aprendizaje de intercambio de colas de mensajes
I. Descripción general
Las colas de mensajes son un middleware importante en los sistemas distribuidos y desempeñan un papel importante en las arquitecturas del sistema, como el alto rendimiento, la alta disponibilidad y el bajo acoplamiento. Los sistemas distribuidos pueden implementar fácilmente las siguientes funciones con la ayuda de capacidades de cola de mensajes:
- El desacoplamiento separa el flujo ascendente y descendente de un proceso, el flujo ascendente se enfoca en producir mensajes y el flujo descendente se enfoca en procesar mensajes.
- Con la radiodifusión , un mensaje producido en sentido ascendente puede ser procesado fácilmente por múltiples servicios descendentes.
- Almacenamiento en búfer , en respuesta a un aumento repentino del tráfico, la cola de mensajes puede actuar como un búfer para proteger los servicios posteriores para que puedan procesar mensajes de acuerdo con las capacidades de consumo reales.
- Asincrónico , el flujo ascendente puede regresar inmediatamente después de enviar el mensaje y el flujo descendente puede procesar el mensaje de forma asincrónica.
- La redundancia , el mantenimiento de mensajes históricos, los errores de procesamiento o las excepciones se pueden volver a intentar o rastrear para evitar pérdidas.
La siguiente figura muestra el modelo básico de la cola de mensajes: quienes almacenan datos en la cola de mensajes se denominan productores y quienes obtienen datos de la cola de mensajes se denominan consumidores.
La imagen de arriba muestra la estructura general, que involucra tres tipos de roles:
1) Productor productor de mensajes : Responsable de generar y enviar mensajes al Broker;
2) Centro de procesamiento de mensajes del intermediario : Responsable del almacenamiento, confirmación, reintento, etc. de mensajes, generalmente contendrá varias colas;
3) Consumidor de mensajes del consumidor : responsable de obtener mensajes del Broker y procesarlos en consecuencia;
2. Introducción e instalación del producto.
| ConejoMQ | ActivoMQ | cohetemq | kafka | |
| Empresa/Comunidad | Conejo | apache | Alí | apache |
| Lenguaje de desarrollo | erlang | Java | Java | escala y Java |
| soporte de protocolo | AMQP, XMPP, SMTP, PISO | OpenWire, PISO, DESCANSO, XMPP, AMQP | protocolo personalizado | protocolo personalizado |
| disponibilidad | alto | generalmente | alto | alto |
| Rendimiento independiente | generalmente | Diferencia | alto | muy alto |
| retraso del mensaje | nivel de microsegundos | Milisegundo | Milisegundo | en milisegundos |
| confiabilidad del mensaje | alto | generalmente | alto | generalmente |
1. conejoMQ
Sitio web oficial de RabbitMQ.
RabbitMQ es un sistema de cola de mensajes de código abierto desarrollado utilizando el lenguaje Erlang e implementado en base al protocolo AMQP. Las características principales de AMQP son la orientación a mensajes, la cola, el enrutamiento (incluido punto a punto y publicación/suscripción), confiabilidad y seguridad. El protocolo AMQP se utiliza principalmente en sistemas empresariales, donde los requisitos de coherencia, estabilidad y confiabilidad de los datos son altos, y los requisitos de rendimiento y rendimiento ocupan un segundo lugar.
La dirección de referencia de instalación es dockerhub.
1.1 Instalación
Rabbitmq se instala en la ventana acoplable de Windows:
docker run -d --hostname my-rabbit --name my-rabbit -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=123456 -p 5672:5672 -p 15672:15672 rabbitmq:3-management
Descripción del parámetro RabbitMQ:
- nombre de host : configura el nombre de host, utilizado en el clúster, la versión independiente también se puede configurar sin configuración
- RABBITMQ_DEFAULT_USER : crear usuario
- RABBITMQ_DEFAULT_PASS : crear contraseña de usuario
Descripción del parámetro de Docker:
- d : ejecutar en segundo plano
- nombre : El nombre del contenedor generado por la imagen.
- p : asigna el puerto host
DIRECCIÓN
interfaz de gestión de RabbitMQ


1.2 Función
Varios conceptos en RabbitMQ:
- canal : una herramienta para operar MQ
- intercambio : enruta mensajes a colas
- cola : mensajes en caché
- host virtual : host virtual, que es una agrupación lógica de recursos como cola e intercambio
Modelos de mensajes comunes:
1. No utilice Exchange (un mensaje solo puede ser consumido por un consumidor)
-
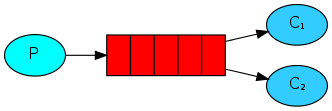
Cola de mensajes básica (BasicQueue)

-
Cola de mensajes de trabajo (WorkQueue)
Segundo, usa el intercambio.
