1. Modelo de cola de mensajes
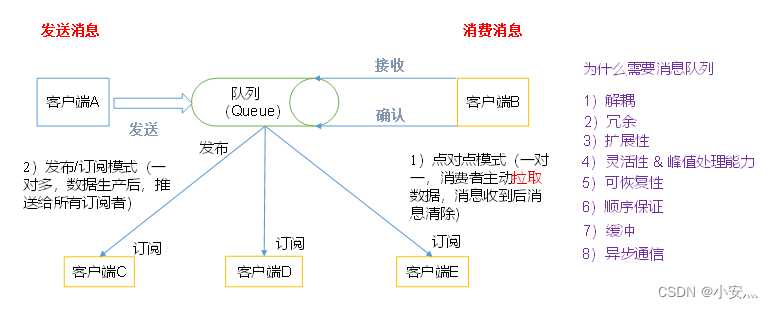
- Modo punto a punto
(uno a uno, los consumidores extraen datos activamente y el mensaje se borra después de recibir el mensaje). El modelo punto a punto suele ser un modelo de mensajería basado en extracción o sondeo. Este modelo solicita información de la cola en lugar de enviar mensajes Push al cliente. La característica de este modelo es que el mensaje enviado a la cola es recibido y procesado por uno y solo un receptor, incluso si hay múltiples escuchas de mensajes. - El modelo de publicación/suscripción
(uno a muchos, después de la producción de datos, se envía a todos los suscriptores) El
modelo de publicación-suscripción es un modelo de mensajería basado en notificaciones. El modelo de publicación-suscripción puede tener muchos suscriptores diferentes. Los suscriptores temporales solo reciben mensajes cuando escuchan activamente el tema, mientras que los suscriptores duraderos escuchan todos los mensajes del tema, incluso si el suscriptor actual no está disponible y está desconectado.
2. Escenarios de uso de la cola de mensajes
-
Desacoplamiento:
le permite ampliar o modificar el procesamiento en ambos lados de forma independiente, siempre que se adhieran a las mismas restricciones de interfaz. -
Redundancia:
las colas de mensajes conservan los datos hasta que se hayan procesado por completo, evitando así el riesgo de pérdida de datos. En el paradigma "insertar-obtener-eliminar" adoptado por muchas colas de mensajes, antes de eliminar un mensaje de la cola, necesita que su sistema de procesamiento indique claramente que el mensaje ha sido procesado, para garantizar que sus datos se guarden de manera segura. hasta que termines de usarlo. -
Escalabilidad:
debido a que la cola de mensajes desacopla su procesamiento, es fácil aumentar la frecuencia de la puesta en cola y el procesamiento de mensajes, siempre que se agregue un procesamiento adicional. -
Flexibilidad y capacidad máxima de procesamiento:
en el caso de un fuerte aumento en el tráfico, la aplicación aún debe seguir funcionando, pero este tráfico en ráfagas no es común. Sin duda, es un gran desperdicio invertir recursos en modo de espera en todo momento para manejar un acceso tan pico. El uso de colas de mensajes puede permitir que los componentes clave resistan la presión de acceso repentino sin colapsar por completo debido a solicitudes de sobrecarga repentinas. -
Recuperabilidad:
La falla de una parte del sistema no afecta a todo el sistema. La cola de mensajes reduce el acoplamiento entre procesos, por lo que incluso si un proceso que procesa mensajes se cuelga, los mensajes agregados a la cola aún se pueden procesar después de que el sistema se recupere. -
Garantía de pedido:
en la mayoría de los escenarios de uso, el orden de procesamiento de datos es importante. La mayoría de las colas de mensajes están ordenadas de forma inherente y pueden garantizar que los datos se procesarán en un orden específico. (Kafka garantiza el orden de los mensajes en una Partición) -
Buffering:
ayuda a controlar y optimizar la velocidad del flujo de datos a través del sistema, y resuelve la inconsistencia en la velocidad de procesamiento de los mensajes de producción y consumo. -
Comunicación asíncrona:
Muchas veces, los usuarios no quieren o no necesitan procesar los mensajes de forma inmediata. Las colas de mensajes proporcionan un mecanismo de procesamiento asíncrono que permite a los usuarios colocar un mensaje en una cola sin procesarlo inmediatamente. Ponga en la cola tantos mensajes como desee y procéselos cuando sea necesario.
