Tiempo estimado de lectura de este artículo: 15 minutos
Antes de mirar la pila de tecnología específica: springboot mysql nginx (solo entienda)
Tabla de contenido
1. Hablemos de reducción de inventario
1.2 Implementación simple de reducción de inventario
1.3 Demostración del fenómeno de sobreventa
1.4 Demostración del problema de bloqueo jvm
1.5.1 Instalar y configurar nginx
1.6. demostración de bloqueo mysql
1.6.3 defecto de bloqueo mysql
2. Realizar bloqueo distribuido basado en mysql
0. escribir delante
En escenarios de alta concurrencia de subprocesos múltiples, para garantizar la seguridad de subprocesos de los recursos, jdk nos proporciona palabras clave sincronizadas y
bloqueos de reentrada ReentrantLock, pero solo pueden garantizar la seguridad de subprocesos dentro de un jvm. En la actualidad, cuando los clústeres distribuidos, los microservicios y la nube nativa son rampantes, jdk no nos brinda las soluciones existentes para garantizar la seguridad de subprocesos de diferentes procesos, servicios y máquinas. En este punto, tenemos que implementarlo manualmente con la ayuda de tecnologías relacionadas. Actualmente existen tres métodos principales de implementación:
1. Basado en la implementación relacional de mysql
2. Basado en la implementación de datos no relacionales de redis
3. Basado en la implementación de zookeeper
Este artículo explica principalmente la realización del bloqueo distribuido basado en el tipo relacional mysql
1. Hablemos de reducción de inventario
El inventario es propenso a la sobreventa cuando la concurrencia es grande, una vez que ocurre el fenómeno de sobreventa, habrá una situación en la que se venderán más pedidos y los productos no se podrán entregar.
Escenario:
Cuando el saldo de stock del producto S es 5, los usuarios A y B compran al mismo tiempo un producto S. En este momento, el inventario de consulta es 5. Si el stock es suficiente, el stock se reducirá: Usuario A: actualizar db_stock set stock = stock - 1
donde id = 1
Usuario B: actualizar db_stock set stock = stock - 1 donde id = 1
En caso de concurrencia, el resultado actualizado puede ser 4, pero el stock final real debe ser 3
1.1 Preparación del entorno
Para simular escenarios específicos, necesitamos preparar el entorno de desarrollo.
Primero, debe preparar una tabla en la base de datos mysql:
CREATE TABLE `db_stock` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`product_code` varchar(255) DEFAULT NULL COMMENT '商品编号',
`stock_code` varchar(255) DEFAULT NULL COMMENT '仓库编号',
`count` int(11) DEFAULT NULL COMMENT '库存量',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;Los datos de la tabla son los siguientes:

Cree un proyecto de demostración de bloqueo distribuido:
Cree la siguiente estructura de directorio de herramientas:
archivo de dependencia pom:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>archivo de configuración application.yml:
server:
port: 6000
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://172.16.116.100:3306/test
username: root
password: rootClase de inicio DistributedLockApplication:
@SpringBootApplication
@MapperScan("com.atguigu.distributedlock.mapper")
public class DistributedLockApplication {
public static void main(String[] args) {
SpringApplication.run(DistributedLockApplication.class, args);
}
}Clase de entidad bursátil:
@Data
@TableName("db_stock")
public class Stock {
@TableId
private Long id;
private String productCode;
private String stockCode;
private Integer count;
}Interfaz de StockMapper:
public interface StockMapper extends BaseMapper<Stock> {
}1.2 Implementación simple de reducción de inventario
A continuación, practiquemos el código.

