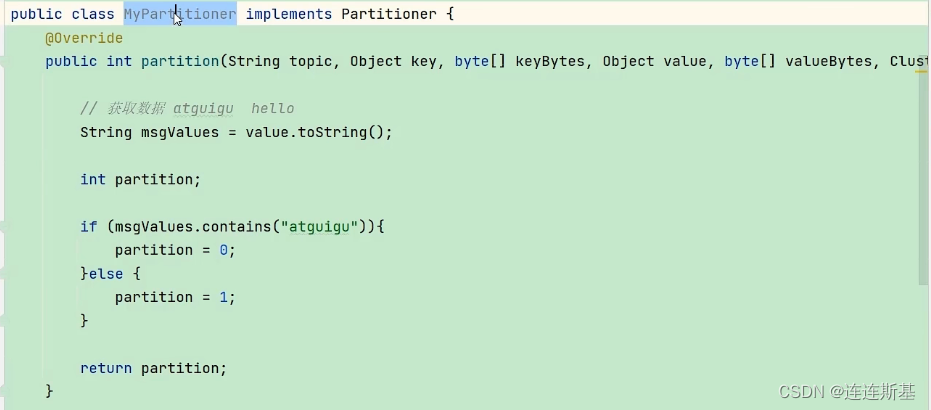
Paso 3: asocie un particionador personalizado al configurar la configuración del productor.

Corredor
consumidor
ejemplo de consumo
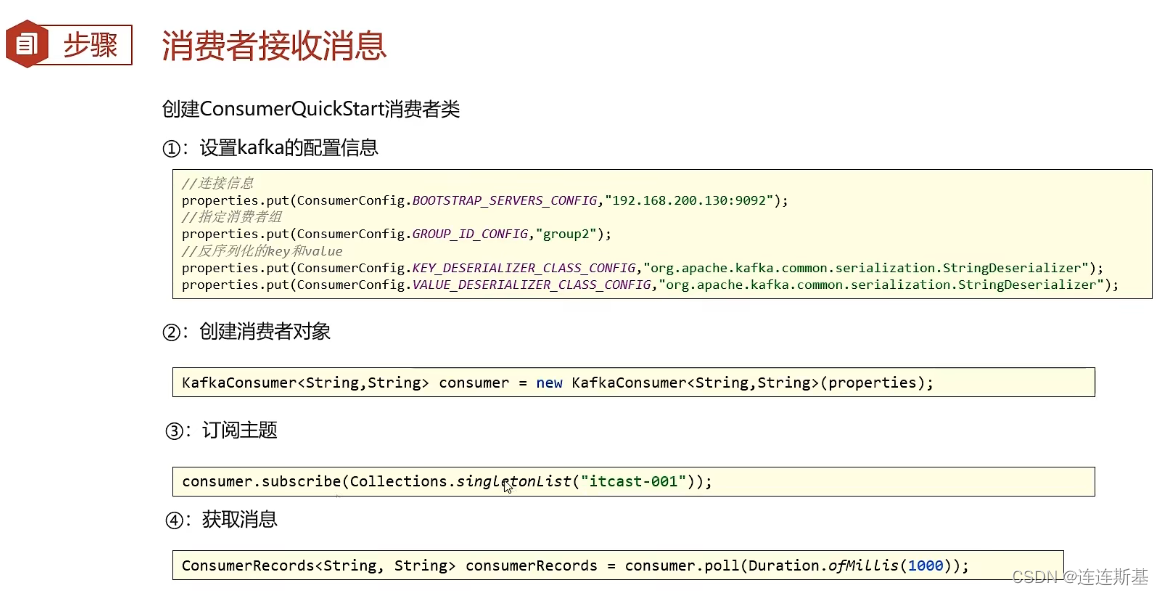
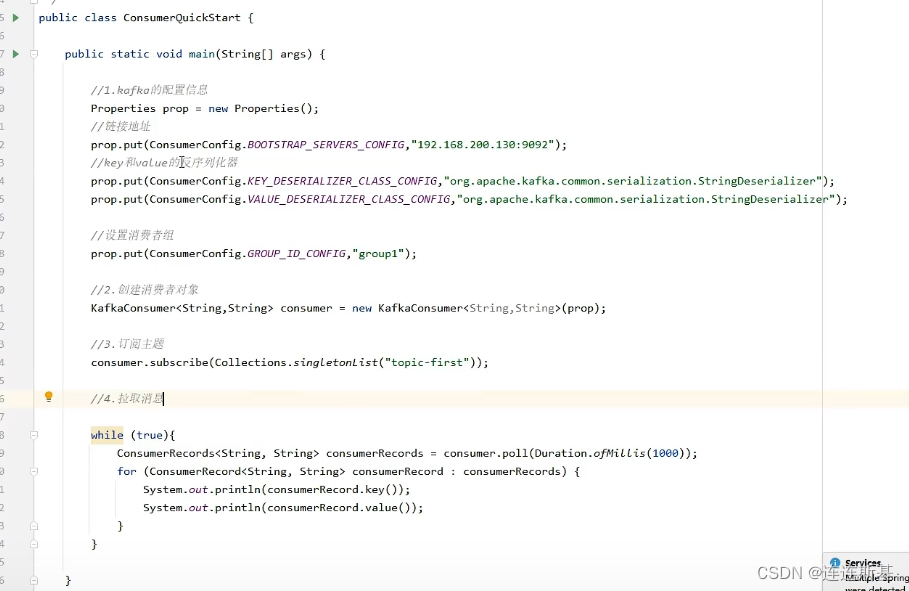
grupo de consumidores

Los patrones de consumo
Kafka extrae activamente datos del corredor.