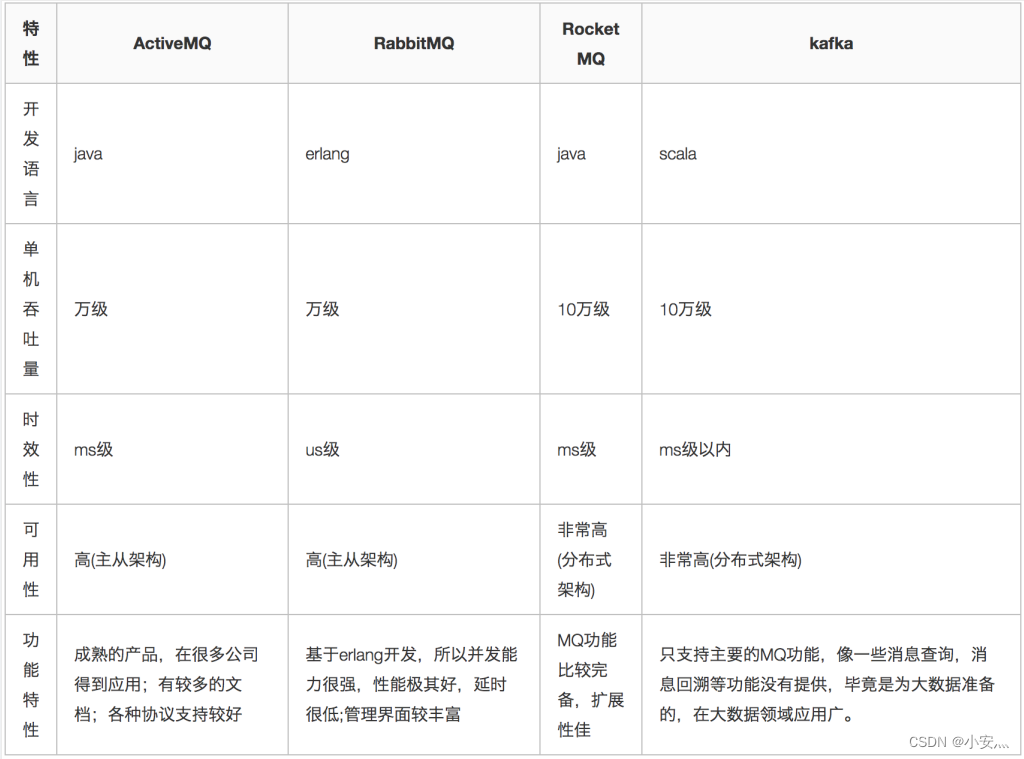
3. Comparación de colas de mensajes
4. Arquitectura de la cola de mensajes
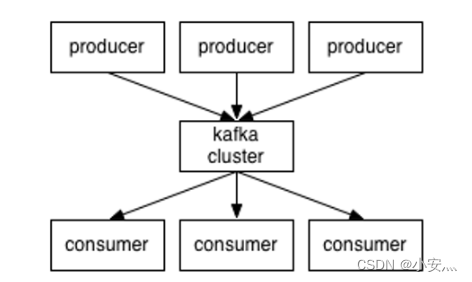
4.1, Kafka
-
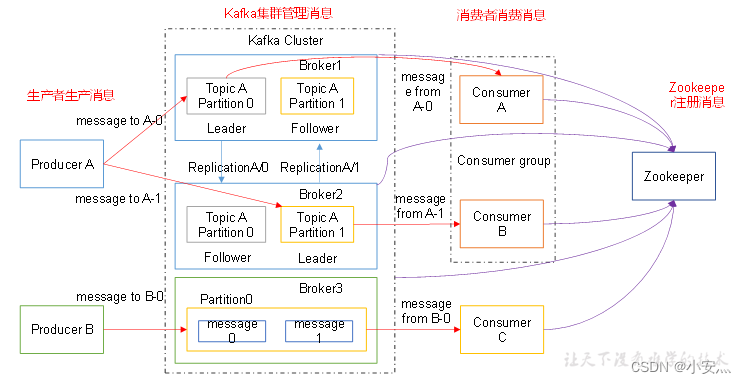
Productor : el productor de mensajes es el cliente que envía mensajes al agente kafka;
-
Consumidor : consumidor de mensajes, el cliente que obtiene mensajes del agente kafka;
-
Tema : Puede entenderse como una cola;
-
Grupo de consumidores (CG) : este es el método utilizado por Kafka para transmitir (enviar a todos los consumidores) y unidifundir (enviar a cualquier consumidor) un mensaje de tema. Un tema puede tener varios CG. El mensaje del tema se copiará (no se copiará realmente, pero sí conceptualmente) a todos los CG, pero cada partición solo enviará el mensaje a un consumidor en el CG. Si necesita implementar la transmisión, siempre que cada consumidor tenga un CG independiente. Lograr unidifusión siempre que todos los consumidores estén en el mismo CG. Con CG, los consumidores también pueden agruparse libremente sin enviar mensajes a diferentes temas varias veces;
-
Broker : Un servidor kafka es un broker. Un clúster consta de varios intermediarios. Un corredor puede acomodar múltiples temas;
-