-
Publicar/Suscribir (Publicar\Suscribir) se divide en tres tipos según los diferentes tipos de conmutadores:
-
Intercambio Fanout: Radiodifusión
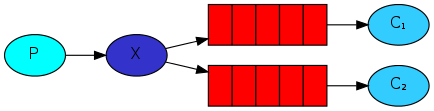
-
Intercambio directo: enrutamiento
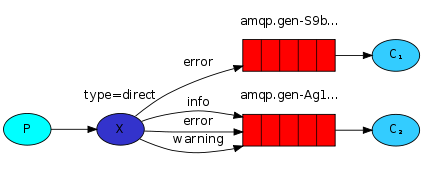
-
Intercambio de temas: tema
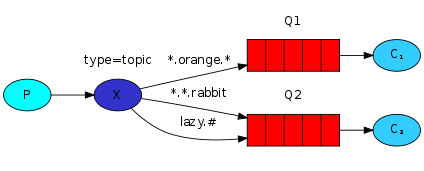
-
1.3 Preguntas frecuentes
- Fiabilidad del mensaje (cómo garantizar que un mensaje enviado se consuma al menos una vez)
- Problema de mensajes retrasados (cómo lograr la entrega retrasada de mensajes)
- Problema de acumulación de mensajes (cómo solucionar el problema de que se acumulan millones de mensajes y no se pueden consumir a tiempo)
- Problemas de alta disponibilidad (cómo evitar problemas de no disponibilidad causados por fallas de MQ de un solo punto)
1.3.1 Fiabilidad del mensaje
El mensaje se envía desde el productor al intercambio, luego a la cola y luego al consumidor, lo que genera la posibilidad de pérdida del mensaje:
- Perdido en el envío:
- El mensaje enviado por el productor no fue entregado al intercambio.
- El mensaje no llegó a la cola después de llegar al intercambio.
- MQ está inactivo, la cola perderá el mensaje
- El consumidor falla sin consumir el mensaje después de recibirlo.
solución:
- Mecanismo de confirmación del productor
RabbitMQ proporciona un mecanismo de confirmación del editor para evitar la pérdida de mensajes cuando se envían a MQ. Después de enviar el mensaje a MQ, se devolverá un resultado al remitente, indicando si el mensaje se procesó correctamente. En consecuencia, existen dos tipos de solicitudes:
- confirmación del editor, el remitente confirma
- El mensaje se entrega exitosamente al conmutador y devuelve un acuse de recibo (acuse de recibo).
- El mensaje no fue entregado al intercambio, devuélvalo nuevamente.
- devolución del editor, recibo del remitente
- El mensaje se entregó al conmutador, pero no se enruta a la cola, se devolvió el reconocimiento y el motivo del error de enrutamiento
Cuando el mecanismo de confirmación envía un mensaje, es necesario establecer una identificación única global para cada mensaje para distinguir diferentes mensajes y evitar conflictos de confirmación.
2) Persistencia del mensaje
La creación de conmutadores y colas en el cliente Rabbitmq no es persistente si Durabilidad no está configurada en Durable y los mensajes deben configurarse en Modo de entrega: persistente; de lo contrario, no son persistentes. Después de reiniciar mq, los conmutadores, las colas y los mensajes desaparecerán.
3) Confirmación del mensaje del consumidor
RabbitMQ admite el mecanismo de confirmación del consumidor, es decir, el consumidor puede enviar un acuse de recibo a MQ después de procesar el mensaje, y MQ eliminará el mensaje solo después de recibir el acuse de recibo. SpringAMQP permite la configuración de tres modos de confirmación:
- manual: confirmación manual, debe llamar a la API para enviar la confirmación después de que finalice el código comercial
- auto: reconocimiento automático, Spring monitorea el código de escucha para ver si hay una excepción; si no hay excepción, devolverá un reconocimiento; si se lanza una excepción, devolverá nack
- none: cerrar confirmación, MQ supone que el consumidor procesará exitosamente el mensaje después de recibirlo, por lo que el mensaje se eliminará inmediatamente después de la entrega.
4) Mecanismo de reintento fallido
Cuando el consumidor tiene una excepción, el mensaje continuará en cola (volver a poner en cola) en la cola y luego se reenviará al consumidor, y luego la excepción nuevamente, se volverá a poner en cola, un bucle infinito, lo que provocará que el procesamiento de mensajes de mq se dispare. ejerciendo presión innecesaria
1.3.2 Intercambio de mensajes no entregados
Cuando un mensaje en una cola cumple una de las siguientes condiciones, puede convertirse en letra muerta:
- El consumidor usa basic.reject o basic.nack para declarar una falla de consumo y el parámetro de cola del mensaje se establece en falso.
- El mensaje es un mensaje caducado, nadie lo consume después del tiempo de espera.
- La cola de mensajes a entregar está llena y los primeros mensajes pueden convertirse en letra muerta
Si la cola está configurada con el atributo de intercambio de mensajes no entregados y se especifica un intercambio, los mensajes no entregados en la cola se entregarán a este intercambio, y este intercambio se denomina Intercambio de mensajes no entregados (DLX para abreviar).
Cómo vincular un intercambio de mensajes no entregados a una cola
- Establezca el atributo de intercambio de mensajes fallidos en la cola y especifique un intercambio
- Establezca el atributo clave de enrutamiento de mensajes no entregados para la cola y configure la clave de enrutamiento del conmutador de mensajes no entregados y la cola de mensajes no entregados.