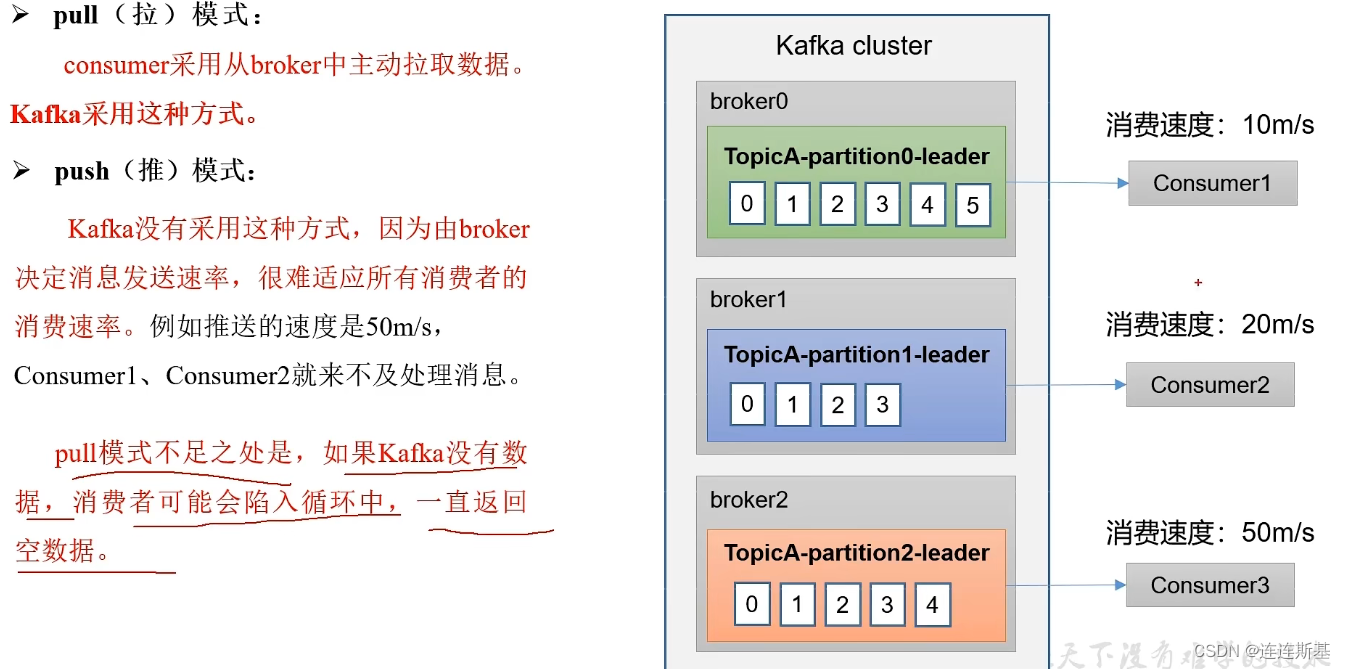
proceso de consumo
- Los consumidores utilizan el método de extracción para obtener mensajes de la partición, y solo un mensaje en el mismo grupo de consumidores puede extraer mensajes de la misma partición.
- Una vez que el consumidor termine de consumir el mensaje, responderá con una compensación al
_consumer_offsetstema del corredor y registrará la ubicación de consumo del consumidor, para facilitar la recuperación cuando el consumidor se reinicie después de un apagado.