Partición : para lograr la escalabilidad, un tema muy grande se puede distribuir a varios intermediarios (es decir, servidores), un tema se puede dividir en varias particiones y cada partición es una cola ordenada. A cada mensaje en la partición se le asignará una identificación ordenada (desplazamiento). Kafka solo garantiza enviar mensajes a los consumidores en el orden de una partición y no garantiza el orden de un tema como un todo (entre múltiples particiones);
-
Offset : los archivos de almacenamiento de Kafka se nombran de acuerdo con offset.kafka. La ventaja de usar offset como nombre es que es fácil de encontrar. Por ejemplo, si desea encontrar la ubicación en 2049, solo necesita encontrar el archivo 2048.kafka. Por supuesto, el primer desplazamiento es 00000000000.kafka.
4. RocketMQ
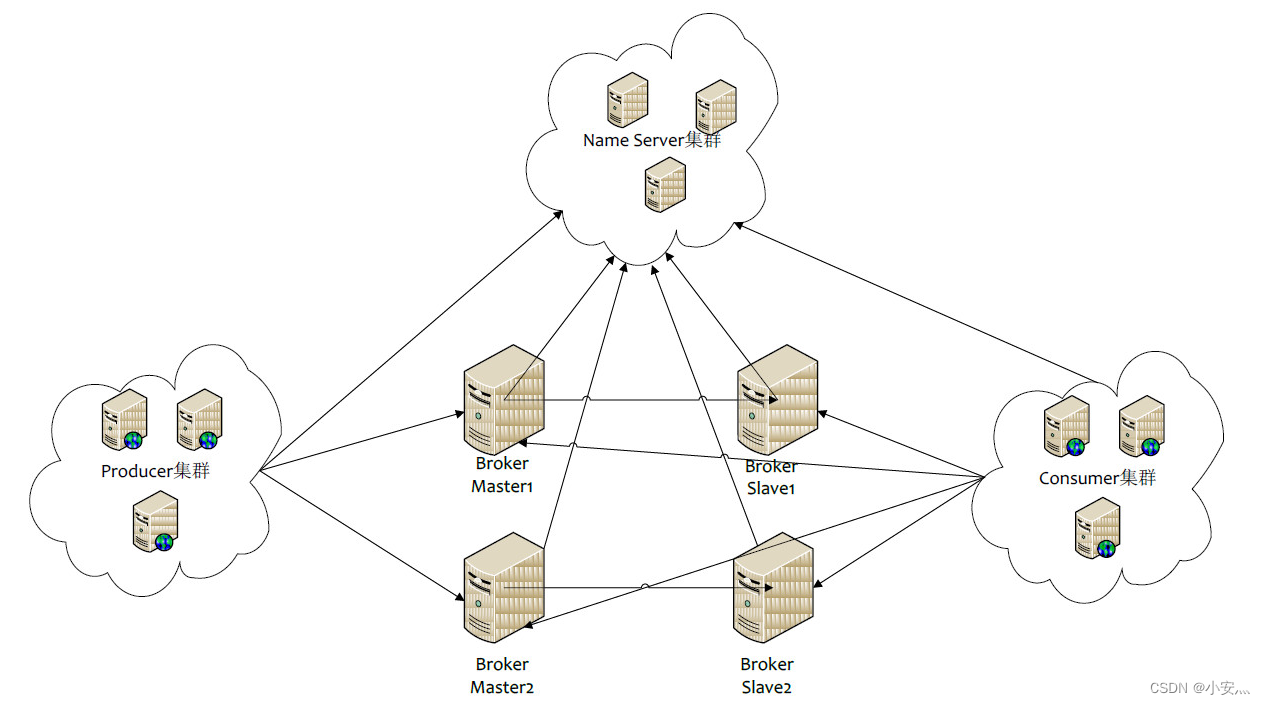
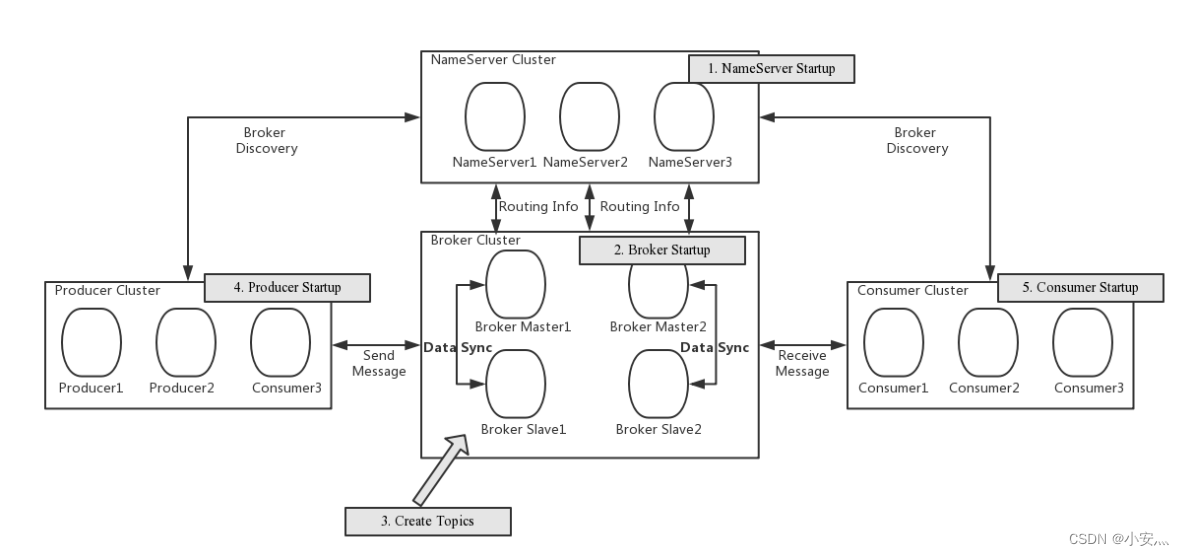
-
NameServer : es un nodo casi sin estado que se puede implementar en un clúster sin ninguna sincronización de información entre nodos.
-
Broker : la implementación de Broker es relativamente complicada. Broker se divide en Master y Slave. Un Master puede corresponder a múltiples Slaves, pero un Slave solo puede corresponder a un Master. La relación correspondiente entre Master y Slave se define especificando el mismo BrokerName y diferentes BrokerId BrokerId 0 significa Maestro, distinto de cero significa Esclavo. El maestro también puede implementar múltiples. Cada Broker establece una conexión persistente con todos los nodos en el clúster de NameServer y registra periódicamente la información del tema para todos los NameServers.