TTL, es decir, Time-To-Live. Si el mensaje TTL en una cola finaliza y aún se consume, se convertirá en letra muerta. Hay dos casos de tiempo de espera de TTL:
- La cola donde se encuentra el mensaje tiene establecido un tiempo de supervivencia
- El mensaje mismo marca el tiempo para vivir.
1.3.3 Cola diferida
-
problema de acumulación de mensajes
Cuando la velocidad a la que los productores envían mensajes excede la velocidad a la que los consumidores pueden procesar mensajes, los mensajes en la cola se acumularán hasta que la cola almacene mensajes hasta el límite superior. El primer mensaje recibido puede convertirse en letra muerta y descartarse: éste es el problema de la acumulación de mensajes.
Hay tres formas de resolver el problema de acumulación de mensajes:
- Agregue más consumidores y aumente la velocidad de consumo.
- Abra el grupo de subprocesos en el consumidor para acelerar el procesamiento de mensajes
- Ampliar el volumen de la cola y aumentar la acumulación en línea.
-
cola perezosa
A partir de la versión 3.6.0 de RabbitMQ, se agregó el concepto de Lazy Queues, es decir, colas diferidas.
Las características de la cola diferida son las siguientes:
- Después de recibir el mensaje, guárdelo directamente en el disco en lugar de en la memoria.
- Los consumidores solo leen del disco y los cargan en la memoria cuando quieren consumir mensajes.
- Admite millones de almacenamiento de mensajes
1.3.4 Clúster MQ
- **Clúster ordinario:** es un clúster distribuido que distribuye la cola a cada nodo del clúster, mejorando así la capacidad de concurrencia de todo el clúster.
- Parte de los datos se compartirán entre cada nodo del clúster, incluidos: metadatos de conmutador y cola. No incluye mensajes en la cola.
- Al acceder a un nodo en el clúster, si la cola no está en el nodo, se pasará del nodo donde se encuentran los datos al nodo actual y se devolverá.
- Si el nodo donde se encuentra la cola deja de funcionar, los mensajes de la cola se perderán
- **Clúster espejo:** es un clúster maestro-esclavo. Sobre la base de los clústeres ordinarios, se agrega una función de copia de seguridad maestro-esclavo para mejorar la disponibilidad de datos del clúster.
- Se realizará una copia de seguridad de los conmutadores, las colas y los mensajes en las colas de forma sincrónica entre los nodos espejo de cada mq.
- El nodo que crea la cola se denomina nodo principal de la cola y los demás nodos de los que se realiza una copia de seguridad se denominan nodos espejo de la cola.
- El nodo maestro de una cola puede ser el nodo espejo de otra cola.
- Todas las operaciones las completa el nodo maestro y luego se sincronizan con el nodo espejo.
- Después de que el maestro caiga, el nodo espejo será reemplazado por el nuevo maestro.
Aunque el clúster espejo admite el esclavo intermedio, la sincronización maestro-esclavo no es muy consistente y, en algunos casos, puede haber riesgo de pérdida de datos. Por lo tanto, después de la versión 3.8 de RabbitMQ, se retira una nueva función: la cola de arbitraje reemplaza el clúster espejo y la capa inferior adopta el protocolo Raft para garantizar la coherencia de los datos del maestro y el esclavo.
2.kafka
Kafka fue desarrollado originalmente por Linkedin. Es un sistema de mensajería distribuida basado en réplicas, que admite particiones y se basa en la coordinación del cuidador del zoológico. Su característica más importante es que puede procesar grandes cantidades de datos en tiempo real para satisfacer varios escenarios de demanda: como Sistema de procesamiento por lotes basado en hadoop, sistema en tiempo real de baja latencia, motor de procesamiento de transmisión Storm/Spark, registro web/nginx, registro de acceso, servicio de mensajes, etc., escrito en lenguaje Scala, aportado por Linkedin en 2010 Gave to the Apache Foundation y se convirtió en uno de los principales proyectos de código abierto.
2.1 Antecedentes
Kafka nació para resolver el problema de la canalización de datos de LinkedIn. Al principio, LinkedIn adoptó ActiveMQ para el intercambio de datos, alrededor de 2010, pero ActiveMQ estaba lejos de cumplir con los requisitos de LinkedIn para los sistemas de entrega de datos, a menudo debido a varios Para resolver este problema, LinkedIn decidió desarrollar su propio sistema de mensajería. En ese momento, Jay Kreps, el arquitecto jefe de LinkedIn, comenzó a organizar un equipo para desarrollar el sistema de mensajería.
2.2 Características de Kafka
- Alto rendimiento, baja latencia : Kafka puede procesar cientos de miles de mensajes por segundo y su latencia es tan baja como unos pocos milisegundos.
- Escalabilidad : el clúster Kafka admite la expansión térmica
- Persistencia y confiabilidad : los mensajes persisten en los discos locales y se admite la copia de seguridad de datos para evitar la pérdida de datos.