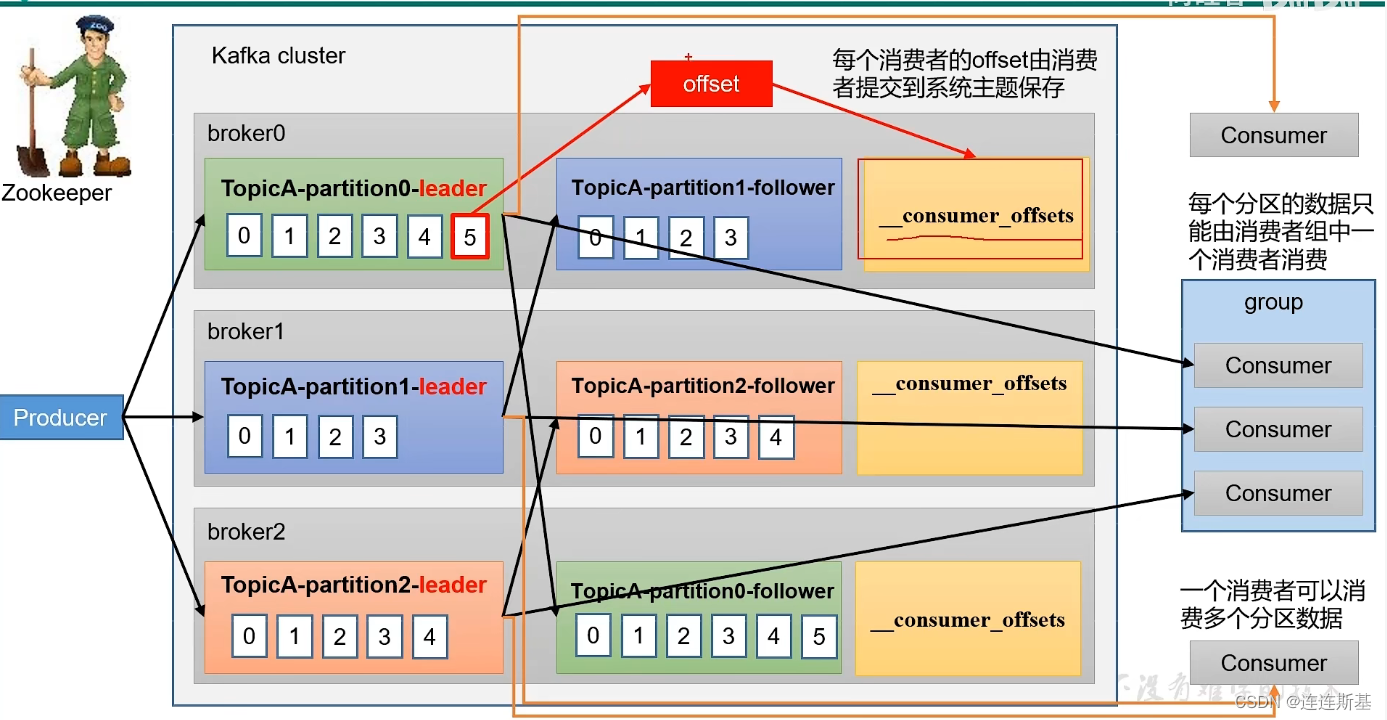
compromisos y compensaciones
Cuando los consumidores consumen mensajes, pueden rastrear la ubicación (desplazamiento) de la repartición del mensaje y _consumer_offsetenviar automáticamente un mensaje a un tema especial llamado, incluido el desplazamiento de la partición.
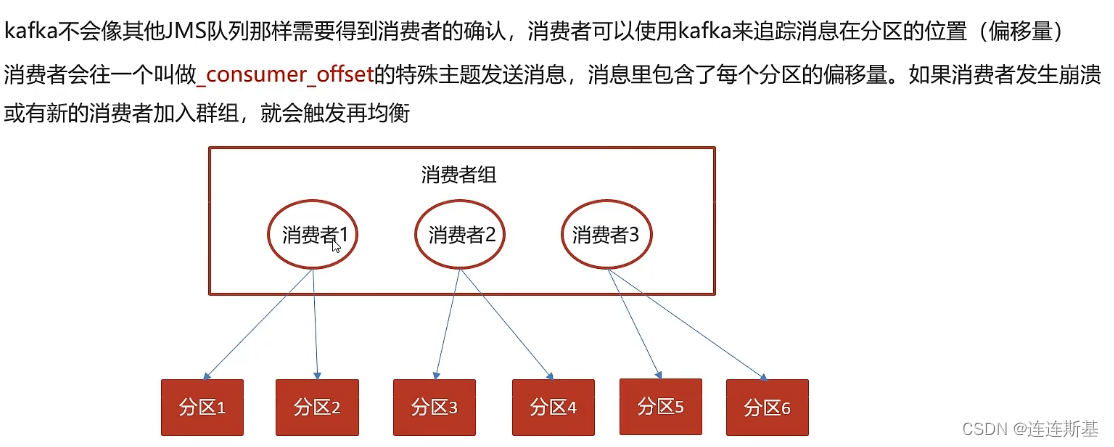
Se activa un reequilibrio si un consumidor envía una falla o si un nuevo consumidor se une al grupo. Por ejemplo, si el consumidor 2 falla, las particiones 3 y 4 se reequilibrarán para apuntar a otros consumidores.