-
Productor : el productor establece una conexión larga con uno de los nodos en el clúster del servidor de nombres (seleccionado al azar), obtiene periódicamente información de enrutamiento de temas del servidor de nombres, establece una conexión larga con el maestro que proporciona servicios de temas y envía latidos al maestro. regularmente. Producer no tiene estado y se puede implementar en clústeres.
-
Consumidor : el consumidor establece una conexión a largo plazo con uno de los nodos en el clúster de NameServer (seleccionado al azar), obtiene regularmente información de enrutamiento de temas de NameServer, establece una conexión a largo plazo con Master y Slave que brindan servicios de temas y envía latidos a Maestro y Esclavo regularmente. Los consumidores pueden suscribirse a los mensajes del Maestro o del Esclavo, y las reglas de suscripción están determinadas por la configuración del Broker.
5. Proceso de escritura de datos
5.1, Kafka
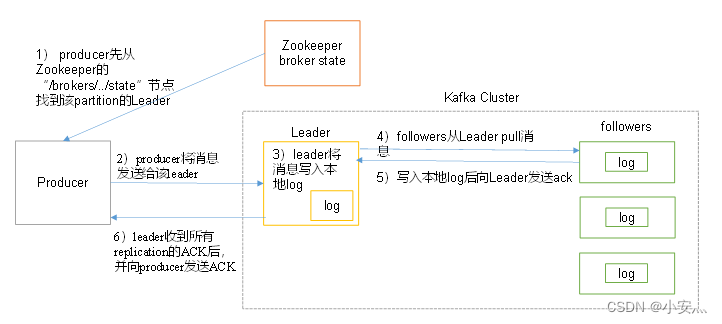
- El productor primero encuentra el líder de la partición desde el nodo "/brokers/.../state" de zookeeper
- El productor envía el mensaje al líder.