- Tolerancia a fallos : permitir que fallen los nodos del clúster (si el número de réplicas es n, se permite que fallen n-1 nodos)
- Alta concurrencia : admite que miles de clientes lean y escriban al mismo tiempo
2.3 Aplicación del escenario Kafka
- Recopilación de registros : una empresa puede utilizar Kafka para recopilar registros de varios servicios y abrirlos a varios consumidores a través de Kafka como un servicio de interfaz unificado, como hadoop, Hbase, Solr, etc.
- Sistema de mensajes : desacoplamiento y productores y consumidores, almacenamiento en caché de mensajes, etc.
- Seguimiento de la actividad del usuario : Kafka se utiliza a menudo para registrar diversas actividades de los usuarios de la web o de la aplicación, como navegar por la web, buscar, hacer clic y otras actividades. Cada servidor publica esta información de actividad en el tema de Kafka y luego los suscriptores se suscriben. a estos temas Para realizar monitoreo y análisis en tiempo real, o cargarlo en hadoop o almacén de datos para análisis y minería fuera de línea.
- Indicadores operativos : Kafka también se utiliza a menudo para registrar datos de seguimiento operativo. Esto incluye recopilar datos de varias aplicaciones distribuidas y producir comentarios centralizados para diversas operaciones, como alarmas e informes.
- Procesamiento de transmisión : como transmisión de chispas y tormenta
- fuente del evento
2.4 instalación
instalar cuidador del zoológico
docker pull zookeeper
docker run --name zoo -p 2181:2181 -d zookeeper
Instalar kafka (método 1)
docker pull bitnami/kafka
docker run --name kafka -p 9092:9092 -e KAFKA_ZOOKEEPER_CONNECT=10.30.1.13:2181 -e ALLOW_PLAINTEXT_LISTENER=yes -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -d bitnami/kafka
La implementación del contenedor Docker debe especificar las siguientes variables de entorno:
- **KAFKA_ZOOKEEPER_CONNECT **Especifique la dirección del cuidador del zoológico: puerto.
- ALLOW_PLAINTEXT_LISTENER permite el uso de oyentes PLAINTEXT.
- KAFKA_ADVERTISED_LISTENERS es una lista de direcciones disponibles que apuntan a corredores de Kafka. Kafka los enviará a los clientes en la conexión inicial. El formato es PLAINTEXT://host:puerto, donde el puerto 9092 del contenedor se ha asignado al puerto 9092 del host, por lo que el host se especifica como localhost y el programa de prueba se puede ejecutar en el host para conectarse a Kafka.
- KAFKA_LISTENERS es una lista de direcciones que el agente Kafka escuchará para detectar conexiones entrantes. El formato es PLAINTEXT://host:puerto, 0.0.0.0 significa aceptar todas las direcciones. Esta variable se establece cuando se establece la variable anterior.
Utilice la implementación del clúster Docker-Compose (método 2)
docker-compose.yml
version: '2'
services:
zoo1:
image: zookeeper
container_name: zoo
ports:
- 2181:2181
kafka1:
image: 'bitnami/kafka:latest'
ports:
- '9092:9092'
container_name: kafka1
environment:
- KAFKA_ZOOKEEPER_CONNECT=zoo1:2181
- KAFKA_BROKER_ID=1
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:///127.0.0.1:9092
depends_on:
- zoo1
kafka2:
image: 'bitnami/kafka:latest'
ports:
- '9093:9092'
container_name: kafka2
environment:
- KAFKA_ZOOKEEPER_CONNECT=zoo1:2181
- KAFKA_BROKER_ID=2
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:///127.0.0.1:9093
depends_on:
- zoo1
kafka3:
image: 'bitnami/kafka:latest'
ports:
- '9094:9092'
container_name: kafka3
environment:
- KAFKA_ZOOKEEPER_CONNECT=zoo1:2181
- KAFKA_BROKER_ID=3
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:///127.0.0.1:9094
depends_on:
- zoo1
instalación de herramientas kafka
Una vez completada la instalación, agregue información de Kafka, como se muestra en la interfaz de operación como se muestra a continuación

Una vez completada la adición, como se muestra en la siguiente figura:

2.5 Funciones

2.5.1 Varios conceptos en Kafka
-
corredor
- Un clúster Kafka consta de varios intermediarios para lograr equilibrio de carga y tolerancia a fallas.
- Los corredores no tienen estado y mantienen el estado del clúster a través del cuidador del zoológico.
- Un corredor de Kafka puede manejar cientos de miles de lecturas y escrituras por segundo, y cada corredor puede manejar mensajes TB sin afectar el rendimiento.
-
cuidador del zoológico
- Zookeeper se utiliza para administrar y coordinar intermediarios y almacena metadatos de Kafka (por ejemplo: cuántos temas, particiones)
- El servicio zookeeper se utiliza principalmente para notificar a productores y consumidores que un nuevo corredor se ha unido al clúster de Kafka o que un corredor ha fallado en el clúster de Kafka.
-
productor
- El productor es responsable de enviar datos al tema del corredor.