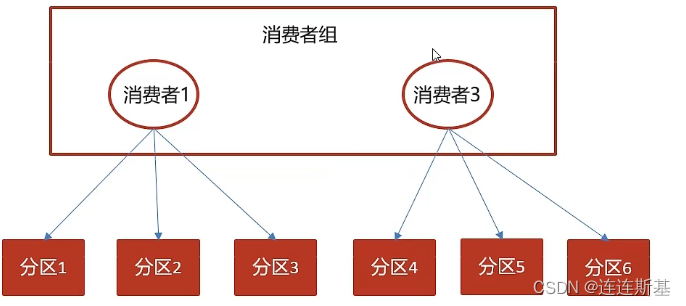
En el modo de compensación de confirmación automática, el mecanismo de reequilibrio puede causar problemas porque las compensaciones de mensajes confirmadas por un consumidor muerto no son consistentes con las compensaciones de mensajes que procesa un consumidor recién designado.
El desplazamiento confirmado es menor que el desplazamiento que se está procesando:
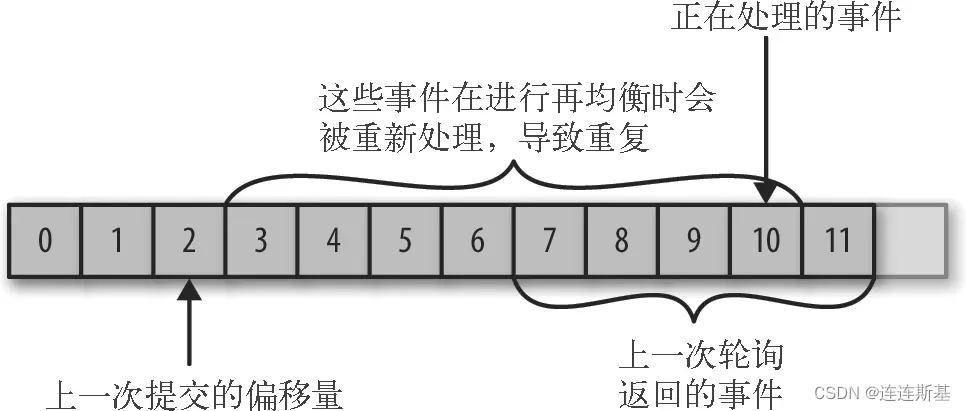
si el desplazamiento confirmado es menor que el desplazamiento del último mensaje que se está procesando, los mensajes entre los dos desplazamientos se procesarán repetidamente.
El desplazamiento confirmado es mayor que el desplazamiento que se está procesando:
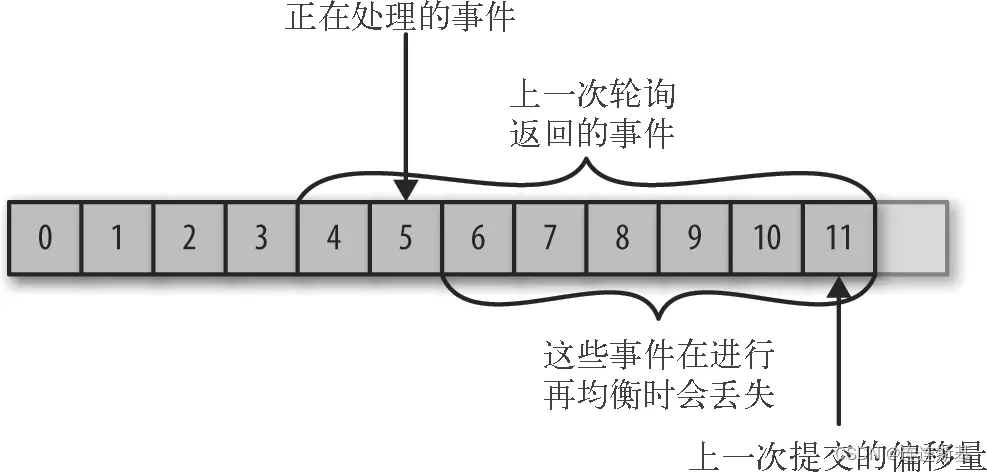
si el desplazamiento confirmado es mayor que el desplazamiento del último mensaje que se está procesando, los mensajes entre los dos desplazamientos se perderán.