- El líder escribe el mensaje en el registro local.
- Los seguidores extraen mensajes del líder, escriben en el registro local y envían ACK al líder
- Después de que el líder recibe el ACK de todas las replicaciones en el ISR , aumenta HW (marca de agua alta, compensación del último compromiso) y envía ACK al productor
6. Estructura de almacenamiento de datos
6.1, Kafka
6.1.1, corredor
- Dividir físicamente el tema en una o más aficiones
- patition: correspondiente a la configuración num.partitions=3 en server.properties
- Cada patición corresponde físicamente a una carpeta (la carpeta almacena todos los mensajes y archivos de índice de la patición), de la siguiente manera:
[root@hadoop102 logs]$ ll
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 root root 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-2
[root@hadoop102 logs]$ cd first-0
[root@hadoop102 first-0]$ ll
-rw-rw-r--. 1 root root 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 root root 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 root root 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 root root 8 8月 6 14:37 leader-epoch-checkpoint
política de almacenamiento
Kafka guarda todos los mensajes independientemente de si se consumen o no. Existen dos estrategias para eliminar datos antiguos:
- Basado en el tiempo: log.retention.hours=168
- Según el tamaño: log.retention.bytes=1073741824
Cabe señalar que debido a que la complejidad de tiempo de Kafka para leer un mensaje específico es O(1), es decir, no tiene nada que ver con el tamaño del archivo, por lo que eliminar aquí los archivos caducados no tiene nada que ver con mejorar el rendimiento de Kafka.
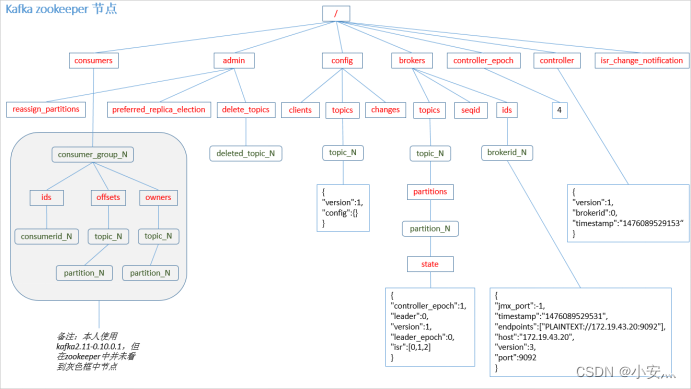
6.1.2, cuidador del zoológico
PD: El productor no está registrado en zk y el consumidor está registrado en zk.
6.2, Rocket MQ
- El almacenamiento de mensajes de RocketMQ se completa con la cooperación de ConsumeQueue y CommitLog.
- CommitLog : es el archivo de almacenamiento físico real del mensaje
- ConsumeQueue : Es una cola lógica de mensajes, similar a un archivo de índice de una base de datos, que almacena direcciones que apuntan al almacenamiento físico.
- Cada Message Queue debajo de cada Tema tiene un archivo ConsumeQueue correspondiente.

- CommitLog : almacenar metadatos para mensajes
- ConsumerQueue : almacena el índice del mensaje en el CommitLog
- IndexFile : proporciona un método de consulta de mensajes por clave o intervalo de tiempo para la consulta de mensajes. Este método de búsqueda de mensajes a través de IndexFile no afecta el proceso principal de envío y consumo de mensajes.
Mecanismo de cepillo:
- Los mensajes de RocketMQ se almacenan en el disco, lo que no solo garantiza la recuperación después de un corte de energía, sino que también permite que la cantidad de mensajes almacenados exceda el límite de memoria.
- Para mejorar el rendimiento, RocketMQ intentará garantizar la escritura secuencial del disco tanto como sea posible.
- Cuando el mensaje se escribe en RocketMQ a través del Productor, hay dos formas de escribir en el disco, que son sincrónicas y asincrónicas.