Controlador de mercancía:
@RestController
public class StockController {
@Autowired
private StockService stockService;
@GetMapping("check/lock")
public String checkAndLock(){
this.stockService.checkAndLock();
return "验库存并锁库存成功!";
}
}Servicio de existencias:
@Service
public class StockService {
@Autowired
private StockMapper stockMapper;
public void checkAndLock() {
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0) {
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
}
}prueba:

Consulta la base de datos:
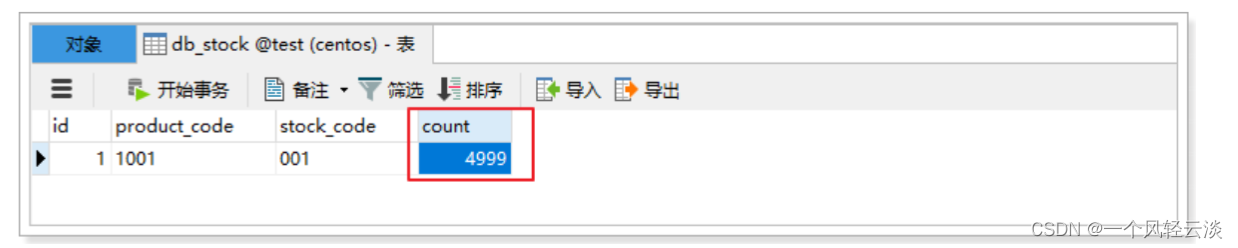
Al visitar uno a uno en el navegador, el inventario se reduce en 1 por cada visita, y no hay problema.
1.3 Demostración del fenómeno de sobreventa
A continuación, usamos la herramienta de prueba de estrés jmeter para probar bajo alta concurrencia y agregar un grupo de hilos: 100 ciclos concurrentes 50 veces, es decir, 5000 solicitudes.

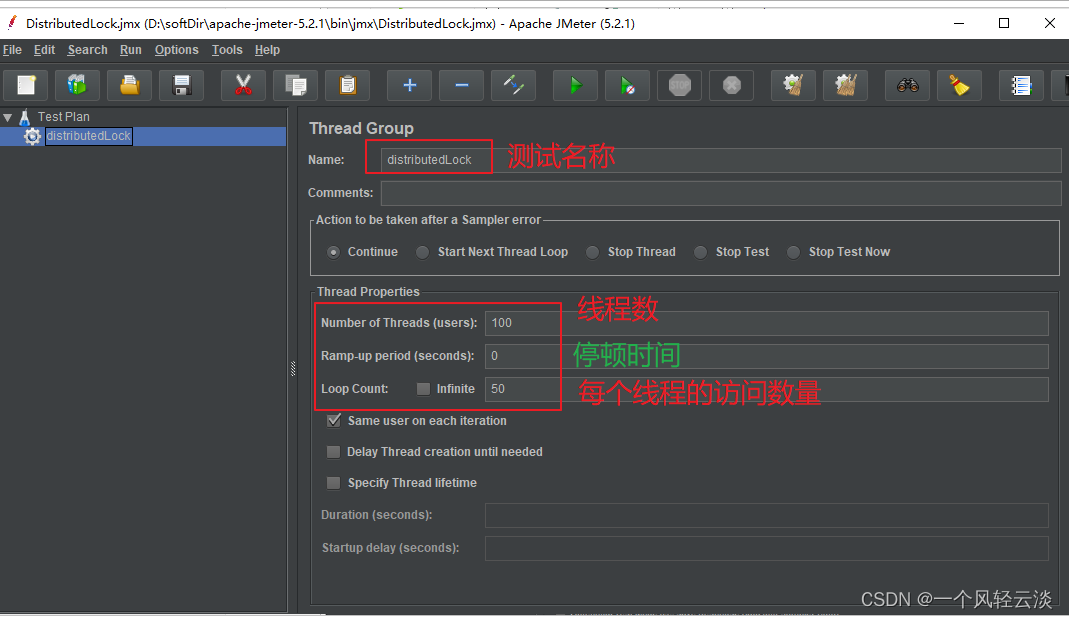
Agregue una solicitud HTTP al grupo de hilos:
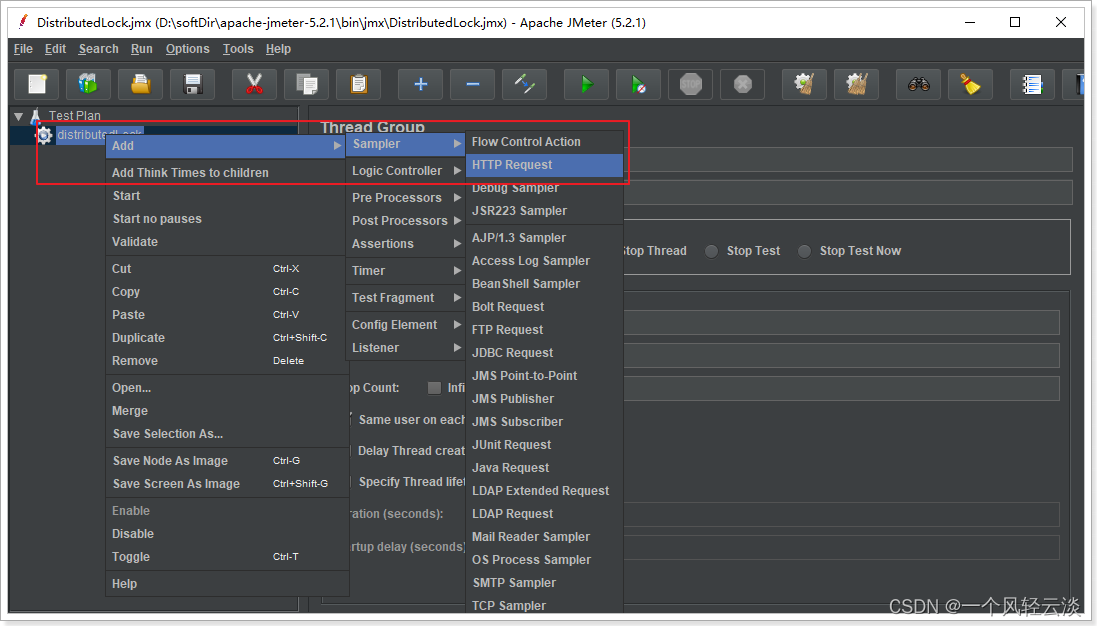
Complete la ruta de la interfaz de prueba de la siguiente manera:

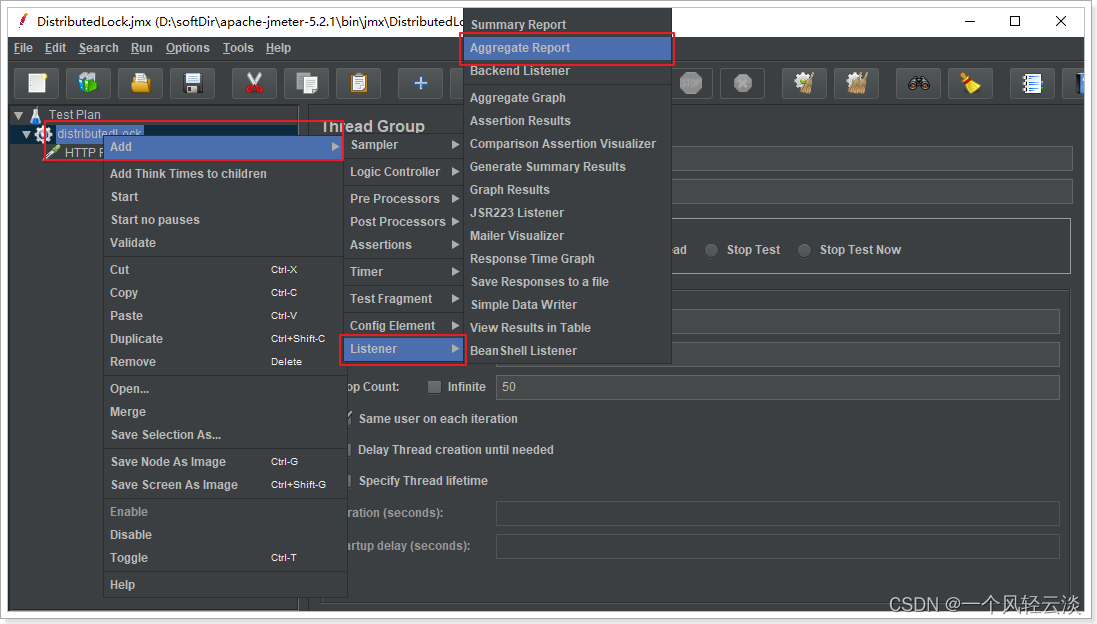
Luego seleccione el informe de prueba que desea, por ejemplo, seleccione el informe de agregación aquí:
Inicie la prueba y vea el informe de la prueba de esfuerzo:
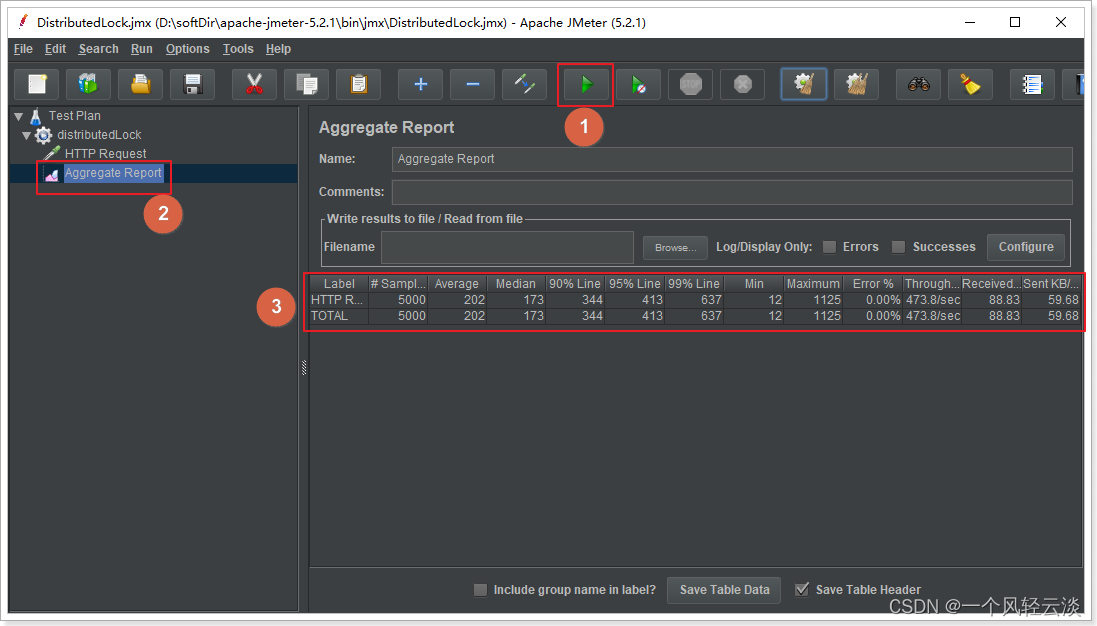
Resultados de la prueba: el número total de solicitudes es 5000, el tiempo de solicitud promedio es de 202 ms, la solicitud mediana (50 %) se completa en 173 ms, el 90 % de las solicitudes se completa en 344 ms, el tiempo mínimo es de 12 ms, el máximo consume mucho tiempo es 1125ms, la tasa de error 0%, un promedio de 473,8 veces por segundo.
Ver el inventario restante de la base de datos mysql: hay 4870