-
consumidor
- Los consumidores son responsables de extraer datos del tema del corredor y procesarlos ellos mismos.
-
grupo de consumidores (grupo de consumidores)

- El grupo de consumidores es un mecanismo de consumidores escalable y tolerante a fallas proporcionado por Kafka.
- Un grupo de consumidores puede contener varios consumidores.
- Un grupo de consumidores tiene una identificación única (ID de grupo)
- Los consumidores del grupo consumen todos los datos de partición del tema juntos
Resumen de comprensión personal:
En términos generales, los modelos de mensajes se pueden dividir en dos tipos: cola y publicación-suscripción. El método de procesamiento de la cola es que un grupo de consumidores lee mensajes del servidor y solo uno de los consumidores puede procesar un mensaje. En el modelo de publicación-suscripción, el mensaje se transmite a todos los consumidores y los consumidores que lo reciben pueden procesarlo. Kafka proporciona una única abstracción de consumidores para ambos modelos: el grupo de consumidores. Los consumidores se identifican con el nombre de un grupo de consumidores. Un mensaje publicado en un tema se entrega a un consumidor de este grupo de consumidores. Si todos los consumidores están en un grupo, este se convierte en el modelo de cola. Si todos los consumidores están en grupos diferentes, entonces se convierte en un modelo completo de publicación-suscripción.
- Particiones

Una partición solo puede ser consumida por un consumidor a la vez
-
replicación
- Las réplicas pueden garantizar que los datos sigan disponibles cuando falla un servicio
-
tema (tema)
- Un tema es un concepto lógico para que los productores publiquen datos y los consumidores extraigan datos.
- Los temas en Kafka deben tener identificadores y ser únicos. Puede haber cualquier número de temas en Kafka y no hay límite en el número.
- Los mensajes del tema están estructurados y, generalmente, un tema contiene un determinado tipo de mensaje.
- Una vez que un productor envía mensajes a un tema, esos mensajes no se pueden actualizar (cambiar)
-
compensación (compensación)
- offset registra el número de secuencia del siguiente mensaje que se enviará a un consumidor
- Por defecto, las tiendas Kafka se compensan en zookeeper
- En una partición, los mensajes se almacenan de manera ordenada y el consumo de cada partición es una identificación incremental, que es el desplazamiento
- El desplazamiento solo tiene significado dentro de la partición y no tiene significado entre particiones.
2.5.2 Cuatro API principales de Kafka
- La API de productor (API de productor ) permite que las aplicaciones publiquen secuencias de registros en uno o más temas de Kafka (temas).
- La API del consumidor (API del consumidor ) permite que una aplicación se suscriba a uno o más temas (temas) y procese los flujos de datos resultantes grabados en ellos.
- **Streams API (Stream API)** permite que una aplicación actúe como un procesador de flujo, consumiendo flujos de entrada de uno o más temas (temas) y produciendo un flujo de salida para uno o más temas de salida (temas), transformando de manera efectiva las transformaciones. el flujo de entrada a un flujo de salida.
- Connector API (Connector API ) permite crear y ejecutar temas (temas) de Kafka para conectarse a aplicaciones o sistemas de datos existentes para reutilizar productores o consumidores. Por ejemplo, un conector a una base de datos relacional podría capturar cada cambio en una tabla.
2.5.3 Idempotencia del productor de Kafka
- idempotencia
- Tome http como ejemplo, una o más solicitudes, la respuesta obtenida es consistente, es decir, el impacto de realizar múltiples operaciones es el mismo que realizar una operación.
- Idempotencia del productor Kafka
- Cuando el productor produce un mensaje, si hay un reintento, un mensaje puede enviarse varias veces. Si Kafka no es idempotente, es posible guardar un mensaje idéntico más en la partición.
Para darse cuenta de la idempotencia de los productores, Kafka es como el concepto de ID de productor (PID) y número de secuencia.
- PID: a cada productor se le asigna un PId único cuando se inicializa, y este PID es transparente para los usuarios.
- Número de secuencia: el mensaje enviado a la partición de tema especificada para cada productor (correspondiente al PID) debe corresponder a un Número de secuencia que aumenta desde 0
Cuando el productor de Kafka produce un mensaje, agregará un pid y un número de secuencia. Al enviar un mensaje, el pid y el sn se enviarán juntos. Cuando Kafka reciba el mensaje, guardará el mensaje, el pid y el sn juntos. Si el La respuesta de reconocimiento falla, el productor vuelve a intentarlo, al enviar el mensaje nuevamente, Kafka guardará un mensaje de acuerdo con el pid/sn (condición de juicio: si el SN enviado por el productor es menor o igual que el SN correspondiente al mensaje en el dividir)
2.5.4 Estrategia de escritura de la partición del productor
El productor escribe el mensaje en el tema y Kafka distribuye los datos a diferentes particiones según cada estrategia diferente.
- Estrategia de partición por turnos
- La estrategia predeterminada, que también es la estrategia más utilizada, puede garantizar que todos los mensajes se distribuyan uniformemente en una partición en la mayor medida posible.