Método de envío de compensación

Enviar manualmente
Primero establezca la confirmación automática en falso:

Confirmación síncrona
Confirmar compensaciones es más fácil y confiable usando commitSync(). Esta API enviará el último desplazamiento devuelto por el método poll(), regresará inmediatamente después de que el envío sea exitoso y generará una excepción si el envío falla.
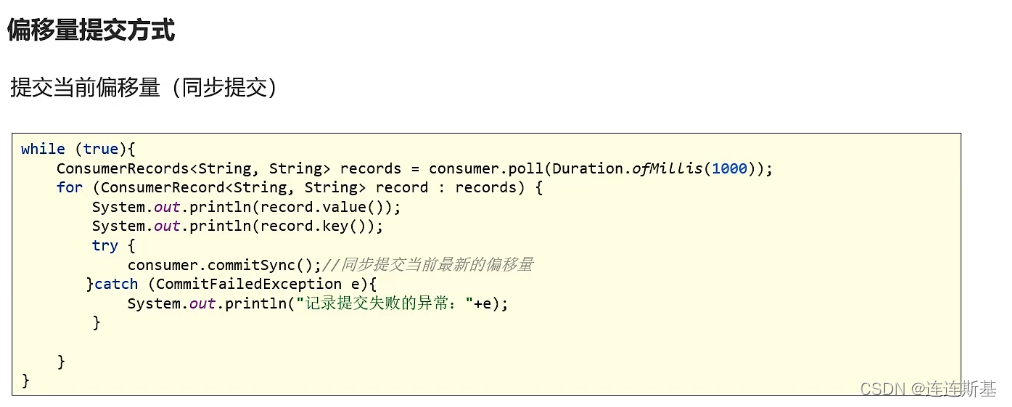
commitSync() confirmará el último desplazamiento devuelto por poll(), así que asegúrese de llamar a commitSync() después de procesar todos los registros; de lo contrario, aún existe el riesgo de perder mensajes.
Si se produce un reequilibrio, se reprocesarán todos los mensajes del lote de mensajes más reciente hasta que se produzca el reequilibrio.
Al mismo tiempo, en este programa, siempre que no se produzcan errores irrecuperables, el método commitSync() seguirá intentándolo hasta que la confirmación sea exitosa. Si el envío falla, solo podemos registrar la excepción en el registro de errores.
Confirmaciones asincrónicas
Las confirmaciones sincrónicas tienen la desventaja de que la aplicación se bloquea hasta que el intermediario responde a la solicitud de confirmación, lo que limita el rendimiento de la aplicación. Podemos mejorar el rendimiento reduciendo la frecuencia de confirmación, pero si se produce un reequilibrio, aumentará la cantidad de mensajes duplicados. En este momento, puede utilizar la API de envío asincrónico. Simplemente enviamos la solicitud de confirmación sin esperar la respuesta del corredor.

commitSync() seguirá reintentando hasta que se confirme con éxito o encuentre un error irrecuperable, pero commitAsync() no lo hará, lo que también es un mal lugar para commitAsync(). La razón por la que no vuelve a intentarlo es porque cuando recibe la respuesta del servidor, es posible que se haya enviado correctamente un desplazamiento mayor. Supongamos que enviamos una solicitud para enviar un desplazamiento de 2000. En este momento, ocurre un problema de comunicación a corto plazo: el servidor no puede recibir la solicitud y, naturalmente, no responderá. Mientras tanto, procesamos otro lote de mensajes y confirmamos con éxito la compensación 3000. Si commitAsync() vuelve a intentar confirmar en el desplazamiento 2000, puede tener éxito después del desplazamiento 3000. Si se produce un reequilibrio en este momento, aparecerán mensajes duplicados. commitAsync() también admite devoluciones de llamada, que se ejecutan cuando el intermediario responde. Las devoluciones de llamada se utilizan a menudo para registrar errores de confirmación o generar métricas. Si desea utilizarlo para volver a intentarlo, debe prestar atención al orden de envío.