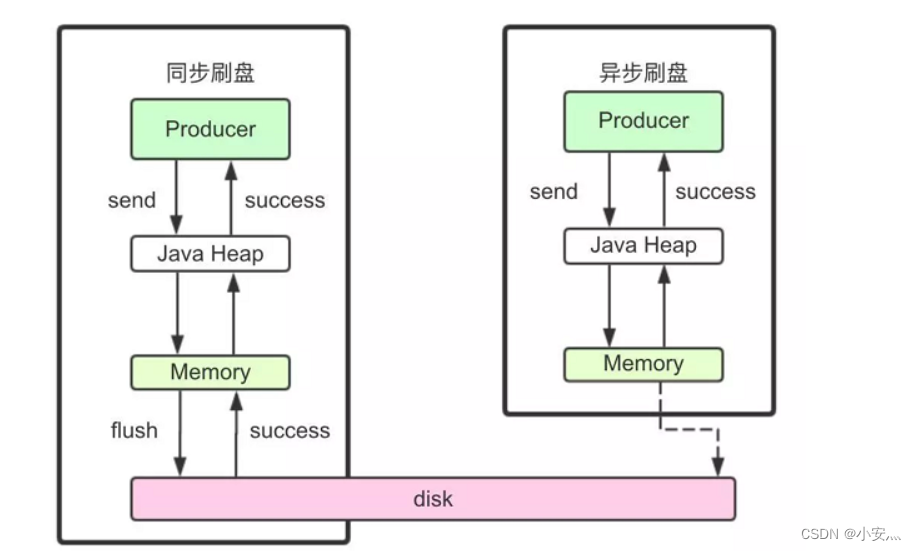
1) Cepillado síncrono
Al devolver un estado de éxito de escritura, el mensaje se ha escrito en el disco. El proceso específico es que después de escribir el mensaje en el PAGECACHE de la memoria, se notifica inmediatamente al subproceso para actualizar el disco que vacíe el disco y luego espera a que finalice el vaciado del disco. completado, el subproceso en espera se activa y el estado de escritura del mensaje se devuelve correctamente.
2) Cepillado asíncrono
Cuando se devuelve el estado de éxito de escritura, el mensaje solo se puede escribir en el PAGECACHE de la memoria. El retorno de la operación de escritura es rápido y el rendimiento es grande; cuando la cantidad de mensajes en la memoria se acumula hasta cierto nivel, el la acción de escritura en disco se activa uniformemente y se escribe rápidamente.
3) Configuración
La descarga del disco de forma síncrona o asíncrona se establece a través del parámetro flushDiskType en el archivo de configuración del bróker.Este parámetro está configurado como uno de SYNC_FLUSH y ASYNC_FLUSH.
Replicación maestro-esclavo de mensajes
Si un grupo de Broker tiene un Maestro y un Esclavo, los mensajes deben copiarse del Maestro al Esclavo, y existen dos métodos de replicación: síncrona y asíncrona.
1) replicación síncrona
El método de replicación síncrona consiste en esperar a que tanto el Maestro como el Esclavo escriban correctamente antes de devolver el estado de escritura correcto al cliente;
En el modo de replicación síncrona, si el Maestro falla, todos los datos de respaldo en el Esclavo son fáciles de restaurar, pero la replicación síncrona aumentará el retraso de escritura de datos y reducirá el rendimiento del sistema.
2) replicación asíncrona
El método de replicación asíncrona consiste en que, siempre que el maestro escriba con éxito, puede informar al cliente sobre el estado de éxito de la escritura.
En el modo de replicación asincrónica, el sistema tiene una latencia más baja y un rendimiento más alto, pero si el Maestro falla, algunos datos pueden perderse porque no se escribieron en el Esclavo;
3) Configuración
La replicación síncrona y la replicación asíncrona se establecen a través del parámetro brokerRole en el archivo de configuración del intermediario.Este parámetro se puede establecer en uno de los tres valores de ASYNC_MASTER, SYNC_MASTER y SLAVE.
4) Resumen
- En aplicaciones prácticas, es necesario combinar los escenarios comerciales y establecer razonablemente el modo de vaciado de disco y el modo de replicación maestro-esclavo, especialmente el modo SYNC_FLUSH, que reducirá significativamente el rendimiento debido a la activación frecuente de acciones de escritura en disco.
- Normalmente, el maestro y el esclavo deben configurarse como ASYNC_FLUSH, y el maestro-esclavo debe configurarse como SYNC_MASTER, de modo que incluso si una máquina falla, los datos no se perderán, lo cual es una buena opción.