- Si la clave es nula cuando se genera el mensaje, se utiliza el algoritmo de operación por turnos para distribuir uniformemente las particiones.
- estrategia de partición aleatoria
- Asigne mensajes aleatoriamente a cada partición cada vez. En versiones anteriores, la estrategia de partición predeterminada es una estrategia aleatoria, que también consiste en escribir mensajes en cada partición de manera equilibrada, pero la estrategia de sondeo de seguimiento funciona mejor, por lo que rara vez utiliza estrategias aleatorias.
- Estrategia de asignación por partición clave
- Según la estrategia de asignación de claves, puede haber un sesgo de datos. Por ejemplo, si una clave contiene una gran cantidad de datos, debido a que el valor de la clave es el mismo, todos los datos se asignarán a una partición, lo que dará como resultado la cantidad de mensajes. en esta partición es mucho más grande que otras particiones.
- estrategia de partición personalizada
problema fuera de servicio
La estrategia de sondeo y la estrategia aleatoria causarán un problema: los datos producidos en Kafka se almacenan desordenados y la partición por clave puede lograr un almacenamiento ordenado de los datos hasta cierto punto, es decir, el orden local, pero esto puede provocar que los datos Inclinado, por lo que en el entorno de producción real, debe hacer una compensación basada en la situación real.
2.5.5 Mecanismo de reequilibrio del consumidor
El reequilibrio en Kafka se llama reequilibrio y es un mecanismo en Kafka para garantizar que todos los consumidores del grupo de consumidores lleguen a un consenso y asignen cada partición del tema suscrito.
El momento de activación del reequilibrio es:
- El número de consumidores en el grupo de consumidores cambia. Por ejemplo: se agrega un nuevo consumidor al grupo de consumidores o un consumidor se detiene.
Efectos adversos del reequilibrio:
- Cuando se produce un reequilibrio, todos los consumidores del grupo de consumidores se coordinarán y participarán juntos. Kafka utiliza la estrategia de distribución para lograr la distribución más justa posible.
- El proceso de reequilibrio tendrá un impacto muy grave en el grupo de consumidores. Durante el proceso de reequilibrio, todos los consumidores dejarán de funcionar hasta que se complete el reequilibrio.
2.5.6 Estrategia de asignación de particiones del consumidor
- estrategia de asignación de rango de rango
- La estrategia de asignación de rango es la estrategia de asignación predeterminada de Kafka, que puede garantizar que el número de particiones consumidas por cada consumidor esté equilibrado. Nota: la estrategia de asignación de rango es para cada tema. (Regla de asignación: número de particiones/número de consumidores, indivisible y sumar 5/3 significa que los dos primeros consumidores consumen dos mensajes (es decir, el mensaje 1.2 es consumido por 1 consumidor y el mensaje 3.4 es consumido por 2 consumidores) , El tercer consumidor consume solo un mensaje)
- Estrategia de encuesta RoundRobin
- La estrategia de sondeo es ordenar todos los consumidores en el grupo de consumidores y todas las particiones suscritas por los consumidores de acuerdo con el diccionario (ordenar el tema y el código hash de la partición) y luego asignar las particiones a cada consumidor una por una mediante sondeo.
- estrategia de asignación pegajosa y pegajosa
- Las particiones se distribuyen lo más uniformemente posible.
- Cuando se produce un reequilibrio, la asignación de particiones debe mantenerse igual que la asignación anterior tanto como sea posible. Cuando no se produce un reequilibrio, la estrategia de asignación adhesiva es similar a la estrategia de asignación roundRobin.
Tres, usa
1. conejoMQ
1.1 Cola de mensajes básica
1.1.1 Uso de la API oficial
public class Recv {
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 建立连接 对应图中的Connetcions模块
Connection connection = factory.newConnection();
// 创建通道 对应图中的Channels
Channel channel = connection.createChannel();
// 创建队列名 对应图中的Queues
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
}
}
1.1.2 Uso de Spring AMQP
-
AMQP
es un estándar para pasar mensajes comerciales entre aplicaciones o aplicaciones. El protocolo no tiene nada que ver con el idioma y la plataforma, y está más en línea con los requisitos de independencia en los microservicios.
-
Primavera AMQP
Basado en un conjunto de especificaciones API definidas por el protocolo AMQP, se proporcionan plantillas para enviar y recibir mensajes. Contiene dos partes, donde spring-amqp es la abstracción básica y spring-rabbit es la implementación predeterminada subyacente.