Envío mixto sincrónico y asincrónico
En general, para fallas de envío ocasionales, no hay gran problema sin volver a intentarlo, porque si la falla de envío es causada por un problema temporal, los envíos posteriores siempre tendrán éxito. Pero si esta es la última confirmación que ocurrió antes de cerrar el consumidor o reequilibrar, asegúrese de que la confirmación se realice correctamente. Entonces, en este caso, deberíamos considerar el uso de un enfoque de confirmación híbrido:

Diseño de alta disponibilidad
grupo
- Modo de clúster (clúster), un clúster de Kafka se compone de varios intermediarios. Si un intermediario deja de funcionar, los intermediarios de otras máquinas aún pueden servir al mundo exterior.
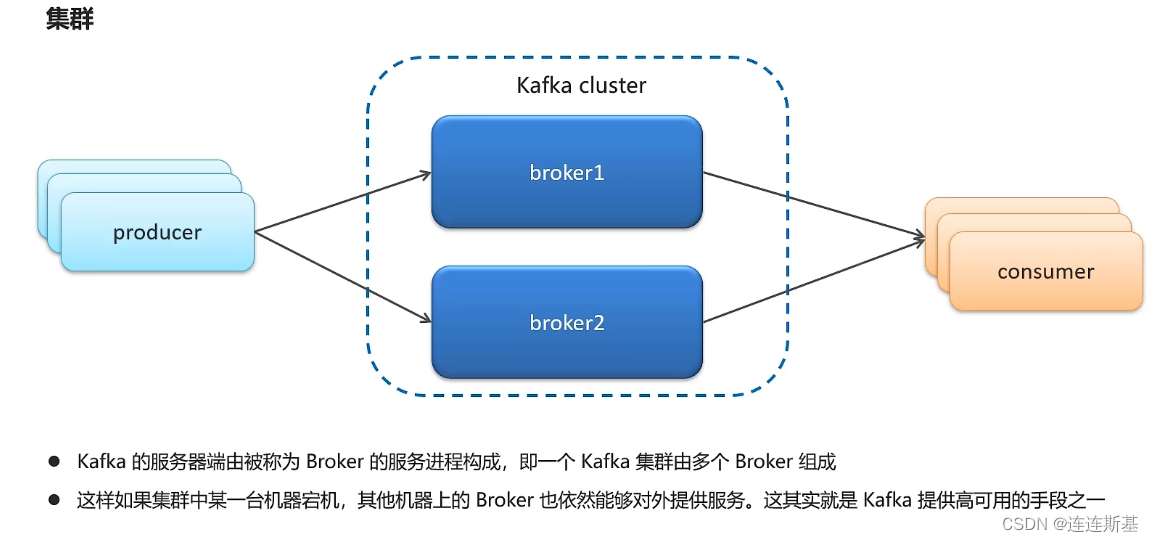
respaldo
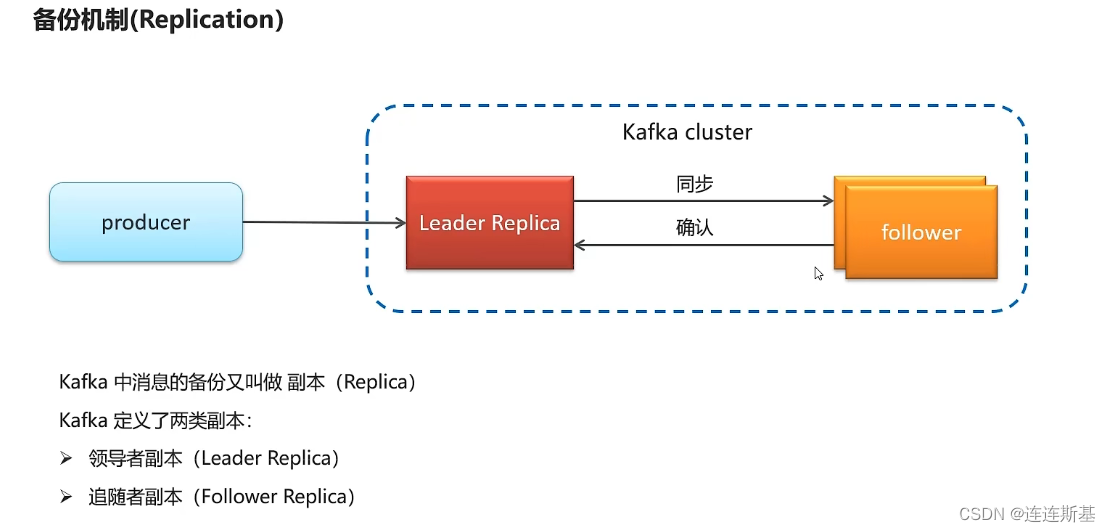
- Mecanismo de copia de seguridad (replicación): Para garantizar la seguridad de los mensajes en Kafka, se realiza una copia de seguridad de la información y se definen dos tipos de copias:
- Copia líder: el productor primero envía mensajes a la copia líder como respaldo, y solo hay una copia líder.