Si todavía hay personas que hacen pedidos en este momento, habrá un fenómeno de sobreventa (otros compran con éxito, pero no hay productos para enviar).
1.4 Demostración del problema de bloqueo jvm
Intente usar jvm lock (palabra clave sincronizada o ReetrantLock):

Reinicie el servicio tomcat y use la prueba de estrés jmeter nuevamente, el efecto es el siguiente:

Ver la base de datos mysql:
 No hay fenómeno de sobreventa, una solución perfecta.
No hay fenómeno de sobreventa, una solución perfecta.
1.4.2 Principio
Después de agregar la palabra clave sincronizada, StockService tiene un bloqueo de objetos. Debido a la adición de un bloqueo exclusivo exclusivo, solo una solicitud puede obtener el bloqueo al mismo tiempo y el inventario se reduce. En este momento, todas las solicitudes solo se ejecutarán una por una y no se producirá una sobreventa.
1.5 Problema multiservicio
De hecho, no hay problema con el uso de bloqueos jvm en el caso de un solo proyecto y un solo servicio, pero ¿qué sucede en una situación de clúster? A continuación, inicie varios servicios y utilice el balanceo de carga de nginx, la estructura es la siguiente:

Inicie tres servicios (los números de puerto son 8000 8100 8200), de la siguiente manera:

