1. Descargar Descargue la versión tensorflow1 del código bert y el modelo de preentrenamiento desde github
1. Descargue la dirección del código bert: google-research/bert
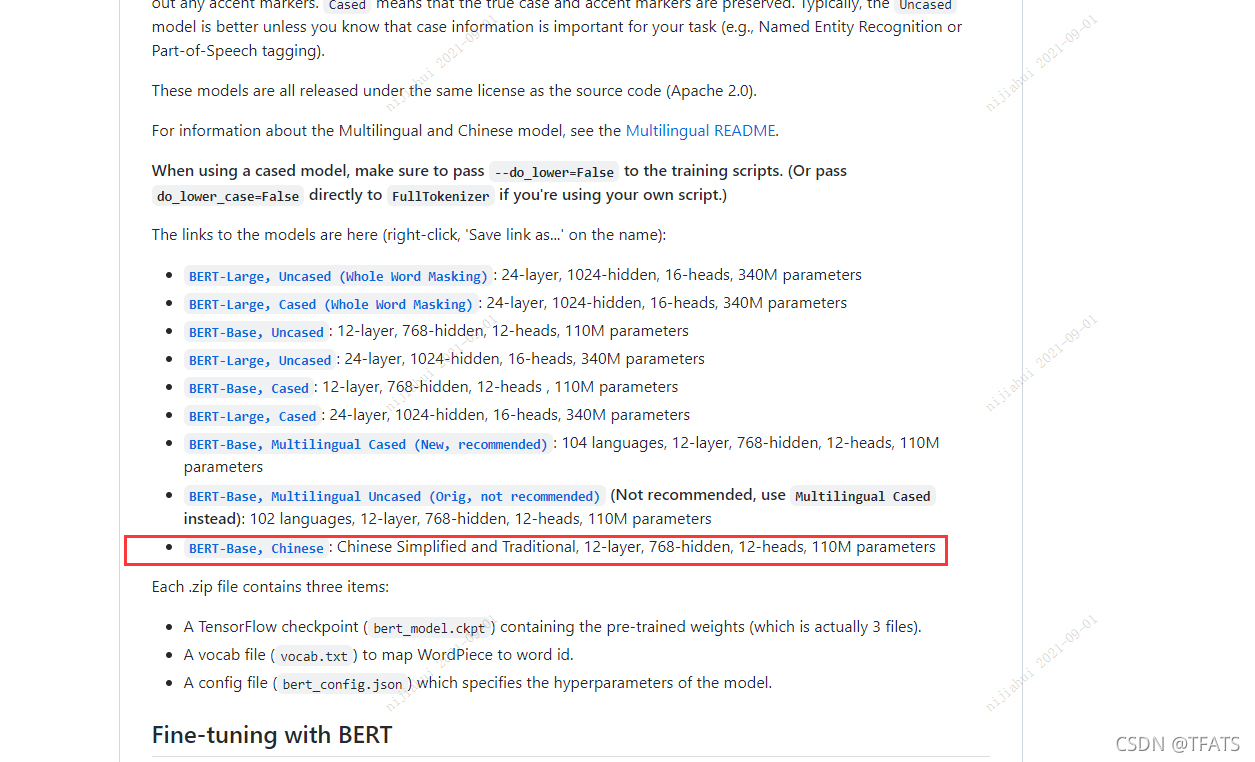
2. Descargue el modelo de preentrenamiento, aquí puede elegir la versión china de bert-base, como se muestra a continuación:
3. Cree un script de ejecución como se muestra en el sitio web oficial, que es conveniente para pasar parámetros, como se muestra en la siguiente figura:
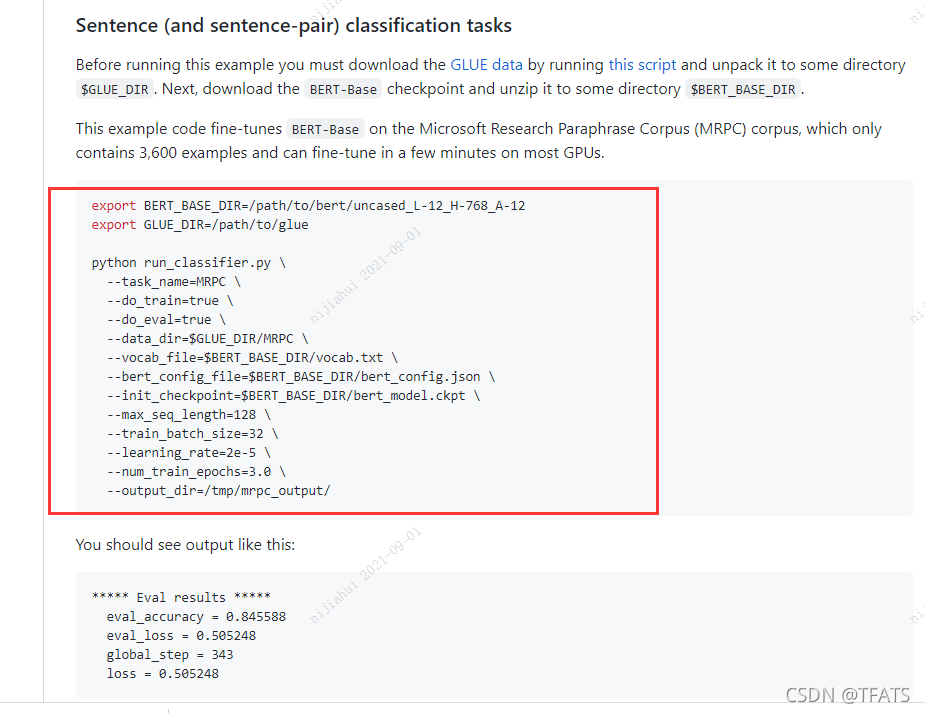
Segundo, modifique y cree el script de ejecución.