- Copia de seguidor: la copia líder sincroniza sus propios mensajes con la copia de seguidor. Puede haber varias copias de seguidores y se pueden dividir en dos categorías:
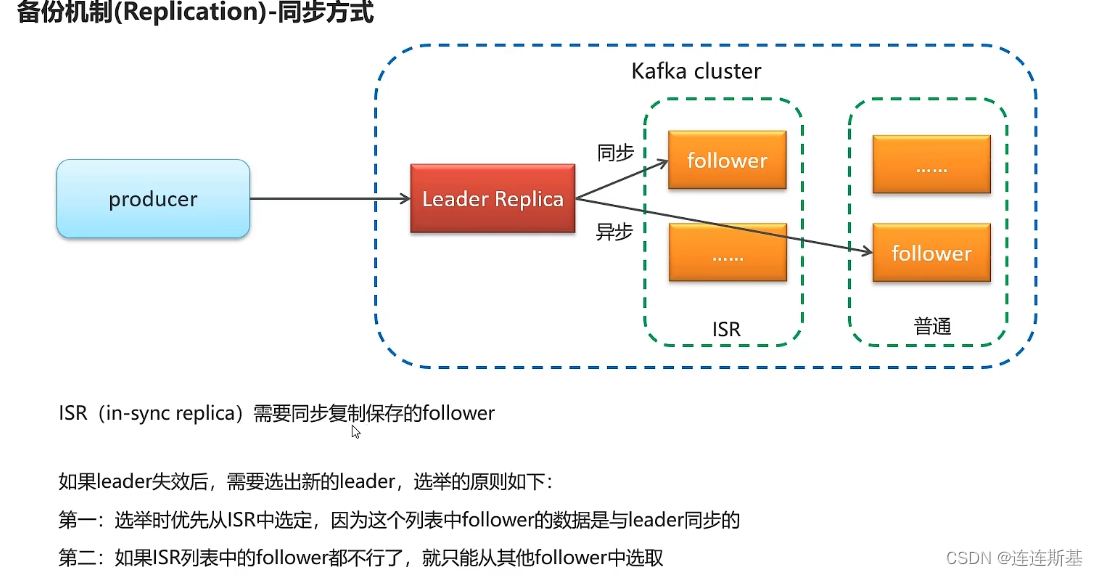
- ISR (réplica sincronizada): seguidores que deben copiarse y guardarse de forma sincrónica.
- Normal: guardado de forma asincrónica con la réplica líder.
- Cuando el líder fracasa, es necesario elegir un nuevo líder. Los principios de elección son los siguientes:
- Seleccione primero del ISR, porque los datos del mensaje en el ISR están sincronizados con el líder
- Si el seguidor en la lista ISR no está disponible, solo se puede seleccionar entre otros seguidores.
- Caso extremo: todas las copias no son válidas, entonces hay dos opciones:
- Espere a que uno de los ISR cobre vida y sea elegido líder. Los datos son confiables, pero el momento es incierto.
- Elija la primera copia que sobreviva como líder, no necesariamente en el ISR, para restaurar la disponibilidad lo más rápido posible, pero es posible que los datos no estén completos.