1.5.1 Instalar y configurar nginx
Instalar nginx basado en:
# 拉取镜像
docker pull nginx:latest
# 创建nginx对应资源、日志及配置目录
mkdir -p /opt/nginx/logs /opt/nginx/conf /opt/nginx/html
# 先在conf目录下创建nginx.conf文件,配置内容参照下方
# 再运行容器
docker run -d -p 80:80 --name nginx -v /opt/nginx/html:/usr/share/nginx/html
-v /opt/nginx/conf/nginx.conf:/etc/nginx/nginx.conf -v
/opt/nginx/logs:/var/log/nginx nginx
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
#include /etc/nginx/conf.d/*.conf;
upstream distributed {
server 172.16.116.1:8000;
server 172.16.116.1:8100;
server 172.16.116.1:8200;
}
server {
listen 80;
server_name 172.16.116.100;
location / {
proxy_pass http://distributed;
}
}
}Prueba en el navegador: 172.16.116.100 es la dirección de mi servidor nginx
 Después de la prueba, todo es normal al acceder a los servicios a través de nginx.
Después de la prueba, todo es normal al acceder a los servicios a través de nginx.
1.5.2 Pruebas de estrés
Nota: primero restaure el inventario de la base de datos a 5000.
Haciendo referencia al caso de prueba anterior, cree un nuevo grupo de prueba: los parámetros son los mismos que antes
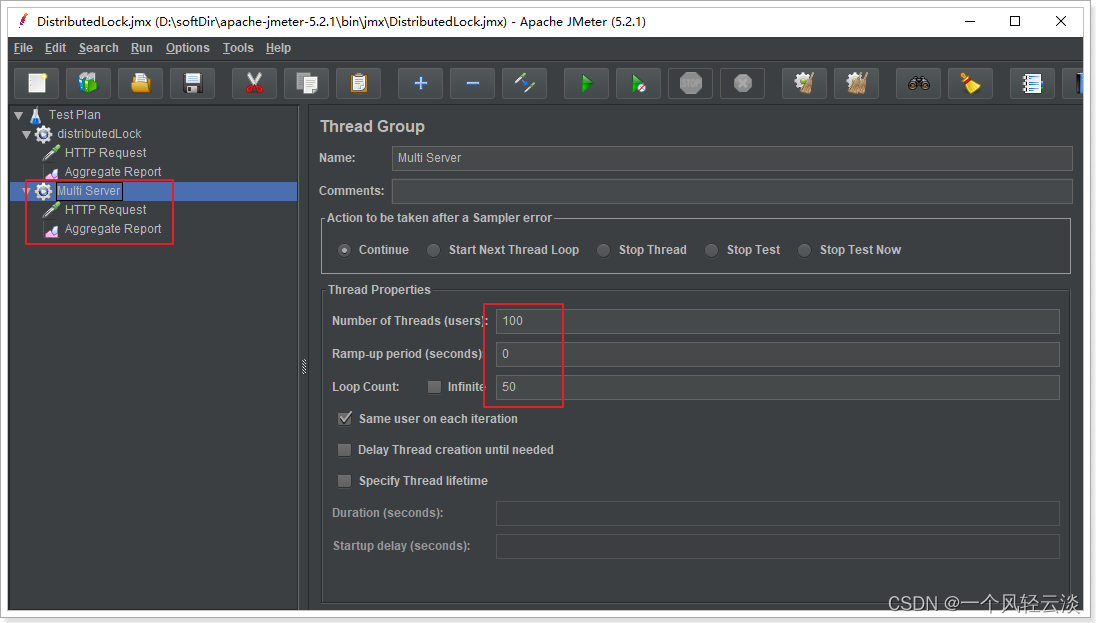
Configure la dirección de nginx y la ruta de acceso del servicio de la siguiente manera:
 Resultados de la prueba: el rendimiento solo mejora ligeramente.
Resultados de la prueba: el rendimiento solo mejora ligeramente.
 El inventario de la base de datos restante es el siguiente:
El inventario de la base de datos restante es el siguiente:
Hay otro problema de concurrencia, es decir, un fenómeno de sobreventa.
1.6. demostración de bloqueo mysql
Además de usar bloqueos jvm, también puede usar bloqueos de datos: bloqueos pesimistas o bloqueos optimistas