Según la cantidad de GPU en la máquina, Horovod ejecuta entrenamiento con múltiples tarjetas
gpu_num=$(nvidia-smi --query-gpu=name --format=csv,noheader | wc -l)
horovodrun -np ${
gpu_num} -H localhost:${
gpu_num} python run_classifier_roberta_wwm_large.py \
--task_name=$TASK_NAME \
--do_train=true \
--do_predict=true \
--data_dir=$GLUE_DATA_DIR/$TASK_NAME \
--vocab_file=$ROBERTA_WWM_LARGE_DIR/vocab.txt \
--bert_config_file=$ROBERTA_WWM_LARGE_DIR/bert_config.json \
--init_checkpoint=$ROBERTA_WWM_LARGE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=4.0 \
--output_dir=$CURRENT_DIR/${
TASK_NAME}_output \
Nota: Si es necesario agregar o modificar los parámetros pasados al archivo de ejecución en el script, deben ir seguidos de \un símbolo
Tercero, modifique el archivo run_classifier.py
#chang 1:引入horovod
flags = tf.flags
FLAGS = flags.FLAGS
import optimization_hvd
import horovod.tensorflow as hvd
hvd.init()
os.environ['CUDA_VISIBLE_DEVICES'] = str(hvd.local_rank())
config = tf.ConfigProto(allow_soft_placement=True)
config.gpu_options.per_process_gpu_memory_fraction = 0.998
config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1
config.gpu_options.allow_growth = True
...
def get_train_examples(self, data_dir):
"""See base class."""
#chang 2 修改训练数据创建方式
return self._create_examples_train(
self._read_json(os.path.join(data_dir, "train.json")))
#chang 3 新增训练数据创建代码
def _create_examples(self, lines):
"""See base class."""
examples = []
for (i, line) in enumerate(lines):
# 【二,horovod - 区对数据 - 分卡处理】
if i % hvd.size() != hvd.rank():
continue
guid = "%s" % (i) if 'id' not in line else line['id']
text_a = tokenization.convert_to_unicode(line['text'])
label = ['O'] * len(text_a)
if 'label' in line:
for l, words in line['label'].items():
for word, indices in words.items():
for index in indices:
if index[0] == index[1]:
label[index[0]] = 'S-' + l
else:
label[index[0]] = 'B-' + l
label[index[1]] = 'E-' + l
for i in range(index[0] + 1, index[1]):
label[i] = 'M-' + l
examples.append(
InputExample(guid=guid, text_a=text_a, label=label))
def _create_examples(self, file_path, set_type):
...
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
#chang 4 为不同的rank定义不同的输出文件名
FLAGS.output_dir = FLAGS.output_dir if hvd.rank() == 0 else os.path.join(FLAGS.output_dir, str(hvd.rank()))
run_config = tf.contrib.tpu.RunConfig(
cluster=tpu_cluster_resolver,
master=FLAGS.master,
model_dir=FLAGS.output_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps,
#chang 5 设置配置
session_config=config,
tpu_config=tf.contrib.tpu.TPUConfig(
iterations_per_loop=FLAGS.iterations_per_loop,
num_shards=FLAGS.num_tpu_cores,
per_host_input_for_training=is_per_host))
...
if FLAGS.do_train:
train_file = os.path.join(FLAGS.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
...
# change 6 确保每个进程拥有同样的初始化权重
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps, hooks=hooks)
#change 7 #只在编号为0的GPU上进行评估
if FLAGS.do_eval and hvd.rank() == 0:
...
#change 8 #只在编号为0的GPU上进行预测
if FLAGS.do_predict and hvd.rank() == 0 :
Cuarto, modifique el archivo optimización.py.
# change 1 导入horovod包、使用混合精度训练
import horovod.tensorflow as hvd
import os
os.environ['TF_AUTO_MIXED_PRECISION_GRAPH_REWRITE_IGNORE_PERFORMANCE'] = '1' ## 混合精度训练
# change 2 修改【create_optimizer】 函数
def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, use_tpu):
...
optimizer = AdamWeightDecayOptimizer(
# Change 3 (optional) 学习率乘以GPU个数
learning_rate=learning_rate * hvd.size(),
...)
# Change 4 使用hvd分布式优化器
# optimizer = tf.train.experimental.enable_mixed_precision_graph_rewrite(optimizer)
optimizer = hvd.DistributedOptimizer(optimizer)
if use_tpu:
optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer)
tvars = tf.trainable_variables()
# Change 5 使用分布式优化器计算梯度
# grads = tf.gradients(loss, tvars)
grads_and_vars = optimizer.compute_gradients(loss, tvars)
# Change 6 根据分布式优化器的调试进行梯度裁剪
grads = [grad for grad, var in grads_and_vars]
tvars = [var for grad, var in grads_and_vars]
# This is how the model was pre-trained.
(grads, _) = tf.clip_by_global_norm(grads, clip_norm=1.0)
# Change 7 调整梯度裁剪进行优化
train_op = optimizer.apply_gradients(
zip(grads, tvars), global_step=global_step)
# Normally the global step update is done inside of `apply_gradients`.
# However, `AdamWeightDecayOptimizer` doesn't do this. But if you use
# a different optimizer, you should probably take this line out.
new_global_step = global_step + 1
train_op = tf.group(train_op, [global_step.assign(new_global_step)])
return train_op