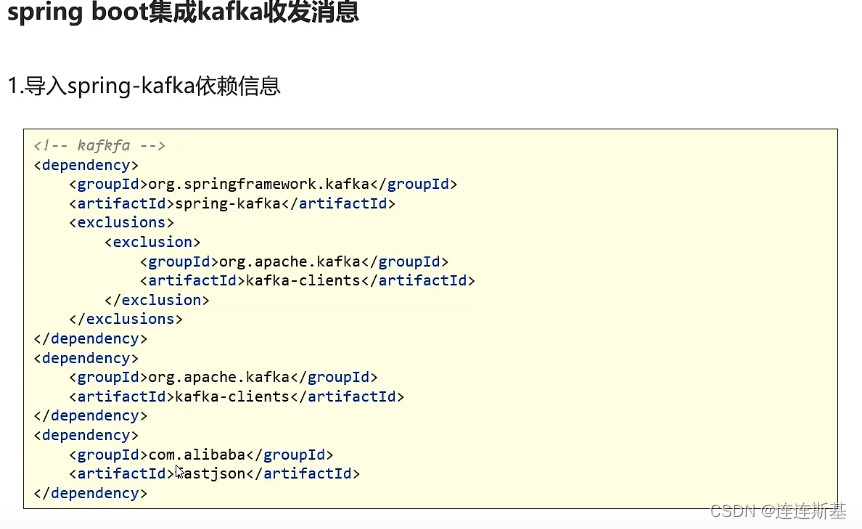
SpringBoot integra Kafka
uso básico

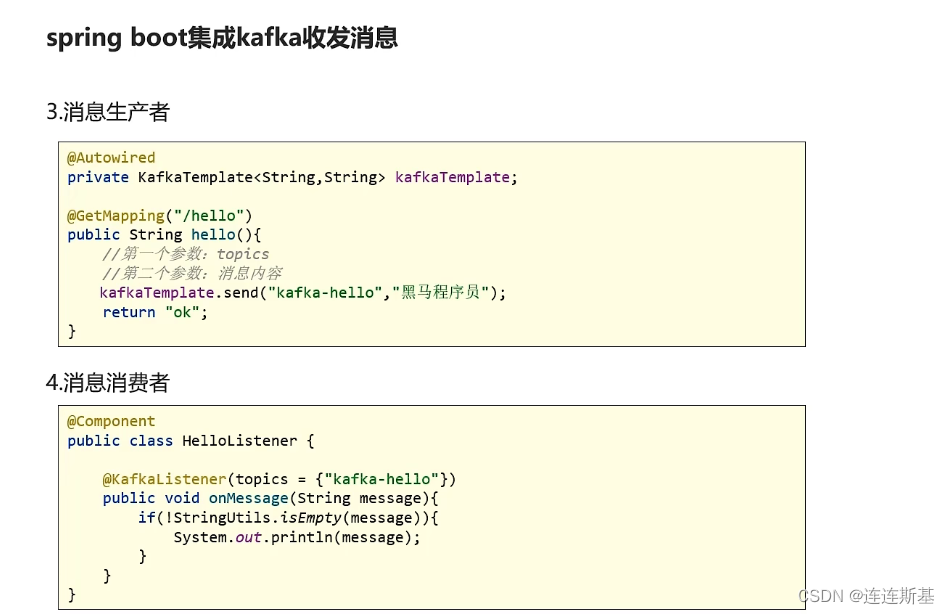
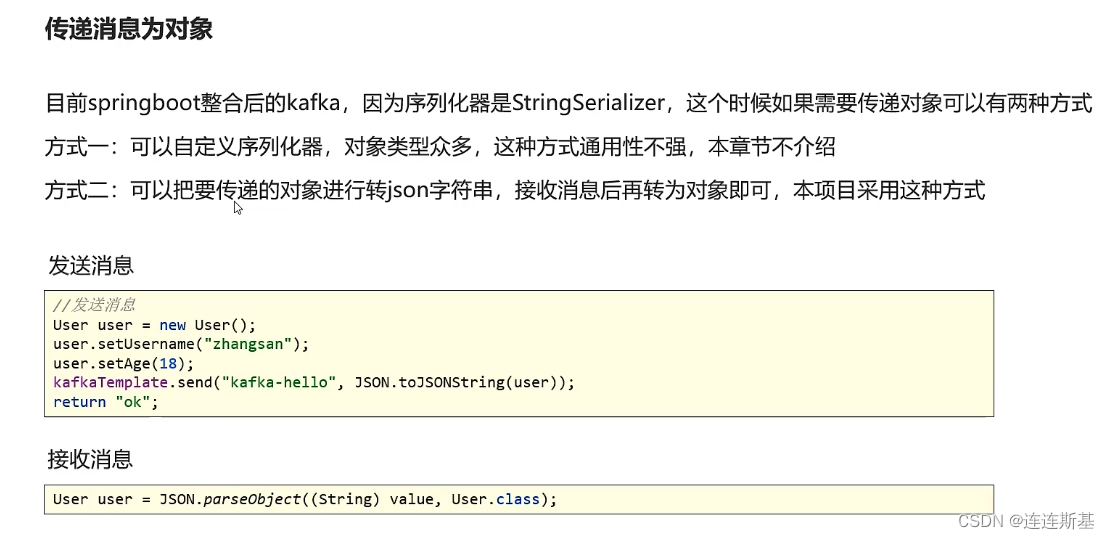
pasar mensaje de objeto