Utilice maven para importar dependencias relacionadas:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
Escriba la información de conexión de RabbitMQ en el archivo de configuración:
spring:
rabbitmq:
host: 127.0.0.1 # 主机
port: 5672 # 端口
virtual-host: / # 虚拟空间
username: admin # 用户名
password: 123456 # 密码
Enviar un mensaje a la cola:
@Service
public class RabbitMQServiceImpl implements IrabbitMQService {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void sendMsg(String msg) {
rabbitTemplate.convertAndSend("testQueue",msg);
}
}
1.2 Cola de mensajes de trabajo
Función: Mejorar la velocidad de procesamiento de mensajes y evitar la acumulación de mensajes. (Un mensaje corresponde a varios consumidores, quien tenga la mejor capacidad consumirá el mensaje)
Productor:
@Override
public void sengMsg2WorkQueue(String msg) {
for (int i = 0; i < 10 ; i++) {
System.out.println("工作消息队列,生产者发送消息:"+msg+i);
rabbitTemplate.convertAndSend("workQueue",msg+i);
}
}
consumidor:
/**
* 模拟两个消费者去消费工作队列中的数据
* @param msg
*/
@RabbitListener(queues = "workQueue")
public void listenWorkQueue(String msg) throws InterruptedException {
System.out.println("工作消息队列,消费者1接收消息:"+msg);
Thread.sleep(200);
}
@RabbitListener(queues = "workQueue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.out.println("工作消息队列,消费者2接收消息:"+msg);
Thread.sleep(20);
}
en conclusión:
Las noticias se distribuyen uniformemente a cada consumidor, lo que no satisface la demanda de producción en un entorno específico, y quien tenga mayor capacidad de consumo debería consumir más noticias.
Avance:
Agregue la siguiente información de configuración al archivo de configuración para resolver los problemas anteriores
listener:
simple:
prefetch: 1 # 表示每次只能占用消费一条消息
1.3 Distribución en abanico
-
Declare fanoutExchange y haga cola y vincule la cola para que se transmita al contenedor de primavera
package com.gdc.springboottest.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.FanoutExchange; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class FanoutConfig { // 1.声明交换机 @Bean public FanoutExchange fanoutExchange () { return new FanoutExchange("fanoutExchange"); } // 2.声明队列 @Bean public Queue queue1 () { return new Queue("fanoutQueue1"); } // 3.绑定 @Bean public Binding binding1 (FanoutExchange fanoutExchange,Queue queue1) { return BindingBuilder.bind(queue1).to(fanoutExchange); } // 2.声明队列2 @Bean public Queue queue2 () { return new Queue("fanoutQueue2"); } // 3.绑定 @Bean public Binding binding2 (FanoutExchange fanoutExchange,Queue queue2) { return BindingBuilder.bind(queue2).to(fanoutExchange); } } -
publicar mensaje (productor)
@Override public void sengMsg2FanoutExchange(String msg) { rabbitTemplate.convertAndSend("fanoutExchange","",msg); } -
Suscríbete a mensajes (consumidor)
/** * 监听fanoutExchange * @param msg */ @RabbitListener(queues = "fanoutQueue1") public void listenFanoutQueue1(String msg) { System.out.println("fanoutQueue1消息队列,消费者接收消息:"+msg); } @RabbitListener(queues = "fanoutQueue2") public void listenFanoutQueue2(String msg) { System.out.println("fanoutQueue2消息队列,消费者接收消息:"+msg); }
1.4 Directo
-
publicar mensaje (productor)
@Override public void sengMsg2DirectExchange(String msg, String routingKey) { rabbitTemplate.convertAndSend("directExchange",routingKey,msg); } -
Suscríbete a mensajes (consumidor)
/** * 监听directExchange * @param msg */ @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue1"), exchange = @Exchange(name = "directExchange",type = "direct"), key = { "red","orange"} )) public void listenDirectQueue1(String msg) { System.out.println("directQueue1消息队列,消费者接收消息:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue2"), exchange = @Exchange(name = "directExchange",type = "direct"), key = { "red","yellow"} )) public void listenDirectQueue2(String msg) { System.out.println("directQueue2消息队列,消费者接收消息:"+msg); }
1.5 Tema
TopicExchange es similar a DirectExchange, la diferencia es que routeKey debe ser una lista de varias palabras y estar separadas por .
Queue y Exchange pueden usar comodines al especificar Bindingkey:
#: Se refiere a 0 o más palabras
*: Se refiere a una palabra
-
publicar mensaje (productor)
@Override public void sengMsg2TopicExchange(String msg, String routingKey) { rabbitTemplate.convertAndSend("topicExchange",routingKey,msg); } -
Suscríbete a mensajes (consumidor)
/** * topic * @param msg */ @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topicQueue1"), exchange = @Exchange(name = "topicExchange",type = ExchangeTypes.TOPIC), key = "shanghai.#" )) public void listenTopictQueue1(String msg) { System.out.println("topicQueue1消息队列,消费者接收消息:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topicQueue2"), exchange = @Exchange(name = "topicExchange",type = ExchangeTypes.TOPIC), key = "#.songjiang" )) public void listenTopictQueue2(String msg) { System.out.println("topicQueue2消息队列,消费者接收消息:"+msg); }
1.6 Resolución de problemas comunes
1.6.1 Confiabilidad del mensaje
-
1. Spring AMQP implementa la confirmación del productor
- Agregar configuración en application.yml
spring: rabbitmq: publisher-confirm-type: correlated publisher-returns: true template: mandatory: trueInstrucciones de configuración:
publicar-confirmar-tipo: habilite la confirmación del editor, aquí se admiten dos tipos:
1) simple: espere sincrónicamente el resultado de confirmación hasta que se agote el tiempo de espera
2) correlacionado: devolución de llamada asincrónica, defina ConfirmCallback, MQ devolverá la llamada a este ConfirmCallback cuando devuelva el resultado
publicar-retornos: habilita la función publicar-retorno, que también se basa en el mecanismo de devolución de llamada, pero define ReturnCallback
template.mandatory: define la estrategia cuando falla el enrutamiento de mensajes. verdadero, llama a ReturnCallback, falso: descarta el mensaje directamente.