Bloqueo pesimista: bloquee esas filas al leer datos, y otras actualizaciones de estas filas deben esperar hasta el final del bloqueo pesimista para continuar. Optimista: sin bloqueo al leer datos, verifique si los datos se han actualizado al actualizar, si es así, cancele la actualización actual, generalmente elegiremos el bloqueo optimista cuando el tiempo de espera del bloqueo pesimista sea demasiado largo e inaceptable.
1.6.1 Bloqueo pesimista mysql
En InnoDB de MySQL, el nivel de aislamiento de Tansaction predeterminado es LECTURA REPETIBLE (relegible)
Hay dos tipos principales de bloqueos de lectura en SELECT:
- SELECCIONE... BLOQUEO EN MODO COMPARTIR (bloqueo compartido)
- SELECCIONE... PARA ACTUALIZAR (bloqueo pesimista)
Estos dos métodos deben esperar a que se envíen otros datos de transacción (Commit) antes de ejecutarse cuando se SELECCIONA en la misma tabla de datos durante la transacción (Transacción). La principal diferencia es que el BLOQUEO EN MODO COMPARTIDO puede provocar fácilmente un punto muerto cuando una transacción quiere actualizar el mismo formulario. En pocas palabras, si desea ACTUALIZAR el mismo formulario después de SELECCIONAR, es mejor usar SELECCIONAR ... PARA ACTUALIZAR.
Implementación de código para transformar StockService:
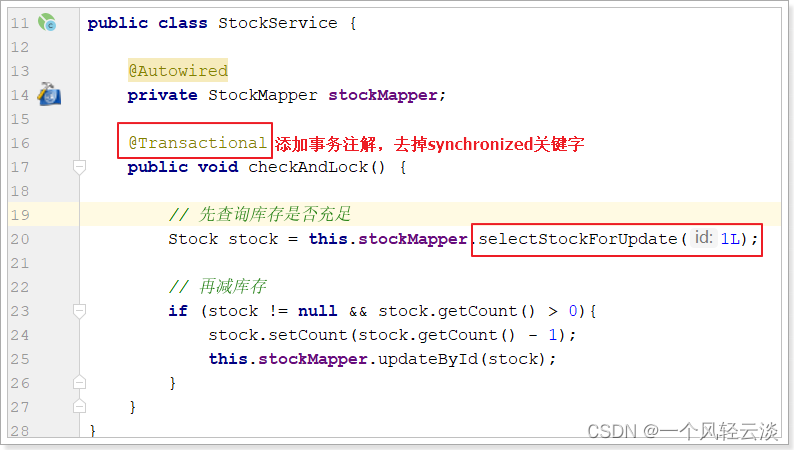
Defina el método selectStockForUpdate en StockeMapper:
public interface StockMapper extends BaseMapper<Stock> {
public Stock selectStockForUpdate(Long id);
}
Defina la configuración correspondiente en StockMapper.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.distributedlock.mapper.StockMapper">
<select id="selectStockForUpdate"
resultType="com.atguigu.distributedlock.pojo.Stock">
select * from db_stock where id = #{id} for update
</select>
</mapper>
test de presión
Nota: antes de la prueba, debe cambiar el inventario a 5000. Los datos de la prueba de presión son los siguientes: rendimiento mucho mayor que jvm, casi 1 veces menor que sin bloqueo

biblioteca de base de datos mysql:

1.6.2 Bloqueo optimista mysql
Bloqueo optimista (Bloqueo optimista) En comparación con el bloqueo pesimista, el bloqueo optimista supone que los datos no causarán conflictos en circunstancias normales, por lo que cuando los datos se envían para su actualización, detectará formalmente si los datos están en conflicto o no. intentar otra vez. Entonces, ¿cómo implementamos el bloqueo optimista?
Se implementa utilizando el mecanismo de grabación de la versión de datos (Version), que es la implementación más utilizada del bloqueo optimista. Esto generalmente se logra agregando un campo de "versión" numérico a la tabla de la base de datos. Al leer datos, lea el valor del campo de versión juntos. Cada vez que se actualizan los datos, el valor de la versión se incrementa en uno. Cuando enviamos una actualización, juzgamos que la información de la versión actual del registro correspondiente en la tabla de la base de datos se compara con el valor de la versión extraído por primera vez. Si el número de la versión actual de la tabla de la base de datos es igual al valor de la versión extraído para la primera vez, se actualiza.
Agregue un campo de versión a la tabla db_stock:

En consecuencia, también debe agregar un atributo de versión a la clase de entidad Stock. Omitir aquí.
Código
public void checkAndLock() {
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
// 获取版本号
Long version = stock.getVersion();
stock.setCount(stock.getCount() - 1);
// 每次更新 版本号 + 1
stock.setVersion(stock.getVersion() + 1);
// 更新之前先判断是否是之前查询的那个版本,如果不是重试
if (this.stockMapper.update(stock, new UpdateWrapper<Stock>
().eq("id", stock.getId()).eq("version", version)) == 0) {
checkAndLock();
}
}
}
Después de reiniciar, los resultados del uso de la herramienta de prueba de esfuerzo jmeter son los siguientes:

Modifique los parámetros de prueba de la siguiente manera:
 Los resultados de la prueba son los siguientes:
Los resultados de la prueba son los siguientes:

Muestra que cuanto mayor sea la cantidad de concurrencia, menor será el rendimiento del bloqueo optimista (porque se requiere una gran cantidad de reintentos); cuanto menor sea la cantidad de concurrencia, mayor será el rendimiento.
1.6.3 defecto de bloqueo mysql
En el caso de los clústeres de bases de datos, los bloqueos de bases de datos dejarán de ser válidos y muchos middleware de clústeres de bases de datos no admiten bloqueos pesimistas en absoluto. Por ejemplo: mycat, en el escenario de separación de lectura y escritura, el bloqueo optimista puede no ser confiable. Este bloqueo depende en gran medida de la disponibilidad de la base de datos. La base de datos es un solo punto. Una vez que la base de datos está inactiva, el sistema comercial no estará disponible.
2. Realizar bloqueo distribuido basado en mysql
Ya sea un bloqueo jvm o un bloqueo mysql, para garantizar la seguridad simultánea de los subprocesos, se proporciona un bloqueo exclusivo exclusivo pesimista. Por lo tanto, la exclusividad también es un requisito básico de los bloqueos distribuidos. Se puede realizar utilizando la característica de que el índice de clave único no se puede insertar repetidamente. La tabla de diseño es la siguiente:
CREATE TABLE `db_lock` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`lock_name` varchar(50) NOT NULL COMMENT '锁名',
`class_name` varchar(100) DEFAULT NULL COMMENT '类名',
`method_name` varchar(50) DEFAULT NULL COMMENT '方法名',
`server_name` varchar(50) DEFAULT NULL COMMENT '服务器ip',
`thread_name` varchar(50) DEFAULT NULL COMMENT '线程名',
`create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP
COMMENT '获取锁时间',
`desc` varchar(100) DEFAULT NULL COMMENT '描述',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_unique` (`lock_name`)
) ENGINE=InnoDB AUTO_INCREMENT=1332899824461455363 DEFAULT CHARSET=utf8;
Clase de entidad de bloqueo:
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("db_lock")
public class Lock {
private Long id;
private String lockName;
private String className;
private String methodName;
private String serverName;
private String threadName;
private Date createTime;
private String desc;
}
Interfaz de LockMapper:
public interface LockMapper extends BaseMapper<Lock> {
}
2.1 Idea básica
La palabra clave sincronizada y el bloqueo ReetrantLock son bloqueos exclusivos y exclusivos, es decir, cuando varios subprocesos compiten por un recurso, solo un subproceso puede apoderarse del recurso al mismo tiempo, y otros subprocesos solo pueden bloquear y esperar hasta que el subproceso que posee. el recurso libera el recurso.
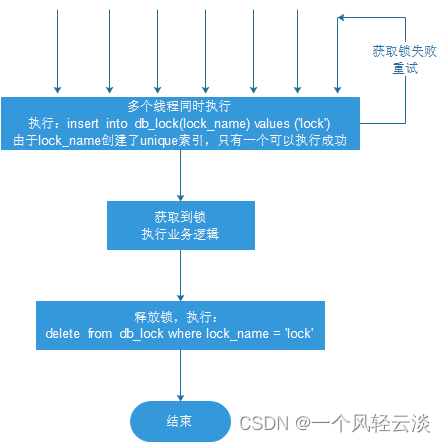
- Los subprocesos adquieren bloqueos simultáneamente (insertar)
- La adquisición es exitosa, la lógica de negocios se ejecuta y la ejecución se completa para liberar el bloqueo (eliminar)
- Otros subprocesos esperan para volver a intentarlo
2.2 Implementación del código
Servicio de actualización de existencias:
@Service
public class StockService {
@Autowired
private StockMapper stockMapper;
@Autowired
private LockMapper lockMapper;
/**
* 数据库分布式锁
*/
public void checkAndLock() {
// 加锁
Lock lock = new Lock(null, "lock", this.getClass().getName(), new
Date(), null);
try {
this.lockMapper.insert(lock);
} catch (Exception ex) {
// 获取锁失败,则重试
try {
Thread.sleep(50);
this.checkAndLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// 释放锁
this.lockMapper.deleteById(lock.getId());
}
}
Cerrar con llave:
// 加锁
Lock lock = new Lock(null, "lock", this.getClass().getName(), new Date(), null);
try {
this.lockMapper.insert(lock);
} catch (Exception ex) {
// 获取锁失败,则重试
try {
Thread.sleep(50);
this.checkAndLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}desbloquear:
// 释放锁
this.lockMapper.deleteById(lock.getId());
Usando los resultados de la prueba de esfuerzo de Jmeter:
 Se puede ver que la actuación es conmovedora. El saldo de inventario de la base de datos mysql es 0, lo que puede garantizar la seguridad de subprocesos.
Se puede ver que la actuación es conmovedora. El saldo de inventario de la base de datos mysql es 0, lo que puede garantizar la seguridad de subprocesos.
2.3 Defectos y soluciones
1. Este bloqueo depende en gran medida de la disponibilidad de la base de datos. La base de datos es un solo punto. Una vez que la base de datos está inactiva, el sistema comercial no estará disponible.
Solución: cree un maestro y una copia de seguridad para la base de datos de bloqueo
2. Este bloqueo no tiene tiempo de caducidad. Una vez que falla la operación de desbloqueo, el registro de bloqueo permanecerá en la base de datos y otros subprocesos ya no podrán obtener el bloqueo.
Solución: simplemente realice una tarea cronometrada para limpiar los datos de horas extra en la base de datos a intervalos regulares.
3. Este bloqueo no es reentrante y el mismo subproceso no puede volver a adquirir el bloqueo hasta que se libere. Porque los datos en los datos ya existen.
Solución: registre la información del host y la información del subproceso que adquirió el bloqueo. Si el mismo subproceso desea adquirir el bloqueo, vuelva a ingresar directamente.
4. Debido al rendimiento de la base de datos, la capacidad de concurrencia es limitada.
Solución: No se puede resolver.