- Cada RabbitTemplate solo se puede configurar con un ReturnCallback, por lo que debe configurarse durante el inicio del proyecto:
@Configuration public class CommonConfig implements ApplicationContextAware { @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { // 从容器中获取rabbitTemplate RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class); /*rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() { @Override public void returnedMessage(Message message, int i, String s, String s1, String s2) { } });*/ // 设置ReturCallback rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> { System.out.println(message.toString()); System.out.println(replyCode); System.out.println(replyText); System.out.println(exchange); System.out.println(routingKey); }); } }- código de productor
// 消息id,唯一 CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString()); // 添加callback correlationData.getFuture().addCallback(new SuccessCallback<CorrelationData.Confirm>() { @Override public void onSuccess(CorrelationData.Confirm confirm) { if (confirm.isAck()) { System.out.println("生产者发送消息成功"); }else { System.out.println("nack"); System.out.println("消息发送失败"); System.out.println("原因:"+confirm.getReason()); } } }, new FailureCallback() { @Override public void onFailure(Throwable throwable) { System.out.println("消息发送异常"+throwable.getMessage()); } }); rabbitTemplate.convertAndSend(DIRECT_EXCHANGE,"red","hello red",correlationData);- consumidor
@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue1"), exchange = @Exchange(name = "directExchange",type = ExchangeTypes.DIRECT), key = { "red","orange"} )) public void directMsg1(String msg) { System.out.println("消费者接收消息:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue2"), exchange = @Exchange(name = "directExchange",type = ExchangeTypes.DIRECT), key = { "red","yellow"} )) public void directMsg2(String msg) { System.out.println("消费者接收消息:"+msg); } -
persistencia del mensaje
- En spring-amqp, los conmutadores predeterminados, las colas de mensajes y los mensajes son todos persistentes.
-
Confirmación de mensaje del consumidor
- Agregar (automático, ninguno, manual) al archivo de configuración
listener: simple: acknowledge-mode: auto -
Mecanismo de reintento por fallo de consumo
- archivo de configuración
listener: simple: prefetch: 1 acknowledge-mode: auto retry: enabled: true # 开启消费者失败重试 initial-interval: 1000 # 初始的失败等待时长为1秒 multiplier: 1 # 下次失败的等待时长倍数,下次等待时长=multipler * last-interval max-attempts: 3 #最大重试次数 stateless: true #true无状态,false有状态。如果业务中包含事务,这里改为false-
Después de activar el modo de reintento, el número de reintentos se agota. Si el mensaje aún falla, se requiere la interfaz MessageRecoverer para manejarlo. Contiene tres implementaciones diferentes:
-
RejectAndDontRequeueRecoverer: una vez agotados los reintentos, rechaza y descarta directamente el mensaje. Este es el valor predeterminado
-
ImmediateRequeueMessageRecoverer: una vez agotados los reintentos, se devuelve nack y el mensaje se vuelve a poner en cola
-
RepublishMessageRecoverer: una vez agotados los reintentos, entrega el mensaje de error al intercambio especificado
- El código se implementa de la siguiente manera:
@Component public class RabbitConfig { /** * 定义错误信息交换机 * @return */ @Bean public DirectExchange errMsgExchange() { return new DirectExchange("errorExchange"); } /** * 定义错误信息队列 * @return */ @Bean public Queue errQueue() { return new Queue("errQueue"); } /** * 将队列与交换机相互绑定 * @return */ @Bean public Binding errorBind() { return BindingBuilder.bind(errQueue()).to(errMsgExchange()).with("error"); } /** * 定义republishMessageRecoverer * */ @Bean public MessageRecoverer republishMessageRecoverer (RabbitTemplate rabbitTemplate) { return new RepublishMessageRecoverer(rabbitTemplate,"errorExchange","error"); } }
-
2. kafka
Importar dependencias de Kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
archivo de configuración
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092 # kafka集群信息
producer: # 生产者配置
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384 #16K
buffer-memory: 33554432 #32M
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: testGroup # 消费者组
enable-auto-commit: true # 自动提交
auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
productor
kafkaTemplate.send("testTopic", "key", msg);
consumidor
package com.gdc.springboottest.config;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaListeners {
//kafka的监听器,topic为"testTopic",消费者组为"testGroup"
@KafkaListener(topics = "testTopic", groupId = "testGroup")
public void listenKafkaMsg(ConsumerRecord<String, String> record) {
String value = record.value();
System.out.println(value);
System.out.println(record);
}
}